并查集
一、问题引入
题意:首先在地图上给你若干个城镇,这些城镇都可以看作点,然后告诉你哪些对城镇之间是有道路直接相连的。最后要解决的是整幅图的连通性问题。比如随意给你两个点,让你判断它们是否连通,或者问你整幅图一共有几个连通分支,也就是被分成了几个互相独立的块。像畅通工程这题,问还需要修几条路,实质就是求有几个连通分支。如果是1个连通分支,说明整幅图上的点都连起来了,不用再修路了;如果是2个连通分支,则只要再修1条路,从两个分支中各选一个点,把它们连起来,那么所有的点都是连起来的了;如果是3个连通分支,则只要再修两条路……
说明:输入4 2 1 3 4 3。即一共有4个点,2条路。下面两行告诉你,1、3之间有条路,4、3之间有条路。那么整幅图就被分成了1-3-4和2两部分。只要再加一条路,把2和其他任意一个点连起来,畅通工程就实现了,那么这个这组数据的输出结果就是1。好了,现在编程实现这个功能吧,城镇有几百个,路有不知道多少条,而且可能有回路。 这可如何是好? 我以前也不会呀,自从用了并查集之后,嗨,效果还真好!
二、故事描述
并查集由一个整数型的数组和两个函数构成。数组pre[]记录了每个点的前导点是什么,函数find是查找,函数join是合并。
话说江湖上散落着各式各样的大侠,有上千个之多。他们没有什么正当职业,整天背着剑在外面走来走去,碰到和自己不是一路人的,就免不了要打一架。但大侠们有一个优点就是讲义气,绝对不打自己的朋友。而且他们信奉“朋友的朋友就是我的朋友”,只要是能通过朋友关系串联起来的,不管拐了多少个弯,都认为是自己人。这样一来,江湖上就形成了一个一个的群落,通过两两之间的朋友关系串联起来。而不在同一个群落的人,无论如何都无法通过朋友关系连起来,于是就可以放心往死了打。但是两个原本互不相识的人,如何判断是否属于一个朋友圈呢? 我们可以在每个朋友圈内推举出一个比较有名望的人,作为该圈子的代表人物,这样,每个圈子就可以这样命名“齐达内朋友之队”“罗纳尔多朋友之队”……两人只要互相对一下自己的队长是不是同一个人,就可以确定敌友关系了。 但是还有问题啊,大侠们只知道自己直接的朋友是谁,很多人压根就不认识队长,要判断自己的队长是谁,只能漫无目的的通过朋友的朋友关系问下去:“你是不是队长?你是不是队长?” 这样一来,队长面子上挂不住了,而且效率太低,还有可能陷入无限循环中。于是队长下令,重新组队。队内所有人实行分等级制度,形成树状结构,我队长就是根节点,下面分别是二级队员、三级队员。每个人只要记住自己的上级是谁就行了。遇到判断敌友的时候,只要一层层向上问,直到最高层,就可以在短时间内确定队长是谁了。由于我们关心的只是两个人之间是否连通,至于他们是如何连通的,以及每个圈子内部的结构是怎样的,甚至队长是谁,并不重要。所以我们可以放任队长随意重新组队,只要不搞错敌友关系就好了。于是,门派产生了。 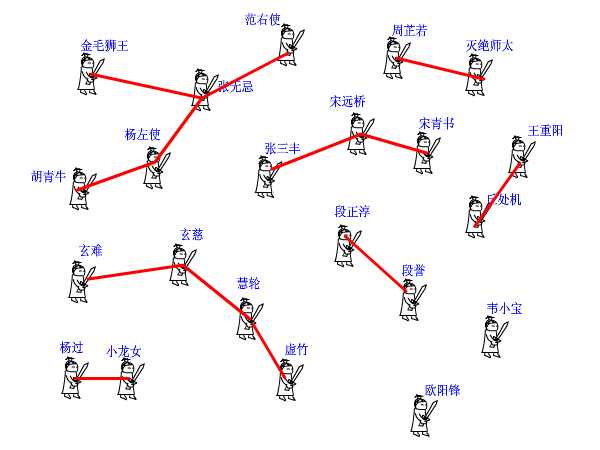
下面我们来看并查集的实现。 int pre[1000]; 这个数组,记录了每个大侠的上级是谁。大侠们从1或者0开始编号(依据题意而定),pre[15]=3就表示15号大侠的上级是3号大侠。如果一个人的上级就是他自己,那说明他就是掌门人了,查找到此为止。也有孤家寡人自成一派的,比如欧阳锋,那么他的上级就是他自己。每个人都只认自己的上级。比如胡青牛同学只知道自己的上级是杨左使。张无忌是谁?不认识!要想知道自己的掌门是谁,只能一级级查上去。 find这个函数就是找掌门用的,意义再清楚不过了(路径压缩算法先不论,后面再说)。
|
1
2
3
4
5
6
7
|
int find(int x) //查找x的掌门{ int r=x; //委托 r 去找掌门 while(pre[r] != r) //如果r的上级不是r自己(也就是说找到的大侠他不是掌门 = =) r = pre[r] ; // r 接着找他的上级,直到找到掌门为止。 return r ; //掌门驾到~~~} |
再来看看join函数,就是在两个点之间连一条线,这样一来,原先它们所在的两个板块的所有点就都可以互通了。这在图上很好办,画条线就行了。但我们现在是用并查集来描述武林中的状况的,一共只有一个pre[]数组,该如何实现呢? 还是举江湖的例子,假设现在武林中的形势如图所示。虚竹小和尚与周芷若MM是我非常喜欢的两个人物,他们的终极boss分别是玄慈方丈和灭绝师太,那明显就是两个阵营了。我不希望他们互相打架,就对他俩说:“你们两位拉拉勾,做好朋友吧。”他们看在我的面子上,同意了。这一同意可非同小可,整个少林和峨眉派的人就不能打架了。这么重大的变化,可如何实现呀,要改动多少地方?其实非常简单,我对玄慈方丈说:“大师,麻烦你把你的上级改为灭绝师太吧。这样一来,两派原先的所有人员的终极boss都是师太,那还打个球啊!反正我们关心的只是连通性,门派内部的结构不要紧的。”玄慈一听肯定火大了:“我靠,凭什么是我变成她手下呀,怎么不反过来?我抗议!”抗议无效,上天安排的,最大。反正谁加入谁效果是一样的,我就随手指定了一个。这段函数的意思很明白了吧?
|
1
2
3
4
5
6
|
void join(int x,int y) //我想让虚竹和周芷若做朋友{ int fx=find(x), fy=find(y); //虚竹的老大是玄慈,芷若MM的老大是灭绝 if(fx != fy) //玄慈和灭绝显然不是同一个人 pre[fx]=fy; //方丈只好委委屈屈地当了师太的手下啦} |
再来看看路径压缩算法。建立门派的过程是用join函数两个人两个人地连接起来的,谁当谁的手下完全随机。最后的树状结构会变成什么样,我也完全无法预计,一字长蛇阵也有可能。这样查找的效率就会比较低下。最理想的情况就是所有人的直接上级都是掌门,一共就两级结构,只要找一次就找到掌门了。哪怕不能完全做到,也最好尽量接近。这样就产生了路径压缩算法。 设想这样一个场景:两个互不相识的大侠碰面了,想知道能不能揍。 于是赶紧打电话问自己的上级:“你是不是掌门?” 上级说:“我不是呀,我的上级是谁谁谁,你问问他看看。” 一路问下去,原来两人的最终boss都是东厂曹公公。 “哎呀呀,原来是记己人,西礼西礼,在下三营六组白面葫芦娃!” “幸会幸会,在下九营十八组仙子狗尾巴花!” 两人高高兴兴地手拉手喝酒去了。 “等等等等,两位同学请留步,还有事情没完成呢!”我叫住他俩。 “哦,对了,还要做路径压缩。”两人醒悟。 白面葫芦娃打电话给他的上级六组长:“组长啊,我查过了,其习偶们的掌门是曹公公。不如偶们一起直接拜在曹公公手下吧,省得级别太低,以后查找掌门麻环。” “唔,有道理。” 白面葫芦娃接着打电话给刚才拜访过的三营长……仙子狗尾巴花也做了同样的事情。 这样,查询中所有涉及到的人物都聚集在曹公公的直接领导下。每次查询都做了优化处理,所以整个门派树的层数都会维持在比较低的水平上。路径压缩的代码,看得懂很好,看不懂也没关系,直接抄上用就行了。总之它所实现的功能就是这么个意思。
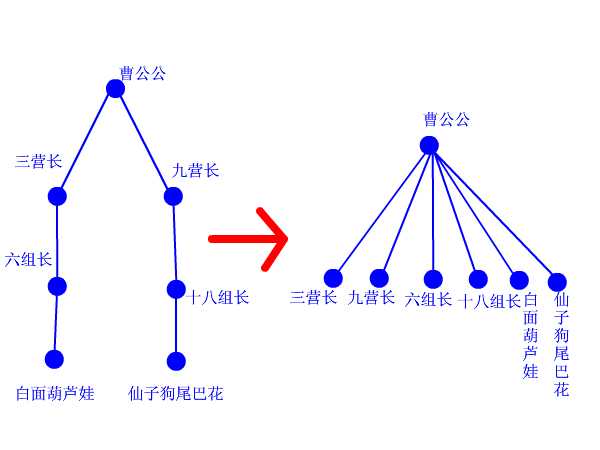
三、算法描述
关键特征:
①用集合中的某个元素来代表这个集合,该元素称为集合的代表元;
②一个集合内的所有元素组织成以代表元为根的树形结构;
③对于每一个元素 pre[x]指向x在树形结构上的父亲节点。如果x是根节点,则令pre[x] = x;
④对于查找操作,假设需要确定x所在的的集合,也就是确定集合的代表元。可以沿着pre[x]不断在树形结构中向上移动,直到到达根节点。
判断两个元素是否属于同一集合,只需要看他们的代表元是否相同即可。
路径压缩:
为了加快查找速度,查找时将x到根节点路径上的所有点的pre(上级)设为根节点,该优化方法称为压缩路径。使用该优化后,平均复杂度可视为Ackerman函数的反函数,实际应用中可粗略认为其是一个常数。
用途:
1、维护无向图的连通性。支持判断两个点是否在同一连通块内,和判断增加一条边是否会产生环。
2、用在求解最小生成树的Kruskal算法里。
一般来说,一个并查集对应三个操作:初始化+查找根结点函数+合并集合函数
【初始化】
包括对所有单个的数据建立一个单独的集合(即根据题目的意思自己建立的最多可能有的集合,为下面的合并查找操作提供操作对象)。
在每一个单个的集合里面,有三个东西。
①集合所代表的数据(这个初始值根据需要自己定义,不固定) ;
②这个集合的层次通常用rank表示(一般来说,初始化的工作之一就是将每一个集合里的rank置为1);
③这个集合的类别pre(其实就是一个指针,用来指示这个集合属于那一类,合并过后的集合,他们的pre指向的最终值一定是相同的) (有的简单题里面集合的数据就是这个集合的标号,也就是说只包含2和3,1省略了)。
初始化的时候,每一个集合的pre都是这个集合自己的标号。没有跟它同类的集合,那么这个集合的源头只能是自己了。
最简单的集合就只含有这三个东西了,当然,复杂的集合就是把3指针这一项添加内容,如PKU食物链那题,我们还可以添加enemy指针,表示这个物种集合的天敌集合;food指针,表示这个物种集合的食物集合。随着指针的增加,并查集操作起来也变得复杂,题目也就显得更难了。
数组表示法
设置很多相同大小的数组,如:
|
1
2
3
4
5
6
7
8
9
|
int pre[max]; //集合index的类别,或者用parent表示int rank[max]; //集合index的层次,通常初始化为0int data[max]; //集合index的数据类型 //初始化集合void Make_pre(int i){ pre[i]=i; //一个集合的pre都是这个集合自己的标号。没有跟它同类的集合,那么这个集合的源头只能是自己了。 rank[i]=0;} |
【查找函数】
就是找到pre指针的源头,可以把函数命名为find_pre,如果集合的pre等于集合的编号(即还没有被合并或者没有同类),那么自然返回自身编号。 如果不同(即经过合并操作后指针指向了源头(合并后选出的rank高的集合))那么就可以调用递归函数,如下面的代码:
|
1
2
3
4
5
6
7
8
9
|
//查找集合i(一个元素是一个集合)的源头(递归实现)int Find_pre(int i){ //如果集合i的父亲是自己,说明自己就是源头,返回自己的标号 if(pre[i]==i) return pre[i]; //否则查找集合i的父亲的源头 return Find_pre(pre[i]); } |
【合并集合函数】
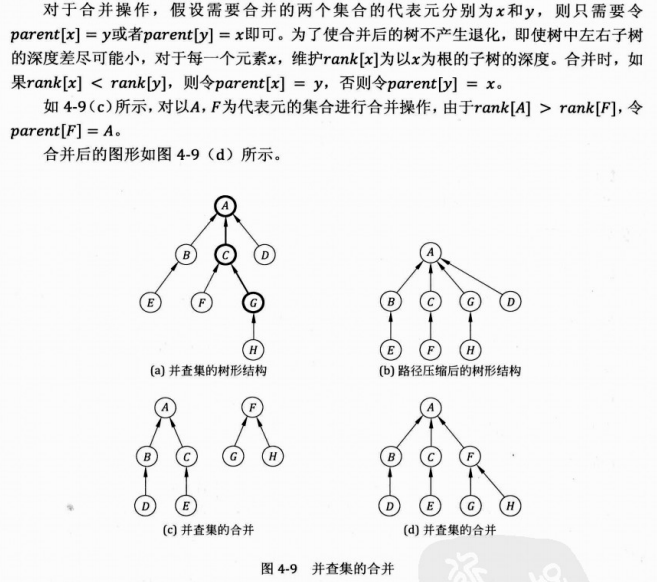
这就是所谓并查集的并了。至于怎么知道两个集合是可以合并的,那就是题目的条件了。先看代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
void Union(int i,int j){ i=Find_pre(i); j=Find_pre(j); if(i==j) return ; if(rank[i]>rank[j]) pre[j]=i; else { if(rank[i]==rank[j]) rank[j]++; pre[i]=j; }} |
四、代码实现
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
#define N 105int pre[N]; //每个结点int rank[N]; //树的高度//初始化int init(int n) //对n个结点初始化{ for(int i = 0; i < n; i++){ pre[i] = i; //每个结点的上级都是自己 rank[i] = 1; //每个结点构成的树的高度为1 }}int find_pre(int x) //查找结点x的根结点{ if(pre[x] == x){ //递归出口:x的上级为x本身,即x为根结点 return x; } return find_pre(pre[x]); //递归查找}//改进查找算法:完成路径压缩,将x的上级直接变为根结点,那么树的高度就会大大降低int find_pre(int x) //查找结点x的根结点{ if(pre[x] == x){ //递归出口:x的上级为x本身,即x为根结点 return x; } return pre[x] = find_pre(pre[x]); //递归查找 此代码相当于 先找到根结点rootx,然后pre[x]=rootx}bool is_same(int x, int y) //判断两个结点是否连通{ return find_pre(x) == find_pre(y); //判断两个结点的根结点(亦称代表元)是否相同}void unite(int x,int y){ int rootx, rooty; rootx = find_pre(x); rooty = find_pre(y); if(rootx == rooty){ return ; } if(rank(rootx) > rank(rooty)){ pre[rooty] = rootx; //令y的根结点的上级为rootx } else{ if(rank(rootx) == rank(rooty)){ rank(rooty)++; } pre[rootx] = rooty; }} |
至此为止,即对并查集有了大致了解:
- 并查集可以判断一幅无向图中有几个连通分量
- 并查集的find、join函数都是必不可少的
- 路径压缩算法对于并查集的优化也很关键
于此,并查集的进阶内容:
- 并查集的进阶主要内容是解决带权并查集的相关问题。
- 在原有并查集的基础上,加入集合内部元素和其父节点之间的关系,这样的拓展,可以解决更多问题
- 带权并查集和普通并查集最大的区别在于带权并查集合并的是可以推算关系的点的集合(可以通过集合中的一个已知值推算这个集合中其他元素的值)。而一般并查集合并的意图在于这个元素属于这个集合。带权并查集相当于把“属于”的定义拓展了一下,拓展为有关系的集合。
来看这么一道题目:警察抓获N个罪犯,这些罪犯只可能属于两个黑帮团伙中的一个,现在给出M个条件(D a b表示a和b不在同一团伙),对于每一个询问(A a b)确定a,b是不是属于同一黑帮团伙或者不能确定。
之前的解题观点:D a b表示a和b不在同一个团伙??我们平时碰到的不都是两人在同一个团伙,然后用unite函数将两人放入同一个连通分支内。所以这道题给我的第一印象是将两个团伙看作两个连通分支,然后将相应的罪犯加入到相应的连通分支中,最后要询问时,只要判断两个罪犯的祖先是否一致(如果一致,那么两人是同一团伙)。
不可行的地方:D a b只表明a和b不属于同一个连通分支,并没有明确说明a和b属于哪个团伙(设想一下,如果说明了,那岂不是so easy),那么该怎么办呢?
新思路:仔细想想,我们是否可以存储每个节点与其祖先的关系。拿这道题来说,我们用一维数组r[]存储每个节点与其祖先是否属于同一团伙(例如r[x]=0表示结点x与其祖先属于同一团伙,而r[x]=1则表示结点x与其祖先不属于同一团伙)。有了这个关系尚且不够,我还有一些疑惑,这个祖先是谁哇?这个关系是怎么得出的哇?
继续前进:对于这题每次输入的D a b,我们都知道a和b不属于同一团伙,也就是a和b不在同一连通分支。而我们要做的是将a和b归于同一个祖先之下(即连接a和b所在的连通分支),伴随这一操作的还有更新r[a]、r[b](怎么更新稍后谈),为何要将a和b归于同一个连通分支呢?因为后面的查询A a b,我们通过判断find(a)==find(b)是否成立来确定我们是否知道他们的关系(成立就说明他们属于同一连通分支,说明他们已经D a b过了,不成立就可以输出"Not sure yet."啦),在find(a)==find(b)成立的情况下,我们就可以通过判断r[a]==r[b]是否成立来确定他们的具体关系(成立就说明他们属于同一团伙,就可以输出"In the same gang.",不成立就说明他们不属于同一个团伙,就可以输出"In different gangs.")。我们应该要知道上面那个式子r[a]==r[b]等价于r[a]==r[b]==0或r[a]==r[b]==1,即a和b如果属于同一团伙,暗含着他们与他们的祖先在同一个团伙或不在同一个团伙。读到这,我们并没有理清祖先是谁,关系怎么得出,但我们知晓了我们努力的目标。
于是,我们敲出了下面的代码:
|
1
2
3
4
5
6
7
8
9
10
11
|
if(a和b属于同一连通分支){ if(a和祖先的关系==b和祖先的关系){ cout<<"a和b属于同一团伙"<<endl; } else{ cout<<"a和b不属于同一团伙"<<endl; }}else{ cout<<"还没有确定a和b的关系"<<endl;} |
再往前迈进:既然每次D a b都将a和b连起来,而且最后形成的那有且仅有一个的连通分支是由每次D a b的a和b结点组成,于是我们就可以确定祖先结点就是第一次D a b的a或b(具体是a还是b要看你的unite函数怎么写的了),后面我们才慢慢这个连通分支上再添加结点的。祖先节点我们搞懂了,再来搞懂关系即可。
最后一根稻草:我们前面说过数组r[x]表示节点x与根节点的关系,我们知道初始的时候,每个点都是一个连通分支(都有pre[i]=i,r[i]=0),而我们在构建一个由多个节点组成的连通分支时,我们新加入的节点的祖先在此刻发生变化,那么他们的r[]也要变化,当然,这是每次D a b出现后,将a和b所在的连通分支连起来时对r[]的更新,也就是在unite函数内的更新。此外,在find函数寻找根结点的时候也要不断更新r[](为啥啊为啥啊),因为unite函数内的r[]更新是在联合两棵树的时候进行的更新两棵树的根的关系,而其中相关子结点却未曾更新,所以要在find函数内进行更新(这样才能判断r[a]==r[b]是否成立)。下面,我们先解释find函数内r[]是怎么更新的,再解释unite函数内r[]是怎么更新的。
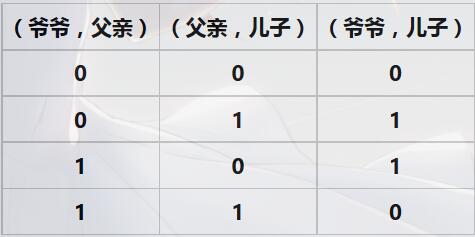
我们先解释:根据子节点a与父亲节点b的关系r1和父节点b与爷爷节点c的关系r2推导子节点a与爷爷节点c的关系r3
很容易通过穷举发现其关系式:a 和 b 的关系为 r1, b 和 c 的关系为r2,则 a 和 c 的关系r3为: r3 = ( r1 + r2) % 2; //(PS:因为只用两种情况所以对 2 取模)
于是find函数变为:
|
1
2
3
4
5
6
7
8
|
int find(int x) //找根节点 { if(x == pre[x]) return x; int t = pre[x]; //记录父亲节点 方便下面更新r[] pre[x] = find(pre[x]); r[x] = (r[x]+r[t])%2; //根据子节点与父亲节点的关系和父节点与爷爷节点的关系,推导子节点与爷爷节点的关系 return pre[x]; //容易忘记 } |
在find函数内,若我们如此调用find(a),那么find函数除了返回a的祖先,还会在这过程中确定r[a]的值(即a与祖先结点的关系)。
最后,我们再来解释unite函数内的r[]更新:
定义:fx 为 x的根节点, fy 为 y 的根节点,联合时,使得 pre[fx] = fy (即fy也变为x和fx的祖先)
同时也要寻找 fx 与 fy 的关系(此时fy是fx的祖先),于是有 r[fx] = (r[x]+r[y]+1)%2
证明过程:fx 与 x 的关系是 r[x], x 与 y 的关系是 1 (因为确定是不同类,才联合的),y与 fy 关系是 r[y],模 2 是因为只有两种关系,所以又上面的一点所推出的定理可以证明 fx 与 fy 的关系是: (r[x]+r[y]+1)%2
于是unite函数变为:
|
1
2
3
4
5
6
7
|
void unite(int x, int y) { int fx = find(x); //x所在集合的根节点 int fy = find(y); pre[fx] = fy; //合并 r[fx] = (r[x]+1+r[y])%2; //fx与x关系 + x与y的关系 + y与fy的关系 = fx与fy的关系 } |


#include<cstdio> #include<iostream> using namespace std; const int maxn = 100000+10; int pre[maxn]; //存父亲节点 int r[maxn]; //存与根节点的关系,0 代表同类, 1代表不同类 int T,n,m; void init() { for(int i=1;i<=n;i++){ pre[i] = i; r[i] = 0; } } int find(int x) { if(x == pre[x]) return x; int t = pre[x]; pre[x] = find(pre[x]); r[x] = (r[x]+r[t])%2; return pre[x]; } void unite(int x,int y) { int fx = find(x); int fy = find(y); pre[fx] = fy; r[fx] = (r[x]+1+r[y])%2; } int main() { scanf("%d",&T); while(T--){ scanf("%d%d",&n,&m); init(); int a,b; char ch; while(m--){ getchar(); scanf("%c%d%d",&ch,&a,&b); if(ch == 'D'){ unite(a,b); } else{ if(find(a) == find(b)){ if(r[a] == r[b]){ cout<<"In the same gang.\n"; } else{ cout<<"In different gangs.\n"; } } else{ cout<<"Not sure yet.\n"; } } } } return 0; } poj1703
上面那道题只是带权并查集中的种类并查集的一道开胃小菜,接下来我们来谈poj1182食物链这道题。
啊!!!我又做到一条和上面poj1073类似的题目,一块讲了,再讲poj1182吧。
题意:给定n只虫子,不同性别的可以在一起,相同性别的不能在一起。给你m对虫子,判断中间有没有同性别在一起的。
因为刚刚做完了上道题,这道题一看到,就有了思路。没得到一对虫子,我们就判断它们是否属于同一连通分支,如果是,我们再判断它们各自与根结点的性别是否相同,如果两个性别都与根结点的性别相同,说明这一对虫子的性别相同,答案就出来了。
具体程序只要稍稍修改一下上面的代码即可。
说是如此说,我看到一个人的题解上写的r[x]表示的是x和父节点的关系(而不是和根结点),具体为r[x] = 0表示x和父节点关系为同性,r[x] = 1表示x和父节点关系为异性。
但是我测试了一下,仅改动这个定义而不该懂其他代码仍然AC。这说明或者我们前面的定义有问题或者这个定义有问题。话不多说,慢慢斟酌,先上这个代码。
#include <cstdio> #include <cstring> #include <cstdlib> using namespace std; #define maxn 5005 int T,n,m; int pre[maxn]; //记录父节点 int r[maxn]; //r[x]记录x和父节点之间的关系 //其中r[x] = 0表示x和父节点关系为同性, r[x] = 1表示x和父节点关系为异性 void init() { for(int i=1;i<=n;i++){ pre[i] = i; r[i] = 0; } } //集合查找 int find(int x) { if(pre[x] == x) return x; int t = pre[x]; pre[x] = find(t); r[x] = (r[x] + r[t]) % 2; //根据老的父节点和新父节点关系,修改r[x]值 return pre[x]; } //合并集合 void unite(int x, int y) { int fx = find(x); int fy = find(y); pre[fx] = fy; r[fx] = ((r[x] - r[y] + 1) % 2); //唯一一处不同的换成 r[fx] = ((r[x] + r[y] + 1) % 2); 还是AC } int main() { scanf("%d", &T); int kase = 1; while(T--) { scanf("%d%d", &n, &m); init(); int a,b,flag = 0; while(m--) { scanf("%d%d", &a, &b); if(find(a) == find(b)) { if(r[a] == r[b]) //如果不满足异性关系,有矛盾 flag = 1; } else { unite(a, b); } } printf("Scenario #%d:\n",kase++); if(flag==1) printf("Suspicious bugs found!\n\n"); else printf("No suspicious bugs found!\n\n"); } return 0; } poj2492
好啦好啦,不管是与父亲结点还是祖先结点的关系,咱们都直接进入poj1182食物链吧。
题意:三类动物A、B、C构成食物链循环,告诉两个动物的关系(同类或天敌),判断有多少个关系是和正确的冲突。
哈哈,看到这道题,一下子就注意到三类动物,之前我们研究的是两类,现在只是多了一类而已,真的是而已吗?
显然不是,如果我们依照上面的想法做,每来一对动物a b就将他们归于同一个祖先下,最后,只剩下一个连通分支。如果我们仍然设r[x]表示x与根结点的关系,那么就有r[x]=0表示与根结点同类,r[x]=1表示与根结点异类(???貌似有三个类啊??这样无法区分另外两个类啊)。
既然之前的想法不能解决问题,我们回本溯源,带权并查集的本质不就是多了各结点之间的关系吗?不妨大胆设一些关系。
想着想着,因为每来一句话都要判断其真假,所以必须要让所有结点在一个连通分支内(如果分3个分支,来了新的一对动物让你判断,如果发生前后矛盾,你将不知道是之前是错的还是现在的是错的),所以数组r[]要保留,既然是食物链,不妨设r[x]=0表示x与根结点同类,r[x]=1表示x吃根结点,r[x]=-1表示x被根结点吃。这样如果命令是1 a b时,我们便可以先判断它们是否是同一连通分支的,如果是,就判断它们各自与根结点的关系(即r[a]==r[b]),如果r[a]==r[b](即表示它们是同类),命令正确,反之说明这个命令是假话。当然,如果它们不是同一连通分支的,它们之间的关系就不好判定,命令真假也就无法确定,我们只能将两个点连入同一连通分支,即直接调用unite函数。如果命令是2 a b时(即a吃b),我们仍然先判断它们是否是同一连通分支的,如果是,我们可以穷举r[a]和r[b]的值来判断此话是否正确(若想命令正确只能是:r[a]=1,r[b]=0或r[a]=0,r[b]=-1或r[a]=-1,r[b]=1)。当然,如果不是同一连通分支的,同上,直接调用unite函数。
于是,我们可以得出下面的代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
cin>>D>>a>>b;if(D==1){ if(find(a) == find(b)) //a和b属于同一连通分量 if(r[a] != r[b]) //a和祖先的关系 与 b和祖先的关系 不一致 假话数量++; //即a和b的种类不一样 else unite(a,b);}if(D==2){ if(find(a)==find(b)) if(不是正确的对应关系) 假话数量++; else unite(a,b);} |
看到这,我们目标就有啦啦啦!!至于关系的得到就锁定在find函数和unite函数内了,详细的推导日后再说。
我怀着自信满满的心去编程,却发现有个地方忽视了。。。当命令D a b过来时,如果a和b属于同一连通分支还好说,如果不是,我们就要unite(a,b),但是unite的具体内容决定r[]的更新,所以与当前传入的D有关。
于是,得到下面的代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
cin>>D>>a>>b;int sum = 0; //假话数量if(a>n || b>n || (D==2&&x==y)) //如果节点编号大于最大编号,或者自己吃自己,说谎 sum++; else if(find(a) == find(b)){ if(D==1 && r[a]!=r[b]) //如果 x 和 y 不属于同一类 sum++; if(D==2 && (r[a]+1)%3!=r[b]) //如果a没有吃b(注意要对应unite(x,y)的情况,否则一路WA到死啊!!!) sum++;}else{ unite(a,b,d); //如果开始没有关系,则建立关系} |
于是相应的代码就有了:
#include<cstdio> #include<iostream> using namespace std; const int maxn = 50000+10; int pre[maxn]; //存父亲节点 int r[maxn]; //存与根节点的关系 //r[x]==0表示x与根结点同种类 r[x]==1代表x会被根结点吃 r[x]==2代表x会吃根结点 int n,k; void init() { for(int i=1;i<=n;i++){ pre[i] = i; r[i] = 0; //初始每个动物都与自己同种类 } } int find(int x) { if(x == pre[x]) return x; int t = pre[x]; pre[x] = find(pre[x]); //回溯由子节点与父节点的关系和父节点与根节点的关系找子节点与根节点的关系 r[x] = (r[x]+r[t])%3; //此处模3 return pre[x]; } void unite(int x,int y,int d) { int fx = find(x); int fy = find(y); pre[fy] = fx; //合并树 注意:被x吃,所以以 x的根为父 r[fy] = (r[x]-r[y]+3+(d-1))%3; //对应更新与父节点的关系 } int main() { cin>>n>>k; init(); int sum = 0,D,a,b; while(k--){ scanf("%d%d%d",&D,&a,&b); if(a>n || b>n || (a==b&&D==2)){ sum++; continue; } else if(find(a) == find(b)) //如果原来有关系,也就是在同一棵树中,那么直接判断是否说谎 { if(D == 1 && r[a] != r[b]) sum++; //如果a和b不属于同一类 if(D == 2 && (r[a]+1)%3 != r[b]) sum++; // 如果a没有吃b (注意要对应unite(a,b)的情况,否则一路WA到死啊!!!) } else unite(a,b,D); //如果开始没有关系,则建立关系 } printf("%d\n",sum); return 0; } poj1182
写到这,只缺一些关系的证明了。
思路:把确定了相对关系的节点放在同一棵树中
每个节点对应的 r[]值记录他与根节点的关系:
0:同类,
1:被父亲节点吃,
2: 吃父亲节点
每次输入一组数据 d, x, y判断是否超过 N 后,先通过find()函数找他们的根节点从而判断他们是否在同一棵树中。(也就是是否有确定的关系)
1.如果在同一棵树中find(x) == find(y):直接判断是否说谎。
1)如果 d ==1,那么 x 与 y 应该是同类,他们的r[]应该相等
如果不相等,则说谎数 +1
2)如果 d==2,那么 x 应该吃了 y,也就是 (r[x]+1)%3 == r[y]
如果不满足,则说谎数 +1
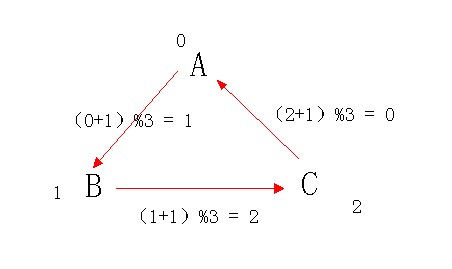
如何判断 x 吃了 y 是 (r[x]+1)%3 == r[y],请看下图:(PS:箭头方向指向被吃方)
2.如果不在同一棵树中:那么合并 x 与 y 分别所在的树。
合并树时要注意顺序,我这里是把 x 树的根当做主根,否则会
WA的很惨
注意:找父亲节点时,要不断更新 r[]的值。
这里有一个关系:如果 x 和y 为关系 r1, y 和 z 为关系 r2
那么 x 和z的关系就是 (r1+r2)%3
如何证明?
无非是3*3 = 9种情况而已
(a, b) 0:同类 、 1:a被b吃 、 2:a吃b
|
(x, y) |
(y, z) |
(x,z) |
如何判断 |
|
0 |
0 |
0 |
0+0 = 0 |
|
0 |
1 |
1 |
0+1 = 1 |
|
0 |
2 |
2 |
0+2 = 2 |
|
1 |
0 |
1 |
1+0 = 1 |
|
1 |
1 |
2 |
1+1 = 2 |
|
1 |
2 |
0 |
(1+2)%3 = 0 |
|
2 |
0 |
2 |
2+0 = 2 |
|
2 |
1 |
0 |
(2+1)%3 = 0 |
|
2 |
2 |
1 |
(2+2)%3 = 1 |
关于合并时r[]值的更新:
如果 d == 1则 x和y 是同类 ,那么 y 对 x 的关系是 0
如果 d == 2 则 x 吃了 y, 那么 y 对 x 的关系是 1, x 对 y 的关系是 2.
综上所述 ,无论 d为1 或者是为 2, y 对 x 的关系都是 d-1
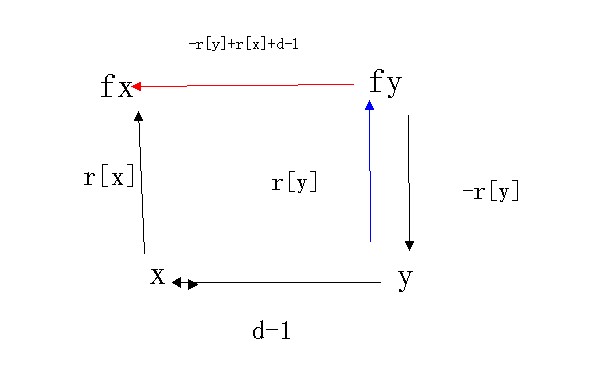
定义 :fx 为 x 的根点, fy 为 y 的根节点
合并时,如果把 y 树合并到 x 树中
如何求 fy 对 fx 的r[]关系?
fy 对 y 的关系为 3-r[y]
y 对 x 的关系为 d-1
x 对 fx 的关系为 r[x]
所以 fy 对 fx 的关系是(3-r[y] + d-1 + r[x])%3

 浙公网安备 33010602011771号
浙公网安备 33010602011771号