GAN相关:SRGAN,GAN在超分辨率中的应用
GAN相关:SRGAN,GAN在超分辨率中的应用
Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
Christian Ledig et al
abstract
用GAN做超分辨率是为了解决常规方法包括deep learning 方法的结果中缺少高频信息和fine details的缺点,而传统的deep CNN只能通过选择目标函数来改善这一缺陷。而GAN可以解决这个问题,得到perceptually satisfying的结果。
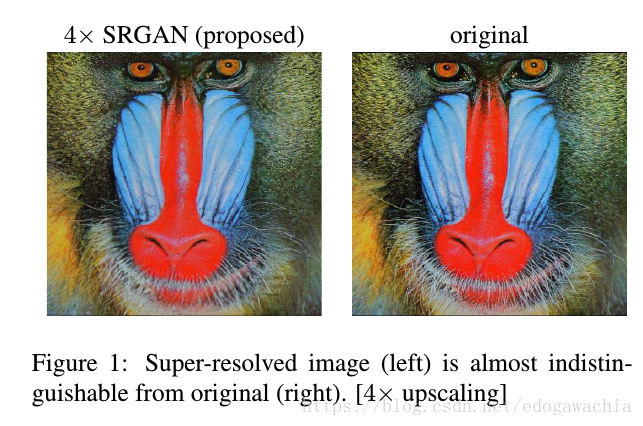
不得不说在细节方面确实还是很溜的。。。左边是SR四倍的结果,右边是原始高清图。
Intro
首先介绍了SR问题,传统的dl方法,由于是优化的mse,所以能够很方便的求解并且优化psnr(因为psnr就是根据mse直接计算出来的),所以在以psnr作为指标的时候表现较好,而实际上mse对于high texture details的约束是非常有限的,因此得到的结果对于细节忽视较为严重,如下图,而GAN可以避免这一问题。虽然psnr和ssim小一些(暗示着我们用GAN恢复出来的图像不是特别的准确(相对于真实图像而言,补充的细节虽然是细节,但是可能和真实的细节不同,比如下图中人物的头饰上的花纹,和脖子上的项圈,明显纹理结构比较单一,并且和实际不符,不过总归是有了细节,视觉感官上要更好一些。)),但是细节较丰富,这就是GAN做超分辨率的优势所在。

这里的模型用的是带skip-connection的ResNet,并且用了perceptual loss,把高阶特征的feature map也算进去,这里用的是vgg提取高层特征。
related work
首先是关于SR的传统和CNN方法,此处从略。
第二小节讲了CNN网络的设计。为了使得我们的映射可以更复杂从而提高准确性,我们需要更深的网络,因此提高深度网络的训练效率就是一个需要解决的问题,那么可以用BN层来counteract the internal co-variate shift。除此之外,另一个powerful design就是residual block或者说skip-connection。
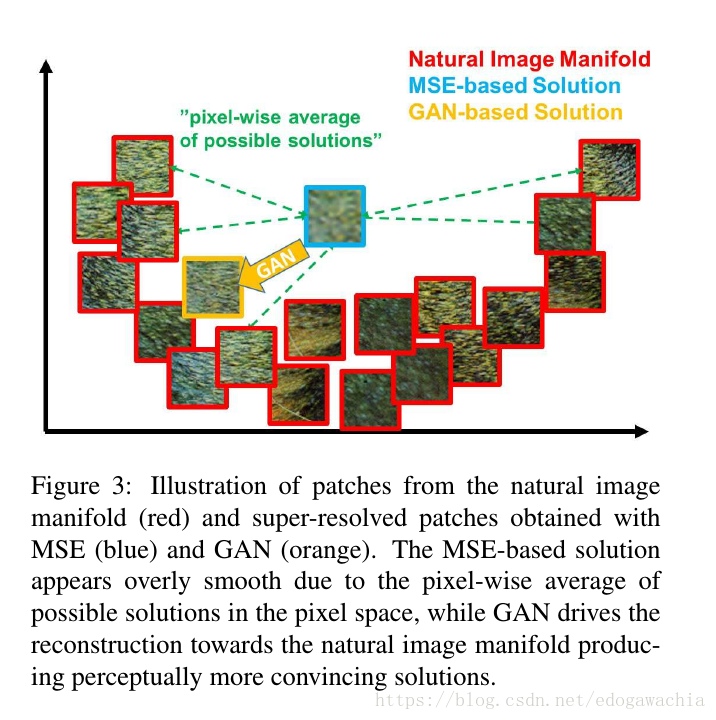
下面说的是loss function。传统的mse是对所有可能的取值,或者说不确定性,做一个平均,这样虽然可以使得mse变小,也就是psnr变大,但是在视觉上我们发现其实这是一种过度平滑,overly-smooth,下面图很好的展示了这一现象。
Dosovitskiy and Brox [12] use loss functions based on Euclidean distances computed in the feature space of neural networks in combination with adversarial training. It is shown that the proposed loss allows visually superior image generation。除了GAN loss 的优点以外,作者还介绍了上面这种,也就是在特征空间的相似性。除了上面【12】中的作者外,还有人用VGG来提取特征,并在特征空间用欧几里得距离做度量,思路是类似的。
method
GAN的好处就是可以提供 photo-realistic images 。网络结构:
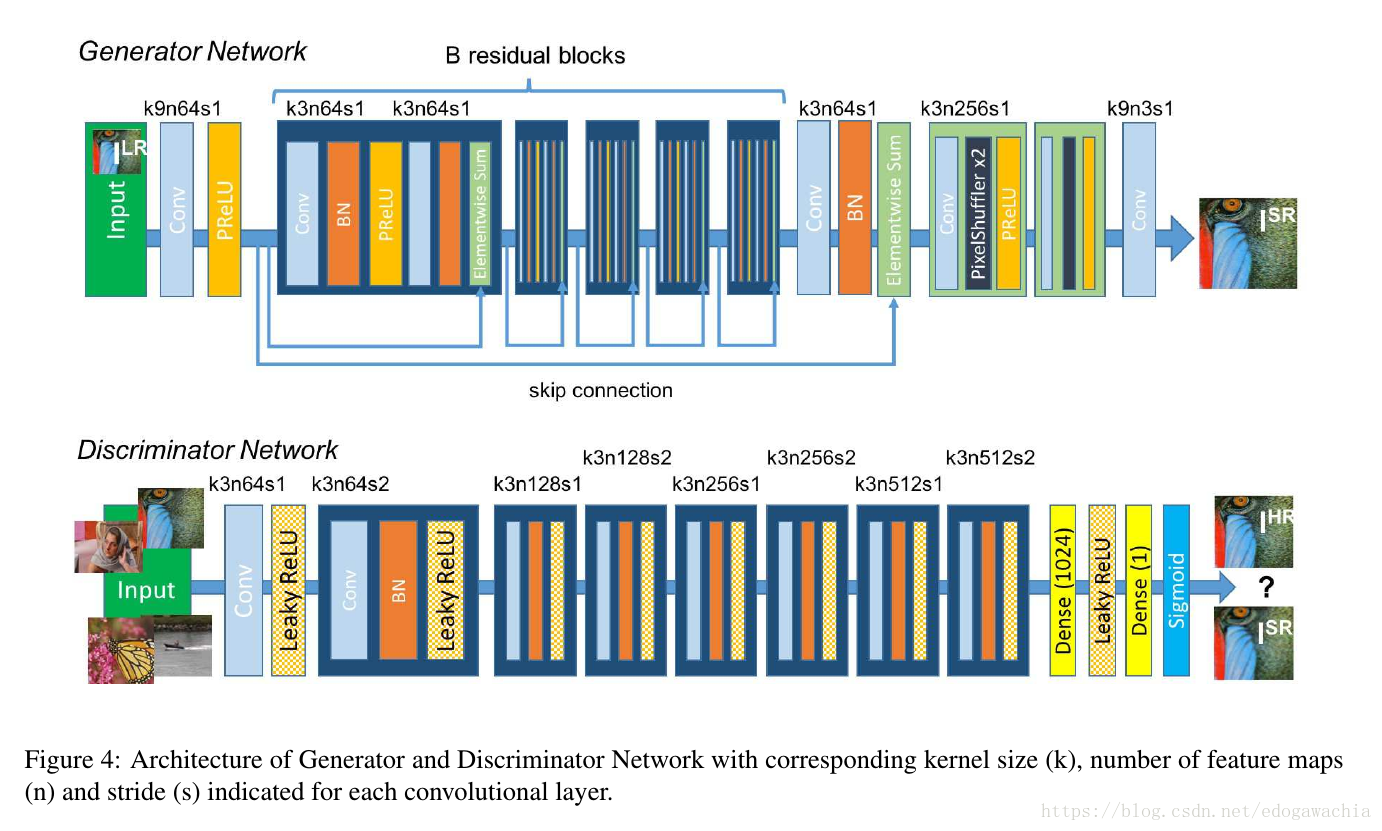
一般看来,GAN做图像任务的时候,通常都是采用pRelu,并且因为网络较深,采用BN层方便训练,以及都不用max-pooling,而是用strided的convolution来降低resolution并且把feature进行double。
下面这个是perceptual loss

里面提到,我们的loss是由content loss和Adversarial loss两部分组成的,用一定的权重进行加权和。这里Adversarial loss就是GAN loss,而content loss,内容的loss指的是vgg loss,也就是说在已经训练好的vgg上提出某一层的feature map,将生成的图像的这一个feature map和真实图像这一个map比较,从而使得他们在特征空间内也很像。Adversarial loss在这里是generative 的,所以没写I HR 的D的log损失。
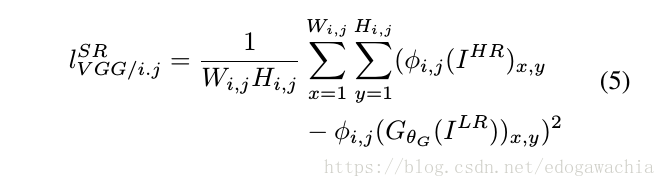
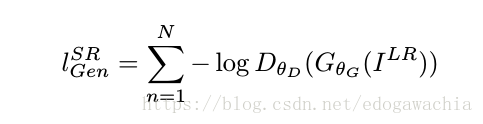
最后的实验结果用的是 mos testing,MOS,指的是 mean opinion score,平均意见评分,实际上是找了26个rater进行打分,得到的结果。
最后的结果可以看到,用SRGAN并且加上vgg54的content loss效果最好。这里的54指的是phi的index(phi就是前面的content loss 里的phi),分别代表这第i层conv+activation后,j层maxpooling前的feature。54表示高层,22表示低层。所以高层特征更有效一些。

最后的结论表明,该方法主要是摆脱了常用的以psnr作为measurement的方法的局限性。可以生成更加photo-realistic的图像。

2018年03月28日17:31:41
