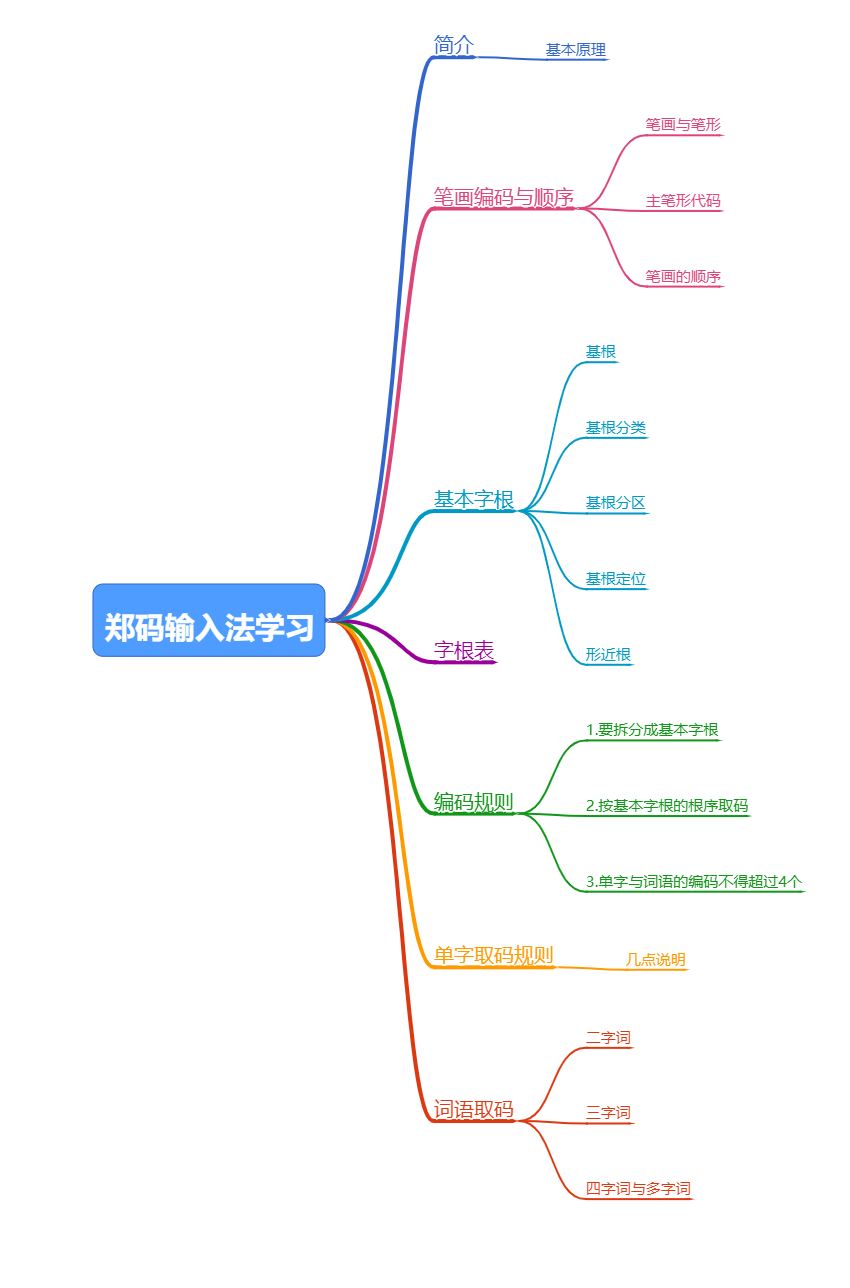
郑码输入法学习
郑码输入法学习
由于喜读古籍,常做摘录,古文中繁体字、异体字又较多,虽识得大部分繁体,但也有一部分完全不认得而电子版古籍多为影印版,只会全拼输入无法输入,以致无法上网查询其读音释义,故决定学习形码输入法。
最初筛选出来的有五笔和郑码,经过一番百度了解到郑码不但可以输入2万汉字,还可以输入68000个和10万个汉字,非常适合古文摘录,于是最终选择了郑码。
简介
《郑码》即 《字根通用码》,又简称《字根码》,是一种按汉字字形编码的中文输入法,属形码范畴。汉字的信息虽来自形、音、义三个方面,但由于汉字是方块的图形文字,见字肯定知道形状却不一定知道读音和字义。而且每字可有多种方言读音,有多个字义诠释,但所用的字形却是同一个。也就是说,利用音、义信息编码歧义多,而利用字形信息却是直观、准确、惟一的。因此利用字形编码具有相对的稳定性,即使某些字我们不知读音也不知字义,却能按字形给出编码输入计算机。——《郑码实用手册》
基本原理
汉字是方块图形文字,每字由一个至数个单元构成。例如『师傅』的『傅』字由单元『亻』、『尃(音fū)』构成,其中的『尃』又有单元『甫』、『寸』构成,可见『亻』、『甫』、『寸』是构成『傅』字的基础单元,构字单元的排列顺序,用图形可表示为![]() 。如果把『亻』换成『氵』,在上面加『⺮』便构成『簿』字;换成『艹』又成为『薄』字。以『薄』为例,构成『薄』字的基础单元是『艹、氵、甫、寸』,用图形表示为
。如果把『亻』换成『氵』,在上面加『⺮』便构成『簿』字;换成『艹』又成为『薄』字。以『薄』为例,构成『薄』字的基础单元是『艹、氵、甫、寸』,用图形表示为![]() 。而基础单元由笔画构成,例如『寸』由笔画『一』、『亅』、『丶』构成。
。而基础单元由笔画构成,例如『寸』由笔画『一』、『亅』、『丶』构成。
用于汉字编码,将构字的基础单元叫做『字根』或者『部件』,构字的最小单元是笔画。也就是说,『薄』字由『艹、氵、甫、寸』四个字根构成;『札』字由字根『木、乚(折)』构成。
笔画编码与顺序
笔画与笔形
主笔形是最基本的笔形,国家文字规范把汉字的主笔形归纳为 『横「一」、竖「丨」、撇「丿」、点「丶」、折「乛」』 5类。《郑码》在给笔画安排代码时,依据笔势和走向,将附笔形归并到主笔形的相应类别中,与主笔形用同一代码。
| 序号 | 主笔形 | 附笔形 | 例字及归并说明 | ||
|---|---|---|---|---|---|
| 1 | 横『一』 | 横提『㇀』 | 『土、地』的『土』的第三笔在『地』字中变为『横提㇀』。 | ||
| 2 | 竖『丨』 | 竖钩『亅』 | 『少、小』的『|』笔形在『小』字中变为带钩的『竖钩亅』。 | ||
| 3 | 撇『丿』 | 横撇『㇒』 | 『片』的第一笔是『竖撇』;『壬』第一笔是『横撇㇒』。 | ||
| 4 | 点『丶』 | 捺『㇏』 | 『料、米』在『料』字中『米』的第六笔『捺㇏』变为『点、』。 | ||
| 5 | 折『乛』 | 弯 | 单弯 | ㇕、㇖、㇁ | 开口向左、弯一次的横折弯和竖弯钩叫单弯。 |
| 复弯 | 𠃌、㇡、㇎、㇠、⺄、㇅ | 开口向左,弯了多次的横折弯叫复弯。 | |||
| 拐 | 单拐 | ㇗、㇜、𡿨、㇂、㇙ | 开囗向右、拐一次的竖折、卧钩、竖提等叫单拐。 | ||
| 复拐 | ㇟、ㄣ、㇉ | 开口向右,拐了多次的竖折钩和竖折折叫复拐。 | |||
主笔形代码
| 笔形 | 对应代码 |
|---|---|
| 横、横提『一、㇀』 | A |
| 竖、竖钩『丨、亅』 | I |
| 撇、横撇『丿、㇒』 | M |
| 点、捺『丶、㇏』 | S |
| 单弯『㇕、㇖、㇁』 | X |
| 复弯『𠃌、㇡、㇎、㇠、⺄、㇅』 | Y |
| 单拐『㇗、㇜、𡿨、㇂、㇙』 | Z |
| 复拐『㇟、ㄣ、㇉』 | Z |
笔画的顺序
单个笔画的排序:
横『一』→ 竖『丨』→ 撇『丿』→ 点『丶』→ 折『㇖』
折『㇖』笔又分为:
弯『㇕』→ 拐『㇗』
两个笔画的排序:
第一笔以 横『一』 起始,笔画两两组合排序为:
横-横『一一』、横-竖『一丨』、横-撇『一丿』、横-点『一丶』、横-折『一㇖』
第一笔以 撇『丿』 起始,笔画两两组合排序为:
撇-横『丿一』、撇-竖『丿丨』、撇-撇『丿丿』、撇-点『丿丶』、撇-折『丿㇖』
《郑码》的基字根大多依据自身前两笔(或前三笔)的笔形进行排序并安排代码。
基本字根
基根
组合两万多个汉字的字根有560余个,《郑码》从中选出170个构字能力较强的字根,用英文字母做他们的代码,这些有代码的字根就是《郑码》的基本字根,简称为“基根”。
基根分类
将基根按第一笔的笔形可分成:横起笔、竖起笔、撇起笔、点起笔、折起笔 5大类:
| 分类 | 代码范围 | 助记 |
|---|---|---|
| 横起笔类基根 | ABCDEFGH | 从三角A到梯子H |
| 竖起笔类基根 | IJKL | 从直棍I到拐棍L |
| 撇起笔类基根 | MNOPQR | 从爱母M到爱儿R |
| 点起笔类基根 | STUVW | 从艾斯S到大步溜W |
| 折起笔类基根 | XYZ | 从X光片到诊Z病 |
基根分区
每一大类中再按前两笔或前三笔笔形将相应基根分配到一个指定的字母。这些具有相似笔形特征的基根构成一个字根分区,称作『根区』。这个指定的字母称作该根区每一个基根的『区码』。26个字母对应26个根区。
基根定位
第一主根:每一个根区中组字频度最高的基根,称为『第一主根』。第一主根不设位码,其代码就是该根区区码。
第二主根:每一个根区中能体现本根区副根笔形特征的基根,称为『第二主根』。它有助于记忆本根区的副根。第二主根的位码均为『D』,第二主根的代码可以表示为『区码+D』。
副根:『副根』是以上两类主根以外基根的统称。副根的位码通常采用与笔画、与主根或与其它副根的区码有联想的方法定名。副根的代码可以表示为『区码+位码』。
形近根
使用形近根,是为了避免不必要的拆分。
字根表

编码规则
1.要拆分成基本字根
- 将汉字拆分成基本字根才能进行编码。
- 若没有合适的基根,则要拆分成笔画。
- 拆分出的基根和笔画必须是最少的。
拆分示例:
| 原字 | 拆分 | 原字 | 拆分 | 原字 | 拆分 | 原字 | 拆分 | 原字 | 拆分 |
| 跟 | 艮 | 甜 | 舌 甘 | 榭 | 木 身 寸 | 靴 | 革 亻 匕 | 鹦 | 贝 贝 女 鸟 |
| 纸 | 纟氏 | 散 | 龷 月 夂 | 举 | ⺍ 一 八 𰀁 | 美 | ⺷ 大 | 凸 | 丨 一 丨 ㇎ 一 |
2.按基本字根的根序取码
- 左右结构和上下结构的字的根序与书写顺序相同,按 『从左向右、从上到下』 的顺序。
- 包围结构的字的根序确定方法:
- 全包围结构视为外内字,根序为 『从外到内』 。
| 结构 | 示例一 | 示例二 |
|---|---|---|
| 全包围结构 ⿴ | 困→口木 | 园→口二儿 |
- 上三包围结构、下三包围结构、左上包围结构、右上包围结构根序为 『从上到下』 。
| 结构 | 示例一 | 示例二 | 示例三 | 示例四 |
|---|---|---|---|---|
| 上三包围结构 ⿵ | 套→大镸 | 周→冂土口 | 阔→门氵舌 | 凤→几又 |
| 下三包围结构 ⿶ | 凶→乂凵 | 函→乛氺凵 | 画→一田凵 | 幽→㇜厶㇜厶山 |
| 左上包围结构 ⿸ | 虚→⾌业 | 质→⺁十贝 | 局→尸㇆口 | 扉→户非 |
| 右上包围结构 ⿹ | 氧→气羊 | 贰→弋二贝 | 匆→勹𰀪㇏ | 戴→𢦏田龷八 |
- 左三包围结构与左下包围结构根序为 『从左到右』 。
| 结构 | 示例一 | 示例二 | 示例三 | 示例四 |
|---|---|---|---|---|
| 左三包围结构 ⿷ | 医→匚矢 | 区→匚乂 | 巨→匚㇕ | 匦→匚车九 |
| 左下包围结构 ⿺ | 起→走己 | 彪→虎彡 | 魁→鬼⺀十 | 毯→毛火火 |
| 达→辶大 | 建→廴肀二 | 断→㇗米斤 | 隨→阝辶丆工月 |
3.单字与词语的编码不得超过4个
- 每个单字和每条词语的编码不得超过4个,输入单字或词语不足4码时,要加空格键结束。
- 对于基根多的单字,若编码数超过4码,应按单字取码规则加以取舍。
单字取码规则
| 首根 | 次根 | 中间根 | 次末根 | 末根 | 示例 | 助记口诀 | |
| 单基根字 | 1码 | 无 | 无 | 无 | 无 | 木 - FA 要(高频字) - F |
加A为主根 不加为高频字 |
| 二 基 根 字 |
1码 | 无 | 无 | 无 | 是1取1 加后缀VV | 拓 - 扌(D)+石(G) —— DGVV | 首1末1加VV |
| 是2取2 | 样 - 木(F)+羊(UC) —— FUC | 首根末根码全取 | |||||
| 2码 | 无 | 无 | 无 | 是1取1 | 社 - 礻(WS)+土(B) —— WSB | ||
| 是2取2 | 配 - 酉(FD)+己(YY) —— FDYY | ||||||
| 三 基 根 字 |
1码 | 只取1 | 无 | 无 | 是1取1 | 腾 - 月(Q)+龹(UB)+马(X) —— QUX | 首1次1末全取 |
| 是2取2 | 谢 - 讠(S)+身(NC)+寸(DS) —— SNDS | ||||||
| 2码 | 只取1 | 无 | 无 | 只取1 | 教 - 耂(BM)+子(YA)+攵(MO) —— BMYM | 首2次、末各取1 | |
| 四 基 根 字 |
1码 | 只取1 | 无 | 只取1 | 只取1 | 镕 - 钅(P)+穴(WO)+人(OD)+口(J) —— PWOJ | 首根1码次根1 首根2码次不取 无论首根1或2 最末两根各取1 |
| 2码 | 代码省略 | 无 | 只取1 | 只取1 | 稳 - 禾{⺈}(MF)+彐(XB)+心(WZ) —— MFXW | ||
| 多 基 根 字 |
1码 | 只取1 | 代码省略 | 只取1 | 只取1 | 攀 - 木(F)+乂(OS)+{乂木}+大(GD)+手(MD) —— FOGM | |
| 2码 | 代码省略 | 代码省略 | 只取1 | 只取1 | 赣 - 立(SU)+{日十⼡}+工(BI)+贝(LO) —— SUBL |
几点说明
- 3码形近根参与单字编码,取码方法同样符合取码的总原则。即:
首根代码按实际码数取,其他各序位基根的位码或整个代码要有所省略。 - 用加后缀 『A』 的方法避免重码:
- 用『A』作为不常用的成字形近根输入码的后缀。
- 用『A』作为不常用的成字基根代码的后缀。
- 用『A』作为不常用的不成字基根或笔画代码的后缀。
- 在『A』、『D』、『V』区安排的基根很少,用『A』、『D』、『V』做后缀不容易产生重码。
- 汉字 『〇』 的输入码为 『JAA』。
词语取码
二字词
取码规则:第一字的首根和次根各1码+第二字的首根和次根各1码
- 第一主根作为单字时,在第一主根的代码后面需加 『A』
- 二字词中有高频字时,高频字代码后需加 『V』
- 二字词中有第二主根或副根作为单字构词时,取用它们区位码的2码。
三字词
取码规则:第一字首根1码+第二字首根和次根各1码+第三字首根1码
- 若第二个单字是第一主根,在第一主根的代码后需加 『A』
- 若第二个单字是高频字,在高频字代码后需加 『V』
- 若第二个单字是第二主根或副根,直接取它们区位码的2码
四字词与多字词
取码规则:第一字首根1码+第二字首根1码+第三字首根1码+第四字首根1码
作者: 暮颜 —— 衣带渐宽终不悔
出处:https://www.cnblogs.com/mowenpan1995/
版权归作者和博客园共有,欢迎转载。但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
转载请注明原文链接:https://www.cnblogs.com/mowenpan1995/p/13925772.html
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
