
volatile
我们应该都知道volatile关键字的作用是保证变量在多线程之间的可见性以及有序性。
普通的共享变量不能保证可见性的原因是缓存,首先了解一下CPU缓存:
CPU缓存的出现主要是为了解决CPU运算速度与内存读写速度不匹配的矛盾,因为显而易见CPU运算速度要比内存读写速度快得多,这种访问速度的显著差异导致CPU可能会花费很长时间等待数据或把数据写入内存。
基于此,现在CPU大多数情况下读写都不会直接访问内存,取而代之的是通过CPU缓存间接读写,CPU缓存是位于CPU与内存之间的临时存储器,它的容量比内存小得多但是交换速度却比内存快得多。而缓存中的数据是内存中的一小部分数据,但这一小部分是短时间内CPU即将访问的,当CPU调用大量数据时,就可先从缓存中读取,从而加快读取速度。
按照读取顺序与CPU结合的紧密程度,CPU缓存可分为:
-
一级缓存(L1 Cache)主要当担的工作是缓存指令和缓存数据。一级缓存的容量与结构对CPU性能影响十分大,但是由于它的结构比较复杂,又考虑到成本等因素,一般来说,CPU的一级缓存较小,通常CPU的一级缓存也就能做到256KB左右的水平。
-
二级缓存(L2 Cache)二级缓存的容量会直接影响到CPU的性能,二级缓存的容量越大越好。例如intel的第八代i7-8700处理器,共有六个核心数量,而每个核心都拥有256KB的二级缓存,属于各核心独享,这样二级缓存总数就达到了1.5MB。
-
三级缓存(L3 Cache)其作用是进一步降低内存的延迟,同时提升海量数据量计算时的性能。和一级缓存、二级缓存不同的是,三级缓存是核心共享的,能够将容量做的很大。
当CPU要读取一个数据时,首先从一级缓存中查找,如果没有找到再从二级缓存中查找,如果还是没有就从三级缓存或内存中查找。一般来说,每级缓存的命中率大概都在80%左右,也就是说全部数据量的80%都可以在一级缓存中找到,只剩下20%的总数据量才需要从二级缓存、三级缓存或内存中读取,由此可见一级缓存是整个CPU缓存架构中最为重要的部分。
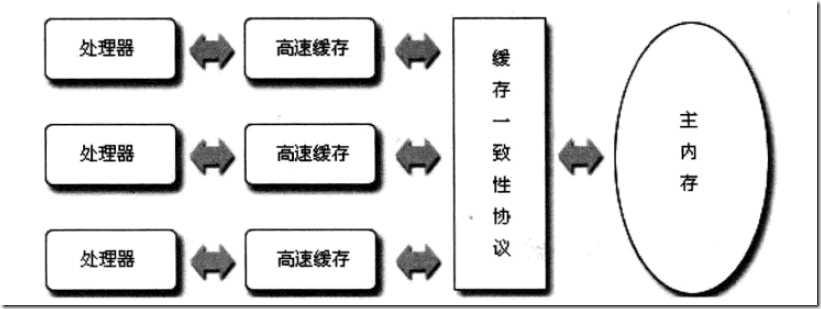
缓存一致性问题
现在的CPU通常是多核,而每个内核都维护了自己的缓存,那么这时候多线程并发就会存在缓存不一致性,这会导致严重问题。
以i++为例,i的初始值是0.那么在开始每块缓存都存储了i的值0,当第一块内核做i++的时候,其缓存中的值变成了1,即使马上回写到主内存,那么在回写之后第二块内核缓存中的i值依然是0,其执行i++,回写到内存就会覆盖第一块内核的操作,使得最终的结果是1,而不是预期中的2。
所以目前通常用在硬件层面解决有两种方案: 1.通过lock#锁的方式 2.通过缓存一致性协议 (如上图所示)
那么理解上述背景后,再回来谈谈volatile如何保证了可见性与禁止指令重排。
我们可以 使用JITWatch获取JIT编译器生成的汇编指令,来看看对Volatile进行写操作CPU会做什么事情。此处参考:https://blog.csdn.net/yjcyyl062c/article/details/84904786
对volatile修饰的变量进行赋值操作:
instance = new Singleton();//instance 是 volatile 变量
生成的汇编代码:
0x01a3de1d: movb $0×0,0×1104800(%esi); 0x01a3de24: lock addl $0×0,(%esp);
“lock addl $0x0,(%esp)”,这个操作中有Lock前缀,Lock不是一种内存屏障,但是它能完成类似内存屏障的功能。Lock会对CPU总线和高速缓存加锁,可以理解为CPU指令级的一种锁。
具体的可以参考下Intel手册:https://www.intel.cn/content/www/cn/zh/architecture-and-technology/64-ia-32-architectures-software-developer-manual-325462.html
它的作用是
- 将当前处理器缓存行的数据会写回到系统内存。
- 这个写回内存的操作会引起在其他 CPU 里缓存了该内存地址的数据无效。
接下来了解下JAVA内存模型
我们已经知道,导致可见性的原因是缓存,导致有序性的原因是编译优化,那解决他们最好的方法是禁用缓存和编译优化,但这样太绝对了,对于程序性能有很大影响,所以合理方案是按需要禁用缓存和编译优化。
简单的说JAVA内存模型就是规范了JVM如何提供按需要禁用缓存和编译优化的方法。
看下下面例子
class VolatileExample {
int x = 0;
volatile boolean v = false;
public void writer() {
x = 42;
v = true;
}
public void reader() {
if (v == true) {
//uses x - guaranteed to see 42.
}
}
}
假设一个线程A调用writer,另一个线程B调用reader。首先根据volatile的语义禁用CPU缓存,线程A对变量v的修改写入内存,线程B会从内存中直接读取变量v,如果此时v==true,那么变量x的值会是多少?
这个其实要看java版本,如果是1.5之前的版本,变量x值可能是0也可能是42,但是1.5之后的版本就是42。
而原因是1.5之后对其进行了增强:Happens-Before 规则。
Happens-Before 规则
本意是前面一个操作的结果对后续操作是可见的,比较正式的说法是:Happens-Before 约束了编译器的优化行为,一共以下几个规则:
(1).程序的顺序规则:在一个线程内,按照程序代码顺序,前面的指令先行发生于在后面的指令。
(2).管程中锁的规则:在java中,管程指synchronized,同一个锁下,一个unlock操作先行发生于后面对同一个锁的lock操作。
(3).volatile变量规则:对一个volatile变量的写操作先行发生于后面对这个变量的读操作。
(4).线程启动规则:假如线程A调用线程B的start()方法,则该start()操作Happens-Before 于线程B中的任何操作。
(5).线程终止规则:线程中的所有操作都先行发生于对此线程的终止检测,我们可以通过Thread.join()方法结束、Thread.isAlive()的返回值等手段检测到线程已经终止执行。
(6).线程中断规则:对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生,可以通过Thread.interrupted()方法检测到是否有中断发生。
(7).对象终结规则:一个对象的初始化完成(构造函数执行结束)先行发生于它的finalize()方法的开始。
参考资料
https://www.infoq.cn/article/zzm-java-hsdis-jvm/
https://www.infoq.cn/article/java-memory-model-4

 浙公网安备 33010602011771号
浙公网安备 33010602011771号