第一章:第二节pandas基础
文章目录
- 第一章:数据载入及初步观察
- 1.4 知道你的数据叫什么
- 1.4.1 任务一:pandas中有两个数据类型DateFrame和Series,通过查找简单了解他们。然后自己写一个关于这两个数据类型的小例子🌰[开放题]
- 1.4.2 任务二:根据上节课的方法载入"train.csv"文件
- 1.4.3 任务三:查看DataFrame数据的每列的名称
- 1.4.4任务四:查看"Cabin"这列的所有值[有多种方法]
- 1.4.5 任务五:加载文件"test_1.csv",然后对比"train.csv",看看有哪些多出的列,然后将多出的列删除
- 1.4.6 任务六: 将['PassengerId','Name','Age','Ticket']这几个列元素隐藏,只观察其他几个列元素
- 1.5 筛选的逻辑
第一章:数据载入及初步观察
1.4 知道你的数据叫什么
我们学习pandas的基础操作,那么上一节通过pandas加载之后的数据,其数据类型是什么呢?
开始前导入numpy和pandas
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
1.4.1 任务一:pandas中有两个数据类型DateFrame和Series,通过查找简单了解他们。然后自己写一个关于这两个数据类型的小例子🌰[开放题]
#写入代码
obj = Series([4, 7, -5, 3])
print(obj)
print(obj.values)
print(obj.index)
obj.index=['a','b','c','d']
print(obj.index)

#我们举的例子
sdata = {'Ohio': 35000, 'Texas': 71000, 'Oregon': 16000, 'Utah': 5000}
example_1 = pd.Series(sdata)
example_1
#我们举的例子
data = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada', 'Nevada'],
'year': [2000, 2001, 2002, 2001, 2002, 2003],'pop': [1.5, 1.7, 3.6, 2.4, 2.9, 3.2]}
example_2 = pd.DataFrame(data)
example_2
1.4.2 任务二:根据上节课的方法载入"train.csv"文件
df = pd.read_csv("train_chinese.csv")
df[0:5]

也可以加载上一节课保存的"train_chinese.csv"文件。通过翻译版train_chinese.csv熟悉了这个数据集,然后我们对trian.csv来进行操作
1.4.3 任务三:查看DataFrame数据的每列的名称
df.rename(columns={'堂兄弟\/姐妹个数':'堂兄弟/姐妹个数'},inplace=True)
print(df.columns)

1.4.4任务四:查看"Cabin"这列的所有值[有多种方法]
print(df['客舱'])
print(df.客舱)

1.4.5 任务五:加载文件"test_1.csv",然后对比"train.csv",看看有哪些多出的列,然后将多出的列删除
经过我们的观察发现一个测试集test_1.csv有一列是多余的,我们需要将这个多余的列删去
#写入代码
df1=pd.read_csv("test_1.csv")
df2=pd.read_csv("train.csv")
print(df1.loc[0])
print("---------")
print(df2.loc[0])

print(df1.drop('a',axis=1))
print(df1.loc[0])
【思考】还有其他的删除多余的列的方式吗?
df.drop(columns=['a'])
del df['a']
1.4.6 任务六: 将[‘PassengerId’,‘Name’,‘Age’,‘Ticket’]这几个列元素隐藏,只观察其他几个列元素
print(df1[['Survived','Pclass','Sex', 'SibSp', 'Parch', 'Embarked']][:5]) #最简单 最烦人的
print(df1.drop(['PassengerId','Name','Age','Ticket'],axis=1)[:5])#inplace不会写回原表格

【思考】对比任务五和任务六,是不是使用了不一样的方法(函数),如果使用一样的函数如何完成上面的不同的要求呢?
【思考回答】
如果想要完全的删除你的数据结构,使用inplace=True,因为使用inplace就将原数据覆盖了,所以这里没有用
1.5 筛选的逻辑
表格数据中,最重要的一个功能就是要具有可筛选的能力,选出我所需要的信息,丢弃无用的信息。
下面我们还是用实战来学习pandas这个功能。
1.5.1 任务一: 我们以"Age"为筛选条件,显示年龄在10岁以下的乘客信息
df1[df1.Age<10]

1.5.2 任务二: 以"Age"为条件,将年龄在10岁以上和50岁以下的乘客信息显示出来,并将这个数据命名为midage
midage=df1[(df1.Age<50)&(df1.Age>10)]
print(midage[:5])

【提示】了解pandas的条件筛选方式以及如何使用交集和并集操作
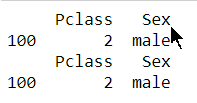
1.5.3 任务三:将midage的数据中第100行的"Pclass"和"Sex"的数据显示出来
midage = midage.reset_index(drop=True) #重新设置索引
print(midage[["Pclass","Sex"]][100:101])#此不需要重新设置索引了
print(midage.loc[[100],["Pclass","Sex"]])
【提示】在抽取数据中,我们希望数据的相对顺序保持不变,用什么函数可以达到这个效果呢?
midage的第100行不一定是df的100行 因此重新设置索引df.reset_index(drop=True)
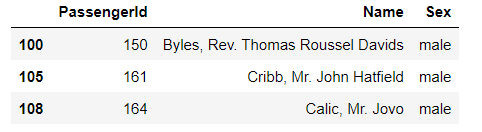
1.5.4 任务四:使用loc方法将midage的数据中第100,105,108行的"Pclass","Name"和"Sex"的数据显示出来
print(midage.loc[[100,105,108],["Pclass","Name","Sex"]])
print(midage.loc[[100,105,108]])

1.5.5 任务五:使用iloc方法将midage的数据中第100,105,108行的"Pclass","Name"和"Sex"的数据显示出来
midage.iloc[[100,105,108],[1,4,5]]
【思考】对比iloc和loc的异同
iloc 即int loc
前者使用区间时左闭右闭 且只能数字作为行列索引
后者切片左闭右开 数字/[""]都能进行行列的索引
