【MOOC】信息标记与提取【<>.find_all()】
一、 信息标记的三种形式【标记+信息】
1、 XML 标签,<> </>
扩展性好,但比较繁琐,标签占据大部分内容
用于Internet上的信息交互和传递

2、 JSON 有类型键值对 key : value,JavaScript面向对象
key,value都需要家双引号:”name”:”呱呱”
适合程序处理,比XML简洁
应用于移动应用云端和节点的信息通信
缺点:无法添加注释

3、 YAML 无类型键值对 key : value,用索引表达所属关系,不需要双引号
文本信息比例高,可读性强
各类系统的配置文件,有注释,易读,应用广泛

二、 信息提取
1、 完整解析信息标记形式,再提取关键信息
需要标记解释器
优点:信息解析准确
缺点:提取过程繁琐,速度慢
2、 直接搜索
对信息文本查找函数
优点:提取过程简洁,速度快
缺点:提取结果准确性于信息内容直接相关
3、 融合方法※
标记解析器+文本查找函数
##查找网页中所有的链接
import requests
from bs4 import BeautifulSoup
r = requests.get('http://python123.io/ws/demo.html')
demo = r.text
soup = BeautifulSoup(demo,'html.parser')
for link in soup.find_all('a'):
print(link.get('href'))
三、 基于bs4库的HTML 内容查找方法【文本检索】
1、<>.find_all(name , attrs , recursive , string , **kwargs)
返回列表类型,存储查找的结果
(1) name:需要检索的标签名字
import requests
from bs4 import BeautifulSoup
r = requests.get('http://python123.io/ws/demo.html')
demo = r.text
soup = BeautifulSoup(demo,'html.parser')
##查找所有的 <a> </a> 标签
print(soup.find_all('a'))
##查找所有的 <a> 和 <b> 标签
print(soup.find_all(['a','b']))
##查找所有的标签
print(soup.find_all(True))
for tag in soup.find_all(True):
print(tag.name)
#查找出所有以 b 开头的标签
import re ##正则表达式库
for tag in soup.find_all(re.compile('b')):
print(tag.name)
(2) attrs:对标签属性值的检索
print(soup.find_all('p','course'))
##返回列表类型,返回带有 ‘course’ 值的 <p> 标签,模糊查找
print(soup.find_all(id = 'link1'))
##返回列表类型,查找id属性为‘link1’的标签,精确查找
import re
print(soup.find_all(id = re.compile('link')))
##查找id属性开头为‘link’的标签,模糊查找
(3) recursive:是否对所有子孙节点进行搜索,默认True,若设为False只搜索子节点
(4) string:<> </> 对标签中的字符串域进行检索
#搜索包含 python 的字符串
import re
print(soup.find_all(string = re.compile('python')))
2、简写形式 soup.find_all( ) = soup( )
print(soup('a'))
print(soup.find_all('a'))
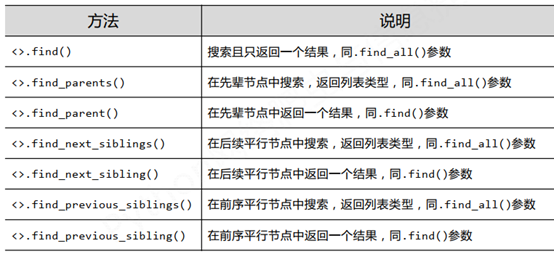
3、扩展方法