3.K均值算法
2). *自主编写K-means算法 ,以鸢尾花花瓣长度数据做聚类,并用散点图显示。
from sklearn.datasets import load_iris#导入鸢尾花数据集
import numpy as np
iris = load_iris()
data = iris['data']
data.shape
n = len(data)#样本个数
m = data.shape[1]#样本分类个数
k = 3#设置类中心
dist = np.zeros([n,k+1])#初始化矩阵
#1.选中心:
center = data[:k,:]#选取前面三个样本为初始类中心
center_new = np.zeros([k,m])
#2.求距离:
while True:
for i in range(n):
for j in range(k):
dist[i,j] = np.sqrt(sum((data[i,:]-center[j,:])**2))#求距离
dist[i,k] = np.argmin(dist[i,:k])#3.归类
for i in range(k):#4.求新类中心
index = dist[:,k]==i
center_new[i,:]= data[index,:].mean(axis = 0)
if np.all((center ==center_new)):#判断类中心是否和上一轮类中心相同
break#5.判定结束
else:
center = center_new#更新类中心
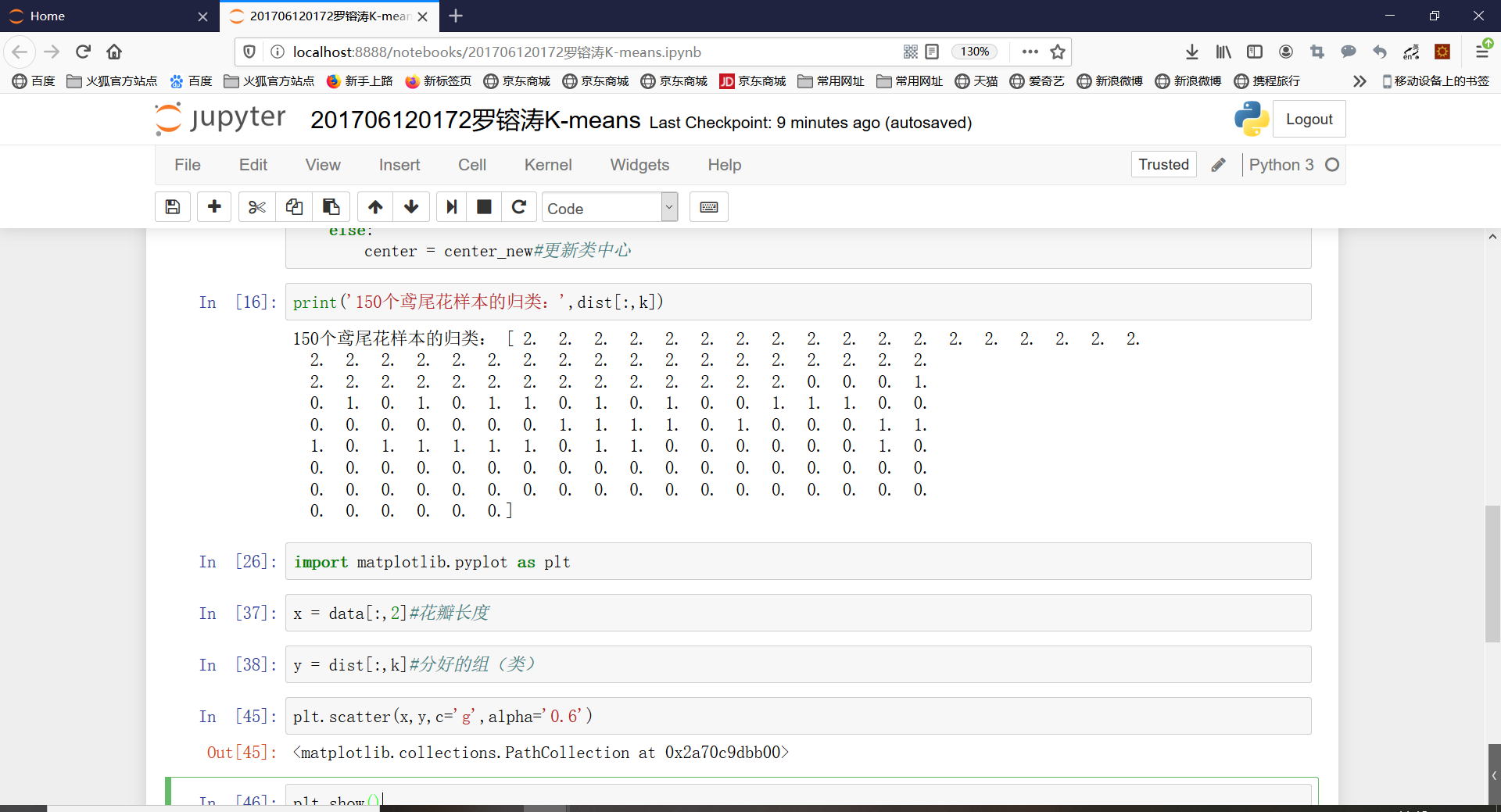
print('150个鸢尾花样本的归类:',dist[:,k])
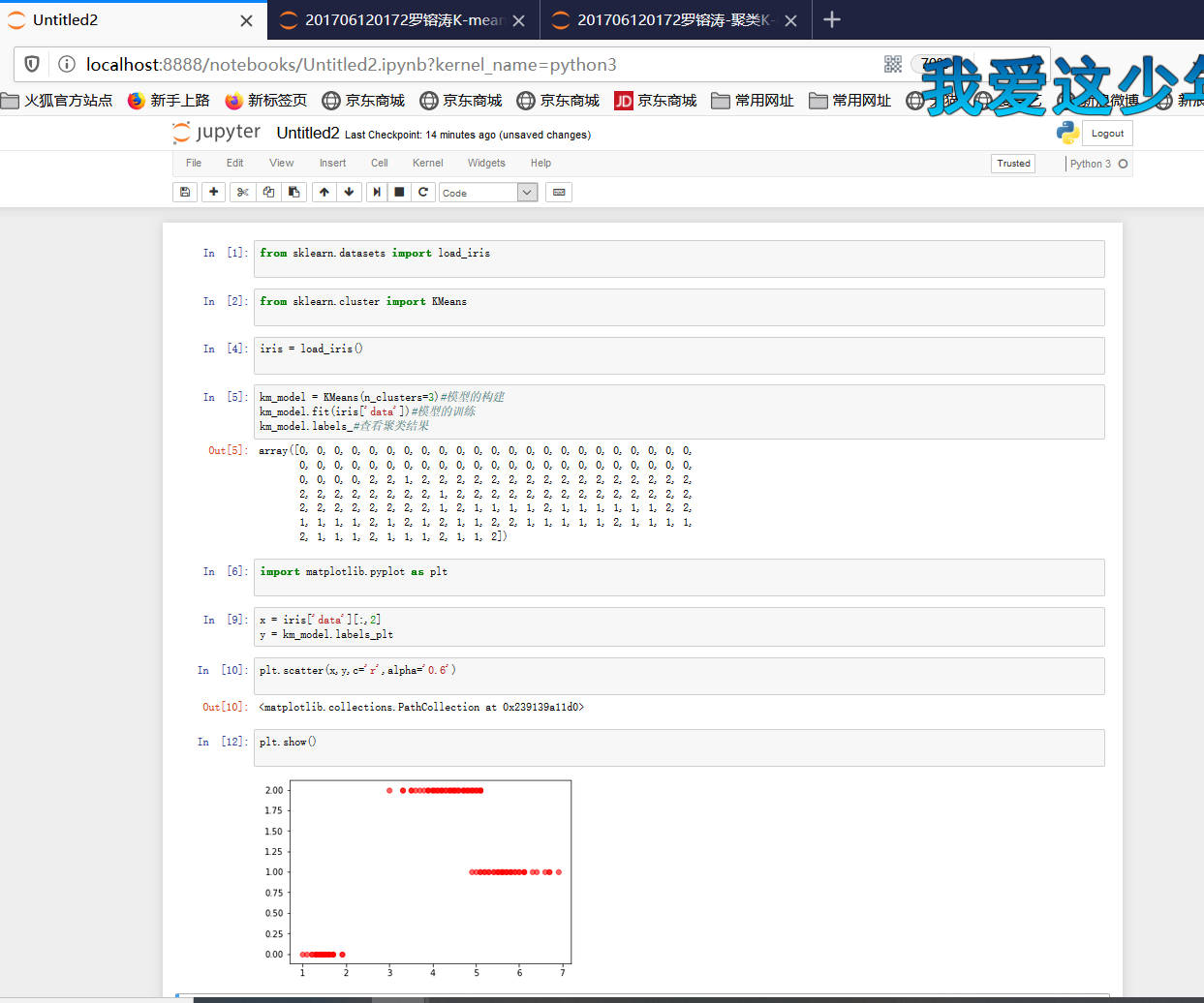
import matplotlib.pyplot as plt
x = data[:,2]#花瓣长度
y = dist[:,k]#分好的组(类)
plt.scatter(x,y,c='g')
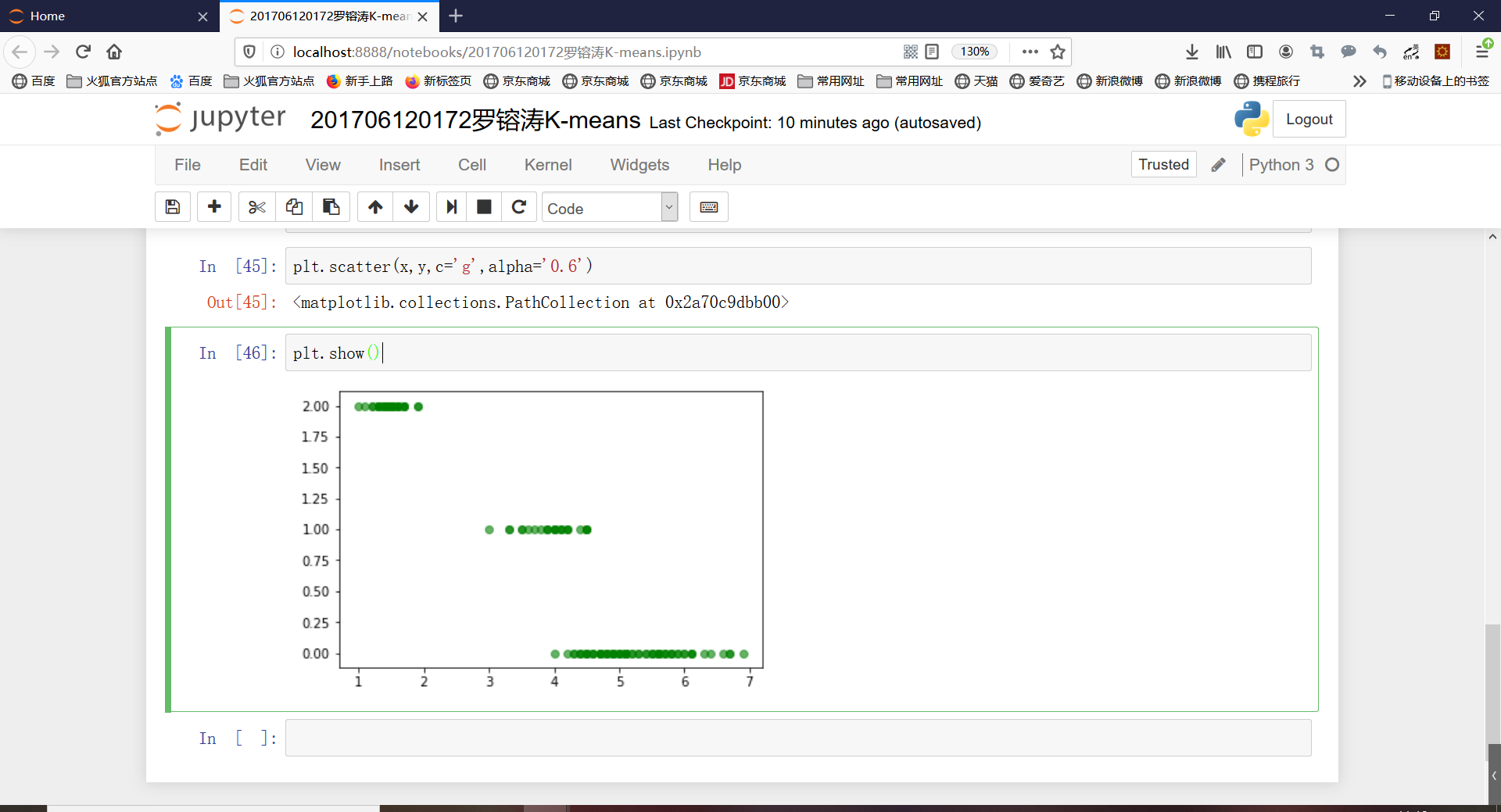
plt.scatter(x,y,c='g',alpha='0.6')
plt.show()
用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类,并用散点图显示.
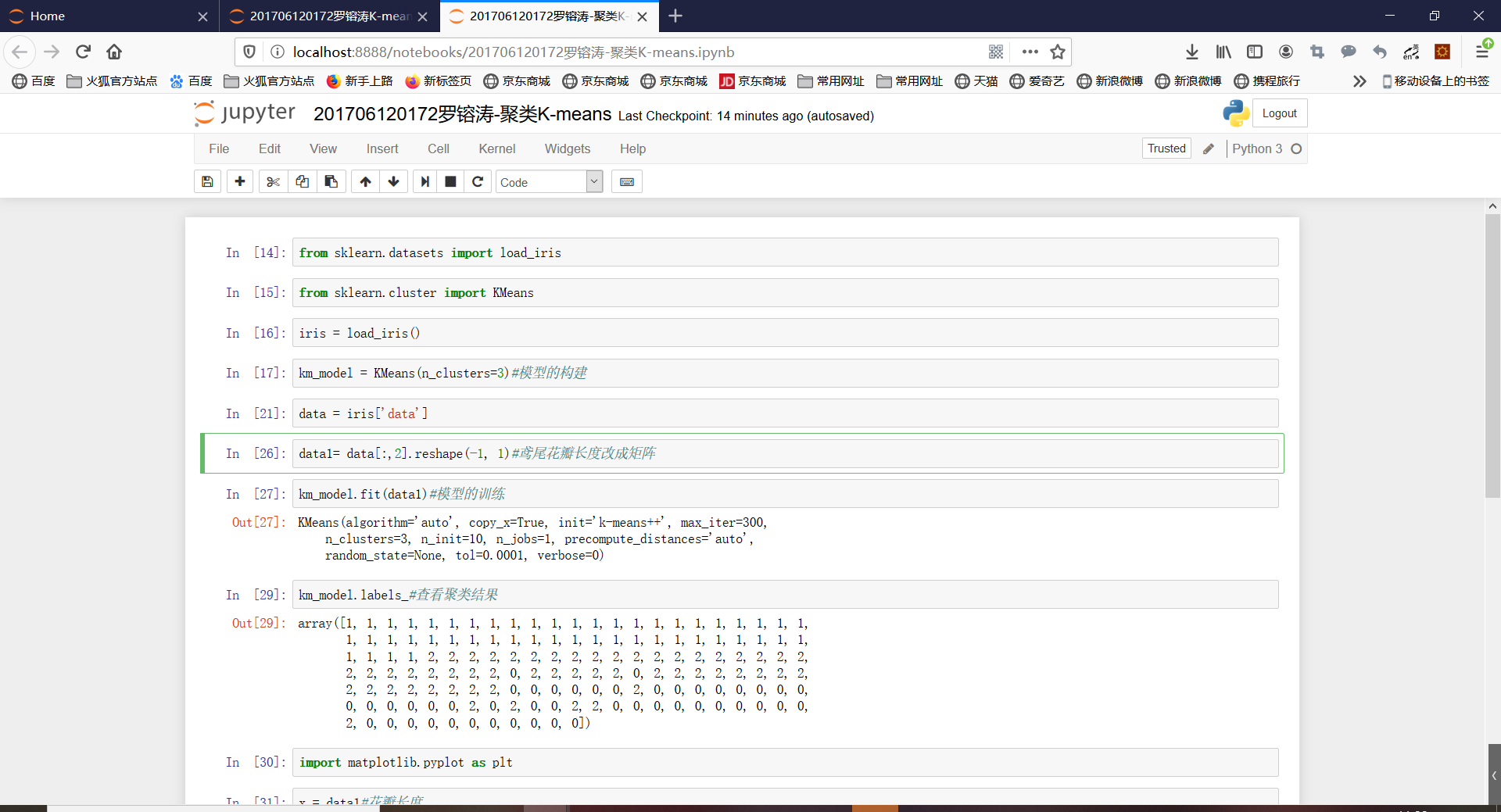

鸢尾花完整数据做聚类并用散点图显示:
想想k均值算法中以用来做什么?
可以用来给能够测量具体数据的一组数据,根据数据进行分类,比如说根据西瓜的瓜蒂的长短来分类成几种西瓜。
翻译 朗读 复制 正在查询,请稍候…… 重试 朗读 复制 复制 朗读 复制 via 谷歌翻译(国内) 译

 浙公网安备 33010602011771号
浙公网安备 33010602011771号