【MOOC】BeautifulSoup库
Requests库—自动爬取HTML页面,自动网络请求提交
Robots.txt—网络爬虫排除标准
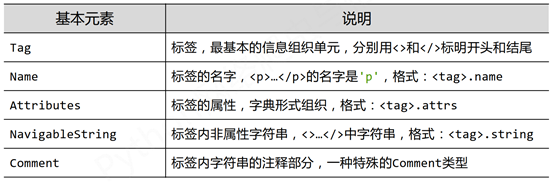
BeautifulSoup库—解析HTML页面,信息标记与提取方法
解析、遍历、维护 “标签树”<> </> 的功能库
一、解析器:根据html文件类型来选择

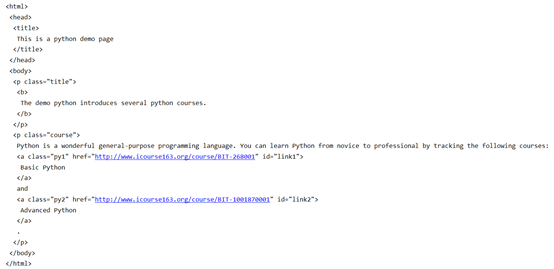
import requests
from bs4 import BeautifulSoup ##从bs4库中导入BeautifulSoup类
r = requests.get('http://python123.io/ws/demo.html')
demo = r.text
soup = BeautifulSoup(demo , 'html.parser') ##html.parser解析demo的解析器,demo是需要解析的html格式信息
二、Beautiful Soup类的5个基本元素
import requests
from bs4 import BeautifulSoup ##从bs4库中导入BeautifulSoup类
r = requests.get('http://python123.io/ws/demo.html')
demo = r.text
soup = BeautifulSoup(demo , 'html.parser') ##html.parser解析demo的解析器,demo是需要解析的html格式信息
print(soup.title) #打印标题 <title>This is a python demo page</title>
#获得标签,类型为 bs4.element.Tag
tag = soup.a ##链接标签
print(tag) ##只能获取第一个链接标签的内容 <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>
#获得标签名字,字符串类型
print(soup.a.name) ##获得链接标签的名字 a
print(soup.a.parent.name) ##获得链接标签父标签的名字 p
print(soup.a.parent.parent.name) ##获得链接标签父标签父标签的名字 body
#获得标签属性,字典类型
print(tag.attrs)##{'href': 'http://www.icourse163.org/course/BIT-268001', 'class': ['py1'], 'id': 'link1'}
print(tag.attrs['class'])##获得class属性的值 ['py1']
print(tag.attrs['href']) ##'http://www.icourse163.org/course/BIT-268001'
#获得<> </> 之间的内容,就是显示在网页中间的内容,类型为bs4.element.NavigableString
print(tag.string) #Basic Python
print(soup.p.string)
#获得页面注释 html页面注释 <!-- -->
print(soup.b.comment)
二、BeautifulSoup库的html内容遍历【标签树的遍历】
迭代类型只能用在 for……in 的循环结构中
1、下行遍历

##标签树下行遍历
import requests
from bs4 import BeautifulSoup
r = requests.get('http://python123.io/ws/demo.html')
demo = r.text
soup = BeautifulSoup(demo , 'html.parser')
print(soup.head) #获取<head></head>标签
print(soup.head.contents) #获取head标签的儿子节点<title></title>,获得列表类型 [<title>This is a python demo page</title>]
print(soup.body.contents) #获取body标签的儿子节点
print(len(soup.body.contents)) #body标签的儿子节点列表由5个元素
print(soup.body.contents[1])
#下行遍历儿子节点
for child in soup.body.children:
if child == '\n': ##由于儿子节点中初标签之外,还包含\n等字符,所以遍历不输出换行符
continue
print(child)
#下行遍历孙子节点
for desc in soup.body.descendants:
if desc =='\n':
continue
print(desc)
2、上行遍历

##标签树上行遍历
import requests
from bs4 import BeautifulSoup
r = requests.get('http://python123.io/ws/demo.html')
demo = r.text
soup = BeautifulSoup(demo , 'html.parser')
print(soup.title) #获取<title></title>标签
print(soup.title.parent) #获取title标签的父亲节点<head></head>,获得列表类型 [<title>This is a python demo page</title>]
print(soup.html.parent) #获取html标签的父亲节点,由于html是最高级标签,其父亲标签是其自身
print(soup.parent) #soup没有父亲标签
##上行遍历
for parent in soup.a.parents: ##上行遍历a的所以父亲节点
if parent is None: #由于soup没有父亲节点,遍历到soup就停止
print(parent)
else:
print(parent.name)
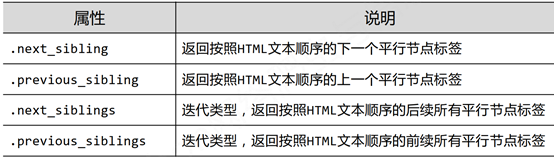
2、平行遍历
标签树的平行遍历必须发生在同一个父亲节点下
#标签树平行遍历
import requests
from bs4 import BeautifulSoup
r = requests.get('http://python123.io/ws/demo.html')
demo = r.text
soup = BeautifulSoup(demo , 'html.parser')
#标签树中字符也构成一个节点
print(soup.a.next_sibling)
print(soup.a.next_sibling.next_sibling)
print(soup.a.previous_sibling)
##平行后续遍历
for sibling in soup.a.next_siblings:
print(sibling)
##平行前续遍历
for sibling in soup.a.previous_siblings:
print(sibling)
三、BeautifulSoup类的html格式输出
prettify()方法可以给每一个标签和内容增加换行符,进行换行显示
import requests
from bs4 import BeautifulSoup ##从bs4库中导入BeautifulSoup类
r = requests.get('http://python123.io/ws/demo.html')
demo = r.text
soup = BeautifulSoup(demo , 'html.parser') ##html.parser解析demo的解析器,demo是需要解析的html格式信息
print(soup.prettify())