每日三省Java
1、集合
- ArrayList,基于数组Object[] elementData实现,因为是连续内存,所以使用native方法System.arraycopy执行扩容操作,1.5倍扩容
- 迭代器模式,定义Iterable接口表示“可迭代”,Collection extends Iterable,List、Set等实现类各自实现Iterable定义的iterator()方法,实现从外部迭代Collection
- HashMap,基于Node<K, V>数组,通过hash算法直接找到数据进行读写操作,put/get的时间复杂度都是O(1),如果hash结果相同但equals结果不同,则判定为发生了hash冲突,用链地址法解决hash冲突,1.8新增了红黑树,2倍扩容,触发rehash后原数组不释放,实际占用内存会是3倍,所以应尽量避免触发rehash
- LinkedHashMap,按插入顺序有序的HashMap,extends HashMap,内部的Entry也是继承了HashMap.Node,增加before、after两个指针,put逻辑复用了HashMap的put逻辑,额外实现了afterNodeInsertion来操作before、after,put/get的时间复杂度也都是O(1)
- TreeMap,基于红黑树实现,通过root节点 Entry<K,V> root 来操作树,put/get的时间复杂度都是O(logN),按key值大小有序,优先使用TreeMap的成员变量comparator做key值比较,comparator为空的时候使用key的compareTo方法做比较,如果key对象没有实现Comparable将会报错
- ConcurrentHashMap,并发安全的HashMap,1.7使用分段Lock,1.8使用CAS+synchronized,Java7/8 中的 HashMap 和 ConcurrentHashMap 全解析
2、多线程&锁
- 引入多线程的原因,CPU和内存、磁盘的性能差异较大,为了尽可能的挖掘CPU的性能,引入多线程
- 多线程操作同一个数据会导致更新丢失等线程安全问题,引入锁解决线程安全问题
- Java线程的生命周期,waiting和block、sleep的区别
- synchronized,JVM实现,可重入、非公平,基于Object的monitor,不需要额外的释放锁操作,1.5之后增加了偏向锁、轻量级锁等,减轻加锁代价
- Lock,JDK实现,CAS乐观锁,可重入,默认非公平,基于AQS,策略可选,基于Condition实现wait/notify机制,一个锁可以创建多个Condition,更灵活
- synchronized 获取的锁,在方法抛出异常的时候会自动解锁,ReentrantLock 获取的锁,异常的时候也不会自动释放!
- volatile,内存屏障,保证变量的内存可见性
- Atomic类的实现原理,volatile保证可见性,自旋+CAS保证原子性
3、线程池
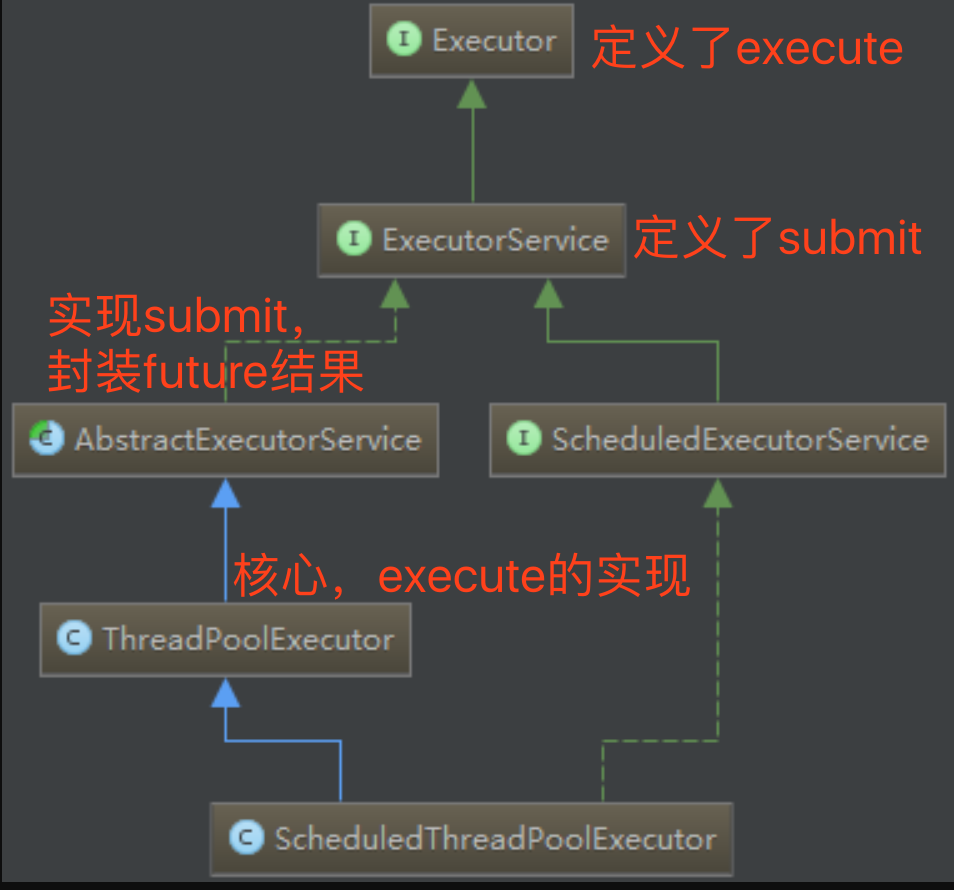
ThreadPoolExecutor的构造参数:
- corePoolSize, 核心线程数
- maximumPoolSize, 最大线程数,任务队列也满员之后才会按此限制继续创建线程
- workQueue, 任务的阻塞队列。若线程池已经被占满,则该队列用于存放无法再放入线程池中的Runnable
- keepAliveTime, 线程存活时间。当线程数大于core数,那么超过该时间的线程将会被终结
- threadFactory, 创建线程的工厂类
- handler, 队列满载后的抛弃策略,可选:抛弃前面的任务、抛弃后面的任务,默认抛出异常RejectedExecutionException
4、JVM
- 堆区,存放Object实例,Object头部记录了对象的age、monitor等信息,整个堆区划分为Old+Young(Eden+S1+S2),有各自的GC策略
- 栈区,一个线程一个栈,栈帧描述的是方法的执行信息,局部变量表、方法返回地址等信息,线程太多会导致OOM
- 方法区,存放class信息、静态变量、常量。类加载机制:装载(双亲委派ClassLoader)、链接、初始化(静态变量、常量)
- 程序计数器,唯一没有规定OOM的区域,每个线程有自己的程序计数器
- CMS,老年代回收器,以获取最小停顿时间为目的,分为4个阶段:初始标记(STW,标记GC ROOT能直接关联到的对象)、并发标记(标记间接关联到的对象)、重标记(STW,查漏补缺,直接+间接的一次完整标记)、并发清理
5、spring
IOC、AOP,反射原理,jdk动态代理、cglib的动态代理的原理
spring启动过程,springMVC处理流程,spring和springMVC的ApplicationContext的关系

springBean的生命周期,filter和intercept的区别,factorybean和beanfactory,
事务的传播机制与隔离级别,事务实现原理
6、网络编程
NIO,非阻塞IO,selector/channel/buffer,零拷贝,同步/异步、阻塞/非阻塞,
netty,基于nio封装的框架
thrift,
11、MySQL
在MySQL InnoDB中,UPDATE/INSERT/DELETE操作都会自动加排他锁,普通的SELECT语句不会加任何锁,称之为“非锁定读”,如果想加锁,可以使用下面方式:
SELECT * FROM table_name WHERE id = 1 LOCK IN SHARE MODE; -- 显式加共享锁 SELECT * FROM table_name WHERE id = 1 FOR UPDATE; -- 显式加排他锁
关系型数据库的隔离级别:
- Read uncommitted,读未提交,有脏读问题
- Read committed,读已提交,有不可重复读问题
- Repeatable read,可重复读,有幻读问题(mysql增加了间隙锁解决了幻读问题)
- Serializable,串行化,呵呵
InnoDB中的MVCC,在事务隔离级别为RC和RR的时候发挥作用,但它并不是真正的MVCC,准确的描述应该是“多版本并发读”,俗称“快照读”,在update/insert操作的时候MySQL会根据ROWKEY加锁,不管是哪个版本的行记录。
- 当事务隔离级别为RC时,非锁定读读取的是最新版本的快照记录,所以会有“不可重复读”问题;
- 当事务隔离级别为RR时,非锁定读读取的是小于等于当前事务版本的快照记录,不存在“不可重复读”问题。
join查询优化:
- 用小结果集驱动大结果集,尽量减少join语句中的Nested Loop的循环总次数;
- 优先优化Nested Loop的内层循环,因为内层循环是循环中执行次数最多的,每次循环提升很小的性能都能在整个循环中提升很大的性能;
- 对被驱动表的join字段上建立索引;
- 当被驱动表的join字段上无法建立索引的时候,设置足够的Join Buffer Size
12、Redis
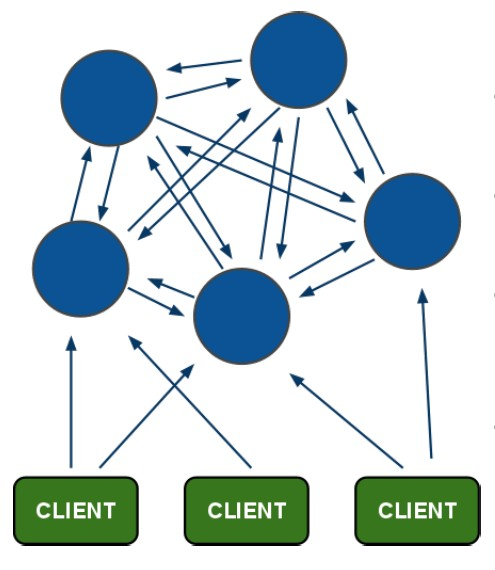
- Redis-Cluster采用无中心结构,由多台Redis服务器彼此互联组成集群,每个节点保存数据和整个集群的状态。节点分槽负责,只处理指定槽的读写请求。其中一台挂掉且没有slave的时候整个集群不可用,一半以上的master挂掉时整个集群也不可用(不管有没有slave)。
- 集群中的每个节点不仅负责指定槽的读写请求,还需要能够自动发现其他节点,检测节点的状态,并在需要时剔除故障节点,提升新的主节点。
- 客户端和集群中的节点直连,不需要中间的Proxy层,当然一个客户端只需要连接集群中任何一个可用节点即可,对于客户端的读写请求,当请求数据不在这个节点上时,节点会响应一个MOVE指令,让客户端重定向到正确的节点完成请求。
- 当集群需要扩展节点或者删除节点时集群会触发槽转移,节点间的数据复制时异步的,转移过程中会存在窗口期,可能会导致数据丢失。
- 对于写请求,每个节点都是单线程处理的,所以不存在线程安全问题,因为分槽负责,也不存在分布式事务(master和slave之间是通过被动复制实现数据同步的,slave会有有延时)。
- 过期键删除策略,懒删除+定期删除
- 持久化方式,AOF+RDB
13、Zookeeper
- zookeeper是一个分布式数据库,集群架构是一主多从,所有服务器存储同一份数据,数据全量存在内存中,定期往磁盘写快照和事务日志。
- 基于分布式系统的CAP理论,zookeeper保证了一致性(顺序一致性)和分区容错性(半数以上可用即可),虽然没有保证可用性,但提供了故障恢复机制(选举)。
- zookeeper的写过程,所有的写请求转发到leader服务器,由leader发起一个分布式写事务,广播到其他服务器,当leader收到半数以上的写成功反馈时发出事务提交命令,同时给客户端响应写成功。
- zookeeper的写操作是全局有序的(也是顺序一致性的前提),由64位的zxid来标识一个写事务,其中高32位表示当前leader的时代(类似于路易12,路易13....),低32位为自增序列。zxid很重要,是Leader选举的重要凭证。zxid还有一个作用,当某个服务器无法提供服务了,客户端会自动重连到其他服务器,选择其他服务器的一个原则是不能重连到zxid小于客户端已经历的zxid的服务器上。
- zookeeper中的数据以树状节点的形式组织,数据节点有持久节点和临时节点两种,临时节点在会话失效后即被删除。临时节点不允许有子节点。临时节点可以用来实现分布式锁。
- zookeeper的所有操作基于会话完成(TCP长连接),服务器维护会话信息,会话可以保证其上操作的顺序性。每个znode都有一个stat数据,记录了当期node的版本+子节点的版本+当前nodeACL的版本。对znode的并发修改是基于当前node的version,CAS更新保证线程安全的。
- znode还可以设置为有序节点,一个有序节点倍分配唯一一个单调递增的整数,序号追加到节点路径后面,如:/task/task1, /task/task2, /task/task3...。可以基于顺序节点实现全局唯一的ID(命名服务)。
- znode上注册的watch事件是单次有效的,若还要监听后续的事件需要反复注册(会有事件丢失问题)。watch监听的是事件而非数据。
- leader选举,当集群原有的leader不可用了,集群进入LOOKING状态,对外表现为集群不可用,所有follow开始投票选举新的leader,投票依据有两个,zxid(事务最新版本号)和myid(机器编号),优先选拥有最大zxid的follow为leader,如果zxid相同,选myid大的follow为leader,半数以上follow达成一致的投票后集群回到服务状态。
14、kafka
15、nginx
正向代理:vpn,代理的是客户端,安装在用户手机或者电脑上,与客户端在一起
反向代理:nginx,代理的是服务端,与服务端部署在一起,由服务端开发维护
nginx工作在Master-Worker模式下
- Master进程,读取并验证配置文件nginx.conf;管理worker进程;
- Worker进程,每一个Worker进程只维护一个线程,处理连接和请求;Worker进程的个数由配置文件决定。
- 热部署,修改配置文件nginx.conf后,master进程重新生成新的worker进程,新的请求必须都交给新的worker进程,至于老的worker进程,等把那些以前的请求处理完毕后,kill掉。
如何处理高并发请求,Nginx采用了Linux的epoll模型,epoll模型基于事件驱动机制,它可以监控多个事件是否准备完毕,如果OK,那么放入epoll队列中,这个过程是异步的。worker只需要从epoll队列循环处理即可。
16、开放式问题
- 秒杀系统的设计思路
- 分布式锁的设计思路
- 全局唯一ID的生成
- 短URL的生成思路
- 并发量、数据量提升100倍后的系统改进思路
