
数组, ArrayList, 集合类 Collection
数组
数组的特点:
- 有序,
- 数组是同类型的.
// 数组声明 int[] intArray = new int[10]; // 典型数组声明是: type[] identifer = new type[length]; // type 是数组元素类型 // identifer 是数组变量名称 // length 是分配数组元素个数(长度)
ArrayList
ArrayList 是基于数组实现的.
java.util 包包含很多工具类,
ArrayList 可以作为顺序表, 本身, ArrayList 封装了许多方法.
// 在 ArrayList 后面添加一个新元素; 返回值 true boolean add(<T> element) // 在 index 指定位置插入一个元素 void add(int index, <T>element) // 删除指定位置的元素, 并返回值 <T> remove(int index) // 从 ArrayList 中删除所有元素 void clear() // 返回 ArrayList 中元素数量 int size() // 获取索引位置元素 <T> get(int index) // 将指定位置元素设置为新值, 并返回原来的值 <T> set(int index, <T>value) // 返回第一个指定值的索引, 如果没有, 返回 -1 int indexOf(<T> value) // 如果ArrayList 包含指定值, 返回 true boolean contains(<T> value) //如果 ArrayList 不包含元素, 返回 true boolean isEmpty()
// 声明, 参数必须是类对象类型, 不能是原始类型, 比如 int ArrayList<String> stringList = new ArrayList<String>();
此外, ArrayList 对比数组还有一个好处, 就是可以动态分配长度, 数组只能在声明时具体指定长度.
HashMap
HashMap 实现映射抽象思想, 映射是 key 和 value 结合, key 是对象, 它在映射里只会出现一次, 所以可以用来确定值; 值也是与 key 相关的对象. 值可以出现多次, HashMap 是更通用的 Map 接口的特殊实现方式.
// HashMap 声明 Map<String, String> stateMap = new HashMap<String, String>();
stateMap.put("1","one");
stateMap.get("1");
声明更通用的 Map 类型的好处是:
HashMap 的实际数据结构是(存储结构) 数组 + 链表 + 红黑树.
每个 Java 对象都有散列码, 散列码可以作为数组的元素标号, 比如 "AK" 的散列码是 2090.这样可以把 "AK" 这个 key 对应的值存储在 数组[2090] 里.
但是, 散列码会有重复度, 当碰到重复时, Java 1.7 之前是把值都存储在链表中, 这样通过散列码找到链表入口地址, 依次遍历链表找寻值, Java 1.8 之后是通过红黑树作为数据结构存储.
举例: (Java 1.7 之前)
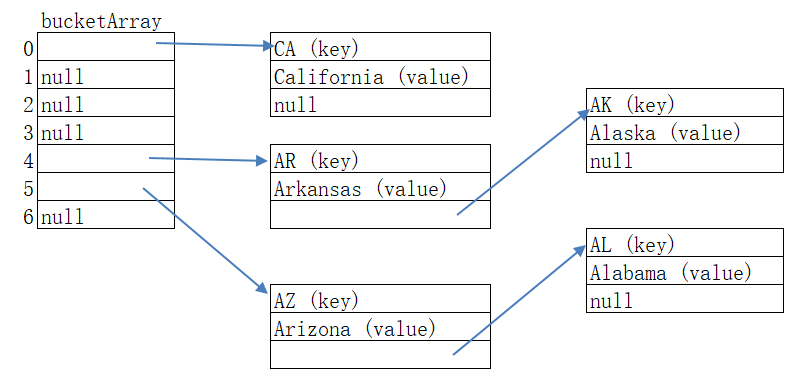
这其中: AR, AK 的散列码相同. AZ 和 AL 的散列码相同.
当我要查找 "AK" 这个 key 作为参数查询值时, 先通过 Java 对象散列码 "AK" -> 2090(比如) 找到了 bucketArray 的位置,
在顺着这个位置先找到 "AR", 这时比较 "AR" 不等于 "AK", 发现有 next 指针, 继续寻找, 最后找到 "AK" 位置, 成功将这个 value: Alaska 取出.
hashCode(), 返回对象的哈希值, 函数用来查找在散列表中的位置, 也就是找到 bucketArray 的入口地址, 所以对 hashCode() 是有要求的. (或者可以理解为 hashCode() 是生成散列码的)
- 如果在相同对象上调用 hashCode()方法,必须返回相同的代码(散列码)
- hashCode 实现必须与 equals 方法实现一致, 因为在内部, 比较两个对象是否相等, 首先要比较他们的 hashCode 是否相等, 如果连 hashCode 都不相等, 这两个对象不可能相等, 但是即便是 hashCode 相等了, 也不带表这两个对象就一定相等.
如果两个对象的 hashCode() 返回值相等,(相同散列码), 并不表示这两个对象相等, 只能说明这两个对象在"同一个篮子里", bucketArray, 例如上例子中的 "AR" 和 "AK"
Collection 集合类
Java 中的集合类, 主要实现 3 种数据结构, 分别是 线性表(ArrayList, LinkedList), 键值对Key:Value(HashMap, TreeMap), 集合(HashSet, TreeSet)

Java 集合架构的好处之一是, 它不强迫选择特定表示法, 除了在对构造函数的调用中之外,例如: 下边的函数, 它用一个字符串作为参数, 最好这样写:
public void alphabetize(List<String>); // 这里使用的是 interface 作为参数类型, 而不是具体指向 ArrayList 还是 LinkedList
Iterator 接口, 可以实现 for each, 它有两个基本方法:
- hasNext 断言方法, 如果集合有迭代器没有提供的值, 返回 true, 也就是说, 还有值没有遍历到, 就返回true.
- next 方法, 返回集合的下一个元素.
例如:
while (iterator.hasNext()) { println(iterator.next()); } for (type variabble: collection) { statements; }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号