
Java基础--说集合框架
版权所有,转载注明出处。
1,Java中,集合是什么?为什么会出现?
根据数学的定义,集合是一个元素或多个元素的构成,即集合一个装有元素的容器。
Java中已经有数组这一装有元素的容器,为什么还要新建其它容器?废话,肯定是数组满足不了实际需求。
数组满足不了的需求:
-
-
- 动态改变容器的大小,如果加入的元素个数不确定,我们需要动态改变容器的大小。
- 数组提供的功能和性能不完善,例如查找效率低,元素之间是无序的。作为成熟的编程语言,Java需要提供更加功能更加丰富的容器。
-
鉴于此,Java创建了集合框架的相关接口和实现类。
2,集合框架的设计思想是什么?
由上所述,Java集合框架首先要可以动态改变添加和删除元素,此外还要提供更丰富的方法来处理数据。
由于集合是依赖数据元素而存在的,考虑元素的构成,我们可以将程序需要处理的数据抽象成类似于关系数据库的形式,每一行是一个数据,并且有索引(主键),我们将数据分为<索引:数据>这样的键值对形式,Java中用Map接口就是基于此产生。
考虑数据为单一元素时(基本数据类型或引用类型),虽然仍可以用Map存储(可以用一个自增值作为键)但意义不大。为了适应这种情况Collection接口被创造出来。
以上就是Java集合框架顶层接口Map和Collection的设计初衷。
3,具体集合类有哪些?它们特点是什么?
3.1、首先考虑简单的Collection接口,对于单个元素存储来说,根据单个元素属性来创建Collection的子接口或者实现类。这些属性有是否要存储相同的,存储是否是有序的。在Java中我们根据是否要存储相同元素设计了Collection常用的两个子接口List和Set.相同和不相同的判断默认判断标准是e1.equals(e2)。
-
- List:可以存储重复元素
- Set:只存不同元素
List:实现List接口常见的类有:
-
-
- ArrayList:底层是可变数组数据结构实现,因此查询快(地址连续,跳转少),增删慢(地址改变),但线程不安全,多线程用时注意。
- Vector:线程安全的ArrayList,每个方法都被同步了,因此使用效率低,实际中使用较少。
- LinkedList:底层用双向链表实现,因此查询慢(地址跳转多),增删快。
-
使用原则:不考虑性能,常用ArrayList。当考虑性能时,如果需要查询操作较多用ArrayList,增删操作较多则用LinkedList
Set:实现Set接口常见的类有,Set用默认用元素的hashCode()方法保证元素的唯一性。
-
-
- HashSet:底层用哈希表实现,无序,加入顺序和存储顺序没有必然联系。
- TreeSet:底层用红黑树(自平衡的二叉树)。使用元素的自然顺序,e1.equals(e2)比较作为大小判断标准。
-
使用原则:根据是否需要对添加的元素进行划分。需要用TreeSet,否则用HashSet
3.2 Map接口,Map接口较为简单,不过需要强调的是Map进行比较等操作都是针对键来说的。常用的实现类:
-
-
- HashMap:无序
- TreeMap:有序
- HashTable:HashMap的线程安全实现,不允许NULL,作为键值。
-
4,具体集合类常用方法?注意事项?
对于集合类来讲,添加,查找,遍历,删除是必须的。其中添加,查找,遍历是基础操作,其它都是依赖于这些操作进行的。
4.1Collection:
添加:boolean add(E e)
查找:boolean contains(Object o)是否包含
遍历:用迭代器接口Iterator<E> iterator()
使用样例:


Iterator it = c.iterator(); while(it.hasNext()){ it.next(); }
以ArrayList为例:
import java.util.ArrayList; import java.util.Collection; import java.util.Iterator; public class ArrayListDemo { public static void main(String[] args) { Collection<String> al = new ArrayList<String>(); al.add("a");//添加 al.add("b"); al.add("c"); al.add("d"); //查询是否含有 System.out.println(al.contains("a")); //遍历 Iterator<String> i = al.iterator(); while(i.hasNext()){ String tmp = i.next(); System.out.println(tmp); } for(String str:al){System.out.println(str);} } }
类特有的方法
ArrayList,由于ArrayList是用可变数组实现的因此会有关索引的操作。
ArrayList:扩容如果初始不指明ArrayList大小,则初始化为10
当需要扩容时,可以指定扩容大小,默认增长为原来的1.5倍-1(Vector扩容为原来的一倍。)
ArrayList()是顺序添加元素。先进位置越靠前。
E get(int index):返回索引位置的的数据
E set(int index, E element):修改索引位置的元素
E remove(int index)
boolean remove(Object o)
LinkedList,采用双向链表实现,因此具备一个反向的迭代器。
ListIterator<String> i = lk.listIterator(lk.size()); while(i.hasPrevious()){ String tmp = i.previous(); System.out.println(tmp); } for(String str:lk){System.out.println(str);} /** * d * c * b * a * a * b * c * d */
Set:
-
- 保证元素的唯一性机制
查看Set的add方法源码:boolean add(E e);是一个抽象方法,
因此定位到HashSet的add()方法
//HashSet的add源码 map是一个HashMap对象 public boolean add(E e) { return map.put(e, PRESENT)==null; }
发现HashSet是使用HashMap来保证元素的唯一性。追踪的HashMap的put()方法源码:
int hash = hash(key); int i = indexFor(hash, table.length); for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; addEntry(hash, key, value, i); return null;
添加元素时先计算待添加元素的哈希值,然后从table中查找,如果查找到,则e不为空,不进入循环,则原来的元素不动,否则进入循环再利用equals() 方法判断是否和其它元素相同。
综上Set用来保证元素唯一性的机制是:
比较hashCode(),根据hashCode()查找元素:
查找:
yes-->原来位置的元素不发生改变
no:
用equals()和其他元素相比
相同 原来位置的元素不发生改变
不同 加入新元素
同理追踪TreeSet的源码可以得到它也是由TreeMap来保证有序的。
-
- HashSet的使用
和ArrayList类似没有很特殊的方法,如果需要加入的元素的不同一般使用HashSet
-
- TreeSet的使用
TreeSet可以保证元素以自然顺序(equals())排列,默认递增。
-
- 使用Set注意事项
保证引用类型元素唯一:
其实,Set使用元素的hashCode()返回值和equals()保证唯一,用默认的比较器保证有序,这在元素是基本数据类型时没有问题的,但当数据元素是引用类型时,由于相同对象的不同引用可能在现实中代表同一个对象实例。例如一下情景:
Student类
//假设业务要求姓名和年龄相同代表同一个学生 public class Student(){ String name; int age; public Student(String name, int age){ this.name = name; this.age = age; } }
HashSetDemo主类
import java.util.HashSet; import java.util.Set; public class HashSetDemo { public static void main(String[] args) { Set<Student> s = new HashSet<Student>(); Student s1 = new Student("小明",16); Student s2 = new Student("小明",16); s.add(s1); s.add(s2); for(Student st:s){System.out.println(st);} } } /* * 输出: * collection.Student@4b0bc3c9 * collection.Student@5f0ee5b8 * */
可以看到HashSet将相同的一个人加了两次,因此为了这种情况,在数据元素是自定义类时,我们通常需要自定义hashCode()方法和equals()方法。
就需要改写方法元素的hashCode()和equals()方法。在Eclipse中可以自动生成。Source-->Generate hashCode()和equals()
修改后的Student类
public class Student { @Override public String toString() { return "Student [name=" + name + ", age=" + age + "]"; } @Override public int hashCode() { final int prime = 31; int result = 1; result = prime * result + age; result = prime * result + ((name == null) ? 0 : name.hashCode()); return result; } @Override public boolean equals(Object obj) { if (this == obj) return true; if (obj == null) return false; if (getClass() != obj.getClass()) return false; Student other = (Student) obj; if (age != other.age) return false; if (name == null) { if (other.name != null) return false; } else if (!name.equals(other.name)) return false; return true; } String name; int age; public Student(String name, int age){ this.name = name; this.age = age; } }
TreeSet保证引用类型有序
TreeSet构造方法
TreeSet(Comparator<? super E> comparator).Comparator是一个比较器接口,我们新建TreeSet时不声明比较器,这时TreeSet按照元素的自然顺序(equals())上升排序,当我们自定义Comparator类后TreeSet就可以按照我们业务要求来写比较器。下面是一个针对学生类的比较器
业务规定:按年龄从大到小排序
比较器类
public class MyComparator implements Comparator<Student>{ @Override public int compare(Student o1, Student o2) { if(o1.age>o2.age){ return -1; } if(o1.age<o2.age){ return 1; } if(o1.equals(o2)&&o1.hashCode()==o2.hashCode()){ return 0; } return 1; } }
之所以比较hashCode和equals方法是因为TreeSet加入元素时如果如果返回为0会认为两个元素相同,只添加一个(原来的值)。
主类调用
import java.util.Set; import java.util.TreeSet; public class TreeSetDemo { public static void main(String[] args) { Set<Student> s = new TreeSet<Student>(new MyComparator()); Student s1 = new Student("小明",16); Student s2 = new Student("小lizi",19); Student s3 = new Student("小lizi",20); Student s4 = new Student("小lizie",20); s.add(s1); s.add(s2); s.add(s3); s.add(s4); for(Student st:s){System.out.println(st.toString());} } /* * (Student [name=小lizi, age=20] * Student [name=小lizie, age=20] * Student [name=小lizi, age=19] * Student [name=小明, age=16] */ }
4.2 Map
Map是针对元素为键值对形式数据的容器,由于Set数据的加入依赖Map的实现类HashMap和TreeMao,故Set使用事项的描述也适用于Map。即在Map加入引用数据类型作为键值时,也应该重写键值对象的hashCode()和equals()方法,同时TreeMap再加入元素时,需要自定义比较器。
Map和Collection使用上形式上最大的不同是遍历操作:
Set<Map.Entry<K,V>> entrySet()
使用规则:
Map<String,String> map = new HashMap<String,String>(); map.put("a", "a"); map.put("b", "b"); map.put("c", "c"); map.put("d", "d"); Set<Map.Entry<String, String>> myset = map.entrySet(); for(Map.Entry<String, String> me:myset){ System.out.println(me.getKey()); System.out.println(me.getValue()); }
此外Map提供获取所有的键集,值集等操作,可查阅API使用,较为简单。
5,总结集合框架
5.1结构
Collection
|List
|ArrayList:一般使用,数组实现,查询快,增删慢,线程不安全
|Vector:较为少用,线程安全,但效率较低
|LinkedList:双向链表实现,查询慢,增删快,线程不安全
|Set
|HashSet:HashMap
|TreeSet:红黑二叉树实现
Map:
|HashMap 无序
|TreeMap 有序
5.2 泛型
List<String> a = new ArrayList<String>();//a中存储的数据类型在编译器就确定下来
List a = new ArrayList();//a中存储的数据类型运行时才知道
ps.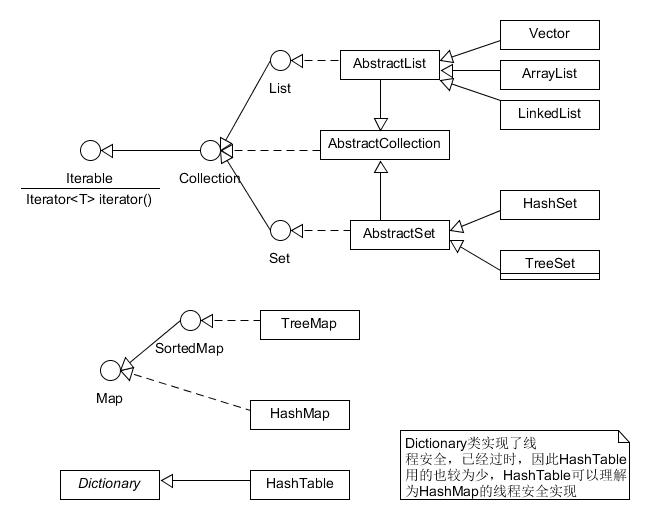

 浙公网安备 33010602011771号
浙公网安备 33010602011771号