
classical CNN models : vgg 模型结构详解
VGG
相关文献
VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION
Karen Simonyan∗ & Andrew Zisserman+
http://arxiv.org/abs/1409.1556
vgg是作者所在的课题组的缩写,visual geometry group,视觉几何学小组。通常有vgg16和vgg19两种模型,16和19指的是网络的深度。由此可以看出,和之前的相比,该网络的深度大大增加,与之相适应,每一层的卷积核变小(3×3)。vgg模型的一个重要贡献就是强调了CNN网络中深度的重要性,从而使得神经网络朝着“深度学习”的方向发展。
vgg是2014年的ImageNet challenge的localisation的冠军和classification的亚军(冠军是googlenet)。下面简单说明一下该网络的一些特点。
网络结构
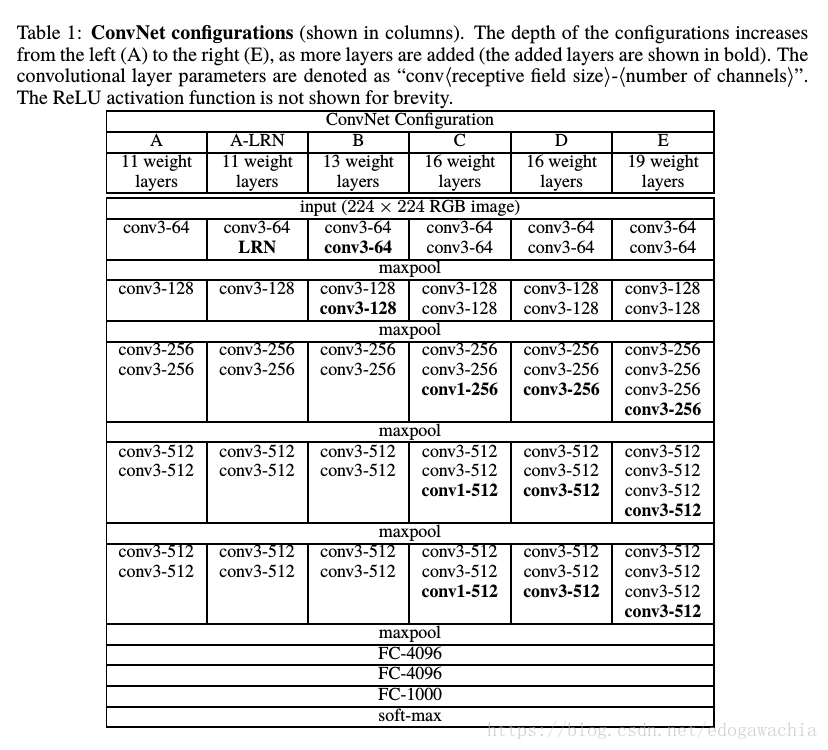
首先,关于训练的预处理,作者只对RGB图像做了一个去掉均值的操作,就直接投入训练,图片大小是224×224。网络的一些特点如下:
- 所有的kernel都是用小的receptive field,除了个别的1×1,都是3×3,代替了之前普遍使用的较大的卷积核。
- convolution 中的 stride 设置为1,并且做了padding,从而保持了分辨率,也就是feature map的尺寸
- 用了1×1的卷积核,相当于对通道之间做了一个线性变换,然后再通过非线性激活函数
- max pooling的方法做的池化,并且用2×2的区域,stride=2.
- 用了较多的卷积层,并设计了集中不同的结构,如上图所示
- 基本框架一样,若干卷积后一次池化,再卷积和池化重复,最后接了三个FC层,大小为4096,用softmax激活后输出。
细节阐释
首先是3×3的kernel size。用3×3的一个好处是可以提高效率,只要和深度结合,比如两层3×3就能达到5×5的感知域,同理,再加一层就是7×7。这样的方式比直接7×7效率更高。(btw,ZF中把11×11改成7×7并且减小了stride的一个原因是这样可以更好的保留信息。)考虑如果输入和输出都是有C个通道,那么3×3的卷积核有3×3×C×C个参数,三层的话就是27乘以C squared。而直接用7×7的话,参数量为7×7×C×C,也就是49乘以C squared。所以说小kernel加上深网络可以用较少的参数量达到与大kernel相当的效果。
另外是1×1的卷积核,这个是用来在不影响receptive fields的情形下,增加判决函数的非线性的操作。尽管1×1卷积核只是一个线性操作(相当于对不同的channel加权求和),但是后面接上激活函数可以引入非线性。1×1的卷积核操作在NiN(Network in Network)https://arxiv.org/abs/1312.4400v3 中有应用。
其他非网络结构的细节如下,主要是训练和测试中的一些trick:
首先,训练过程中,损失函数是softmax,也就是multinomial logistic regression的优化。下降方法用的是mini-batch的gradient descent with momentum。batch size设置为256,momentum 0.9。训练过程中的正则化包括weight decay(l2 penalty multiplier set to 5e-4),以及dropout,ratio设置为0.5。
另外,训练的图像大小问题,有两种方法。一种是给一个fixed scale,然后都resize成这个scale,另一种是给一个range,即Smin和Smax,然后随机抽取scale,这样也可以起到training set augmentation 的作用。
需要注意的是,分类问题的输入图像的处理方式和端到端的image-to-image,比如去噪或者去模糊之类的low level vision问题是有区别的。low level 的这些只需要训练时候patch固定,把kernel的weights学出来即可,然后通过调用这些卷积核,可以适用于任何尺寸的大小,实际上就是学习了一堆非线性的滤波器。而分类不同,它对于输入图像的尺寸不要求,任何大小的图像中的一只猫都会被分到猫的类别,所以可以放缩,并且为了保持object的形状不变,还必须长宽同比例的,也就是isotropical的放缩。一般来说是将短边放缩成一个固定的值,然后滑动窗口去取得patch。
对于训练这样好实现,因为S,即scale,输入图像的尺寸都被切成了固定的大小。但是对于测试来说,这里又一个技巧。
从最简单的考虑来说,我们可以把test image也resize成短边为S的图像,然后切成patch的大小,最后挨个分类,然后取平均。这样的过程比较繁琐。本文中采用了把FC层变成卷积层的策略,如下:
Namely, the fully-connected layers are first converted to convolutional layers (the first FC layer to a 7 × 7 conv. layer, the last two FC layers to 1 × 1 conv. layers). The resulting fully-convolutional net is then applied to the whole (uncropped) image. The result is a class score map with the number of channels equal to the number of classes, and a variable spatial resolution, dependent on the input image size. Finally, to obtain a fixed-size vector of class scores for the image, the class score map is spatially averaged (sum-pooled).
简单解释一下,比如我们在FC的前一层得到了一个7×7×64的feature map,那么我们需要flatten,然后连上全连接。这样的操作可以通过一个卷积操作来实现,实现方法就是用4096个大小为7×7的卷积核去卷积和这个fm,那么就会得到4096个1×1的fm,相当于一个4096的FC,然后进行后续处理。这样做的好处是,卷积是不管输入大小的,因此我们可以把整张图投进去测试,比如一个大一些的图,到了FC的前一层不是7×7×64,而是15×15×64,那么它通过4096个7×7的kernel后,会得到一个9×9×4096的fm,再继续下去, (the first FC layer to a 7 × 7 conv. layer, the last two FC layers to 1 × 1 conv. layers) 最终将得到一个9×9×1000的fm,这里实际上就标志着在test image 的81个位置切patch所得到的分类的softmax的概率向量是多少,因为我们要对整张图做判断,因此做一个sum pooling,也就是空域平均,即可得到整张图平均分类结果。这样便于计算。
结论
Our results yet again confirm the importance of depth in visual representations.
2018年04月18日15:10:12
人间的真话本就不多,一个女子的脸红胜过一大段对白。 —— 作家,老舍 【骆驼祥子】

