
对抗样本机器学习_Note1
对抗样本机器学习_Note1
简介
机器学习方法,如SVM,神经网络等,虽然在如图像分类等问题上已经outperform人类对同类问题的处理能力,但是也有其固有的缺陷,即我们的训练集喂的都是natural input,因此在正常情况下处理的比较好。然而如果我们想要对ML模型进行攻击的话,可以通过一定的手段生成对抗样本(adversarial examples),以图像为例,对抗样本在每个像素点只有微小的扰动(pertubations),因此对于人类的眼睛是无法分辨的,即生成前后我们人类还会将其归为同一类别。然而ML模型在面对这些对抗样本时会出现不鲁棒的特点,对它们会产生错分。对抗样本生成的基本思路是:在训练模型的过程中,我们把输入固定去调整参数,使得最后的结果能对应到相应的输入;而生成对抗样本时,我们将模型固定,通过调整输入,观察在哪个特征方向上只需要微小的扰动即可使得我们的模型给出我们想要的错分的分类结果。研究对抗样本机器学习的目的就是,希望我们的模型对于对抗样本更加robust。
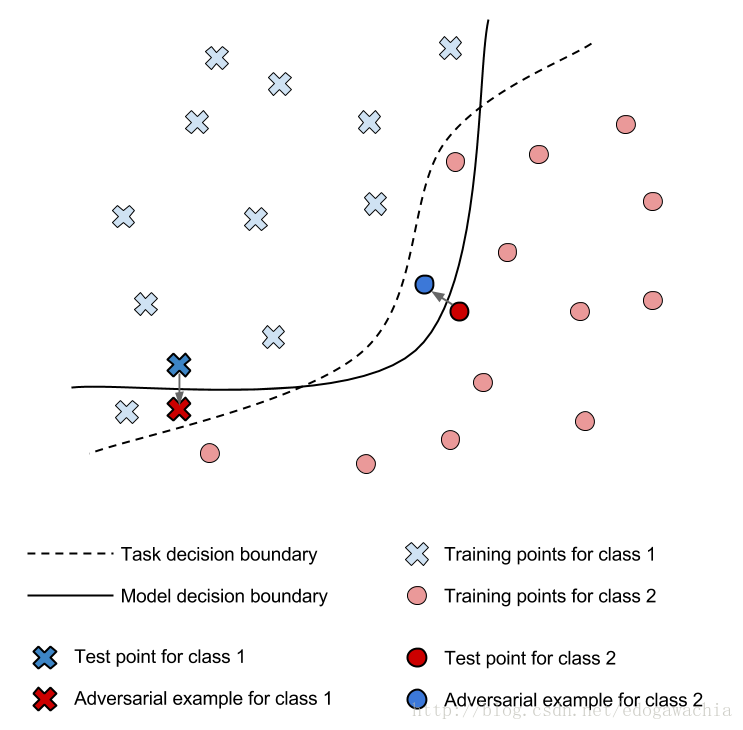
上图可以说明对抗样本是如何工作的。Model decision boundary 是我们训练的模型的分类边界,这个边界可以较好的将两类样本分开,但是如果我们对标出来的两个Test point 做一个微小的扰动,即可使其越过边界产生misclassification,因此我们的Task decision boundary就应当将这些对抗样本也分到其原本的类别。
对于这个问题,与普遍的安全问题类似,我们一般考虑两种角度,即attack和defense。其中attack试图更好的生成对抗样本以便使得分类结果符合attacker自己的预期;defense希望通过提高模型的鲁棒性,从而对这些adversarial examples 不敏感,从而抵御攻击。常见的attack方法,即生成对抗样本的方法有 fast gradient sign method (FGSM)和 Jacobian-based saliency map approach(JSMA)。如下图,生成的对抗样本中的扰动对人类视觉来说不敏感,但是对于ML模型来说,原本以57.7percent的概率被判成熊猫的图片在修改后以99.3的概率被判成了长臂猿。

对于defense,常见的方法有:
- Adversarial training:该方法思路非常平凡,即在训练网络的过程中,对每个图片都生成一些对抗样本,然后给他们与原图相同的标签喂给网络训练,从而使得网络相对来说对于对抗样本更鲁棒一些。开源的cleverhans即为用FGSM或JSMA生成对抗样本进行对抗训练的一个library。
- Defensive distillation:该方法用来smooth对抗样本进行扰动的方向的decision surface,Distillation(勉强译为 蒸馏?) 是Hinton大神提出来的一种用来使得小模型可以模仿大模型的方法,基本思路为,我们在训练分类模型的时候,输出来的时one-hot的向量,这种叫做hard label,用hard label对一个模型进行训练后,我们不仅仅保留softmax之后最大的概率的那一个维度,而是将整个概率向量作为label(小编个人感觉和label smoothing的思路有点像),这叫做soft label, 这样来说,每个输入样本不仅仅只有一个信息量较小的(因为对于分类结果太过确定,即该图片确定为该类别,其他类别完全无关)one-hot的向量,而是一个对每个类别都有一定概率的vector。这样由于训练网络,就会得到一些附加信息,如有一张图片可能在某两类之间比较难以分别,这样它们就会有较高的概率,这样的label实际上附带了大模型训练得到的信息,因此可以提高小模型的效果。(flag:以上为个人理解,之后阅读Hinton的参考论文)所谓的Defensive distillation即先训练用硬标签一个网络,然后得到软标签,并训练另一个网络(蒸馏网络),用蒸馏过的网络去分类就会对adversarial更加鲁棒。
一个失败的defense案例是 gradient masking,即直接输出类别而不是概率,使得没法通过gradient微小扰动图像,但是通过训练一个有gradient 的网络,在此基础上扰动,也可以attack经过该方法defense过的网络。
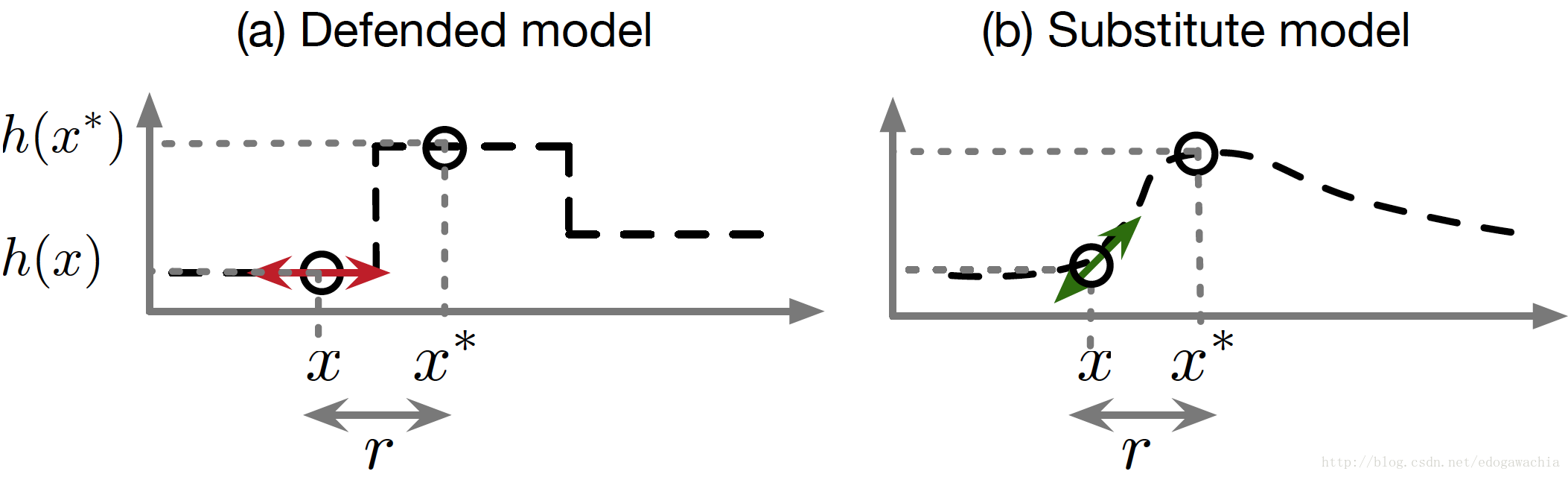
上图说明,即使defense使得gradient被掩盖,但是我们可以训练替代模型用来生成对抗样本。
相对于attack,机器学习的defense更难一些。因为缺少较好的theoratical model 来说明某种方法可以将某类对抗样本排除出去。
对于设计一个稳定可靠的系统来说,需要有testing和verification,所谓testing是指,在若干不同的条件下评估该系统,观察其在这些条件下的表现;而verification是指,给出一个有说服里的理由证明该系统在broad range of circumstances下都不会misbehave。仅仅testing是不够的,因为testing只给出了系统的失败率的一个下界,但是为了安全防护的目的,我们需要知道失败率的上界。但是对于机器学习的verification没法对对抗样本有一个guarantee,因此还很不完善。
reference:
cleverhans-blog : http://www.cleverhans.io/

