
图像质量评价(IQA)论文笔记:Blind Image Quality Assessment via Deep Learning
IQA论文笔记:Blind Image Quality Assessment via Deep Learning
Weilong Hou et al
IEEE TRANSACTIONS ON NEURAL NETWORKS AND LEARNING SYSTEMS, VOL. 26, NO. 6, JUNE 2015
INTRO
对于IQA的label,也就是通常用来做回归的score,是由人主观打分得到的,但是数值的分数受个人因素影响较严重,比如对一个主观的个人来说,给一幅图片打分为70还是75实际上是一个很难抉择的问题,并且这样的分数也是irregular的。所以这种评价方式是非常 noisy and unreliable,噪声较多且不可信。
心理学表明人类更加偏向于qualitative(定性的)的评价而不是quantitative(定量的),定性的评价是通过自然语言实现的。所以作者认为,用excellent,good,bad等这样的自然语言定性的评价更加natural,并且更容易开展实验,而且可以减轻被试的负担,还能降低score的randomness,避免上面说的定量打分的缺点。
现在的主观评价实验有两种,一种是The absolute category rating,比如LIVE,IVC数据集;另一种是pairwise comparison,一般来说人们对图片质量进行排序比起单独对某张图片的质量进行打分要更easy一些。然后得到的结果再转成numerical rating,作为groundtruth。
In specific, this paper focuses on how to learn rules from qualitative description rather than comparison order。因为作者认为人们对于一张图片,并不需要对比,仅仅通过个人经验就可以判断出质量好坏。
这篇文章的一个思路就是bridge the gap between qualitatively labeled samples and numerical outputs。首先把BIQA问题作为一个5分类问题,五个分类分别表示五种心理状态:excellent,good,fair,poor,bad。输入图像用NSS特征表示。首先利用该表示将图片分类到5个grade,分类依据的是深度分类器得到的probabilistic confidence,然后在将label和他们对应的prob confidence转到numerical score。
framework的示意图如下:
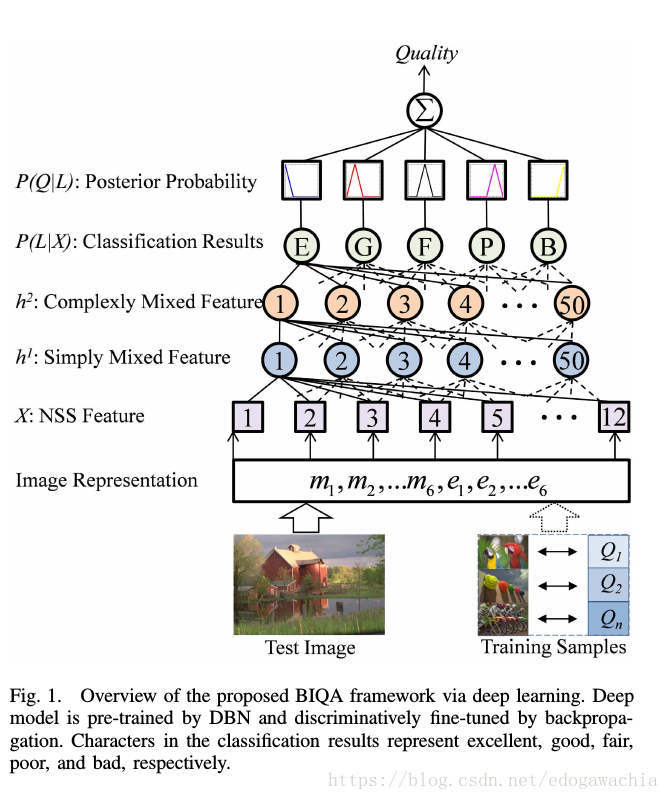
作者认为该模型有以下优点:Reasonability,因为用的是分类而不是回归模型,和现有的IQA scheme一致;以及effectiveness和efficiency,因为训练好以后,做预测速度很快;还有robustness,用分类提高了鲁棒性,解决了small sample size problem,用小样本即可训练得到较好的结果;comprehensiveness,是说模型的三个层面上给出了质量描述,因此易于解释。
RELATED WORK
之前的IQA问题模型通常都需要很强的假设,比如要预先知道distortion的类型,然后进行回归。后来的模型可以不需要分辨类型直接对分数进行回归。这些方法的缺点是不能充分的学到image和score之间的关系,而且unnatural,并且多数都需要大样本进行训练。
BIQA VIA DEEP LEARNING
主要有如下阶段:image representation;discriminative deep model;quality pooling。
image representation
首先是 image representation。一般来说,图像处理用CNN的话需要将图片切成patch,但是IQA问题中,score是针对整个图像的,因此不适合切块来做。但是不切块的话,直接投入整张图,那么维度太高,需要的训练集也应该较大,所以不适合直接投入,那么我们利用可以表征自然图像和畸变图像的差异的NSS feature作为输入。
NSS在小波域可以分成3 levels of property:primary,secondary和tertiary。
Primary properties give the wavelet coefficients of natural images significant statistical structure, such as locality and multiresolution. Secondary properties, which consist of non-Gaussianity and persistency, give rise to joint wavelet statistics. the tertiary properties show the self-similar property of scenes, of which the exponential decay across scales is the most significant property.
下面说明NSS feature是如何取得的:首先,将image做wavelet trans,然后把LH和HL不加区分,做三个scale,那么就得到了6个subband,对于每个subband,In each sub-band, the magnitude mk and the entropy ek are calculated according to :
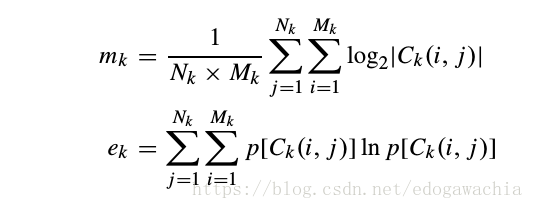
然后将所有这些子带的m和e放在一个向量里,用该向量表征图像

discriminative deep model
在论文模型中,用了一个四层的判别模型,输入就是上面的NSS特征向量,第二三层形成简单和复杂的混合特征,L层是分类结果,通过概率的置信度P(L|X)给出。输入12节点,隐层各50个,输出5个节点。
quality pooling
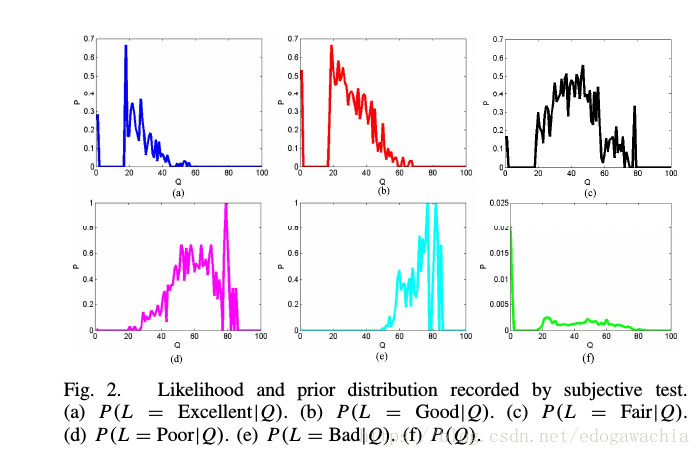
得到了五个级别的label 的概率置信度,其实可以直接根据五个概率的大小直接挑出最大的那个作为最后的评分。但是为了和其他的IQA方法比较,需要把label变成score,这里有如下假设:每个图片都有一个intrinsic的Q来表示其quality;每个well-trained 个人对于同样Q的图像每次给定label是constant恒定不变的。下图表示的是对于不同的内在的Q的图片,得到五个label的条件概率。这里的Q是通过DMOS得到的。
然后通过三角形分布函数和平均分布来模拟各个似然函数和先验分布:
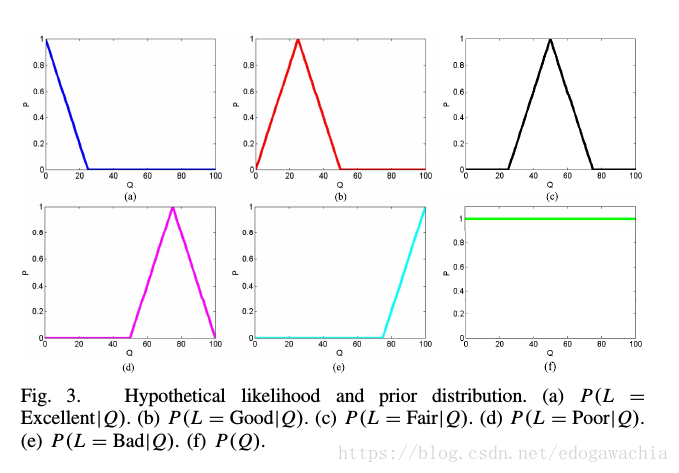
由于DBN网络输出的是给出5个label的概率,而给出某个label表示对Q有一个分布,就成了一个混合分布的问题,然后把5中可能的分布相加,得到最终的分数,也就是quality 的期望,作为最终的结果。这是一种非常Bayesian的方法。这里是概率方面的说明:

EXPERIMENTS
作者做了大量的实验,分析了一致性,泛化能力,敏感度,复杂度等等,并比较了运行速率。此略。
2018年04月12日17:23:51

