ssh链接过多问题分析及复盘
缘起#
某一天,产品侧同事联系过来,反馈话单传输程序报错,现象如下:
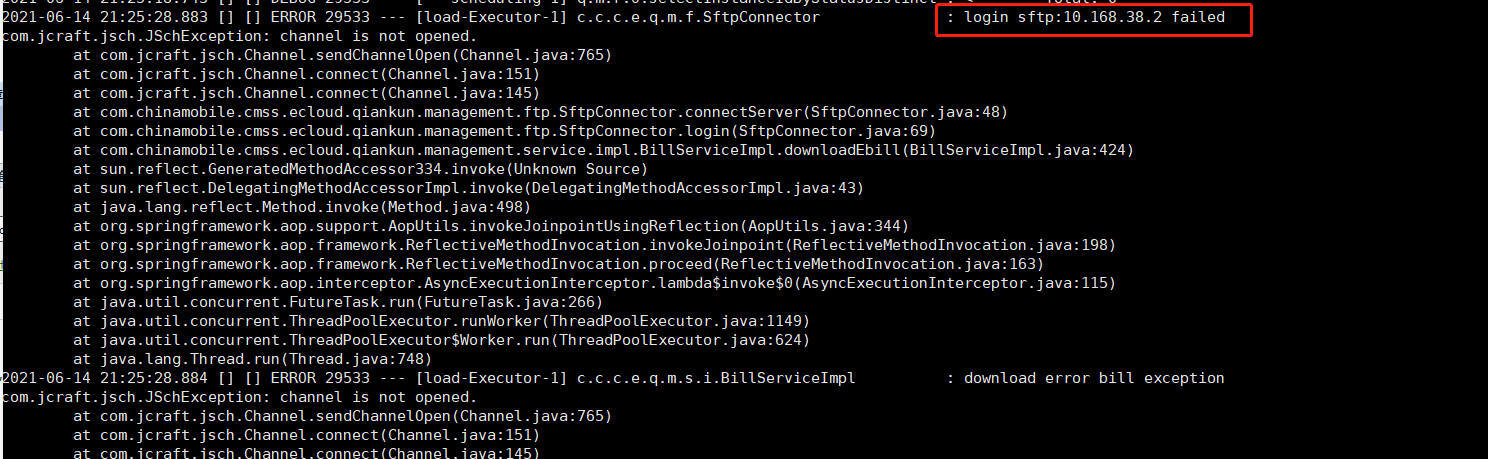
实际上,该节点仅提供了一个sftp服务,供产品侧传输话单过来进行临时存储,由计费部门取走而已。
分析#
于是找运维同事上服务器看了下情况,发现有以下几个问题:
-
ssh进程过高(由于前期给各个部门分配的sftp账号不同,正好可以以账号名辨别来源)

-
根据以上信息,检查了TCP链接状态,发现绝大多数都是ESTABLISHED连接:
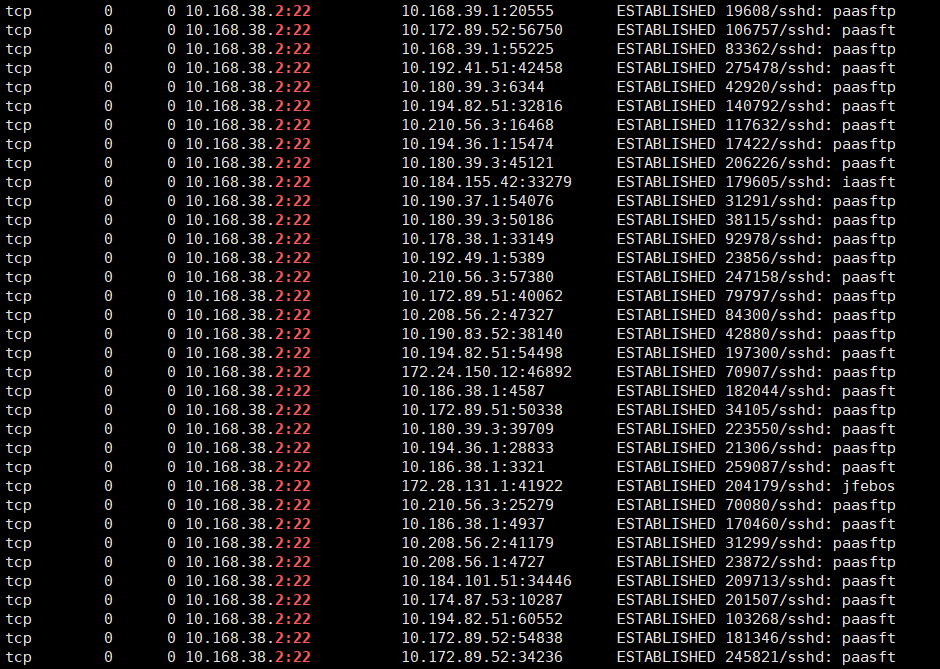
-
于是统计了一下TCP链接来源
#/bin/bash
for i in `netstat -ant | grep ESTABLISHED | awk '{print $5}' | awk -F: '{print $1}' | sort |uniq`
do
count=`netstat -ant | grep ESTABLISHED | grep $i|wc -l`
if [[ ${count} -ge 30 ]] ;then
echo "$i的连接数是$count"
#else
# continue
fi
done
-
发现链接主要集中于部分IP:
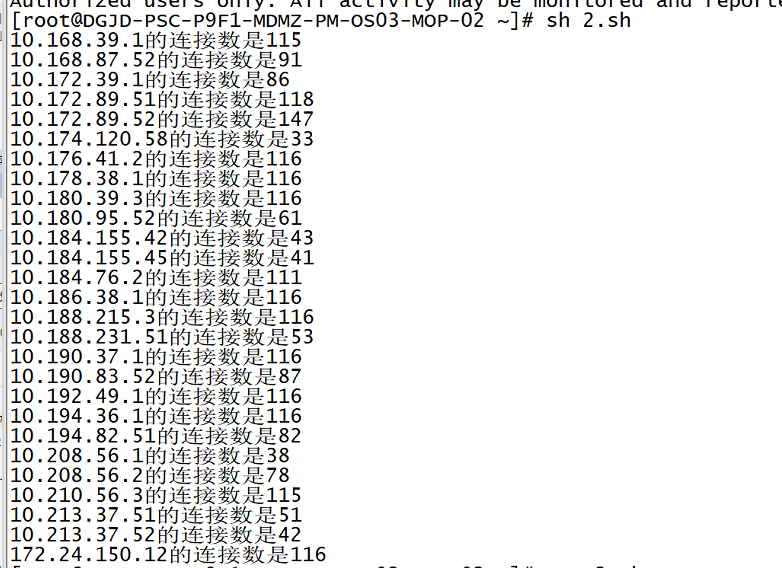
-
由于链接持续上涨,结合业务场景推测为ssh连接未正常释放的问题引发。
拓展#
首先,链接在多天的时间内积攒到几万,并且不进行自动释放,几乎可以断定是由于客户端未释放,原因如下:
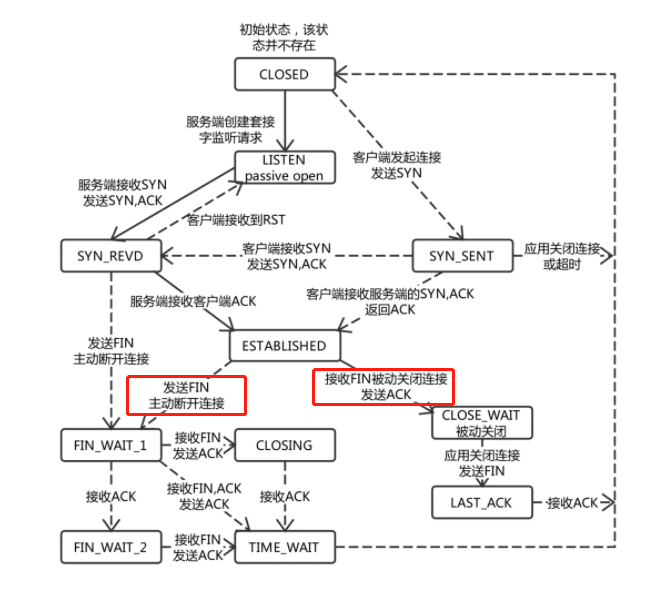
根据TCP请求的状态机,ESTABLISHED状态的链接,只有在发送FIN,或者收到FIN的时候,才会主动断开TCP链接(也就是意味着没有人发FIN);
而假设一种场景,客户端发送了FIN,但服务端因为网络或者某种原因未收到的话,TCP keepalive机制会进行多次探测,将其断开(也就是意味着keepalive机制一直存在响应)。
补充:下一篇将对TCP请求的keepalive机制做一个介绍。
根因#
于是组织产品侧进行排查,最终找到原因:
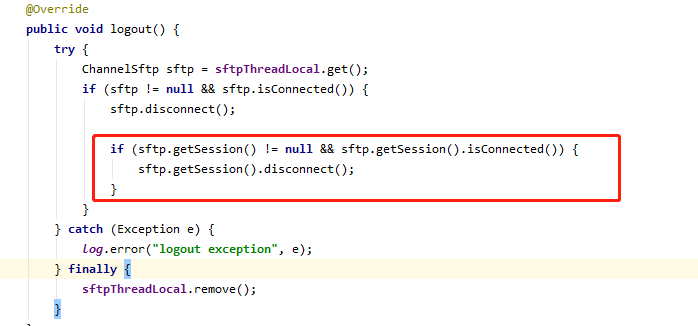
原代码中,在退出sftp任务之后,只关闭了channel,而未关闭对应的session(缺少红框内容)
根据官方example:http://www.jcraft.com/jsch/examples/Sftp.java.html ,最终关闭的应该是session,这样就不会有残留了。

channel是什么,session又是什么?#
- Channel Mechanism --------- from:rfc4254
All terminal sessions, forwarded connections, etc., are channels.
Either side may open a channel. Multiple channels are multiplexed
into a single connection.
Channels are identified by numbers at each end. The number referring
to a channel may be different on each side. Requests to open a
channel contain the sender's channel number. Any other channel-
related messages contain the recipient's channel number for the
channel.
Channels are flow-controlled. No data may be sent to a channel until
a message is received to indicate that window space is available.
-----------------------------------------------------from:rfc4254
3.1. What are Channels? ----------------- from:Net::SSH Manual
The SSH protocol requires that requests for services on a remote machine be made over channels. A single SSH connection may contain multiple channels, all run simultaneously over that connection.
Each channel, in turn, represents the processing of a single service. When you invoke a process on the remote host with Net::SSH, a channel is opened for that invocation, and all input and output relevant to that process is sent through that channel. The connection itself simply manages the packets of all of the channels that it has open.
This means that, for instance, over a single SSH connection you could execute a process, download a file via SFTP, and forward any number of ports, all (seemingly) at the same time!
Naturally, they do not occur simultaneously, but rather work in a “time-share” fashion by sharing the bandwidth of the connection. Nevertheless, the fact that these channels exist make working with the SSH protocol a bit more challenging than simpler protocols (like FTP, HTTP, or Telnet).
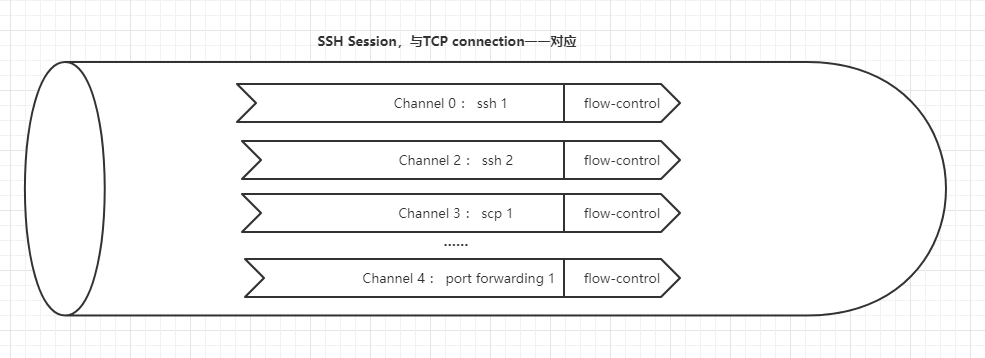
根据以上信息,我们可知:
- 登录一次ssh,产生一个ssh会话(session),也就是对应一个TCP链接;
- 一个会话/TCP链接可以承载多个channel;
- scp/ssh/port forwarding都可以成为独立的channel;
- 不同channel之间存在流控以保证互相独立的安全;
形如:
复盘#
至此问题解决,那么需要复盘分析了:
前期是否有做过sshd服务的性能限制配置?#
经了解,前期为了限制产品侧的链接个数,已经有过配置对应的限制配置:

这里解释下这两个配置:
MaxSessions 1000 限制最大会话个数;
MaxStartups 1000:30:1200 会话个数达到1000之后的链接,有30%几率失败;会话个数达到1200后,全部失败;
可是为何实际生产中连接数达到了几十万都没有释放呢?
经过一番调查最终找到原因:每次登录会在ssh服务新建一个连接,每次代码层面进行sftp操作,会生成一个新的会话/session。
所以这个maxsession,实际上限制的是每一个连接能新建出多少个会话的个数。
因此配置是存在的,只是没有起到预期的效果。
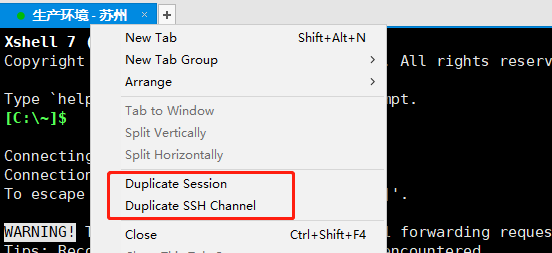
对应到各种ssh工具上,有一个复制会话,有一个复制渠道(channel),对应的即是这两个概念。
那么应该如何正确的配置呢?#
实际上,在ulimit里面是可以配置针对用户级别的登录连接个数限制的:
/etc/security/limits.conf 文件实际是 Linux PAM(插入式认证模块,Pluggable Authentication Modules)中 pam_limits.so 的配置文件,而且只针对于单个会话。
# /etc/security/limits.conf
#
#This file sets the resource limits for the users logged in via PAM.
该文件为通过PAM登录的用户设置资源限制。
#It does not affect resource limits of the system services.
#它不影响系统服务的资源限制。
#Also note that configuration files in /etc/security/limits.d directory,
#which are read in alphabetical order, override the settings in this
#file in case the domain is the same or more specific.
请注意/etc/security/limits.d下按照字母顺序排列的配置文件会覆盖 /etc/security/limits.conf中的
domain相同的的配置
#That means for example that setting a limit for wildcard domain here
#can be overriden with a wildcard setting in a config file in the
#subdirectory, but a user specific setting here can be overriden only
#with a user specific setting in the subdirectory.
这意味着,例如使用通配符的domain会被子目录中相同的通配符配置所覆盖,但是某一用户的特定配置
只能被字母路中用户的配置所覆盖。其实就是某一用户A如果在/etc/security/limits.conf有配置,当
/etc/security/limits.d子目录下配置文件也有用户A的配置时,那么A中某些配置会被覆盖。最终取的值是 /etc/security/limits.d 下的配置文件的配置。
#
#Each line describes a limit for a user in the form:
#每一行描述一个用户配置,配置格式如下:
#<domain> <type> <item> <value>
#Where:
#<domain> can be:
# - a user name 一个用户名
# - a group name, with @group syntax 用户组格式为@GROUP_NAME
# - the wildcard *, for default entry 默认配置为*,代表所有用户
# - the wildcard %, can be also used with %group syntax,
# for maxlogin limit
#
#<type> can have the two values:
# - "soft" for enforcing the soft limits
# - "hard" for enforcing hard limits
有soft,hard和-,soft指的是当前系统生效的设置值,软限制也可以理解为警告值。
hard表名系统中所能设定的最大值。soft的限制不能比hard限制高,用-表名同时设置了soft和hard的值。
#<item> can be one of the following: <item>可以使以下选项中的一个
# - core - limits the core file size (KB) 限制内核文件的大小。
# - data - max data size (KB) 最大数据大小
# - fsize - maximum filesize (KB) 最大文件大小
# - memlock - max locked-in-memory address space (KB) 最大锁定内存地址空间
# - nofile - max number of open file descriptors 最大打开的文件数(以文件描叙符,file descripter计数)
# - rss - max resident set size (KB) 最大持久设置大小
# - stack - max stack size (KB) 最大栈大小
# - cpu - max CPU time (MIN) 最多CPU占用时间,单位为MIN分钟
# - nproc - max number of processes 进程的最大数目
# - as - address space limit (KB) 地址空间限制
# - maxlogins - max number of logins for this user 此用户允许登录的最大数目
# - maxsyslogins - max number of logins on the system 系统最大同时在线用户数
# - priority - the priority to run user process with 运行用户进程的优先级
# - locks - max number of file locks the user can hold 用户可以持有的文件锁的最大数量
# - sigpending - max number of pending signals
# - msgqueue - max memory used by POSIX message queues (bytes)
# - nice - max nice priority allowed to raise to values: [-20, 19] max nice优先级允许提升到值
# - rtprio - max realtime pr iority
因此解就很明显了,只要在limit中配置
testssh - maxlogins 1
即可,即时生效。
etc: 可以结合以上的maxsession,为某个用户的连接/session数做更精确的控制。
前期是如何测试上线的呢?#
此处不作展开,测试工作之重要不容质疑;然而也不能为了测试而测试,上一个小功能就需要把所有的测试run一遍;
个中文章摊开来说恐怕小小篇幅不足讨论。
为何没有提前发现呢?#
前期曾做过监控告警的接入,但接入内容仅限于openssh进程消失,22端口丢失的场景;
很显然,此处缺少进程数量,TCP链接数量,端口消耗数量监控;
一言以蔽之,也就是只有1/0监控,没有health/err的监控;
同样是以上的道理,既不能被动等待故障发现后做单个的补充,也不能因为过多细节监控项带来整体运维的复杂度;
因此个人的理解是要加上通用指标的监控项,即监控指标需要反应系统级的普遍问题或者服务级的健康度,落实到ssh服务,建议如下:
进程数量监控(no),TCP链接数量监控(yes,百分比监控),端口消耗数量监控(yes,百分比),ssh服务响应时长拨测(yes,模拟ssh登录及scp操作监控)




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· .NET Core 中如何实现缓存的预热?
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 如何调用 DeepSeek 的自然语言处理 API 接口并集成到在线客服系统