《软件工程》第2次作业:第1次项目:第1次个人项目——论文查重
作业标题
| 这个作业属于哪个课程 | 软件工程 |
|---|---|
| 这个作业的要求在哪里 | 作业的要求 |
| 这个作业的目标 | 文本查重 |
作业信息
- 在Github仓库中新建一个学号为名的文件夹,同时在博客正文首行给出作业github链接,并在注册软工在线网站。(3')
GitHub项目:打开即为一个eclipse项目的内容,里面是本次作业内容:实现一个论文查重算法。
注意:该项目已经在2020年09月25日03:00前完成,请手下留情,不要扣分!之所以晚于25日03:00提交只是没有写好博文。
PSP
- 在开始实现程序之前,在下述PSP表格记录下你估计将在程序的各个模块的开发上耗费的时间。(6')
- 在你实现完程序之后,在附录提供的PSP表格记录下你在程序的各个模块上实际花费的时间。(3')
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 45 |
| ·Estimate | ·估计这个任务需要多少时间 | 1380 | 2270 |
| Developemnt | 开发 | 1350 | 2140 |
| ·Analysis | ·需求分析(包括学习新技术) | 720 | 360 |
| ·Design Spec | ·生成设计文档 | 30 | 30 |
| ·Design Review | ·设计复审 | 30 | 180 |
| ·Coding Standard | ·代码规范(为目前的开放制定合适的规范) | 30 | 10 |
| ·Design | ·具体设计 | 120 | 360 |
| ·Coding | ·具体编码 | 240 | 960 |
| ·Code Review | ·代码复审 | 260 | 120 |
| ·Test | ·测试(自我测试,修改代码,提交修改) | 120 | 120 |
| Reporting | 报告 | 120 | 85 |
| ·Test Repor | ·测试报告 | 30 | 40 |
| ·Size Measurement | ·计算工作量 | 30 | 15 |
| ·Postmortem & Process Improvement Plan | ·事后总结,并提出过程改进计划 | 60 | 30 |
| ·合计 |
计算模块接口的设计与实现过程
- 计算模块接口的设计与实现过程。设计包括代码如何组织,比如会有几个类,几个函数,他们之间关系如何,关键函数是否需要画出流程图?说明你的算法的关键(不必列出源代码),以及独到之处。(18')
- mortal.text.similarity.TextSimilarityApp
- 功能:文本相似度计算程序的主类,入口类
- 参数:从命令行接受3个合理的文件路径,依次为:原文文件路径,被测试重复率文件路径,答案保存文件路径
- 注意:
- 前两个命令行参数所指路径必须真实存在,否则抛出异常
- 答案文件可以不存在,此时程序将自动创建文件,请确保路径合理,应用程序有创建文件的权限。
- 若答案文件存在且保存了重要信息,请备份!否则程序输出答案前会删除文件
- mortal.text.similarity.repeatcounter.RepeatWords
- 功能:比较一对字符串数组的相似度,它基于以下规则进行比较
- 字符串数组的每个元素(即字符串)表示一个词语
- 字符串数组表示一个句子中去掉标点符号后分词的结果的数组
- 一对字符串数组之间只有必须超过指定数目的公共重复词语子数组,才会被记录为重复的词语
- 对于一对字符串数组A、B,所得的重复词语子数组,存在不同子数组在不同字符串中有不尽相同的部分词语重复。故对于每一个字符串数组,重复词语数量不是所有词语子数组的简单相加,而是在以该字符串数组为参考,去掉重复的词语后的数量。故A对B的重复词语数与B对A的重复词语不一定相等。(A对B是指以A为参考,去掉重复词语)
- 功能控制:构造器接受两个字符串数组和一个int参数,int参数指示了开始计数为重复时的最少重复词语子数组长度。
- 功能:比较一对字符串数组的相似度,它基于以下规则进行比较
- mortal.textsimilarity.repeatcounter.RepeatRate
- 功能:
- 接受两个字符串,这两个字符串包含要对比的两文本。
- 使用正则将文本划分为句子。
- 使用分词工具将句子分词
- 调用RepeatWords对对句子进行比较,获取这对句子中的重复词语数量
- 功能控制:
- RepeatRate.calculater是进行第4步工作,这个方法接受两参数
- int Range: 控制一个文本中某一位置的句子应该与 在另一个文本中的相同位置的前后各相差Range个句子的范围内的所有句子 都计算重复率, 然后取最大值,作为该文本句子中与另一文本相似词语的数量
- int min : 传递给RepeatWords构造器的参数,指示RepeatWords应该计算重复词语的阈值。
- 功能:
- mortal.text.similarity.repeatcounter.KMP
- 功能:实现KMP算法匹配子串,用来实现获取文本中的不重复的相似词语。
- 注意:该类是暂时未必使用,还没有实现获取文本中的不重复的相似词语的功能。预计在下一个版本中完成这个功能。
计算模块接口部分的性能改进
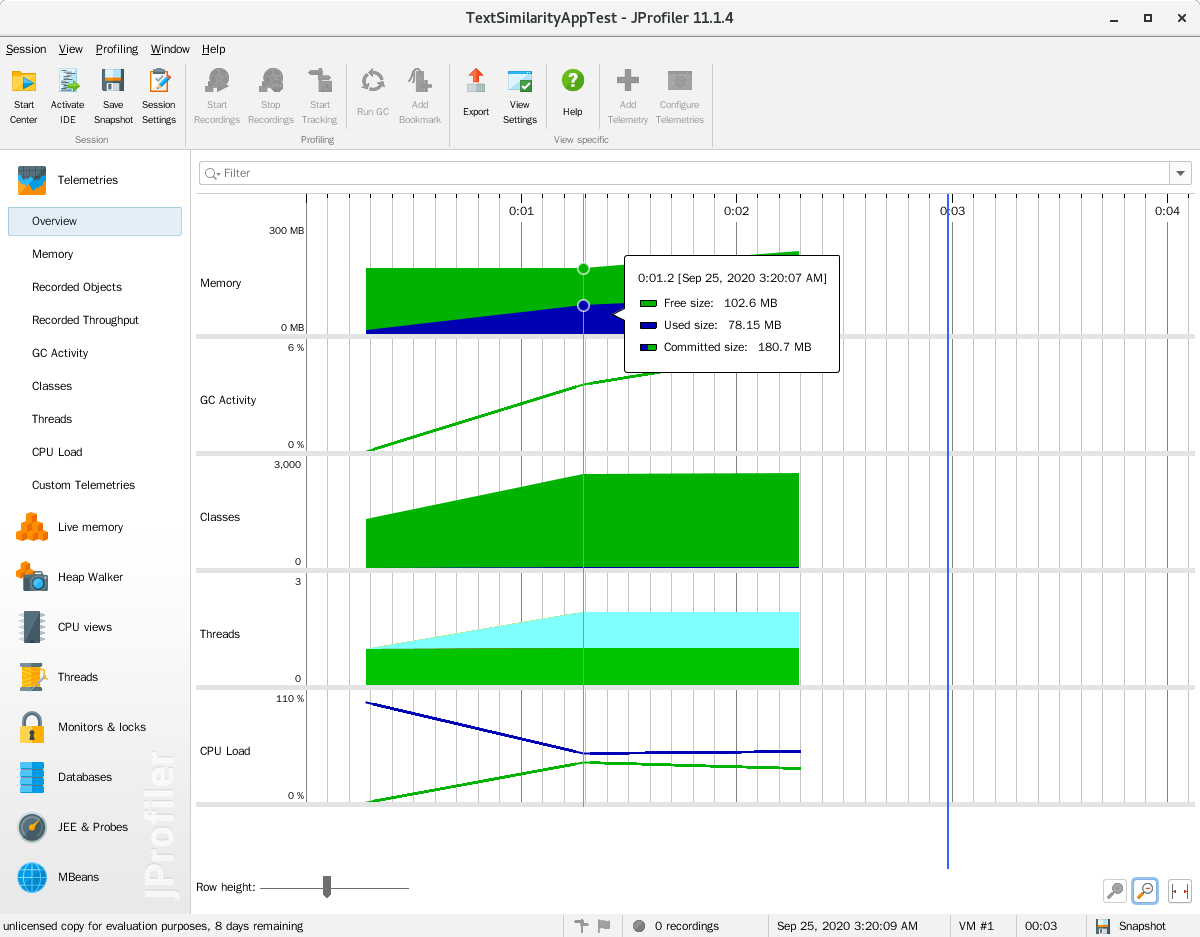
- 计算模块接口部分的性能改进。记录在改进计算模块性能上所花费的时间,描述你改进的思路,并展示一张性能分析图(由VS 2017/JProfiler的性能分析工具自动生成),并展示你程序中消耗最大的函数。(12')
性能改进描述
- mortal.text.similarity.repeatcounter.RepeatWord.calculatePosition()方法使用矩阵来计算所有的重复字符串。
- 参考算法:计算公共字符算法由 “矩阵计算最大公共字符串”改进而来!
- 改进算法功能,由计算一个最大公共字符串改进为计算所有重复字符串
- 改进内存消耗,使用两行数组交替动态工作来形成矩阵,减少了构建矩阵消耗的内存。
整个程序连续测试五个样本的性能分析
计算模块部分的单元测试
- 计算模块部分单元测试展示。展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路。并将单元测试得到的测试覆盖率截图,发表在博客中。(12')
测试是通过java的Junit框架进行测试。
通过注解参数测试@ParameterizedTest 来使得测试方法被自动调用,
并用参数源注解@MethodSourc指示如何获取每次测试应该传入的参数。
测试数据包括期望答案,与被测方法参数。
通过assertEqual方法自动对比期望答案 与 测试方法的返回值,从而知道测试是否正确。
部分测试由于结果数据过大,不再使用对比期望答案的方法来测试正确性,而是直接输出测试结果,再进行人为分辨。
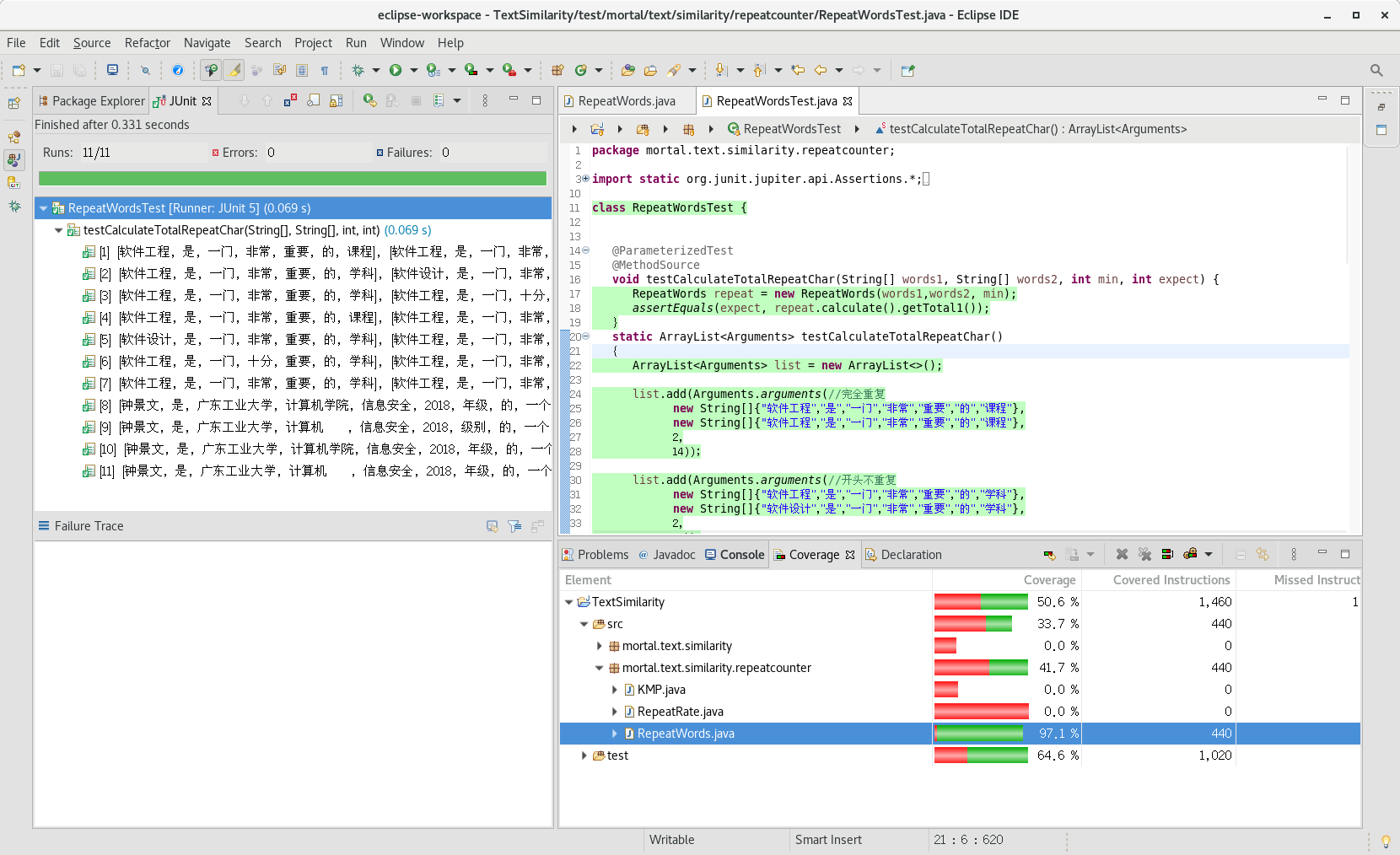
测试RepeatWord
测试思路:自动对比答案
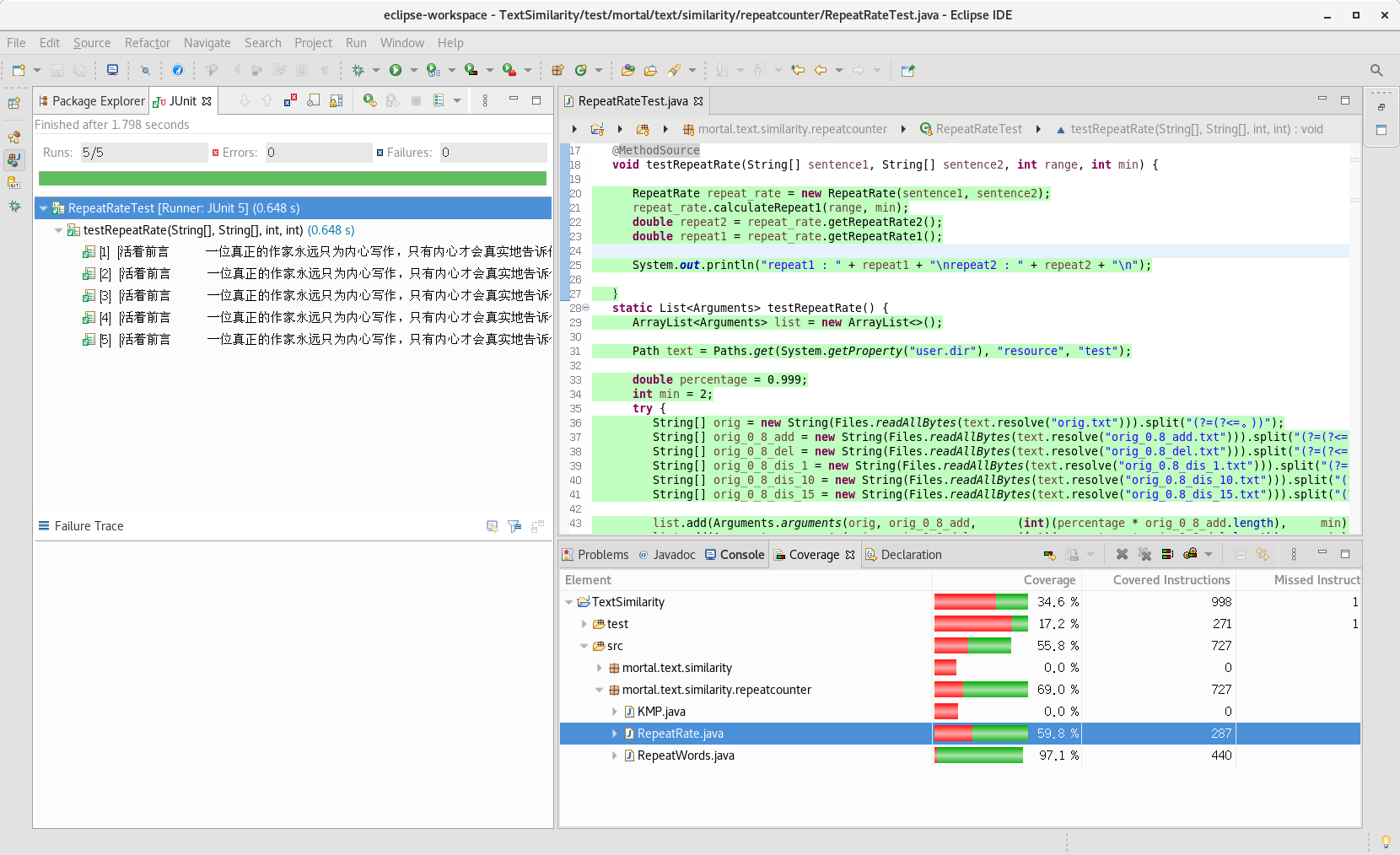
测试RepeatRate
测试思路:显示答案,人工判断。
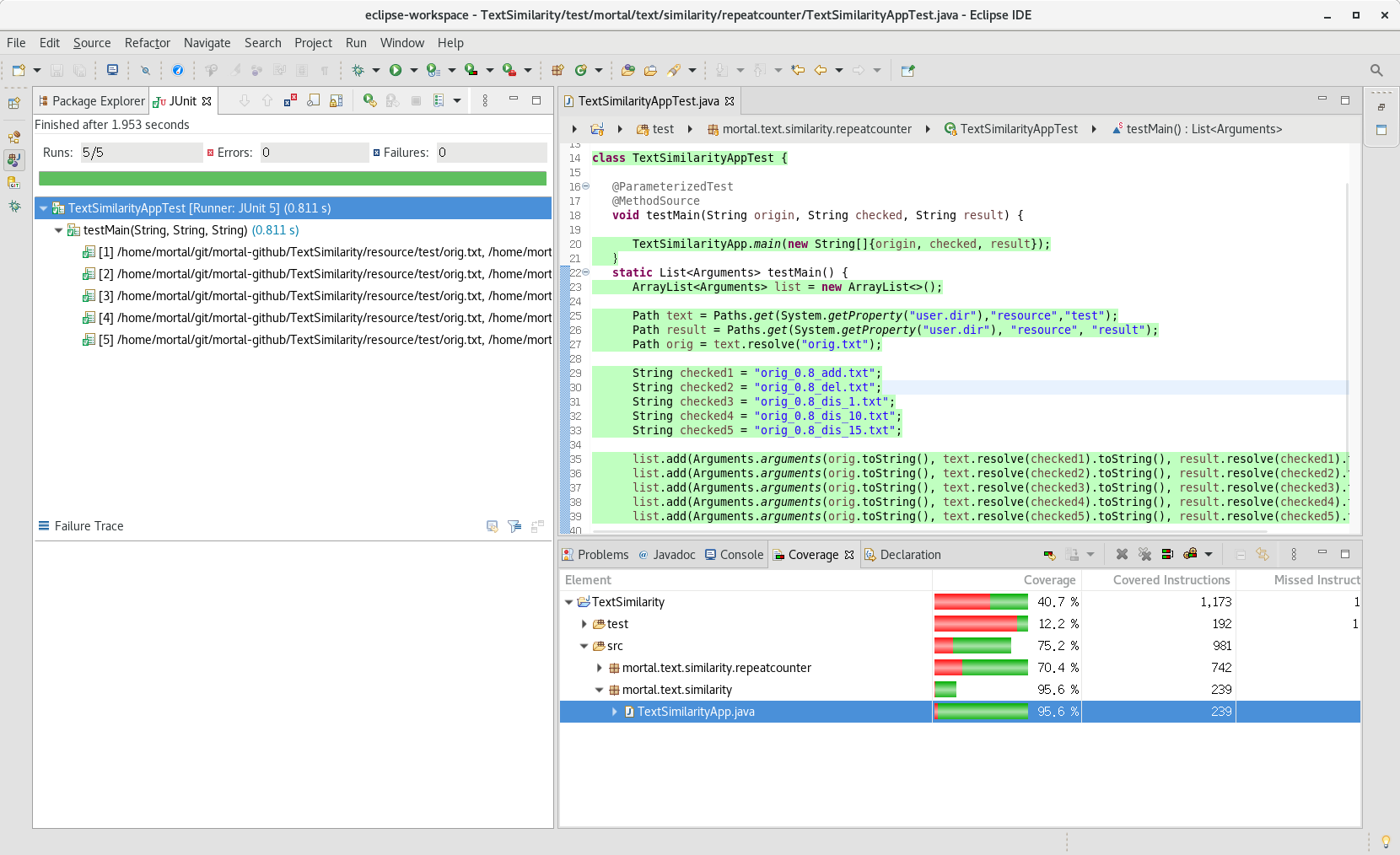
测试TextSimiliarity
测试思路:输出答案文件,人工判断。
计算模块部分异常处理说明
- 计算模块部分异常处理说明。在博客中详细介绍每种异常的设计目标。每种异常都要选择一个单元测试样例发布在博客中,并指明错误对应的场景。(6')
TextSimiliarity类的异常处理
- main 方法参数验证:若没有输入3个参数,则抛出IllegalArgumentExcepton非受查异常,提醒用户正确输入命令行参数
- main 方法中调用的Paths.get(path)将在path不合理时候抛出InvalidPathException非受查异常,提醒用户输入正确的路径字符串参数
- main方法中用try catch块 捕获输入输出异常IOException, 以便处理输入输出错误。
RepeatRate类的异常处理
- 构造器将在用于构造对象的参数的状态会使得文本相似度计算出错的时候抛出NullPointerException异常,具体请查看源代码
RepeatWrod类的异常处理
- 其构造器也会在其参数状态不利于计算重复词语数的时候抛出异常,具体请看源代码!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号