【Python编程与数据分析】数据类型
Python常用数据结构
1.序列(Sequence):
1.1 序列中每个元素都有自己的编号(位置/索引)
1.2 索引从0开始
1.3 Python内置序列类型:列表(list)、元组(tuple)、字符串(string)、 unicode字符串、buffer对象和xrange对象
2.映射(map):
2.1 字典(dict)是Python中唯一内建的映射类型
2.2 键-值对 (键值无重复)
3.集合(set)
3.1 无序排列、无法使用索引、元素不重复
Python高级数据结构
Collections模块
1.Counter(计数器): 统计一个list中元素出现的次数
2.Deque (双端队列): 在队列两端添加或删除
3.Defaultdict(默认字典): dict的子类, 如果键不在于字典中,会添加新的键并将值设为默认值
4.Nametuple(可命名元组): 给元祖的而每个元素起一个名字,这样就可以通过名字访问元素,有点类似字典
5.OrderedDict( 有序字典): 将无序的字典变为有序
列表
1.列表(List) ∈ 序列(Sequence)
1.1序列中每个元素都有自己的编号(位置/索引)
1.2索引从0开始
1.3用[]来表示
2.定义后可修改
3.每个元素的类型不必一致
4.几乎在所有情况下都可使用列表来代替元组
edward = ['Edward Gumby', 42]
john = ['John Smith', 50]
database = [edward, john]
列表(list)的基本操作
1.函数 list(object) :
1.1创建列表,创建空列表 : list()
1.2将字符串、字典、元组、集合等可迭代对象转换为列表
list(‘Hello’) # ['H', 'e', 'l', 'l', 'o’]
1.3转换回字符串: ''.join( ['H', 'e', 'l', 'l', 'o’] )
2.修改列表:给某个元素赋值
x = [1,1,1]
x[1] = 2
x # [1,2,1]
3.删除元素
names = ['Alice', 'Beth', 'Cecil', 'Dee-Dee', 'Earl']
del names[2:4]
names # ['Alice', 'Beth', 'Earl']
4.切片赋值 (批量赋值)
name = list('Perl') # ['P', 'e', 'r', 'l']
name[2:] =list(‘ar’) # ['P', 'e', 'a', 'r’]
# 将切片替换为长度与其不同的序列
name[1:] = list('ython') #['P', 'y', 't', 'h', 'o', 'n']
# 在某位置插入新元素
numbers = [1, 5]
numbers[1:1] = [2, 3, 4]
numbers # [1, 2, 3, 4, 5]
# 用切片赋值操作来删除元素
numbers = [1, 2, 3, 4, 5]
numbers[1:4] = []
numbers # [1, 5]
列表的常用方法
1.方法的调用:object.method(arguments)
2.append, clear
lst = [1, 2, 3]
lst.append(4) # [1,2,3,4] ,将对象附加到队列末尾
lst.clear() # [] ,清空列表内容 类似于 lst [ : ] = [ ]
3.copy
另外开辟空间,不同于b=a
a = [1, 2, 3]
b = a.copy() # a[:]或list(a)也都复制a
b[1] = 4
a # [1,2,3]
4.count:统计列表中某元素出现的次数
x = [[1, 2], 1, 1, [2, 1, [1, 2]]]
x.count(1) # 2
5.extend 将多个值添加到列表队尾
a = [1, 2, 3]
b = [4, 5, 6]
a.extend(b) # a=a+b 结果等同于 a.extend(b),但效率低
a # [1, 2, 3, 4, 5, 6]
6.index : 在列表中查找指定值第一次出现的索引
knights = ['We', 'are', 'the', 'knights', 'who', 'say', 'ni']
knights.index(‘who’) # 4
knights.index(‘herring‘) # error
7.insert : 在索引处插入对象到列表
numbers = [1, 2, 3, 5, 6, 7]
numbers.insert(3, 'four‘)
numbers # [1, 2, 3, 'four', 5, 6, 7]
8.pop : 从列表中删除一个元素,并返回此元素
既修改列表,又返回非none值
numbers.pop() # [1, 2, 3, 'four', 5, 6] # 默认弹出最后一个元素
numbers.pop(0) # [2, 3, 'four', 5, 6] # 指定位置弹出
9.remove : 删除第一个指定的元素
与pop不同的是,remove修改列表,但不返回值
x = ['to', 'be', 'or', 'not', 'to', 'be']
x.remove('be') # ['to', 'or', 'not', 'to', 'be']
10.reverse: 反序排列列表中元素
修改列表,但不返回值
11.sort : 就地排序,修改列表,无返回值
y = x.sort() # x已排完序,y为none
# 函数sorted:非就地排序
x = [4, 6, 2, 1, 7, 9]
y = sorted(x) # 有返回值,不改变x,可获得排序后的副本
x # [4, 6, 2, 1, 7, 9]
y # [1, 2, 4, 6, 7, 9]
高级sort
◼方法sort接受两个可选参数:key和reverse
◼key=len:根据元素长度排序
x = ['aardvark', 'abalone', 'acme', 'add', 'aerate']
x.sort(key=len)
x # ['add', 'acme', 'aerate', 'abalone', 'aardvark’]
# 获取elem的第二个元素
def takeSecond(elem):
return elem[1]
random = [(2, 2), (3, 4), (4, 1), (1, 3)]
# 指定第二个元素排序
random.sort(key=takeSecond)
# 输出
print(random)
#[(4, 1), (2, 2), (1, 3), (3, 4)]
reverse参数可以指定为True/False,表示是否要反序排列
x = [4, 6, 2, 1, 7, 9]
x.sort(reverse=True) # 排序后再反序
x # [9, 7, 6, 4, 2, 1]
元组
1.不可修改的序列:与列表唯一的区别
2.用逗号分隔,可用( )括起来
x = 1, 2, 3
x = (1, 2, 3)
( ) # 空元组
x = 42, # (42,) 只有一个值的元组,最后需有一个逗号
3 * (40 + 2) # 126
3 * (40 + 2,) # (42, 42, 42)
3.tuple(iterable) 方法
◼ 传入序列,创建元组
◼ 与list函数类似
tuple([1, 2, 3]) # (1, 2, 3)
tuple(‘abc’) # ('a', 'b', 'c’)
tuple((1, 2, 3)) # (1, 2, 3)
4.元组取值操作和列表一样
5.一般使用列表足以满足对序列的要求,存在意义?
◼ 元组可用作映射中的键(以及集合的成员),而列表不行。
◼ 有些内置函数和方法返回元组
字符串
1.所有标准序列操作都适用于字符串
◼ 索引,切片,乘法,加法,成员资格检查,长度,最小最大值
2.字符串不可变
◼ 元素赋值和切片赋值都非法,报错
# below both error
x = 'abcdef'
x[-3:] = ‘aaa'
3.字符串格式设置
◼ 转换说明符——百分号(%)。
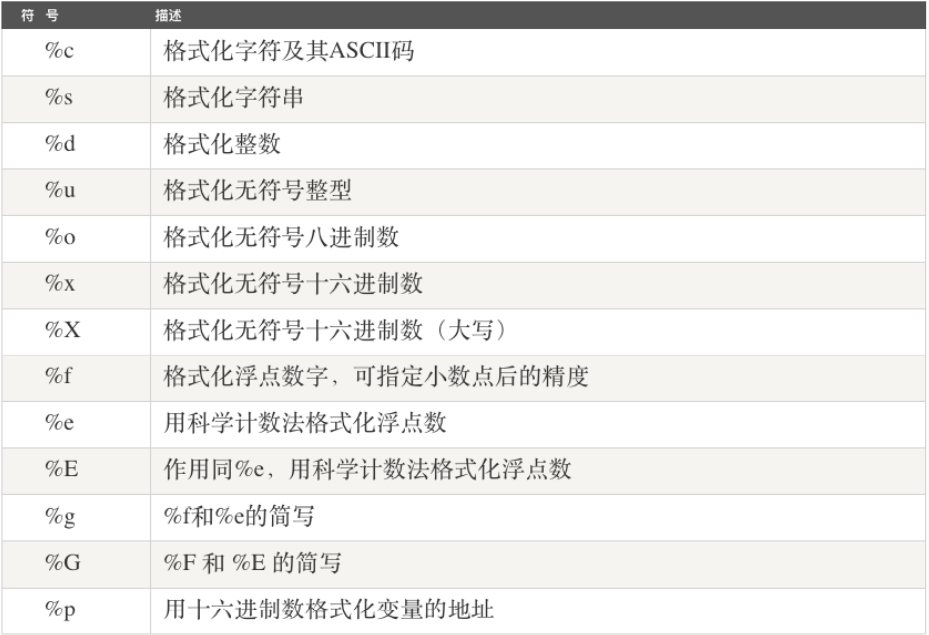
◼ 模版字符串
from string import Template # 使用Template()创建模板
tmpl = Template("Hello, $who! $what enough for ya?")
tmpl.substitute(who=“Mars”, what=“Dusty”) # 'Hello, Mars! Dusty enough for ya?'
◼ 字符串方法format(推荐)
“{}, {} and {}”.format(“first”, “second”, “third”) # 'first, second and third'
“{3} {0} {2} {1} {3} {0}”.format(“be”, “not”, “or”, “to”) # ‘to be or not to be’ 使用索引
# 使用关键字参数
# 结果: 'π is approximately 3.14.'
from math import pi
"{name} is approximately {value:.2f}.".format(value=pi, name="π")
◼ f字符串: 如果变量与替换字段同名,可使用f字符串简写。在字符串前加上f
# 输出:"Euler's constant is roughly 2.718281828459045."
from math import e
f"Euler's constant is roughly {e}."
# 或者
"Euler's constant is roughly {e}.".format(e=e)
输出:"Euler's constant is roughly 2.718281828459045."
字符串基本转换
1.设置花括号内字段的格式
◼ 转换标志:!
◼ 三种标志: !s (与原值一样), !r(原值加引号), !a(带引号的ascii编码)
print("{pi!s} {pi!r} {pi!a}".format(pi="π"))
# π 'π' '\u03c0'
◼ 格式说明符(冒号:)
"The number is {num:f}".format(num=42)
# 'The number is 42.000000’
"The number is {num:b}".format(num=42)
'The number is 101010'
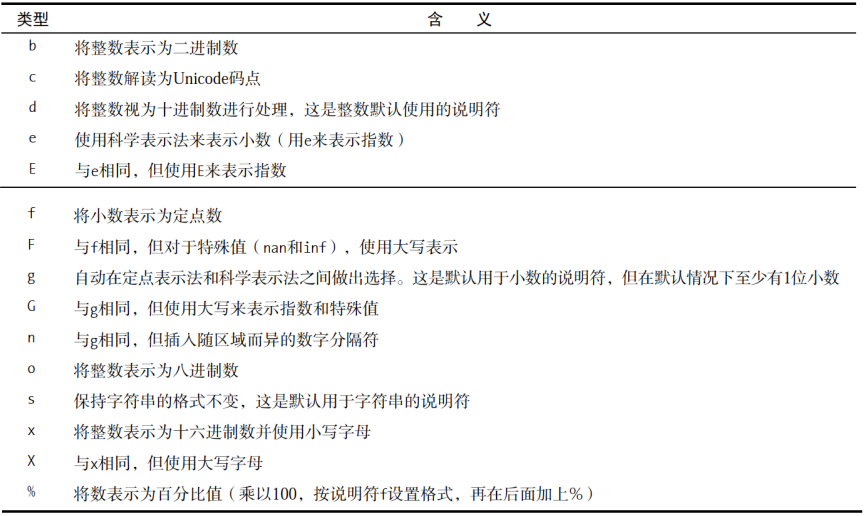
类型说明符表格
宽度、精度、千位分隔符
1.宽度使用整数指定
◼ 数和字符串对齐方式不同
"{num:10}".format(num=3)
# ' 3'
"{name:10}".format(name="Bob")
# 'Bob '
2.精度也使用整数指定
◼ 可同时指定宽度和精度
"{pi:10.2f}".format(pi=pi)
# ' 3.14'
3.千分位分隔符:逗号
‘One googol is { :, }'.format(10**10)
# 'One googol is 10,000,000,000'
符号、对齐、用0填充
1.在指定宽度和精度的数前面,可添加一个标志
◼ 可以是零、加号减号或空格
◼ 零表示使用0来填充
'{:010.2f}'.format(pi)
# '0000003.14’
# 010.2f中,第一个0表示用0填充,10表示宽度
2.左对齐(<)、右对齐(>)、居中(^)
print('{0:<10.2f}\n{0:^10.2f}\n{0:>10.2f}'.format(pi))
3.14
3.14
3.14
3.说明符 “=”,将填充字符放在符号和数字之间
print('{0:10.2f}\n{1:=10.2f}'.format(pi, -pi)) # 此处没有指定填充字符,默认为空格
# 3.14
#- 3.14
# 如果想使用$号填充,则:
print(‘{0:10.2f}\n{1:$=10.2f}’.format(pi, -pi))
4.加号、减号:显示正负号
print('{0:-.2}\n{1:-.2}'.format(pi, -pi)) # 显示负号是默认的,不写也行
3.1
-3.1
print('{0:+.2}\n{1:+.2}'.format(pi, -pi)) # 当数字是正数时,显示正号
+3.1
-3.1
字符串的方法
1.center方法:通过填充,让字符居中
"The Middle by Jimmy Eat World".center(39, "*") '*****The Middle by Jimmy Eat World*****'
2.find方法:查找子串,返回第一个字符索引,或-1
◼ str.find(str, start=0, end=len(string))
'With a moo-moo here, and a moo-moo there'.find('moo’)
# 7
# 区别于成员资格检查:in(返回True/False)
str='$$$ Get rich now!!! $$$'
str.find(‘!!!’, 0, 16) # 指定了查找的起点和终点
3.join方法:与split相反,用于合并序列元素
sep = ‘+’
seq = ['1', '2', '3', '4', '5']
sep.join(seq) # 用加号合并一个字符串列表
# '1+2+3+4+5'
4.lower,upper方法:返回字符串的小写/大写版本
5.replace方法:将指定子串替换为另一个字符串
◼ replace(old, new, count=-1, /)
`'This is a test'.replace('is', 'eez’)
'Theez eez a test'
6.strip方法:把开头和末尾的空格删除,并返回
◼ str.lstrip()、str.rstrip()`
7.split方法:将字符串拆分为序列,默认按空格和换行
◼ split(sep=None, maxsplit=-1)
'1+2+3+4+5'.split('+’)
#['1', '2', '3', '4', '5']
8.判断字符串是否满足特定条件的方法:is开头,返回True/False
◼ isalnum、isdigit、isidentifier、islower、isnumeric、isprintable、isspace、isupper


isdigit()
True: Unicode数字,byte数字(单字节),全角数字(双字节),罗马数字
False: 汉字数字
Error: 无
isdecimal()
True: Unicode数字,,全角数字(双字节)
False: 罗马数字,汉字数字
Error: byte数字(单字节)
isnumeric()
True: Unicode数字,全角数字(双字节),罗马数字,汉字数字
False: 无
Error: byte数字(单字节)
字典(python唯一内置映射)
1.字典:
◼ 通过键(不重复),访问值(键-值对)
◼ 不按顺序排列
◼ 键可以是 数、字符、元组 (不可变的类型)
2.创建和使用字典
phonebook = {'Alice': '2341', 'Beth': '9102', 'Cecil': '3258’} # 键-值对称为项(item)
空字典 : {}
3.函数dict():从其他字典或者键-值序列创建字典
items = [('name', 'Gumby'), ('age', 42)]
d = dict(items) #{'age': 42, 'name': 'Gumby’}
d = dict(name='Gumby', age=42)
4.字典的基本操作
◼ len(d) : 返回字典的项数
◼ d[key] : 返回键key的值
◼ d[key] = v : 将值v关联到键key
◼ del d[key] : 删除键为k的项
◼ key in d :检查字典d中是否包含键是k的项
字典方法
- clear:删除所有字典项,无返回值
x = {}
y = x
x['key'] = 'value‘
y #{'key': 'value’}
x = {} # 并不能清空,而是在内存中开辟一个空字典,并贴上名为x的标签
y #{'key': 'value’}
x.clear() # 清空x中的内容
y # {} y指向的内容也被清空
2.copy:浅复制(无法复制嵌套的值)
也就是说y=x.copy(),改y的值,x也会跟着变
3.deepcopy( 深复制 )
◼ 同时复制值及其包含的所有值
◼ 需使用 模块copy中的函数deepcopy
from copy import deepcopy
y = deepcopy(x)
4.fromkeys:只使用键创建新字典,值为None
dict.fromkeys(['name', 'age’])
5.get方法:访问字典项
◼ 传入键,返回值
d = {}
print(d['name']) # 报错
# 使用get()不会报错:
print(d.get('name')) # None
6.items():
◼ 返回包含所有项的列表,每个元素为(key,value)的形式
X=dict.fromkeys(['name', 'age'])
print(X.items()) # dict_items([('name', None), ('age', None)])
7.pop():获取key的值,并删除键-值对
dict.pop(‘key’) # return value
8.popitem():随机弹出字典项
◼ 字典项的顺序不确定,只能随机pop
◼ 可高效的逐个删除并处理所有字典项
9.keys方法:
◼ 返回字典视图,包含所有键。
10.values方法:
◼ 返回所有值(可重复)
集合
1.集合(set)是一个无序、不重复元素序列
◼ 使用{ }表示集合(字典也是{ })
◼ 也可使用set()函数创建集合
◼ 创建空集合需使用set(),而不是{ } (空字典)
basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana’}
print(basket) # {'orange', 'banana', 'pear', 'apple’}
a = set('abracadabra') # 用字符串创建集合
print(a) # {'a', 'r', 'b', 'c', 'd'}
◼ 集合间运算符:-(差集), |(并集), &(交集)
集合方法

2.由内置类set实现
◼ 老版本需导入模块sets
◼ 集合是可变的,不可用做字典中的键
◼ 集合只能包含不可变的值,因此不能包含其他集合
◼ 使用fronzenset类型可以嵌套集合
a.add(frozenset(b))
Python中的内置数字类型
1.int类型
◼ 包括正整数,0和负整整,不能包含小数点
◼ int类型默认为10进制的,我们也可以在程序中使用二进制、八进制和十六进制的整型数字
2.float类型
◼ float类型是含小数点的数字。包括正负浮点数
◼ 也可以使用“e”或“E”来定义科学计数法的浮点数
x = 1.2E3
print(x) # 输出1200.0
y = 12.34e3
print(y) # 输出12340.0
3.complex类型
◼ 复数类型有两部分组成:实部和虚部,复数的虚部在Python中使用j来做后缀。

堆(heap)
1.一种优先队列
◼ 能够以任意顺序添加对象
◼ 随时找出(并删除)最小的元素:比列表的min方法要高效
2.模块heapq(q表示queue)
◼ Python中没有独立的堆类型,需要使用模块

3.heappush:往堆中添加元素
heappush(heap, 0.5)
4.heap特征:
位置i处的元素总是大于位置i // 2处的元素(反过来说就是小于位置2 * i和2 * i + 1处的元素)。这是底层堆算法的基础
heappop弹出最小元素(总是位于索引0处)
5.heapify将列表变成合法的堆
如果堆不是用heappush创建的,则应该在使用heappush和pop之前使用heapify
heap = [5, 8, 0, 3, 6, 7, 9, 1, 4, 2]
heapify(heap)
6.heapreplace方法 :弹出最小元素、同时压入一个新元素
heapreplace(heap, 10)
列表推导
1.定义:从其他列表创建列表的一种方式
- 类似for循环
- 需要用方括号[]括起来。(因为是列表)
- 例:由range(10)内每个值的平方组成的列表:
[x * x for x in range(10)] # [0, 1, 4, 9, 16, 25, 36, 49, 64, 81] - 可以在推导中添加一条if语句
[x * x for x in range(10) if x % 3 == 0] # [0, 9, 36, 81]
# for前面的部分(x*x),代表所生成列表中的元素
5.添加更多for的部分
[(x, y) for x in range(3) for y in range(3)] # [(0, 0), (0, 1), (0, 2), (1, 0), (1, 1), (1, 2), (2, 0), (2, 1), (2, 2)]
6.使用多个for时,也可以添加if子句
girls = ['alice', 'bernice', 'clarice']
boys = ['chris', 'arnold', 'bob']
[b+'+'+g for b in boys for g in girls if b[0] == g[0]]
# ['chris+clarice', 'arnold+alice', 'bob+bernice']
字典推导
1.可使用花括号来执行字典推导。
squares = {i:"{} squared is {}".format(i, i**2) for i in range(10)}
squares[8] # '8 squared is 64'
在列表推导中,for前面只有一个表达式,而在字典推导中,for前面有两个用冒号分隔的表达式。这两个表达式分别为键及其对应的值。
squares = {i: i*i for i in range(10)}
print(squares) # {0: 0, 1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81}
生成器(generator)
1.生成器是一种使用普通函数语法定义的迭代器
nested = [[1, 2], [3, 4], [5]]
def flatten(nested):
for sublist in nested:
for element in sublist:
yield element # 包含yield语句的函数都被称为生成器
2.生成器不使用return返回值,而是可以生成多个值,每次一个。每次使用yield生成一个值后,函数都将冻结,即在此停止执行,等待被重新唤醒。被重新唤醒后,函数将从停止的地方开始继续执行。使用next()函数逐个取出
3.若想使用生成器的所有的值,可对生成器进行迭代。
nested = [[1, 2], [3, 4], [5]]
for num in flatten(nested):
print(num)
# 1
# 2
# 3
# 4
# 5
# 也可以
x = list(flatten(nested))
x
[1, 2, 3, 4, 5]
生成器推导
1.使用圆括号代替方括号不能实现元组推导,而是创建生成器
2.生成器推导(也叫生成器表达式),可以逐步计算
◼ 工作原理与列表推导相同,但不是创建一个列表(即不立即执行循环),而是返回一个生成器
g = ((i + 2) ** 2 for i in range(2, 27)) # 此时,g是一个生成器
next(g) # 16
next(g) # 25
3.优点:
a.迭代量大时,占内存少 b.代码优雅 sum(i ** 2 for i in range(10))
迭代器
1.生成器不但可以作用于for循环,还可以被next()函数不断调用并返回下一个值
◼ 可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator
# 生成器也是Iterator对象
# list、dict、str不是Iterator实例
# tuple也不是Iterator实例
# Python 3.10版本开始要改为:from collections.abc import Iterator, Generator
from collections import Iterator, Generator
isinstance((x for x in range(10)), Generator) # True
isinstance((x for x in range(10)), Iterator) # True
isinstance([], Iterator) # False
isinstance({}, Iterator) # False
isinstance('abc', Iterator) # False
2.任何实现了__iter__() 和 next()方法的对象都是迭代器
- ◼ iter() 返回迭代器自身
- ◼ next() 返回下一个值
- ◼ 如果迭代时没有更多元素了,则抛出StopIteration异常
- ◼ 例:itertools这个模块内含有多种类型的迭代器
- ◼ count方法用于生成连续整数,从13开始的无限整数序列,是一种迭代器
from itertools import count
counter = count(start=13)
next(counter) # 13
next(counter) # 14
自定义迭代器
class Fib:
def __init__(self):
self.prev = 0
self.curr = 1
def __iter__(self):
return self
def __next__(self):
value = self.curr
self.curr += self.prev
self.prev = value
return value
f = Fib()
for x in f:
print(x)
if(x>100):
break
可迭代对象(Iterable)
1.Iterable:可以直接作用于for循环的数据类型,有:
- ◼ 内置数据类型,如list、tuple、dict、set、str
- ◼ 生成器,包括生成器推导和带yield的生成器函数
- ◼ 迭代器
2.使用isinstance()查看是否是可迭代对象
from collections.abc import Iterable # 需导入模块
isinstance([], Iterable) # True
isinstance({}, Iterable) # True
isinstance('abc', Iterable) # True
isinstance((x for x in range(10)), Iterable) # True
迭代器与生成器区别
- 生成器只能遍历一次,而迭代器可以迭代多次。
- 生成器是一类特殊的迭代器, 它的返回值不是通过return而是用yield 。
lambda表达式
1.也叫做匿名函数: 能够创建内嵌的简单函数: lambda arg1,arg2,arg3… :<表达式>
f = lambda x: x.isalnum()
f("aa12") # true
g = lambda x, y: x + y # 多个参数
g(1,2) # 3
2.lambda与def的区别:
- ◼ def创建的方法是有名称的,而lambda没有
- ◼ lambda表达式 ” : “ 后面,只能有一个表达式,def则可以有多个
- ◼ 像 if 或 for 等语句不能用于lambda中
- ◼ lambda表达式不能共享给别的程序调用(写单独脚本时候用)
结合map、filter、reduce函数
- map(function, sequence)会根据提供的函数对指定序列的每个元素做映射
lst = ['1','2','3','4']
list(map(int,lst)) # [1, 2, 3, 4]
str = "1234"
list(map(int,str)) # [1, 2, 3, 4]
foo = [2, 18, 9, 22]
list(map(lambda x: x * 2 + 10, foo)) # [14, 46, 28, 54]
2.filter(function, sequence)函数——筛选函数
- ◼ 按照 function函数的规则在列表 sequence 中筛选数据
lst =[1,2,3,4]
list(filter(lambda x: x>2, lst)) # [3, 4]
3.reduce(function, sequence)——求积累运算
- ◼ 将sequence 中数据,按照 function 函数操作,如将列表第一个数与第二个数进行 function 操作,得到的结果和列表中下一个数据进行function 操作,一直循环,返回一个值
from functools import reduce
lst =[1, 2, 3, 4]
reduce(lambda x,y: x+y, lst) # 10
reduce(lambda x,y: x*y, lst) # 24
def myadd(x,y):
return x+y
lst =[1, 2, 3, 4]
reduce(myadd, lst) # 10

 浙公网安备 33010602011771号
浙公网安备 33010602011771号