Hadoop 1 ecosystem
ref:http://www.bogotobogo.com/Hadoop/BigData_hadoop_Ecosystem.php
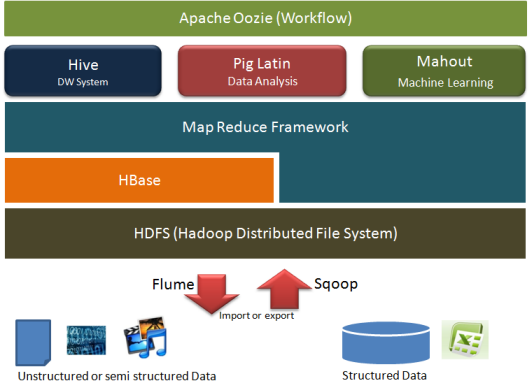
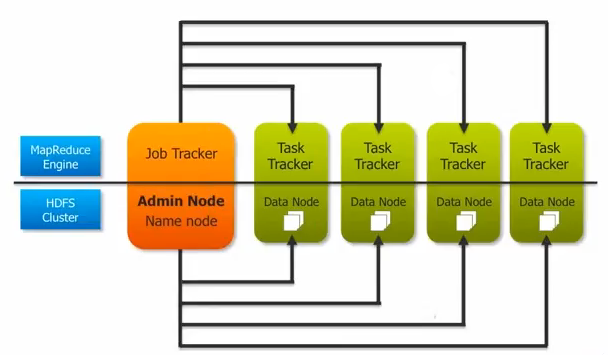
Hadoop consist of two main pieces, HDFS and MapReduce
- The HDFS is the data part of Hadoop and the HDFS server on a typical machine is called a DataNode
- The MapReduce is the processing part of Hadoop and the MapReduce server on a typical machine is called TaskTracker
MapReduce needs a coordinator which is called a JobTracker.
JobTracker
1. responsible for accepting user's job, dividing it into tasks and assigning it to individual TaskTracker. TaskTracker will run the task and
reports the status as it runs and completes.
2. responsible for noticing if the TaskTracker disappears because of software failure or hardware failure. It needs to reassign the task to
another TaskTracker
The NameNode takes the similar role to HDFS as the JobTracker does to the MapReduce
Since the hadoop project was first started, lots of other software has been built around it. Lots of them designed to make Hadoop easier to use, people who are not programmers or are businessman can use Hadoop
1. several open source project have been created to make it easier for people to query their data without having to write macros and reducers.
Hive: in Hive we just write a statement which looks like standard SQL query:
select * from ...
The Hive interpreter truns the SQL into map reduce code, which then runs on the cluster. Facebook use it intensely.
Pig: allows us to write code to analyse our data in a fairlry simple scripting lanaguage, rather than map reduce.
It is a high-level language for routing data. The code is just turned into mao reduce and run on cluster. It wirds like a compiler which translates our program into an assembly. So, the Pig does the same thing for MapReduce jobs.
** Though Hive and Pig are great, they are still running map reduce jobs, and can take a resonable time to run, especially over large amounts of data.
 That is why another open source project called Impala created. It was developed
That is why another open source project called Impala created. It was developed
as a way to query data with SQL directly from HDFS, it does not run map reduce program. Impala is optimized for low latency queries.
Therefore, impala queries run very faster than Hive, while Hive is optimized for running long batch processing jobs.
 Sqoop takes data from traditional relational databases such as Mirosoft SQL server and puts it in HDFS
Sqoop takes data from traditional relational databases such as Mirosoft SQL server and puts it in HDFS
 Flume is for streaming data into Hadoop. It injects data as it's generated by external systems
Flume is for streaming data into Hadoop. It injects data as it's generated by external systems
and put it into the cluster. So if we have severs generating data continuously, we can use Flume. Like reading facebook, twitter data into HDFS
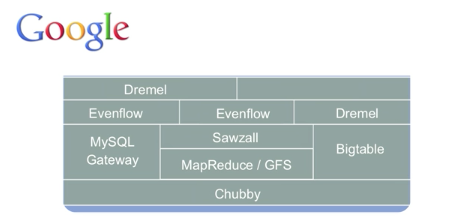
![]() Hbase is a real time databse, built on top of HDFS, It's colum-family stored on the Google's BigTable design.
Hbase is a real time databse, built on top of HDFS, It's colum-family stored on the Google's BigTable design.
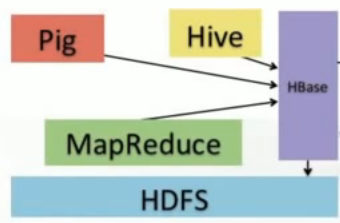 we need to read/write data in real time and HBase is a top-level Apache project meets that need. It provides a simple interface to our distributed data that allows incremental processing. HBase can be accessed by Hive and Pig by MapReduce and stores that information in its HDFS and it's guranteed to be reliable and durable. HBase is used for application such as Facebook messages.
we need to read/write data in real time and HBase is a top-level Apache project meets that need. It provides a simple interface to our distributed data that allows incremental processing. HBase can be accessed by Hive and Pig by MapReduce and stores that information in its HDFS and it's guranteed to be reliable and durable. HBase is used for application such as Facebook messages.
 KijiSchema provides a simple Java API and comman line interface for importing, managing, and retrieving data from HBase by setting up HBase layouts using user-friendly tools including a DDL
KijiSchema provides a simple Java API and comman line interface for importing, managing, and retrieving data from HBase by setting up HBase layouts using user-friendly tools including a DDL
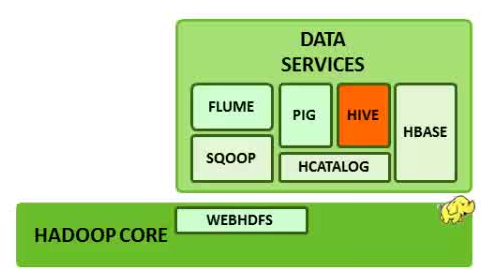
Hive: Hive is a data warehouse system layer built on Hadoop. It allows us to define a structure for our unstructureed
Big Data. With a HiveQL which is an SQL-like scripting language, we can simplify analysis and queries.
Hive is not a databse but uses a databse to store metadata. The data that Hive processes isstored in HDFS, Hive runs on Hadoop and
is NOT designed for on-line transaction processing because the latency for Hive queries is generally high. Therefore, Hive is NOT suited for real-tme queries. Hive is best suited for batch jobs over large sets of immutable data such as web logs
Hue: is a graphical front end to quester
Oozie: is a workflow scheduler tool it provides workflow/coordination service to manage Hadoop jobs. So, we define when we want our MapReduce jobs to run and Oozie will fire them up automatically. It also will trigger when data becomes avaliablel
Mahout: is a library for scalable machine learing and data mining
Avro: is a Serialization and RPC framework
** In fact, there are so many ecosystem projects that making them all talk to one another, and work well can be tricky
To make installing and maintaining a cluster like this easier, a company called Cloudera, has put together a distribution of HADOOP called CDH(Cloudera distribution including a patchy HADOOP) takes all the key echosystem projects, along with Hadoop itself, and packages them together so that installation is a really easy process. It is free and open source, just like Hadoop itself, While we coild install everything from scratch, it is far easier to use CDH
Zookeeper: allows distributed process to coordinate with each other through a shared hierarchical name sapce of data registers
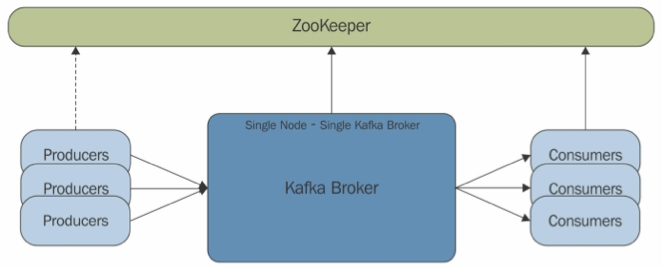 Kafka: kafka is a distributed, partitioned, replicated commit log service. It provides the functionality of a message system, but with a unique design.
Kafka: kafka is a distributed, partitioned, replicated commit log service. It provides the functionality of a message system, but with a unique design.
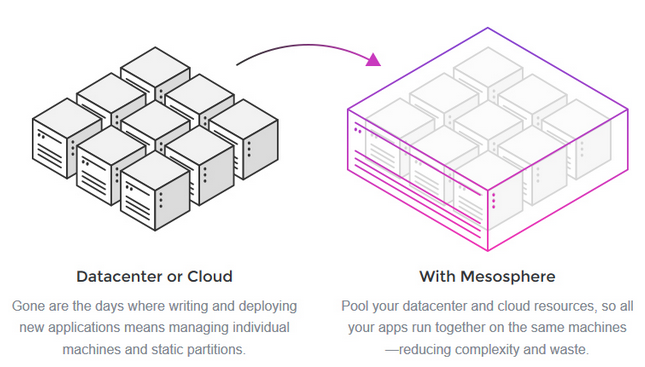
Data center orchestration - Mesos
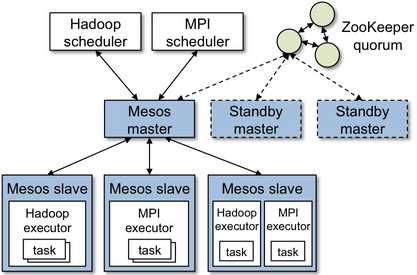
Mesos is built using the same principle as the linux kernal, only at different level of abstraction. The Mesos kernel runs on every machine and provides application(e.g. Hadoop, Spark, Kafka, Elastic Search) with API's for resource management and scheduling across entire datacenter and cloud environments.