
【MOOC】正则表达式--Re库
Requests库—自动爬取HTML页面,自动网络请求提交
Robots.txt—网络爬虫排除标准
BeautifulSoup库—解析HTML页面,信息标记与提取方法
Re库—正则表达式,提取页面关键信息
简洁表达字符串,应用于字符串匹配,模糊查找
一、正则表达式常用操作符
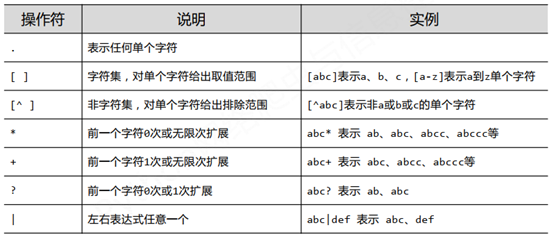
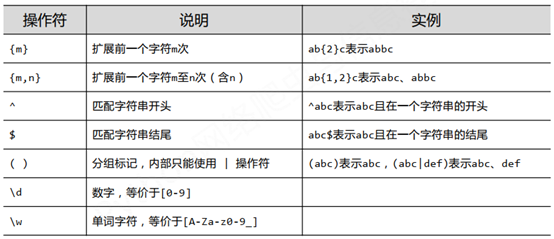
二、经典的正则表达式

三、正则表达式的表示类型
原生字符串--raw string类型
r'[1-9]\d{5}'
四、Re库的主要功能函数

1、 re.search(pattern, string, flags=0) 搜索,返回第一个匹配到的结果
pattern—原生字符串
string—待匹配的字符串
flags—控制标记

import re
match = re.search(r'[1-9]\d{5}' , 'BIT 361000') ## 匹配邮政编码类型
if match:
print(match.group(0))
2、 re.match(pattern, string, flags=0) 从开始位置开始匹配
match = re.match(r'[1-9]\d{5}' , '361000 BIT') ## 匹配邮政编码类型
if match:
print(match.group(0))
3、 re.findall(pattern, string, flags=0) 搜索,返回全部匹配的结果,列表类型
match = re.findall(r'[1-9]\d{5}' , '361000BIT TLT178209') ## 匹配邮政编码类型
print(match) ##['361000', '178209']
4、 re.split(pattern, string, maxsplit=0, flags=0) 分割匹配结果,返回列表类型
maxsplit—最大分割数,剩余部分作为最后一个结果输出
match = re.split(r'[1-9]\d{5}' , '361000BIT TLT178209') ## 匹配邮政编码类型
print(match) ##['', 'BIT TLT', '']
match = re.split(r'[1-9]\d{5}' , '361000BIT TLT178209',maxsplit=1) ## 匹配邮政编码类型
print(match) ##['', 'BIT TLT178209']
5、 re.finditer(pattern, string, flags=0) 返回匹配结果的迭代类型,可以迭代地获得每一次匹配结果
for m in re.finditer(r'[1-9]\d{5}' , '361000BIT TLT178209'):
if m:
print(m.group(0))
#361000
#178209
6、 re.sub(pattern, repl, string, count=0, flags=0)
repl—替换匹配地字符串
count—匹配地最大替换次数
m = re.sub(r'[1-9]\d{5}' , ':zipcode' , '361000BIT TLT178209')
print(m) ## :zipcodeBIT TLT:zipcode
五、 等价用法 re.compile()
用于多次使用和匹配正则表达式,加快程序运行
re.compile(pattern, flags=0)
rst = re.search(r'[1-9]\d{5}' , 'BIT 361000')
##等价于
pat = re.compile(r'[1-9]\d{5}')
rst = pat.search('BIT 361000')
六、 Match对象
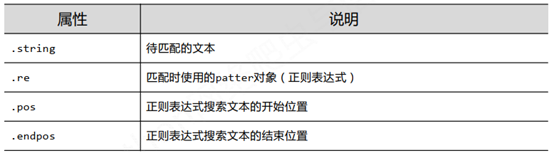
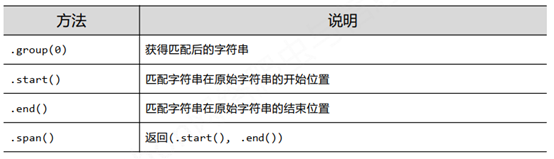
m = re.search(r'[1-9]\d{5}' , '361000BIT TLT178209')
print(m.string) ## 361000BIT TLT178209
print(m.re) ## re.compile('[1-9]\\d{5}')
print(m.pos) ## 0
print(m.endpos) ## 19
print(m.group(0)) ## 361000 ##返回第一次匹配地结果
print(m.start()) ## 0
print(m.end()) ## 6
print(m.span()) ## (0, 6)
七、 Re库地贪婪匹配—输出匹配最长地子串
match = re.search(r'啦啦.*去','咕咕咕啦啦啦去狗狗去猫猫去来来去') print(match.group(0)) ## 啦啦啦去狗狗去猫猫去来来去
八、 Re库地最小匹配 ,操作符后面加一个 ?
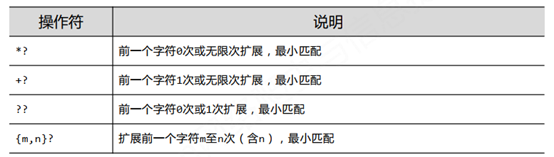
match = re.search(r'啦啦.*?去','咕咕咕啦啦啦去狗狗去猫猫去来来去') print(match.group(0)) ## 啦啦啦去

