java面试题
一、基础
1. 如何用io创建文件
java中创建文件的五种方法:
1、Java 8 Files.newBufferedWriter
java8 提供的newBufferedWriter可以创建文件,并向文件内写入数据。可以通过追加写模式,向文件内追加内容。
@Test
void testCreateFile1() throws IOException {
String fileName = "D:\\data\\test\\newFile.txt";
Path path = Paths.get(fileName);
// 使用newBufferedWriter创建文件并写文件
// 这里使用了try-with-resources方法来关闭流,不用手动关闭
try (BufferedWriter writer =
Files.newBufferedWriter(path, StandardCharsets.UTF_8)) {
writer.write("Hello World -创建文件!!");
}
//追加写模式
try (BufferedWriter writer =
Files.newBufferedWriter(path,
StandardCharsets.UTF_8,
StandardOpenOption.APPEND)){
writer.write("Hello World -字母哥!!");
}
}
2、Java 7 Files.write
下面的这种方式Files.write,是笔者推荐的方式,语法简单,而且底层是使用Java NIO实现的。同样提供追加写模式向已经存在的文件种追加数据。这种方式是实现文本文件简单读写最方便快捷的方式。
@Test
void testCreateFile2() throws IOException {
String fileName = "D:\\data\\test\\newFile2.txt";
// 从JDK1.7开始提供的方法
// 使用Files.write创建一个文件并写入
Files.write(Paths.get(fileName),
"Hello World -创建文件!!".getBytes(StandardCharsets.UTF_8));
// 追加写模式
Files.write(
Paths.get(fileName),
"Hello World -字母哥!!".getBytes(StandardCharsets.UTF_8),
StandardOpenOption.APPEND);
}
3、PrintWriter:PrintWriter是一个比较古老的文件创建及写入方式,从JDK1.5就已经存在了,比较有特点的是:PrintWriter的println方法,可以实现一行一行的写文件。
@Test
void testCreateFile3() throws IOException {
String fileName = "D:\\data\\test\\newFile3.txt";
// JSD 1.5开始就已经存在的方法
try (PrintWriter writer = new PrintWriter(fileName, "UTF-8")) {
writer.println("Hello World -创建文件!!");
writer.println("Hello World -字母哥!!");
}
// Java 10进行了改进,支持使用StandardCharsets指定字符集
/*try (PrintWriter writer = new PrintWriter(fileName, StandardCharsets.UTF_8)) {
writer.println("first line!");
writer.println("second line!");
} */
}
4、File.createNewFile()
createNewFile()方法的功能相对就比较纯粹,只是创建文件不做文件写入操作。 返回true表示文件成功,返回 false表示文件已经存在.可以配合FileWriter 来完成文件的写操作
@Test
void testCreateFile4() throws IOException {
String fileName = "D:\\data\\test\\newFile4.txt";
File file = new File(fileName);
// 返回true表示文件成功
// false 表示文件已经存在
if (file.createNewFile()) {
System.out.println("创建文件成功!");
} else {
System.out.println("文件已经存在不需要重复创建");
}
// 使用FileWriter写文件
try (FileWriter writer = new FileWriter(file)) {
writer.write("Hello World -创建文件!!");
}
}
5、最原始的管道流方法
最原始的方式就是使用管道流嵌套的方法,但是笔者觉得这种方法历久弥新,使用起来非常灵活。你想去加上Buffer缓冲,你就嵌套一个BufferedWriter,你想去向文件中写java对象你就嵌套一个ObjectOutputStream。但归根结底要用到FileOutputStream。
@Test
void testCreateFile5() throws IOException {
String fileName = "D:\\data\\test\\newFile5.txt";
try(FileOutputStream fos = new FileOutputStream(fileName);
OutputStreamWriter osw = new OutputStreamWriter(fos);
BufferedWriter bw = new BufferedWriter(osw);){
bw.write("Hello World -创建文件!!");
bw.flush();
}
}
2. 过滤器、拦截器、监听器对比及使用场景分析
过滤器
过滤器(Filter)是处于客户端与服务器目标资源之间的⼀道过滤技术。
● 生活中的过滤器:净⽔器,空气净化器
● web中的过滤器:当访问服务器的资源时,过滤器可以将请求拦截下来,完成⼀些特殊的功能。
过滤器作用
● 执行是在Servlet之前,客户端发送请求时,会先经过Filter,再到达目标Servlet中;响应时, 会根据执行流程再次反向执行Filter
● ⼀般用于完成通用的操作。如:登录验证、统⼀编码处理、敏感字符过滤
常见的过滤器用途主要包括:对用户请求进行统一认证、对用户的访问请求进行记录和审核、对用户发送的数据进行过滤或替换、转换图象格式、对响应内容进行压缩以减少传输量、对请求或响应进行加解密处理、触发资源访问事件等**。

生命周期
过滤器的配置比较简单,直接实现Filter 接口即可,也可以通过@WebFilter注解实现对特定URL拦截,看到Filter 接口中定义了三个方法。
- init() :该方法在容器启动初始化过滤器时被调用,它在 Filter 的整个生命周期只会被调用一次。注意:这个方法必须执行成功,否则过滤器会不起作用。
- doFilter() :容器中的每一次请求都会调用该方法, FilterChain 用来调用下一个过滤器 Filter。
- destroy(): 当容器销毁 过滤器实例时调用该方法,一般在方法中销毁或关闭资源,在过滤器 Filter 的整个生命周期也只会被调用一次。
@Component
@WebFilter("/myservlet1")//过滤路径
public class MyFilter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
System.out.println("Filter 前置");
}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
System.out.println("Filter 处理中");
filterChain.doFilter(servletRequest, servletResponse);
}
@Override
public void destroy() {
System.out.println("Filter 后置");
}
}
值得注意的是doFilter()方法,它有三个参数(ServletRequest,ServletResponse,FilterChain),从前两个参数我们可以发现:过滤器可以完成任何协议的过滤操作!
在Java中就使用了链式结构。把所有的过滤器都放在FilterChain里边,如果符合条件,就执行下一个过滤器(如果没有过滤器了,就执行目标资源)。
过滤器链和优先级
过滤器链
客户端对服务器请求之后,服务器调用Servlet之前会执行⼀组过滤器(多个过滤器),那么这组过滤 器就称为⼀条过滤器链。
每个过滤器实现某个特定的功能,当第⼀个Filter的doFilter方法被调用时,Web服务器会创建⼀个代 表Filter链的FilterChain对象传递给该方法。在doFilter方法中,开发⼈员如果调用了FilterChain对象 的doFilter方法,则Web服务器会检查FilterChain对象中是否还有filter,如果有,则调用第2个filter, 如果没有,则调用目标资源。
优先级:
● 如果为注解的话,是按照类全名称的字符串顺序决定作用顺序
● 如果web.xml,按照 filter-mapping注册顺序,从上往下
● web.xml配置高于注解方式
过滤器路径
过滤器的过滤路径通常有三种形式:
- 精确过滤匹配 ,比如/index.jsp /myservlet1
- 后缀过滤匹配,比如.jsp、.html、*.jpg
- 通配符过滤匹配/,表示拦截所有。注意过滤器不能使用/匹配。 /aaa/bbb/ 允许
过滤器应用
@WebFilter(urlPatterns = "/*")
@Component
public class EncodingFilter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse,
FilterChain filterChain) throws IOException, ServletException {
//统⼀处理请求和响应的乱码
servletRequest.setCharacterEncoding("UTF-8");
servletResponse.setContentType("text/html;charset=utf-8");
filterChain.doFilter(servletRequest,servletResponse);
}
@Override
public void destroy() {
}
}
拦截器
拦截器作用
拦截器采用AOP的设计思想, 它跟过滤器类似, 用来拦截处理方法在之前和之后执行一些 跟主业务没有关系的一些公共功能:
比如:可以实现:权限控制、日志、异常记录、记录方法执行时间.....
自定义拦截器
SpringMVC提供了拦截器机制,允许运行目标方法之前进行一些拦截工作或者目标方法运行之后进行一下其他相关的处理。自定义的拦截器必须实现 HandlerInterceptor接口。
HandlerInterceptor 接口中定义了三个方法。
- preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) :这个方法将在请求处理之前进行调用。注意:如果该方法的返回值为false ,将视为当前请求结束,不仅自身的拦截器会失效,还会导致其他的拦截器也不再执行。
- postHandle(HttpServletRequest request, HttpServletResponse response, Object handler):只有在 preHandle() 方法返回值为true 时才会执行。会在Controller 中的方法调用之后,DispatcherServlet 返回渲染视图之前被调用。 此时我们可以通过modelAndView(模型和视图对象)对模型数据进行处理或对视图进行处理,modelAndView也可能为null。
- afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler):只有在 preHandle() 方法返回值为true 时才会执行。在整个请求结束之后, DispatcherServlet 渲染了对应的视图之后执行。如性能监控中我们可以在此记录结束时间并输出消耗时间,还可以进行一些资源清理,类似于trycatchfinally中的finally,但仅调用处理器执行链中preHandle返回true的拦截器才会执行。
import org.springframework.web.method.HandlerMethod;
import org.springframework.web.servlet.HandlerInterceptor;
import org.springframework.web.servlet.ModelAndView;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.util.Arrays;
public class MyFirstInterceptor implements HandlerInterceptor {
/**
* 在处理方法之前执 日志、权限、 记录调用时间
* @param request 可以在方法请求进来之前更改request中的属性值
* @param response
* @param handler 封装了当前处理方法的信息
* @return true 后续调用链是否执行/ false 则中断后续执行
* @throws Exception
*/
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
// 在请求映射到对应的处理方法映射,实现类才是HandlerMethod。
// 如果是视图控制器,实现类ParameterizableViewController
if(handler instanceof HandlerMethod ) {
HandlerMethod handMethod = (HandlerMethod) handler;
}
/*System.out.println("-------类["+handMethod.getBean().getClass().getName()+"]" +
"方法名["+handMethod.getMethod().getName()+"]" +
"参数["+ Arrays.toString(handMethod.getMethod().getParameters()) +"]前执行--------preHandle");*/
System.out.println(this.getClass().getName()+"---------方法后执行,在渲染之前--------------preHandle");
return true;
}
/**
* 如果preHandle返回false则会不会允许该方法
* 在请求执行后执行, 在视图渲染之前执行
* 当处理方法出现了异常则不会执行方法
* @param request
* @param response 可以在方法执行后去更改response中的信息
* @param handler 封装了当前处理方法的信息
* @param modelAndView 封装了model和view.所以当请求结束后可以修改model中的数据或者新增model数据,也可以修改view的跳转
* @throws Exception
*/
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
System.out.println(this.getClass().getName()+"---------方法后执行,在渲染之前--------------postHandle");
}
/**
* 如果preHandle返回false则会不会允许该方法
* 在视图渲染之后执行,相当于try catch finally 中finally,出现异常也一定会执行该方法
* @param request
* @param response
* @param handler
* @param ex Exception对象,在该方法中去做一些:记录异常日志的功能,或者清除资源
* @throws Exception
*/
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
System.out.println(this.getClass().getName()+"---------在视图渲染之后--------------afterCompletion");
}
}
在spring boot 项目中配置
实现 WebMvcConfigurer 接口 并重写 addInterceptors方法。
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.InterceptorRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;
@Configuration
public class InterceptorAdapter implements WebMvcConfigurer {
@Bean
public MyFirstInterceptor myInterceptor(){
return new MyFirstInterceptor();
}
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(myInterceptor()).addPathPatterns("/**").excludePathPatterns("/*.html");
}
}
@RequestMapping("/test01")
public String test01(){
System.out.println("请求方法执行中...");
return "admin";
}
}
输出结果
demo.springboot.web.MyFirstInterceptor---------方法后执行,在渲染之前--------------preHandle 请求方法执行中... demo.springboot.web.MyFirstInterceptor---------方法后执行,在渲染之前--------------postHandle demo.springboot.web.MyFirstInterceptor---------在视图渲染之后--------------afterCompletion
通过运行结果能够发现拦截器的执行顺序如下:
可以看到先执行拦截器的preHandle方法》执行目标方法》执行 拦截器的postHandle方法》执行页面跳转》执行拦截器的afterCompletion方法 。
在配置拦截器的时候有两个需要注意的点:
1、如果prehandle方法返回值 为false,那么意味着不放行,那么就会造成后续的所有操作都中断
2、如果执行到方法中出现异常,那么后续流程不会处理但是 afterCompletion方法会执行
配置多个拦截器
import org.springframework.web.servlet.HandlerInterceptor;
import org.springframework.web.servlet.ModelAndView;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
public class MySecondInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
System.out.println(this.getClass().getName()+"‐‐‐‐‐‐‐ >preHandle");
return true;
}
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
System.out.println(this.getClass().getName()+"--------------postHandle");
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
System.out.println(this.getClass().getName()+"-------------afterCompletion");
}
}
@Configuration
public class InterceptorAdapter implements WebMvcConfigurer {
@Bean
public MyFirstInterceptor myInterceptor(){
return new MyFirstInterceptor();
}
@Bean
public MySecondInterceptor mySecondInterceptor(){
return new MySecondInterceptor();
}
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(myInterceptor()).addPathPatterns("/**").excludePathPatterns("/*.html");
registry.addInterceptor(mySecondInterceptor()).addPathPatterns("/**").excludePathPatterns("/*.html");
}
}
运行结果:
demo.springboot.web.MyFirstInterceptor---------方法后执行,在渲染之前--------------preHandle demo.springboot.web.MySecondInterceptor‐‐‐‐‐‐‐ >preHandle
请求方法执行中...
demo.springboot.web.MySecondInterceptor--------------postHandle
demo.springboot.web.MyFirstInterceptor---------方法后执行,在渲染之前--------------postHandle demo.springboot.web.MySecondInterceptor-------------afterCompletion
demo.springboot.web.MyFirstInterceptor---------在视图渲染之后--------------afterCompletion
大家可以看到对应的效果,谁先执行取决于配置的顺序。
如果执行的时候核心的业务代码出问题了,那么已经通过的拦截器的 afterCompletion会接着执行。
拦截器跟过滤器的区别
定义过滤器
@WebFilter("/*")
public class MyFilter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
System.out.println("===================过滤器前===================");
filterChain.doFilter(servletRequest,servletResponse);
System.out.println("===================过滤器后===================");
}
@Override
public void destroy() {
}
}
定义拦截器
public class MyFirstInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
System.out.println("---------方法后执行,在渲染之前--------------preHandle");
return true;
}
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
System.out.println("---------方法后执行,在渲染之前--------------postHandle");
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
System.out.println("---------在视图渲染之后--------------afterCompletion");
}
}
运行结果:
=过滤器前=
---------方法后执行,在渲染之前--------------preHandle
请求方法执行中...
---------方法后执行,在渲染之前--------------postHandle
---------在视图渲染之后--------------afterCompletion
=过滤器后=
过滤器Filter执行了两次,拦截器Interceptor只执行了一次。
过滤器和拦截器区别:
1、过滤器是基于函数回调的,而拦截器是基于java反射的
在我们自定义的过滤器中都会实现一个 doFilter()方法,这个方法有一个FilterChain 参数,而实际上它是一个回调接口。ApplicationFilterChain是它的实现类, 这个实现类内部也有一个 doFilter() 方法就是回调方法。
public interface FilterChain {
void doFilter(ServletRequest var1, ServletResponse var2) throws IOException, ServletException;
}
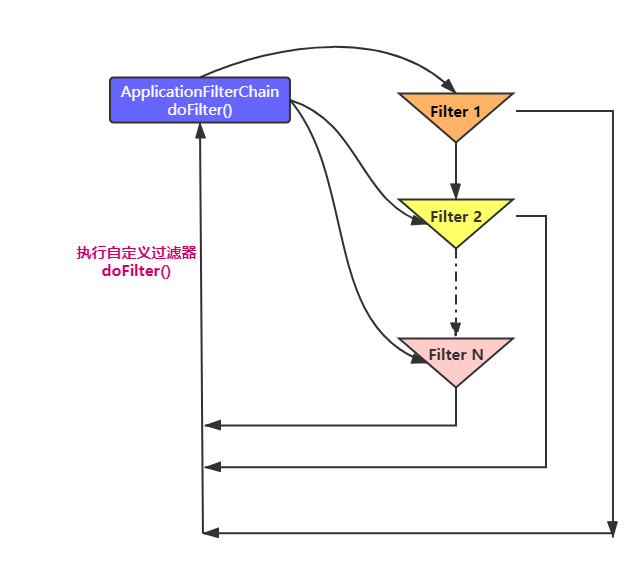
ApplicationFilterChain里面能拿到我们自定义的xxxFilter类,在其内部回调方法doFilter()里调用各个自定义xxxFilter过滤器,并执行 doFilter() 方法。
public final class ApplicationFilterChain implements FilterChain {
@Override
public void doFilter(ServletRequest request, ServletResponse response) {
...//省略
internalDoFilter(request,response);
}
private void internalDoFilter(ServletRequest request, ServletResponse response){
if (pos < n) {
//获取第pos个filter
ApplicationFilterConfig filterConfig = filters[pos++];
Filter filter = filterConfig.getFilter();
...
filter.doFilter(request, response, this);
}
}
}
而每个xxxFilter 会先执行自身的 doFilter() 过滤逻辑,最后在执行结束前会执行filterChain.doFilter(servletRequest, servletResponse),也就是回调ApplicationFilterChain的doFilter() 方法,以此循环执行实现函数回调。
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
filterChain.doFilter(servletRequest, servletResponse);
}
2、过滤器依赖于servlet容器,而拦截器不依赖与Servlet容器,拦截器依赖SpringMVC
3、过滤器几乎对所有的请求都可以起作用,而拦截器只能对SpringMVC请求起作用
4、拦截器可以访问处理方法的上下文,而过滤器不可以
5、触发时机不同,过滤器Filter是在请求进入容器后,但在进入servlet之前进行预处理,请求结束是在servlet处理完以后。
拦截器 Interceptor 是在请求进入servlet后,在进入Controller之前进行预处理的,Controller 中渲染了对应的视图之后请求结束。
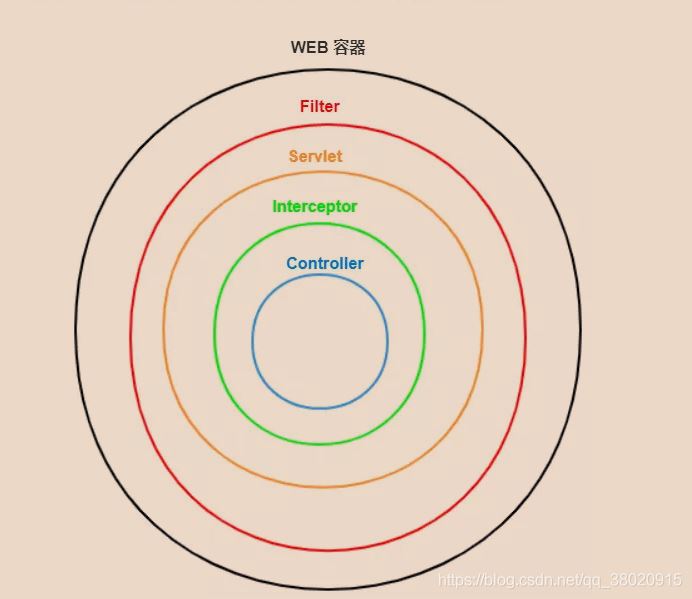
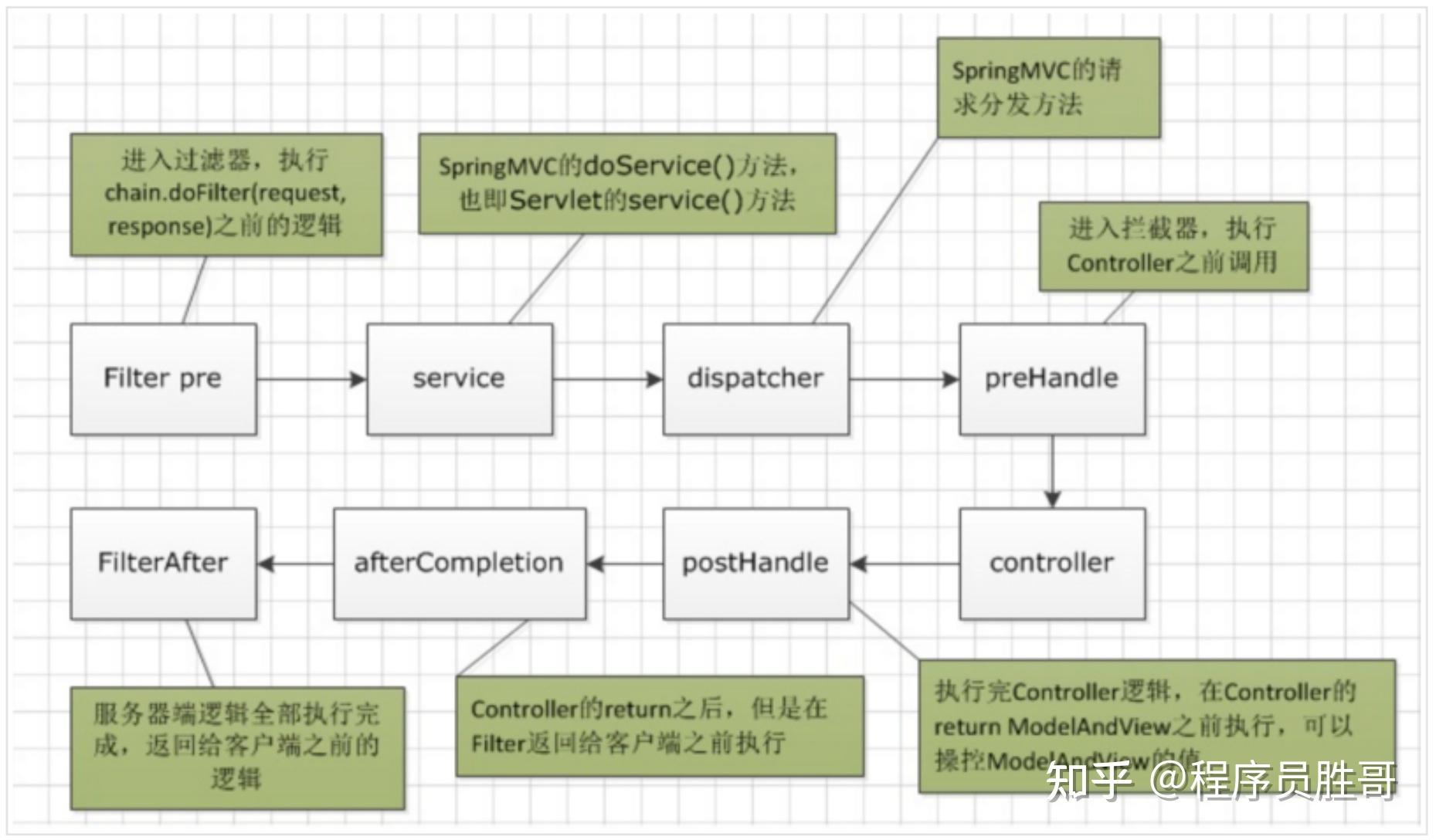
6、控制执行顺序不同
实际开发过程中,会出现多个过滤器或拦截器同时存在的情况,不过,有时我们希望某个过滤器或拦截器能优先执行,就涉及到它们的执行顺序。
过滤器用@Order注解控制执行顺序,通过@Order控制过滤器的级别,值越小级别越高越先执行。
@Order(Ordered.HIGHEST_PRECEDENCE)
@Component
public class MyFilter2 implements Filter {
拦截器默认的执行顺序,就是它的注册顺序,也可以通过Order手动设置控制,值越小越先执行。
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new MyInterceptor2()).addPathPatterns("/**").order(2);
registry.addInterceptor(new MyInterceptor1()).addPathPatterns("/**").order(1);
registry.addInterceptor(new MyInterceptor()).addPathPatterns("/**").order(3);
}
看到输出结果发现,先声明的拦截器 preHandle() 方法先执行,而postHandle()方法反而会后执行。
postHandle() 方法被调用的顺序跟 preHandle() 居然是相反的!如果实际开发中严格要求执行顺序,那就需要特别注意这一点。
我们要知道controller 中所有的请求都要经过核心组件DispatcherServlet路由,都会执行它的 doDispatch() 方法,而拦截器postHandle()、preHandle()方法便是在其中调用的。
protected void doDispatch(HttpServletRequest request, HttpServletResponse response) throws Exception {
try {
...........
try {
// 获取可以执行当前Handler的适配器
HandlerAdapter ha = getHandlerAdapter(mappedHandler.getHandler());
// Process last-modified header, if supported by the handler.
String method = request.getMethod();
boolean isGet = "GET".equals(method);
if (isGet || "HEAD".equals(method)) {
long lastModified = ha.getLastModified(request, mappedHandler.getHandler());
if (new ServletWebRequest(request, response).checkNotModified(lastModified) && isGet) {
return;
}
}
// 注意: 执行Interceptor中PreHandle()方法
if (!mappedHandler.applyPreHandle(processedRequest, response)) {
return;
}
// 注意:执行Handle【包括我们的业务逻辑,当抛出异常时会被Try、catch到】
mv = ha.handle(processedRequest, response, mappedHandler.getHandler());
if (asyncManager.isConcurrentHandlingStarted()) {
return;
}
applyDefaultViewName(processedRequest, mv);
// 注意:执行Interceptor中PostHandle 方法【抛出异常时无法执行】
mappedHandler.applyPostHandle(processedRequest, response, mv);
}
}
...........
}
看看两个方法applyPreHandle()、applyPostHandle()具体是如何被调用的,就明白为什么postHandle()、preHandle() 执行顺序是相反的了。
boolean applyPreHandle(HttpServletRequest request, HttpServletResponse response) throws Exception {
HandlerInterceptor[] interceptors = this.getInterceptors();
if(!ObjectUtils.isEmpty(interceptors)) {
for(int i = 0; i < interceptors.length; this.interceptorIndex = i++) {
HandlerInterceptor interceptor = interceptors[i];
if(!interceptor.preHandle(request, response, this.handler)) {
this.triggerAfterCompletion(request, response, (Exception)null);
return false;
}
}
}
return true;
}
void applyPostHandle(HttpServletRequest request, HttpServletResponse response, @Nullable ModelAndView mv) throws Exception {
HandlerInterceptor[] interceptors = this.getInterceptors();
if(!ObjectUtils.isEmpty(interceptors)) {
for(int i = interceptors.length - 1; i >= 0; --i) {
HandlerInterceptor interceptor = interceptors[i];
interceptor.postHandle(request, response, this.handler, mv);
}
}
}
发现两个方法中在调用拦截器数组 HandlerInterceptor[] 时,循环的顺序竟然是相反的。。。,导致postHandle()、preHandle() 方法执行的顺序相反。
总结
过滤器就是筛选出你要的东西,比如requeset中你要的那部分 拦截器在做安全方面用的比较多,比如终止一些流程
过滤器(Filter) :可以拿到原始的http请求,但是拿不到你请求的控制器和请求控制器中的方法的信息。
拦截器(Interceptor):可以拿到你请求的控制器和方法,却拿不到请求方法的参数。
切片(Aspect): 可以拿到方法的参数,但是却拿不到http请求和响应的对象
监听器
主要作用是:做一些初始化的内容添加工作、设置一些基本的内容、比如一些参数或者是一些固定的对象等等。
监听器定义为接口,监听的方法需要事件对象传递进来,从而在监听器上通过事件对象获取得到事件源,对事件源进行修改!
监听器组件
- 事件源:拥有事件
- 监听器:监听事件源所拥有的事件(带事件对象参数的)
- 事件对象:事件对象封装了事件源对象
当事件源发生某个动作的时候,它会调用事件监听器的方法,并在调用事件监听器方法的时候把事件对象传递进去。
我们在监听器中就可以通过事件对象获取得到事件源,从而对事件源进行操作!
分类
listener具体分为八种,能够监听包括request域,session域,application域的产生,销毁和属性的变化;
ServletContextAttributeListener、HttpSessionAttributeListener、ServletRequestAttributeListener分别监听着Context、Session、Request对象属性的变化。
按监听的对象划分
可以分为:
- ServletContext对象的监听器
- HttpSession对象的监听器
- ServletRequest对象的监听器
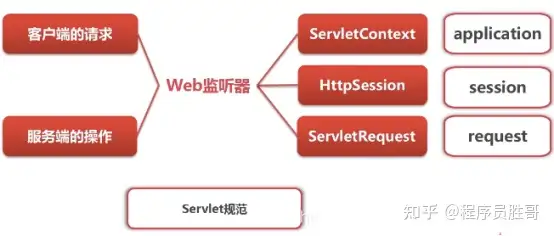
按监听的事件划分
可以分为:
- 对象自身的创建和销毁的监听器
- 对象中属性的创建和消除的监听器
- session中的某个对象的状态变化的监听器
Servlet监听器
在Servlet规范中定义了多种类型的监听器,它们用于监听的事件源分别 ServletContext, HttpSession和ServletRequest这三个域对象
和其它事件监听器略有不同的是,servlet监听器的注册不是直接注册在事件源上,而是由WEB容器负责注册,开发人员只需在web.xml文件中使用标签配置好监听器。
ServletContextListener:监听ServletContext对象的创建和销毁
包含两个方法:
void contextDestroyed(ServletContextEvent sce) :ServletContext对象被销毁之前会调用
void contextInitialized(ServletContextEvent sce) :ServletContext对象创建后会调用该方法
自定义监听器:
使用注解@WebListener
import javax.servlet.*;
import javax.servlet.http.*;
import avax.servlet.annotation.*;
@WebListener
@Component
public class ListenerDemo2 implements ServletContextListener {
public ListenerDemo2() {
}
@Override
public void contextInitialized(ServletContextEvent sce) {
/* This method is called when the servlet context is initialized(when the Web application is deployed). */
//加载资源 //1,获取ServletContext对象
ServletContext servletContext = servletContextEvent.getServletContext();
//2,加载资源⽂件
String contextLoadConfig = servletContext.getInitParameter("contextLoadConfig"); System.out.println("contextLoadConfig:"+contextLoadConfig);
System.out.println("ListenerDemo2 contextInitialized....");
}
@Override
public void contextDestroyed(ServletContextEvent sce) {
/* This method is called when the servlet Context is undeployed or Application Server shuts down. */
System.out.println("ListenerDemo2 contextDestroyed....");
}
}
监听对象的创建和销毁
HttpSessionListener、ServletContextListener、ServletRequestListener分别监控着Session、Context、Request对象的创建和销毁。
package demo.springboot.web;
import org.springframework.stereotype.Component;
import javax.servlet.ServletContextEvent;
import javax.servlet.ServletContextListener;
import javax.servlet.ServletRequestEvent;
import javax.servlet.ServletRequestListener;
import javax.servlet.annotation.WebListener;
import javax.servlet.http.HttpSessionEvent;
import javax.servlet.http.HttpSessionListener;
@Component
@WebListener
public class Listener1 implements ServletContextListener, HttpSessionListener, ServletRequestListener {
public Listener1() {
}
public void contextInitialized(ServletContextEvent sce) {
System.out.println("容器创建了");
}
public void contextDestroyed(ServletContextEvent sce) {
System.out.println("容器销毁了");
}
@Override
public void sessionCreated(HttpSessionEvent se) {
System.out.println("Session创建了");
}
@Override
public void sessionDestroyed(HttpSessionEvent se) {
System.out.println("Session销毁了");
}
@Override
public void requestDestroyed(ServletRequestEvent servletRequestEvent) {
}
@Override
public void requestInitialized(ServletRequestEvent servletRequestEvent) {
}
}
监听器监听到ServletContext的初始化了,Session的创建和ServletContext的销毁。(服务器停掉,不代表Session就被销毁了。Session的创建是在内存中的,所以没看到Session被销毁了)
监听对象属性变化
ServletContextAttributeListener、HttpSessionAttributeListener、ServletRequestAttributeListener分别监听着Context、Session、Request对象属性的变化
这三个接口中都定义了三个方法来处理被监听对象中的属性的增加,删除和替换的事件,同一个事件在这三个接口中对应的方法名称完全相同,只是接受的参数类型不同。
- attributeAdded()
- attributeRemoved()
- attributeReplaced()
public class Listener2 implements ServletContextAttributeListener {
@Override
public void attributeAdded(ServletContextAttributeEvent servletContextAttributeEvent) {
System.out.println("Context对象增加了属性");
}
@Override
public void attributeRemoved(ServletContextAttributeEvent servletContextAttributeEvent) {
System.out.println("Context对象删除了属性");
}
@Override
public void attributeReplaced(ServletContextAttributeEvent servletContextAttributeEvent) {
System.out.println("Context对象替换了属性");
}
}
测试方法
@GetMapping("/test")
public String get(@RequestParam("msg") String msg, HttpServletRequest request){
System.out.println(msg);
request.setAttribute("aa", "123");
return msg;
}
Context对象增加了属性
监听Session内的对象
监听Session内的对象,分别是HttpSessionBindingListener和HttpSessionActivationListener
应用场景
拦截器是在DispatcherServlet这个servlet中执行的,因此所有的请求最先进入Filter,最后离开Filter。其顺序如下。
Filter->Interceptor.preHandle->Handler->Interceptor.postHandle->Interceptor.afterCompletion->Filter
拦截器应用场景
拦截器本质上是面向切面编程(AOP),符合横切关注点的功能都可以放在拦截器中来实现,主要的应用场景包括:
- 登录验证,判断用户是否登录。
- 权限验证,判断用户是否有权限访问资源,如校验token
- 日志记录,记录请求操作日志(用户ip,访问时间等),以便统计请求访问量。
- 处理cookie、本地化、国际化、主题等。
- 性能监控,监控请求处理时长等。
- 通用行为:读取cookie得到用户信息并将用户对象放入请求,从而方便后续流程使用,还有如提取Locale、Theme信息等,只要是多个处理器都需要的即可使用拦截器实现)
过滤器应用场景
- 过滤敏感词汇(防止sql注入)
- 设置字符编码
- URL级别的权限访问控制
- 压缩响应信息
3. 接口和抽象类的区别
相似点:
(1)接口和抽象类都不能被实例化
(2)实现接口或继承抽象类的普通子类都必须实现这些抽象方法
不同点:
(1)抽象类可以包含普通方法和代码块,接口里只能包含抽象方法,静态方法和默认方法,
(2)抽象类可以有构造方法,而接口没有
(3)抽象类中的成员变量可以是各种类型的,接口的成员变量只能是 public static final 类型的,并且必须赋值
4. 重载和重写的区别
重载发生在同一个类中,方法名相同、参数列表、返回类型、权限修饰符可以不同
重写发生在子类中,方法名相、参数列表、返回类型都相同,权限修饰符要大于父类方法,声明异常范围要小于父类方法,但是final和private修饰的方法不可重写
5. ==和equals的区别
比较基本类型,比较的是值,比较引用类型,比较的是内存地址
equlas是Object类的方法,本质上与==一样,但是有些类重写了equals方法,比如String的equals被重写后,比较的是字符值,另外重写了equlas后,也必须重写hashcode()方法
6. 异常处理机制
(1)使用try、catch、finaly捕获异常,finaly中的代码一定会执行,捕获异常后程序会继续执行
(2)使用throws声明该方法可能会抛出的异常类型,出现异常后,程序终止
7、HashMap原理
1.HashMap在Jdk1.8以后是基于数组+链表+红黑树来实现的,特点是,key不能重复,可以为null,线程不安全
2.HashMap的扩容机制:
HashMap的默认容量为16,默认的负载因子为0.75,当HashMap中元素个数超过容量乘以负载因子的个数时,就创建一个大小为前一次两倍的新数组,再将原来数组中的数据复制到新数组中。当数组长度到达64且链表长度大于8时,链表转为红黑树
3.HashMap存取原理:
(1)计算key的hash值,然后进行二次hash,根据二次hash结果找到对应的索引位置
(2)如果这个位置有值,先进性equals比较,若结果为true则取代该元素,若结果为false,就使用高低位平移法将节点插入链表(JDK8以前使用头插法,但是头插法在并发扩容时可能会造成环形链表或数据丢失,而高低位平移发会发生数据覆盖的情况)
8、想要线程安全的HashMap怎么办?
(1)使用ConcurrentHashMap
(2)使用HashTable
(3)Collections.synchronizedHashMap()方法
9、ConcurrentHashMap原如何保证的线程安全?
JDK1.7:使用分段锁,将一个Map分为了16个段,每个段都是一个小的hashmap,每次操作只对其中一个段加锁
JDK1.8:采用CAS+Synchronized保证线程安全,每次插入数据时判断在当前数组下标是否是第一次插入,是就通过CAS方式插入,然后判断f.hash是否=-1,是的话就说明其他线程正在进行扩容,当前线程也会参与扩容;删除方法用了synchronized修饰,保证并发下移除元素安全
10、HashTable与HashMap的区别
(1)HashTable的每个方法都用synchronized修饰,因此是线程安全的,但同时读写效率很低
(2)HashTable的Key不允许为null
(3)HashTable只对key进行一次hash,HashMap进行了两次Hash
(4)HashTable底层使用的数组加链表
11、ArrayList和LinkedList的区别
ArratList的底层使用动态数组,默认容量为10,当元素数量到达容量时,生成一个新的数组,大小为前一次的1.5倍,然后将原来的数组copy过来;因为数组在内存中是连续的地址,所以ArrayList查找数据更快,由于扩容机制添加数据效率更低
LinkedList的底层使用链表,在内存中是离散的,没有扩容机制;LinkedList在查找数据时需要从头遍历,所以查找慢,但是添加数据效率更高
12、如何保证ArrayList的线程安全?
(1)使用collentions.synchronizedList()方法为ArrayList加锁
(2)使用Vector,Vector底层与Arraylist相同,但是每个方法都由synchronized修饰,速度很慢
(3)使用juc下的CopyOnWriterArrayList,该类实现了读操作不加锁,写操作时为list创建一个副本,期间其它线程读取的都是原本list,写操作都在副本中进行,写入完成后,再将指针指向副本。
13、List如何排序?
方式1:JAVA中我们可以使用java.util.Collections类的sort(List list)方法对list集合中的元素排序。
方式2:JDK8之后特别是lambda表达式的盛行,而且Collections的sort方法其实是调用了List接口自己的sort方法;所以可以使用List接口自己的sort方法排序
方式3:Stream流的sort方法写法
集合元素是基本类型包装类型
public static void main(String[] args) {
List<Integer> numList=new ArrayList<>();
numList.add(999);
numList.add(123);
numList.add(456);
numList.add(66);
numList.add(9);
Collections.sort(numList); //使用Collections类的方法排序
numList.sort(new Comparator<Integer>() {//使用List接口的方法排序
@Override
public int compare(Integer o1, Integer o2) {
return o1.compareTo(o2);
}
});
//lambda表达式实现List接口sort方法排序
numList.sort((num1,num2)->{return num1.compareTo(num2);});
System.out.println(numList);
}
对象的集合根据某个属性排序
public static void main(String[] args) {
List<User> numList=new ArrayList<>();
User u=new User();
u.setAge(12);
numList.add(u);
User u1=new User();
u1.setAge(34);
numList.add(u1);
User u2=new User();
u2.setAge(6);
numList.add(u2);
User u3=new User();
u3.setAge(99);
numList.add(u3);
//Collections类的sort方法对对象集合排序,要传集合和Comparator接口两个参数
Collections.sort(numList, new Comparator<User>() {
@Override
public int compare(User o1, User o2) {
Integer age1= o1.getAge();
Integer age2= o2.getAge();
return age1.compareTo(age2);
}
});
//List接口自身的sort方法对对象集合排序,重写Comparator接口方法即可
numList.sort(new Comparator<User>() {
@Override
public int compare(User u1, User u2) {
Integer age1= u1.getAge();
Integer age2= u2.getAge();
return age1.compareTo(age2);
}
});
//List接口的sort方法,lambda表达式写法
numList.sort((u4,u5)->{
Integer age1= u4.getAge();
Integer age2= u5.getAge();
return age1.compareTo(age2);
});
System.out.println(numList);
}
使用Stream流排序
1.首先你需要list.parallelStream().sorted 进行流处理,使用parallelStream可以充分调度多核CPU。
2.使用Comparator.comparing进行排序,reversed()进行倒序排列,thenComparing进行下一个排序。
3.Comparator.comparing()里面的内容,也是就是Object::getter,例如KeywordCounterDTO::getKeyword
4.最后格式化为需要的格式 List 是.collect(Collectors.toList()) , Map 是 .collect(Collectors.toMap(KeywordCounterDTO::getKey, KeywordCounterDTO::getValue))
根据年龄倒序排
public static void main(String[] args) {
List<User> numList=new ArrayList<>();
User u=new User();
u.setAge(12);
numList.add(u);
User u1=new User();
u1.setAge(34);
numList.add(u1);
User u2=new User();
u2.setAge(6);
numList.add(u2);
User u3=new User();
u3.setAge(99);
numList.add(u3);
numList = numList.stream().sorted(Comparator.comparing(User::getAge).reversed()).collect(Collectors.toList());
}
先对学生的班级做排序,然后同班级做倒序
public static void main(String[] args) {
List<User> numList=new ArrayList<>();
User u=new User();
u.setClass(1);
u.setAge(12);
numList.add(u);
User u1=new User();
u.setClass(1);
u1.setAge(34);
numList.add(u1);
User u2=new User();
u.setClass(2);
u2.setAge(6);
numList.add(u2);
User u3=new User();
u.setClass(2);
u3.setAge(99);
numList.add(u3);
numList = numList.parallelStream().sorted(
Comparator.comparing(User::getClass).reversed().thenComparing(User::getAge)
).collect(Collectors.toList());
}
# 当集合中存在null元素时,可以使用针对null友好的比较器,null元素排在集合的最前面:nullsFirst
public static void main(String[] args) {
List<User> numList=new ArrayList<>();
User u=new User();
u.setClass(1);
u.setAge(12);
numList.add(u);
User u1=new User();
u.setClass(1);
u1.setAge(34);
numList.add(u1);
User u2=new User();
u.setClass(2);
u2.setAge(6);
numList.add(u2);
User u3=new User();
u.setClass(2);
u3.setAge(99);
numList.add(u3);
numList = numList.parallelStream().sorted(
Comparator.nullsFirst(User::getClass).reversed().thenComparing(User::getAge)
).collect(Collectors.toList());
}
14、排序方法
交换排序
所谓交换,就是序列中任意两个元素进行比较,根据比较结果来交换各自在序列中的位置,以此达到排序的目的。
1、冒泡排序
冒泡排序是一种简单的交换排序算法,以升序排序为例,其核心思想是:
- 从第一个元素开始,比较相邻的两个元素。如果第一个比第二个大,则进行交换。
- 轮到下一组相邻元素,执行同样的比较操作,再找下一组,直到没有相邻元素可比较为止,此时最后的元素应是最大的数。
- 除了每次排序得到的最后一个元素,对剩余元素重复以上步骤,直到没有任何一对元素需要比较为止。
用 Java 实现的冒泡排序如下
public void bubbleSortOpt(int[] arr) {
if(arr == null) {
throw new NullPoniterException();
}
if(arr.length < 2) {
return;
}
int temp = 0;
for(int i = 0; i < arr.length - 1; i++) {
for(int j = 0; j < arr.length - i - 1; j++) {
if(arr[j] > arr[j + 1]) {
temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
}
2、快速排序
快速排序的思想很简单,就是先把待排序的数组拆成左右两个区间,左边都比中间的基准数小,右边都比基准数大。接着左右两边各自再做同样的操作,完成后再拆分再继续,一直到各区间只有一个数为止。
举个例子,现在我要排序 4、9、5、1、2、6 这个数组。一般取首位的 4 为基准数,第一次排序的结果是:
2、1、4、5、9、6
可能有人觉得奇怪,2 和 1 交换下位置也能满足条件,为什么 2 在首位?这其实由实际的代码实现来决定,并不影响之后的操作。以 4 为分界点,对 2、1、4 和 5、9、6 各自排序,得到:
1、2、4、5、9、6
不用管左边的 1、2、4 了,将 5、9、6 拆成 5 和 9、6,再排序,至此结果为:
1、2、4、5、6、9
为什么把快排划到交换排序的范畴呢?因为元素的移动也是靠交换位置来实现的。算法的实现需要用到递归(拆分区间之后再对每个区间作同样的操作)
public void quicksort(int[] arr, int start, int end) {
if(start < end) {
// 把数组中的首位数字作为基准数
int stard = arr[start];
// 记录需要排序的下标
int low = start;
int high = end;
// 循环找到比基准数大的数和比基准数小的数
while(low < high) {
// 右边的数字比基准数大
while(low < high && arr[high] >= stard) {
high--;
}
// 使用右边的数替换左边的数
arr[low] = arr[high];
// 左边的数字比基准数小
while(low < high && arr[low] <= stard) {
low++;
}
// 使用左边的数替换右边的数
arr[high] = arr[low];
}
// 把标准值赋给下标重合的位置
arr[low] = stard;
// 处理所有小的数字
quickSort(arr, start, low);
// 处理所有大的数字
quickSort(arr, low + 1, end);
}
}
插入排序
插入排序是一种简单的排序方法,其基本思想是将一个记录插入到已经排好序的有序表中,使得被插入数的序列同样是有序的。按照此法对所有元素进行插入,直到整个序列排为有序的过程。
1、直接插入排序
直接插入排序就是插入排序的粗暴实现。对于一个序列,选定一个下标,认为在这个下标之前的元素都是有序的。将下标所在的元素插入到其之前的序列中。接着再选取这个下标的后一个元素,继续重复操作。直到最后一个元素完成插入为止。我们一般从序列的第二个元素开始操作。
用 Java 实现的算法如下:
public void insertSort(int[] arr) {
// 遍历所有数字
for(int i = 1; i < arr.length - 1; i++) {
// 当前数字比前一个数字小
if(arr[i] < arr[i - 1]) {
int j;
// 把当前遍历的数字保存起来
int temp = arr[i];
for(j = i - 1; j >= 0 && arr[j] > temp; j--) {
// 前一个数字赋给后一个数字
arr[j + 1] = arr[j];
}
// 把临时变量赋给不满足条件的后一个元素
arr[j + 1] = temp;
}
}
}
2. 希尔排序
某些情况下直接插入排序的效率极低。比如一个已经有序的升序数组,这时再插入一个比最小值还要小的数,也就意味着被插入的数要和数组所有元素比较一次。我们需要对直接插入排序进行改进。
怎么改进呢?前面提过,插入排序对已经排好序的数组操作时,效率很高。因此我们可以试着先将数组变为一个相对有序的数组,然后再做插入排序。
希尔排序能实现这个目的。希尔排序把序列按下标的一定增量(步长)分组,对每组分别使用插入排序。随着增量(步长)减少,一直到一,算法结束,整个序列变为有序。因此希尔排序又称缩小增量排序。
一般来说,初次取序列的一半为增量,以后每次减半,直到增量为一。
用 Java 实现的算法如下:
public void shellSort(int[] arr) {
// gap 为步长,每次减为原来的一半。
for (int gap = arr.length / 2; gap > 0; gap /= 2) {
// 对每一组都执行直接插入排序
for (int i = 0 ;i < gap; i++) {
// 对本组数据执行直接插入排序
for (int j = i + gap; j < arr.length; j += gap) {
// 如果 a[j] < a[j-gap],则寻找 a[j] 位置,并将后面数据的位置都后移
if (arr[j] < arr[j - gap]) {
int k;
int temp = arr[j];
for (k = j - gap; k >= 0 && arr[k] > temp; k -= gap) {
arr[k + gap] = arr[k];
}
arr[k + gap] = temp;
}
}
}
}
}
选择排序
选择排序是一种简单直观的排序算法,首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
1. 简单选择排序
选择排序思想的暴力实现,每一趟从未排序的区间找到一个最小元素,并放到第一位,直到全部区间有序为止。
public void selectSort(int[] arr) {
// 遍历所有的数
for (int i = 0; i < arr.length; i++) {
int minIndex = i;
// 把当前遍历的数和后面所有的数进行比较,并记录下最小的数的下标
for (int j = i + 1; j < arr.length; j++) {
if (arr[j] < arr[minIndex]) {
// 记录最小的数的下标
minIndex = j;
}
}
// 如果最小的数和当前遍历的下标不一致,则交换
if (i != minIndex) {
int temp = arr[i];
arr[i] = arr[minIndex];
arr[minIndex] = temp;
}
}
}
2. 堆排序
我们知道,对于任何一个数组都可以看成一颗完全二叉树。堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆;或者每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆。如下图:
像上图的大顶堆,映射为数组,就是 [50, 45, 40, 20, 25, 35, 30, 10, 15]。可以发现第一个下标的元素就是最大值,将其与末尾元素交换,则末尾元素就是最大值。所以堆排序的思想可以归纳为以下两步:
- 根据初始数组构造堆
- 每次交换第一个和最后一个元素,然后将除最后一个元素以外的其他元素重新调整为大顶堆
重复以上两个步骤,直到没有元素可操作,就完成排序了。
我们需要把一个普通数组转换为大顶堆,调整的起始点是最后一个非叶子结点,然后从左至右,从下至上,继续调整其他非叶子结点,直到根结点为止。
/**
* 转化为大顶堆
* @param arr 待转化的数组
* @param size 待调整的区间长度
* @param index 结点下标
*/
public void maxHeap(int[] arr, int size, int index) {
// 左子结点
int leftNode = 2 * index + 1;
// 右子结点
int rightNode = 2 * index + 2;
int max = index;
// 和两个子结点分别对比,找出最大的结点
if (leftNode < size && arr[leftNode] > arr[max]) {
max = leftNode;
}
if (rightNode < size && arr[rightNode] > arr[max]) {
max = rightNode;
}
// 交换位置
if (max != index) {
int temp = arr[index];
arr[index] = arr[max];
arr[max] = temp;
// 因为交换位置后有可能使子树不满足大顶堆条件,所以要对子树进行调整
maxHeap(arr, size, max);
}
}
/**
* 堆排序
* @param arr 待排序的整型数组
*/
public static void heapSort(int[] arr) {
// 开始位置是最后一个非叶子结点,即最后一个结点的父结点
int start = (arr.length - 1) / 2;
// 调整为大顶堆
for (int i = start; i >= 0; i--) {
SortTools.maxHeap(arr, arr.length, i);
}
// 先把数组中第 0 个位置的数和堆中最后一个数交换位置,再把前面的处理为大顶堆
for (int i = arr.length - 1; i > 0; i--) {
int temp = arr[0];
arr[0] = arr[i];
arr[i] = temp;
maxHeap(arr, i, 0);
}
}
归并排序
归并排序是建立在归并操作上的一种有效,稳定的排序算法。该算法采用分治法的思想,是一个非常典型的应用。归并排序的思路如下:
- 将 n 个元素分成两个各含 n/2 个元素的子序列
- 借助递归,两个子序列分别继续进行第一步操作,直到不可再分为止
- 此时每一层递归都有两个子序列,再将其合并,作为一个有序的子序列返回上一层,再继续合并,全部完成之后得到的就是一个有序的序列
关键在于两个子序列应该如何合并。假设两个子序列各自都是有序的,那么合并步骤就是:
- 创建一个用于存放结果的临时数组,其长度是两个子序列合并后的长度
- 设定两个指针,最初位置分别为两个已经排序序列的起始位置
- 比较两个指针所指向的元素,选择相对小的元素放入临时数组,并移动指针到下一位置
- 重复步骤 3 直到某一指针达到序列尾
- 将另一序列剩下的所有元素直接复制到合并序列尾
用 Java 实现的归并排序如下:
/**
* 合并数组
*/
public static void merge(int[] arr, int low, int middle, int high) {
// 用于存储归并后的临时数组
int[] temp = new int[high - low + 1];
// 记录第一个数组中需要遍历的下标
int i = low;
// 记录第二个数组中需要遍历的下标
int j = middle + 1;
// 记录在临时数组中存放的下标
int index = 0;
// 遍历两个数组,取出小的数字,放入临时数组中
while (i <= middle && j <= high) {
// 第一个数组的数据更小
if (arr[i] <= arr[j]) {
// 把更小的数据放入临时数组中
temp[index] = arr[i];
// 下标向后移动一位
i++;
} else {
temp[index] = arr[j];
j++;
}
index++;
}
// 处理剩余未比较的数据
while (i <= middle) {
temp[index] = arr[i];
i++;
index++;
}
while (j <= high) {
temp[index] = arr[j];
j++;
index++;
}
// 把临时数组中的数据重新放入原数组
for (int k = 0; k < temp.length; k++) {
arr[k + low] = temp[k];
}
}
/**
* 归并排序
*/
public static void mergeSort(int[] arr, int low, int high) {
int middle = (high + low) / 2;
if (low < high) {
// 处理左边数组
mergeSort(arr, low, middle);
// 处理右边数组
mergeSort(arr, middle + 1, high);
// 归并
merge(arr, low, middle, high);
}
}
基数排序
基数排序的原理是将整数按位数切割成不同的数字,然后按每个位数分别比较。为此需要将所有待比较的数值统一为同样的数位长度,数位不足的数在高位补零。
使用 Java 实现的基数排序:
/**
* 基数排序
*/
public static void radixSort(int[] arr) {
// 存放数组中的最大数字
int max = Integer.MIN_VALUE;
for (int value : arr) {
if (value > max) {
max = value;
}
}
// 计算最大数字是几位数
int maxLength = (max + "").length();
// 用于临时存储数据
int[][] temp = new int[10][arr.length];
// 用于记录在 temp 中相应的下标存放数字的数量
int[] counts = new int[10];
// 根据最大长度的数决定比较次数
for (int i = 0, n = 1; i < maxLength; i++, n *= 10) {
// 每一个数字分别计算余数
for (int j = 0; j < arr.length; j++) {
// 计算余数
int remainder = arr[j] / n % 10;
// 把当前遍历的数据放到指定的数组中
temp[remainder][counts[remainder]] = arr[j];
// 记录数量
counts[remainder]++;
}
// 记录取的元素需要放的位置
int index = 0;
// 把数字取出来
for (int k = 0; k < counts.length; k++) {
// 记录数量的数组中当前余数记录的数量不为 0
if (counts[k] != 0) {
// 循环取出元素
for (int l = 0; l < counts[k]; l++) {
arr[index] = temp[k][l];
// 记录下一个位置
index++;
}
// 把数量置空
counts[k] = 0;
}
}
}
}
八种排序算法的总结
| 排序法 | 最好情形 | 平均时间 | 最差情形 | 稳定度 | 空间复杂度 |
|---|---|---|---|---|---|
| 冒泡排序 | O(n) | O(n^2) | O(n^2) | 稳定 | O(1) |
| 快速排序 | O(nlogn) | O(nlogn) | O(n^2) | 不稳定 | O(nlogn) |
| 直接插入排序 | O(n) | O(n^2) | O(n^2) | 稳定 | O(1) |
| 希尔排序 | 不稳定 | O(1) | |||
| 直接选择排序 | O(n^2) | O(n^2) | O(n^2) | 不稳定 | O(1) |
| 堆排序 | O(nlogn) | O(nlogn) | O(nlogn) | 不稳定 | O(nlogn) |
| 归并排序 | O(nlogn) | O(nlogn) | O(nlogn) | 稳定 | O(n) |
15、String、StringBuffer、StringBuilder的区别
String 由 char[] 数组构成,使用了 final 修饰,对 String 进行改变时每次都会新生成一个 String 对象,然后把指针指向新的引用对象。
StringBuffer可变并且线程安全
StringBuiler可变但线程不安全。
操作少量字符数据用 String;单线程操作大量数据用 StringBuilder;多线程操作大量数据用 StringBuffer。
16、hashCode和equals
hashCode()和equals()都是Obkect类的方法,hashCode()默认是通过地址来计算hash码,但是可能被重写过用内容来计算hash码,equals()默认通过地址判断两个对象是否相等,但是可能被重写用内容来比较两个对象
所以两个对象相等,他们的hashCode和equals一定相等,但是hashCode相等的两个对象未必相等
如果重写equals()必须重写hashCode(),比如在HashMap中,key如果是String类型,String如果只重写了equals()而没有重写hashcode()的话,则两个equals()比较为true的key,因为hashcode不同导致两个key没有出现在一个索引上,就会出现map中存在两个相同的key
17、面向对象和面向过程的区别
面向对象有封装、继承、多态性的特性,所以相比面向过程易维护、易复用、易扩展,但是因为类调用时要实例化,所以开销大性能比面向过程低
18、深拷贝和浅拷贝
深拷贝和浅拷贝
这两个概念是在项目中比较常见的,在很多时候,都会遇到拷贝的问题,我们总是需要将一个对象赋值到另一个对象上,但可能会在改变新赋值对象的时候,忽略掉我是否之后还需要用到原来的对象,那么就会出现当改变新赋值对象的某一个属性时,也同时改变了原对象,此时我们就需要用到拷贝这个概念了。
Java中的对象拷贝(Object Copy)指的是将一个对象的所有属性(成员变量)拷贝到另一个有着相同类类型的对象中去。举例说明:比如,对象A和对象B都属于类S,具有属性a和b。那么对对象A进行拷贝操作赋值给对象B就是:B.a=A.a; B.b=A.b;在程序中拷贝对象是很常见的,主要是为了在新的上下文环境中复用现有对象的部分或全部数据。Java中的对象拷贝主要分为:浅拷贝(Shallow Copy)、深拷贝(Deep Copy)。先介绍一点铺垫知识:Java中的数据类型分为基本数据类型和引用数据类型。对于这两种数据类型,在进行赋值操作、用作方法参数或返回值时,会有值传递和引用(地址)传递的差别。
深拷贝和浅拷贝的区别
1.浅拷贝: 将原对象或原数组的引用直接赋给新对象,新数组,新对象/数组只是原对象的一个引用
2.深拷贝: 创建一个新的对象和数组,将原对象的各项属性的“值”(数组的所有元素)拷贝过来,是“值”而不是“引用”
一、浅拷贝(Shallow Copy)
①对于数据类型是基本数据类型的成员变量,浅拷贝会直接进行值传递,也就是将该属性值复制一份给新的对象。因为是两份不同的数据,所以对其中一个对象的该成员变量值进行修改,不会影响另一个对象拷贝得到的数据。
②对于数据类型是引用数据类型的成员变量,比如说成员变量是某个数组、某个类的对象等,那么浅拷贝会进行引用传递,也就是只是将该成员变量的引用值(内存地址)复制一份给新的对象。因为实际上两个对象的该成员变量都指向同一个实例。在这种情况下,在一个对象中修改该成员变量会影响到另一个对象的该成员变量值。
具体模型如图所示:可以看到基本数据类型的成员变量,对其值创建了新的拷贝。而引用数据类型的成员变量的实例仍然是只有一份,两个对象的该成员变量都指向同一个实例。
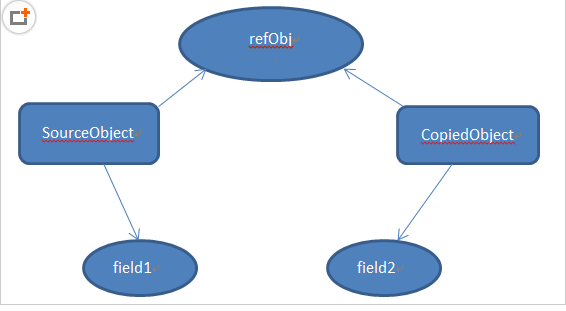
浅拷贝的实现方式主要有三种:
1)通过拷贝构造方法实现浅拷贝:
拷贝构造方法指的是该类的构造方法参数为该类的对象。使用拷贝构造方法可以很好地完成浅拷贝,直接通过一个现有的对象创建出与该对象属性相同的新的对象。
代码参考如下:
/* 拷贝构造方法实现浅拷贝 */
public class CopyConstructor {
public static void main(String[] args) {
Age a=new Age(20);
Person p1=new Person(a,"摇头耶稣");
Person p2=new Person(p1);
System.out.println("p1是"+p1);
System.out.println("p2是"+p2);
//修改p1的各属性值,观察p2的各属性值是否跟随变化
p1.setName("小傻瓜");
a.setAge(99);
System.out.println("修改后的p1是"+p1);
System.out.println("修改后的p2是"+p2);
}
}
class Person{
//两个属性值:分别代表值传递和引用传递
private Age age;
private String name;
public Person(Age age,String name) {
this.age=age;
this.name=name;
}
//拷贝构造方法
public Person(Person p) {
this.name=p.name;
this.age=p.age;
}
public void setName(String name) {
this.name=name;
}
public String toString() {
return this.name+" "+this.age;
}
}
class Age{
private int age;
public Age(int age) {
this.age=age;
}
public void setAge(int age) {
this.age=age;
}
public int getAge() {
return this.age;
}
public String toString() {
return getAge()+"";
}
}
运行结果为:
- p1是摇头耶稣 20
- p2是摇头耶稣 20
- 修改后的p1是小傻瓜 99
- 修改后的p2是摇头耶稣 99
结果分析:这里对Person类选择了两个具有代表性的属性值:一个是引用传递类型;另一个是字符串类型(属于常量)。通过拷贝构造方法进行了浅拷贝,各属性值成功复制。其中,p1值传递部分的属性值发生变化时,p2不会随之改变;而引用传递部分属性值发生变化时,p2也随之改变。
要注意:如果在拷贝构造方法中,对引用数据类型变量逐一开辟新的内存空间,创建新的对象,也可以实现深拷贝。而对于一般的拷贝构造,则一定是浅拷贝。
2)通过重写clone()方法进行浅拷贝:
Object类是类结构的根类,其中有一个方法为protected Object clone() throws CloneNotSupportedException,这个方法就是进行的浅拷贝。有了这个浅拷贝模板,我们可以通过调用clone()方法来实现对象的浅拷贝。但是需要注意:
- Object类虽然有这个方法,但是这个方法是受保护的(被protected修饰),所以我们无法直接使用。
- 使用clone方法的类必须实现Cloneable接口,否则会抛出异常CloneNotSupportedException。对于这两点,我们的解决方法是,在要使用clone方法的类中重写clone()方法,通过super.clone()调用Object类中的原clone方法。
参考代码如下:对Student类的对象进行拷贝,直接重写clone()方法,通过调用clone方法即可完成浅拷贝。
/* clone方法实现浅拷贝 */
public class ShallowCopy {
public static void main(String[] args) {
Age a=new Age(20);
Student stu1=new Student("摇头耶稣",a,175);
//通过调用重写后的clone方法进行浅拷贝
Student stu2=(Student)stu1.clone();
System.out.println(stu1.toString());
System.out.println(stu2.toString());
//尝试修改stu1中的各属性,观察stu2的属性有没有变化
stu1.setName("大傻子");
//改变age这个引用类型的成员变量的值
a.setAge(99);
//stu1.setaAge(new Age(99)); 使用这种方式修改age属性值的话,stu2是不会跟着改变的。因为创建了一个新的Age类对象而不是改变原对象的实例值
stu1.setLength(216);
System.out.println(stu1.toString());
System.out.println(stu2.toString());
}
}
/** 创建年龄类*/
class Age{
//年龄类的成员变量(属性)
private int age;
//构造方法
public Age(int age) {
this.age=age;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String toString() {
return this.age+"";
}
}
/** 创建学生类*/
class Student implements Cloneable{
//学生类的成员变量(属性),其中一个属性为类的对象
private String name;
private Age aage;
private int length;
//构造方法,其中一个参数为另一个类的对象
public Student(String name,Age a,int length) {
this.name=name;
this.aage=a;
this.length=length;
}
//eclipe中alt+shift+s自动添加所有的set和get方法
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Age getaAge() {
return this.aage;
}
public void setaAge(Age age) {
this.aage=age;
}
public int getLength() {
return this.length;
}
public void setLength(int length) {
this.length=length;
}
//设置输出的字符串形式
public String toString() {
return "姓名是: "+this.getName()+", 年龄为: "+this.getaAge().toString()+", 长度是: "+this.getLength();
}
//重写Object类的clone方法
public Object clone() {
Object obj=null;
//调用Object类的clone方法,返回一个Object实例
try {
obj= super.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
return obj;
}
}
String类型非常特殊,所以我额外设置了一个字符串类型的成员变量来进行说明。首先,String类型属于引用数据类型,不属于基本数据类型,但是String类型的数据是存放在常量池中的,也就是无法修改的!也就是说,当我将name属性从“摇头耶稣”改为“大傻子"后,并不是修改了这个数据的值,而是把这个数据的引用从指向”摇头耶稣“这个常量改为了指向”大傻子“这个常量。在这种情况下,另一个对象的name属性值仍然指向”摇头耶稣“不会受到影响。
二、深拷贝(Deep Copy)
首先介绍对象图的概念。设想一下,一个类有一个对象,其成员变量中又有一个对象,该对象指向另一个对象,另一个对象又指向另一个对象,直到一个确定的实例。这就形成了对象图。那么,对于深拷贝来说,不仅要复制对象的所有基本数据类型的成员变量值,还要为所有引用数据类型的成员变量申请存储空间,并复制每个引用数据类型成员变量所引用的对象,直到该对象可达的所有对象。也就是说,对象进行深拷贝要对整个对象图进行拷贝!简单地说,深拷贝对引用数据类型的成员变量的对象图中所有的对象都开辟了内存空间;而浅拷贝只是传递地址指向,新的对象并没有对引用数据类型创建内存空间。
深拷贝模型如图所示:可以看到所有的成员变量都进行了复制。
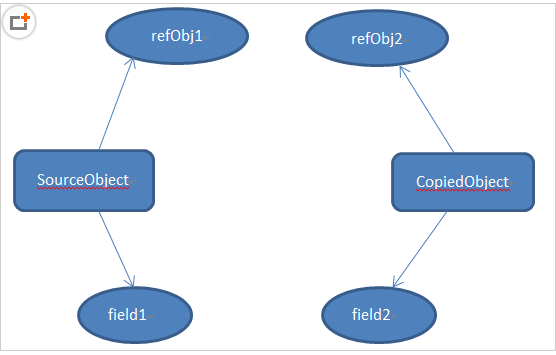
因为创建内存空间和拷贝整个对象图,所以深拷贝相比于浅拷贝速度较慢并且花销较大。
深拷贝的实现方法主要有两种:
1)通过重写clone方法来实现深拷贝
与通过重写clone方法实现浅拷贝的基本思路一样,只需要为对象图的每一层的每一个对象都实现Cloneable接口并重写clone方法,最后在最顶层的类的重写的clone方法中调用所有的clone方法即可实现深拷贝。简单的说就是:每一层的每个对象都进行浅拷贝=深拷贝。
参考代码如下:
package linearList;
/* 层次调用clone方法实现深拷贝 */
public class DeepCopy {
public static void main(String[] args) {
Age a=new Age(20);
Student stu1=new Student("摇头耶稣",a,175);
//通过调用重写后的clone方法进行浅拷贝
Student stu2=(Student)stu1.clone();
System.out.println(stu1.toString());
System.out.println(stu2.toString());
System.out.println();
//尝试修改stu1中的各属性,观察stu2的属性有没有变化
stu1.setName("大傻子");
//改变age这个引用类型的成员变量的值
a.setAge(99);
//stu1.setaAge(new Age(99)); 使用这种方式修改age属性值的话,stu2是不会跟着改变的。因为创建了一个新的Age类对象而不是改变原对象的实例值
stu1.setLength(216);
System.out.println(stu1.toString());
System.out.println(stu2.toString());
}
}
/** 创建年龄类*/
class Age implements Cloneable{
//年龄类的成员变量(属性)
private int age;
//构造方法
public Age(int age) {
this.age=age;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String toString() {
return this.age+"";
}
//重写Object的clone方法
public Object clone() {
Object obj=null;
try {
obj=super.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
return obj;
}
}
/** 创建学生类*/
class Student implements Cloneable{
//学生类的成员变量(属性),其中一个属性为类的对象
private String name;
private Age aage;
private int length;
//构造方法,其中一个参数为另一个类的对象
public Student(String name,Age a,int length) {
this.name=name;
this.aage=a;
this.length=length;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Age getaAge() {
return this.aage;
}
public void setaAge(Age age) {
this.aage=age;
}
public int getLength() {
return this.length;
}
public void setLength(int length) {
this.length=length;
}
public String toString() {
return "姓名是: "+this.getName()+", 年龄为: "+this.getaAge().toString()+", 长度是: "+this.getLength();
}
//重写Object类的clone方法
public Object clone() {
Object obj=null;
//调用Object类的clone方法——浅拷贝
try {
obj= super.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
//调用Age类的clone方法进行深拷贝
//先将obj转化为学生类实例Student stu=(Student)obj;
//学生类实例的Age对象属性,调用其clone方法进行拷贝stu.aage=(Age)stu.getaAge().clone();return obj;}
}
运行结果为:
- 姓名是: 摇头耶稣, 年龄为: 20, 长度是: 175
- 姓名是: 摇头耶稣, 年龄为: 20, 长度是: 175
- 姓名是: 大傻子, 年龄为: 99, 长度是: 216
- 姓名是: 摇头耶稣, 年龄为: 20, 长度是: 175
分析结果可以验证:进行了深拷贝之后,无论是什么类型的属性值的修改,都不会影响另一个对象的属性值。
2)通过对象序列化实现深拷贝
虽然层次调用clone方法可以实现深拷贝,但是显然代码量实在太大。特别对于属性数量比较多、层次比较深的类而言,每个类都要重写clone方法太过繁琐。将对象序列化为字节序列后,默认会将该对象的整个对象图进行序列化,再通过反序列即可完美地实现深拷贝。
参考代码如下:
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;/* 通过序列化实现深拷贝 */
public class DeepCopyBySerialization {
public static void main(String[] args) throws IOException, ClassNotFoundException {
Age a=new Age(20);
Student stu1=new Student("摇头耶稣",a,175);
//通过序列化方法实现深拷贝
ByteArrayOutputStream bos=new ByteArrayOutputStream();
ObjectOutputStream oos=new ObjectOutputStream(bos);
oos.writeObject(stu1);
oos.flush();
ObjectInputStream ois=new ObjectInputStream(new ByteArrayInputStream(bos.toByteArray()));
Student stu2=(Student)ois.readObject();
System.out.println(stu1.toString());
System.out.println(stu2.toString());
System.out.println();
//尝试修改stu1中的各属性,观察stu2的属性有没有变化stu1.setName("大傻子");
//改变age这个引用类型的成员变量的值
a.setAge(99);
stu1.setLength(216);
System.out.println(stu1.toString());
System.out.println(stu2.toString());
}
}
/** 创建年龄类*/
class Age implements Serializable{
//年龄类的成员变量(属性)
private int age;
//构造方法
public Age(int age) {
this.age=age;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String toString() {
return this.age+"";
}
}
/** 创建学生类*/
class Student implements Serializable{
//学生类的成员变量(属性),其中一个属性为类的对象
private String name;
private Age aage;
private int length;
//构造方法,其中一个参数为另一个类的对象
public Student(String name,Age a,int length) {
this.name=name;
this.aage=a;
this.length=length;
}
//eclipe中alt+shift+s自动添加所有的set和get方法
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Age getaAge() {
return this.aage;
}
public void setaAge(Age age) {
this.aage=age;
}
public int getLength() {
return this.length;
}
public void setLength(int length) {
this.length=length;
}
//设置输出的字符串形式
public String toString() {return "姓名是: "+this.getName()+", 年龄为: "+this.getaAge().toString()+", 长度是: "+this.getLength();}
}
运行结果为:
- 姓名是: 摇头耶稣, 年龄为: 20, 长度是: 175
- 姓名是: 摇头耶稣, 年龄为: 20, 长度是: 175
- 姓名是: 大傻子, 年龄为: 99, 长度是: 216
- 姓名是: 摇头耶稣, 年龄为: 20, 长度是: 175
可以通过很简洁的代码即可完美实现深拷贝。不过要注意的是,如果某个属性被transient修饰,那么该属性就无法被拷贝了。以上是浅拷贝的深拷贝的区别和实现方式。
19、多态的作用
多态的实现要有继承、重写,父类引用指向子类对象。它的好处是可以消除类型之间的耦合关系,增加类的可扩充性和灵活性。
20、什么是反射?
反射是通过获取类的class对象,然后动态的获取到这个类的内部结构,动态的去操作类的属性和方法。
应用场景有:要操作权限不够的类属性和方法时、实现自定义注解时、动态加载第三方jar包时、按需加载类,节省编译和初始化时间;
获取class对象的方法有:class.forName(类路径),类.class(),对象的getClass()
21、反射机制
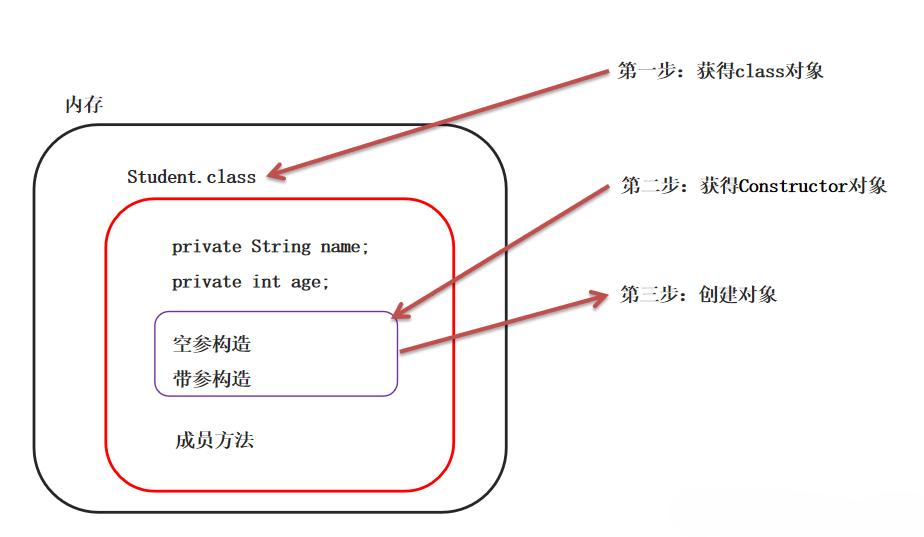
反射的原理(类加载)
类加载机制流程
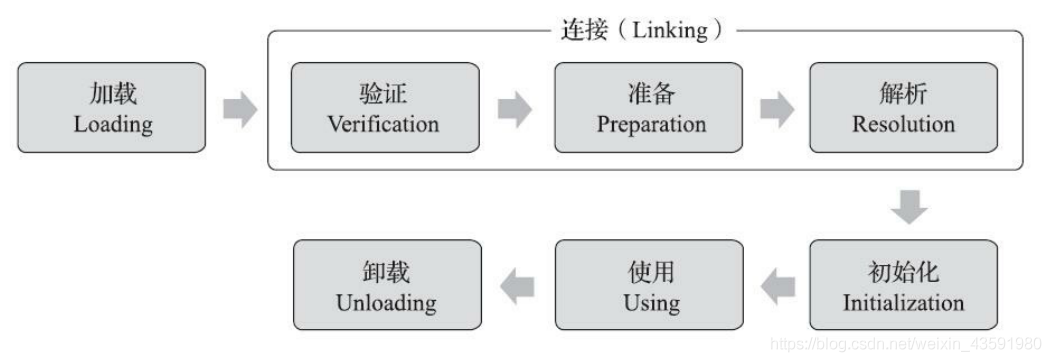
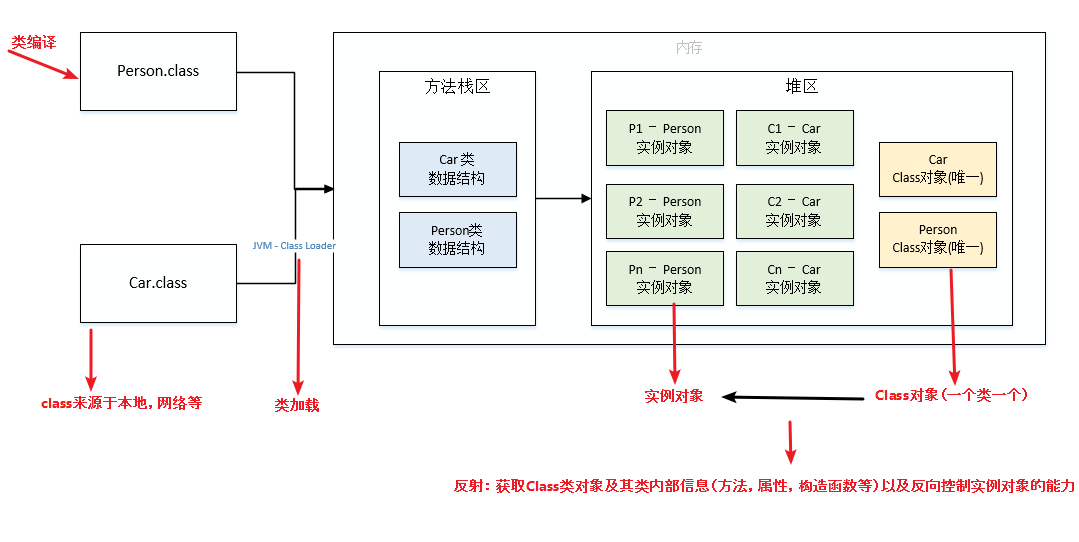
反射的原理图解

二. 反射的作用
一个类的成员包括以下三种:域信息、构造器信息、方法信息。
而反射则可以在运行时动态获取到这些信息,在使用反射时,我们常用的类有以下五种。
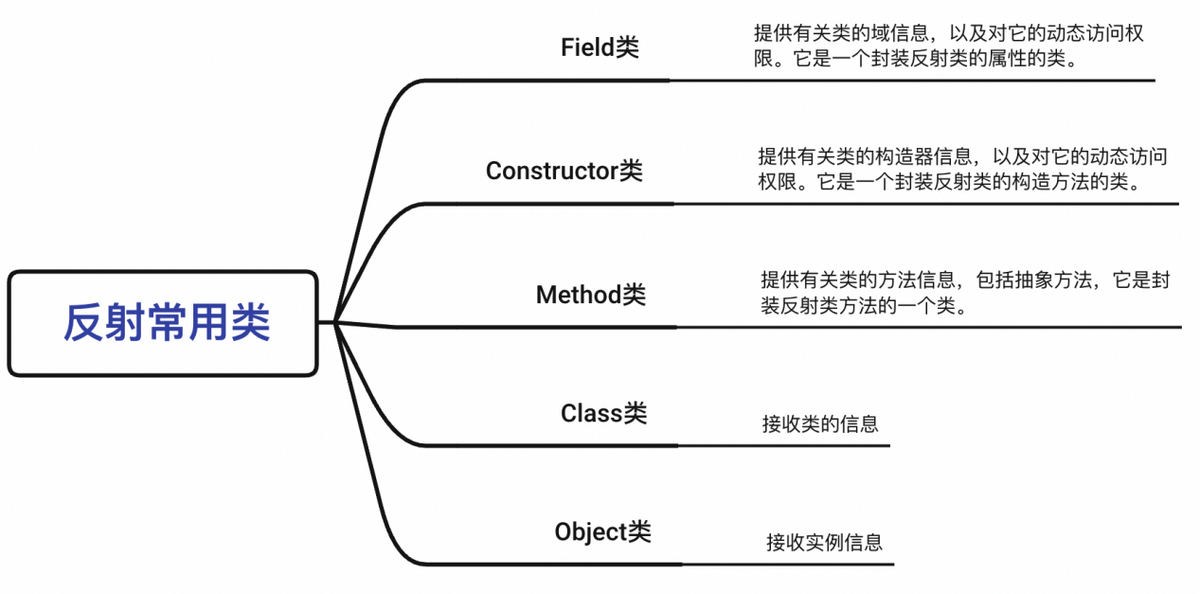
Class类对象的获取
1、获得Class:主要有三种方法:
(1)Object–>getClass
(2)任何数据类型(包括基本的数据类型)都有一个“静态”的class属性
(3)通过class类的静态方法:forName(String className)(最常用)
package fanshe;
public class Fanshe {
public static void main(String[] args) {
//第一种方式获取Class对象
Student stu1 = new Student();
//这一new 产生一个Student对象,一个Class对象。
Class stuClass = stu1.getClass();
//获取Class对象
System.out.println(stuClass.getName());
//第二种方式获取Class对象
Class stuClass2 = Student.class;
System.out.println(stuClass == stuClass2);
//判断第一种方式获取的Class对象和第二种方式获取的是否是同一个
//第三种方式获取Class对象
try {
Class stuClass3 = Class.forName("fanshe.Student");
//注意此字符串必须是真实路径,就是带包名的类路径,包名.类名
System.out.println(stuClass3 == stuClass2);
//判断三种方式是否获取的是同一个Class对象
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
注意,在运行期间,一个类,只有一个Class对象产生,所以打印结果都是true;
三种方式中,常用第三种,第一种对象都有了还要反射干什么,第二种需要导入类包,依赖太强,不导包就抛编译错误。一般都使用第三种,一个字符串可以传入也可以写在配置文件中等多种方法。
Class类的方法

getName、getCanonicalName与getSimpleName的区别:
- getSimpleName:只获取类名
- getName:类的全限定名,jvm中Class的表示,可以用于动态加载Class对象,例如Class.forName。
- getCanonicalName:返回更容易理解的表示,主要用于输出(toString)或log打印,大多数情况下和getName一样,但是在内部类、数组等类型的表示形式就不同了。
Constructor类及其获取对象方法
- Constructor提供了一个类的单个构造函数的信息和访问。
- Constructor允许在将实际参数与newInstance()与底层构造函数的形式参数进行匹配时进行扩展转换,但如果发生缩小转换,则抛出IllegalArgumentException 。
Constructor类的方法

获取Constructor对象是通过Class类中的方法获取的,Class类与Constructor相关的主要方法如下:

使用反射技术获取构造器对象并使用
@Testpublic void test2() throws NoSuchMethodException {
Class<Student> sc = Student.class;
// 1. 拿到所有的构造器
Constructor<?>[] constructors = sc.getDeclaredConstructors();
// 输出构造器的名称+参数个数
for (Constructor<?> constructor : constructors) {
System.out.println(constructor.getName() + " 参数个数:" + constructor.getParameterCount() + "个");
}
// 2. 拿到单个构造器
Constructor<Student> constructor = sc.getDeclaredConstructor(String.class, String.class);
System.out.println(constructor.getName() + "参数个数:" + constructor.getParameterCount());
}
使用反射技术获取构造器对象并使用获取到的内容创建出一个对象
反射得到构造器之后的作用仍是创建一个对象,如果说构造器是public,就可以直接new对象,如果说是构造器是私有的private,需要提前将构造器进行暴力反射,再进行构造对象。
反射是可以直接破换掉封装性的,私有的也是可以执行的

Field类及其用法
Field 提供有关类或接口的单个字段的信息,以及对它的动态访问权限。反射的字段可能是一个类(静态)字段或实例字段。
Field类涉及的get方法

同样的道理,我们可以通过Class类的提供的方法来获取代表字段信息的Field对象,Class类与Field对象相关方法如下:

下面的代码演示了上述方法的使用过程
public class ReflectField {
public static void main(String[] args) throws ClassNotFoundException, NoSuchFieldException {
Class<?> clazz = Class.forName("reflect.Student");
//获取指定字段名称的Field类,注意字段修饰符必须为public而且存在该字段,
// 否则抛NoSuchFieldException
Field field = clazz.getField("age");
System.out.println("field:" + field);
//获取所有修饰符为public的字段,包含父类字段,注意修饰符为public才会获取
Field fields[] = clazz.getFields();
for (Field f : fields) {
System.out.println("f:" + f.getDeclaringClass());
}
System.out.println("================getDeclaredFields====================");
//获取当前类所字段(包含private字段),注意不包含父类的字段
Field fields2[] = clazz.getDeclaredFields();
for (Field f : fields2) {
System.out.println("f2:" + f.getDeclaringClass());
}
//获取指定字段名称的Field类,可以是任意修饰符的自动,注意不包含父类的字段
Field field2 = clazz.getDeclaredField("desc");
System.out.println("field2:" + field2);
}
/**
输出结果:
field:public int reflect.Person.age
f:public java.lang.String reflect.Student.desc
f:public int reflect.Person.age
f:public java.lang.String reflect.Person.name
================getDeclaredFields====================
f2:public java.lang.String reflect.Student.desc
f2:private int reflect.Student.score
field2:public java.lang.String reflect.Student.desc
*/
}
class Person {
public int age;
public String name;
//省略set和get方法
}
class Student extends Person {
public String desc;
private int score;
//省略set和get方法
}
上述方法需要注意的是,如果我们不期望获取其父类的字段,则需使用Class类的
getDeclaredField/getDeclaredFields方法来获取字段即可,倘若需要连带获取到父类的字段,那么请使用Class类的getField/getFields,但是也只能获取到public修饰的的字段,无法获取父类的私有字段。下面将通过Field类本身的方法对指定类属性赋值,代码演示如下:
//获取Class对象引用
Class<?> clazz = Class.forName("reflect.Student");
Student st= (Student) clazz.newInstance();
//获取父类public字段并赋值
Field ageField = clazz.getField("age");
ageField.set(st,18);
Field nameField = clazz.getField("name");
nameField.set(st,"Lily");
//只获取当前类的字段,不获取父类的字段
Field descField = clazz.getDeclaredField("desc");
descField.set(st,"I am student");
Field scoreField = clazz.getDeclaredField("score");
//设置可访问,score是private的
scoreField.setAccessible(true);
scoreField.set(st,88);
System.out.println(st.toString());
//输出结果:Student{age=18, name='Lily ,desc='I am student', score=88}
//获取字段值System.out.println(scoreField.get(st));// 88
其中的set(Object obj, Object value)方法是Field类本身的方法,用于设置字段的值,而get(Object obj)则是获取字段的值,当然关于Field类还有其他常用的方法如下:
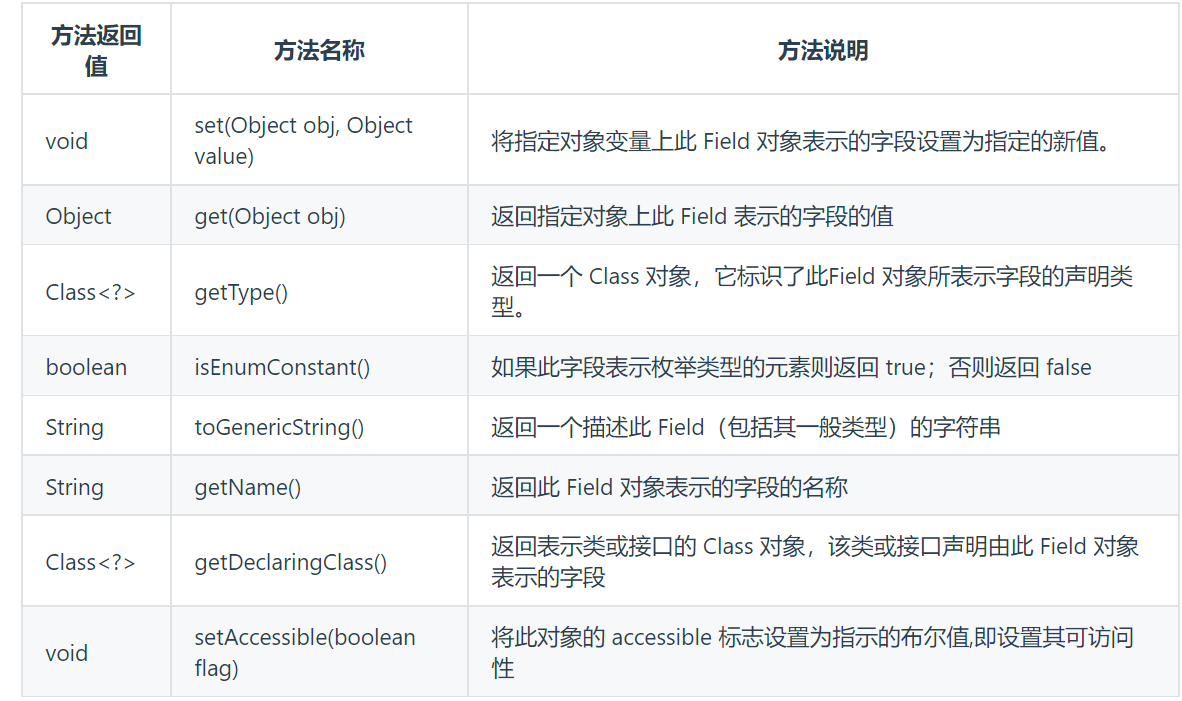
上述方法可能是较为常用的,事实上在设置值的方法上,Field类还提供了专门针对基本数据类型的方法,如setInt()/getInt()、setBoolean()/getBoolean、setChar()/getChar()等等方法,这里就不全部列出了,需要时查API文档即可。需要特别注意的是被final关键字修饰的Field字段是安全的,在运行时可以接收任何修改,但最终其实际值是不会发生改变的。
Method类及其用法
Method 提供关于类或接口上单独某个方法(以及如何访问该方法)的信息,所反映的方法可能是类方法或实例方法(包括抽象方法)。
Method类的主要方法

下面是Class类获取Method对象相关的方法:

同样通过案例演示上述方法:
import java.lang.reflect.Method;public class ReflectMethod {
public static void main(String[] args) throws ClassNotFoundException, NoSuchMethodException {
Class clazz = Class.forName("reflect.Circle");
//根据参数获取public的Method,包含继承自父类的方法
Method method = clazz.getMethod("draw", int.class, String.class);
System.out.println("method:" + method);
//获取所有public的方法:
Method[] methods = clazz.getMethods();
for (Method m : methods) {
System.out.println("m::" + m);
}
System.out.println("=========================================");
//获取当前类的方法包含private,该方法无法获取继承自父类的method
Method method1 = clazz.getDeclaredMethod("drawCircle");
System.out.println("method1::" + method1);
//获取当前类的所有方法包含private,该方法无法获取继承自父类的method
Method[] methods1 = clazz.getDeclaredMethods();
for (Method m : methods1) {
System.out.println("m1::" + m);
}
}
}
class Shape {
public void draw() {
System.out.println("draw");
}
public void draw(int count, String name) {
System.out.println("draw " + name + ",count=" + count);
}
}
class Circle extends Shape {
private void drawCircle() {
System.out.println("drawCircle");
}
public int getAllCount() {
return 100;
}
}
在通过getMethods方法获取Method对象时,会把父类的方法也获取到,如上的输出结果,把Object类的方法都打印出来了。而
getDeclaredMethod/getDeclaredMethods方法都只能获取当前类的方法。我们在使用时根据情况选择即可。下面将演示通过Method对象调用指定类的方法:
Class clazz = Class.forName("reflect.Circle");
//创建对象
Circle circle = (Circle) clazz.newInstance();
//获取指定参数的方法对象
MethodMethod method = clazz.getMethod("draw",int.class,String.class);
//通过Method对象的invoke(Object obj,Object... args)方法调用
method.invoke(circle,15,"圈圈");
//对私有无参方法的操作
Method method1 = clazz.getDeclaredMethod("drawCircle");
//修改私有方法的访问标识
method1.setAccessible(true);
method1.invoke(circle);
//对有返回值得方法操作
Method method2 =clazz.getDeclaredMethod("getAllCount");
Integer count = (Integer) method2.invoke(circle);
System.out.println("count:"+count);
输出结果
draw 圈圈,count=15
drawCircle
count:100
在上述代码中调用方法,使用了Method类的invoke(Object obj,Object... args)第一个参数代表调用的对象,第二个参数传递的调用方法的参数。这样就完成了类方法的动态调用。
三、反射机制执行的流程
执行流程图
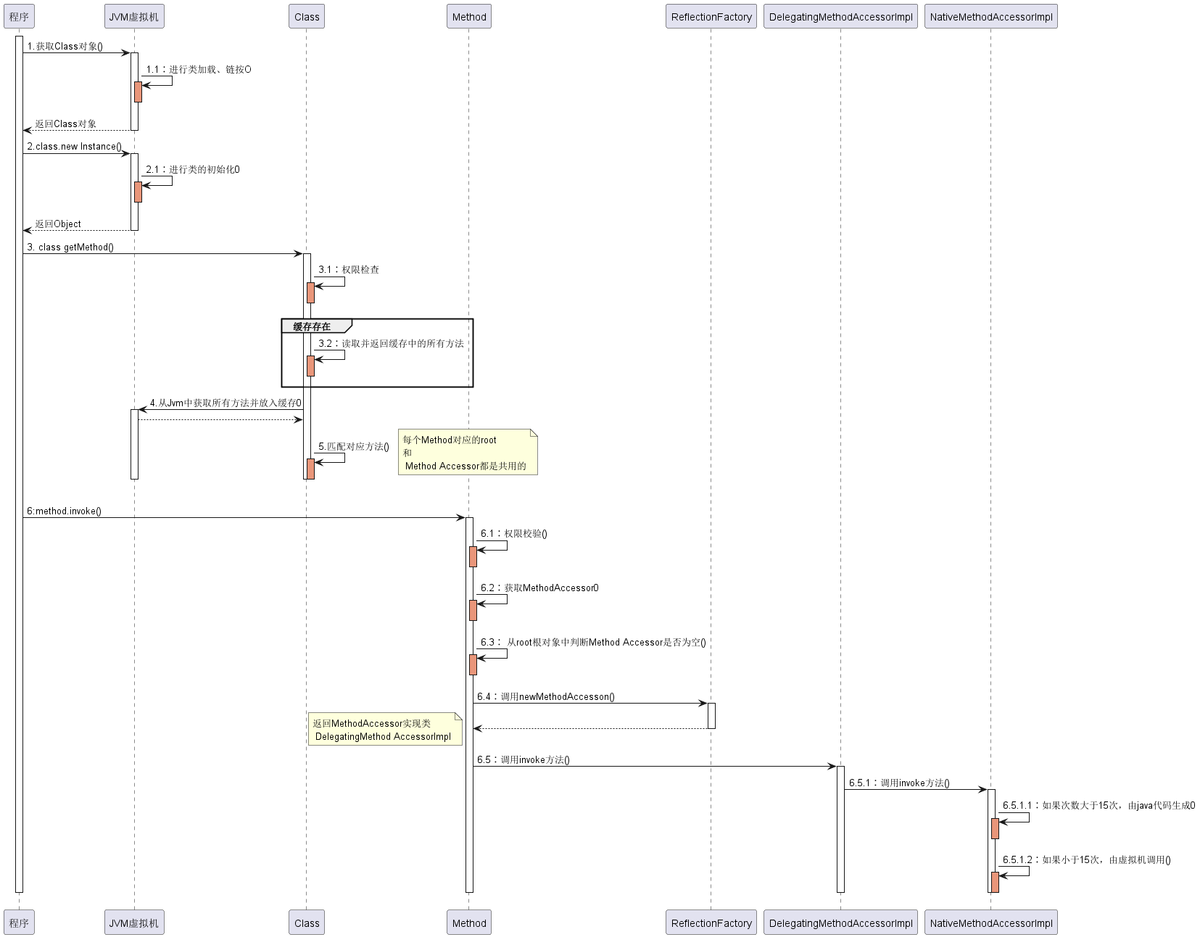
反射获取类实例
首先调用了 java.lang.Class 的静态方法,获取类信息。
@CallerSensitive
public static Class<?> forName(String className) throws ClassNotFoundException {
// 先通过反射,获取调用进来的类信息,从而获取当前的
classLoader Class<?> caller = Reflection.getCallerClass();
// 调用native方法进行获取class信息
return forName0(className, true, ClassLoader.getClassLoader(caller), caller);
}
forName()反射获取类信息,并没有将实现留给了java,而是交给了jvm去加载。
主要是先获取 ClassLoader, 然后调用 native 方法,获取信息,加载类则是回调 java.lang.ClassLoader.
最后,jvm又会回调 ClassLoader 进类加载。
// public Class<?> loadClass(String name) throws ClassNotFoundException { return loadClass(name, false); }
// sun.misc.Launcher
public Class<?> loadClass(String var1, boolean var2) throws ClassNotFoundException {
int var3 = var1.lastIndexOf(46);
if(var3 != -1) {
SecurityManager var4 = System.getSecurityManager();
if(var4 != null) {
var4.checkPackageAccess(var1.substring(0, var3));
}
}
if(this.ucp.knownToNotExist(var1)) {
Class var5 = this.findLoadedClass(var1);
if(var5 != null) {
if(var2) {
this.resolveClass(var5);
}
return var5;
} else {
throw new ClassNotFoundException(var1);
}
} else {
return super.loadClass(var1, var2);
}
}
// java.lang.ClassLoader
protected Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException {
// 先获取锁
synchronized (getClassLoadingLock(name)) {
// First, check if the class has already been loaded
// 如果已经加载了的话,就不用再加载了
Class<?> c = findLoadedClass(name);
if (c == null) {
long t0 = System.nanoTime();
try {
// 双亲委托加载
if (parent != null) {
c = parent.loadClass(name, false);
} else {
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
// 父类没有加载到时,再自己加载
if (c == null) {
// If still not found, then invoke findClass in order
// to find the class.
long t1 = System.nanoTime();
c = findClass(name);
// this is the defining class loader; record the stats
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
}
protected Object getClassLoadingLock(String className) {
Object lock = this;
if (parallelLockMap != null) {
// 使用 ConcurrentHashMap来保存锁
Object newLock = new Object();
lock = parallelLockMap.putIfAbsent(className, newLock);
if (lock == null) {
lock = newLock;
}
}
return lock;
}
protected final Class<?> findLoadedClass(String name) {
if (!checkName(name))return null;
return findLoadedClass0(name);
}
下面来看一下 newInstance() 的实现方式。
// 首先肯定是 Class.newInstance
@CallerSensitive
public T newInstance() throws InstantiationException, IllegalAccessException {
if (System.getSecurityManager() != null) {
checkMemberAccess(Member.PUBLIC, Reflection.getCallerClass(), false);
}
// NOTE: the following code may not be strictly correct under
// the current Java memory model.
// Constructor lookup
// newInstance() 其实相当于调用类的无参构造函数,所以,首先要找到其无参构造器
if (cachedConstructor == null) {
if (this == Class.class) {
// 不允许调用 Class 的 newInstance() 方法
throw new IllegalAccessException("Can not call newInstance() on the Class for java.lang.Class");
}
try {
// 获取无参构造器
Class<?>[] empty = {};
final Constructor<T> c = getConstructor0(empty, Member.DECLARED);
// Disable accessibility checks on the constructor
// since we have to do the security check here anyway
// (the stack depth is wrong for the Constructor's
// security check to work)
java.security.AccessController.doPrivileged(
new java.security.PrivilegedAction<Void>() {
public Void run() {
c.setAccessible(true);
return null;
}
});
cachedConstructor = c;
} catch (NoSuchMethodException e) {
throw (InstantiationException)
new InstantiationException(getName()).initCause(e);
}
}
Constructor<T> tmpConstructor = cachedConstructor;
// Security check (same as in java.lang.reflect.Constructor)
int modifiers = tmpConstructor.getModifiers();
if (!Reflection.quickCheckMemberAccess(this, modifiers)) {
Class<?> caller = Reflection.getCallerClass();
if (newInstanceCallerCache != caller) {
Reflection.ensureMemberAccess(caller, this, null, modifiers);
newInstanceCallerCache = caller;
}
}
// Run constructor
try {
// 调用无参构造器
return tmpConstructor.newInstance((Object[]) null);
} catch (InvocationTargetException e) {
Unsafe.getUnsafe().throwException(e.getTargetException());
// Not reached
return null;
}
}
newInstance() 主要做了三件事:
- 权限检测,如果不通过直接抛出异常;查找无参构造器,并将其缓存起来;调用具体方法的无参构造方法,生成实例并返回;
下面是获取构造器的过程:
private Constructor<T> getConstructor0(Class<?>[] parameterTypes, int which) throws NoSuchMethodException {
// 获取所有构造器
Constructor<T>[] constructors = privateGetDeclaredConstructors((which == Member.PUBLIC));
for (Constructor<T> constructor : constructors) {
if (arrayContentsEq(parameterTypes, constructor.getParameterTypes())) {
return getReflectionFactory().copyConstructor(constructor);
}
}
throw new NoSuchMethodException(getName() + ".<init>" + argumentTypesToString(parameterTypes));
}
getConstructor0() 为获取匹配的构造方器;分三步:
- 先获取所有的constructors, 然后通过进行参数类型比较;找到匹配后,通过 ReflectionFactory copy一份constructor返回;否则抛出 NoSuchMethodException;
返回构造器的实例后,可以根据外部进行进行类型转换,从而使用接口或方法进行调用实例功能了。
反射获取方法
- 第一步,先获取 Method;
// java.lang.Class
@CallerSensitive
public Method getDeclaredMethod(String name, Class<?>... parameterTypes) throws NoSuchMethodException, SecurityException {
checkMemberAccess(Member.DECLARED, Reflection.getCallerClass(), true);
Method method = searchMethods(privateGetDeclaredMethods(false), name, parameterTypes);
if (method == null) {
throw new NoSuchMethodException(getName() + "." + name + argumentTypesToString(parameterTypes));
}
return method;
}
... TODO 后续学习
反射调用流程小结
最后,用几句话总结反射的实现原理:
反射类及反射方法的获取,都是通过从列表中搜寻查找匹配的方法,所以查找性能会随类的大小方法多少而变化;
每个类都会有一个与之对应的Class实例,从而每个类都可以获取method反射方法,并作用到其他实例身上;
反射也是考虑了线程安全的,放心使用;
反射使用软引用relectionData缓存class信息,避免每次重新从jvm获取带来的开销;
反射调用多次生成新代理Accessor, 而通过字节码生存的则考虑了卸载功能,所以会使用独立的类加载器;
当找到需要的方法,都会copy一份出来,而不是使用原来的实例,从而保证数据隔离;
调度反射方法,最终是由jvm执行invoke0()执行
21、Java创建对象得五种方式?
1)new关键字 (2)Class.newInstance (3)Constructor.newInstance (4)Clone方法 (5)反序列化
22 、设计模式 单例模式
单例模式定义与特点
定义:
单例模式(Singleton)指一个类只有一个实例,并且该类能自行创建这个实例的一种模式。例如,Windows 中只能打开一个任务管理器,这样可以避免因打开多个任务管理器窗口而造成内存资源的浪费,或出现各个窗口显示内容的不一致等错误。
特点:
- 单例类只有一个实例对象;
- 该单例对象必须由单例类自行创建;
- 单例类对外提供一个访问该单例的全局访问点;
单例模式的两种模式
两种单例模式实现方式:饿汉式、懒汉式
1. 饿汉式
该模式的特点是类一旦加载就创建一个单例,保证在调用 getInstance 方法之前单例已经存在了。
package com.fs.singleton;
/**
* 饿汉模式
*/
public class HungrySingleton {
/**
* 私有实例,静态变量会在类加载的时候初始化,是线程安全的
*/
private static final HungrySingleton instance=new HungrySingleton();
/**
* 私有构造方法
*/
private HungrySingleton(){
System.out.println("private HungrySingleton()");
}
/**
* 唯一公开获取实例的方法(静态工厂方法)
*
* @return
*/
public static HungrySingleton getInstance() {
return instance;
}
public static void otherMethod(){
System.out.println("otherMethod()");
}
}
懒汉式
package com.fs.singleton;
/**
* 懒汉模式
*/
public class LazySingleton {
/**
* 私有实例
*/
private static LazySingleton instance=null;
/**
* 私有构造方法
*/
private LazySingleton(){
System.out.println("private LazySingleton()");
}
/**
* 唯一公开获取实例的方法(静态工厂方法),
*
* @return
*/
public static LazySingleton getInstance(){
if(instance==null){
instance=new LazySingleton();
}
return instance;
}
public static void otherMethod(){
System.out.println("otherMethod()");
}
}
单例模式的应用场景
在应用场景中,某类只要求生成一个对象的时候,比如一个班级生成一个班长。
当对象需要被共享的场合。由于单例模式只允许创建一个对象,共享该对象可以节省内存,并加快对象访问速度。如 Web 中的配置对象、数据库的连接池等。
当某类需要频繁实例化,而创建的对象又频繁被销毁的时候,如多线程的线程池、网络连接池等。
23、树、二叉树、红黑树、B+tree
24、map集合
1. 简介
Map集合是一种以键值对形式存储和操作数据的数据结构,建立了key-value之间的映射关系,常用于存储和处理复杂的数据。同时Map也是一种双列集合接口,它有多个实现类,包括HashMap、TreeMap、LinkedHashMap等,最常用的是HashMap类。其中,HashMap是按哈希算法来实现存取键对象的,这是我们开发时最常用的Map子类,而TreeMap类则可以对键对象进行排序。

Map集合中的每个元素,都包含了一个键(key)和一个值(value),key和value组成了键-值的映射表,我们称其为键值对。键用于唯一标识一个元素,值用于存储该元素的数据,一般情况下,这个key和value可以是任何引用类型的数据。其中,键key是无序、无下标、不重复的,最多只能有一个key为null。值value是无序、无下标、可重复的,可以有多个value为null。
并且这个key和value之间是单向的一对一关系,即通过指定的key,总能找到唯一的、确定的value。当我们想从Map中取出数据时,只要给出指定的key,就能取出对应的value。
2. 特点
根据上面我们对Map概念的讲解,把Map的主要特点给大家总结如下:
- Map和List不同,Map是一种双列集合;
- Map存储的是key-value的映射关系;
- Map不保证顺序。在遍历时,遍历的顺序不一定是put()时放入的key的顺序,也不一定是key的排序顺序。
3. 实现方式
在Java中,Map集合的实现方式主要有两种:基于哈希表和基于树结构。接下来给大家简单介绍一下基于这两种结构的Map集合。
3.1 基于哈希表的Map集合
基于哈希表的Map,其底层是基于哈希表作为数据结构的集合,主要的实现类是HashMap。在HashMap中,每个元素都包含一个键和一个值。当我们在添加元素时,HashMap会根据键的哈希值计算出对应的桶(Bucket),并将元素存储到该桶中。如果不同的键具有相同的哈希值,就会出现哈希冲突,此时HashMap会使用链表或红黑树等数据结构来解决冲突。基于哈希表的Map集合具有快速的添加、删除和查找元素的特点,但元素的顺序是不确定的。
3.2 基于树结构的Map集合
基于树结构的Map集合,其底层是基于红黑树作为数据结构的集合,主要的实现类是TreeMap。在TreeMap中,每个元素也都包含一个键和一个值。我们在添加元素时,TreeMap会根据键的比较结果,将元素存储到正确的位置上,使得元素可以按照键的升序或降序排列。基于树结构的Map集合,具有快速查找和遍历元素的特点,但添加和删除元素的速度较慢。
4. 常用方法
Map集合的使用和其他集合类似,主要包括添加、删除、获取、遍历元素等操作。当我们调用put(K key, V value)方法时,会把key和value进行映射并放入Map。当调用V get(K key)时,可以通过key获取到对应的value;如果key不存在,则返回null。如果我们只是想查询某个key是否存在,可以调用containsKey(K key)方法。另外我们也可以通过 Map提供的keySet()方法,获取所有key组成的集合,进而遍历Map中所有的key-value对。
下表中就是Map里的一些常用方法,大家可以记一下,这些方法在Map的各实现子类中也都存在。

5. 常用实现类
Java中有多个Map接口的实现类,接下来就给大家逐一简单介绍一下

5.1 HashMap
HashMap是Java中最常用的Map集合实现类,它基于哈希表实现,具有快速查找键值对的优点。HashMap的存储方式是无序的,也就是说,遍历HashMap集合时,得到的键值对顺序是不确定的。下面是创建HashMap集合的代码示例:
HashMap<String, Object> map = new HashMap<>();
5.2 TreeMap
TreeMap是Java中另一个常用的Map集合实现类,它基于红黑树实现,具有自动排序键值对的优点。TreeMap的存储方式是有序的,也就是说,遍历TreeMap集合时得到的键值对,是按照键的自然顺序或指定比较器的顺序排序的。下面是创建TreeMap集合的代码示例
Map<String, Integer> treeMap = new TreeMap<>();
5.3 LinkedHashMap
LinkedHashMap是Java中另一个Map集合实现类,它继承自HashMap,并保持了插入顺序。也就是说,遍历LinkedHashMap集合时,得到的键值对的顺序是按照插入顺序排序的。下面是创建LinkedHashMap集合的代码示例:

5.4 Hashtable
Hashtable是Java中另一个Map集合实现类,它与HashMap非常相似,但Hashtable是线程安全的。Hashtable的存储方式是无序的,也就是说,遍历Hashtable集合时,得到的键值对的顺序是不确定的。下面是创建Hashtable集合的代码示例

5.5 ConcurrentHashMap
ConcurrentHashMap是Java中的另一个Map集合实现类,它与Hashtable非常相似,但是ConcurrentHashMap是线程安全的,并且性能更高。ConcurrentHashMap的存储方式是无序的,也就是说,遍历ConcurrentHashMap集合时,得到的键值对的顺序是不确定的。下面是创建ConcurrentHashMap集合的代码示例:

需要注意的是,虽然ConcurrentHashMap是线程安全的,但仍然需要注意多线程环境下的并发问题。
6.线程安全:
使用Hashtable
使用Collections.synchronizedMap(new Hashtable())
使用ConcurrentHashMap
二、Java多线程篇
线程的返回值
1.进程和线程的区别,进程间如何通信
进程:系统运行的基本单位,进程在运行过程中都是相互独立,但是线程之间运行可以相互影响。
线程:独立运行的最小单位,一个进程包含多个线程且它们共享同一进程内的系统资源
进程间通过管道、 共享内存、信号量机制、消息队列通信
2. 什么是线程上下文切换
当一个线程被剥夺cpu使用权时,切换到另外一个线程执行
3.什么是死锁
死锁指多个线程在执行过程中,因争夺资源造成的一种相互等待的僵局
4.死锁的必要条件
互斥条件:同一资源同时只能由一个线程读取
不可抢占条件:不能强行剥夺线程占有的资源
请求和保持条件:请求其他资源的同时对自己手中的资源保持不放
循环等待条件:在相互等待资源的过程中,形成一个闭环
想要预防死锁,只需要破坏其中一个条件即可,比如使用定时锁、尽量让线程用相同的加锁顺序,还可以用银行家算法可以预防死锁
5.Synchrpnized和lock的区别
(1)synchronized是关键字,lock是一个类
(2) synchronized在发生异常时会自动释放锁,lock需要手动释放锁
(3)synchronized是可重入锁、非公平锁、不可中断锁,lock的ReentrantLock是可重入锁,可中断锁,可以是公平锁也可以是非公平锁
(4)synchronized是JVM层次通过监视器实现的,Lock是通过AQS实现的
6.什么是AQS锁?
AQS是一个抽象类,可以用来构造锁和同步类,如ReentrantLock,Semaphore,CountDownLatch,CyclicBarrier。
AQS的原理是,AQS内部有三个核心组件,一个是state代表加锁状态初始值为0,一个是获取到锁的线程,还有一个阻塞队列。当有线程想获取锁时,会以CAS的形式将state变为1,CAS成功后便将加锁线程设为自己。当其他线程来竞争锁时会判断state是不是0,不是0再判断加锁线程是不是自己,不是的话就把自己放入阻塞队列。这个阻塞队列是用双向链表实现的
可重入锁的原理就是每次加锁时判断一下加锁线程是不是自己,是的话state+1,释放锁的时候就将state-1。当state减到0的时候就去唤醒阻塞队列的第一个线程。
7.为什么AQS使用的双向链表?
因为有一些线程可能发生中断 ,而发生中断时候就需要在同步阻塞队列中删除掉,这个时候用双向链表方便删除掉中间的节点
8.有哪些常见的AQS锁
AQS分为独占锁和共享锁
ReentrantLock(独占锁):可重入,可中断,可以是公平锁也可以是非公平锁,非公平锁就是会通过两次CAS去抢占锁,公平锁会按队列顺序排队
Semaphore(信号量):设定一个信号量,当调用acquire()时判断是否还有信号,有就获取一个信号量,没有就阻塞等待其他线程释放信号量,当调用release()时释放一个信号量,唤醒阻塞线程。
应用场景:允许多个线程访问某个临界资源时,如上下车,买卖票
CountDownLatch(倒计数器):给计数器设置一个初始值,当调用CountDown()时计数器减一,当调用await() 时判断计数器是否归0,不为0就阻塞,直到计数器为0。
应用场景:启动一个服务时,主线程需要等待多个组件加载完毕,之后再继续执行
CyclicBarrier(循环栅栏):给计数器设置一个目标值,当调用await() 时会计数+1并判断计数器是否达到目标值,未达到就阻塞,直到计数器达到目标值
应用场景:多线程计算数据,最后合并计算结果的应用场景
9.sleep()和wait()的区别
(1)wait()是Object的方法,sleep()是Thread类的方法
(2)wait()会释放锁,sleep()不会释放锁
(3)wait()要在同步方法或者同步代码块中执行,sleep()没有限制
(4)wait()要调用notify()或notifyall()唤醒,sleep()自动唤醒
10.yield()和join()区别
join和yield的区别是:
yield()方法是暂停当前正在执行的线程对象,并执行其他线程。
jion()方法:线程实例的join()方法可以使得一个线程在另一个线程结束后再执行,即也就是说使得当前线程可以阻塞其他线程执行。
yield()方法
暂停当前正在执行的线程对象,并执行其他线程。理论上,yield意味着放手,放弃,投降。一个调用yield()方法的线程告诉虚拟机它乐意让其他线程占用自己的位置。这表明该线程没有在做一些紧急的事情。注意,这仅是一个暗示,并不能保证不会产生任何影响。
yield()应该做的是让当前运行线程回到可运行状态,以允许具有相同优先级的其他线程获得运行机会。因此,使用yield()的目的是让相同优先级的线程之间能适当的轮转执行。但是,实际中无法保证yield()达到让步目的,因为让步的线程还有可能被线程调度程序再次选中。
结论:yield()从未导致线程转到等待/睡眠/阻塞状态。在大多数情况下,yield()将导致线程从运行状态转到可运行状态,但有可能没有效果。
jion()方法
线程实例的join()方法可以使得一个线程在另一个线程结束后再执行,即也就是说使得当前线程可以阻塞其他线程执行;
thread.Join把指定的线程加入到当前线程,可以将两个交替执行的线程合并为顺序执行的线程。
比如在线程B中调用了线程A的Join()方法,直到线程A执行完毕后,才会继续执行线程B。
线程实例的join()方法可以使得一个线程在另一个线程结束后再执行。如果join()方法在一个线程实例上调用,当前运行着的线程将阻塞直到这个线程实例完成了执行。例如下面代码所示,t将阻塞t1知道t执行完毕后在执行t1;
在join()方法内可以设定超时,使得join()方法在超时后无效。当超时时,主方法和任务线程申请运行的时候是平等的。然而,当涉及sleep时,join()方法依靠操作系统计,所以你不应该假定join()方法将会等待你指定的时间。
像sleep,join通过抛出InterruptedException对中断做出回应。
11.线程池七大参数
核心线程数:线程池中的基本线程数量
最大线程数:当阻塞队列满了之后,逐一启动
最大线程的存活时间:当阻塞队列的任务执行完后,最大线长的回收时间
最大线程的存活时间单位
阻塞队列:当核心线程满后,后面来的任务都进入阻塞队列
线程工厂:用于生产线程
任务拒绝策略:阻塞队列满后,拒绝任务,有四种策略(1)抛异常(2)丢弃任务不抛异常(3)打回任务(4)尝试与最老的线程竞争

public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
关键参数:
- 核心线程数corePoolSize,也就是即使线程数小于核心线程数也不会回收。除非设置了allowCoreThreadTimeOut
- 最大线程数maximumPoolSize,也就是可以容纳的最大线程数量包括核心线程和非核心线程。非核心线程空闲的时候会被回收。
- 最大存活时间keepAliveTime,非核心线程超过该时间是闲置的就回收该线程。
- 时间单位
- 任务队列workQueue, 线程池中维护了一个任务队列 , 线程池启动后 , 会不停的从任务队列中取出任务 , 如果有新任务 , 执行如下操作 ;
如果线程数小于核心线程数 ( CoreSize ) , 那么创建核心线程 , 执行上述任务 ;
如果 线程数 大于核心线程数 ( CoreSize ) , 小于最大线程数 ( MaxSize ) , 那么创建非核心线程 , 执行上述任务 ;
如果 线程数 超过 最大线程数 ( MaxSize )
如果 任务队列没满 , 则将任务放入任务队列 ;
如果 任务队列满了 , 则抛出异常 ; 这里一般情况下需要手动处理这种情况 , 任务拒绝后 , 处理善后 - 线程工厂,控制如何产生线程。
- 拒绝策略RejectedExecutionHandler,若线程池中的核心线程数被用完且阻塞队列已排满,则此时线程池的资源已耗尽,线程池将没有足够的线程资源执行新的任务。为了保证操作系统的安全,线程池将通过拒绝策略处理新添加的线程任务。
12.Java内存模型
主内存与工作内存
Java内存模型规定了所有的变量都存储在主内存(Main Memory)中(此处的主内存与介绍物理硬件时的主内存名字一样,两者也可以互相类比,但此处仅是虚拟机内存的一部分)。每条线程还有自己的工作内存(Working Memory,可与前面讲的处理器高速缓存类比),线程的工作内存中保存了被该线程使用到的变量的主内存副本拷贝,线程对变量的所有操作(读取、赋值等)都必须在工作内存中进行,而不能直接读写主内存中的变量。不同的线程之间也无法直接访问对方工作内存中的变量,线程间变量值的传递均需要通过主内存来完成。线程、主内存、工作内存三者的交互关系如图所示:
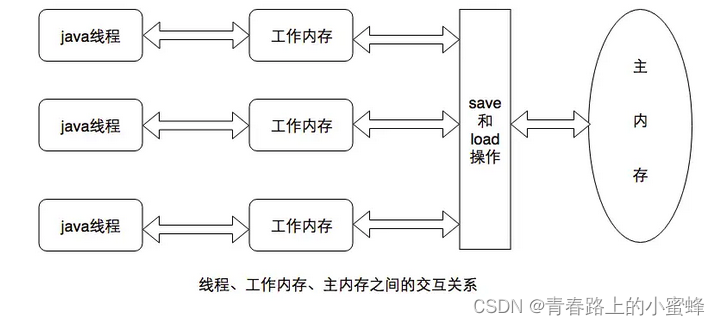
内存间交互操作
关于主内存与工作内存之间具体的交互协议,即一个变量如何从主内存拷贝到工作内存、如何从工作内存同步回主内存的实现细节,Java内存模型规定了以下8种操作来完成,虚拟机实现时必须保证下面提及的每一种操作都是原子的、不可再分的(对于double和long类型的变量来说,load、store、read和write操作在某些平台上允许有例外)
- lock(锁定):作用于主内存中的变量,一个变量在同一时间只能一个线程独占,该操作表示这条线程独占这个变量。
- unlock(解锁):作用于主内存的变量,表示这个变量的状态由处于锁定状态被释放,这样其他线程能对该变量进行锁定。
- read(读取):作用于主内存变量,表示把一个主内存变量的值传输到线程的工作内存,以便随后的load操作使用。
- load(载入):作用于线程的工作内存的变量,表示把read操作从主内存中读取的变量的值放到工作内存的副本中(副本相对于主内存的变量而言的)
- use(使用):作用于线程的工作内存的变量,表示把工作内存中的一个变量的值传递给执行引擎,每当虚拟机遇到一个需要使用变量的值的字节码指令时就会执行该操作
- assign(赋值):作用于线程的工作内存中的变量,表示把执行引擎返回的结果赋值给工作内存中的变量,每当虚拟机遇到一个给变量赋值的字节码指令时就会执行该操作
- store(存储):作用于线程的工作内存中的变量,把工作内存中的一个变量的值传递给主内存,以便随后的write操作使用
- write(写入):作用于主内存中的变量,把store操作从工作内存中得到的变量的值放入到主内存的变量中
注意:如果要把一个变量从主内存复制到工作内存,那就要顺序地执行read和load操作,如果要把变量从工作内存同步回主内存,就要顺序地执行store和write操作。注意,Java内存模型只要求上述两个操作必须按顺序执行,而没有保证是连续执行。也就是说,read与load之间,store与write之间是可以插入其他指令的,如对内存中的变量a、b进行访问时,一种可能出现的顺序是read a、read b、load a、loadb。
除此之外,Java内存模型还规定了在执行上述8种操作时必须满足如下规则:
- 不允许read和load、store和write操作之一单独出现,即不允许一个变量从主内存读取了但工作内存不接受,或者从工作内存发起回写了但主内存不接受的情况出现。
- 不允许一个线程丢弃它的最近的assign操作,即变量在工作内存中改变了之后必须把该变化同步回主内存
- 不允许一个线程回写没有修改的变量到主内存,即不允许一个线程无原因地(没有发生过任何assign操作)把数据从线程的工作内存同步回主内存中。
- 变量只能在主内存中产生,即不允许在工作内存中直接使用一个未被初始化(load或assign)的变量,换句话说,就是对一个变量实施use、store操作之前,必须先执行过了assign和load操作。
- 一个变量在同一时刻只能被一个线程对其进行lock操作,也就是说一个线程一旦对一个变量加锁后,在该线程没有释放掉锁之前,其他线程是不能对其加锁的,但是同一个线程对一个变量加锁后,可以继续加锁,同时在释放锁的时候释放锁的次数必须和加锁次数相同。
- 对变量执行lock操作,就会清空工作空间该变量的值,执行引擎使用这个变量之前,需要重新load或assign操作初始化变量的值
- 不允许对没有lock的变量执行unlock操作,如果一个变量没有被lock操作,那也不能对其执行unlock操作,当然一个线程也不能对被其他线程lock的变量执行unlock操作
- 对一个变量执行unlock之前,必须先把变量同步回主内存中,也就是执行store和write操作。
13.保证并发安全的三大特性?
原子性:一次或多次操作在执行期间不被其他线程影响
可见性:当一个线程在工作内存修改了变量,其他线程能立刻知道
有序性:JVM对指令的优化会让指令执行顺序改变,有序性是禁止指令重排
14.volatile
保证变量的可见性和有序性,不保证原子性。使用了 volatile 修饰变量后,在变量修改后会立即同步到主存中,每次用这个变量前会从主存刷新。
单例模式双重校验锁变量为什么使用 volatile 修饰? 禁止 JVM 指令重排序,new Object()分为三个步骤:为实例对象分配内存,用构造器初始化成员变量,将实例对象引用指向分配的内存;实例对象在分配内存后实才不为null。如果分配内存后还未初始化就先将实例对象指向了内存,那么此时最外层的if会判断实例对象已经不等于null就直接将实例对象返回。而此时初始化还没有完成。
15.线程使用方式
(1)继承 Tread 类
(2)实现 Runnable 接口
(3)实现 Callable 接口:带有返回值
(4)线程池创建线程
16.ThreadLocal原理
原理是为每个线程创建变量副本,不同线程之间不可见,保证线程安全。每个线程内部都维护了一个Map,key为threadLocal实例,value为要保存的副本。
但是使用ThreadLocal会存在内存泄露问题,因为key为弱引用,而value为强引用,每次gc时key都会回收,而value不会被回收。所以为了解决内存泄漏问题,可以在每次使用完后删除value或者使用static修饰ThreadLocal,可以随时获取value
17.什么是CAS锁
CAS锁可以保证原子性,思想是更新内存时会判断内存值是否被别人修改过,如果没有就直接更新。如果被修改,就重新获取值,直到更新完成为止。这样的缺点是
(1)只能支持一个变量的原子操作,不能保证整个代码块的原子操作
(2)CAS频繁失败导致CPU开销大
(3)ABS问题:线程1和线程2同时去修改一个变量,将值从A改为B,但线程1突然阻塞,此时线程2将A改为B,然后线程3又将B改成A,此时线程1将A又改为B,这个过程线程2是不知道的,这就是ABA问题,可以通过版本号或时间戳解决
18、CAS和AQS的区别
- CAS(Compare and Swap),中文为比较并交换,是一种实现并发算法的原语。而AQS(AbstractQueuedSynchronizer)是一种基于CAS的同步工具,通过将共享资源封装在AQS上,避免了用户直接使用CAS的复杂性。因此,CAS与AQS的主要区别就在于是否封装了共享资源。
- CAS面向的是共享变量的原子性操作,而AQS面向的是独占锁和共享锁。通过AQS的实现,可以方便地对锁进行控制,实现线程的同步和互斥访问。
19.Synchronized锁原理和优化
Synchronize是通过对象头的markwordk来表明监视器的,监视器本质是依赖操作系统的互斥锁实现的。操作系统实现线程切换要从用户态切换为核心态,成本很高,此时这种锁叫重量级锁,在JDK1.6以后引入了偏向锁、轻量级锁、重量级锁
偏向锁:当一段代码没有别的线程访问,此时线程去访问会直接获取偏向锁
轻量级锁:当锁是偏向锁时,有另外一个线程来访问,会升级为轻量级锁。线程会通过CAS方式获取锁,不会阻塞,提高性能,
重量级锁:轻量级锁自旋一段时间后线程还没有获取到锁,会升级为重量级锁,重量级锁时,来竞争锁的所有线程都会阻塞,性能降低
注意,锁只能升级不能降级
20.如何根据 CPU 核心数设计线程池线程数量
IO 密集型:线程中十分消耗Io的线程数*2
CPU密集型: cpu线程数量
21.AtomicInteger的使用场景
AtomicInteger是一个提供原子操作的Integer类,使用CAS+volatile实来现线程安全的数值操作。
因为volatile禁止了jvm的排序优化,所以它不适合在并发量小的时候使用,只适合在一些高并发程序中使用
三、JVM篇
1 、JVM运行时数据区(内存结构)
线程私有区:
(1)虚拟机栈:每次调用方法都会在虚拟机栈中产生一个栈帧,每个栈帧中都有方法的参数、局部变量、方法出口等信息,方法执行完毕后释放栈帧
(2)本地方法栈:为native修饰的本地方法提供的空间,在HotSpot中与虚拟机合二为一
(3)程序计数器:保存指令执行的地址,方便线程切回后能继续执行代码
线程共享区:
(4)堆内存:Jvm进行垃圾回收的主要区域,存放对象信息,分为新生代和老年代,内存比例为1:2,新生代的Eden区内存不够时时发生MinorGC,老年代内存不够时发生FullGC
(5)方法区:存放类信息、静态变量、常量、运行时常量池等信息。JDK1.8之前用持久代实现,JDK1.8后用元空间实现,元空间使用的是本地内存,而非在JVM内存结构中
2、JMM(Java内存模型 )
JMM(Java内存模型 )屏蔽了各种硬件和操作系统的内存访问差异,实现让Java程序在各平台下都能达到一致的内存访问效果,它定义了JVM如何将程序中的变量在主存中读取
具体定义为:所有变量都存在主存中,主存是线程共享区域;每个线程都有自己独有的工作内存,线程想要操作变量必须从主从中copy变量到自己的工作区,每个线程的工作内存是相互隔离的
由于主存与工作内存之间有读写延迟,且读写不是原子性操作,所以会有线程安全问题
Java虚拟机在运行Java程序时,会管理着一块内存区域:运行时数据区
在运行时数据区里,会根据用途进行划分:
Java虚拟机栈(栈区)
本地方法栈
Java堆(堆区)
方法区
程序计数器
下面,我将详细介绍每个内存模型分区
1 、Java堆

2、Java虚拟机栈

3、本地方法栈
简介:十分类似Java虚拟机栈,与Java虚拟机区别在于:服务对象,即Java虚拟机栈为执行 Java 方法服务;本地方法栈为执行 Native方法服务
4、方法区
 注:其内部包含一个运行时常量池,具体介绍如下:
注:其内部包含一个运行时常量池,具体介绍如下:

6、程序计数器

7、额外知识:直接内存
定义:NIO类(JDK1.4引入)中基于通道和缓冲区的I/O方式 通过使用Native函数库 直接分配 的堆外内存
特点:不受堆大小限制
不属于虚拟机运行时数据区的一部分 & 不在堆中分配
应用场景:适用于频繁调用的场景
通过一个 存储在Java堆中的DirectByteBuffer对象 作为这块内存的引用 进行操作,从而避免在 Java 堆和 Native堆之间来回复制数据,提高使用性能
抛出的异常:OutOfMemoryError,即与其他内存区域的总和 大于 物理内存限制
8、总结
本文全面讲解JVM中的内存模型 & 分区,总结如下

3、什么情况下会内存溢出?
堆内存溢出:(1)当对象一直创建而不被回收时(2)加载的类越来越多时(3)虚拟机栈的线程越来越多时
栈溢出:方法调用次数过多,一般是递归不当造成
4、JVM有哪些垃圾回收算法?
(1)标记清除算法: 标记不需要回收的对象,然后清除没有标记的对象,会造成许多内存碎片。
(2)复制算法: 将内存分为两块,只使用一块,进行垃圾回收时,先将存活的对象复制到另一块区域,然后清空之前的区域。用在新生代
(3)标记整理算法: 与标记清除算法类似,但是在标记之后,将存活对象向一端移动,然后清除边界外的垃圾对象。用在老年代
5.GC如何判断对象可以被回收?
(1)引用计数法:已淘汰,为每个对象添加引用计数器,引用为0时判定可以回收,会有两个对象相互引用无法回收的问题
(2)可达性分析法:从GCRoot开始往下搜索,搜索过的路径称为引用链,若一个对象GCRoot没有任何的引用链,则判定可以回收
GCRoot有:虚拟机栈中引用的对象,方法区中静态变量引用的对象,本地方法栈中引用的对象
6、典型垃圾回收器
CMS:以最小的停顿时间为目标、只运行在老年代的垃圾回收器,使用标记-清除算法,可以并发收集。
G1 :JDK1.9以后的默认垃圾回收器,注重响应速度,支持并发,采用标记整理+复制算法回收内存,使用可达性分析法来判断对象是否可以被回收。
7、类加载器和双亲委派机制
从父类加载器到子类加载器分别为:
BootStrapClassLoader 加载路径为:JAVA_HOME/jre/lib
ExtensionClassLoader 加载路径为:JAVA_HOME/jre/lib/ext
ApplicationClassLoader 加载路径为:classpath
还有一个自定义类加载器
当一个类加载器收到类加载请求时,会先把这个请求交给父类加载器处理,若父类加载器找不到该类,再由自己去寻找。该机制可以避免类被重复加载,还可以避免系统级别的类被篡改
8、JVM中有哪些引用?
强引用:new的对象。哪怕内存溢出也不会回收
软引用:只有内存不足时才会回收
弱引用:每次垃圾回收都会回收
虚引用:必须配合引用队列使用,一般用于追踪垃圾回收动作
9、类加载过程
(1)加载 :把字节码通过二进制的方式转化到方法区中的运行数据区
(2)连接:
验证:验证字节码文件的正确性。
准备:正式为类变量在方法区中分配内存,并设置初始值,final类型的变量在编译时已经赋值了
解析:将常量池中的符号引用(如类的全限定名)解析为直接引用(类在实际内存中的地址)
(3)初始化 :执行类构造器(不是常规的构造方法),为静态变量赋初值并初始化静态代码块。
10、JVM类初始化顺序
父类静态代码块和静态成员变量
-->子类静态代码块和静态成员变量
-->父类代码块和普通成员变量
-->父类构造方法
-->子类代码块和普成员变量
-->子类构造方法
11、对象的创建过程
(1)检查类是否已被加载,没有加载就先加载类
(2)为对象在堆中分配内存,使用CAS方式分配,防止在为A分配内存时,执行当前地址的指针还没有来得及修改,对象B就拿来分配内存。
(3)初始化,将对象中的属性都分配0值或null
(4)设置对象头
(5)为属性赋值和执行构造方法
12、对象头中有哪些信息
对象头中有两部分,一部分是MarkWork,存储对象运行时的数据,如对象的hashcode、GC分代年龄、GC标记、锁的状态、获取到锁的线程ID等;另外一部分是表明对象所属类,如果是数组,还有一个部分存放数组长度
13、JVM内存参数
-Xmx[]:堆空间最大内存
-Xms[]:堆空间最小内存,一般设置成跟堆空间最大内存一样的
-Xmn[]:新生代的最大内存
-xx:[survivorRatio=3]:eden区与from+to区的比例为3:1,默认为4:1
-xx[use 垃圾回收器名称]:指定垃圾回收器
-xss:设置单个线程栈大小
一般设堆空间为最大可用物理地址的百分之80
14、GC的回收机制和原理
GC的目的实现内存的自动释放,使用可达性分析法判断对象是否可回收,采用了分代回收思想,
将堆分为新生代、老年代,新生代中采用复制算法,老年代采用整理算法,当新生代内存不足时会发生minorGC,老年代不足时会发送fullGC
四、Mysql篇
1、MyIsAm和InnoDB的区别
InnoDB有三大特性,分别是事务、外键、行级锁,这些都是MyIsAm不支持的,
另外InnoDB是聚簇索引,MyIAm是非聚簇索引,
InnoDB不支持全文索引,MyIAm支持
InnoDB支持自增和MVCC模式的读写,MyIAm不支持
MyIsAM的访问速度一般InnoDB快,差异在于innodb的mvcc、行锁会比较消耗性能,还可能有回表的过程(先去辅助索引中查询数据,找到数据对应的key之后,再通过key回表到聚簇索引树查找数据)
2、mysql事务特性
原子性:一个事务内的操作统一成功或失败
一致性:事务前后的数据总量不变
隔离性:事务与事务之间相互不影响
持久性:事务一旦提交发生的改变不可逆
3、事务靠什么保证
原子性:由undolog日志保证,他记录了需要回滚的日志信息,回滚时撤销已执行的sql#
一致性:由其他三大特性共同保证,是事务的目的
隔离性:由MVCC保证
持久性:由redolog日志和内存保证,mysql修改数据时内存和redolog会记录操作,宕机时可恢复
4、事务的隔离级别
在高并发情况下,并发事务会产生脏读、不可重复读、幻读问题,这时需要用隔离级别来控制
- 读未提交: 允许一个事务读取另一个事务已提交的数据,可能出现不可重复读,幻读。
- 读提交: 只允许事务读取另一个事务没有提交的数据可能出现不可重复读,幻读。
- 可重复读: 确保同一字段多次读取结果一致,可能出现欢幻读。
- 可串行化: 所有事务逐次执行,没有并发问日
Inno DB 默认隔离级别为可重复读级别,分为快照度和当前读,并且通过间隙锁解决了幻读问题。
- 脏读:脏读指的是读到了其他事务未提交的数据,未提交意味着这些数据可能会回滚,也就是可能最终不会存到数据库中,也就是不存在的数据。读到了并一定最终存在的数据,这就是脏读。
- 不可重复读:不可重复读指的是在一个事务内,最开始读到的数据和事务结束前的任意时刻读到的同一批数据出现不一致的情况。
- 幻读:幻读,并不是说两次读取获取的结果集不同,幻读侧重的方面是某一次的 select 操作得到的结果所表征的数据状态无法支撑后续的业务操作。更为具体一些:select 某记录是否存在,不存在,准备插入此记录,但执行 insert 时发现此记录已存在,无法插入,此时就发生了幻读。
5、什么是快照读和当前读
*快照读读取的是当前数据的可见版本,可能是会过期数据,不加锁的select就是快照都
*当前读读取的是数据的最新版本,并且当前读返回的记录都会上锁,保证其他事务不会并发修改这条记录。如update、insert、delete、select for undate(排他锁)、select lockin share mode(共享锁) 都是当前读
6、MVCC是什么
MVCC是多版本并发控制,为每次事务生成一个新版本数据,每个事务都由自己的版本,从而不加锁就决绝读写冲突,这种读叫做快照读。只在读已提交和可重复读中生效。
实现原理由四个东西保证,他们是
undolog日志:记录了数据历史版本
readView:事务进行快照读时动态生成产生的视图,记录了当前系统中活跃的事务id,控制哪个历史版本对当前事务可见
隐藏字段DB_TRC_ID: 最近修改记录的事务ID
隐藏字段DB_Roll_PTR: 回滚指针,配合undolog指向数据的上一个版本
7、MySQL有哪些索引
主键索引:一张表只能有一个主键索引,主键索引列不能有空值和重复值
唯一索引:唯一索引不能有相同值,但允许为空
普通索引:允许出现重复值
组合索引:对多个字段建立一个联合索引,减少索引开销,遵循最左匹配原则
全文索引:myisam引擎支持,通过建立倒排索引提升检索效率,广泛用于搜索引擎
8.聚簇索引和非聚簇索引的区别
聚簇索引:聚簇索引的叶子节点存放的是主键值和数据行;辅助索引(在聚簇索引上创建的其它索引)的叶子节点存放的是主键值或指向数据行的指针。
优点:根据索引可以直接获取值,所以他获取数据更快;对于主键的排序查找和范围查找效率更高;
缺点:如果主键值很大的话,辅助索引也会变得很大;如果用uuid作为主键,数据存储会很稀疏;修改主键或乱序插入会让数据行移动导致页分裂;所以一般我们定义主键时尽量让主键值小,并且定义为自增和不可修改。
非聚簇索引(辅助索引):叶子节点存放的是数据行地址,先根据索引找到数据地址,再根据地址去找数据
他们都是b+数结构
9.MySQL如何做慢SQL优化
可以查看执行计划分析数据的扫描类型、索引是否生效,常见的慢查询优化有:
(1)尽量减少select的数据列,尽量使用覆盖索引
(2)orderby查找时使用索引进行排序,否则的话需要进行回表
(3)groupby查询时,同样要用索引,避免使用到临时表
(4)分页查询时,如果limit 后面的数字太大,可以使用子查询查出主键,再limit主键后n条数据就能走覆盖索引
(5) 使用复杂查询时,使用关联查询来代替子查询,并且最好使用内连接
(6)使用count函数时直接使用count的话count(*)的效率最高
count(*)或count(唯一索引)或count(数字):表中总记录数,count(字段)不会统计null
(7) 在写update语句时,where条件要使用索引,否则会锁会从行锁升级为表锁
(8)表中数据是否太大,是不是要分库分表
10.为什么要用内连接而不用外连接?
用外连接的话连接顺序是固定死的,比如left join,他必须先对左表进行全表扫描,然后一条条到右表去匹配;而内连接的话mysql会自己根据查询优化器去判断用哪个表做驱动。
子查询的话同样也会对驱动表进行全表扫描,所以尽量用小表做驱动表。
11、MySQL整个查询的过程
(1)客户端向 MySQL 服务器发送一条查询请求
(2)服务器首先检查查询缓存,如果命中缓存,则返回存储在缓存中的结果。否则进入下一阶段
(3)服务器进行 SQL 解析、预处理、再由优化器生成对应的执行计划
(4)MySQL 根据执行计划,调用存储引擎的 API 来执行查询
(5)将结果返回给客户端,同时缓存查询结果
注意:只有在8.0之前才有查询缓存,8.0之后查询缓存被去掉了
12、执行计划中有哪些字段?
我们想看一个sql的执行计划使用的语句是explain+SQL,表中的字段包括:
type:扫描类型,效率从底到高为ALL(全表扫描)>index(全索引扫描,我们的需要的数据在索引中可以获取)>range(使用索引进行范围查找)>ref(使用非唯一索引列进行了关联查询)> eq_ref (使用唯一索引进行关联查询)>const(使用唯一索引查询一行数据)>system(表中只有一行数据)
extra(额外的):mysql如何查询额外信息,常见的有:
filesort:在排序缓冲区中进行排序,需要回表查询数据
index:表示使用覆盖索引
index scan:排序时使用了索引排序,但如果是按照降序排序的话就会使用反向扫描索引
temporary:查询时要建立一个临时表存放数据
rows:找到了多少行数据
key:实际使用到的索引
id:select查询的优先级,id越大优先级越高,子查询的id一般会更大
select_type:查询的类型,是普通查询还是联合查询还是子查询,常见类型有simple(不包含子查询),primary(标记复杂查询中最外层的查询),union(标记primart只后子查询)
table:者一行的数据是数哪张表的
possible_keys(可能的):当前查询语句可能用到的索引,可能为null(如果用了索引但是为null有可能是表数据太少innodb认为全表扫描更快)
ref(编号):显示索引的哪一行被使用了
13、哪些情况索引会失效
(1)where条件中有or,除非所有查询条件都有索引,否则失效
(2)like查询用%开头,索引失效
(3)索引列参与计算,索引失效
(4)违背最左匹配原则,索引失效
(5)索引字段发生类型转换,索引失效
(6)mysql觉得全表扫描更快时(数据少),索引失效
14、B和B+数的区别,为什么使用B+数
二叉树:索引字段有序,极端情况会变成链表形式
AVL数:树的高度不可控
B数:控制了树的高度,但是索引值和data都分布在每个具体的节点当中,若要进行范围查询,要进行多次回溯,IO开销大
B+树:非叶子节点只存储索引值,叶子节点再存储索引+具体数据,从小到大用链表连接在一起,范围查询可直接遍历不需要回溯7
15、MySQL有哪些锁
基于粒度:
*表级锁:对整张表加锁,粒度大并发小
*行级锁:对行加锁,粒度小并发大
*间隙锁:间隙锁,锁住表的一个区间,间隙锁之间不会冲突只在可重复读下才生效,解决了幻读
基于属性:
*共享锁:又称读锁,一个事务为表加了读锁,其它事务只能加读锁,不能加写锁
*排他锁:又称写锁,一个事务加写锁之后,其他事务不能再加任何锁,避免脏读问题
16、Mysql内连接、左连接、右连接的区别
内连接取量表交集部分,左连接取左表全部右表匹部分,右连接取右表全部坐表匹部分
17.sql执行顺序
18、如何设计数据库?
(1)抽取实体,如用户信息,商品信息,评论
(2)分析其中属性,如用户信息:姓名、性别...
(3)分析表与表之间的关联关系
然后可以参考三大范式进行设计,设计主键时,主键要尽量小并且定义为自增和不可修改。
19、where和having的区别?
where是约束声明,having是过滤声明,where早于having执行,并且where不可以使用聚合函数,having可以
20、三大范式
第一范式:每个列都不可以再拆分。
第二范式:在第一范式的基础上,非主键列完全依赖于主键,而不能是依赖于主键的一部分。
第三范式:在第二范式的基础上,非主键列只依赖于主键,不依赖于其他非主键。
21、char和varchar的区别
char是不可变的,最大长度为255,varchar是可变的字符串,最大长度为2^16
22、InnoDB 什么情况下会产生死锁
事务1已经获取数据A的写锁,想要去获取数据B的写锁,然后事务2获取了B的写锁,想要去获取A的写锁,相互等待形成死锁。
mysql解决死锁的机制有两个:1.等待, 直到超时 2.发起死锁检测,主动回滚一条事务
死锁检测的原理是构建一个以事务为顶点、 锁为边的有向图, 判断有向图是否存在环, 存在即有死锁。
我们平时尽量减少事务操作的资源和隔离级别
23.MySQL 删除自增 id,随后重启 MySQL 服务,再插入数据,自增 id 会从几开始?
innodb 引擎:
MySQL8.0前,下次自增会取表中最大 id + 1。原理是最大id会记录在内存中,重启之后会重新读取表中最大的id
MySQL8.0后,仍从删除数据 id 后算起。原理是它将最大id记录在redolog里了
myisam:
自增的 id 都从删除数据 id 后算起。原理是它将最大id记录到数据文件里了
24、MySQL插入百万级的数据如何优化?
(1)一次sql插入多条数据,可以减少写redolog日志和binlog日志的io次数(sql是有长度限制的,但可以调整)
(2)保证数据按照索引进行有序插入
(3)可以分表后多线程插入
25、mybatis的#号和$符的区别
#占位符的特点
-
MyBatis处理 #{ } 占位符,使用的 JDBC 对象是PreparedStatement 对象,执行sql语句的效率更高。
-
使用PreparedStatement 对象,能够避免 sql 注入,使得sql语句的执行更加安全。
-
{ } 常常作为列值使用,位于sql语句中等号的右侧;#{ } 位置的值与数据类型是相关的。
$占位符的特点
- MyBatis处理 ${ } 占位符,使用的 JDBC 对象是 Statement 对象,执行sql语句的效率相对于 #{ } 占位符要更低。
- ${ } 占位符的值,使用的是字符串连接的方式,有 sql 注入的风险,同时也存在代码安全的问题。
- ${ } 占位符中的数据是原模原样的,不会区分数据类型。
- ${ } 占位符常用作表名或列名,这里推荐在能保证数据安全的情况下使用 ${ }。
1.#和$两者含义不同
#会把传入的数据都当成一个字符串来处理,会在传入的数据上面加一个双引号来处理。
而$则是把传入的数据直接显示在sql语句中,不会添加双引号。
2.两者的实现方式不同
(1)$作用相等于是字符串拼接
(2)#作用相当于变量值替换
3、#和$使用场景不同
(1)在sql语句中,如果要接收传递过来的变量的值的话,必须使用#。因为使用#是通过PreparedStement接口来操作,可以防止sql注入,并且在多次执行sql语句时可以提高效率。
(2)\(只是简单的字符串拼接而已,所以要特别小心sql注入问题。对于sql语句中非变量部分,那就可以使用\),比如$方式一般用于传入数据库对象(如传入表名)。
例如:
select * from \({tableName},\) 对于不同的表执行统一的查询操作时,就可以使用$来完成。
(3)如果在sql语句中能同时使用#和$的时候,最好使用#。
26、mysql大数据量查询的处理
1、MySQL处理大数据查询的方法之一是使用索引。索引是一种数据结构,可以大大加速数据检索的速度。如果在查询中使用索引,则MySQL将优先使用索引,而不是扫描整个表。因此,创建索引对于大数据查询而言至关重要。
2、另一个方法是利用合适的数据分区方案来提升查询效率。数据分区是一种将表分割成若干个较小分区的技术,每个分区独立地存储和维护数据。这样,当执行大数据查询时,MySQL只需要对相关分区进行扫描,提高了查询效率。
3、此外,我们可以使用MySQL的预存储过程和视图,来简化大数据查询的复杂度。预存储过程是一种可以在MySQL中实现的存储过程,可以将常用的查询逻辑进行编写和封装,然后通过调用预存储过程的方式来执行查询。
4、视图是一种虚拟的表,它可以在查询时返回一个结果集,使得数据查询和数据处理变得更加灵活和方便。对于大数据量的查询,使用视图可以极大地简化代码,并提升查询速度。
27、mybatis怎么定义全局sql。整个程序的全局变量怎么设置
MyBatis中数据库的全局配置和局部配置都是通过XML文件实现的
全局配置
MyBatis全局配置文件的名称一般为mybatis-config.xml,其主要用于配置一些全局性的配置信息,比如数据源、数据库方言、类型处理器、插件等。
在使用MyBatis时,可以通过SqlSessionFactoryBuilder类的build()方法来读取全局配置文件并创建SqlSessionFactory实例。在全局配置文件中,可以通过properties元素为属性值进行配置,如下所示:
<configuration>
<properties>
<property name="username" value="root"/>
<property name="password" value="root"/>
</properties>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/test"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="org/mybatis/example/BlogMapper.xml"/>
</mappers>
</configuration>
局部配置
MyBatis中局部配置主要是通过Mapper文件来实现的。Mapper文件中可以定义SQL语句、参数映射、结果映射等信息。Mapper文件可以定义在全局配置文件中,也可以单独定义。在使用MyBatis时,需要将Mapper文件映射到接口中,通常是通过注解或XML文件实现。
以下是一个Mapper文件的示例:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.mapper.UserMapper">
<resultMap type="User" id="BaseResultMap">
<id column="id" property="id" />
<result column="name" property="name" />
<result column="age" property="age" />
</resultMap>
<select id="selectUserById" resultMap="BaseResultMap">
SELECT * FROM user WHERE id = #{id}
</select>
<select id="selectAllUsers" resultMap="BaseResultMap">
SELECT * FROM user
</select>
<insert id="insertUser" parameterType="User">
INSERT INTO user(id, name, age) VALUES(#{id}, #{name}, #{age})
</insert>
<update id="updateUser" parameterType="User">
UPDATE user SET name = #{name}, age = #{age} WHERE id = #{id}
</update>
<delete id="deleteUserById" parameterType="int">
DELETE FROM user WHERE id = #{id}
</delete>
</mapper>
五、Spring
1、什么是spring bean
1.1在 Spring 中,构成应用程序主干并由Spring IoC容器管理的对象称为bean。bean是一个由Spring IoC容器实例化、组装和管理的对象。
概念简单明了,我们提取处关键的信息:
bean是对象,一个或者多个不限定
bean由Spring中一个叫IoC的东西管理
我们的应用程序由一个个bean构成
1.2、Bean创建方式
可以通过三种不同的方式定义Spring bean:
1.使用构造型@Component注释(或其衍生物)注释你的类
2.编写在自定义Java配置类中使用@Bean注释的bean工厂方法
3.在XML配置文件中声明bean定义
1.3 Bean作用域
Spring bean的范围定义了框架在运行时创建的特定类的实例数。作用域还描述了创建新对象的条件。
Spring为你的bean提供了几个作用域。框架的核心有两个:
- 单例 - 单个实例
- 原型 - 多个实例
此外,Spring还附带了专门用于Web应用程序的bean作用域:
- 请求
- 会话
- 全局会话
- 应用级别Application
所有bean的默认作用域是单例。当bean具有单例作用域时,Spring只创建一个实例并在整个应用程序中共享它。单例是无状态对象的完美选择。如今,我们应用程序中的绝大多数bean都是无状态单例。
另一方面,如果对象包含状态,则应考虑其他作用域。要选择正确的一个,你应该问自己框架应该将该状态保留在内存中多长时间
1.4 如何设置作用域?
无论是使用@Component直接注释类还是使用@Bean创建工厂方法,该方法都是相同的。使用@Scope批注及其字符串属性选择范围。
@Component
@Scope("prototype")
class MyPrototypeClass {
//...
}
@Bean
@Scope("prototype")
MyPrototypeClass myPrototypeClass() {
return new MyPrototypeClass();
}
- 更重要的是,对于Web作用域,Spring附带了额外的别名注释。你可以使用这些注释代替@Scope:
- @RequestScope
- @SessionScope
- @ApplicationScope
2 控制反转(IoC)
控制反转英文全称:Inversion of Control,简称就是IoC。
控制反转通过依赖注入(DI)方式实现对象之间的松耦合关系。程序运行时,依赖对象由【辅助程序】动态生成并注入到被依赖对象中,动态绑定两者的使用关系。Spring IoC容器就是这样的辅助程序,它负责对象的生成和依赖的注入,让后在交由我们使用。 简而言之,就是:IoC就是一个对象定义其依赖关系而不创建它们的过程。
这里我们可以细分为两个点。
2.1 私有属性保存依赖
第1点:使用私有属性保存依赖对象,并且只能通过构造函数参数传入,构造函数的参数可以是工厂方法、保存类对象的属性、或者是工厂方法返回值。 假设我们有一个Computer类:
public class Computer {
private String cpu; // CPU型号
private int ram; // RAM大小,单位GB
public Computer(String cpu, int ram) {
this.cpu = cpu;
this.ram = ram;
}
}
我们有另一个Person类依赖于Computer类,符合IoC的做法是这样:
public class Person {
private Computer computer;
public Person(Computer computer) {
this.computer = computer;
}
}
不符合IoC的做法如下:
// 直接在Person里实例化Computer类
public class Person {
private Computer computer = new Computer(AMD, 3);
}
// 通过【非构造函数】传入依赖
public class Person {
private Computer computer;
public void init(Computer computer) {
this.computer = computer;
}
}
简单来说,person依赖Computer,但person不控制Computer的创建和销毁,仅使用Computer,那么Computer的控制权交给person之外处理,这叫控制反转(IOC),而person要依赖computer,必然要使用computer的instance,那么
通过a的接口,把b传入;
通过a的构造,把b传入;
通过设置a的属性,把b传入;
这个过程叫依赖注入(DI)。
2.2 让Spring控制类构建过程
第2点:不用new,让Spring控制new过程。在Spring中,我们基本不需要 new 一个类,这些都是让 Spring 去做的。 Spring 启动时会把所需的类实例化成对象,如果需要依赖,则先实例化依赖,然后实例化当前类。 因为依赖必须通过构建函数传入,所以实例化时,当前类就会接收并保存所有依赖的对象。 这一步也就是所谓的依赖注入。
2.3 这就是IoC
在 Spring 中,类的实例化、依赖的实例化、依赖的传入都交由 Spring Bean 容器控制, 而不是用new方式实例化对象、通过非构造函数方法传入依赖等常规方式。 实质的控制权已经交由程序管理,而不是程序员管理,所以叫做控制反转。
3、AOP是什么?
-
AOP是面向切面编程,可以将那些与业务不相关但是很多业务都要调用的代码抽取出来,思想就是不侵入原有代码的情况下对功能进行增强。
-
SpringAOP是基于动态代理实现的,动态代理是有两种,一种是jdk动态代理,一种是cglib动态代理;
- jdk动态代理是原理是利用反射来实现的,需要调用反射包下的Proxy类的newProxyInstance方法来返回代理对象,这个方法中有三个参数,分别是用于加载代理类的类加载器,被代理类实现的接口的class数组和一个用于增强方法的InvocaHandler实现类。
- cglib动态代理原理是利用asm开源包来实现的,是把被代理类的class文件加载进来,通过修改它的字节码生成子类来处理
-
jdk动态代理要求被代理类必须有实现的接口,生成的动态代理类会和代理类实现同样的接口,cglib则,生成的动态代理类会继承被代理类。Spring默认使用jdk动态代理,当被代理的类没有接口时就使用cglib动态代理
4、如何定义一个全局异常处理类?
想要定义一个全局异常处理类的话,我们需要在这个类上添加@ContaollerAdvice注解,然后定义一些用于捕捉不同异常类型的方法,在这些方法上添加@ExceptionHandler(value = 异常类型.class)和@ResponseBody注解,方法参数是HttpServletRequest和异常类型,然后将异常消息进行处理。
如果我们需要自定义异常的话,就写一个自定义异常类,该类需要继承一个异常接口,类属性包括final类型的连续id、错误码、错误信息,再根据需求写构造方法;
5、如何使用aop自定义日志?
第一步:创建一个切面类,把它添加到ioc容器中并添加@Aspect注解
第二步: 在切面类中写一个通知方法,在方法上添加通知注解并通过切入点表达式来表示要对哪些方法进行日志打印,然后方法参数为JoinPoint
第三步:通过JoinPoint这个参数可以获取当前执行的方法名、方法参数等信息,这样就可以根据需求在方法进入或结束时打印日志
6、循环依赖是什么,怎么解决的?
循环依赖就是在创建 A 实例的时候里面包含着 B 属性实例,所以这个时候就需要去创建 B 实例,而创 建 B 实例过程中也包含着 A 实例。 这样 A 实例还在创建的过程当中,所以就导致 A 和 B 实例都创建不出来。
spring通过三级缓存来解决循环依赖:
-
一级缓存:缓存经过完整的生命周期的Bean
-
二级缓存 :缓存未经过完整的生命周期的Bean
-
三级缓存:缓存的是ObjectFactory,其中存储了一个生成代理类的拉姆达表达式
我们在创建 A 的过程中,先将 A 放入三级缓存 ,这时要创建B,B要创建A就直接去三级缓存中查找,并且判断需不需要进行 AOP 处理,如果需要就执行拉姆达表达式得到代理对象,不需要就取出原始对象。然后将取出的对象放入二级缓存中,因为这个时候 A 还未经 过完整的生命周期所以不能放入一级缓存。这个时候其他需要依赖 A 对象的直接从二级缓存中去获取即可。当B创建完成,A 继续执行生命周期,当A完成了属性的注入后,就可以放入一级缓存了
7、Bean 的作用域
(1)Singleton:一个IOC容器只有一个
(2)Prototype:每次调用getBean()都会生成一个新的对象
(3)request:每个http请求都会创建一个自己的bean
(4)session:同一个session共享一个实例
(5)application:整个serverContext只有一个bean
(6)webSocket:一个websocket只有一个bean
8、Bean 生命周期
实例化 Instantiation->属性赋值 Populate->初始化 Initialization->销毁 Destruction
在这四步的基础上面,Spring 提供了一些拓展点:
*Bean 自身的方法: 包括了 Bean 本身调用的方法和通过配置文件中的 init-method 和 destroy-method 指定的方法
*Bean 级生命周期接口方法:包括了 BeanNameAware、BeanFactoryAware、InitializingBean 和 DiposableBean 这些接口的方法
*容器级生命周期接口方法:包括了 InstantiationAwareBeanPostProcessor 和 BeanPostProcessor 这两个接口实现,一般称它们的实现类为“后处理器”。
*工厂后处理器接口方法: 包括了 AspectJWeavingEnabler, ConfigurationClassPostProcessor, CustomAutowireConfigurer 等等非常有用的工厂后处理器接口的方法。工厂后处理器也是容器级的。在应用上下文装配配置文件之后立即调用。
9、Spring 事务原理?
spring事务有编程式和声明式,我们一般使用声明式,在某个方法上增加@Transactional注解,这个方法中的sql会统一成功或失败。
原理是:
当一个方法加上@Transactional注解,spring会基于这个类生成一个代理对象并将这个代理对象作为bean,当使用这个bean中的方法时,如果存在@Transactional注解,就会将事务自动提交设为false,然后执行方法,执行过程没有异常则提交,有异常则回滚、
10、spring事务失效场景
(1)事务方法所在的类没有加载到容器中
(2)事务方法不是public类型
(3)同一类中,一个没有添加事务的方法调用另外以一个添加事务的方法,事务不生效
(4)spring事务默认只回滚运行时异常,可以用rollbackfor属性设置
(5)业务自己捕获了异常,事务会认为程序正常秩序
11.spring事务的隔离级别
- DEFAULT:Spring 中默认的事务隔离级别,以连接的数据库的事务隔离级别为准;
- READ_UNCOMMITTED:读未提交,也叫未提交读,该隔离级别的事务可以看到其他事务中未提交的数据。该隔离级别因为可以读取到其他事务中未提交的数据,而未提交的数据可能会发生回滚,因此我们把该级别读取到的数据称之为脏数据,把这个问题称之为脏读;
- READ_COMMITTED:读已提交,也叫提交读,该隔离级别的事务能读取到已经提交事务的数据,因此它不会有脏读问题。但由于在事务的执行中可以读取到其他事务提交的结果,所以在不同时间的相同 SQL 查询中,可能会得到不同的结果,这种现象叫做不可重复读;
- REPEATABLE_READ:可重复读,它能确保同一事务多次查询的结果一致。但也会有新的问题,比如此级别的事务正在执行时,另一个事务成功的插入了某条数据,但因为它每次查询的结果都是一样的,所以会导致查询不到这条数据,自己重复插入时又失败(因为唯一约束的原因)。明明在事务中查询不到这条信息,但自己就是插入不进去,这就叫幻读 (Phantom Read);
- SERIALIZABLE:串行化,最高的事务隔离级别,它会强制事务排序,使之不会发生冲突,从而解决了脏读、不可重复读和幻读问题,但因为执行效率低,所以真正使用的场景并不多。
12、spring事务的传播行为
(1)支持当前事务,如果不存在,则新启一个事务
(2)支持当前事务,如果不存在,则抛出异常
(3)支持当前事务,如果不存在,则以非事务方式执行
(4)不支持当前事务,创建一个新事物
(5)不支持当前事务,如果已存在事务就抛异常
(6)不支持当前事务,始终以非事务方式执行
13.Spring IoC

14.spring用了哪些设计模式
-
BeanFactory用了工厂模式,
-
AOP用了动态代理模式,
-
RestTemplate用来模板方法模式,
-
SpringMVC中handlerAdaper用来适配器模式,
-
Spring里的监听器用了观察者模式
14、SpringMV工作原理
SpringMVC工作过程围绕着前端控制器DispatchServerlet,几个重要组件有HandleMapping(处理器映射器)、HandleAdapter(处理器适配器)、ViewReslover(试图解析器)
工作流程:
(1)DispatchServerlet接收用户请求将请求发送给HandleMapping
(2)HandleMapping根据请求url找到具体的handle和拦截器,返回给DispatchServerlet
(3)DispatchServerlet调用HandleAdapter,HandleAdapter执行具体的controller,并将controller返回的ModelAndView返回给DispatchServler
(4)DispatchServerlet将ModelAndView传给ViewReslover,ViewReslover解析后返回具体view
(5)DispatchServerlet根据view进行视图渲染,返回给用户
15、Springboot和SpringMVC的区别
1、含义不同
springboot:SpringBoot是一个自动化配置的工具。
springmvc:SpringMVC是一个web框架。
2、配置不同
springboot:SpringBoot采用约定大于配置的方式,通过其自动配置功能自动处理配置,同时内置服务器,打开就可以直接用。
springmvc:此框架需要大量配置,例如 DispatcherServlet 配置和 View Resolver 配置。需要手动配置xml文件,同时需要配置Tomcat服务器。
3、依赖项不同
springboot:springboot具有启动器的概念,一旦将其添加到类路径中,它将带来开发Web应用程序所需的所有依赖项。
springmvc:需要单独指定每个依赖项才能运行功能。
4、开发时间不同
springboot:Spring Boot有助于减少开发时间,因为所有与依赖关系相关的任务都会得到处理。
springmvc:与Spring Boot相比,开发所需的时间更多,因为开发人员需要花时间添加所需的依赖项。
5、生产力不同
springboot:由于开发时间更短,生产力提高。
springmvc:生产力降低,因为需要了解依赖性附加组件。
6、实现JAR打包功能的方式不同
springboot:Spring Boot 允许嵌入式服务器以独立的方式运行该功能。
springmvc:Spring MVC需要大量手动配置才能实现JAR打包的功能。
7、是否提供批处理功能
springboot:它提供强大的批处理。
springmvc:它不提供强大的批处理。
8、作用不同
springboot:Spring Boot也允许构建不同类型的应用程序。
springmvc:Spring MVC仅用于开发动态网页和RESTful网络服务。
16、spring的bean是线程安全的吗?
spring的默认bean作用域是单例的,单例的bean不是线程安全的,但是开发中大部分的bean都是无状态的,不具备存储功能,比如controller、service、dao,他们不需要保证线程安全。
如果要保证线程安全,可以将bean的作用域改为prototype,比如像Model View。
另外还可以采用ThreadLocal来解决线程安全问题。ThreadLocal为每个线程保存一个副本变量,每个线程只操作自己的副本变量。
17、@Autoware和@Resource的区别
@Autowired 和 @Resource 都是 Spring/Spring Boot 项目中,用来进行依赖注入的注解。它们都提供了将依赖对象注入到当前对象的功能,但二者却有众多不同,并且这也是常见的面试题之一,所以我们今天就来盘它。 @Autowired 和 @Resource 的区别主要体现在以下 5 点:
- 来源不同;
- 依赖查找的顺序不同;
- 支持的参数不同;
- 依赖注入的用法不同;
- 编译器 IDEA 的提示不同。
1、来源不同
@Autowired 和 @Resource 来自不同的“父类”,其中 @Autowired 是 Spring 定义的注解,而 @Resource 是 Java 定义的注解,它来自于 JSR-250(Java 250 规范提案)。
2、依赖查找顺序不同
依赖注入的功能,是通过先在 Spring IoC 容器中查找对象,再将对象注入引入到当前类中。而查找有分为两种实现:按名称(byName)查找或按类型(byType)查找,其中 @Autowired 和 @Resource 都是既使用了名称查找又使用了类型查找,但二者进行查找的顺序却截然相反。
2.1 @Autowired 查找顺序
@Autowired 是先根据类型(byType)查找,如果存在多个 Bean 再根据名称(byName)进行查找,它的具体查找流程如下:

2.2 @Resource 查找顺序
@Resource 是先根据名称查找,如果(根据名称)查找不到,再根据类型进行查找,它的具体流程如下图所示:
2.3 查找顺序小结
由上面的分析可以得出:
- @Autowired 先根据类型(byType)查找,如果存在多个(Bean)再根据名称(byName)进行查找;
- @Resource 先根据名称(byName)查找,如果(根据名称)查找不到,再根据类型(byType)进行查找。
3、支持的参数不同
@Autowired 和 @Resource 在使用时都可以设置参数,比如给 @Resource 注解设置 name 和 type 参数,实现代码如下:
@Resource(name = "userinfo", type = UserInfo.class)
private UserInfo user;
但二者支持的参数以及参数的个数完全不同,其中 @Autowired 只支持设置一个 required 的参数,而 @Resource 支持 7 个参数
4.依赖注入的支持不同
@Autowired 和 @Resource 支持依赖注入的用法不同,常见依赖注入有以下 3 种实现:
- 属性注入
- 构造方法注入
- Setter 注入
其中, @Autowired 支持属性注入、构造方法注入和 Setter 注入,而 @Resource 只支持属性注入和 Setter 注入,当使用 @Resource 实现构造方法注入时就会提示以下错误:
总结
@Autowired 和 @Resource 都是用来实现依赖注入的注解(在 Spring/Spring Boot 项目中),但二者却有着 5 点不同:##
来源不同:@Autowired 来自 Spring 框架,而 @Resource 来自于(Java)JSR-250;
依赖查找的顺序不同:@Autowired 先根据类型再根据名称查询,而 @Resource 先根据名称再根据类型查询;
支持的参数不同:@Autowired 只支持设置 1 个参数,而 @Resource 支持设置 7 个参数;
依赖注入的用法支持不同:@Autowired 既支持构造方法注入,又支持属性注入和 Setter 注入,而 @Resource 只支持属性注入和 Setter 注入;
编译器 IDEA 的提示不同:当注入 Mapper 对象时,使用 @Autowired 注解编译器会提示错误,而使用 @Resource 注解则不会提示错误。
六、Springboot
1、springboot自动配置原理
一.原理解释
Spring Boot的自动配置是Spring框架的一个重要特性,它旨在简化应用程序的开发和部署过程。自动配置通过基于类路径中的依赖关系和配置文件内容来预先配置Spring应用程序的各种组件和功能。这样,我们可以在无需显式配置大量参数的情况下,快速搭建一个运行良好的Spring应用程序,极大的提高了我们的开发效率。
下面我们对于Spring Boot自动配置的工作原理做一个详细解释(我们只谈原理和概念,不设计实现):
1.条件装配:
Spring Boot的自动配置采用了条件装配的机制。条件装配根据特定条件来决定是否创建特定的Bean或应用特定的配置。这些条件可以基于类路径中存在的依赖、配置属性的值、环境变量或其他Spring Bean的存在等。这样,当满足特定条件时,相关的Bean会被自动创建和配置,否则它们将被跳过。
2、Spring Boot Starter:
Spring Boot提供了一系列Starter模块,每个Starter模块都包含了特定功能的默认依赖和配置。例如,spring-boot-starter-web包含了构建Web应用程序所需的依赖和配置。这些Starter模块通过自动配置来简化应用程序的搭建,开发者只需添加相应的Starter依赖,即可自动启用相关功能。
3、Spring Boot的启动过程:
当Spring Boot应用程序启动时,会触发自动配置的过程。首先,它会扫描类路径上的所有Starter模块,并加载它们的自动配置类。然后,Spring Boot会根据条件装配机制,检查是否满足自动配置的条件,并决定是否创建相应的Bean和应用相关的配置。
4、条件注解:
Spring Boot中有许多条件注解,这些注解用于根据特定条件来启用或禁用配置。例如,@ConditionalOnClass注解表示只有类路径中存在指定的类时,相关配置才会生效。@ConditionalOnProperty注解则允许根据配置属性的值来决定是否启用某个配置。
5、自动配置类的优先级:
在某些情况下,可能存在多个自动配置类都能满足条件的情况。为了解决这种冲突,Spring Boot为自动配置类定义了优先级。具有更高优先级的配置类将覆盖具有较低优先级的配置类。这样,开发者可以通过自定义配置类来覆盖Spring Boot默认的自动配置行为。
6、自定义自动配置:
Spring Boot允许开发者定义自己的自动配置类。要创建自定义的自动配置,只需在类上添加@Configuration注解,并在类中配置所需的Bean。然后,Spring Boot会在启动过程中将这些自定义配置类纳入自动配置的流程中。
二、什么是springboot自动配置
SpringBoot通过@EnableAutoConfiguration注解开启自动配置,对jar包下的spring.factories文件进行扫描,这个文件中包含了可以进行自动配置的类,当满足@Condition注解指定的条件时,便在依赖的支持下进行实例化,注册到Spring容器中。
通俗的来讲,我们之前在写ssm项目时候,配置了大量坐标和配置内容,搭环境的过程在项目开发中占据了大量时间,SpringBoot的最大的特点就是简化了各种xml配置内容,所以springboot的自动配置就是用注解来对一些常规的配置做默认配置,简化xml配置内容,使你的项目能够快速运行。
springboot核心配置原理:
- 自动配置类都存放在spring-boot-autoconfigure-版本号.jar下的org.springframework.boot.autoconfigure中
- 当我们在application.properties中配置debug=true后启动容器。可以看到服务器初始化的初始化配置
- DispatcherServletAutoConfigratio注册前端控制器
- EmbeddedServletContainerAutoConfiguration注册容器类型
- HttpMessageConvertersAutoConfiguration注册json或者xml处理器
- JacksonAutoConfiguration注册json对象解析器
- 如果加入其他功能的依赖,springBoot还会实现这些功能的自动配置
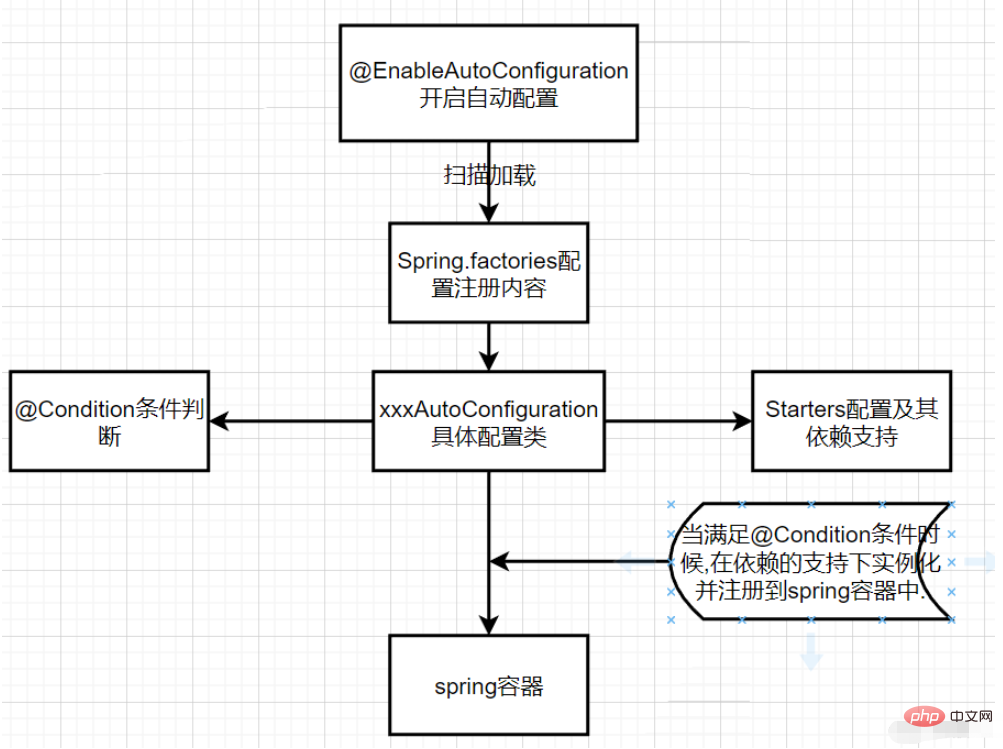
二、Starter组件
Starter组件是可被加载在应用中的Maven依赖项项。只有在Maven配置中添加对应的依赖配置,即可使用对应的Starter组件。例如,添加spring-boot-starter-web依赖,就可以用于构建RESTAPI服务,其包含了SpringMVC和Tomcat内嵌容器。
一个完整的Starter组件包括以下两点:
- 提供自动配置功能的自动配置模块
- 提供依赖关系管理岗功能的组件模块,即封装了组件所有功能,开箱即用。
spring-boot-starter-web依赖源码
三、三大注解
@SpringBootConfiguration:继承自Configuration,支持JavaConfig的方式进行配置。
@EnableAutoConfiguration:本文重点讲解,主要用于开启自动配置。
@ComponentScan:自动扫描组件,默认扫描该类所在包及其子包下所有带有指定注解的类,将它们自动装配到bean容器中,会被自动装配的注解包括@Controller、@Service、@Component、@Repository等。也可以指定扫描路径。
四、@EnableAutoConfiguration
这个注解是帮助我们自动加载默认配置的,它里面有两个关键注解@AutoConfigurationPackage和@Import,我们来详细了解@Import注解。
@Import(AutoConfigurationImportSelector.class)注解,这里导入AutoConfigurationImportSelector类。这个类中有一个非常重要的方法——selectImports(),它几乎涵盖了组件自动装配的所有处理逻辑,包括获得候选配置类、配置类去重、排除不需要的配置类、过滤等,最终返回符合条件的自动配置类的全限定名数组。
五、SpringFactoriesLoader
spring-core包里定义了SpringFactoriesLoader类,这个类实现了检索META-INF/spring.factories文件,并获取指定接口的配置的功能。在这个类中定义了两个对外的方法:
- loadFactories根据接口类获取其实现类的实例,这个方法返回的是对象列表。
- loadFactoryNames根据接口获取其接口类的名称,这个方法返回的是类名的列表。
上面的两个方法的关键都是从指定的ClassLoader中获取spring.factories文件,并解析得到类名列表,具体代码如下:
2、springboot常用注解
@RestController :修饰类,该控制器会返回Json数据
@RequestMapping("/path") :修饰类,该控制器的请求路径
@Autowired : 修饰属性,按照类型进行依赖注入
@PathVariable : 修饰参数,将路径值映射到参数上
@ResponseBody :修饰方法,该方法会返回Json数据
@RequestBody(需要使用Post提交方式) :修饰参数,将Json数据封装到对应参数中
@Controller@Service@Compont: 将类注册到ioc容器
@Transaction:开启事务
3、Spring Boot 有哪些特点?
Spring Boot 是 Spring 的扩展,它消除了设置 Spring 应用程序所需的样板配置。
1、自动配置
-
这是 Spring Boot 最重要的特性。这极大地消除了手动配置。基础框架附带了一个名为 auto-configure 的内置库,它为我们完成了这项工作。它检测某些类的存在以及类路径上的存在,并为我们自动配置它们。
-
例如:— 当我们在项目中添加spring-boot-starter-web依赖项时,Spring Boot 自动配置会查找 Spring MVC 是否在类路径中。它自动配置dispatcherServlet、默认错误页面和web jars。— 同样,当我们添加
spring-boot-starter-data-jpa依赖项时,我们会看到 Spring Boot 自动配置,自动配置一个数据源和一个实体管理器。 -
嵌入式 Tomcat Web 服务器
Spring Boot 默认随 Tomcat 服务器一起提供。因此,我们不需要配置服务器来运行应用程序(如果我们的首选服务器是 Tomcat)。
2、入门 POM
Spring Boot 本身提供了许多启动 POM 来完成开发生活中最常见的任务。我们可以依赖它们和框架本身,而不需要去第三方库。我在这里列出了其中的一些。
- spring-boot-starter-web:创建 REST API
- spring-boot-starter-data-jpa:连接 SQL 数据库
- spring-boot-starter-data-mongodb:连接 MongoDB
- spring-boot-starter -aop:应用面向方面的编程概念
- spring-boot-starter-security:实现安全性,如基于角色的身份验证
- spring-boot-starter-test:实现单元测试
3、Actuator执行器 API
Spring Boot Actuator 是 Spring Boot 框架的一个子项目。它使我们能够通过一组 API 端点查看见解和指标并监控正在运行的应用程序。我们不需要手动创建它们。
-
数据库统计信息:数据源使用情况
-
CPU内存使用情况
-
GC 周期
-
跟踪 HTTP 请求
4、SpringBoot初始化器
这是一个基于 Web 的 UI,主要提供了使用可用依赖项创建新 Spring Boot 项目并下载创建为 zip 的项目的能力。所以我们不必从头开始创建它。该项目的所有基本结构都已在此下载的 zip 中。Spring Initializer 作为 IDE 插件提供,也具有不同的名称。
例如:对于 IntelliJ - 插件是 Spring Assistant 或 Spring Initializer
4、你知道“@SpringBootApplication”注解在内部是如何工作的吗?
Spring Boot 应用程序使用此注解执行。实际上它是其他 3 个注释的组合
ComponentScan、EnableAutoConfiguration、Configuration。
- “@Configuration” ——所有带注释的类都被视为 Spring Boot 的广告配置,它们有资格创建 bean 并返回到 IOC 容器。
- “@ComponentScan” ——所有带注释的类都将通过包(在哪里寻找)进行扫描,并帮助创建这些类的实例。
- “@EnableAutoConfiguration” ——这是神奇的注解。这会寻找类路径。基础框架附带了一个名为auto-configure的内置库,它为我们完成了这项工作。它检测某些类的存在以及类路径上的存在,并为我们自动配置它们。我在下面放了图书馆的快照。如果您前往 spring.factories 文件,您将看到可用的类配置。

5、我们如何在Spring Boot中实现依赖注入?
DI — 将对象作为依赖项传递给另一个对象
在 Spring Boot 中,我们可以使用“@Autowired”注解来实现这一点。然后 Spring IOC 容器将代表我们创建对象。通常,在控制器层我们注入服务,在服务层我们注入存储库来使用这个注解。
6、我们需要在哪里使用“@Qualifier”注解?
此注解用于专门告诉 Spring Boot 从其所有可用实现 bean 中获取特定类。@Qualifier注解与“ @Autowired”注解一起用于依赖注入。
假设我们有1 个接口和 2 个不同的实现类。
例如:UserService 接口 => AdminUserService、StaffUserService 类
AdminUserService、StaffUserService 都在实现 UserService 接口。我们必须在服务启动时选择StaffUserService 。否则 Spring Boot 将抛出异常并抱怨候选人太多。
所以我们应该在 Autowired 之后放置 Qualifier 注释来解决这个问题:
@Autowired
@Qualifier("staffUserService")
private UserService userService;
7、Spring Boot项目中可以替换Tomcat服务器吗?
是的。如果需要,我们可以通过在 POM 中添加 maven 排除来删除 Tomcat 服务器。实际上,Web 服务器捆绑在started-web Spring Boot starter 依赖项中。应该添加排除。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId> spring-boot-starter-tomcat</artifactId>
</exclusion>
</exclusions>
</dependency>
然后我们必须将任何其他服务器(如 Jetty)添加到 POM。无论如何,我们必须在删除 tomcat 后添加一个 Web 服务器。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jetty</artifactId>
</dependency>
8、“@PathVariable”和“@RequestParam”有什么区别?
PathVariable - 当我们设置 API 端点时使用以“/”分隔的参数。
@GetMapping(path = "/profile/{username}")
public ResponseEntity<?> getUser( @PathVariable("username") String username) {
return ResponseEntity.ok().body(authService.findUserByUsername(username));
}
9、什么是Spring Boot Actuator?
简单地说,Spring Boot 框架的一个子项目,它使用 HTTP 端点来公开有关任何正在运行的应用程序的操作信息。
这些信息包括应用程序指标、连接的数据库状态、应用程序状态、bean 信息、请求跟踪等。
它可作为启动器依赖项使用。我们可以通过安装以下依赖项来使用该库。
10、SpringBoot的核心配置文件有哪几个?他们的区别是什么?
Spring Boot的核心配置文件有以下几个:
application.properties
application.yml
bootstrap.properties
bootstrap.yml
其中,application.properties和application.yml是应用程序的配置文件,而bootstrap.properties和bootstrap.yml是用于Spring Boot上下文的配置文件。它们之间的区别在于加载的优先级不同,bootstrap配置文件的优先级更高,可以用于设置一些比较敏感和重要的配置信息。
七、SpringCloud + 微服务
1、什么是springcloud
Spring cloud 流应用程序启动器是基于Spring Boot的Spring集成应用程序,提供与外部系统的集成。Spring cloud Task,一个生命周期短暂的微服务框架,用于快速构建执行有限数据处理的应用程序。
2、使用Spring Cloud有什么优势?
解决了复杂性问题:它将单体应用分解为一组服务。虽然功能总量不变,但应用程序已被分解为可管理的模块或服务。这些服务定义了明确的RPC或消息驱动的API边界。微服务架构强化了应用模块化的水平,而这通过单体代码库很难实现。因此,微服务开发的速度要快很多,更容易理解和维护。
单独开发每个服务,与其他服务互不干扰:只要符合服务API契约,开发人员可以自由选择开发技术。这就意味着开发人员可以采用新技术编写或重构服务,由于服务相对较小,所以这并不会对整体应用造成太大影响。
可以独立部署每个微服务:开发人员无需协调对服务升级或更改的部署。这些更改可以在测试通过后立即部署。所以微服务架构也使得CI/CD成为可能。
3、微服务的缺点
- 多服务运维难度
- 系统部署依赖
- 服务间通信成本
- 数据一致性
- 系统集成测试
- 重复工作
- 性能监控
4、实现微服务要解决的四个问题?
- 客户端如何访问这些服务?
- 服务之间如何通信?
- 这么多服务,怎么找?
- 服务挂了怎么办?
1、客户端如何访问这些服务
原来的服务都是可以进行单独调用,现在按功能拆分成独立的服务,变成了一个独立的Java进程了。客户端UI如何访问他的?后台有N个服务,前台就需要记住管理N个服务,一个服务下线/更新/升级,前台就要重新部署,这明显不服务我们拆分的理念,特别当前台是移动应用的时候,通常业务变化的节奏更快。另外,N个小服务的调用也是一个不小的网络开销。还有一般微服务在系统内部,通常是无状态的,用户登录信息和权限管理最好有一个统一的地方维护管理(OAuth)。
所以,一般在后台N个服务和UI之间一般会一个代理或者叫API Gateway,他的作用包括
- 提供统一服务入口,让微服务对前台透明
- 聚合后台的服务,节省流量,提升性能
- 提供安全,过滤,流控等API管理功能
我的理解其实这个API Gateway可以有很多广义的实现办法,可以是一个软硬一体的盒子,也可以是一个简单MVC框架,甚至是一个Node.js的服务端。他们最重要的作用是为前台(通常是移动应用)提供后台服务的聚合,提供一个统一的服务出口,解除他们之间的耦合,不过API Gateway也有可能成为单点故障点或者性能的瓶颈。
2、 服务之间如何通信?
因为所有的微服务都是独立的Java进程跑在独立的虚拟机上,所以服务间的通行就是IPC(inter process communication),已经有很多成熟的方案。现在基本最通用的有两种方式。
- 同步调用
- REST(JAX-RS)
- RPC(Dubbo)
- 异步消息调用(Kafka, Notify, MetaQ)
一般同步调用比较简单,一致性强,但是容易出调用问题,性能体验上也会差些,特别是调用层次多的时候。RESTful和RPC的比较也是一个很有意思的话题。一般REST基于HTTP,更容易实现,更容易被接受,服务端实现技术也更灵活些,各个语言都能支持,同时能跨客户端,对客户端没有特殊的要求,只要封装了HTTP的SDK就能调用,所以相对使用的广一些。RPC也有自己的优点,传输协议更高效,安全更可控,特别在一个公司内部,如果有统一个的开发规范和统一的服务框架时,他的开发效率优势更明显些。就看各自的技术积累实际条件,自己的选择了。
而异步消息的方式在分布式系统中有特别广泛的应用,他既能减低调用服务之间的耦合,又能成为调用之间的缓冲,确保消息积压不会冲垮被调用方,同时能保证调用方的服务体验,继续干自己该干的活,不至于被后台性能拖慢。不过需要付出的代价是一致性的减弱,需要接受数据最终一致性;还有就是后台服务一般要实现幂等性,因为消息发送出于性能的考虑一般会有重复(保证消息的被收到且仅收到一次对性能是很大的考验);最后就是必须引入一个独立的broker,如果公司内部没有技术积累,对broker分布式管理也是一个很大的挑战。
3、这么多服务,怎么找?
在微服务架构中,一般每一个服务都是有多个拷贝,来做负载均衡。一个服务随时可能下线,也可能应对临时访问压力增加新的服务节点。服务之间如何相互感知?服务如何管理?这就是服务发现的问题了。一般有两类做法,也各有优缺点。基本都是通过zookeeper等类似技术做服务注册信息的分布式管理。当服务上线时,服务提供者将自己的服务信息注册到ZK(或类似框架),并通过心跳维持长链接,实时更新链接信息。服务调用者通过ZK寻址,根据可定制算法,找到一个服务,还可以将服务信息缓存在本地以提高性能。当服务下线时,ZK会发通知给服务
客户端。
-
客户端做:优点是架构简单,扩展灵活,只对服务注册器依赖。缺点是客户端要维护所有调用服务的地址,有
技术难度,一般大公司都有成熟的内部框架支持,比如Dubbo。
-
服务端做:优点是简单,所有服务对于前台调用方透明,一般在小公司在云服务上部署的应用采用的比较多。
4、这么多服务,服务挂了怎么办?
前面提到,Monolithic方式开发一个很大的风险是,把所有鸡蛋放在一个篮子里,一荣俱荣,一损俱损。而分布式最大的特性就是网络是不可靠的。通过微服务拆分能降低这个风险,不过如果没有特别的保障,结局肯定是噩梦。我们刚遇到一个线上故障就是一个很不起眼的SQL计数功能,在访问量上升时,导致数据库load彪高,影响了所在应用的性能,从而影响所有调用这个应用服务的前台应用。所以当我们的系统是由一系列的服务调用链组成的时候,我们必须确保任一环节出问题都不至于影响整体链路。相应的手段有很多:
- 重试机制
- 限流
- 熔断机制
- 负载均衡
- 降级(本地缓存)
5、分布式和微服务有什么区别?
- 分布式,就是将巨大的一个系统划分为多个模块,这一点和微服务是一样的,都是要把系统进行拆分,部署到不同机器上,因为一台机器可能承受不了这么大的访问压力,或者说要支撑这么大的访问压力需要采购一台性能超级好的服务器,其财务成本非常高,有这些预算完全可以采购很多台普通的服务器了,分布式系统各个模块通过接口进行数据交互,其实分布式也是一种微服务,因为都是把模块拆分变为独立的单元,提供接口来调用,那么它们本质的区别是什么?
- 它们的本质的区别体现在“目标”上, 何为目标,就是你采用分布式架构或者采用微服务架构,你最终是为了什么,要达到什么目的?
- 分布式架构的目标是什么?就是访问量很大一台机器承受不了,或者是成本问题,不得不使用多台机器来完成服务的部署;
- 而微服务的目标是什么?只是让各个模块拆分开来,不会被互相影响,比如模块的升级或者出现BUG或者是重构等等都不要影响到其他模块,微服务它是可以在一台机器上部署;
- 但是:分布式也是微服务的一种,微服务也属于分布式;
6、微服务与Spring Cloud的关系或区别?
微服务只是一种项目的架构方式、架构理念,或者说是一种概念,就如同我们的MVC架构一样, 那么Spring Cloud便是对这种架构方式的技术落地实现;
7、微服务一定要使用Spring Cloud吗?
微服务只是一种项目的架构方式、架构理念,所以任何技术都可以实现这种架构理念,只是微服务架构里面有很多问题需要我们去解决,比如:负载均衡,服务的注册与发现,服务调用,服务路由,服务熔断等等一系列问题,如果你自己从0开始实现微服务的架构理念,那头发都掉光了,所以Spring Cloud 帮我们做了这些事情,Spring Cloud将处理这些问题的的技术全部打包好了,我们只需要开箱即用;
8、什么是Spring Cloud?
官方解释:Spring Cloud是一系列框架的有序集合。它利用Spring Boot的开发便利性巧妙地简化了分布式系统基础设施的开发,如服务发现注册、配置中心、消息总线、负载均衡、断路器、数据监控等,都可以用Spring Boot的开发风格做到一键启动和部署。Spring Cloud并没有重复制造轮子,它只是将各家公司开发的比较成熟、经得起实际考验的服务框架组合起来,通过Spring Boot风格进行再封装屏蔽掉了复杂的配置和实现原理,最终给开发者留出了一套简单易懂、易部署和易维护的分布式系统开发工具包。
9、SpringCloud 五大基本组件
服务发现-->nacos、eureka
客服端负载均衡-->ribbon、fegin
断路器-->Hystrix、Sentinel
服务网关--> Zuul、gateway
分布式配置-->config、nacos
10、Eureka的服务治理是什么?
Spring Cloud 封装了 Netflix 公司开发的 Eureka 模块来实现服务治理。
在传统的rpc远程调用框架中,管理每个服务与服务之间依赖关系比较复杂,管理比较复杂,所以需要使用服务治理,管理服务于服务之间依赖关系,可以实现服务调用、负载均衡、容错等,实现服务发现与注册。
11、Eureka的服务注册是什么?
Eureka采用了CS的设计架构,Eureka Server 作为服务注册功能的服务器,它是服务注册中心。而系统中的其他微服务,使用 Eureka的客户端连接到 Eureka Server并维持心跳连接。这样系统的维护人员就可以通过 Eureka Server 来监控系统中各个微服务是否正常运行。
在服务注册与发现中,有一个注册中心。当服务器启动的时候,会把当前自己服务器的信息 比如 服务地址通讯地址等以别名方式注册到注册中心上。另一方(消费者|服务提供者),以该别名的方式去注册中心上获取到实际的服务通讯地址,然后再实现本地RPC调用。RPC远程调用框架核心设计思想:在于注册中心,因为使用注册中心管理每个服务与服务之间的一个依赖关系(服务治理概念)。在任何rpc远程框架中,都会有一个注册中心(存放服务地址相关信息(接口地址))

12 、Eureka如何获取服务信息?
通过服务发现的方式获取,自动装配DiscoveryClient,调用里面方法即可
//获取所有服务
List<String> services = discoveryClient.getServices();
//指定服务名获取对应的信息
List<ServiceInstance> instances = discoveryClient.getInstances("XIAOBEAR-CLOUD-PAYMENT-SERVICE");
13、Eureka的自我保护模式是什么?
默认情况下,如果EurekaServer在一定时间内没有接收到某个微服务实例的心跳,EurekaServer将会注销该实例(默认90秒)。但是当网络分区故障发生(延时、卡顿、拥挤)时,微服务与EurekaServer之间无法正常通信,以上行为可能变得非常危险了——因为微服务本身其实是健康的,此时本不应该注销这个微服务。Eureka通过“自我保护模式”来解决这个问题——当EurekaServer节点在短时间内丢失过多客户端时(可能发生了网络分区故障),那么这个节点就会进入自我保护模式。
在自我保护模式中,Eureka Server会保护服务注册表中的信息,不再注销任何服务实例。
它的设计哲学就是宁可保留错误的服务注册信息,也不盲目注销任何可能健康的服务实例。一句话讲解:好死不如赖活着.
综上,自我保护模式是一种应对网络异常的安全保护措施。它的架构哲学是宁可同时保留所有微服务(健康的微服务和不健康的微服务都会保留)也不盲目注销任何健康的微服务。使用自我保护模式,可以让Eureka集群更加的健壮、稳定。
14、Eureka、Consul、Zookeeper三者都是注册中心,有什么区别?
| Eureka | Consul | Zookeeper | |
|---|---|---|---|
| 语言 | Java | Go | Java |
| CAP | AP | CP | CP |
| 服务健康检查 | 可配置支持 | 支持 | 支持 |
| 对外暴露接口 | HTTP | HTTP/DNS | 客户端 |
| Spring Cloud | 可集成 | 可集成 | 可集成 |
CAP
- C:consistency(强一致性)
- A:Availability(可用性)
- P:Partition tolerance(分区容错性)
15、CAP理论
C:一致性,这里指的强一致性,也就是数据更新完,访问任何节点看到的数据完全一致
A:可用性,就是任何没有发生故障的服务必须在规定时间内返回合正确结果
P:容灾性,当网络不稳定时节点之间无法通信,造成分区,这时要保证系统可以继续正常服务。提高容灾性的办法就是把数据分配到每一个节点当中,所以P是分布式系统必须实现的,然后需要在C和A中取舍
16、为什么不能同时保证一致性和可用性呢?
当网络发生故障时,如果要保障数据一致性,那么节点相互间就只能阻塞等待数据真正同步时再返回,就违背可用性了。如果要保证可用性,节点要在有限时间内将结果返回,无法等待其它节点的更新消息,此时返回的数据可能就不是最新数据,就违背了一致性了
17、Nacos
主要提供的功能是:
- 作为微服务的注册中心,提供服务的注册与发现功能
- 作为微服务的分布式配置中心,提供统一配置管理,动态配置修改等功能
1、nacos的注册表结构
Nacos最外层是namespace隔离环境,然后是group对服务进行分组,然后就是服务,一个服务下 有多个集群,集群下有多个实例。
对应Java代码,Map<String,Map<String,Service>>,最外层的key是namespaceId,值是map,内部map大的key是group拼接serviceName(group@@serviceName),值是service对象;service对象内部又是一个map,key是集群名称,值是Cluster对象,Cluster对象内部维护了实例对象集合。
2、消费者是如何调用提供者的
通过创建RestTemplate对象来实现。
3、Nacos和Eureka区别
| Nacos | Eureka | |
|---|---|---|
| 服务发现 | Nacos采用定时拉取和订阅推送两种模式 | Eureka只支持定时拉取模式 |
| 实例类型 | Nacos有永久实例和临时实例两种 | Eureka 只有临时实例 |
| 健康检测 | Nacos对临时实例采用心跳检测,对永久实例采用主动请求 | Eureka 只支持心跳模式 |
4、负载均衡通过什么实现
通过Ribbon实现,Ribbon中定义了负载均衡算法,然后基于这些算法从服务实例中获取一个实例为想要服务方提供服务
5、项目中为什么要定义bootstarp.yml文件?
此文件被读取的优先级比较高,在服务启动时读取配置中心的数据
6、nacos配置中心宕机了,我们的服务还可以读取到配置信息吗?
可以从内存,客户端获取配置信息后,会将配置信息在本地保存一份
7、nocosCAP
Nacos的 CP 和 AP 架构的选择,取决于我们配置的服务实例是临时实例还是持久实例
spring:
cloud:
nacos:
discovery:
ephemeral: false //false:持久化实例,使用 CP架构;true:临时实例,使用 AP架构
18、Config
1、什么是Spring Cloud Config?
SpringCloud Config为微服务架构中的微服务提供集中化的外部配置支持,配置服务器为各个不同微服务应用的所有环境提供了一个中心化的外部配置。
SpringCloud Config分为服务端和客户端两部分。
- 服务端也称为分布式配置中心,它是一个独立的微服务应用,用来连接配置服务器并为客户端提供获取配置信息,加密/解密信息等访问接口
- 客户端则是通过指定的配置中心来管理应用资源,以及与业务相关的配置内容,并在启动的时候从配置中心获取和加载配置信息配置服务器默认采用git来存储配置信息,这样就有助于对环境配置进行版本管理,并且可以通过git客户端工具来方便的管理和访问配置内容。
2、Spring Cloud Config有什么作用?
集中管理配置文件
不同环境不同配置,动态化的配置更新,分环境部署,比如/dev、/test、/prod、/beta、/release
运行期间动态调整配置,不再需要在每个服务部署的机器上编写配置文件,服务会向配置中心统一拉取配置自己的信息
当配置发生变动时,服务不需要重启即可感知到配置的变化并应用新的配置
将配置信息以REST接口的形式暴露
post、curl访问刷新即可
3、Spring Cloud Config怎么读取配置文件?
/{application}/{profile}[/{label}] /{application}-{profile}.yml /{label}/{application}-{profile}.yml /{application}-{profile}.properties /{label}/{application}-{profile}.properties
其中“应用程序”作为SpringApplication中的spring.config.name注入(即常规Spring Boot应用程序中通常为“应用程序”),“配置文件”是活动配置文件(或逗号分隔列表)的属性),“label”是可选的git标签(默认为“master”)
label:分支(branch)
name :服务名
profiles:环境(dev/test/prod)
4、Spring Cloud Config修改配置文件,如何动态刷新?
配合Spring Cloud Bus实现配置的动态的刷新
19、Ribbon\Fegin
1、什么是Ribbon
Spring Cloud Ribbon是基于Netflix Ribbon实现的一套客户端负载均衡的工具。
简单的说,Ribbon是Netflix发布的开源项目,主要功能是提供客户端的软件负载均衡算法和服务调用。Ribbon客户端组件提供一系列完善的配置项如连接超时,重试等。简单的说,就是在配置文件中列出Load Balancer(简称LB)后面所有的机器,Ribbon会自动的帮助你基于某种规则(如简单轮询,随机连接等)去连接这些机器。
2、Ribbon内置的负载均衡策略有哪些?(7种)
(1)RoundRobinRule轮询(默认):
第一次到A,第二次就到B,第三次又到A,第四次又到B…
具体实现是一个负载均衡算法:第N次请求 % 服务器集群的总数 = 实际调用服务器位置的下标
那么怎么保证线程安全问题呢?因为N次请求次数会自增,怎么保证不会多次请求都拿到同一个N进行自增?答案就是简单的CAS

(2)RandomRule随机
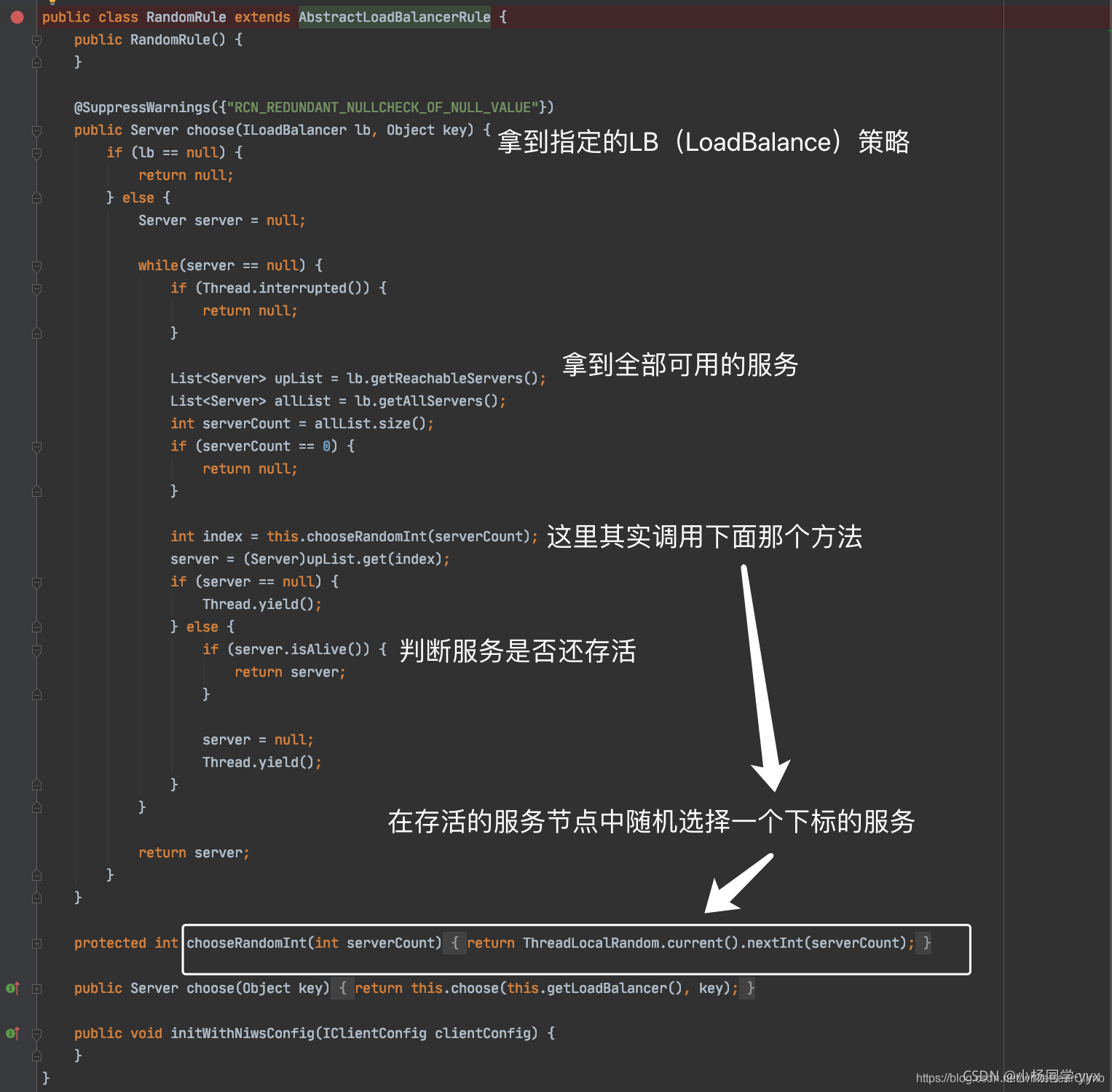
(3)RetryRule轮询重试(重试采用的默认也是轮询)
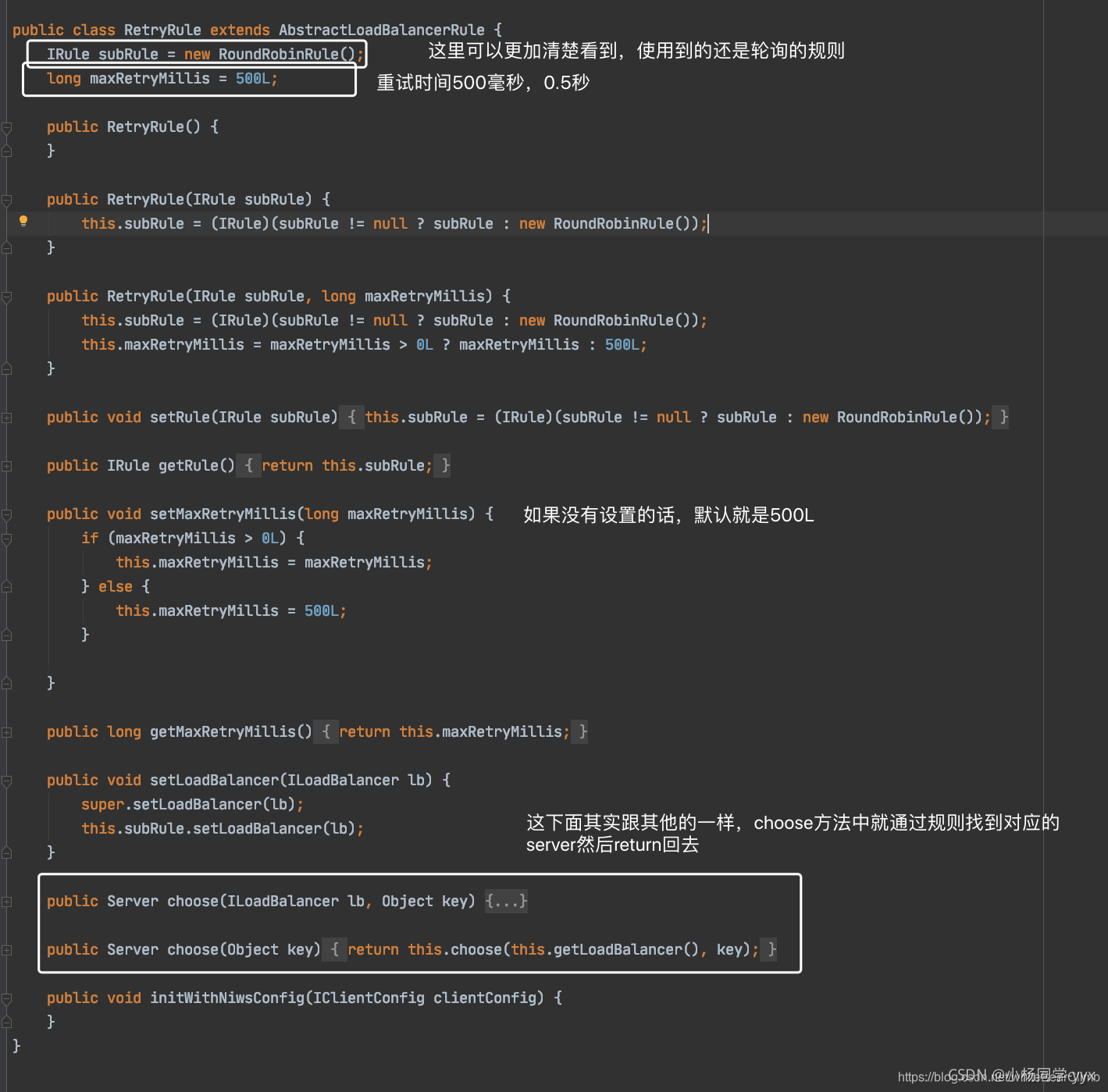
(4)WeightedResponseTimeRule响应速度决定权重:
其实是对RoundRobbin的一种增强,加入了权重和计算响应时间的概念,其中响应速度最快的权重越大,权重越大则选中的概率越大。
(5)BestAvailableRule最优可用(底层也有RoundRobinRule):
最优可用,判断最优其实用的是并发连接数。选择并发连接数较小的server发送请求。
(6)AvailabilityFilteringRule可用性过滤规则(底层也有RoundRobinRule):
可用过滤规则,其实它功能是先过滤掉不可用的Server实例,再选择并发连接最小的实例。
(7)ZoneAvoidanceRule区域内可用性能最优:
基于AvailabilityFilteringRule基础上做的,首先判断一个zone的运行性能是否可用,剔除不可用的区域zone的所有server,然后再利用AvailabilityPredicate过滤并发连接过多的server。
3、@LoadBalanced注解的作用是什么?
答:描述Restemplate对象,用于告诉spring框架,在使用RestTemplate进行服务调用时,这个调用过程会被一个拦截器进行拦截,然后在拦截器内部,启动负载均衡策略
4、ribbon和feign区别
Ribbon添加maven依赖 spring-starter-ribbon 使用@RibbonClient(value="服务名称") 使用RestTemplate调用远程服务对应的方法。
feign添加maven依赖 spring-starter-feign 服务提供方提供对外接口 调用方使用 在接口上使用@FeignClient("指定服务名")
Ribbon和Feign的区别:
Ribbon和Feign都是用于调用其他服务的,不过方式不同。
启动类使用的注解不同,Ribbon用的是@RibbonClient,Feign用的@EnableFeignClients。
服务的指定位置不同,Ribbon是在@RibbonClient注解上声明,Feign则是在定义抽象方法的接口中使用@FeignClient声明。
调用方式不同,Ribbon需要自己构建http请求,模拟http请求然后使用RestTemplate发送给其他服务,步骤相当繁琐。
Feign则是在Ribbon的基础上进行了一次改进,采用接口的方式,将需要调用的其他服务的方法定义成抽象方法即可,
不需要自己构建http请求。不过要注意的是抽象方法的注解、方法签名要和提供服务的方法完全一致。
5、Spring Cloud Feign是什么?
Feign是一个声明式WebService客户端。使用Feign能让编写Web Service客户端更加简单。
它的使用方法是定义一个服务接口然后在上面添加注解。Feign也支持可拔插式的编码器和解码器。Spring Cloud对Feign进行了封装,使其支持了Spring MVC标准注解和HttpMessageConverters。Feign可以与Eureka和Ribbon组合使用以支持负载均衡
6、Feign与OpenFeign的区别?
| Feign | OpenFeign |
|---|---|
| Feign是Spring Cloud组件中的一个轻量级RESTful的HTTP服务客户端;Feign内置了Ribbon,用来做客户端负载均衡,去调用服务注册中心的服务。Feign的使用方式是:使用Feign的注解定义接口,调用这个接口,就可以调用服务注册中心的服务 | OpenFeign是Spring Cloud 在Feign的基础上支持了SpringMVC的注解,如@RequesMapping等等。OpenFeign的@FeignClient可以解析SpringMVC的@RequestMapping注解下的接口,并通过动态代理的方式产生实现类,实现类中做负载均衡并调用其他服务。 |
| <dependency> <groupId>org.springframework.cloud |
7、OpenFeign的超时控制你了解?
默认Feign客户端只等待一秒钟,但是服务端处理需要超过1秒钟,导致Feign客户端不想等待了,直接返回报错。
为了避免这样的情况,有时候我们需要设置Feign客户端的超时控制。
#设置feign客户端超时时间(OpenFeign默认支持ribbon)
ribbon:
#指的是建立连接所用的时间,适用于网络状况正常的情况下,两端连接所用的时间
ReadTimeout: 5000
#指的是建立连接后从服务器读取到可用资源所用的时间
ConnectTimeout: 5000
20、Hystrix、Sentinel
hystrix注重隔离;Sentinel注重限流;
1、什么是服务熔断和服务降级?
- 熔断机制是应对雪崩效应的一种微服务链路保护机制。当某个微服务不可用或者响应时间太长时,会进行服务降级,进而熔断该节点微服务的调用,快速返回“错误”的响应信息。当检测到该节点微服务调用响应正常后恢复调用链路。在SpringCloud框架里熔断机制通过Hystrix实现,Hystrix会监控微服务间调用的状况,当失败的调用到一定阈值,缺省是5秒内调用20次,如果失败,就会启动熔断机制。
- 服务降级,一般是从整体负荷考虑。就是当某个服务熔断之后,服务器将不再被调用,此时客户端可以自己准备一个本地的fallback回调,返回一个缺省值。这样做,虽然会出现局部的错误,但可以避免因为一个服务挂机,而影响到整个架构的稳定性。
Hystrix相关注解:
@EnableHystrix:开启熔断
@HystrixCommand(fallbackMethod=”XXX”):声明一个失败回滚处理函数XXX,当被注解的方法执行超时(默认是1000毫秒),就会执行fallback函数,返回错误提示。
2、Hystrix实现延迟和容错的方法有哪些?
- 包裹请求:使用HystrixCommand包裹对依赖的调用逻辑,每个命令在独立线程中执行。这使用了设计模式中的“命令模式”。
- 跳闸机制:当某服务的错误率超过一定的阈值时,Hystrix可以自动或手动跳闸,停止请求该服务一段时间。
- 资源隔离:Hystrix为每个依赖都维护了一个小型的线程池(或者信号量)。如果该线程池已满,发往该依赖的请求就被立即拒绝,而不是排队等待,从而加速失败判定。
- 监控:Hystrix可以近乎实时地监控运行指标和配置的变化,例如成功、失败、超时、以及被拒绝的请求等。
- 回退机制:当请求失败、超时、被拒绝,或当断路器打开时,执行回退逻辑。回退逻辑由开发人员自行提供,例如返回一个缺省值。
- 自我修复:断路器打开一段时间后,会自动进入“半开”状态。
3、雪崩效应,你了解吗?
在微服务架构中,一个请求需要调用多个服务是非常常见的。如客户端访问A服务,而A服务需要调用B服务,B服务需要调用C服务,由于网络原因或者自身的原因,如果B服务或者C服务不能及时响应,A服务将处于阻塞状态,直到B服务C服务响应。此时若有大量的请求涌入,容器的线程资源会被消耗完毕,导致服务瘫痪。服务与服务之间的依赖性,故障会传播,造成连锁反应,会对整个微服务系统造成灾难性的严重后果,这就是服务故障的“雪崩”效应。
造成雪崩效应的原因:
- 单个服务的代码存在bug
- 请求访问量激增导致服务发生崩溃(如大型商城的枪红包,秒杀功能)
- 服务器的硬件故障也会导致部分服务不可用



4、服务熔断,你了解吗?
类比保险丝达到最大的服务访问后,直接拒绝访问,拉闸限电,然后调用服务降级的方法并返回友好提示
就相当于保险丝,服务的降级-----》进而熔断-----》恢复调用链路
5、服务降级,你了解吗?
所谓降级,就是当某个服务熔断之后,服务器将不再被调用,此时客户端可以自己准备一个本地的fallback回调,返回一个缺省值。也可以理解为兜底方法。
会发生降级的情况
- 程序运行异常
- 超时
- 服务熔断触发服务降级
- 线程池、信号量打满也会导致服务降级
6、服务限流,你了解吗?
限流可以认为服务降级的一种,限流就是限制系统的输入和输出流量已达到保护系统的目的。一般来说系统的吞吐量是可以被测算的,为了保证系统的稳固运行,一旦达到的需要限制的阈值,就需要限制流量并采取少量措施以完成限制流量的目的。比方:推迟解决,拒绝解决,或者者部分拒绝解决等等。秒杀高并发等操作,严禁一窝蜂的一样拥挤,排队有序进行,一秒钟N个,有序进行
7、Hystrix工作流程?

| 序号 | 操作 |
|---|---|
| 1 | 创建 HystrixCommand(用在依赖的服务返回单个操作结果的时候) 或 HystrixObserableCommand(用在依赖的服务返回多个操作结果的时候) 对象。 |
| 2 | 命令执行。其中 HystrixComand 实现了下面前两种执行方式;而 HystrixObservableCommand 实现了后两种执行方式:execute():同步执行,从依赖的服务返回一个单一的结果对象, 或是在发生错误的时候抛出异常。queue():异步执行, 直接返回 一个Future对象, 其中包含了服务执行结束时要返回的单一结果对象。observe():返回 Observable 对象,它代表了操作的多个结果,它是一个 Hot Obserable(不论 "事件源" 是否有 "订阅者",都会在创建后对事件进行发布,所以对于 Hot Observable 的每一个 "订阅者" 都有可能是从 "事件源" 的中途开始的,并可能只是看到了整个操作的局部过程)。toObservable():同样会返回 Observable 对象,也代表了操作的多个结果,但它返回的是一个Cold Observable(没有 "订阅者" 的时候并不会发布事件,而是进行等待,直到有 "订阅者" 之后才发布事件,所以对于 Cold Observable 的订阅者,它可以保证从一开始看到整个操作的全部过程)。 |
| 3 | 若当前命令的请求缓存功能是被启用的, 并且该命令缓存命中, 那么缓存的结果会立即以 Observable 对象的形式 返回。 |
| 4 | 检查断路器是否为打开状态。如果断路器是打开的,那么Hystrix不会执行命令,而是转接到 fallback 处理逻辑(第 8 步);如果断路器是关闭的,检查是否有可用资源来执行命令(第 5 步)。 |
| 5 | 线程池/请求队列/信号量是否占满。如果命令依赖服务的专有线程池和请求队列,或者信号量(不使用线程池的时候)已经被占满, 那么 Hystrix 也不会执行命令, 而是转接到 fallback 处理逻辑(第8步)。 |
| 6 | Hystrix 会根据我们编写的方法来决定采取什么样的方式去请求依赖服务。HystrixCommand.run() :返回一个单一的结果,或者抛出异常。HystrixObservableCommand.construct():返回一个Observable 对象来发射多个结果,或通过 onError 发送错误通知。 |
| 7 | Hystrix会将 "成功"、"失败"、"拒绝"、"超时" 等信息报告给断路器, 而断路器会维护一组计数器来统计这些数据。断路器会使用这些统计数据来决定是否要将断路器打开,来对某个依赖服务的请求进行 "熔断/短路"。 |
| 8 | 当命令执行失败的时候, Hystrix 会进入 fallback 尝试回退处理, 我们通常也称该操作为 "服务降级"。而能够引起服务降级处理的情况有下面几种:第4步:当前命令处于"熔断/短路"状态,断路器是打开的时候。第5步:当前命令的线程池、 请求队列或 者信号量被占满的时候。第6步:HystrixObservableCommand.construct() 或 HystrixCommand.run() 抛出异常的时候。 |
| 9 | 当Hystrix命令执行成功之后, 它会将处理结果直接返回或是以Observable 的形式返回。 |
tips:如果我们没有为命令实现降级逻辑或者在降级处理逻辑中抛出了异常, Hystrix 依然会返回一个 Observable 对象, 但是它不会发射任何结果数据, 而是通过 onError 方法通知命令立即中断请求,并通过onError()方法将引起命令失败的异常发送给调用者。
8、熔断限流的理解?
SprngCloud中用Hystrix组件来进行降级、熔断、限流
熔断是对于消费者来讲,当对提供者请求时间过久时为了不影响性能就对链接进行熔断,
限流是对于提供者来讲,为了防止某个消费者流量太大,导致其它更重要的消费者请求无法及时处理。限流可用通过拒绝服务、服务降级、消息队列延时处理、限流算法来实现
9、常用限流算法
计数器算法:使用redis的setnx和过期机制实现
漏桶算法:一般使用消息队列来实现,系统以恒定速度处理队列中的请求,当队列满的时候开始拒绝请求。
令牌桶算法:计数器算法和漏桶算法都无法解决突然的大并发,令牌桶算法是预先往桶中放入一定数量token,然后用恒定速度放入token直到桶满为止,所有请求都必须拿到token才能访问系统
21、Gateway 、Zuul
1、什么是Spring Cloud Zuul?
Zuul是对SpringCloud提供的成熟对的路由方案,他会根据请求的路径不同,网关会定位到指定的微服务,并代理请求到不同的微服务接口,他对外隐蔽了微服务的真正接口地址。三个重要概念:动态路由表,路由定位,反向代理
- 动态路由表:Zuul支持Eureka路由,手动配置路由,这俩种都支持自动更新
- 路由定位:根据请求路径,Zuul有自己的一套定位服务规则以及路由表达式匹配
- 反向代理:客户端请求到路由网关,网关受理之后,在对目标发送请求,拿到响应之后在 给客户端
2、Zuul的应用场景有哪些?
对外暴露,权限校验,服务聚合,日志审计
3、网关与过滤器有什么区别?
网关是对所有服务的请求进行分析过滤,过滤器是对单个服务而言
4、Zuul与Nginx有什么区别?
- Zuul是java语言实现的,主要为java服务提供网关服务,尤其在微服务架构中可以更加灵活的对网关进行操作。
- Nginx是使用C语言实现,性能高于Zuul,但是实现自定义操作需要熟悉lua语言,对程序员要求较高,可以使用Nginx做Zuul集群。
5、ZuulFilter常用有那些方法?
-
Run():过滤器的具体业务逻辑
-
shouldFilter():判断过滤器是否有效
-
fifilterOrder():过滤器执行顺序
-
fifilterType():过滤器拦截位置
6、什么是Spring Cloud GateWay?
- Spring Cloud Gateway 作为 Spring Cloud 生态系统中的网关,目标是替代 Zuul,在Spring Cloud 2.0以上版本中,没有对新版本的Zuul 2.0以上最新高性能版本进行集成,仍然还是使用的Zuul 1.x非Reactor模式的老版本。
- 而为了提升网关的性能,SpringCloud Gateway是基于WebFlux框架实现的,而WebFlux框架底层则使用了高性能的Reactor模式通信框架Netty。
- Spring Cloud Gateway的目标提供统一的路由方式且基于 Filter 链的方式提供了网关基本的功能,例如:安全,监控/指标,和限流。
7、为什么我们选择GateWay?
netflix不靠谱,迟迟不发布
因为Zuul1.0已经进入了维护阶段,而且Gateway是SpringCloud团队研发的,是亲儿子产品,值得信赖。而且很多功能Zuul都没有用起来也非常的简单便捷。
Gateway是基于异步非阻塞模型上进行开发的,性能方面不需要担心。虽然Netflix早就发布了最新的 Zuul 2.x,但 Spring Cloud 貌似没有整合计划。而且Netflix相关组件都宣布进入维护期;不知前景如何?
多方面综合考虑Gateway是很理想的网关选择。
Spring Cloud GateWay有很多特性
- 基于Spring Framework 5, Project Reactor 和 Spring Boot 2.0 进行构建;
- 动态路由:能够匹配任何请求属性;
- 可以对路由指定 Predicate(断言)和 Filter(过滤器);
- 集成Hystrix的断路器功能;
- 集成 Spring Cloud 服务发现功能;
- 易于编写的 Predicate(断言)和 Filter(过滤器);
- 请求限流功能;
- 支持路径重写。
8、Spring Cloud Gateway 与 Zuul的区别?
- Zuul 1.x,是一个基于阻塞 I/ O 的 API Gateway
- Zuul 1.x 基于Servlet 2. 5使用阻塞架构它不支持任何长连接(如 WebSocket) Zuul 的设计模式和Nginx较像,每次 I/ O 操作都是从工作线程中选择一个执行,请求线程被阻塞到工作线程完成,但是差别是Nginx 用C++ 实现,Zuul 用 Java 实现,而 JVM 本身会有第一次加载较慢的情况,使得Zuul 的性能相对较差。
- Zuul 2.x理念更先进,想基于Netty非阻塞和支持长连接,但SpringCloud目前还没有整合。Zuul 2.x的性能较 Zuul 1.x 有较大提升。在性能方面,根据官方提供的基准测试, Spring Cloud Gateway 的 QPS(每秒请求数)是Zuul 的 1. 6 倍。
- Spring Cloud Gateway 建立 在 Spring Framework 5、 Project Reactor 和 Spring Boot 2 之上, 使用非阻塞 API。
- Spring Cloud Gateway 还 支持 WebSocket, 并且与Spring紧密集成拥有更好的开发体验
9、Spring Cloud GateWay工作流程?

客户端向 Spring Cloud Gateway 发出请求。然后在 Gateway Handler Mapping 中找到与请求相匹配的路由,将其发送到 Gateway Web Handler。
Handler 再通过指定的过滤器链来将请求发送到我们实际的服务执行业务逻辑,然后返回。
过滤器之间用虚线分开是因为过滤器可能会在发送代理请求之前(“pre”)或之后(“post”)执行业务逻辑。
Filter在“pre”类型的过滤器可以做参数校验、权限校验、流量监控、日志输出、协议转换等,
在“post”类型的过滤器中可以做响应内容、响应头的修改,日志的输出,流量监控等有着非常重要的作用。
核心逻辑:路由转发+执行过滤链
10、Spring Cloud GateWay网关配置的两种方式?
- yaml配置
server:
port: 9527
spring:
application:
name: xiaobear-cloud-gateway
cloud:
gateway:
routes:
- id: payment_routh
#payment_route
#路由的ID,没有固定规则但要求唯一,建议配合服务名
uri: http://localhost:8001
#匹配后提供服务的路由地址
predicates: - Path=/payment/selectOne/**
# 断言,路径相匹配的进行路由
- id: payment_routh2
#payment_route
#路由的ID,没有固定规则但要求唯一,建议配合服务名
uri: http://localhost:8001
#匹配后提供服务的路由地址
predicates: - Path=/payment/payment/lb/**
# 断言,路径相匹配的进行路由
- 代码中注入RouteLocator的Bean
@Configuration
public class GateWayConfig {
@Bean
public RouteLocator customRouteLocator(RouteLocatorBuilder routeBuilder){
return routeBuilder.routes().route("xiaobear-config",r -> r.path("/spring-cloud-gateway-configuration").uri("https://www.bilibili.com/video/BV18E411x7eT")).build();
}
}
11、Spring Cloud GateWay常用的断言方式有哪些?
- After Route Predicate Factory:表示在这个时区里的时间点才允许访问,时间格式为Java 8新特性的时区时间格式
ZonedDateTime zbj = ZonedDateTime.now(); // 默认时区
ZonedDateTime zny = ZonedDateTime.now(ZoneId.of("America/New_York")); // 用指定时区获取当前时间
spring:
application:
name: xiaobear-cloud-gateway
cloud:
gateway:
routes:
- id: payment_routh2
#payment_route
#路由的ID,没有固定规则但要求唯一,建议配合服务名
uri: lb://XIAOBEAR-CLOUD-PAYMENT-SERVICE #uri: http://localhost:8001
#匹配后提供服务的路由地址
predicates: - Path=/payment/payment/lb/** # 断言,路径相匹配的进行路由
- After=2021-05-24T15:17:53.623+08:00[Asia/Shanghai] # 断言,路径相匹配的进行路由
- Before Route Predicate Factory:在时间点前才允许访问
spring:
application:
name: xiaobear-cloud-gateway
cloud:
gateway:
routes:
- id: payment_routh2 #payment_route
#路由的ID,没有固定规则但要求唯一,建议配合服务名
uri: lb://XIAOBEAR-CLOUD-PAYMENT-SERVICE #uri: http://localhost:8001
#匹配后提供服务的路由地址
predicates: - Path=/payment/payment/lb/** # 断言,路径相匹配的进行路由
- Before=2021-05-24T15:17:53.623+08:00[Asia/Shanghai] # 断言,路径相匹配的进行路由
- Between Route Predicate Factory:在两者之间
spring:
application:
name: xiaobear-cloud-gateway
cloud:
gateway:
routes:
- id: payment_routh2 #payment_route
#路由的ID,没有固定规则但要求唯一,建议配合服务名
uri: lb://XIAOBEAR-CLOUD-PAYMENT-SERVICE #uri: http://localhost:8001
#匹配后提供服务的路由地址
predicates: - Path=/payment/payment/lb/**
# 断言,路径相匹配的进行路由
- Between=2021-05-24T15:17:53.623+08:00[Asia/Shanghai], 2021-05-24T15:30:53.623+08:00[Asia/Shanghai]
# 断言,路径相匹配的进行路由
- Cookie Route Predicate Factory:Cookie Route Predicate需要两个参数,一个是 Cookie name ,一个是正则表达式。
路由规则会通过获取对应的 Cookie name 值和正则表达式去匹配,如果匹配上就会执行路由,如果没有匹配上则不执行
spring: application: name: xiaobear-cloud-gateway cloud: gateway: routes: - id: payment_routh2 #payment_route #路由的ID,没有固定规则但要求唯一,建议配合服务名 uri: lb://XIAOBEAR-CLOUD-PAYMENT-SERVICE #uri: http://localhost:8001 #匹配后提供服务的路由地址 predicates: - Path=/payment/payment/lb/** # 断言,路径相匹配的进行路由 - Between=2021-05-24T15:17:53.623+08:00[Asia/Shanghai], 2021-05-24T15:30:53.623+08:00[Asia/Shanghai] # 断言,路径相匹配的进行路由
- Header Route Predicate Factory:两个参数:一个是属性名称和一个正则表达式,这个属性值和正则表达式匹配则执行。
spring: application: name: xiaobear-cloud-gateway cloud: gateway: routes: - id: payment_routh2 #payment_route #路由的ID,没有固定规则但要求唯一,建议配合服务名 uri: lb://XIAOBEAR-CLOUD-PAYMENT-SERVICE #uri: http://localhost:8001 #匹配后提供服务的路由地址 predicates: - Path=/payment/payment/lb/** # 断言,路径相匹配的进行路由 - Header=X-Request-Id, \d+ # 请求头要有X-Request-Id属性并且值为整数的正则表达式
- Host Route Predicate Factory:Host Route Predicate 接收一组参数,一组匹配的域名列表,这个模板是一个 ant 分隔的模板,用.号作为分隔符。它通过参数中的主机地址作为匹配规则
spring: application: name: xiaobear-cloud-gateway cloud: gateway: routes: - id: payment_routh2 #payment_route #路由的ID,没有固定规则但要求唯一,建议配合服务名 uri: lb://XIAOBEAR-CLOUD-PAYMENT-SERVICE #uri: http://localhost:8001 #匹配后提供服务的路由地址 predicates: - Path=/payment/payment/lb/** # 断言,路径相匹配的进行路由 - Host=**.xiaobear.com # 断言,路径相匹配的进行路由
12、什么是Spring Cloud GateWay Filter过滤?
路由过滤器可用于修改进入的HTTP请求和返回的HTTP响应,路由过滤器只能指定路由进行使用。
Spring Cloud Gateway 内置了多种路由过滤器,他们都由GatewayFilter的工厂类来产生。
13、Spring Cloud GateWay Filter过滤器的分类有哪些?
按生命周期分类
- Pre
- Post
按种类分类
- GatewayFilter Factories
- Global Filters
14、如何自定义Spring Cloud GateWay全局过滤器?
自定义全局过滤器Global Filters
主要是实现两个接口 implements GlobalFilter,Ordered
具体案例请参考:实例教程
22 什么是Spring Cloud Bus消息总线?
Spring Cloud Bus将分布式系统的节点与轻量级消息代理链接。这可以用于广播状态更改(例如配置更改)或其他管理指令。一个关键的想法是,Bus就像一个扩展的Spring Boot应用程序的分布式执行器,但也可以用作应用程序之间的通信渠道。当前唯一的实现是使用AMQP代理作为传输,但是相同的基本功能集(还有一些取决于传输)在其他传输的路线图上。
1、Spring Cloud Bus如何动态刷新全局广播?
-
利用消息总线触发一个客户端/bus/refresh,而刷新所有客户端配置
-
利用消息总线触发一个服务端ConfigServer的/bus/refresh端点,而刷新所有客户端的配置
推荐:第二个思想更合适一点,第一个不适合原因如下:
-
打破了微服务的单一职责性,因为微服务本身是业务模块,它本不应该承担配置刷新的职责
-
破坏了微服务各节点的对等性
-
有一定的局限性。比如微服务在迁移时,它的网络地址时常发生变化,这时要想做到自动刷新,那就会增加更多的修改
2、Spring Cloud Bus如何动态刷新定点通知?
不想通知所有刷新,而只是想刷新一部分配置,公式如下👇
http://localhost:配置中心的端口号/actuator/bus-refresh/{destination}
bus/refresh请求不再发送到具体的服务实例上,而是发给config server并通过destination参数类指定需要更新配置的服务或实例
示例:以刷新运行在3355端口上的config-client为例
- curl -X POST "http://localhost:3344/actuator/bus-refresh/config-client:3355"
23、Spring Cloud Stream消息驱动是什么?
屏蔽底层消息中间件的差异,降低切换成本,统一消息的编程模型;轻量级事件驱动微服务框架,可以使用简单的声明式模型来发送及接收消息,主要实现为Apache Kafka及RabbitMQ;
1、为什么Spring Cloud Stream可以统一底层差异?
在没有绑定器这个概念的情况下,我们的SpringBoot应用要直接与消息中间件进行信息交互的时候,由于各消息中间件构建的初衷不同,它们的实现细节上会有较大的差异性通过定义绑定器作为中间层,完美地实现了应用程序与消息中间件细节之间的隔离。通过向应用程序暴露统一的Channel通道,使得应用程序不需要再考虑各种不同的消息中间件实现。通过定义绑定器Binder作为中间层,实现了应用程序与消息中间件细节之间的隔离。
2、Spring Cloud Stream如何解决重复消费和持久化?
加入分组属性Group,微服务应用放置于同一个Group中,就能够保证消息只会被其中一个应用消费一次。不同的组是可以消费的,同一个组内会发生竞争关系,只有其中一个可以消费。
八、Redis系列
Redis之所以备受青睐,原因如下:
- 快速读写性能: Redis将数据存储在内存中,因此能够实现高速的读写操作,是传统数据库的数倍甚至更高。
- 多样数据结构: Redis不仅支持简单的键值存储,还提供了丰富的数据结构,可以方便地存储和处理复杂的数据。
- 持久化支持: Redis支持数据持久化,可以将内存中的数据保存到磁盘,确保数据不会因为系统重启而丢失。
- 分布式支持: Redis的分布式特性使得它可以构建高可用、高可扩展的应用系统。
1.redis为什么快?
1)完全基于内存操作
(2)数据结构简单,对数据操作简单
(3)redis执行命令是单线程的,避免了上下文切换带来的性能问题,也不用考虑锁的问题
(4) 采用了非阻塞的io多路复用机制,使用了单线程来处理并发的连接;内部采用的epoll+自己实现的事件分离器
其实Redis不是完全多线程的,在核心的网络模型中是多线程的用来处理并发连接,但是数据的操作都是单线程。Redis坚持单线程是因为Redis是的性能瓶颈是网络延迟而不是CPU,多线程对数据读取不会带来性能提升。
2、redis持久化机制
(1)快照持久化RDB
redis的默认持久化机制,通过父进程fork一个子进程,子进程将redis的数据快照写入一个临时文件,等待持久化完毕后替换上一次的rdb文件。整个过程主进程不进行任何的io操作。持久化策略可以通过save配置单位时间内执行多少次操作触发持久化。所以RDB的优点是保证redis性能最大化,恢复速度数据较快,缺点是可能会丢失两次持久化之间的数据
(2)追加持久化AOF
以日志形式记录每一次的写入和删除操作,策略有每秒同步、每次操作同步、不同步,优点是数据完整性高,缺点是运行效率低,恢复时间长
3、Redis如何实现key的过期删除?
采用的定期过期+惰性过期
定期删除 :Redis 每隔一段时间从设置过期时间的 key 集合中,随机抽取一些 key ,检查是否过期,如果已经过期做删除处理。
惰性删除 :Redis 在 key 被访问的时候检查 key 是否过期,如果过期则删除。
4、Redis数据类型应用场景
String:可以用来缓存json信息,可以用incr命令实现自增或自减的计数器
Hash:与String一样可以保存json信息
List:可以用来做消息队列,list的pop是原子性操作能一定程度保证线程安全
Set:可以做去重,比如一个用户只能参加一次活动 ;可以做交集求共友
SortSet :有序的。可以实现排行榜
5、Redis缓存穿透如何解决?
缓存穿透是指频繁请求客户端和缓存中都不存在的数据,缓存永远不生效,请求都到达了数据库。
解决方案:
(1)在接口上做基础校验,比如id<=0就拦截
(2)缓存空对象:找不到的数据也缓存起来,并设置过期时间,可能会造成短期不一致
(3)布隆过滤器:在客户端和缓存之间添加一个过滤器,拦截掉一定不存在的数据请求
6、Redis如何解决缓存击穿?
缓存击穿是值一个key非常热点,key在某一瞬间失效,导致大量请求到达数据库
解决方案:
(1)设置热点数据永不过期
(2)给缓存重建的业务加上互斥锁,缺点是性能低
7、Redis如何解决缓存雪崩?
缓存雪崩是值某一时间Key同时失效或redis宕机,导致大量请求到达数据库
解决方案:
(1)搭建集群保证高可用
(2)进行数据预热,给不同的key设置随机的过期时间
(3)给缓存业务添加限流降级,通过加锁或队列控制操作redis的线程数量
(4)给业务添加多级缓存
8、Redis分布式锁的实现原理
原理是使用setnx+setex命令来实现,但是会有一系列问题:
(1)任务时常超过缓存时间,锁自动释放。可以使用Redision看门狗解决
(2)加锁和释放锁的不是同一线程。可以在Value中存入uuid,删除时进行验证。但是要注意验证锁和删除锁也不是一个原子性操作,可以用lua脚本使之成为原子性操作
(3)不可重入。可以使用Redision解决(实现机制类似AQS,计数)
(4)redis集群下主节点宕机导致锁丢失。使用红锁解决
Redision
1.Redisson的引入
1、我们先看看之前基于setnx实现的分布式锁存在的问题: 不可重入:同一个线程无法多次获取同一把锁 不可重试:获取锁只尝试一次就返回false,没有重试机制 超时释放:锁超时释放虽然避免死锁,但是业务执行耗时较长,也会导致释放存在安全隐患 主从一致:如果redis提供了主从集群,主从同步存在延迟,当主节点宕机,如果从节点同步主中的锁数据,则会出现锁失效
2、什么Redisson?
Redisson是一个在Redis的基础上实现的Java驻内存数据网格(In-Memory Data Grid)。它不仅提供了一系列的分布式的Java常用对象,还提供了许多分布式服务,其中就包含了各种分布式锁的实现。
3、Redisson使用手册
Redission使用手册https://www.bookstack.cn/read/redisson-wiki-zh/Redisson%E9%A1%B9%E7%9B%AE%E4%BB%8B%E7%BB%8D.md里面提到了Redisson可以实现大致如下的分布式锁
4、Redisson快速入门
<!-- redis-redisson -->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.13.6</version>
</dependency>
/**
* 配置 Redisson
*/
@Configuration
public class RedisConfig {
@Bean
public RedissonClient redissonClient() {
// 配置
Config config = new Config();
config.useSingleServer().setAddress("redis://192.168.56.20:6379").setPassword("123456");
// 创建 RedissonClient 对象
return Redisson.create(config);
}
}
@Test
void testRedisson() throws Exception {
RLock anyLock = redissonClient.getLock("anyLock");
boolean isLock = anyLock.tryLock(1, 10, TimeUnit.SECONDS);
if(isLock)
try
System.out.println("执行业务");
finally
anyLock.unlock();
}
5、redision的加锁解锁流程

优点
-
互斥性。在任意时刻,只有一个客户端能持有锁,也叫唯一性。
-
不会发生死锁。即使有一个客户端在持有锁的期间崩溃而没有主动解锁,也能保证后续其他客户端能加锁。
-
防误删。加锁和解锁必须是同一个客户端,客户端自己不能把别人加的锁给解了,即不能误解锁。(业务执行时间过长,超过锁失效时间,锁被释放,第二个线程获取锁,此时第一个线程执行到释放锁代码时,不能删除第二个线程的锁)
-
看门狗机制。延长过期时间(没有设置过期时间的情况,leaseTime=-1,默认失效时间为30秒,启动看门狗线程,定时检查是否需要延长时间scheduleExpirationRenewal)。
-
具有可用性、容错性。只要大多数Redis节点正常运行,客户端就能够获取和释放锁。
-
可重入性。相同线程不需要在等待锁,而是可以直接进行相应操作
-
锁种类多样。可重入锁、公平锁、联锁、红锁、读写锁
-
可阻塞等待。
存在的问题
分布式架构中的CAP理论,分布式系统只能同时满足两个: 一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)
Redisson分布式锁是AP模式,当锁存在的redis节点宕机,可能会被误判为锁失效,或者没有加锁。(Zookeeper实现的分布式锁,是CP理论)
因为在工作中Redis都是集群部署的,所以要考虑集群节点挂掉的问题。给大家举个例子:
- A客户端请求主节点获取到了锁
- 主节点挂掉了,但是还没把锁的信息同步给其他从节点
- 由于主节点挂了,这时候开始主从切换,从节点成为主节点继续工作,但是新的主节点上,没有A客户端的加锁信息
- 这时候B客户端来加锁,因为目前是一个新的主节点,上面没有其他客户端加锁信息,所以B客户端获取锁成功
- 这时候就存在问题了,A和B两个客户端同时都持有锁,同时在执行代码,那么这时候分布式锁就失效了。
解决办法:
tradoff,分布式锁的redis采用单机部署,分布式锁专用
RedLock: RedLock算法思想,意思是不能只在一个redis实例上创建锁,应该是在多个redis实例上创建锁,n / 2 + 1,必须在大多数redis节点上都成功创建锁,才能算这个整体的RedLock加锁成功,避免说仅仅在一个redis实例上加锁而带来的问题。
如果对锁比较关注,一致性要求比较高,可以使用ZK实现的分布式锁
红锁
1:介绍
红锁本质上就是使用多个Redis做锁。例如有5个Redis,一次锁的获取,会对每个请求都获取一遍,如果获取锁成功的数量超过一半(2.5),则获取锁成功,反之失败;
释放锁也需要对每个Redis释放
2、红锁原理
- 在Redis的分布式环境中,我们假设有5个Redis master。这些节点完全互相独立,没有主从关系
- 线程1向这5个redis加锁,当加到第三个的时候,4和5加不上了;但是符合红锁的n/2+1原则,所以线程1获取到了锁;
- 当redis3挂了,此时线程1获取到了锁,正在顺序执行,
- 线程2来到了redis抢占锁,因为3挂了,1,2有锁,只有4和5可以加锁,因为我们注册的时候是5台,4和5这两台不满足n/2+1原则,抢占锁失败;
3、红锁使用说明-官网介绍
基于Redis的Redisson红锁RedissonRedLock对象实现了Redlock介绍的加锁算法。该对象也可以用来将多个RLock对象关联为一个红锁,每个RLock对象实例可以来自于不同的Redisson实例。
RLock lock1 = redissonInstance1.getLock("lock1");
RLock lock2 = redissonInstance2.getLock("lock2");
RLock lock3 = redissonInstance3.getLock("lock3");
RedissonRedLock lock = new RedissonRedLock(lock1, lock2, lock3);
// 同时加锁:lock1 lock2 lock3
// 红锁在大部分节点上加锁成功就算成功。
lock.lock();
...
lock.unlock();
大家都知道,如果负责储存某些分布式锁的某些Redis节点宕机以后,而且这些锁正好处于锁住的状态时,这些锁会出现锁死的状态。为了避免这种情况的发生,Redisson内部提供了一个监控锁的看门狗,它的作用是在Redisson实例被关闭前,不断的延长锁的有效期。默认情况下,看门狗的检查锁的超时时间是30秒钟,也可以通过修改Config.lockWatchdogTimeout来另行指定。
另外Redisson还通过加锁的方法提供了leaseTime的参数来指定加锁的时间。超过这个时间后锁便自动解开了。
RedissonRedLock lock = new RedissonRedLock(lock1, lock2, lock3);
// 给lock1,lock2,lock3加锁,如果没有手动解开的话,10秒钟后将会自动解开
lock.lock(10, TimeUnit.SECONDS);
// 为加锁等待100秒时间,并在加锁成功10秒钟后自动解开
boolean res = lock.tryLock(100, 10, TimeUnit.SECONDS);
...
lock.unlock();
4、红锁实战
注册红锁的RedissonClient
@Component
public class RedisConfig {
@Bean(name = "redissonRed1")
@Primary
public RedissonClient redissonRed1(){
Config config = new Config();
config.useSingleServer().setAddress("127.0.0.1:6379").setDatabase(0);
return Redisson.create(config);
}
@Bean(name = "redissonRed2")
public RedissonClient redissonRed2(){
Config config = new Config();
config.useSingleServer().setAddress("127.0.0.1:6380").setDatabase(0);
return Redisson.create(config);
}
@Bean(name = "redissonRed3")
public RedissonClient redissonRed3(){
Config config = new Config();
config.useSingleServer().setAddress("127.0.0.1:6381").setDatabase(0);
return Redisson.create(config);
}
@Bean(name = "redissonRed4")
public RedissonClient redissonRed4(){
Config config = new Config();
config.useSingleServer().setAddress("127.0.0.1:6382").setDatabase(0);
return Redisson.create(config);
}
@Bean(name = "redissonRed5")
public RedissonClient redissonRed5(){
Config config = new Config();
config.useSingleServer().setAddress("127.0.0.1:6383").setDatabase(0);
return Redisson.create(config);
}
}
红锁使用
package com.online.taxi.order.service.impl;
import com.online.taxi.order.constant.RedisKeyConstant;
import com.online.taxi.order.service.GrabService;
import com.online.taxi.order.service.OrderService;
import org.redisson.Redisson;
import org.redisson.RedissonRedLock;
import org.redisson.api.RLock;
import org.redisson.api.RedissonClient;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
import java.util.concurrent.TimeUnit;
@Service
public class GrabRedisRedissonRedLockLockServiceImpl implements GrabService {
// 红锁
@Autowired
@Qualifier("redissonRed1")
private RedissonClient redissonRed1;
@Autowired
@Qualifier("redissonRed2")
private RedissonClient redissonRed2;
@Autowired
@Qualifier("redissonRed3")
private RedissonClient redissonRed3;
@Autowired
@Qualifier("redissonRed4")
private RedissonClient redissonRed4;
@Autowired
@Qualifier("redissonRed5")
private RedissonClient redissonRed5;
@Autowired
OrderService orderService;
@Override
public String grabOrder(int orderId , int driverId){
System.out.println("红锁实现类");
//生成key
String lockKey = ("" + orderId).intern();
//redisson锁 单节点
// RLock rLock = redissonRed1.getLock(lockKey);
//红锁 redis son
RLock rLock1 = redissonRed1.getLock(lockKey);
RLock rLock2 = redissonRed2.getLock(lockKey);
RLock rLock3 = redissonRed3.getLock(lockKey);
RLock rLock4 = redissonRed4.getLock(lockKey);
RLock rLock5 = redissonRed5.getLock(lockKey);
RedissonRedLock rLock = new RedissonRedLock(rLock1,rLock2,rLock3,rLock4,rLock5);
try {
/**红锁
* waitTimeout 尝试获取锁的最大等待时间,超过这个值,则认为获取锁失败
* leaseTime 锁的持有时间,超过这个时间锁会自动失效(值应设置为大于业务处理的时间,确保在锁有效期内业务能处理完)
*/
boolean b1 = rLock.tryLock((long)waitTimeout, (long)leaseTime, TimeUnit.SECONDS);
if (b1){
System.out.println("加锁成功");
// 此代码默认 设置key 超时时间30秒,过10秒,再延时
System.out.println("司机:"+driverId+" 执行抢单逻辑");
boolean b = orderService.grab(orderId, driverId);
if(b) {
System.out.println("司机:"+driverId+" 抢单成功");
}else {
System.out.println("司机:"+driverId+" 抢单失败");
}
System.out.println("加锁成功");
}else {
System.out.println("加锁失败");
}
} finally {
rLock.unlock();
}
return null;
}
}
9、Redis集群方案
(1)主从模式:个master节点,多个slave节点,master节点宕机slave自动变成主节点
(2)哨兵模式:在主从集群基础上添加哨兵节点或哨兵集群,用于监控master节点健康状态,通过投票机制选择slave成为主节点
(3)分片集群:主从模式和哨兵模式解决了并发读的问题,但没有解决并发写的问题,因此有了分片集群。分片集群有多个master节点并且不同master保存不同的数据,master之间通过ping相互监测健康状态。客户端请求任意一个节点都会转发到正确节点,因为每个master都被映射到0-16384个插槽上,集群的key是根据key的hash值与插槽绑定
10、Redis集群主从同步原理
主从同步第一次是全量同步:slave第一次请求master节点会根据replid判断是否是第一次同步,是的话master会生成RDB发送给slave。
后续为增量同步:在发送RDB期间,会产生一个缓存区间记录发送RDB期间产生的新的命令,slave节点在加载完后,会持续读取缓存区间中的数据
11、Redis缓存一致性解决方案
Redis缓存一致性解决方案主要思考的是删除缓存和更新数据库的先后顺序
先删除缓存后更新数据库存在的问题是可能会数据不一致,一般使用延时双删来解决,即先删除缓存,再更新数据库,休眠X秒后再次淘汰缓存。第二次删除可能导致吞吐率降低,可以考虑进行异步删除。
先更新数据库后删除缓存存在的问题是会可能会更新失败,可以采用延时删除。但由于读比写快,发生这一情况概率较小。
但是无论哪种策略,都可能存在删除失败的问题,解决方案是用中间件canal订阅binlog日志提取需要删除的key,然后另写一段非业务代码去获取key并尝试删除,若删除失败就把删除失败的key发送到消息队列,然后进行删除重试。
12、Redis内存淘汰策略
当内存不足时按设定好的策略进行淘汰,策略有(1)淘汰最久没使用的(2)淘汰一段时间内最少使用的(3)淘汰快要过期的
13、应用场景
- 缓存: 作为高性能缓存,加速热门数据的读取,减轻数据库压力。
- 会话存储: 存储用户会话信息,支持快速的用户认证和状态管理。
- 排行榜和计数器: 统计热门内容、用户活跃度等数据,快速计算排名和增减计数。
- 消息队列: 作为轻量级消息队列,支持任务异步处理和解耦系统组件。

14、Redis 用作缓存时
1 作为缓存使用流程
在典型的缓存场景中,应用程序首先检查 Redis 缓存中是否存在所需数据。如果缓存命中(数据存在于 Redis 中),则直接从 Redis 获取数据,避免了昂贵的数据库查询。如果缓存未命中,则从数据库中读取数据,并将数据缓存在 Redis 中,以便后续快速访问。
2 数据一致性问题
在使用 Redis 作为缓存时,需要考虑数据的一致性问题。数据一致性指的是在缓存与数据库之间保持数据的同步,避免数据出现不一致的情况。以下是常见的数据一致性策略:
2.1 先更新缓存,再更新数据库
在这种策略中,应用程序首先更新 Redis 缓存中的数据,然后再更新数据库。这样确保了数据先在缓存中更新,后在数据库中更新,减少了数据不一致的可能性。

2.2 先更新数据库,再更新缓存
这种策略与上述相反,应用程序首先更新数据库中的数据,然后再更新 Redis 缓存。这样做的好处是,在数据库更新失败的情况下,可以避免缓存中的数据与数据库不一致。

2.3 先删除缓存,再更新数据库
在执行更新操作之前,先删除 Redis 缓存中的对应数据。这样在下次读取数据时,强制从数据库中获取最新数据并更新到缓存中。

但如果是处于读写并发的情况下,还是会出现数据不一致的情况:

2.4 先更新数据库,再删除缓存
这种策略类似于先更新数据库再更新缓存,但在更新数据库成功后,再删除 Redis 缓存中的数据,确保缓存中的数据被删除,不再返回过期或无效的数据。

和之前一样,如果两段代码都执行成功,在并发情况下会是什么样呢?

3 数据一致性保障的最佳实践
3.1 延迟双删
在数据一致性方面,常常会出现"延迟双删"的问题。当数据在数据库更新后,立即删除 Redis 缓存可能会导致缓存中的数据在短时间内不一致。为了避免这种情况,可以采取延迟双删策略,即在更新数据库后,延迟一段时间再删除缓存,以确保数据已经在应用中稳定使用。


延迟双删的流程图:

3.2 通过发送MQ,在消费者线程去同步
Redis 为了更好地控制缓存与数据库的同步过程,可以使用消息队列(MQ)来处理缓存更新。在数据更新后,应用程序发送消息到 MQ,由消费者线程负责更新 Redis 缓存。这种异步方式避免了直接操作 Redis 导致的性能损耗,提高了系统的整体响应速度。

3.3 Canal 订阅日志实现
Canal 是阿里巴巴开源的一款基于数据库日志解析的工具,它可以订阅数据库的 binlog,并将数据变更事件转发给消息队列。通过 Canal,可以将数据库更新操作实时同步到 Redis 缓存,从而保持数据的一致性。

订阅数据库变更日志,当数据库发生变更时,我们可以拿到具体操作的数据,然后再去根据具体的数据,去删除对应的缓存。
3.4 使用事务
对于需要保证数据库与缓存数据完全一致性的场景,可以使用事务来处理数据更新。在更新数据库的同时,使用 Redis 事务来更新缓存,确保两者的操作要么同时成功,要么同时失败,从而维持数据的一致性。
3.5 采用乐观锁机制
乐观锁机制是一种较为轻量级的数据同步策略。在读取数据时,先获取数据的版本号,然后在更新数据时,检查版本号是否一致,如果一致才进行更新。这样可以避免并发更新导致的数据不一致问题。
九、RabbitMQ
1、为什么要使用MQ
1、流量消峰
举个例子:如果订单系统最多能处理一万次订单,这个处理能力应付正常时段的下单时绰绰有余,正常时段我们下单一秒后就能返回结果。但是在高峰期,如果有两万次下单操作系统是处理不了的,只能限制订单超过一万后不允许用户下单。使用消息队列做缓冲,我们可以取消这个限制,把一秒内下的订单分散成一段时间来处理,这时有些用户可能在下单十几秒后才能收到下单成功的操作,但是比不能下单的体验要好。
2、应用解耦
以电商应用为例,应用中有订单系统、库存系统、物流系统、支付系统。用户创建订单后,如果耦合调用库存系统、物流系统、支付系统,任何一个子系统出了故障,都会造成下单操作异常。当转变成基于消息队列的方式后,系统间调用的问题会减少很多,比如物流系统因为发生故障,需要几分钟来修复。在这几分钟的时间里,物流系统要处理的内存被缓存在消息队列中,用户的下单操作可以正常完成。当物流系统恢复后,继续处理订单信息即可,中单用户感受不到物流系统的故障,提升系统的可用性。
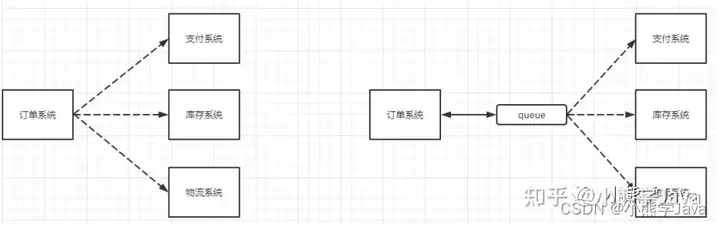
3、异步处理
有些服务间调用是异步的,例如 A 调用 B,B 需要花费很长时间执行,但是 A 需要知道 B 什么时候可以执行完,以前一般有两种方式:
- A 过一段时间去调用 B 的查询 api 查询
- A 提供一个 callback api, B 执行完之后调用 api 通知 A 服务。
这两种方式都不是很优雅,使用消息总线,可以很方便解决这个问题,A 调用 B 服务后,只需要监听 B 处理完成的消息,当 B 处理完成后,会发送一条消息给 MQ,MQ 会将此消息转发给 A 服务。这样 A 服务既不用循环调用 B 的查询 api,也不用提供 callback api。同样 B 服务也不用做这些操作。A 服务还能及时的得到异步处理成功的消息。
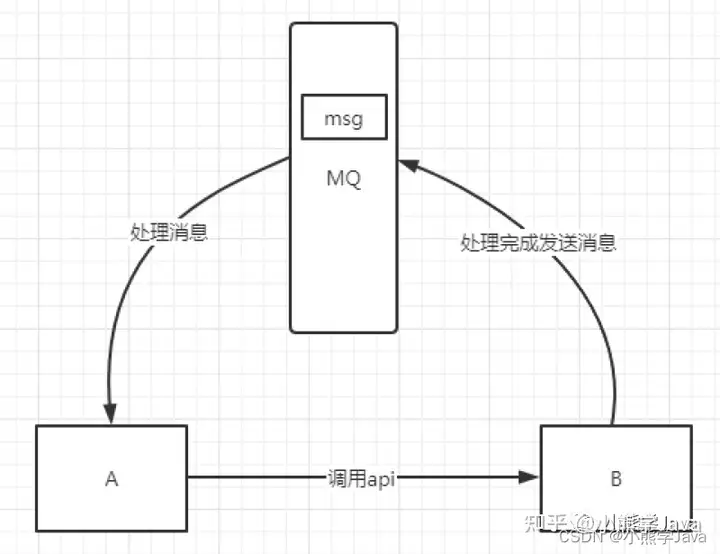
2、什么是RabbitMQ
RabbitMQ是一个消息中间件:它接受并转发消息。你可以把它当做一个快递站点,当你要发送一个包裹时,你把你的包裹放到快递站,快递员最终会把你的快递送到收件人那里,按照这种逻辑RabbitMQ是一个快递站,一个快递员帮你传递快件。RabbitMQ与快递站的主要区别在于,它不处理快件而是接收,存储和转发消息数据。
3、RabbitMQ各组件的功能
- Server:接收客户端的连接,实现
AMQP实体服务。 - Connection:连接,应用程序与Server的网络连接,TCP连接。
- Channel:信道,消息读写等操作在信道中进行。客户端可以建立多个信道,每个信道代表一个会话任务。如果每一次访问 RabbitMQ 都建立一个 Connection,在消息量大的时候建立 TCP Connection 的开销将是巨大的,效率也较低。Channel 是在 connection 内部建立的逻辑连接,如果应用程序支持多线程,通常每个 thread 创建单独的 channel 进行通讯,AMQP method 包含了 channel id 帮助客户端和 message broker 识别 channel,所以 channel 之间是完全隔离的。Channel 作为轻量级的
Connection极大减少了操作系统建立TCP connection****的开销 - Message:消息,应用程序和服务器之间传送的数据,消息可以非常简单,也可以很复杂。由Properties和Body组成。Properties为外包装,可以对消息进行修饰,比如消息的优先级、延迟等高级特性;Body就是消息体内容。
- Virtual Host:虚拟主机,用于逻辑隔离。一个虚拟主机里面可以有若干个Exchange和Queue,同一个虚拟主机里面不能有相同名称的Exchange或Queue。
- Exchange:交换器,接收消息,按照路由规则将消息路由到一个或者多个队列。如果路由不到,或者返回给生产者,或者直接丢弃。
RabbitMQ常用的交换器常用类型有direct、topic、fanout、headers四种,后面详细介绍。 - Binding:绑定,交换器和消息队列之间的虚拟连接,绑定中可以包含一个或者多个
RoutingKey,Binding 信息被保存到 exchange 中的查询表中,用于 message 的分发依据 RoutingKey:路由键,生产者将消息发送给交换器的时候,会发送一个RoutingKey,用来指定路由规则,这样交换器就知道把消息发送到哪个队列。路由键通常为一个“.”分割的字符串,例如“com.rabbitmq”。- Queue:消息队列,用来保存消息,供消费者消费。
4、RabbitMQ工作原理
不得不看一下经典的图了,如下
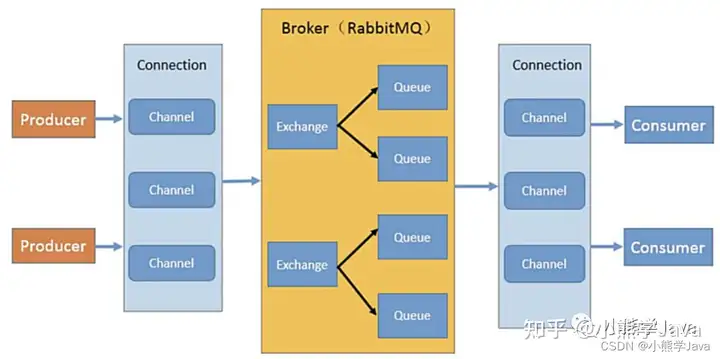
AMQP 协议模型由三部分组成:生产者、消费者和服务端,执行流程如下:
- 生产者是连接到 Server,建立一个连接,开启一个信道。
- 生产者声明交换器和队列,设置相关属性,并通过路由键将交换器和队列进行绑定。
- 消费者也需要进行建立连接,开启信道等操作,便于接收消息。
- 生产者发送消息,发送到服务端中的虚拟主机。
- 虚拟主机中的交换器根据路由键选择路由规则,发送到不同的消息队列中。
- 订阅了消息队列的消费者就可以获取到消息,进行消费。
5、RabbitMQ 上的一个 queue 中存放的 message 是否有数量限制?
可以认为是无限制,因为限制取决于机器的内存,但是消息过多会导致处理效率的下降。
6、RabbitMQ 允许发送的 message 最大可达多大?
根据 AMQP 协议规定,消息体的大小由 64-bit 的值来指定,所以你就可以知道到底能发多大的数据了
7、RabbitMQ的工作模式
1、simple模式(即最简单的收发模式)

- 消息产生消息,将消息放入队列
- 消息的消费者(consumer) 监听 消息队列,如果队列中有消息,就消费掉,消息被拿走后,自动从队列中删除(隐患 消息可能没有被消费者正确处理,已经从队列中消失了,造成消息的丢失,这里可以设置成手动的ack,但如果设置成手动ack,处理完后要及时发送ack消息给队列,否则会造成内存溢出)。
2、Work Queues(工作队列)
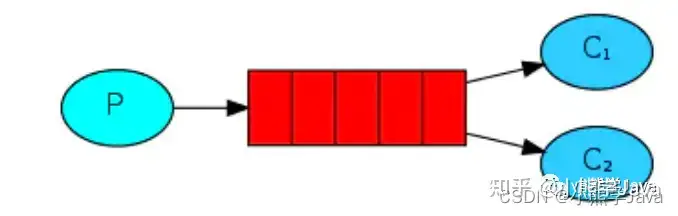
消息产生者将消息放入队列消费者可以有多个,消费者1,消费者2同时监听同一个队列,消息被消费。C1 C2共同争抢当前的消息队列内容,谁先拿到谁负责消费消息(隐患:高并发情况下,默认会产生某一个消息被多个消费者共同使用,可以设置一个开关(syncronize) 保证一条消息只能被一个消费者使用)。
3、publish/subscribe发布订阅(共享资源)
- 每个消费者监听自己的队列;
- 生产者将消息发给broker,由交换机将消息转发到绑定此交换机的每个队列,每个绑定交换机的队列都将接收到消息。
4、routing路由模式
- 消息生产者将消息发送给交换机按照路由判断,路由是字符串(info) 当前产生的消息携带路由字符(对象的方法),交换机根据路由的key,只能匹配上路由key对应的消息队列,对应的消费者才能消费消息;
- 根据业务功能定义路由字符串
- 从系统的代码逻辑中获取对应的功能字符串,将消息任务扔到对应的队列中。
- 业务场景:error 通知;EXCEPTION;错误通知的功能;传统意义的错误通知;客户通知;利用key路由,可以将程序中的错误封装成消息传入到消息队列中,开发者可以自定义消费者,实时接收错误;
5、topic 主题模式(路由模式的一种)
- 星号井号代表通配符
- 星号代表多个单词,井号代表一个单词
- 路由功能添加模糊匹配
- 消息产生者产生消息,把消息交给交换机
- 交换机根据key的规则模糊匹配到对应的队列,由队列的监听消费者接收消息消费
8、如何保证RabbitMQ消息的顺序性?
- 拆分多个 queue(消息队列),每个 queue(消息队列) 一个 consumer(消费者),就是多一些 queue(消息队列)而已,确实是麻烦点;
- 或者就一个 queue (消息队列)但是对应一个 consumer(消费者),然后这个 consumer(消费者)内部用内存队列做排队,然后分发给底层不同的 worker 来处理。
9、RabbitMQ消息丢失的情况有哪些?
- 生产者发送消息RabbitMQ Server 消息丢失
- RabbitMQ Server中存储的消息丢失
- RabbitMQ Server中存储的消息分发给消费者者丢失
1、生产者发送消息RabbitMQ Server 消息丢失
- 发送过程中存在网络问题,导致消息没有发送成功
- 代码问题,导致消息没发送
2、RabbitMQ Server中存储的消息丢失
消息没有持久化,服务器重启导致存储的消息丢失
3、RabbitMQ Server到消费者消息丢失
- 消费端接收到相关消息之后,消费端还没来得及处理消息,消费端机器就宕机了
- 处理消息存在异常
10、RabbitMQ如何保证消息不丢失?
针对上面的情况,确保消息不丢失
1、生产者发送消息RabbitMQ Server 消息丢失解决方案:
- 常用解决方案:发送方确认机制(publisher confirm)
- 开启AMQP的事务处理(不推荐)
2、RabbitMQ Server中存储的消息丢失解决方案:
- 消息回退:通过设置 mandatory 参数可以在当消息传递过程中不可达目的地时将消息返回给生产者
- 设置持久化:保证重启过程中,交换机和队列也是持久化的
3、RabbitMQ Server到消费者消息丢失解决方案:
- 手动ack确认机制
11、RabbitMQ消息基于什么传输?
由于 TCP 连接的创建和销毁开销较大,且并发数受系统资源限制,会造成性能瓶颈。RabbitMQ 使用信道的方式来传输数据。信道是建立在真实的 TCP 连接内的虚拟连接,且每条 TCP 连接上的信道数量没有限制。
12、RabbitMQ支持消息的幂等性吗?
支持。在消息生产时,MQ 内部针对每条生产者发送的消息生成一个 inner-msg-id,作为去重的依据(消息投递失败并重传),避免重复的消息进入队列。
在消息消费时,要求消息体中必须要有一个 bizId(对于同一业务全局唯一,如支付 ID、订单 ID、帖子 ID 等)作为去重的依据,避免同一条消息被重复消费。
13、RabbitMQ怎么确保消息已被消费?
- 消费端配置手动ACK确认机制
- 结合数据库进行状态标记处理
14、RabbitMQ支持事务消息吗?
支持事务消息。前面在第9题中保证生产者不丢失消息,提到可以使用AMQP的事务,但是它是同步的,所以不怎么推荐使用
事务的实现主要是对信道(Channel)的设置,主要方法如下: 1. channel.txSelect() 声明启动事务模式 2.channel.txCommit() 提交事务 3.channel.txRollback()回滚事务
15、RabbitMQ消息持久化的条件?
消息持久化,当然前提是队列必须持久化
- 声明队列必须设置持久化 durable 设置为 true.
- 消息推送投递模式必须设置持久化,deliveryMode 设置为 2(持久)。
- 消息已经到达持久化交换器。
- 消息已经到达持久化队列。
16、RabiitMQ消息什么情况下会变成死信消息?
由于特定的原因导致 queue 中的某些消息无法被消费,这样的消息如果没有后续的处理,就变成了死信消息
17、RabbitMQ死信消息的来源?
- 消息 TTL 过期
- 队列达到最大长度(队列满了,无法再添加数据到 mq 中)
- 消息被拒绝(basic.reject 或 basic.nack)并且 requeue=false.
18、RabbitMQ死信队列的用处?
- 可以用于实现延迟队列
19、RabbitMQ支持延迟队列吗?
支持。延时队列,队列内部是有序的,最重要的特性就体现在它的延时属性上,延时队列中的元素是希望在指定时间到了以后或之前取出和处理,简单来说,延时队列就是用来存放需要在指定时间被处理的元素的队列。
20、RabbitMQ延迟队列的使用场景
- 订单在十分钟之内未支付则自动取消
- 新创建的店铺,如果在十天内都没有上传过商品,则自动发送消息提醒
- 用户注册成功后,如果三天内没有登陆则进行短信提醒
- 用户发起退款,如果三天内没有得到处理则通知相关运营人员
- 预定会议后,需要在预定的时间点前十分钟通知各个与会人员参加会议
21、RabbitMQ实现延迟队列的有什么条件?
- 消息设置TTL
- 配置了死信队列
十、flowable
Flowable是一个基于Java的开源BPM框架,它主要基于Activiti中的一些组件,并在此基础上进行了扩展和升级。以下是Flowable的设计原理及架构解析:
架构
- Flowable架构主要分为四部分:工作流引擎、应用程序接口(API)、模型器和任务表单设计器。
- 工作流引擎:Flowable的核心组件,包括运行时引擎和执行引擎。它管理整个流程的生命周期,监控、控制任务的执行以及记录流程实例的状态等信息。
- 应用程序接口(API):根据RESTful风格,提供给外部系统访问Flowable引擎的接口,可以通过编写调用API的客户端程序来使用Flowable引擎服务。
- 模型器:用于创建和修改流程定义文件,支持基于Web的图形化编辑器。
- 任务表单设计器:用于创建和修改任务表单,支持基于Web的表单设计器。
设计原理
Flowable从设计层面遵循以下原则:
- 可扩展性(Extensibility):Flowable允许用户对平台进行扩展,可以使用自定义的Java类和JavaScript脚本添加新功能。
- 易用性(Usability):Flowable提供易于使用的编排和操作工具,用户可以快速创建、部署和管理业务流程。
- 平台独立性(Platform In-dependency):Flowable在设计时避免了与底层系统相关的代码,从而实现平台独立性。
总体来说,Flowable是一个基于Java语言、可扩展的BPM框架。其核心设计原则是可扩展性、易用性和平台独立性这三个方面。用户可以使用Flowable提供的工具,轻松构建、操作并监视高效的工作流程。
1、 Flowable是什么?请介绍一下其核心特点和优势
Flowable是一个开源的工作流引擎,它可以部署在Java平台上,支持BPMN 2.0标准,以及CMMN和DMN标准。它具有以下核心特点和优势:
-
可扩展性:Flowable可以轻松地与其他应用程序集成,例如Spring和Hibernate等,以实现更高级的工作流管理。
-
云原生:Flowable是云原生工作流引擎,可以轻松适应不同的云环境,并支持基于容器的部署,因此可以部署在不同的云提供商的环境中。
-
高性能:Flowable具有高性能工作流建模和执行能力,可以在大量用户和大量数据的情况下快速运行。
-
灵活性:Flowable支持多种流程,并允许用户创建自定义操作,以适应各种业务需求。
-
可视化:Flowable提供了易于使用的web界面,可以轻松地设计、部署和监控工作流。
总的来说,Flowable是一个功能强大、灵活和易于使用的工作流引擎,可以帮助企业更好地管理和优化其业务流程。
2、什么是BPMN?Flowable支持哪些版本的BPMN规范?
BPMN(Business Process Model and Notation)是一种用于建模和描述业务流程的图形化标准。它提供了一组符号和规则,使得用户可以清晰地表示各种复杂的流程和活动。
Flowable支持BPMN 2.0规范,这是当前最新版本的BPMN标准。该标准包括许多新的功能和扩展,如消息、数据对象、错误处理等,以及更加灵活的事件定义和网关控制。Flowable支持BPMN 2.0中的所有元素和规则,并提供了丰富的API和工具,以帮助用户创建、执行和监视复杂的业务流程。
3、请对比一下Flowable与Activiti的异同点?
Flowable和Activiti都是用于管理、执行和监视业务流程的开源Java引擎。它们有许多相似之处,但也存在一些差异。
相同点:
- 均为基于Java的开源流程引擎。
- 两个项目的创建者和核心开发者都是同一个团队。
- 均支持BPMN 2.0规范,并提供了可视化建模工具和丰富的API以及插件。
- 都提供了与Spring等常用框架的集成。
不同点:
-
历史背景:Activiti最初是从JBoss jBPM项目中分离出来的,而Flowable则是由Activiti核心开发者创建的新项目。
-
社区活跃度:Flowable最近几年得到了较为广泛的关注和使用,社区活跃度更高;Activiti在2019年被Alfresco收购后,其发展方向和未来发展变得不确定。
-
架构设计:Flowable的架构更加灵活、模块化,可以更好地适应各种需求和场景;Activiti的架构则更加简单,适合快速实现基本的流程管理功能。
-
功能特性:Flowable在任务分配、事件处理、历史数据管理、REST API等方面拥有更多的功能特性;Activiti则更加注重用户界面的设计和易用性。
总体来说,Flowable和Activiti都是优秀的流程引擎,具有自己的优势和特点。用户可以根据实际需求和场景选择适合自己的解决方案。
4、请列举一些常用的flowable API,以及它们分别的作用?
以下是一些常用的Flowable API及其功能:
-
RepositoryService:用于管理流程定义,包括部署、删除和查询等。
-
RuntimeService:用于启动、管理和执行流程实例,包括开始、暂停、恢复和终止等。
-
TaskService:用于管理任务,包括查询、委派、转派、认领以及完成等。
-
HistoryService:用于管理历史数据,包括流程实例、任务、变量、活动和步骤等的记录和查询。
-
IdentityService:用于管理用户和组,包括创建、更新、删除和查询等。
-
ManagementService:提供了一些管理和监控流程引擎的API,如查询数据库表、修改流程参数、获取引擎信息等。
-
FormService:用于渲染任务表单,并将表单提交到后台处理。
-
ProcessEngineConfiguration:用于配置流程引擎,包括数据库连接、缓存策略、事件监听器、任务分配策略等。
通过使用这些API,用户可以在代码中轻松地集成Flowable引擎,并实现各种业务需求。
5、请说明一下flowable中流程监听器的作用,以及有哪些类型的监听器?
流程监听器在Flowable中用于监听各种事件,以便在事件发生时执行一些自定义逻辑。它们可以通过API或流程定义文件(BPMN XML)进行配置,并与各种事件关联。
Flowable中存在以下类型的监听器:
-
ExecutionListener:用于监听流程实例和执行实例的生命周期事件,如开始、结束、删除等。
-
TaskListener:用于监听任务的生命周期事件,如创建、分配、完成和删除等。
-
VariableListener:用于监听流程变量的创建、更新和删除等事件。
-
EventListener:用于监听信号、消息和定时器等事件,并触发相应的动作。
-
CaseExecutionListener:用于监听CMMN案例实例和执行实例的生命周期事件,如开始、结束、删除等。
通过使用这些监听器,用户可以在流程运行期间监视和响应各种事件,并与其他系统进行交互。例如,当某个任务被分配给一个用户时,可以触发一个TaskListener并将通知发送到用户的邮件或移动设备上。这些监听器提供了丰富的扩展性和个性化定制能力,可以满足各种需求。
6、请解释一下什么是流程实例和执行对象,在flowable中有什么关系?
在Flowable中,流程实例和执行对象是用于管理和执行业务流程的两个重要概念。
流程实例是业务流程的一个运行实例,包含了所有活动和状态信息。当一个业务流程被启动时,会创建一个新的流程实例,并在整个流程生命周期内负责管理和维护流程状态。每个流程实例都有唯一的标识符,可以用来区分不同的实例。
执行对象是业务流程的运行时对象,它代表了流程实例当前正在执行的任务或活动。例如,当一个用户任务被分配给某个用户时,就会产生一个执行对象,表示该用户任务的执行状态和相关信息。执行对象通常与流程实例密切相关,但它们并不等同于流程实例。
在Flowable中,流程实例和执行对象之间存在一种父子关系。每个执行对象都有一个父级执行对象,代表其所属的流程实例。通过这种方式,Flowable能够有效地管理和执行复杂的流程实例,同时提供丰富的API和工具来查询、更新和监视流程实例和执行对象的状态。
7、请说明一下flowable中流程定义的基本组成部分,以及这些组成部分的作用。
在Flowable中,流程定义是用于描述和管理业务流程的一个重要概念。它由以下几个基本组成部分构成:
-
流程图:流程图是用于可视化表示流程执行顺序和流转方向的一种图形化表示方式,使用BPMN 2.0标准符号进行建模。在流程定义中,流程图用于描述整个业务流程的结构和逻辑。
-
节点:节点是流程图中的基本元素,代表了流程中的各种任务、活动、网关等。每个节点都有自己的名称、类型、输入输出参数等属性,用于指定节点的行为和功能。
-
连线:连线用于连接节点之间的关系,并表示流程执行的先后顺序。它们可以是有向边或无向边,可以包含条件和事件等约束条件。
-
变量:变量用于存储和传递流程中的数据和状态信息。在流程定义中,可以定义各种变量和变量类型,并在不同的节点中进行读写操作。
通过使用这些组成部分,用户可以轻松地创建、修改和管理业务流程,并通过Flowable引擎实现流程的管理和执行。流程定义提供了一个通用的框架,以支持各种复杂的工作流和业务流程需求。
8、如何使用Flowable创建和部署一个流程定义?
使用Flowable创建和部署一个流程定义通常需要以下步骤:
-
创建BPMN 2.0流程图:使用BPMN 2.0规范的符号和元素,设计和绘制业务流程的流程图。可以使用Flowable Modeler等工具进行可视化建模。
-
将BPMN 2.0流程图转换为XML格式:在完成流程图的设计后,将其导出为BPMN 2.0 XML文件,并保存到本地或者版本控制系统中。
-
配置流程引擎:使用Flowable提供的API或配置文件,配置流程引擎的参数和属性,如数据库连接、缓存策略、事件监听器、任务分配策略等。
-
部署流程定义:使用RepositoryService API向流程引擎上传BPMN 2.0 XML文件,将其编译成可执行的流程定义,并进行部署。部署操作通常包括以下几个步骤:创建DeploymentBuilder实例、添加BPMN 2.0 XML文件、设置部署名称和类别等属性、执行部署操作。
-
启动流程实例:使用RuntimeService API启动流程实例,创建一个新的流程执行对象,开始执行业务流程。可以通过传递变量、指定流程启动人和其他参数来控制流程的行为和执行顺序。
以上步骤只是一个大致的流程,并不是详尽的描述。具体实现细节和操作方式可以参考Flowable官方文档和示例代码。
9、如何启动、暂停、删除、挂起某个具体的流程实例?
在Flowable中,可以使用RuntimeService API启动、暂停、删除和挂起某个具体的流程实例。以下是每个操作对应的API方法:
-
启动流程实例:使用startProcessInstanceByKey()或startProcessInstanceById()方法启动流程实例。其中,startProcessInstanceByKey()方法根据流程定义的key启动流程实例,而startProcessInstanceById()方法根据流程定义的ID启动流程实例。
-
暂停流程实例:使用suspendProcessInstanceById()方法暂停流程实例。该方法接受一个流程实例ID参数,并将其暂停。在暂停状态下,流程实例不会执行任何活动或任务。可以使用activateProcessInstanceById()方法恢复流程实例的正常执行。
-
删除流程实例:使用deleteProcessInstance()或deleteProcessInstances()方法删除流程实例。其中,deleteProcessInstance()方法根据流程实例ID删除指定的流程实例,而deleteProcessInstances()方法通过过滤器批量删除符合条件的流程实例。删除流程实例时,还可以选择是否级联删除相关的历史数据和运行时数据。
-
挂起流程实例:使用suspendProcessInstanceById()方法挂起流程实例。该方法与暂停流程实例类似,但挂起状态下,流程实例不能被恢复,除非先将其激活。
需要注意的是,在暂停或挂起流程实例时,需要考虑相关的任务、事件和变量等的状态和处理方式,以免影响流程实例的正确性和一致性。同时,也需要谨慎处理删除操作,以避免误删重要的数据和记录。
10、在Flowable中,如何查询并处理当前待办的任务?
在Flowable中,可以使用TaskService API查询和处理当前待办的任务。以下是一些常用的API方法:
1、查询待办任务列表:
使用createTaskQuery()方法创建一个TaskQuery对象,然后设置各种过滤条件(如任务的候选人、办理人、所属流程实例等),最后调用list()或singleResult()方法获取符合条件的待办任务列表。例如,以下代码查询当前用户的所有待办任务:
List<Task> tasks = taskService.createTaskQuery() .taskCandidateOrAssigned("userId") .list();
获取待办任务详情:通过TaskService API提供的getTaskById()方法,根据任务ID获取指定的待办任务,并可以获取相关属性,如任务名称、所属流程定义、候选人/受理人等。
完成待办任务:使用complete()或claim()方法完成待办任务。其中,complete()方法用于标记任务已经完成,并将执行结果传递给下一个节点;而claim()方法用于将任务分配给某个用户或者组,以便其进行处理。例如,以下代码完成某个任务并将执行结果传递给下一个节点:
taskService.complete(taskId, variables);
转派待办任务:使用setAssignee()方法将待办任务转派给其他用户或组。例如,以下代码将某个任务转派给其他用户:
taskService.setAssignee(taskId, "newAssigneeId");
除了以上方法,TaskService API还提供了各种其他的查询和处理API,如委托、转办、查询历史任务等。用户可以根据实际需求,选择适合自己的API方法进行操作。
11、如何使用Flowable实现子流程的调用和管理?
在Flowable中,可以使用子流程来实现业务流程的模块化和复用。以下是使用Flowable实现子流程调用和管理的一些基本步骤:
-
创建子流程:使用BPMN 2.0规范的符号和元素,设计和绘制子流程的流程图。可以使用Flowable Modeler等工具进行可视化建模,并将其保存为独立的BPMN 2.0 XML文件。
-
部署子流程:通过RepositoryService API向流程引擎上传BPMN 2.0 XML文件,将其编译成可执行的子流程定义,并进行部署。可以使用以下代码实现子流程的部署:
Deployment deployment = repositoryService.createDeployment() .addClasspathResource("subprocess.bpmn20.xml") .deploy();
调用子流程:在主流程中,通过BPMN 2.0规范的Call Activity元素,调用已经部署的子流程。Call Activity元素有两种类型:independent(独立)和embedded(嵌入)。其中,独立类型的子流程会创建一个新的独立流程实例,而嵌入类型的子流程会在当前流程实例内部直接执行。例如,以下代码在主流程中调用独立的子流程:
ProcessInstance subProcessInstance = runtimeService .createProcessInstanceByKey("subProcess") .businessKey(businessKey) .execute();
管理子流程:在子流程中,可以使用Flowable提供的各种API方法,管理和控制子流程的执行。例如,可以使用ExecutionService API查询当前正在运行的子流程实例、设置子流程变量等
十一、VUE、前端
十二、linux系列
1.linux常用命令
ifconfig:查看网络接口详情
ping:查看与某主机是否能联通
ps -ef|grep 进程名称:查看进程号
lost -i 端口 :查看端口占用情况
top:查看系统负载情况,包括系统时间、系统所有进程状态、cpu情况
free:查看内存占用情况
kill:正常杀死进程,发出的信号可能会被阻塞
kill -9:强制杀死进程,发送的是exit命令,不会被阻塞
2.linux的io模型
IO是对磁盘或网络数据的读写,用户进程读取一次IO请求分为两个阶段:等待数据到达内核缓冲区和将内核缓冲区数据拷贝到用户空间,当用户去内核中拷贝数据时,要从用户态转为核心态
5中io模型:
(1)同步阻塞IO模型
用户进程发起io调用后会被阻塞,等待内核缓冲区数据准备完毕时就被唤醒,将内核数据复制到用户进程。这两个阶段都是阻塞的
(2)同步非阻塞IO模型
用户进程发起IO调用后,若内核缓冲区数据还未准备好,进程会继续干别的事,每隔一段时间就去看看内核数据是否准备好。不过将内核数据复制到用户进程这个阶段依旧是阻塞的
(3)IO多路复用模型
linux中把一切都看成文件,每个文件都有一个文件描述符(FD)来关联, IO多路复用模型就是复用单个进程同时监测多个文件描述符,当某个文件描述符可读或可写,就去通知用户进程。
(4)信号IO模型
用户进程发起IO调用后,会向内核注册一个信号处理函数然后继续干别的事,当内核数据准备就绪时就通知用户进程来进行拷贝。
(5)异步非阻塞模型
前面四种全是同步的。进程在发起IO调用后,会直接返回结果。待内核数据准备好时,由内核将数据复制给用户进程。两个阶段都是非阻塞的
3、IO多路复用详解
linux中把一切都看成文件,每个文件都有一个文件描述符(FD)来关联, IO多路复用模型就是复用单个进程同时监测多个文件描述符,当某个文件描述符可读或可写,就去通知用户进程。IO多路复用有三种方式
(1)select:采用数组结构,监测的fd有限,默认为1024;当有文件描述符就绪时,需要遍历整个FD数组来查看是哪个文件描述符就绪了,效率较低;每次调用select时都需要把整个文件描述符数组从用户态拷贝到内核态中来回拷贝,当fd很多时开销会很大;
(2)poll:采用链表结构,监测的文件描述符没有上限,其它的根select差不多
(3)epoll:采用红黑树结构,监测的fd没有上限,它有三个方法,epoll_create() 用于创建一个epoll实例,epoll实例中有一颗红黑树记录监测的fd,一个链表记录就绪的fd;epoll_ctl() 用于往epoll实例中增删要监测的文件描述符,并设置回调函数,当文件描述符就绪时触发回调函数将文件描述符添加到就绪链表当中;epoll_wait() 用于见擦汗就绪列表并返回就绪列表的长度,然后将就绪列表的拷贝到用户空间缓冲区中。
所以epoll的优点是当有文件描述符就绪时,只把已就绪的文件描述符写给用户空间,不需要每次都遍历FD集合;每个FD只有在调新增的时候和就绪的时候才会在用户空间和内核空间之间拷贝一次。
4、epoll的LT和ET模式
LT(默认):水平触发,当FD有数据可读的时候,那么每次 epoll_wait都会去通知用户来操作直到读完
ET:边缘触发,当FD有数据可读的时候,它只会通知用户一次,直到下次再有数据流入才会再通知,所以在ET模式下一定要把缓冲区的数据一次读完
十三、场景题
Java如何实现统计在线人数的功能?
分析:
首先,我遇见问题喜欢先分析下思路。
- 用什么技术,可以监听用户访问服务器? (监听器)
- 用那些技术,可以实时的存储每次登陆服务器的用户数量? (java四大域对象)
- 用那些技术,可以让用户的数量显示到客户端页面? (el表达式)
package com.cyl.count;
import javax.servlet.ServletContext;
import javax.servlet.ServletContextEvent;
import javax.servlet.ServletContextListener;
import javax.servlet.annotation.WebListener;
/*
初始化:
只有服务器的启动,才会创建servletContext对象。
用于监听servletContext创建,一旦创建servletContext创建,则设置servletContext中的count值为0;
*/
@WebListener
/*
这个注解的作用是启动监听,相当于在web.xml配置(
<listener>
<listener-class>com.cyl.count.InitServletContexListener</listener-class>
</listener>
*/
public class InitServletContexListener implements ServletContextListener {
@Override
public void contextInitialized(ServletContextEvent servletContextEvent) {
//获取ServletContext域对象
ServletContext servletContext = servletContextEvent.getServletContext();
//给ServletContext域对象,设置count=0
servletContext.setAttribute("count",0);
}
@Override
public void contextDestroyed(ServletContextEvent servletContextEvent) {
}
}
package com.cyl.count;
import javax.servlet.ServletContext;
import javax.servlet.annotation.WebListener;
import javax.servlet.http.HttpSession;
import javax.servlet.http.HttpSessionEvent;
import javax.servlet.http.HttpSessionListener;
/**
* @监听在线人数,监听session的创建和销毁
* 如果session创建 获取ServletContext中的count++,重新设置
* 如果session销毁 获取ServletContext中的count--,重新设置
*/
@WebListener
public class OnlineNumberHttpSessionListener implements HttpSessionListener {
@Override
public void sessionCreated(HttpSessionEvent httpSessionEvent) {
//1.获取session
HttpSession session = httpSessionEvent.getSession();
ServletContext servletContext = session.getServletContext();
//2.获取counnt值,加1
int count = (int) servletContext.getAttribute("count");
count++;
//3.把servlet存储到servletContext对象中
servletContext.setAttribute("count",count);
}
@Override
public void sessionDestroyed(HttpSessionEvent httpSessionEvent) {
//1.获取session
HttpSession session = httpSessionEvent.getSession();
ServletContext servletContext = session.getServletContext();
//2.获取counnt值,减1
int count = (int) servletContext.getAttribute("count");
count--;
//3.把servlet存储到servletContext对象中
servletContext.setAttribute("count",count);
}
}
十四、其他
1、Java IO概念(阻塞与非阻塞、同步与异步、BIO、NIO、AIO剖析)
1、阻塞和非阻塞、同步和异步
阻塞和非阻塞是进程在访问数据的时候,数据是否准备就绪的一种处理方式,当数据没有准备的时候。
-
阻塞:往往需要等待缓冲区中的数据准备好过后才处理其他的事情,否则一直等待在那里。
-
非阻塞:当我们的进程访问我们的数据缓冲区的时候,如果数据没有准备好则直接返回,不会等待。如果数据已经准备好,也直接返回。
2、同步(Synchronization)和异步(Asynchronous)
同步和异步都是基于应用程序和操作系统处理 IO 事件所采用的方式。比如同步:是应用程序要直接参与 IO 读写的操作。异步:所有的 IO 读写交给操作系统去处理,应用程序只需要等待通知。
同步方式在处理 IO 事件的时候,必须阻塞在某个方法上面等待我们的 IO 事件完成(阻塞 IO 事件或者通过轮询 IO事件的方式),对于异步来说,所有的 IO 读写都交给了操作系统。这个时候,我们可以去做其他的事情,并不需要去完成真正的 IO 操作,当操作完成 IO 后,会给我们的应用程序一个通知。
同步 : 阻塞到 IO 事件,阻塞到 read 或则 write。这个时候我们就完全不能做自己的事情。让读写方法加入到线程里面,然后阻塞线程来实现,对线程的性能开销比较大。
2、BIO与 NIO 对比
Java BIO(Block IO)和 NIO(Non-Block IO)之间的主要差别异:
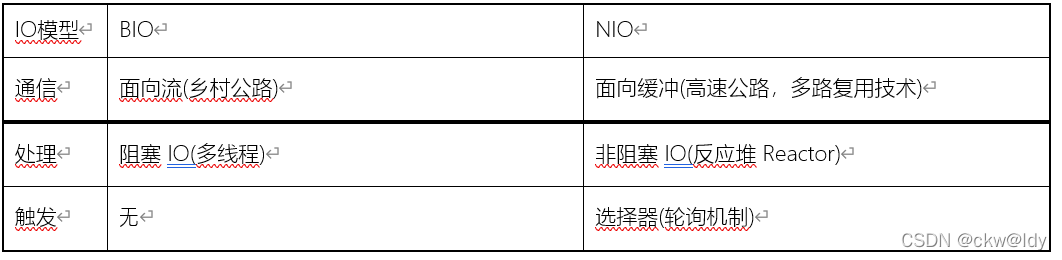
1、面向流与面向缓冲
Java NIO 和 BIO 之间第一个最大的区别是,BIO 是面向流的,NIO 是面向缓冲区的。 Java BIO 面向流意味着每次从流中读一个或多个字节,直至读取所有字节,它们没有被缓存在任何地方。此外,它不能前后移动流中的数据。如果需要前后移动从流中读取的数据,需要先将它缓存到一个缓冲区。 Java NIO 的缓冲导向方法略有不同。数据读取到一个它稍后处理的缓冲区,需要时可在缓冲区中前后移动。这就增加了处理过程中的灵活性。但是,还需要检查是否该缓冲区中包含所有你需要处理的数据。而且,需确保当更多的数据读入缓冲区时,不要覆盖缓冲区里尚未处理的数据。
2、阻塞与非阻塞
Java BIO 的各种流是阻塞的。这意味着,当一个线程调用 read() 或 write()时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干任何事情了。 Java NIO 的非阻塞模式,使一个线程从某通道发送请求读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用时,就什么都不会获取。而不是保持线程阻塞, 所以直至数据变的可以读取之前,该线程可以继续做其他的事情。 非阻塞写也是如此。一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。 线程通常将非阻塞 IO 的空闲时间用于在其它通道上执行 IO 操作,所以一个单独的线程现在可以管理多个输入和输出通道(channel)。
3、选择器
Java NIO 的选择器(Selector)允许一个单独的线程来监视多个输入通道,你可以注册多个通道使用一个选择器,然后使用一个单独的线程来“选择”通道:这些通道里已经有可以处理的输入,或者选择已准备写入的通道。这种选择机制,使得一个单独的线程很容易来管理多个通道。
4、NIO 和BIO 如何影响应用程序的设计
无论选择 BIO 或 NIO 工具箱,可能会影响应用程序设计的以下几个方面:
- 对 NIO 或 BIO 类的 API 调用。
- 数据处理逻辑。
- 用来处理数据的线程数。
1、API 调用
当然,使用 NIO 的 API 调用时看起来与使用 BIO 时有所不同,但这并不意外,因为并不是仅从一个 InputStream 逐字节读取,而是数据必须先读入缓冲区再处理。
2、数据处理
使用纯粹的 NIO 设计相较 BIO 设计,数据处理也受到影响。
在 BIO 设计中,我们从 InputStream 或 Reader 逐字节读取数据。假设你正在处理一基于行的文本数据流,例如: 有如下一段文本:
Name:Ckw
Age:18
Email: ckw@qq.com
Phone:13888888888
该文本行的流可以这样处理:
FileInputStream input = new FileInputStream("d://info.txt");
BufferedReader reader = new BufferedReader(new InputStreamReader(input));
String nameLine = reader.readLine();
String ageLine = reader.readLine();
String emailLine = reader.readLine();
String phoneLine = reader.readLine();
处理状态由程序执行多久决定。换句话说,一旦 reader.readLine()方法返回,你就知道肯定文本行就已读完, readline()阻塞直到整行读完,这就是原因。你也知道此行包含名称;同样,第二个 readline()调用返回的时候,你知道这行包含年龄等。 正如你可以看到,该处理程序仅在有新数据读入时运行,并知道每步的数据是什么。一旦正在运行的线程已处理过读入的某些数据,该线程不会再回退数据(大多如此)。下图也说明了这条原则:
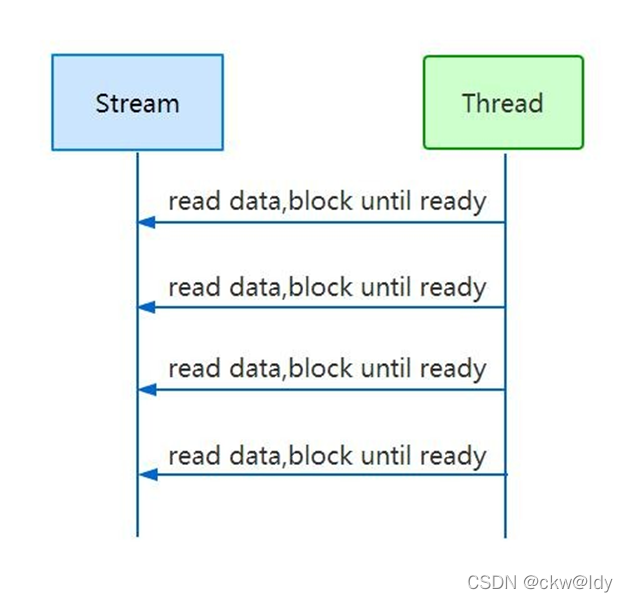
(Java BIO: 从一个阻塞的流中读数据) 而一个 NIO 的实现会有所不同,下面是一个简单的例子
ByteBuffer buffer = ByteBuffer.allocate(48);
int bytesRead = inChannel.read(buffer);
注意第二行,从通道读取字节到 ByteBuffer。当这个方法调用返回时,你不知道你所需的所有数据是否在缓冲区内。你所知道的是,该缓冲区包含一些字节,这使得处理有点困难。
所以,你怎么知道是否该缓冲区包含足够的数据可以处理呢?你不知道。发现的方法只能查看缓冲区中的数据。其结果是,在你知道所有数据都在缓冲区里之前,你必须检查几次缓冲区的数据。这不仅效率低下,而且可以使程序设计方案杂乱不堪。例如:
ByteBuffer buffer = ByteBuffer.allocate(48);
int bytesRead = inChannel.read(buffer);
while(!bufferFull(bytesRead)) {
bytesRead = inChannel.read(buffer);
}
bufferFull()方法必须跟踪有多少数据读入缓冲区,并返回真或假,这取决于缓冲区是否已满。换句话说,如果缓冲区准备好被处理,那么表示缓冲区满了。
如果缓冲区已满,它可以被处理。如果它不满,并且在你的实际案例中有意义,你或许能处理其中的部分数据。但是许多情况下并非如此。下图展示了“缓冲区数据循环就绪”:
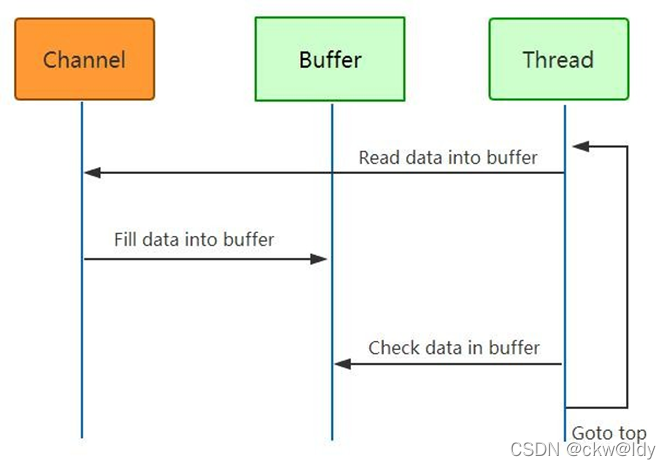
3、设置处理线程数
NIO 可只使用一个(或几个)单线程管理多个通道(网络连接或文件),但付出的代价是解析数据可能会比从一个阻塞流中读取数据更复杂。
如果需要管理同时打开的成千上万个连接,这些连接每次只是发送少量的数据,例如聊天服务器,实现 NIO 的服务器可能是一个优势。同样,如果你需要维持许多打开的连接到其他计算机上,如 P2P 网络中,使用一个单独的线程来管理你所有出站连接,可能是一个优势。一个线程多个连接的设计方案如:

Java NIO: 单线程管理多个连接
如果你有少量的连接使用非常高的带宽,一次发送大量的数据,也许典型的 IO 服务器实现可能非常契合。下图说明了一个典型的 IO 服务器设计

Java BIO: 一个典型的 IO 服务器设计- 一个连接通过一个线程处理
3、Java AIO 详解
jdk1.7 (NIO2)才是实现真正的异步 AIO、把 IO 读写操作完全交给操作系统,学习了 linux epoll 模式
1、AIO(Asynchronous IO)基本原理
服务端:AsynchronousServerSocketChannel 客服端:AsynchronousSocketChannel
用户处理器:CompletionHandler 接口,这个接口实现应用程序向操作系统发起 IO 请求,当完成后处理具体逻辑,否则做自己该做的事情,
“真正”的异步IO需要操作系统更强的支持。在IO多路复用模型中,事件循环将文件句柄的状态事件通知给用户线程, 由用户线程自行读取数据、处理数据。而在异步IO模型中,当用户线程收到通知时,数据已经被内核读取完毕,并放在了用户线程指定的缓冲区内,内核在IO完成后通知用户线程直接使用即可。异步IO模型使用了Proactor设计模式实现了这一机制,如下图所示:

2、AIO 代码实现
服务端代码:
/**
* AIO服务端
*/
public class AIOServer {
private final int port;
public static void main(String args[]) {
int port = 8000;
new AIOServer(port);
}
public AIOServer(int port) {
this.port = port;
listen();
}
private void listen() {
try {
ExecutorService executorService = Executors.newCachedThreadPool();
AsynchronousChannelGroup threadGroup = AsynchronousChannelGroup.withCachedThreadPool(executorService, 1);
//工作线程,用来侦听回调的,事件响应的时候需要回调
final AsynchronousServerSocketChannel server = AsynchronousServerSocketChannel.open(threadGroup);
server.bind(new InetSocketAddress(port));
System.out.println("服务已启动,监听端口" + port);
//准备接受数据
server.accept(null, new CompletionHandler<AsynchronousSocketChannel, Object>(){
final ByteBuffer buffer = ByteBuffer.allocateDirect(1024);
//实现completed方法来回调
//由操作系统来触发
//回调有两个状态,成功
public void completed(AsynchronousSocketChannel result, Object attachment){
System.out.println("IO操作成功,开始获取数据");
try {
buffer.clear();
result.read(buffer).get();
buffer.flip();
result.write(buffer);
buffer.flip();
} catch (Exception e) {
System.out.println(e.toString());
} finally {
try {
result.close();
server.accept(null, this);
} catch (Exception e) {
System.out.println(e.toString());
}
}
System.out.println("操作完成");
}
@Override
//回调有两个状态,失败
public void failed(Throwable exc, Object attachment) {
System.out.println("IO操作是失败: " + exc);
}
});
try {
Thread.sleep(Integer.MAX_VALUE);
} catch (InterruptedException ex) {
System.out.println(ex);
}
} catch (IOException e) {
System.out.println(e);
}
}
}
客户端代码:
/**
* AIO客户端
*/
public class AIOClient {
private final AsynchronousSocketChannel client;
public AIOClient() throws Exception{
client = AsynchronousSocketChannel.open();
}
public void connect(String host,int port)throws Exception{
client.connect(new InetSocketAddress(host,port),null,new CompletionHandler<Void,Void>() {
@Override
public void completed(Void result, Void attachment) {
try {
client.write(ByteBuffer.wrap("这是一条测试数据".getBytes())).get();
System.out.println("已发送至服务器");
} catch (Exception ex) {
ex.printStackTrace();
}
}
@Override
public void failed(Throwable exc, Void attachment) {
exc.printStackTrace();
}
});
final ByteBuffer bb = ByteBuffer.allocate(1024);
client.read(bb, null, new CompletionHandler<Integer,Object>(){
@Override
public void completed(Integer result, Object attachment) {
System.out.println("IO操作完成" + result);
System.out.println("获取反馈结果" + new String(bb.array()));
}
@Override
public void failed(Throwable exc, Object attachment) {
exc.printStackTrace();
}
}
);
try {
Thread.sleep(Integer.MAX_VALUE);
} catch (InterruptedException ex) {
System.out.println(ex);
}
}
4、各 IO 模型对比与总结

5、分布式事物
分布式事务是指事务的参与者,支持事务的服务器,资源服务器以及事务管理器分别位于分布式系统的不同节点之上。通常一个分布式事务中会涉及对多个数据源或业务系统的操作。分布式事务也可以被定义为一种嵌套型的事务,同时也就具有了ACID事务的特性。
强一致性
任何一次读都能读到某个数据的最近一次写的数据。系统中的所有进程,看到的操作顺序,都和全局时钟下的顺序一致。简言之,在任意时刻,所有节点中的数据是一样的。
弱一致性
数据更新后,如果能容忍后续的访问只能访问到部分或者全部访问不到,则是弱一致性。
最终一致性
不保证在任意时刻任意节点上的同一份数据都是相同的,但是随着时间的迁移,不同节点上的同一份数据总是在向趋同的方向变化。简单说,就是在一段时间后,节点间的数据会最终达到一致状态。
由于分布式事务方案,无法做到完全的ACID的保证,没有一种完美的方案,能够解决掉所有业务问题。因此在实际应用中,会根据业务的不同特性,选择最适合的分布式事务方案。
分布式事务的基础
CAP理论
- Consistency(一致性):数据一致更新,所有数据变动都是同步的(强一致性)。
- Availability(可用性):好的响应性能。
- Partition tolerance(分区容错性) :可靠性。
定理:任何分布式系统只可同时满足二点,没法三者兼顾。
CA系统(放弃P):指将所有数据(或者仅仅是那些与事务相关的数据)都放在一个分布式节点上,就不会存在网络分区。所以强一致性以及可用性得到满足。
CP系统(放弃A):如果要求数据在各个服务器上是强一致的,然而网络分区会导致同步时间无限延长,那么如此一来可用性就得不到保障了。坚持事务ACID(原子性、一致性、隔离性和持久性)的传统数据库以及对结果一致性非常敏感的应用通常会做出这样的选择。
AP系统(放弃C):这里所说的放弃一致性,并不是完全放弃数据一致性,而是放弃数据的强一致性,而保留数据的最终一致性。如果即要求系统高可用又要求分区容错,那么就要放弃一致性了。因为一旦发生网络分区,节点之间将无法通信,为了满足高可用,每个节点只能用本地数据提供服务,这样就会导致数据不一致。一些遵守BASE原则数据库,(如:Cassandra、CouchDB等)往往会放宽对一致性的要求(满足最终一致性即可),一次来获取基本的可用性。
BASE理论
BASE 是 Basically Available(基本可用)、Soft state(软状态)和 Eventually consistent (最终一致性)三个短语的缩写。是对CAP中AP的一个扩展。
- 基本可用:分布式系统在出现故障时,允许损失部分可用功能,保证核心功能可用。
- 软状态:允许系统中存在中间状态,这个状态不影响系统可用性,这里指的是CAP中的不一致。
- 最终一致:最终一致是指经过一段时间后,所有节点数据都将会达到一致。
BASE解决了CAP中理论没有网络延迟,在BASE中用软状态和最终一致,保证了延迟后的一致性。BASE和 ACID 是相反的,它完全不同于ACID的强一致性模型,而是通过牺牲强一致性来获得可用性,并允许数据在一段时间内是不一致的,但最终达到一致状态。
分布式事务解决方案
分布式事务的实现主要有以下 6 种方案:
- 2PC 方案
- TCC 方案
- 本地消息表
- MQ事务
- Saga事务
- 最大努力通知方案
2PC方案
2PC方案分为两阶段:
第一阶段:事务管理器要求每个涉及到事务的数据库预提交(precommit)此操作,并反映是否可以提交.
第二阶段:事务协调器要求每个数据库提交数据,或者回滚数据。
优点:
尽量保证了数据的强一致,实现成本较低,在各大主流数据库都有自己实现,对于MySQL是从5.5开始支持。
缺点:
- 单点问题:事务管理器在整个流程中扮演的角色很关键,如果其宕机,比如在第一阶段已经完成,在第二阶段正准备提交的时候事务管理器宕机,资源管理器就会一直阻塞,导致数据库无法使用。
- 同步阻塞:在准备就绪之后,资源管理器中的资源一直处于阻塞,直到提交完成,释放资源。
- 数据不一致:两阶段提交协议虽然为分布式数据强一致性所设计,但仍然存在数据不一致性的可能,比如在第二阶段中,假设协调者发出了事务commit的通知,但是因为网络问题该通知仅被一部分参与者所收到并执行了commit操作,其余的参与者则因为没有收到通知一直处于阻塞状态,这时候就产生了数据的不一致性。
总的来说,2PC方案比较简单,成本较低,但是其单点问题,以及不能支持高并发(由于同步阻塞)依然是其最大的弱点。
TCC
TCC 的全称是:Try、Confirm、Cancel。
- Try 阶段:这个阶段说的是对各个服务的资源做检测以及对资源进行 锁定或者预留。
- Confirm 阶段:这个阶段说的是在各个服务中执行实际的操作。
- Cancel 阶段:如果任何一个服务的业务方法执行出错,那么这里就需要 进行补偿,就是执行已经执行成功的业务逻辑的回滚操作。(把那些执行成功的回滚)
举个简单的例子如果你用100元买了一瓶水, Try阶段:你需要向你的钱包检查是否够100元并锁住这100元,水也是一样的。
如果有一个失败,则进行cancel(释放这100元和这一瓶水),如果cancel失败不论什么失败都进行重试cancel,所以需要保持幂等。
如果都成功,则进行confirm,确认这100元扣,和这一瓶水被卖,如果confirm失败无论什么失败则重试(会依靠活动日志进行重试)。
这种方案说实话几乎很少人使用,但是也有使用的场景。因为这个事务回滚实际上是严重依赖于你自己写代码来回滚和补偿了,会造成补偿代码巨大。
本地消息表
本地消息表的核心是将需要分布式处理的任务通过消息日志的方式来异步执行。消息日志可以存储到本地文本、数据库或消息队列,再通过业务规则自动或人工发起重试。人工重试更多的是应用于支付场景,通过对账系统对事后问题的处理。
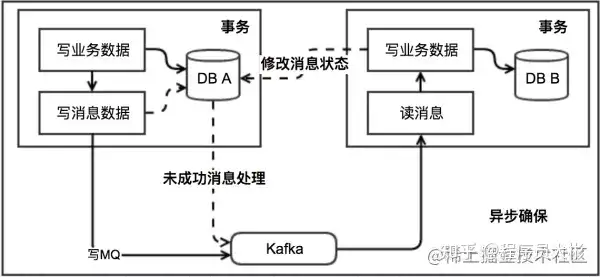
对于本地消息队列来说核心是把大事务转变为小事务。还是举上面用100元去买一瓶水的例子。
1.当你扣钱的时候,你需要在你扣钱的服务器上新增加一个本地消息表,你需要把你扣钱和写入减去水的库存到本地消息表放入同一个事务(依靠数据库本地事务保证一致性。
2.这个时候有个定时任务去轮询这个本地事务表,把没有发送的消息,扔给商品库存服务器,叫他减去水的库存,到达商品服务器之后这个时候得先写入这个服务器的事务表,然后进行扣减,扣减成功后,更新事务表中的状态。
3.商品服务器通过定时任务扫描消息表或者直接通知扣钱服务器,扣钱服务器本地消息表进行状态更新。
4.针对一些异常情况,定时扫描未成功处理的消息,进行重新发送,在商品服务器接到消息之后,首先判断是否是重复的,如果已经接收,在判断是否执行,如果执行在马上又进行通知事务,如果未执行,需要重新执行需要由业务保证幂等,也就是不会多扣一瓶水。
本地消息队列是BASE理论,是最终一致模型,适用于对一致性要求不高的。实现这个模型时需要注意重试的幂等。
MQ事务
基于 MQ 的分布式事务方案其实是对本地消息表的封装,将本地消息表基于 MQ 内部,其他方面的协议基本与本地消息表一致。
MQ事务方案整体流程和本地消息表的流程很相似,如下图:
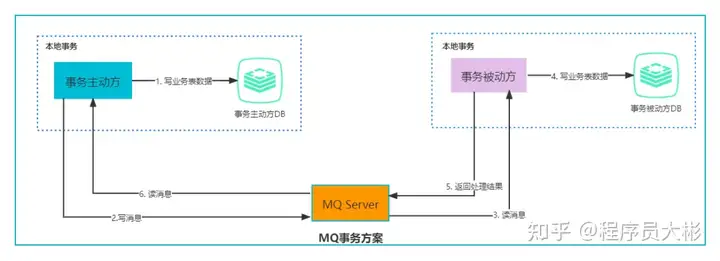
从上图可以看出和本地消息表方案唯一不同就是将本地消息表存在了MQ内部,而不是业务数据库中。
那么MQ内部的处理尤为重要,下面主要基于 RocketMQ 4.3 之后的版本介绍 MQ 的分布式事务方案。
在本地消息表方案中,保证事务主动方发写业务表数据和写消息表数据的一致性是基于数据库事务,RocketMQ 的事务消息相对于普通 MQ提供了 2PC 的提交接口,方案如下:
正常情况:事务主动方发消息

这种情况下,事务主动方服务正常,没有发生故障,发消息流程如下:
- 发送方向 MQ 服务端(MQ Server)发送 half 消息。
- MQ Server 将消息持久化成功之后,向发送方 ack 确认消息已经发送成功。
- 发送方开始执行本地事务逻辑。
- 发送方根据本地事务执行结果向 MQ Server 提交二次确认(commit 或是 rollback)。
- MQ Server 收到 commit 状态则将半消息标记为可投递,订阅方最终将收到该消息;MQ Server 收到 rollback 状态则删除半消息,订阅方将不会接受该消息。
异常情况:事务主动方消息恢复
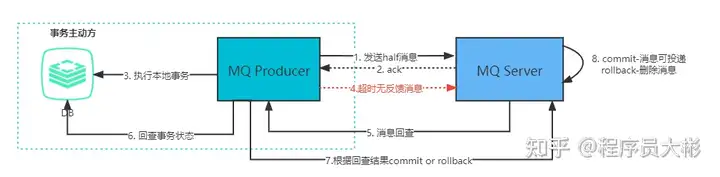
在断网或者应用重启等异常情况下,图中 4 提交的二次确认超时未到达 MQ Server,此时处理逻辑如下:
- MQ Server 对该消息发起消息回查。
- 发送方收到消息回查后,需要检查对应消息的本地事务执行的最终结果。
- 发送方根据检查得到的本地事务的最终状态再次提交二次确认。
- MQ Server基于 commit/rollback 对消息进行投递或者删除。
优点
相比本地消息表方案,MQ 事务方案优点是:
- 消息数据独立存储 ,降低业务系统与消息系统之间的耦合。
- 吞吐量大于使用本地消息表方案。
缺点
- 一次消息发送需要两次网络请求(half 消息 + commit/rollback 消息) 。
- 业务处理服务需要实现消息状态回查接口。
Saga事务
Saga是由一系列的本地事务构成。每一个本地事务在更新完数据库之后,会发布一条消息或者一个事件来触发Saga中的下一个本地事务的执行。如果一个本地事务因为某些业务规则无法满足而失败,Saga会执行在这个失败的事务之前成功提交的所有事务的补偿操作。
Saga的实现有很多种方式,其中最流行的两种方式是:
- 基于事件的方式。这种方式没有协调中心,整个模式的工作方式就像舞蹈一样,各个舞蹈演员按照预先编排的动作和走位各自表演,最终形成一只舞蹈。处于当前Saga下的各个服务,会产生某类事件,或者监听其它服务产生的事件并决定是否需要针对监听到的事件做出响应。
- 基于命令的方式。这种方式的工作形式就像一只乐队,由一个指挥家(协调中心)来协调大家的工作。协调中心来告诉Saga的参与方应该执行哪一个本地事务。
6、设计模式六大原则
(1)单一职责原则:一个类或者一个方法只负责一项职责,尽量做到类只有一个行为引起变化;
(2)里氏替换原则:子类可以扩展父类的功能,但不能改变原有父类的功能
(3)依赖倒置原则:高层模块不应该依赖底层模块,两者都应该依赖接口或抽象类
(4)接口隔离原则:建立单一接口,尽量细化接口
(5)迪米特原则:只关心其它对象能提供哪些方法,不关心过多内部细节
(6)开闭原则:对于拓展是开放,对于修改是封闭的
7、设计模式分类
创建型模式:主要是描述对象的创建,代表有单例、原型模式、工厂方法、抽象工厂、建造者模式
结构型模式:主要描述如何将类或对象按某种布局构成更大的结构,代表有代理、适配器、装饰
行为型模式:描述类或对象之间如何相互协作共同完成单个对象无法完成的任务,代表有模板方法模式、策略模式、观察者模式、备忘录模式
8、各个模式应用场景
23种经典设计模式共分为3种类型,分别是创建型、结构型和行为型。今天,我们把这3种类型分成3个对应的小模块,逐一带你看一下每一种设计模式的原理、实现、设计意图和应用场景。

Creational Patterns 创建型模式
1 、Prototype Pattern 原型模式
用原型实例指定创建对象的种类,并且通过拷贝这些原型创建新的对象。
应用场景:不是同一个对象,但是属于同类的复制,例如复印技术。
2 Singleton Pattern 单例模式
确保某一个类只有一个实例,而且自行实例化并向整个系统提供这个实例。
应用场景:控制游戏中声音播放;UI窗口显示;资源加载;计时器等。
3 Abstract Factory Pattern 抽象工厂模式
提供一个接口,用于创建相关或者依赖对象的家族,而不需要指定具体的实现类。
应用场景:同一种类的使用,游戏难度、游戏阵营:不同级别难度下游戏可以产生不同类型的建筑、英雄以及技能;AI 战术选择:实现确定好几种可选战术作为产品族,每种战术按照类似海军、空军、陆军作为产品等级结构选择具体兵种进行生产建造;国际化:用户改变语言环境时,会改变响应的文字显示,音效,图片显示,操作习惯适配等;皮肤更换或者资源管理:用户选择不同主题的皮肤将会影响图片显示以及动画效果;屏幕适配:对高、中、低分辨率的移动设备使用不同的显示资源。
4 Builder Pattern 建造者模式
将一个复杂对象的构造与它的表示分离,使同样的构建过程可以创建不同的表示,这样的设计模式被称为建造者模式。
应用场景:需要生成的产品对象复杂内部结构,这些产品具备共性;隔离复杂的对象的创建和使用,并使的相同的创建的不同的产品。
5 Factory Method Pattern 工厂方法模式
定义一个用于创建对象的接口,让子类决定实例化哪一个类。工厂方法使一个类的实例化延迟到其子类。
应用场景:游戏场景转换;角色AI状态管理。
Structural Patterns 结构型模式
1 Adapter Pattern 适配器模式
将一个类的接口转换成客户希望的另外一个接口。适配器模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。
应用场景:转接,复用已有的功能,但已有的功能接口不是客户端想要的。
2 Bridge Pattern 桥接模式
将抽象和实现解耦,使得两者可以独立地变化。
应用场景:一个类存在两个独立变化的维度,且这两个维度都需要进行扩展;需要从继承或多重继承中简化结构,且应对频繁变动的需求。
3 Composite Pattern 组合模式
将对象组合成树形结构以表示“部分-整体”的层次结构,使得用户对单个对象和组合对象的使用具有一致性。
应用场景:不同的界面的逻辑和UI通过一个管理器统一控制。
4 Decorator Pattern 装饰模式
动态地给一个对象添加一些额外的职责。就增加功能来说,装饰模式相比生成子类更为灵活。
应用场景:写好一个相应的战斗模块,但是在进入之前或者进入之后添加一些,输出日志、数据监测、数据收集埋点触发之类的功能
5 Facade Pattern 外观模式
要求一个子系统的外部与其内部的通信必须通过一个统一的对象进行。外观模式提供一个高层次的接口,使得子系统更易于使用。
应用场景:汽车的内部运作机制复杂,但是它给我们提供了方向盘、仪表盘、刹车、油门这些高级接口,我们便不需要了解引擎系统、动力传输系统等复杂系统,所以外观模式的重点在于,隐藏系统内部的互动细节,并提供简单方便的接口。之后让客户端只需要通过这个接口,就可以操作一个复杂的系统,并让它们顺利运行。
6 Flyweight Pattern 享元模式
使用共享对象可有效地支持大量的细粒度的对象。
应用场景:五子棋创建;游戏中某些不断创建销毁的物体,子弹对象池。
7 Proxy Pattern 代理模式
使用共享对象可有效地支持大量的细粒度的对象。
应用场景:代理Text, Button, Image等组件的功能;登陆设置;委托;代理下载资源等。
Behavioral Patterns 行为型模式
1 Command Pattern 命令模式
命令模式将“请求”封装成对象,以便使用不同的请求、队列或者日志来参数化其他对象,同时支持可撤消的操作。
应用场景:用户的客户端请求,实现请求的队列操作和日志光里,并且支持对操作进行撤销回退。
2 State Pattern 状态模式
当一个对象内在状态改变时允许其改变行为,这个对象看起来像改变了其类。
应用场景:角色状态;AI状态;账号登录状态;场景状态;动画机状态等。
3 Observer Pattern 观察者模式
定义对象间一种一对多的依赖关系,使得每当一个对象改变状态,则所有依赖于它的对象都会得到通知并被自动更新。
应用场景:发布;订阅消息;角色血条值下降被改变(防御力、攻击力等)。
4 Chain of Responsibility Pattern 责任链模式
使多个对象都有机会处理请求,从而避免了请求的发送者和接受者之间的耦合关系。将这些对象连成一条链,并沿着这条链传递该请求,直到有对象处理它为止。
应用场景:如游戏中敌方角色的设置、通关条件、下一关纪录。
5 Mediator Pattern 中介者模式
用一个中介对象封装一系列的对象交互,中介者使各对象不需要显示地相互作用,从而使其耦合松散,而且可以独立地改变它们之间的交互。
应用场景:感知系统,里面涉及视觉感应器、听觉感应器、视觉触发器、听觉触发器等交互可通过中介者完成。
6 Interpreter Pattern 解释器模式
给定一门语言,定义它的文法的一种表示,并定义一个解释器,该解释器使用该表示来解释语言中的句子。
应用场景:编译器;这些程序代码经过一般文本编辑器编写完成后放入指定的位置,例如Lua。
7 Iterator Pattern 迭代器模式
提供一种方法访问一个容器对象中各个元素,而又不需暴露该对象的内部细节。
应用场景:C#自带的IEnumerator;需要按指定顺序迭代查询集合中的元素。
8 Memento Pattern 备忘录模式
在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态。这样以后就可将该对象恢复到原先保存的状态。
应用场景:资源备份;历史记录;还原操作。
9 Strategy Pattern 策略模式
定义一组算法,将每个算法都封装起来,并且使它们之间可以互换。
应用场景:算法与环境都独立开来,算法的增减、修改不会对环境和客户端影响.例如:外挂[同步图片、名言、笑话,各自的售卖算法];技能效果类和方法的构建。
10 Template Method Pattern 模板方法模式
定义一个操作中的算法的框架,而将一些步骤延迟到子类中。使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。
应用场景:技能效果类和方法的构建。
11 Visitor Pattern 访问者模式
封装一些作用于某种数据结构中的各元素的操作,它可以在不改变数据结构的前提下定义作用于这些元素的新的操作。
应用场景:例如利用一个类,表示敌人和士兵都可以访问在做一样的事情,可以封装一个父类,然后子类继承。
9、docker容器
10、跨越问题
1.跨域的概念
1.“源”由协议、域名、端口号组成
2.同源策略是浏览器的一种保护机制。同源顾名思义,指两个源相同(即,两个源的协议、域名、端口号都相同)
3.违反了同源策略的请求就是通常说的跨域请求
2、跨域的解决方案-JSONP
JSONP方案和ajax没有任何关系,是通过script标签的src属性实现,因此JSONP方案只支持get请求,并且兼容性好,几乎所有浏览器都支持。
实现原理:在全局定义一个函数,将函数名以get传参的方式写入到script标签的src属性中(如下图所示),后端返回函数名以及参数,全局定义的函数就会自动调用,形参会接收后端传过来的参数。

3、跨域的解决方案-CORS
CORS(Cross-Origin Resource Sharing,跨域资源共享)方案,就是通过服务器设置一系列响应头来实现跨域。而客户端不需要做什么额外的事情。
4、跨域的解决方案-代理转发
代理转发的原理:在前端服务和后端接口服务之间架设一个中间代理服务,它的地址保持和前端服务一致,那么:
-
代理服务和前端服务之间由于协议域名端口三者统一不存在跨域问题,可以直接发送请求
-
代理服务和后端服务之间由于并不经过浏览器没有同源策略的限制,可以直接发送请求
这样,我们就可以通过中间这台服务器做接口转发,在开发环境下解决跨域问题(只能解决开发环境下跨域的问题)。
实现方法:vue-cli为我们内置了该技术,我们只需要按照要求配置一下即可。
在vue.config.js配置文件中,有一项是devServer,它就是我们下边要操作的主角。
module.exports = {
devServer: {
// ... 省略
// 代理配置
proxy: {
// 如果请求地址以/api打头,就出触发代理机制
// http://localhost:8080/api/login -> http://localhost:3000/api/login
'/api': {
target: 'http://localhost:3000' // 我们要代理的真实接口地址
}
}
}
}
5、nginx反向代理
反向代理和代理很像,都是在客户端与服务端中间架设一个中间代理服务器,不同点在于代理是代表客户端向服务端发送请求,反向代理是代表服务端接收客户端发送的请求。
实现方式是配置Nginx,修改nginx.conf配置文件,如下图所示:
11、nginx
1、请解释一下什么是Nginx?
Nginx是一个web服务器和方向代理服务器,用于HTTP、HTTPS、SMTP、POP3和IMAP协议。
2、请列举Nginx的一些特性。
Nginx服务器的特性包括:
反向代理/L7负载均衡器
嵌入式Perl解释器
动态二进制升级
可用于重新编写URL,具有非常好的PCRE支持
3、Nginx应用场景?
http服务器。Nginx是一个http服务可以独立提供http服务。可以做网页静态服务器。
虚拟主机。可以实现在一台服务器虚拟出多个网站,例如个人网站使用的虚拟机。
反向代理,负载均衡。当网站的访问量达到一定程度后,单台服务器不能满足用户的请求时,需要用多台服务器集群可以使用nginx做反向代理。并且多台服务器可以平均分担负载,不会应为某台服务器负载高宕机而某台服务器闲置的情况。
nginz 中也可以配置安全管理、比如可以使用Nginx搭建API接口网关,对每个接口服务进行拦截。
4、Nginx怎么处理请求的?
server { # 第一个Server区块开始,表示一个独立的虚拟主机站点
listen 80; # 提供服务的端口,默认80
server_name localhost; # 提供服务的域名主机名
location / { # 第一个location区块开始
root html; # 站点的根目录,相当于Nginx的安装目录
index index.html index.html; # 默认的首页文件,多个用空格分开
} # 第一个location区块结果
- Nginx 在启动时,会解析配置文件,得到需要监听的端口与 IP 地址,然后在 Nginx 的 Master
进程里面先初始化好这个监控的Socket(创建 S ocket,设置 addr、reuse 等选项,绑定到指定的 ip 地址端口,再
listen 监听)。 - 再 fork(一个现有进程可以调用 fork 函数创建一个新进程。由 fork 创建的新进程被称为子进程 )出多个子进程出来。
- 子进程会竞争 accept 新的连接。此时,客户端就可以向 nginx 发起连接了。当客户端与nginx进行三次握手,与
nginx 建立好一个连接后。此时,某一个子进程会 accept 成功,得到这个建立好的连接的 Socket ,然后创建 nginx
对连接的封装,即 ngx_connection_t 结构体。 - 设置读写事件处理函数,并添加读写事件来与客户端进行数据的交换。
- 最后,Nginx 或客户端来主动关掉连接,到此,一个连接就寿终正寝了。
5、Nginx 是如何实现高并发的?
如果一个 server 采用一个进程(或者线程)负责一个request的方式,那么进程数就是并发数。那么显而易见的,就是会有很多进程在等待中。等什么?最多的应该是等待网络传输。
而 Nginx 的异步非阻塞工作方式正是利用了这点等待的时间。在需要等待的时候,这些进程就空闲出来待命了。因此表现为少数几个进程就解决了大量的并发问题。
Nginx是如何利用的呢,简单来说:同样的 4 个进程,如果采用一个进程负责一个 request 的方式,那么,同时进来 4 个 request 之后,每个进程就负责其中一个,直至会话关闭。期间,如果有第 5 个request进来了。就无法及时反应了,因为 4 个进程都没干完活呢,因此,一般有个调度进程,每当新进来了一个 request ,就新开个进程来处理。
Nginx 不这样,每进来一个 request ,会有一个 worker 进程去处理。但不是全程的处理,处理到什么程度呢?处理到可能发生阻塞的地方,比如向上游(后端)服务器转发 request ,并等待请求返回。那么,这个处理的 worker 不会这么傻等着,他会在发送完请求后,注册一个事件:“如果 upstream 返回了,告诉我一声,我再接着干”。于是他就休息去了。此时,如果再有 request 进来,他就可以很快再按这种方式处理。而一旦上游服务器返回了,就会触发这个事件,worker 才会来接手,这个 request 才会接着往下走。
这就是为什么说,Nginx 基于事件模型。
由于 web server 的工作性质决定了每个 request 的大部份生命都是在网络传输中,实际上花费在 server 机器上的时间片不多。这是几个进程就解决高并发的秘密所在。即:
webserver 刚好属于网络 IO 密集型应用,不算是计算密集型。
异步,非阻塞,使用 epoll ,和大量细节处的优化。也正是 Nginx 之所以然的技术基石。
6、什么是正向代理?
一个位于客户端和原始服务器(origin server)之间的服务器,为了从原始服务器取得内容,客户端向代理发送一个请求并指定目标(原始服务器),然后代理向原始服务器转交请求并将获得的内容返回给客户端。
客户端才能使用正向代理。
正向代理总结就一句话:代理端代理的是客户端。
例如说:我们使用的OpenVPN 等等。
7、什么是反向代理?
反向代理(Reverse Proxy)方式,是指以代理服务器来接受 Internet上的连接请求,然后将请求,发给内部网络上的服务器并将从服务器上得到的结果返回给 Internet 上请求连接的客户端,此时代理服务器对外就表现为一个反向代理服务器。
反向代理总结就一句话:代理端代理的是服务端。
透明代理
透明代理的意思是客户端根本不需要知道有代理服务器的存在,它改编你的request fields(报文),并会传送真实IP。注意,加密的透明代理则是属于匿名代理,意思是不用设置使用代理了。 透明代理实践的例子就是时下很多公司使用的行为管理软件。如下图所示:

8、反向代理服务器的优点是什么?
反向代理服务器可以隐藏源服务器的存在和特征。它充当互联网云和web服务器之间的中间层。这对于安全方面来说是很好的,特别是当您使用web托管服务时。
9、Nginx负载均衡的算法怎么实现的?策略有哪些?
为了避免服务器崩溃,大家会通过负载均衡的方式来分担服务器压力。将对台服务器组成一个集群,当用户访问时,先访问到一个转发服务器,再由转发服务器将访问分发到压力更小的服务器。
Nginx负载均衡实现的策略有以下五种:
1 .轮询(默认)
每个请求按时间顺序逐一分配到不同的后端服务器,如果后端某个服务器宕机,能自动剔除故障系统。
upstream backserver {
server 192.168.31.12;
server 192.168.31.13;
}
2. 权重 weight
weight的值越大,分配到的访问概率越高,主要用于后端每台服务器性能不均衡的情况下。其次是为在主从的情况下设置不同的权值,达到合理有效的地利用主机资源。
# 权重越高,在被访问的概率越大,如上例,分别是20%,80%。
upstream backserver {
server 192.168.0.12 weight=2;
server 192.168.0.13 weight=8;
}
3. ip_hash( IP绑定)
每个请求按访问IP的哈希结果分配,使来自同一个IP的访客固定访问一台后端服务器,并且可以有效解决动态网页存在的session共享问题
upstream backserver {
ip_hash;
server 192.168.0.12:88;
server 192.168.0.13:80;
}
4、fair(第三方插件)
必须安装upstream_fair模块。
对比 weight、ip_hash更加智能的负载均衡算法,fair算法可以根据页面大小和加载时间长短智能地进行负载均衡,响应时间短的优先分配。
# 哪个服务器的响应速度快,就将请求分配到那个服务器上。
upstream backserver {
server server1;
server server2;
fair;
}
5、url_hash(第三方插件)
必须安装Nginx的hash软件包
按访问url的hash结果来分配请求,使每个url定向到同一个后端服务器,可以进一步提高后端缓存服务器的效率。
upstream backserver {
server squid1:3128;
server squid2:3128;
hash $request_uri;
hash_method crc32;
}
10 、Nginx配置高可用性怎么配置?
当上游服务器(真实访问服务器),一旦出现故障或者是没有及时相应的话,应该直接轮训到下一台服务器,保证服务器的高可用
server {
listen 80;
server_name www.lijie.com;
location / {
### 指定上游服务器负载均衡服务器
proxy_pass http://backServer;
###nginx与上游服务器(真实访问的服务器)超时时间 后端服务器连接的超时时间_发起握手等候响应超时时间
proxy_connect_timeout 1s;
###nginx发送给上游服务器(真实访问的服务器)超时时间
proxy_send_timeout 1s;
### nginx接受上游服务器(真实访问的服务器)超时时间
proxy_read_timeout 1s;
index index.html index.htm;
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号