
面试-服务端框架
Spring
Spring用到了哪些设计模式
- 工厂模式:Spring通过BeanFactory和ApplicationContext来创建对象,其中BeanFactory就是简单工厂模式的体现。工厂模式隐藏了对象实例化的复杂性,并提供一个统一的方式来获取对象。
- 单例模式:在Spring中,默认情况下,bean以单例的形式存在。这意味着对于每个bean定义,Spring容器只会创建一个共享的实例。这样做可以减少系统资源的消耗,并减少垃圾回收器的压力。
- 代理模式:Spring的面向切面编程(AOP)功能使用到了JDK的动态代理和CGLIB字节码生成技术。这使得可以在不修改源代码的情况下,为对象添加额外的行为。
- 策略模式:例如,Resource接口的不同实现类针对不同的资源文件实现了不同的资源获取策略。策略模式允许在运行时选择算法或操作的具体实现。
- 模板方法模式:Spring中的JdbcTemplate、RestTemplate等都是模板方法模式的应用。它们提供了一个操作的框架,而具体的实现步骤则可以由子类来提供,从而实现代码复用和减少重复代码。
- 观察者模式:Spring事件驱动模型使用了观察者模式。当某个事件发生时,所有注册为该事件监听者的bean都会收到通知。
- 装饰器模式:在Spring中,装饰器模式用于给对象添加额外的功能,这比生成子类更为灵活。
- 适配器模式:在Spring MVC中,处理器适配器将不同的控制器适配成统一的Handler接口,使得不同的控制器可以被统一处理。
- 责任链模式:在AOP中,责任链模式用于组织多个拦截器,形成一个处理请求的责任链。
- 桥接模式:在Spring中,桥接模式可以用来解耦抽象部分和实现部分,例如动态切换不同的数据源。
Spring的优点
通过Ioc控制反转和DI依赖注入实现松耦合
支持AOP面向切面的编程,提高了代码的复用性和可维护性。
支持声明式事务
Spring是非侵入式的。使用Spring的框架不用继承Spring的类和接口
Spring框架拥有庞大的社区支持
- 控制:指的是对象创建(实例化、管理)的权力
- 反转:控制权交给外部环境(Spring 框架、IoC 容器)
在Spring创建对象的过程中,把对象依赖的属性注入到对象中。spring就是通过反射来实现注入的。依赖注入主要有三种方式:注解注入(@Autowired),构造器注入和属性注入。
IOC和DI的作用
最终目标就是:充分解耦,具体实现靠:
- 使用IOC容器管理bean(IOC)
- 在IOC容器内将有依赖关系的bean进行关系绑定(DI)
- 最终:使用对象时不仅可以直接从IOC容器中获取,并且获取到的bean已经绑定了所有的依赖关系.
Spring的IOC和DI用了什么设计模式
- 工厂模式:IoC 容器负责创建对象,当需要创建一个对象时,只需配置好相应的配置文件或注解,无需关心对象的创建过程。IoC 容器就像一个工厂,它根据配置文件或注解来生成和管理对象实例。
- 单例模式:在 Spring 框架中,默认情况下,Bean 是单例的,即在整个应用中只有一个实例。这是通过单例模式实现的,确保每个 Bean 的生命周期内只有一个共享的实例。
- 代理模式:AOP(面向切面编程)是 Spring 的另一个核心特性,它使用代理模式来实现。通过代理模式,可以在不修改原始类代码的情况下,为对象提供额外的功能,例如事务管理和日志记录。
AOP
AOP是面向切面编程,将公共逻辑(事务管理、日志、缓存等)封装成切面,跟业务代码进行分离
具体组成:
1.连接点(JoinPoint):程序执行过程中的任意位置,粒度为执行方法、抛出异常、设置变量等
- 在SpringAOP中,理解为方法的执行
2.切入点(Pointcut):匹配连接点的式子
- 在SpringAOP中,一个切入点可以描述一个具体方法,也可也匹配多个方法
- 连接点范围要比切入点范围大,是切入点的方法也一定是连接点,但是是连接点的方法就不一定要被增强,所以可能不是切入点。
切入点定义依托一个不具有实际意义的方法进行,即无参数、无返回值、方法体无实际逻辑,然后在上面加个@PointCut注解。
3.通知(Advice):在切入点处执行的操作,也就是共性功能,是通知类的一个函数
4.通知类:定义通知的类
5.切面(Aspect):描述通知与切入点的对应关系。
静态代理
静态代理:代理类在编译阶段生成,在编译阶段将通知织入Java字节码中,也称编译时增强。AspectJ使用的是静态代理。
缺点:代理对象需要与目标对象实现一样的接口,并且实现接口的方法,会有冗余代码。同时,一旦接口增加方法,目标对象与代理对象都要维护。
动态代理
动态代理:代理类在程序运行时创建,AOP框架不会去修改字节码,而是在内存中临时生成一个代理对象,在运行期间对业务方法进行增强,不会生成新类。
Spring的AOP是通过动态代理实现的。而Spring的AOP使用了两种动态代理,分别是JDK的动态代理(有接口的对象),以及CGLib的动态代理(无接口的对象)可以在运行时动态生成类的字节码,动态创建目标类的子类对象,在子类对象中增强目标类。。
Spring通知类型
- 前置通知(Before):在目标方法被调用之前调用通知功能;
- 后置通知(After):在目标方法完成之后调用通知,此时不会关心方法的输出是什么;
- 返回通知(After-returning ):在目标方法成功执行之后调用通知;
- 异常通知(After-throwing):在目标方法抛出异常后调用通知;
- 环绕通知(Around):通知包裹了被通知的方法,在被通知的方法调用之前和调用之后执行自定义的逻辑。
怎么用AOP实现公共日志保存
使用aop中的环绕通知+切点表达式
怎么用AOP实现事务处理
在方法前后进行拦截,在执行方法之前开启事务
多个切面的执行顺序如何控制?
可以使用@Order 注解直接定义切面顺序
Spring事务
- 编程式事务:通过编程的方式管理事务,这种方式带来了很大的灵活性,但很难维护。
- 声明式事务:在 XML 配置文件中配置或者直接基于注解(推荐使用) : 实际是通过 AOP 实现(基于
@Transactional的全注解方式使用最多)
Spring事务有几种事务传播行为?7种
当事务方法被另一个事务方法调用时,必须指定事务应该如何传播。
PROPAGATION_NESTED 与PROPAGATION_REQUIRES_NEW的区别:
使用PROPAGATION_REQUIRES_NEW时,内层事务与外层事务是两个独立的事务。一旦内层事务进行了提交后,外层事务不能对其进行回滚。两个事务互不影响。
使用PROPAGATION_NESTED时,外层事务的回滚可以引起内层事务的回滚。而内层事务的异常并不会导致外层事务的回滚,它是一个真正的嵌套事务。
Spring事务隔离级别
1.ISOLATION_DEFAULT :使用后端数据库默认的隔离级别,MySQL 默认采用的 REPEATABLE_READ 隔离级别 Oracle 默认采用的 READ_COMMITTED 隔离级别.
2.读未提交ISOLATION_READ_UNCOMMITTED` :
3.读已提交ISOLATION_READ_COMMITTED`:
4.可重复读ISOLATION_REPEATABLE_READ:
5.可串行化ISOLATION_SERIALIZABLE` :
Spring事务失效场景
1.访问权限问题:如果事务方法的访问权限不是定义成public,这样会导致事务失效,因为spring要求被代理方法必须是public的。
2. 方法用final修饰:如果事务方法用final修饰,将会导致事务失效。因为spring事务底层使用了aop,也就是通过jdk动态代理或者cglib,帮我们生成了代理类,在代理类中实现的事务功能。但如果某个方法用final修饰了,那么在它的代理类中,就无法重写该方法添加事务功能。
3.对象没有被spring管理:使用spring事务的前提是:对象要被spring管理,需要创建bean实例。如果类没有加@Controller、@Service、@Component、@Repository等注解,即该类没有交给spring去管理,那么它的方法也不会生成事务。
4.在代码中捕获异常没有抛出:事务通知只有捉到了目标抛出的异常才能进行后续的回滚处理。如果我们自己捕获了异常处理掉了没有抛出,这种情况下spring事务不会回滚。
5.表不支持事务:如果MySQL使用的存储引擎是myisam,这样的话是不支持事务的。因为myisam存储引擎不支持事务。
将一个类声明为 Bean 的注解有哪些?
@Component:通用的注解,可标注任意类为Spring组件。如果一个 Bean 不知道属于哪个层,可以使用@Component注解标注。@Repository: 对应持久层即 Dao 层,主要用于数据库相关操作。@Service: 对应服务层,主要涉及一些复杂的逻辑,需要用到 Dao 层。@Controller: 对应 Spring MVC 控制层,主要用于接受用户请求并调用Service层返回数据给前端页面。
@Component 和 @Bean 的区别是什么?
都是使用注解定义 Bean。@Bean 是使用 Java 代码装配 Bean,@Component 是自动装配 Bean。
Bean 的作用域/作用范围有哪些?
Spring 中 Bean 的作用域通常有下面几种:
- singleton : IoC 容器中只有唯一的 bean 实例。Spring 中的 bean 默认都是单例的,是对单例设计模式的应用。
- prototype : 每次获取都会创建一个新的 bean 实例。也就是说,连续
getBean()两次,得到的是不同的 Bean 实例。 - request (仅 Web 应用可用): 每一次 HTTP 请求都会产生一个新的 bean(请求 bean),该 bean 仅在当前 HTTP request 内有效。
- session (仅 Web 应用可用) : 每一次来自新 session 的 HTTP 请求都会产生一个新的 bean(会话 bean),该 bean 仅在当前 HTTP session 内有效。
- application/global-session (仅 Web 应用可用):每个 Web 应用在启动时创建一个 Bean(应用 Bean),该 bean 仅在当前应用启动时间内有效。
- websocket (仅 Web 应用可用):每一次 WebSocket 会话产生一个新的 bean。
单例bean线程安全问题解决办法
对于有状态单例 Bean 的线程安全问题,常见的有两种解决办法:
- 在 Bean 中尽量避免定义可变的成员变量。
- 在类中定义一个
ThreadLocal成员变量,将需要的可变成员变量保存在ThreadLocal中(推荐的一种方式)。
SpringBoot如何实现自动装配?
SpringBoot通过@EnableAutoConfiguration注解和自动配置类实现自动装配。
SpringBoot的自动装配机制主要涉及以下几个步骤:
- 使用@SpringBootConfiguration注解:该注解中包含@EnableAutoConfiguration,它是实现自动装配的起始点。
- 启用自动配置:通过@EnableAutoConfiguration注解启用自动配置功能,该注解会导入一个特殊的组件,即AutoConfigurationImportSelector类型的组件。
- 加载自动配置类:AutoConfigurationImportSelector类型的组件会根据项目的依赖以及spring.factories文件中的配置,自动导入相应的自动配置类到Spring容器中。
- 按需加载配置类:所有被扫描到的自动配置类将根据条件进行生效,比如对应的配置文件是否存在,依赖是否满足等。满足条件的自动配置类将会为容器装配所需的组件。
- 自定义配置:如果需要替换或修改默认的自动配置,可以通过定义自己的@Bean来替换默认的Bean,或者在application.properties中修改相关参数来达到定制化配置的目的。
- SPI机制:SpringBoot还采用了Service Provider Interface (SPI)机制来实现一些自动装配的功能,使得程序可以自动地、可插拔地进行装配。
bean自动装配的方式/注入方式有哪些?
默认情况下@Autowired是按类型匹配的(byType)。如果需要按名称(byName)匹配的话,可以使用@Qualifier注解与@Autowired结合。
BeanFactory和FactoryBean的区别?
BeanFactory:是所有Spring Bean的容器根接口,给Spring 的容器定义一套规范,给IOC容器提供了一套完整的规范,比如我们常用到的getBean方法等
FactoryBean:是一个bean。但是他不是一个普通的bean,是可以创建对象的bean。。通常是用来创建比较复杂的bean,一般的bean 直接用xml配置即可,但如果一个bean的创建过程中涉及到很多其他的bean 和复杂的逻辑,直接用xml配置比较麻烦,这时可以考虑用FactoryBean,可以隐藏实例化复杂Bean的具体的细节.
BeanFactory和ApplicationContext有什么区别?
1、功能上的区别。BeanFactory是Spring里面最底层的接口,包含了各种Bean的定义,读取bean配置文档,管理bean的加载、实例化,控制bean的生命周期,维护bean之间的依赖关系。
ApplicationContext接口作为BeanFactory的派生,除了提供BeanFactory所具有的功能外,还提供了更完整的框架功能,如继承MessageSource、支持国际化、统一的资源文件访问方式、同时加载多个配置文件等功能。
2、加载方式的区别。BeanFactroy采用的是延迟加载形式来注入Bean的,即只有在使用到某个Bean时(调用getBean()),才对该Bean进行加载实例化。这样,我们就不能发现一些存在的Spring的配置问题。如果Bean的某一个属性没有注入,BeanFacotry加载后,直至第一次使用调用getBean方法才会抛出异常。
而ApplicationContext是在容器启动时,一次性创建了所有的Bean。这样,在容器启动时,我们就可以发现Spring中存在的配置错误,这样有利于检查所依赖属性是否注入。 ApplicationContext启动后预载入所有的单例Bean,那么在需要的时候,不需要等待创建bean,因为它们已经创建好了。
相对于基本的BeanFactory,ApplicationContext 唯一的不足是占用内存空间。当应用程序配置Bean较多时,程序启动较慢。
怎么让2个bean按顺序加载?
当一个 bean 需要在另一个 bean 初始化之后再初始化时,可以使用@DependOn注解
springboot中不想加载一个bean如何做
- 自定义@ComponentScan:通过自定义@ComponentScan注解,您可以指定需要扫描的包路径,从而排除不想加载的bean。在@ComponentScan注解中使用excludeFilters属性来排除特定的类。
- 使用@SpringBootApplication的exclude属性:如果您使用的是@SpringBootApplication注解,可以利用它的exclude属性来排除自动配置类。例如,如果您不想加载某个自动配置类,可以在@SpringBootApplication注解中列出这个类。
- 使用@EnableAutoConfiguration的exclude属性:在Spring Boot的启动类上使用@EnableAutoConfiguration(exclude = {ClassNotToLoad.class}),这样可以排除掉不需要自动配置的类。
- 使用TypeExcludeFilter:创建一个自定义的TypeExcludeFilter实现,并在@ComponentScan注解中引用它。这样可以实现更精细的控制,只排除特定类型的bean。
- 移除相关注解:如果某个bean是通过@Component、@Service、@Repository等注解自动注册到Spring容器中的,您可以通过移除这些注解来阻止它的加载。
- 调整bean加载顺序:在某些情况下,您可能需要控制bean的加载顺序。虽然@Order、@AutoConfigureOrder、@AutoConfigureAfter和@AutoConfigureBefore等注解主要用于控制Spring组件的顺序,但它们也可以在一定程度上影响bean的加载顺序。
Spring循环依赖问题(三级缓存)
循环依赖其实就是循环引用,也就是两个或两个以上的bean互相持有对方,最终形成闭环。比如A依赖于B,B依赖于A。
对于构造器注入的循环依赖,Spring处理不了,会直接抛出异常。我们可以使用@Lazy懒加载,什么时候需要对象再进行bean对象的创建
对于属性注入的循环依赖,是通过三级缓存处理来循环依赖的。
1.singletonObjects:一级缓存,里面放置的是已经完成所有创建动作的单例对象,也就是说这里存放的bean已经完成了所有创建的生命周期过程,在项目运行阶段当执行多次getBean()时就是从一级缓存中获取的。 2.earlySingletonObjects:二级缓存,里面存放的只是进行了实例化的bean,还没有进行属性设置和初始化操作,也就是bean的创建还没有完成,还在进行中,这里是为了方便被别的bean引用
3.singletonFactories:三级缓存,Spring中的每个bean创建都有自己专属的ObjectFactory工厂类,三级缓存缓存的就是对应的bean的工厂实例,可以通过该工厂实例的getObject()方法获取该bean的实例。
第一,先实例A对象,同时会创建ObjectFactory对象存入三级缓存singletonFactories
第二,A在初始化的时候需要B对象,这个走B的创建的逻辑
第三,B实例化完成,也会创建ObjectFactory对象存入三级缓存singletonFactories
第四,B需要注入A,通过三级缓存中获取ObjectFactory来生成一个A的对象同时存入二级缓存,这个是有两种情况,一个是可能是A的普通对象,另外一个是A的代理对象,都可以让ObjectFactory来生产对应的对象,这也是三级缓存的关键
第五,B通过从通过二级缓存earlySingletonObjects 获得到A的对象后可以正常注入,B创建成功,存入一级缓存singletonObjects
第六,回到A对象初始化,因为B对象已经创建完成,则可以直接注入B,A创建成功存入一次缓存singletonObjects
第七,二级缓存中的临时对象A清除
Spring启动过程
- 读取web.xml文件。
- 创建 ServletContext,为 ioc 容器提供宿主环境。
- 触发容器初始化事件,调用 contextLoaderListener.contextInitialized()方法,在这个方法会初始化一个应用上下文WebApplicationContext,即 Spring 的 ioc 容器。ioc 容器初始化完成之后,会被存储到 ServletContext 中。
- 初始化web.xml中配置的Servlet。如DispatcherServlet,用于匹配、处理每个servlet请求。
Spring MVC
MVC的全名是Model View Controller,是模型(model)-视图(view)-控制器(controller)的缩写,是一种软件设计典范。
- 模型(Model):模型代表应用程序的数据结构和业务逻辑,它负责处理应用程序的数据和业务规则。模型可以直接管理数据库,并且当数据发生变化时,它能够通知视图进行更新。
- 视图(View):视图是用户界面的组成部分,它负责展示模型中的数据。视图通常会从模型中获取数据并显示给用户,但它并不直接与模型交互,而是通过控制器来进行数据的更新和请求。
- 控制器(Controller):控制器作为模型和视图之间的中介,它负责接收用户的输入,并根据输入更新模型或视图。控制器处理用户的请求,决定调用哪个模型来处理数据,并选择相应的视图来显示响应。
什么是拦截器
- 拦截器(Interceptor)是一种动态拦截方法调用的机制,在SpringMVC中动态拦截控制器方法的执行
- 作用:
- 在指定的方法调用前后执行预先设定的代码
- 阻止原始方法的执行
怎么自定义拦截器
- 前置处理(preHandle()方法):该方法在执行控制器方法之前执行。返回值为Boolean类型,如果返回false,表示拦截请求,不再向下执行,如果返回true,表示放行,程序继续向下执行(如果后面没有其他Interceptor,就会执行controller方法)。所以此方法可对请求进行判断,决定程序是否继续执行,或者进行一些初始化操作及对请求进行预处理。
- 后置处理(postHandle()方法):该方法在执行控制器方法调用之后,且在返回ModelAndView之前执行。由于该方法会在DispatcherServlet进行返回视图渲染之前被调用,所以此方法多被用于处理返回的视图,可通过此方法对请求域中的模型和视图做进一步的修改。
- 已完成处理(afterCompletion()方法):该方法在执行完控制器之后执行,由于是在Controller方法执行完毕后执行该方法,所以该方法适合进行一些资源清理,记录日志信息等处理操作。
拦截器工作流程
1.所有的拦截器(Interceptor)和处理器(Handler)都注册在HandlerMapping中。
2.Spring MVC中所有的请求都是由DispatcherServlet`分发的。
3.当请求进入DispatcherServlet.doDispatch()时候,首先会得到处理该请求的Handler(即Controller中对应的方法)以及所有拦截该请求的拦截器。拦截器就是在这里被调用开始工作的。
4.当有拦截器后,请求会先进入preHandle方法,如果方法返回true,postHandle、afterCompletion才有可能被执行。如果返回false,则直接跳过后面方法的执行。
拦截器和过滤器的区别
- 归属不同:Filter属于Servlet技术,Interceptor属于SpringMVC技术
- 拦截内容不同:Filter对所有访问进行增强,Interceptor仅针对SpringMVC的访问进行增强
- 拦截器提供了三个方法,分别在不同的时机执行;过滤器仅提供一个方法
什么是restful风格
使用统一的资源标识符(URI)来表示资源、使用标准的HTTP方法(如GET、POST、PUT、DELETE)来对资源进行操作、使用状态码来表示操作结果等.
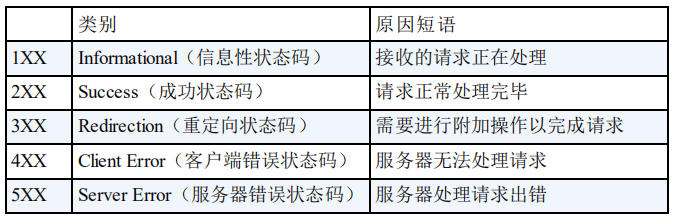
常见 HTTP 状态码
- 200 OK:表示请求成功。
- 201 Created:表示新资源已经成功创建。
- 204 No Content:表示服务器成功处理了请求,但没有返回任何内容。
- 400 Bad Request:表示请求无效,例如缺少必需的参数。
- 401 Unauthorized:表示未经授权,需要进行身份验证。
- 403 Forbidden:表示服务器理解请求,但拒绝执行。
- 404 Not Found:表示请求的资源不存在。
- 405 Method Not Allowed:表示请求中指定的方法不被允许。
- 500 Internal Server Error:表示服务器遇到了一个未曾预料的状况,导致无法完成对请求的处理。
SpringMVC执行流程/工作原理
- 客户端(浏览器)发送请求,
DispatcherServlet拦截请求。 DispatcherServlet根据请求信息调用HandlerMapping。HandlerMapping根据 URL 去匹配查找能处理的Handler(也就是我们平常说的Controller控制器) ,并会将请求涉及到的拦截器和Handler一起封装。DispatcherServlet调用HandlerAdapter适配器执行Handler。Handler完成对用户请求的处理后,会返回一个ModelAndView对象给DispatcherServlet,ModelAndView顾名思义,包含了数据模型以及相应的视图的信息。Model是返回的数据对象,View是个逻辑上的View。ViewResolver会根据逻辑View查找实际的View。DispaterServlet把返回的Model传给View(视图渲染)。- 把
View返回给请求者(浏览器)
Spring MVC的主要组件?
DispatcherServlet:核心的中央处理器,负责接收请求、分发,并给予客户端响应。HandlerMapping:处理器映射器,根据 URL 去匹配查找能处理的Handler,并会将请求涉及到的拦截器和Handler一起封装。HandlerAdapter:处理器适配器,根据HandlerMapping找到的Handler,适配执行对应的Handler;Handler:请求处理器,处理实际请求的处理器。ViewResolver:视图解析器,根据Handler返回的逻辑视图 / 视图,解析并渲染真正的视图,并传递给DispatcherServlet响应客户端
springmvc 如何给接口做幂等?
请求幂等令牌
- 客户端在发起写操作(如创建订单)时,先向服务端申请一个 幂等令牌(UUID)。
- 请求中携带该令牌(HTTP 头
Idempotency-Key或请求体字段)。 - 服务端在处理时:
- 检查 Redis(或数据库)中是否已有该令牌
- 如果已存在,直接返回上次的处理结果
- 如果不存在,先在 Redis 中写入令牌(设置过期),然后执行业务逻辑,最后把处理结果缓存
数据库唯一索引
分布式锁
幂等消息中间件
Springboot
Spring Boot 的核心注解是哪个?
启动类上面的注解是@SpringBootApplication,它也是 Spring Boot 的核心注解,主要组合包含了以下 3 个注解:
- @SpringBootConfiguration:组合了 @Configuration 注解,实现配置文件的功能。
- @EnableAutoConfiguration:打开自动配置的功能,也可以关闭某个自动配置的选项,如关闭数据源自动配置功能: @SpringBootApplication(exclude = { DataSourceAutoConfiguration.class })。
- @ComponentScan:Spring组件扫描。
@EnableAutoConfiguration是实现自动化配置的核心注解。
该注解通过@Import注解导入对应的配置选择器。关键的是内部就是读取了该项目和该项目引用的Jar包的classpath路径下META-INF/spring.factories文件中的所配置的类的全类名。
在这些配置类中所定义的Bean会根据条件注解所指定的条件来决定是否需要将其导入到Spring容器中。
一般条件判断会有像@ConditionalOnClass这样的注解,判断是否有对应的class文件,如果有则加载该类,把这个配置类的所有的Bean放入spring容器中使用。
SpringBoot默认的包扫描路径是启动类所在的包及其子包。
工作原理如下:
- 当Spring Boot应用启动时,会扫描主程序类上的@SpringBootApplication注解。
- 根据@SpringBootConfiguration注解,将当前类作为配置类。
- 根据@ComponentScan注解,扫描指定包下的类,并将其注册为Spring容器中的Bean。
- 根据@EnableAutoConfiguration注解,Spring Boot会自动根据项目中的依赖配置相关的Bean。例如,如果项目中引入了spring-boot-starter-web依赖,那么Spring Boot会自动配置Tomcat和Spring MVC等相关的Bean。
- Spring Boot会将所有配置好的Bean注入到Spring容器中,完成自动配置。
- 最后,Spring Boot会调用主程序类的main方法,启动应用。
Spring常用注解
第一类是:声明bean,有@Component、@Service、@Repository、@Controller
第二类是:依赖注入相关的,有@Autowired、@Qualifier、@Resourse
第三类是:设置作用域 @Scope
第四类是:spring配置相关的,比如@Configuration,@ComponentScan 和 @Bean
第五类是:跟aop相关做增强的注解 @Aspect,@Before,@After,@Around,@Pointcut
注入bean的2个注解@Autowired和@Resource的区别?
1.@Autowired 是 Spring 提供的注解,@Resource 是 JDK 提供的注解。
2.Autowired 默认的注入方式为byType(根据类型进行匹配。
@Resource 有两个比较重要且日常开发常用的属性:name(名称)、type(类型)。如果仅指定 name 属性则注入方式为byName,如果仅指定type属性则注入方式为byType
3.当存在多个同类型的bean(比如一个接口有两个实现类,且它们都已经被 Spring 容器所管理。),@Autowired 和@Resource都需要通过名称才能正确匹配到对应的 Bean。Autowired 可以通过 @Qualifier 注解来指定名称,@Resource可以通过 name 属性来指定名称。
@PathVariable主要用于接收http://host:port/path/{参数值}数据。@RequestParam主要用于接收http://host:port/path?参数名=参数值数据
MyBatis
- MyBatis框架是一个开源的数据持久层框架。
- 它的内部封装了通过JDBC访问数据库的操作,支持普通的SQL查询、存储过程和高级映射,几乎消除了所有的JDBC代码和参数的手工设置以及结果集的检索。
- MyBatis作为持久层框架,其主要思想是将程序中的大量SQL语句剥离出来,配置在配置文件当中,实现SQL的灵活配置。
- 这样做的好处是将SQL与程序代码分离,可以在不修改代码的情况下,直接在配置文件当中修改SQL。
Mybatis和Mybatis-plus的区别
- 实现方式:MyBatis是基于XML或注解方式进行数据库操作的持久化框架,提供了基本的CRUD操作及动态SQL生成等功能。MyBatis-Plus则是在MyBatis的基础上进行了扩展和增强,通过提供更加简化的API使得开发更为便捷,同时在性能、效率和易用性上都有所优化。
- 功能支持:MyBatis-Plus相较于MyBatis增加了许多额外的实用组件,例如条件构造器、代码生成器、分页插件和性能分析拦截器等。
- 编程风格:在MyBatis中,通常需要定义mapper.xml文件和使用相应的SQL查询语句,而在MyBatis-Plus中,开发者可以通过继承BaseMapper和使用Lambda表达式。
延迟加载的底层原理知道吗?
延迟加载的基本原理是,使用 CGLIB 动态代理创建目标对象的代理对象,当调用目标方法时,进入拦截器方法。
Mybatis的一级,二级缓存
Mybatis里面设计了二级缓存来提升数据的检索效率,避免每次数据的访问都需要去查询数据库。
一级缓存是SqlSession级别的缓存:Mybatis对缓存提供支持,默认情况下只开启一级缓存,一级缓存作用范围为同一个SqlSession。在SQL和参数相同的情况下,我们使用同一个SqlSession对象调用同一个Mapper方法,往往只会执行一次SQL。因为在使用SqlSession第一次查询后,Mybatis会将结果放到缓存中,以后再次查询时,如果没有声明需要刷新,并且缓存没超时的情况下,SqlSession只会取出当前缓存的数据,不会再次发送SQL到数据库。若使用不同的SqlSession,因为不同的SqlSession是相互隔离的,不会使用一级缓存。
二级缓存需要自己开启:可以使缓存在各个SqlSession之间共享。当多个用户在查询数据的时候,只要有任何一个SqlSession拿到了数据就会放入到二级缓存里面,其他的SqlSession就可以从二级缓存加载数据。
pagehelper原理
- 拦截 Executor 执行流程
- 利用 MyBatis 插件机制(
Interceptor),拦截Executor.query(...)方法。 - 在拦截器
plugin阶段,PageHelper 会判断是否已开启分页(通过 ThreadLocal 中是否有分页参数),如果没有,则不做处理。
- 利用 MyBatis 插件机制(
- 注入分页参数
- 当调用
PageHelper.startPage(pageNum, pageSize)时,会在当前线程的PageContext(ThreadLocal)里记录pageNum、pageSize、orderBy等信息。 - 拦截器在
before阶段读取这些参数。
- 当调用
- 改写原始 SQL
- 统计总数:如果设置了自动统计(
count = true),PageHelper 会先构造一条SELECT COUNT(1) FROM (原始 SQL) t的 countSQL,执行获取总记录数,并封装到Page对象。 - 分页查询:根据不同数据库方言(MySQL、Oracle、PostgreSQL 等),PageHelper 会在原始 SQL 上追加
LIMIT ?,?(MySQL),或使用ROW_NUMBER()+ 外层WHERE RN BETWEEN ...(Oracle)等手段,覆盖原 SQL 的排序和分页。 - SQL 重写后,通过对原有参数列表前加上
offset、limit(以及 countSQL 的参数),再传给下游执行。
- 统计总数:如果设置了自动统计(
多表分页优化
先在主表用索引分页拿主键,再用小结果集关联其它表

 浙公网安备 33010602011771号
浙公网安备 33010602011771号