Lucene创建索引流程

1.创建索引流程
原始文档:互联网上的网页(爬虫或蜘蛛)、数据库中的数据、磁盘上的文件
创建文档对象(非结构化数据)
文档对象中的属性不叫属性现在成为域。
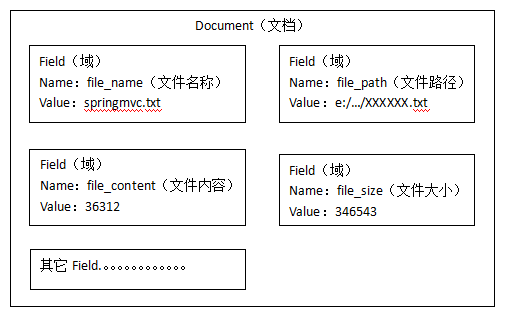
每个 Document 可以有多个 Field ,不同的 Document 可以有不同的 Field,同一个 Document 可以有相同的 Field(域名和域值都相同)。
每个文档都有一个唯一的编号,就是文档id
分析文档
将原始内容包含域的文档,需要再对域中的内容进行分析,分析的过程是经过对原始文档提取单词、将字母转为小写、去除标点符号、去除停用词等过程生成最终的词汇单元,可以将词汇单元理解为一个个单词。
原文档内容:
Luncene is a Java full-text search engine.
分析后得到的语汇单元:
lucene、java、full、search、engine…
每个单词叫做一个 Term,不同的域中拆分出来相同的单词是不同的 Term。Term中包含两部分一部分是文档的域名,另一部分是单词的内容。 Term K 域(文件名称) V spring Term K 域(文件内容) V spring 刚才两个Tream不是一个
创建索引
对所有文档分析得出的语汇单元进行创建索引,创建索引的目地是为了搜索,最终要实现只搜索被搜索的语汇单元从而找到 Document(文档)
注意:创建索引是对语汇索引,通过词语找文档,这种索引的结构叫倒排索引结构。包括索引和文档两部分,索引即词汇表,它的规模较小,而文档集合较大。
传统方式是根据文件找到该文件的内容,在文件内容中匹配搜索关键字,这种方法是顺序扫描法,数据量大、搜索慢
// 创建索引 @Test public void testIndex() throws Exception { // 第一步创建一个indexwriter对象 Directory directory = FSDirectory.open(new File("D:\\temp\\index")); // Directory directory2 = new RAMDirectory();//保存索引到内存中(内存索引库) //Analyzer analyzer = new StandardAnalyzer();// 官方推荐 Analyzer analyzer = new IKAnalyzer(); IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer); IndexWriter indexWriter = new IndexWriter(directory, config); // 第三步创建Filed域,将field添加到document对象中 File f = new File("D:\\Lucent&solr\\searchsoure"); File[] listFiles = f.listFiles(); for (File file : listFiles) { // 第二步创建Document对象 Document document = new Document(); // 文件名称 String file_name = file.getName(); Field fileNameField = new TextField("fileName", file_name, Store.YES); // 文件大小 long file_size = FileUtils.sizeOf(file); Field fileSizeField = new LongField("fileSize", file_size, Store.YES); // 文件路径 String file_path = file.getPath(); Field filePathField = new StoredField("filePath", file_path); // 文件内容 String file_content = FileUtils.readFileToString(file); Field fileContentField = new TextField("fileContent", file_content, Store.NO); document.add(fileNameField); document.add(fileSizeField); document.add(filePathField); document.add(fileContentField); // 第四步:使用indexwriter对象将document对象写入索引库,此过程进行索引创建。并将索引和document对象写入索引库 indexWriter.addDocument(document); } // 第五步:关闭IndexWriter对象 indexWriter.close(); } // 查询索引 @Test public void testSearch() throws Exception { // 第一步:创建一个Directory对象,也就是索引库存放的位置。 Directory directory = FSDirectory.open(new File("D:\\temp\\index"));// 磁盘硬盘库 // 第二步:创建一个indexReader对象,需要指定Directory对象。 IndexReader indexReader = DirectoryReader.open(directory);// 流 // 第三步:创建一个indexsearcher对象,需要指定IndexReader对象 IndexSearcher indexSearcher = new IndexSearcher(indexReader); // 第四步:创建一个TermQuery对象,指定查询的域和查询的关键词。 Query query = new TermQuery(new Term("fileName", "java")); // 第五步:执行查询。 TopDocs topDocs = indexSearcher.search(query, 2); // 第六步:返回查询结果。遍历查询结果并输出。 ScoreDoc[] scoreDocs = topDocs.scoreDocs;// 文档id for (ScoreDoc scoreDoc : scoreDocs) { int doc = scoreDoc.doc; Document document = indexSearcher.doc(doc); // 文件名称 String fileName = document.get("fileName"); System.out.println(fileName); // 文件内容 String fileContent = document.get("fileContent"); System.out.println(fileContent); // 文件大小 String fileSize = document.get("fileSize"); System.out.println(fileSize); // 文件路径 String filePath = document.get("filePath"); System.out.println(filePath); System.out.println("-----------------"); } // 第七步:关闭IndexReader对象 indexReader.close(); }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号