8.Transformer模型
1- Transformer模型是什么
Transformer模型是一个基于多头自注意力的序列到序列模型(seq2seq model),整个网络结构可以分为编码器(encoder)和解码器(decoder)两部分。seq2seq模型输出序列的长度是不确定的。我们输入一个sequence后,先由encoder负责处理,再把处理好的结果输入到decoder中,由decoder决定最后输出什么样的sequence。Transformer的完整结构如下图所示:
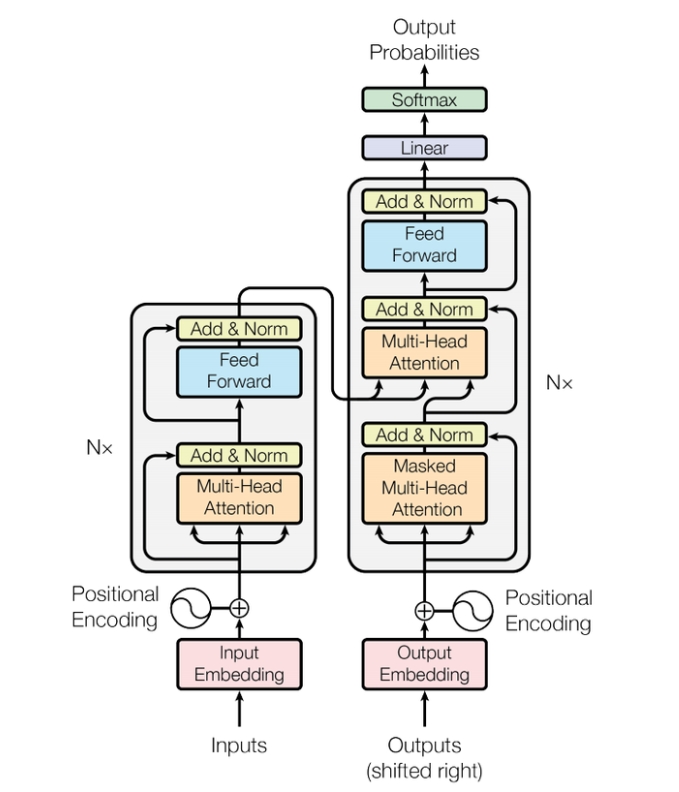
2- 编码器Encoder
2.1- encoder的输入输出
上图中左侧就是encoder部分, 由图中可以看出它里面有N个blocks, 每个block会输入一排向量, 然后输出一排向量作为下一个block的输入; 在每个block中, 输入会先经过一个自注意力层, 然后再通过一个全连接层之后输出;
2.2- Block中的自注意力层
encoder中自注意力层的输出和之前说过的有一些区别; 它应用了像Resnet模型那样的残差计算, 自注意力层计算出的结果会再加上原来的输入作为最终的输出, 这就是图中Add的含义; 之后我们再对输出进行一次归一化(normalization), 不过这里用的是不是之前用过的批量归一化(Batch Normalization), 而是层归一化(Layer Normalization);
对了, 观察图中可以发现这里用的就是多头注意力机制;
2.2.1- 批量归一化和层归一化
批量归一化我在之前卷积神经网络已经说过了, 所以这里只说说层归一化和批量归一化不同的点在哪;
批量归一化是在一批数据中, 对每个特征维度独立地进行归一化; 例如对于一个图像, 它的特征可能有颜色, 形状等; 这批数据的每个特征的均值都是0, 方差都是1; 而层归一化则是对针对单个数据, 对这个数据的所有特征进行归一化, 也就是让每个数据的所有特征均值为0, 方差为1;
直观来说, 我们可以想象一个立方体, 它有三个维度, x轴是一个批量的数据, y轴是特征, z轴是一个数据的值; 左图表示批量归一化, 他对一个批量的数据操作, 并且每次只选一个特征; 右图表示层归一化, 它每次只对一个数据操作, 每次选择全部特征;
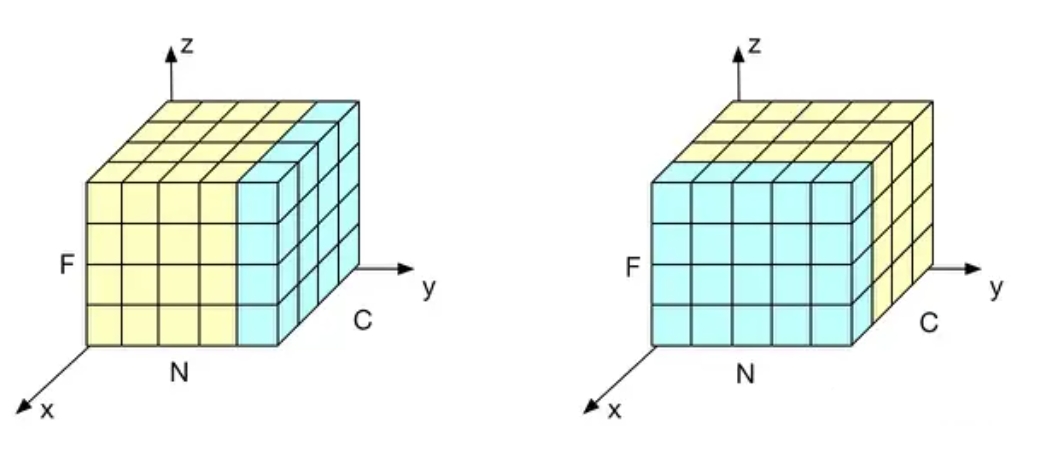
总结一下就是对于BN来说, 他更多的是关注样本之间的不同, 学习样本之间的差异性, 要考虑全局性; 而LN关于于样本自身的结构, 学习内部结构的特征; 这里因为样本之间的长度差异(embedding虽然会统一长度,但也只是补0而已)可能较大, 所以用BN的应用性并不是很好;
2.3- Block中的全连接层
经过层归一化后得到的输出会再经过一个全连接层, 并且全连接层的后面也会进行残差计算和层归一化; 之后就得到了当前block的输出;
3- 解码器Decoder
3.1- decoder的输入输出
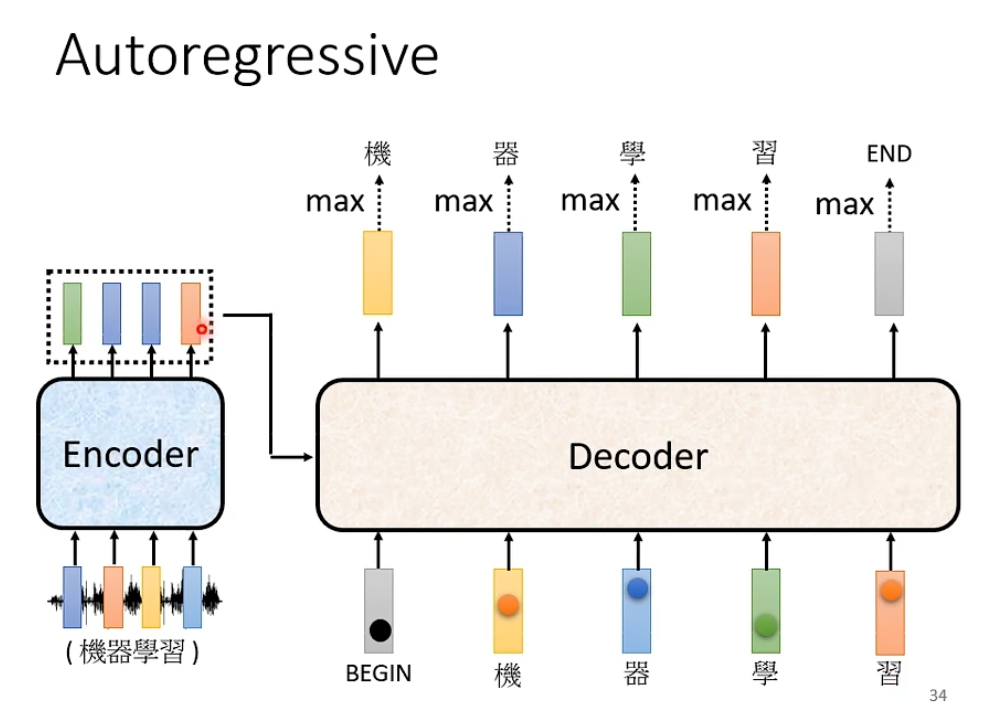
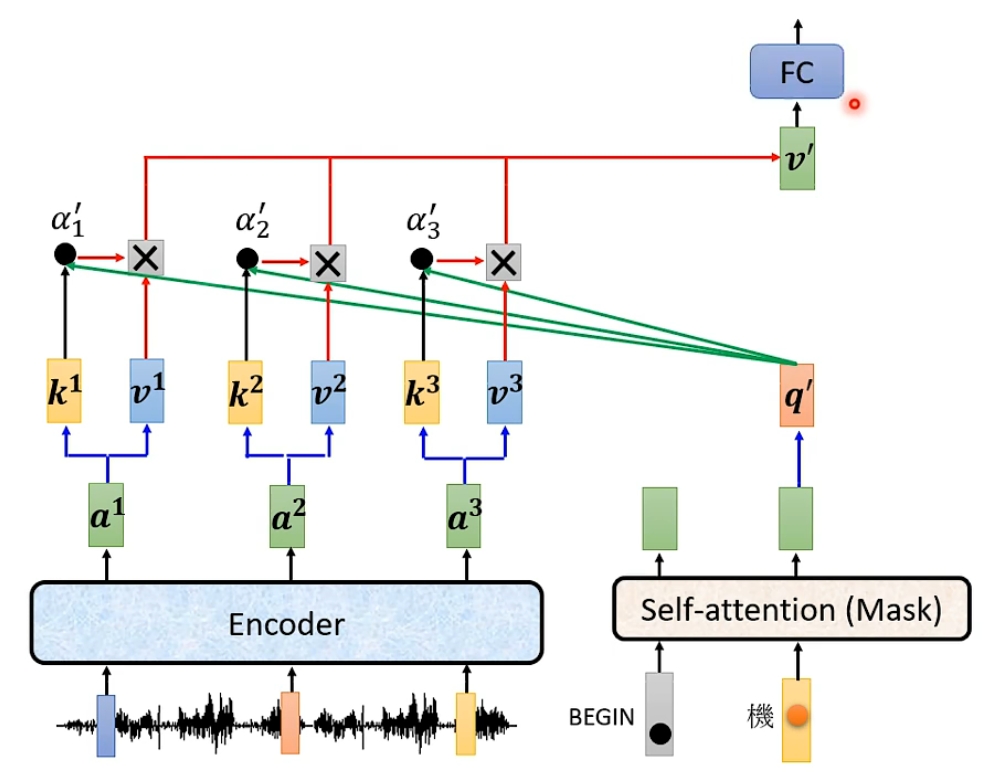
以语音识别为例, 我们输入一段声音给encoder, 然后输出一排向量, decoder读入这一排向量后输出文字; 在生成文字过程中, 我们首先会向decoder中输入一个特殊向量BEGIN, 表示进程的开始, 经过一系列处理后会输出一个向量; 在最开始的时候我们还会设置一个数据库, 里面有n个文字用于输出, 这个向量的长度就是n, 我们让这个向量通过一个softmax函数, 这样就得到了所有文字可能的概率, 输出其中概率最大的文字, 这就是图中的'机'; 接下来我们会把'机'也作为输入进行下一个文字的识别, 也就是说此时有BEGIN和'机'两个输入, 越到后面参与运算的输入越多;
那为什么要这样操作呢, 就像我在文章最开始说的, decoder的输出长度是不确定的(下图有四个输出完全是偶然), 完全由机器自己决定, 他需要不断根据语义和上文来进行调整, 如果我们像encoder那样一下子把所有输入都读进去, 那么decoder就无法根据生成过程中的反馈来调整自己的输出,可能会导致语法错误或语义不通; 但是这样decoder可能会永远都不会停下来; 所以我们要在数据库中准备一个特殊的符号END, 一般把它和BEGIN设为同一个符号, 当输出END时就可以停止了;
3.2- Block中的Masked Self-attention层
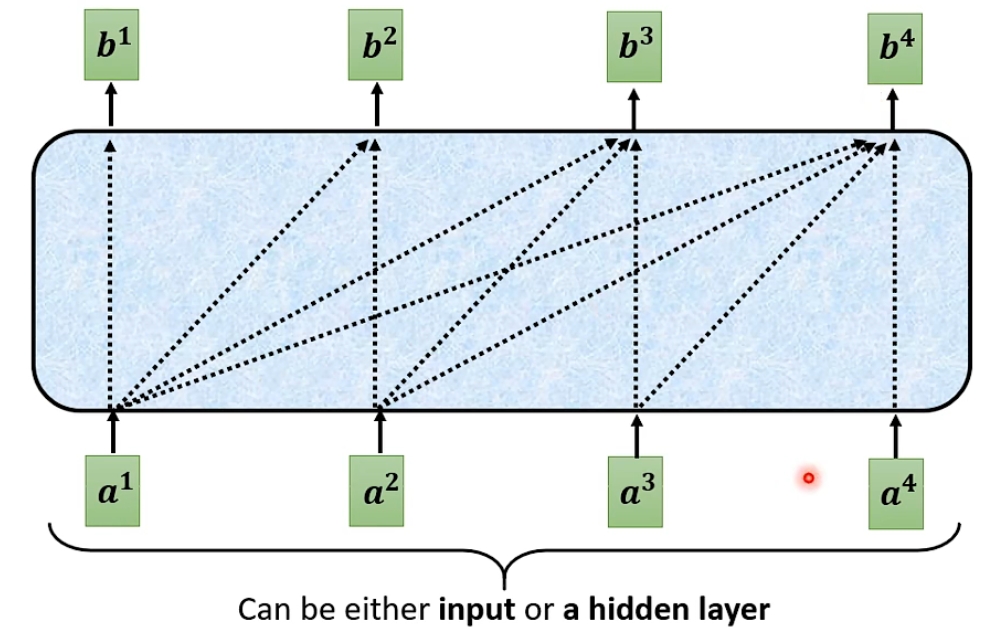
在decoder的block中第一个层是一个masked self-attention(掩盖自注意力)层; 自注意力层的每个输出都是和所有输入相关联的, 而掩盖自注意力层的第i个输出只和前i个输入有关; 这正是因为我上面所讲的, 当你处理第i个信息时, 我们只把前i个信息作为输入, 后面的还没给他读进去;
3.3- Block中的交叉注意力层(Cross-attention)
encoder的所有输出ai都会产生键ki和值vi, 经过掩盖自注意力层得到的输出会产生查询q, 该查询会和encoder的所有键运算得到注意力权重αi, 然后再和值运算得到最终的输出; 这个过程和自注意力是相似的;
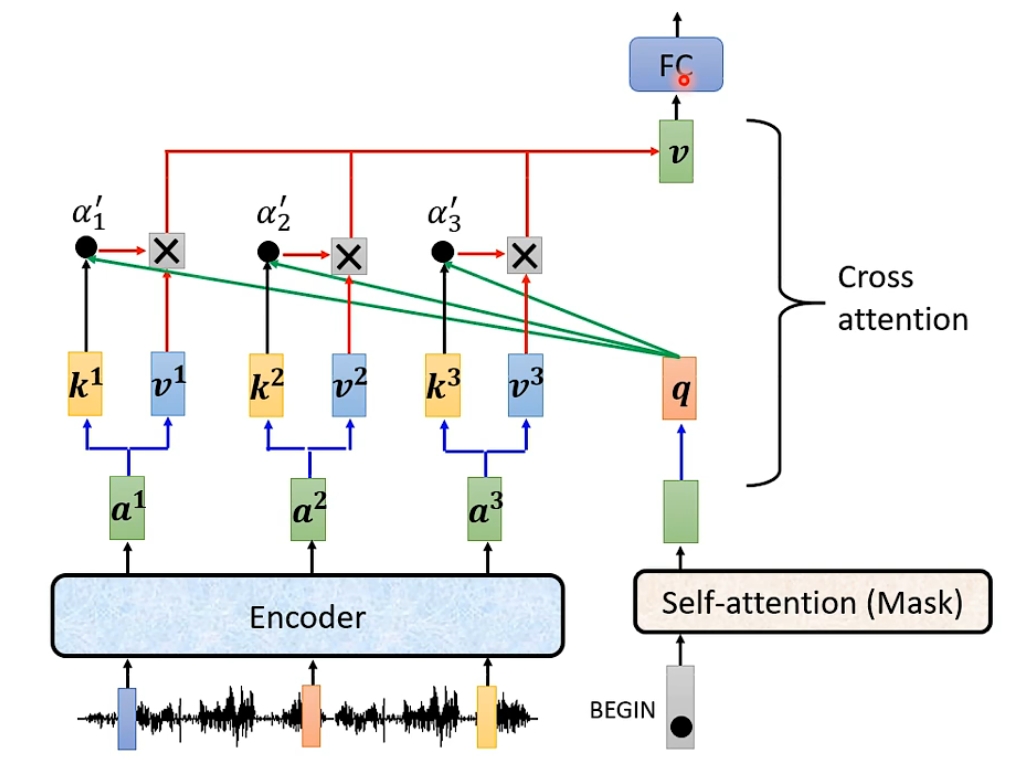
下一个block也是进行相同的运算;
4- 位置编码(Positional Encoding)
在Transformer模型的总览图中, encoder和decoder的输入后面都会紧跟一个位置编码的操作, 这是对输入进行排序; 因为Transformer模型没有循环结构, 所以它无法获取每个单词在句子中的相对位置, 在自注意力中"我爱你"和"你爱我"的结果是一样的; 为了让模型知道每个单词各自的前后顺序, 我们需要提前对所有向量进行位置编码排序;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号