7.注意力机制
1- 注意力机制的作用
注意力机制是为了更好地捕捉关键信息, 提高网络的运行效率; 注意力机制的输入往往是一个矩阵, 经过一些操作后我们会得到一个权重矩阵, 这个权重矩阵会根据输入元素对结果的影响程度对其分配一个权重, 将权重矩阵和输入矩阵相乘后就得到了输出矩阵, 输出矩阵会放大关键元素的作用; 例如在图像处理领域, 注意力机制可以帮助模型提取更有意义的特征, 在图像分类或目标检测任务中, 注意力机制可以让模型根据任务的需求, 自动地关注图像中的重要区域或对象, 而忽略没必要的背景或者噪声;
2- 自注意力机制的实现
注意力机制的本质是一种带权求和的过程,它根据一个查询(query)和一组键(key)来计算出对应的值(value)的加权和。查询和键之间的相似度决定了每个值的权重; 这里我们说一下自注意力机制的实现过程;
自注意力机制的思想是在处理输出序列时, 其中的每个元素都可以和序列中的其他元素相关联; 具体而言,对于序列中的每个元素,自注意力机制计算其与其他元素之间的相似度,并将这些相似度归一化为注意力权重。然后,通过将每个元素与对应的注意力权重进行加权求和,可以得到自注意力机制的输出
2.1- embedding操作
自注意力机制的最开始要对序列进行embedding, 操作就是每个元素都乘一个各自的权重矩阵, 其目的是将输入数据中的每个元素(比如词、像素点等)表示为一个向量,称为输入向量。这样做有两个好处:一是可以将不同类型或长度的输入数据统一为相同维度的向量表示,方便后续的计算。二是可以利用预训练好的词向量或图像特征等,提高输入向量的质量和含义。
2.2- 生成query, key, value
经过embedding操作之后每个序列中的元素都变成统一格式的向量ai作为注意力机制的输入; 然后下一步每个输入都会乘三个矩阵来生成qi, ki, vi, 其分别是Wq, Wk, Wv; 要注意的是所有的输入都是乘这三个矩阵, 也就是说这三个矩阵是所有输入所共享的, 同时这三个矩阵是可以训练的;
2.3- 生成注意力权重
qi的含义是用来计算当前输入和其他输入直接的相似程度和联系的; 而qi正是通过和其他输入的ki进行运算从而实现目的, 所以ki可以理解为当前输入的关键信息; 通过qi和其他输入的k, 我们就可以计算出第i个输入和所有输入之间(包括自己)的注意力权重αi j=qi * kj; (用q和k做乘法的方式求α的方法叫做Dot-product) 然后我们让所有注意力权重α经过一个激活函数(softmax, relu...)得到最终的注意力权重;
这里激活函数可以让所有注意力权重的值落在一个区间内(归一化), 并且可以增加离散性, 让大的更大, 小的更小; 这样可以让模型更加关注与当前查询相关的键和值,而忽略不相关或噪声的部分;
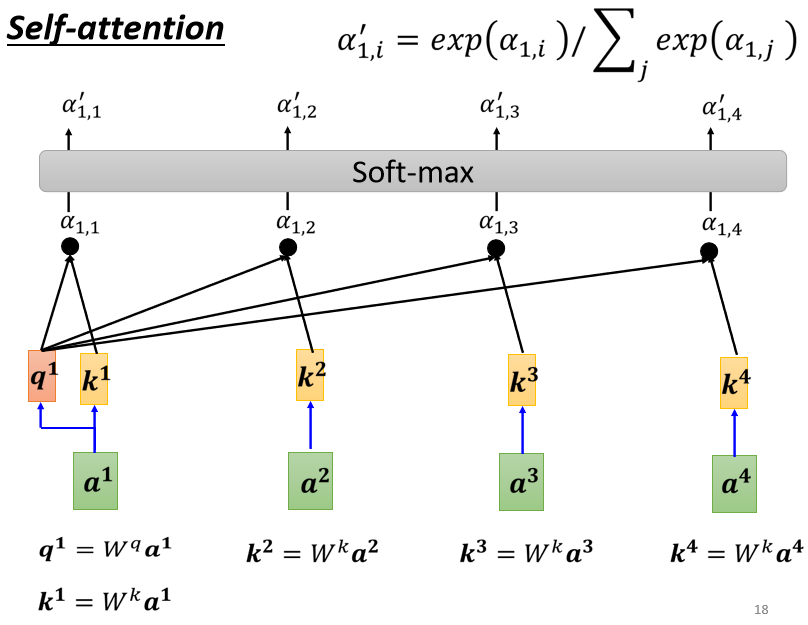
2.4- 生成输出
我们将得到的注意力权重αi j和各自的vj相乘后求和, 就得到了输出bi; 假设a1和a2的关联性很强, 则由这两个输入计算得到的α1 2就会很大, 最后求得的b1的值就会和v2很接近;
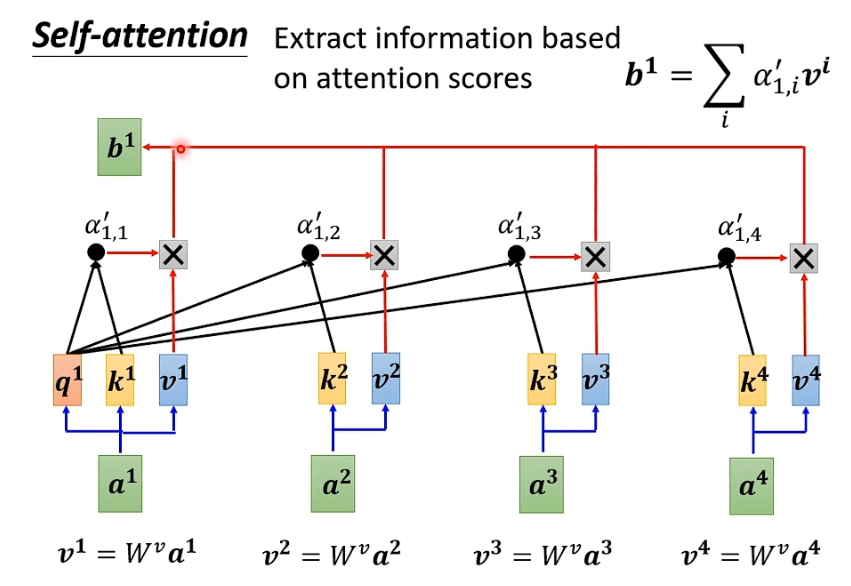
2.5- 并行运算
上面我们只是举了计算一个输出的例子, 但实际运算中注意力机制是并行运算的, 可以同时计算出所有输出b的值, 这是注意力机制很大的一个特点和优势, 可以大大加快运行速度; 其具体操作类似于全连接层的矩阵运算, 将每个qi, ki ,vi向量堆叠在一起成为矩阵;
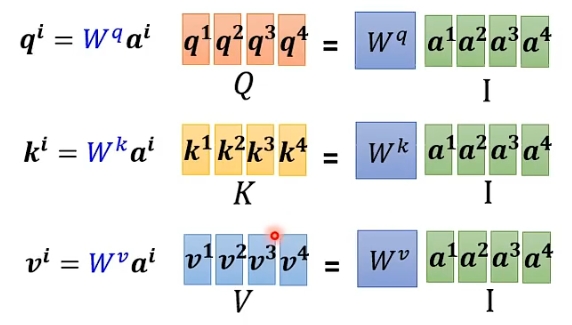
下面看一下注意力权重的并行计算过程, 将q的矩阵和k的转置矩阵做乘法就得到了所有注意力权重的矩阵;
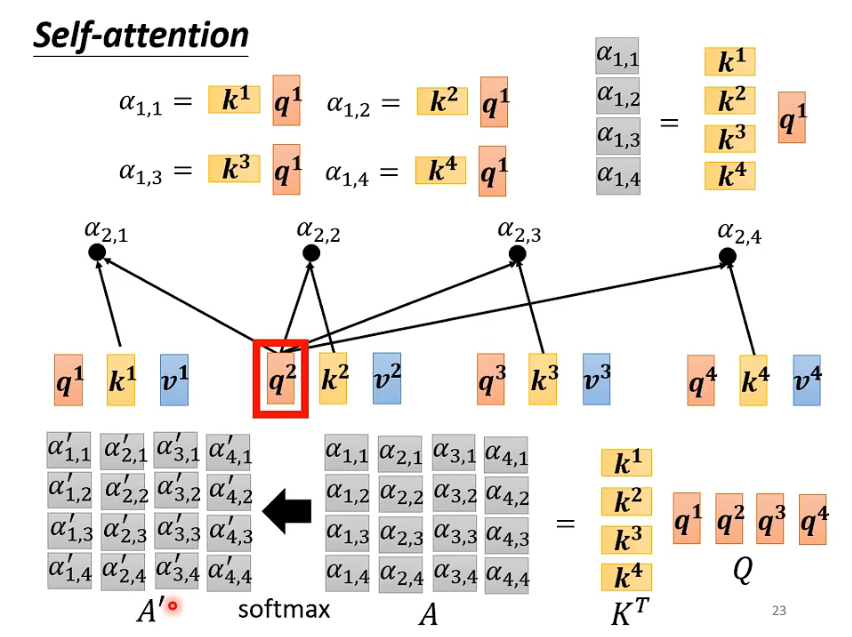
对于注意力权重矩阵, 它的第i列就是第i个输入的注意力权重; 所以我们可以用v的矩阵和注意力权重矩阵做乘法, 得到的就是输出矩阵, 第i列就是第i个输出; 这样就实现了并行运算;
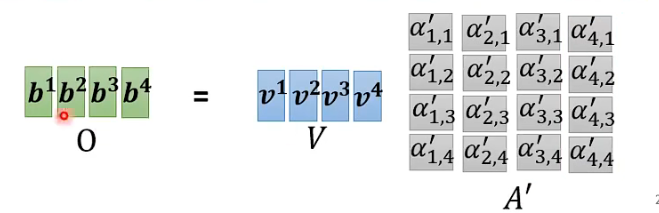
2.6- 注意事项
在这里我再详细说一下query, key, value的具体含义;
1.查询 (query) 是指要求输出的元素,它可以看作是一个问题,例如“这个词的词性是什么?”
2.键 (key) 是指用于匹配查询的元素,它可以看作是一个答案用于回答查询,例如“这个词是名词”
3.值 (value) 是指与键相关联的元素,它可以看作是一个补充信息,例如“这个词的含义是什么?”查询和键的维度相同,因为它们要用于计算点积相似度,表示两个元素之间的匹配程度
值的维度可以不同于查询和键,它们用于加权求和,表示输出元素的内容
而用于控制维度的就是一开始embedding操作;
3- 多头自注意力(Multi-head Self-Attention)
在前面讲的自注意力机制中, 我们用q去匹配相关的k, 但是很多情况输入之间的相关性不止一种, 也就是说我们可能需要很多个q来实现更准确的计算, 多种相关性对应到计算方式中就是多个矩阵q, 不同矩阵负责不同的相关性; 以双头自注意力为例, 用两个不同的查询矩阵Wq1和Wq2对原来的qi进行处理得到多个q; k和v也是同理; 在后续的计算中, 我们只需要把同一个相关性下的矩阵进行运算, 例如图中, qi2只和ki2, kj2进行运算得到αi2和αj2, 然后αi2和αj2再与vi2和vj2进行运算得到bi2和bj2
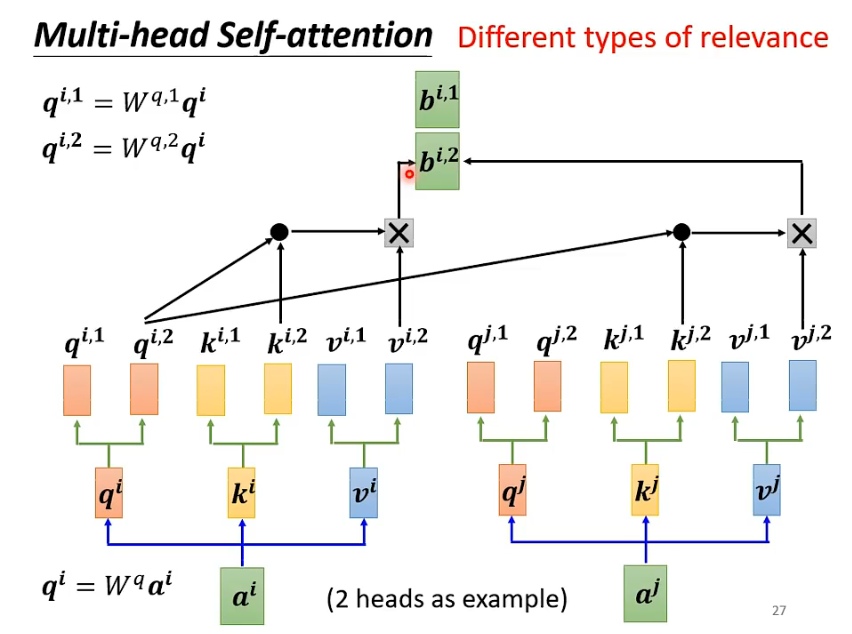
这里我们还需要一个矩阵W, 让bi2和bj2堆叠起来的矩阵和W做乘法, 就得到了最终的输出bi;
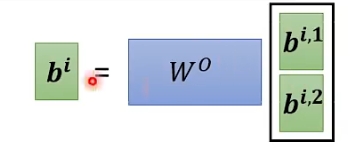

 浙公网安备 33010602011771号
浙公网安备 33010602011771号