
深入理解linux网络技术内幕读书笔记(十)--帧的接收
Table of Contents
概述
帧接收的中断处理
- 把帧拷贝到sk_buff数据结构。
- 对一些sk_buff参数做初始化,以便稍后由上面的网络层使用。
- 更新其他一些该设备私用函数。
设备的开启与关闭
设备的开启与关闭是由net_device->state成员进行标识的。
- 当设备打开(dev_open()),该标识置为__LINK_STATE_START.
1: set_bit(__LINK_STATE_START, &dev->state);
- 当设备关闭(dev_close()),该标识清位__LINK_STATE_START.
1: clear_bit(__LINK_STATE_START, &dev->state);
[注] net/core/dev.c
队列
帧接收时有入口队列,帧传输时有出口队列。
每个队列都有一个指针指向其相关的设备,以及一个指针指向存储输入/输出缓冲区的sk_buff数据接口。
只有少数专用设备不需要队列,例如回环设备。
通知内核帧已接收:NAPI和netif_rx
NAPI: New API(新型API)
- 通过旧函数netif_rx
多数设备依然使用。
- 通过NAPI机制
NAPI简介
NAPI优点
- 异步事件 —如帧的接收—是由中断事件指出,如果设备的入口队列为空,内核就不用去查了。
- 如果内核知道设备的入口队列中有数据存在,就没必要去处理中断事件的通知信息。用简单轮询就够了。
- 减轻了CPU负载(因为中断事件变少了)
- 设备的处理更为公平
一些设备的入口队列中若有数据,就会以相当公平的循环方式予以访问。
NAPI所用之net_device字段
为了处理驱动程序使用NAPI接口的设备,有四个新字段添加到此结构中,以供NET_RX_SOFTIRQ软IRQ使用。其它设备(非NAPI的设备)不会用到这些字段,
但是它们可共享嵌入在softnet_data结构中作为backlog_dev字段的net_device结构的字段。(backlog_dev是积压设备,主要是为了处理非NAPI的驱动程序来满足NAPI的架构的一个对象)
poll
这个虚拟函数可用于把缓冲区从设备的输入队列中退出。此队列是使用NAPI设备的私有队列,而softnet_data->input_pkt_queu供其它设备使用
poll_list
这是设备列表,其中的设备就是在入口队列中有新帧等待被处理的设备。这些设备就是所谓的处于轮询状态。此列表的头为softnet_data->poll_list。
此列表中的设备都处于中断功能关闭状态,而内核当前正在予以轮询。
由于Linux现在已经将NAPI的架构整合进了内核,并取代了老式的架构,所以当不支持NAPI的设备接受到来的新帧时,这个设备列表中的当前设备就是刚才说的积压设备——backlog_dev。
积压设备有自己的方法来模拟NAPI的机制。这个之后会说明。
quota
weight
quota(配额)是一个整数,代表的是poll虚拟函数一次可以从队列退出的缓冲区的最大数目。其值的增加以weight为单位,用于在不同设备间施加某种公平性。
配额越低, 表示潜在的延时愈低,因此让其他设备饿死的风险就愈低,另方面,低配额会增加设备间的切换量,因此整体的耗费会增加。
对配有非NAPI驱动程序的设备而言,weight的默认值为64。存储在net/core/dev.c顶端的weight_p变量。weight_p之值可通过/proc修改。
对配有NAPI程序的设备而言,默认值是由驱动程序所选。最常见的值是64,但是也有使用16和32的,其值可能过sysfs调整。
net_rx_action软中断处理函数和NAPI
如下图所示,是每次内核轮询进来的网络流量时所发生的事,在此图中可以看到poll_list列表,其内的设备处于轮询状态,也可以看到poll虚拟函数以及软中断函数net_rx_action之间的关系。

图10-1:net_rx_action函数与NAPI概述
新旧驱动程序接口
我们已经知道net_rx_action是与NET_RX_SOFTIRQ标识相关联的函数。
假设在一段低活动量期间之后有些设备开始接收帧,并在硬件中断中触发了对应于NIC的中断服务例程,并且为NET_RX_SOFTIRQ软IRQ调度以准备执行,最终这些行为触发了net_rx_action的软中断。
net_rx_action会浏览列表中处于轮询状态的设备,然后为每个设备都调用相关联的poll虚拟函数,以处理入口队列中的帧。
之前说过,该列表中的设备会按照循环方式被查阅,而且每次其poll方法启用时,能处理的帧数目都有最大值存在。如果在其时间片内无法使队列清空,就得等到下一个时间片继续下去。也就是说,
net_rx_action软中断处理函数会持续为入口队列中有数据的设备调用其设备驱动程序所提供的poll方法,真到入口队列为空。到那时就不再轮询了,而设备驱动程序就可重新开启该设备的中断事件通知功能。
值得强调的是,中断功能关闭只针对那些在poll_list中的设备,也就是只用于那些使用NAPI而不共享backlog_dev的设备。
net_rx_action会限制其执行时间,当其用完限制的执行时间或处理过一定数量的帧后,就会自行重新调度准备执行,这样是为了强制net_rx_action能与其他内核任务彼此公平运行。同是,
每个设备也公限制其poll方法每次启用时所能处理的帧数目,才能与其它设备之间彼此公平运行。当设备无法清空其入口队列时,就得等到下一次调用其poll方法的时候。
从设备驱动程序的角度看,NAPI和非NAPI之间只有两点差异。首先,NAPI驱动程序必须提供一个poll方法。其次,为帧调度所调用的函数有别:非NAPI调用netif_rx,而NAPI驱动程序调用__netif_rx_schedule。
内核提供一个名为netif_rx_schedule的包裹函数,检查以确保该设备正在运行,而且该IRQ还调度,然后才调用__netif_rx_schedule。这些检查由以netif_rx_schedule_prep进行的。
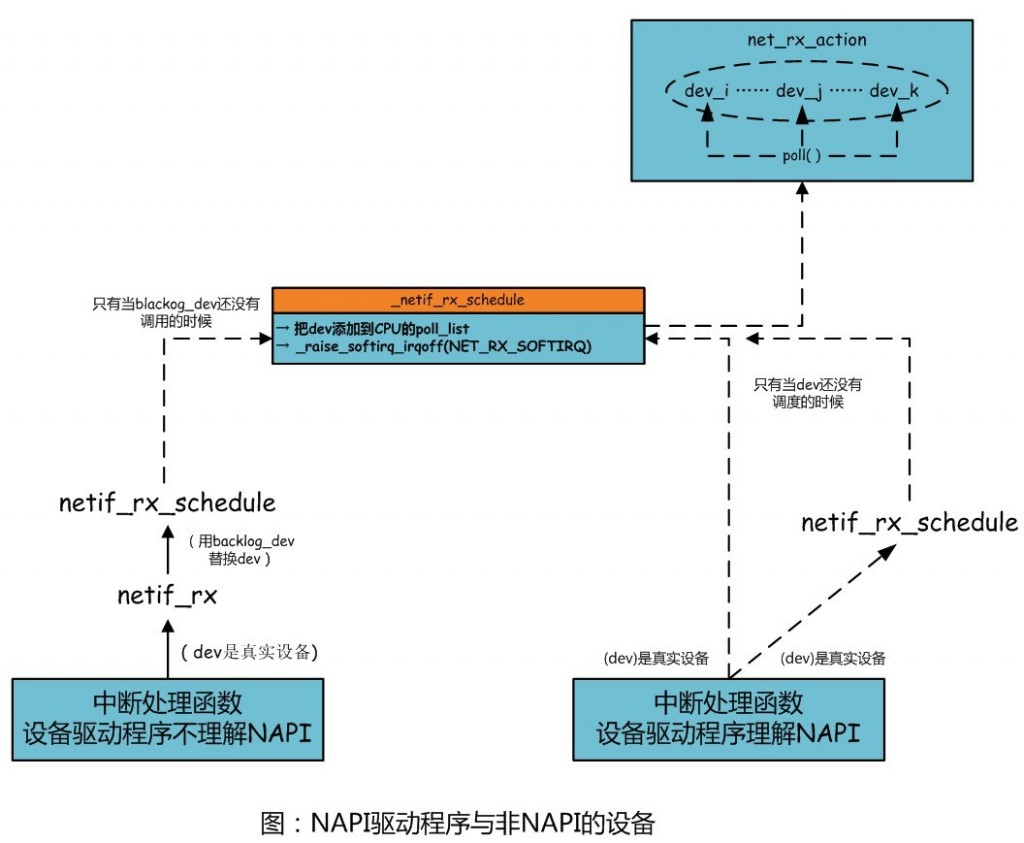
图10-2:NAPI驱动程序与非NAPI的设备
如上图所未,这两种驱动程序都会把输入设备排入轮询列表,为NET_RX_SOFTIRQ软中断调度以及准备执行,最后再由net_rx_action予以处理。即使这两种驱动程序最后都会调用__netif_rx_schedule。
NAPI设备所给予的性能会好很多。(因为NAPI中的poll函数是直接从设备中取数据,而非NAPI的是用积压设备来替代真实设备,实际上的数据依然是从内核中取走的)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号