
classical CNN models : GoogLeNet 模型结构详解
GoogLeNet
相关文献:
Going Deeper with Convolutions
Christian Szegedy1, Wei Liu2, Yangqing Jia1, Pierre Sermanet1 , Scott Reed3,
Dragomir Anguelov1 , Dumitru Erhan1 , Vincent Vanhoucke1 , Andrew Rabinovich4
CVPR 2015
模型简介:
googlenet并没有采用之前的sequential的conv,pooling,fc这样的序列的结构,而是在串行中引入了并行操作,使得每个并行的操作都成为了一个模块,每个模块就叫做一个inception,每个inception里包含了不同大小的卷积核和池化层。因此具有更好的表达能力,并且为了在应用inception这种模块的时候降低运算量,引入了bottleneck机制。该模型是2014年的ImageNet的冠军。
模型结构
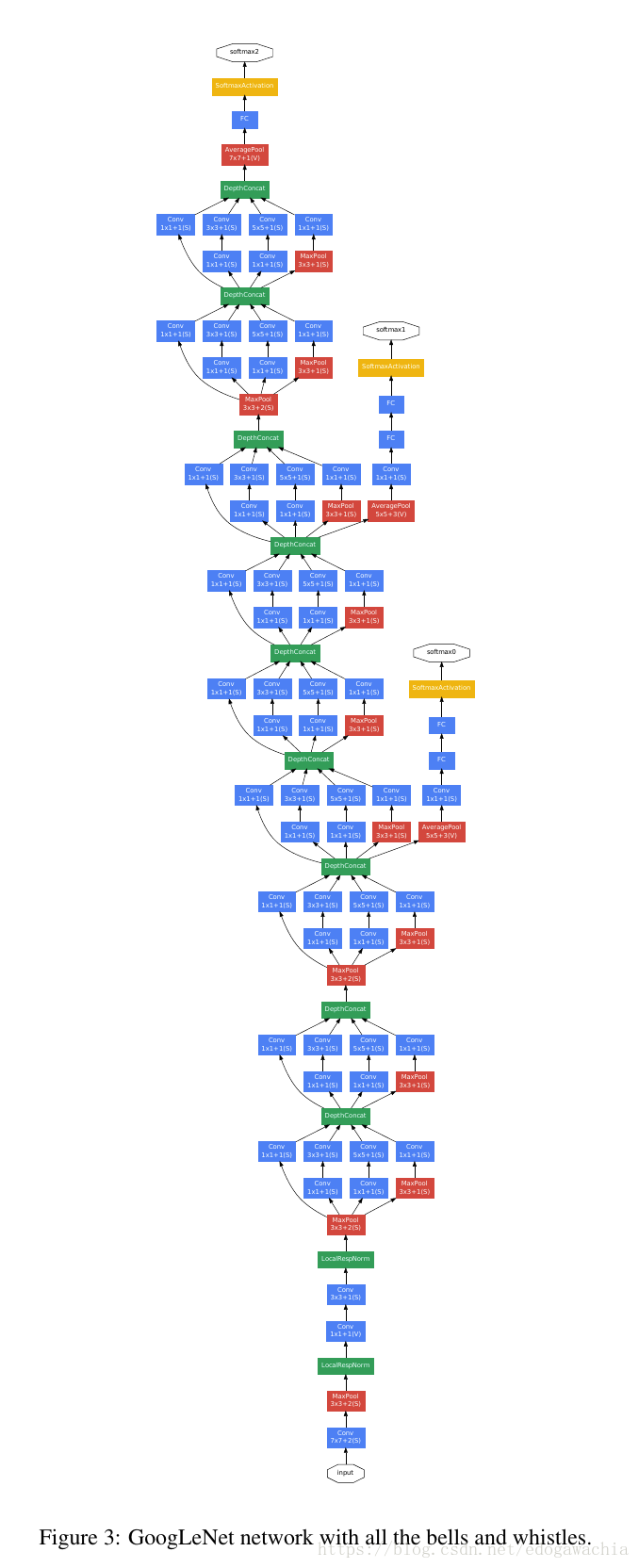
该结构基于Hebbian principle 和 multi-scale processing 的intuition。秉承 ‘we need to go deeper’ 的原则,在两方面进行了deep的改进,第一就是Inception module 的引入,另一个就是常规的网络深度的deepen。
Inspired by a neuroscience model of the primate visual cortex, Serre et al. [15] used a series of fixed Gabor filters of different sizes to handle multiple scales. We use a similar strategy here. However, contrary to the fixed 2-layer deep model of [15], all filters in the Inception architecture are learned. Furthermore, Inception layers are repeated many times, leading to a 22-layer deep model in the case of the GoogLeNet model.
inception 模型受到下面这个模型的影响,这个模型是用一系列的 gabor 滤波器来实现的多尺度的处理。
[15] T. Serre, L. Wolf, S. M. Bileschi, M. Riesenhuber, and T. Poggio. Robust object recognition with cortex-like mechanisms. IEEE Trans. Pattern Anal. Mach. Intell., 29(3):411–426, 2007.
不过 googlenet 中虽然也是多尺度,但是所有的滤波器都是学出来的。
另外,在NiN模型的启发下,引入了1×1的convolutional layers,一方面可以减少参数,从而打破计算瓶颈,从而可以将网络做的更大,另一方面也可以用来在不太降低performance的情况下增加网络的width。
utilizing low-level cues such as color and texture in order to generate object location proposals in a category-agnostic fashion and using CNN classifiers to identify object categories at those locations.
这里是受到R-CNN的启发,把问题分解为两个方面,一方面考虑low-level的cue在不区分类别的情况下找到location proposal,另一方面用分类器对这些位置上的对象种类进行识别。
Motivation and High Level Considerations
最直接的提高DNN的performance的方法就是增加它的体量。但是这也会导致一些问题,比如容易过拟合,为了避免过拟合,就要有特别多的labeled样本,但是标记很费人工。另一方面,还会导致计算量过大,难以承受。
一个解决这一问题的理论工作给出了一个结论:如果一个数据集的概率分布可以被一个很大的稀疏的DNN来表征的话,那么最优的网络拓扑结构可以通过如下方法逐层生成,即分析前面的layer的activation的correlation,把那些高度相关的神经元聚类起来。实际上这个和Hebb规则很像(hebb规则:neurons that fire together,wire together)
Architectural Details
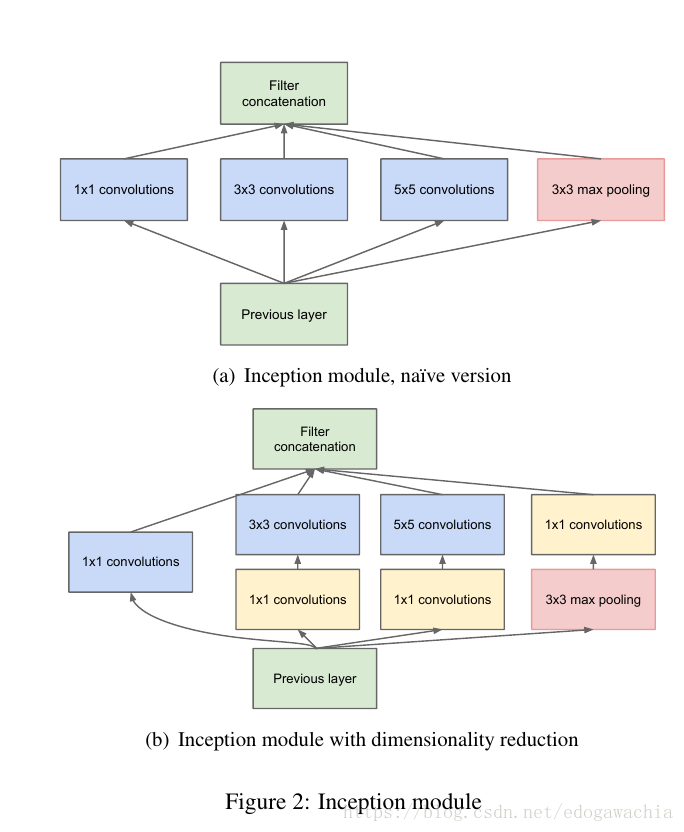
上面展示了inception的结构,a图是最基础的构思,就是把上一层用1,3,5三个尺寸的卷积层操作,加上一个3的max pooling,最后concat起来。但是直接这样操作会产生大量的参数,因此考虑引入bottleneck结构,也就是在卷积操作前先对fm的个数做一个缩减,1×1的conv之前介绍过,实际上就是在不改变局部信息的前提下对通道间做一个线性加权处理(如果接了activation就是非线性),这样可以通过选择1×1卷积后的fm的数量来进行fm 的 channel的降维操作,从而降低计算量。除了降低计算量,they also include the use of rectified linear activation making them dual-purpose。
Furthermore, the design follows the practical intuition that visual information should be processed at various scales and then aggregated so that the next stage can abstract features from the different scales simultaneously.
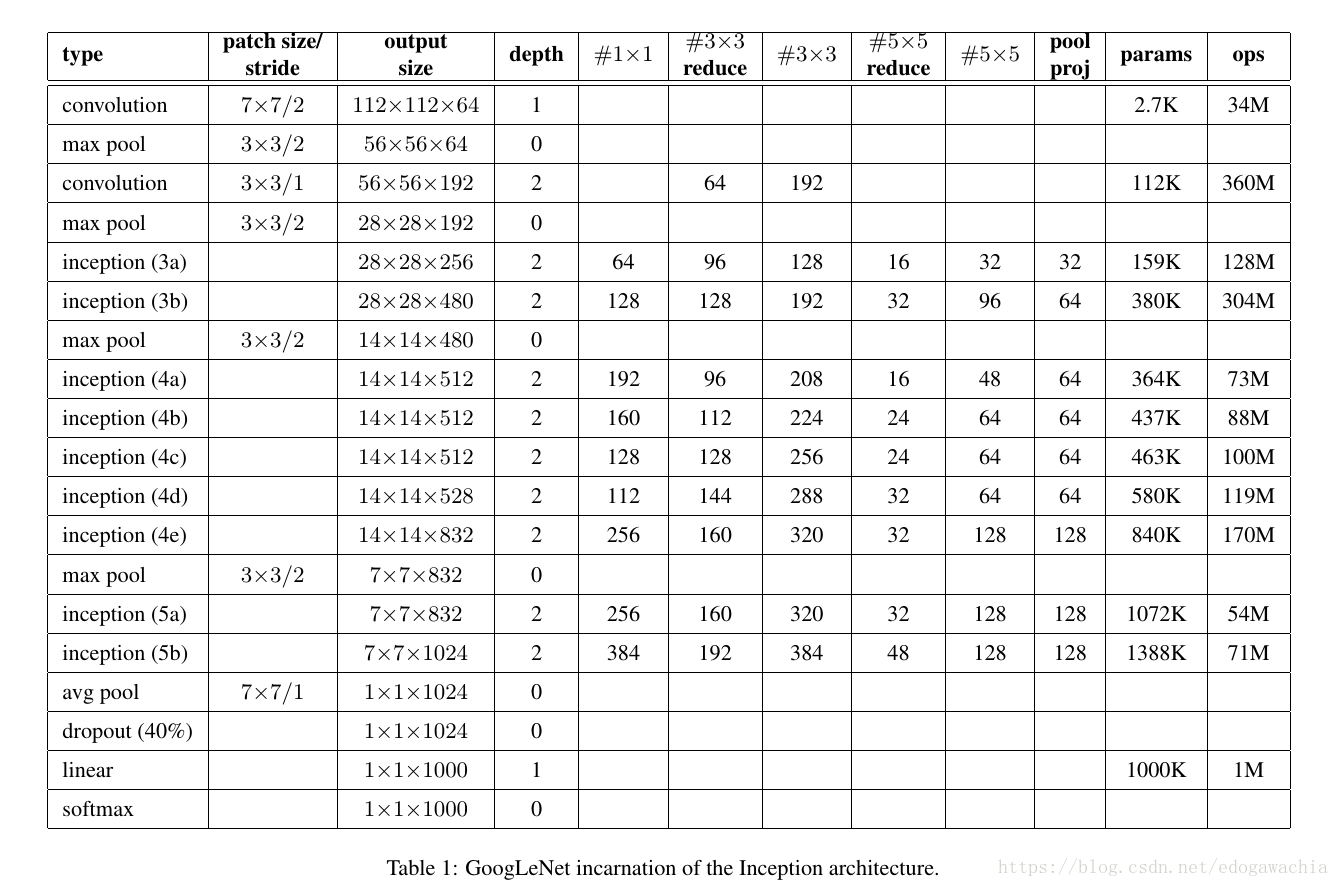
GoogLeNet的一个incarnation如下所示:
结论
Still, our approach yields solid evidence that moving to sparser architectures is feasible and useful idea in general. This suggest future work towards creating sparser and more refined structures in automated ways on the basis of [2], as well as on applying the insights of the Inception architecture to other domains.
说明模拟一个最优的稀疏结构的方法(也就是这里提到的【2】中的理论方法)是可行的,并且可以探索其他稀疏表征方法,或者把inception用在其他领域。
[2] S. Arora, A. Bhaskara, R. Ge, and T. Ma. Provable bounds for learning some deep representations. CoRR,
abs/1310.6343, 2013.
2018年04月18日18:54:51

