

【翻译】Raft 共识算法:集群成员变更
转载请注明出处:https://www.cnblogs.com/morningli/p/16770129.html
之前都在集群配置是固定的(参与共识算法的server集合)假设下讨论raft。在实践中,偶尔有需要改变配置,比如说当server故障时替换server,或者改变复制级别。虽然可以通过下线整个集群,更新配置文件,重启集群来实现,但是这样会导致集群在改变的过程中一直不可用。另外,人工操作存在操作错误的风险。为了避免这样的问题,raft通过自动化配置变更并将它包含到raft共识算法中。
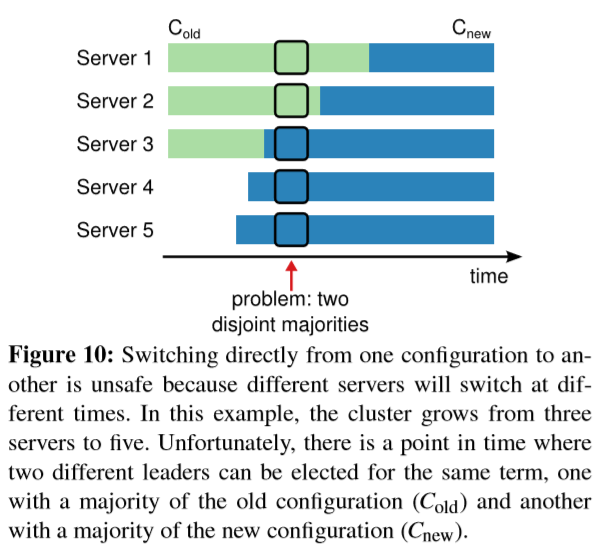
为了保证配置变更机制是安全的,必须保证不存在转换过程中有两个leader在同一个term内被选举出来。不幸的是,server直接从老配置转换到新配置的任何方法都是不安全的。不可能自动一下子自动切换所有的server,所以集群在转换期间存在分裂成两个独立的大多数的可能性(见 Figure 10)。
为了保证安全性,配置变更必须使用两阶段方法。有不同的方式来实现两阶段。举个例子,一些系统使用第一阶段禁用老的配置,这样系统无法处理客户端请求;然后第二阶段启用新的配置。在raft集群首先切换到一个过度的配置,称为joint consensus;一旦joint consensus被提交,系统切换到新的配置。joint consensus结合了新老配置:
- 日志记录复制到新老配置的所有server
- 两个配置中任何一个server都可以作为leader
- 达成一致(针对选举和提交)需要分别在两种配置上获得大多数的支持。
joint consensus允许各个服务器在不同时间在配置之间进行转换,而不会影响安全性。此外,joint consensus允许集群在整个配置更改期间继续为客户端请求提供服务。

集群配置通过复制的日志中的特殊记录来存储和交流;Figure 11介绍了配置变更过程。当leader接收到一个将配置从Cold修改为Cnew的请求时,它会为joint consensus (图中的Cold,new)将这个配置存储成一个日志记录并复制这个记录。一旦一个server将这个新的配置记录添加到它的日志里,它以后的决定都会使用这个配置(server总会使用日志中最新的配置,无论这个配置是否提交)。这意味着leader将会使用Cold,new的规则来决定Cold,new这个记录什么时候是committed的。如果leader崩溃了,一个新的leader有可能包含配置Cold或者Cold,new,取决于取胜的candidate有没有收到Cold,new。在这个期间,任何情况Cnew不能单方面做决定。
一旦Cold,new已经被提交,Cold或者Cnew都不能在没有得到对方同意的情况下做决定的,Leader Completeness Property保证了只有包含Cold,new的记录的server会被选为leader。leader这是创建一个Cnew的日志并复制到集群中是安全的。这个配置会在server接收到后立马生效。当新的配置在Cnew的规则下被提交时,老的配置已经不重要了,不在新配置中的server可以被关停。如Figure 11所示,不存在Cold和Cnew单方面做决定的时候。这保证了安全性。
配置变更还有三个问题需要解决。第一个问题是新的server刚开始不会存储任何日志。如果新server被添加到集群,它们跟上日志需要一些时间,这段时间内不能提交新的日志记录。为了避免这种可用性的间隔时间,raft在更新配置之前引入了额外的步骤,新加入集群的server作为一个 non-voting 成员(leader复制记录给它们,但是在大多数投票时不会将它考虑进来)。一旦这个新server追上集群中其他server的进度,配置更新像上面描述的过程一样。
第二个问题是集群leader可能不属于新配置中的成员。这种情况,leader提交了Cnew后立马下台(变回follower状态)。这表示会有一段时间(正在提交Cnew)leader会管理一个不包含自己的集群;它复制日志记录但是在计算大多数时不会把自己考虑进去。在Cnew被提交的时候变更leader是因为这是新配置可以独立运行的最早的时间点(新的leader肯定会包含Cnew)。在这个点之前,有可能选出一个包含Cold配置的leader。
第三个问题是移除server(不在Cnew)会扰乱集群。这些server不会受到心跳,所以它们会超时并开始新的投票。它们会使用新的term发送RequestVote RPCs ,这会导致当前的leader转换到follower状态。最终会选出一个新的leader,但是已经移除的server会再次超时,上面的过程会重复发送,影响了可用性。
为了避免这样的问题,server在确认当前leader存在时,会忽略RequestVote RPCs。确切的来说,如果server在最小选举超时时间内收到一个来自当前leader的 RequestVote RPC ,它不会更新它的term或者投票。这不会影响正常的选举,每个server在开始选举之前都至少会等待一个最小选举超时时间。然而,这避免了来自移除节点的干扰:如果一个leader可以发送心跳到集群中,它不会被更大的term罢免。
本文来自博客园,作者:morningli,转载请注明原文链接:https://www.cnblogs.com/morningli/p/16770129.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!