
dropout :深度学习中的正则化
dropout :深度学习中的正则化
参考文献:
Dropout: A Simple Way to Prevent Neural Networks from Overfitting
Nitish Srivastava
Geoffrey Hinton
Alex Krizhevsky
Ilya Sutskever
Ruslan Salakhutdinov
Editor: Yoshua Bengio
dropout 原理简介
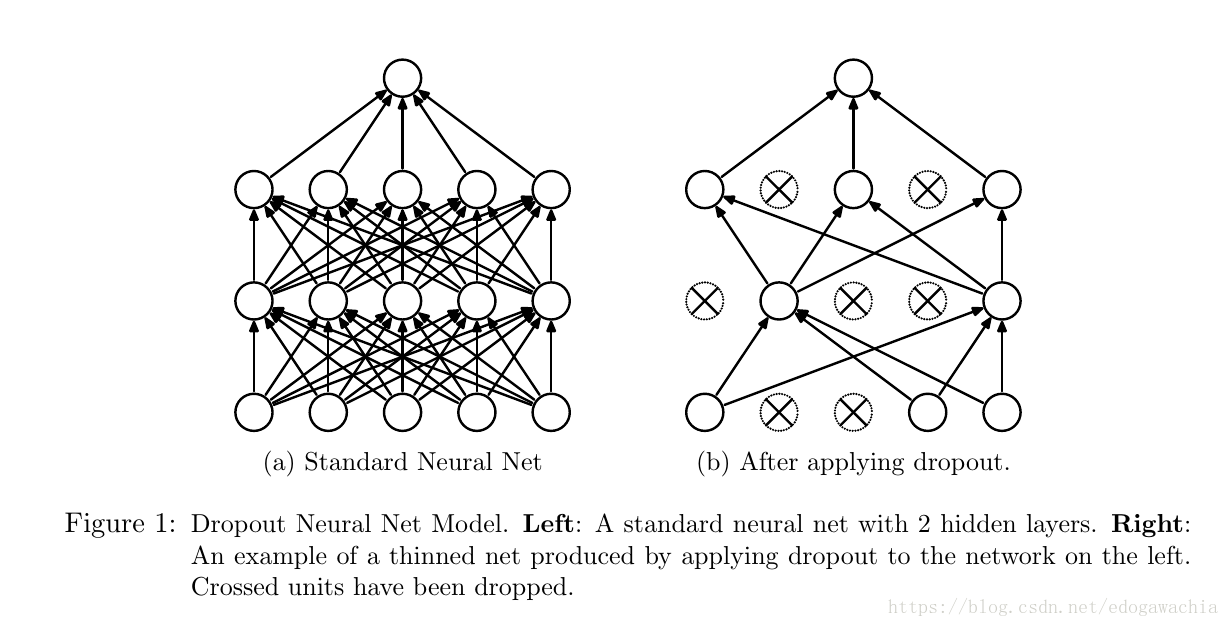
dropout是Hinton组发明的一种可以用来做神经网络的正则化约束的一种技术,可以防止网络过拟合。
深度网络通常会对训练样本过拟合,为了应对过拟合的问题,通常采用的方法有early stopping,早停,即在验证集上开始变坏之前就立即停止训练,从而防止外推性变差。或者采用各种形式的weight penalty,也就是对权重的约束,通常来说就是l1,l2正则化,以及 soft weight sharing (Nowlan and Hinton, 1992)。
如果不考虑计算量的话,最好的正则化方法就是训练固定规模的model,然后做平均,对于小模型这是简单可行的,但是这里作者希望将它用较少的计算量应用到模型中,这里作者说We propose to do this by approximating an equally weighted geometric mean of the predictions of an exponential number of learned models that share parameters。也就是说,dropout可以得到共享权重的指数级数量的模型,并且做平均。
当然,直接对神经网络做训练,并把每个的结果进行平均是一件工作量很大的事情,因此不能直接采用对network进行ensemble,而是通过dropout的方法来进行。所谓dropout指的是在神经网络中drop丢弃掉一些units,也就是把这些单元以及流入它和流出它的连接一并从神经网络中暂时移除,如上图所示,这种drop是随机的,一般是对每个unit都设置为按照一定概率p得到保留,这里的p可以根据validation上的表现选择,或者直接选为0.5即可解决很多任务,这是对于隐层,对于输入的dropout,一般p要接近1,也就是比隐层节点保留的更多。
对于一个n节点的network,这样的方法可以生成2的n次方个thinned network,因为每个节点都有两种状态,故2的n次方。但是由于权重是共享的,因此参数量没有增多。对于训练过程中,先sample出一个thin网络,然后对它训练。在测试的时候,将p乘以网络的节点, The weights of this network are scaled-down versions of the trained weights.这样就可以保证,对于每个节点,输出的期望和test时的真实输出相等。
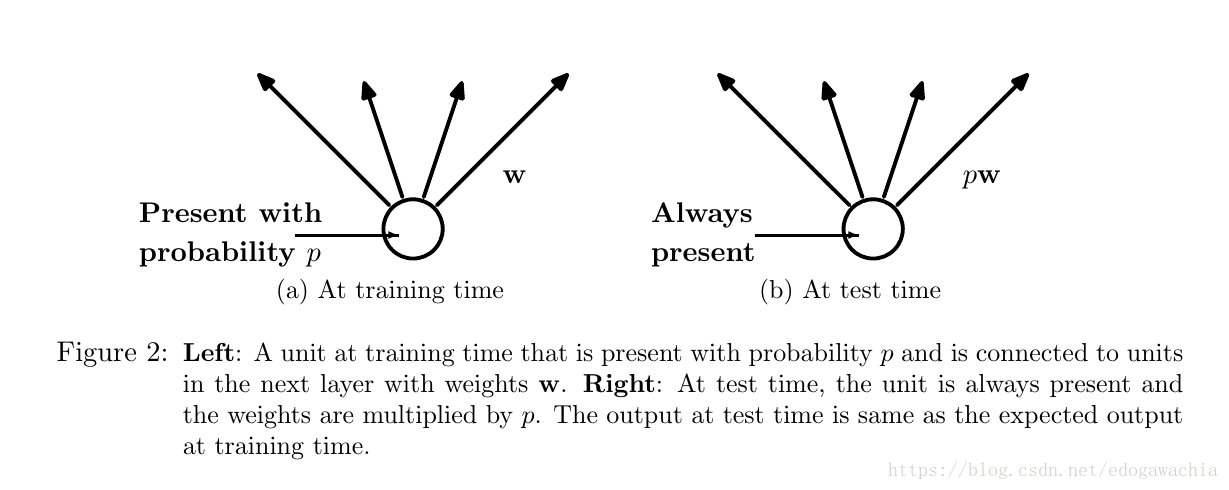
用dropout作为正则,比其他的正则处理在泛化性能上表现要好很多。
motivation
这里作者举了一个栗子来说明这个问题,或者说是dropout的idea产生的一个动机。这个动机就是对进化过程中有性繁殖的作用的理解。按理说,如果把进化视为一个优化过程的话,那么,直观上来说,无性生殖应该更有优势才对,因为无性生殖的物种可以基本上把父辈所有的基因内容都保存下来,而这些基因是父辈优化好的结果,因此这样一直下去的话,应该会越来越优。但是事实上不是如此,反而是有性生殖更高级。看上去有性生殖似乎打乱了已优化好的内容,从而降低的性能,但是实际上,有性繁殖似乎可以打破基因组之间的co-adaptation,也就是相互的以来和协作,使得每个基因组尽量少依赖其他基因组,而是自己学习到某些适应性,从而提高了鲁棒性。
另外一个栗子是,如果有50个反贼想要制造暴动,那么分成10组每组5人要比50人集中起来更容易成功(游击战的力量(滑稽))。当然,如果情况很固定,并且演练时间很长,那么大组50人可以工作的较好,但是如果环境变化较大,那么前者自然就更好了。在训练数据的过程中,复杂的协作co-adaptation可以在训练集中训练的很好,就好比50个人提前的排练,但是在test中可能会有很多新的数据,在这些数据上这种复杂的就不如简单的多数组了。
related work
一个类似的工作是DAE,去噪自编码网络。DAE里也应用了在神经元中加入噪声(dropout实际上也可以视为在隐变量单元中加噪声)。
模型的实现
无dropout:
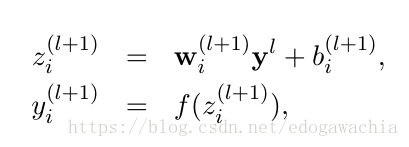
有dropout:
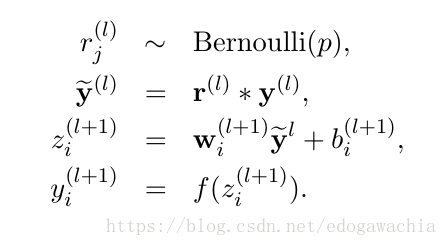

dropout模型的实现很简单,就是在神经元向下一级连接之前先生成一个随机数,服从bernoulli分布,参数为p,然后将生成的0和1组成的向量和上一级神经元输出的结果进行Hadarma乘积,然后作为下一层的输入。
模型学到的特征

上面是MNIST上的autoencoder学出来的特征,明显可以看出,加上dropout之后学到的特征更加独立,更少co-adaptation,虽然都能很好的重建,但是dropout学出来的特征可以期望一个较好的泛化能力。
为什么dropout可以破坏co-adaptation?一个解释是这样的:在我们对参数求导,也就是BP的时候,每个参数求偏导数相当于把其他的参数看做固定的,然后改变这个参数使得loss降低。但是这个loss可能是很多参数的不合适共同导致的,因此也就是说,我们的某个参数的调整可能在fix up其他神经节点的错误,因此会造成神经节点间的互作。dropout就减少了这一现象发生。(实际上从原理上讲dropout就是多个小网络的集成)
其它
还提到了训练策略,比如在sgd的基础上加上max norm regularization ,将weight的norm限制在某个常数c中。另外,还可以利用无监督的pretrain预训练,这里注意pretrain得到的weight在用dropout之前先要做一个scale ,系数为1/p,这样保证在dropout的网络训练时的神经元的期望输出和预训练出来的一样。
2018年04月21日21:37:31
清晰明确也未必就代表真相。 —— 编剧,作家 迈克尔·翁达杰 【安尼尔的鬼魂】

