Batch Normalization :深度网络中的BN层
Batch Normalization :深度网络中的BN层
参考文献:
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Sergey Ioffe
Google Inc., sioffe@google.com
Christian Szegedy
Google Inc., szegedy@google.com
Internal Covariate Shift 问题
在训练神经网络的过程中,实际上我们希望网络学习的是输入数据的分布特征,但是由于深度网络中每一层的输入都是前一层的输出,而前一层的参数是随着学习变化的,这就导致它的输出也随之改变,这种分布的不稳定导致训练深度网络较为困难(训练困难的意思就是说,可能需要很小心地设置初值,并且给一个很小的学习率,从而效率变慢),特别是对于有饱和现象的非线性激活函数,比如sigmoid,tanh等等,如果分布的变化过程中落到了饱和区域,那么就会很难继续下降。这种现象被称为:Internal covariate shift,内部协方差漂移。BN操作就是为了解决这一问题而产生的。
mini-batch SGD
在做梯度下降的时候,通常SGD效果表现较好,包括SGD的一些变种,比如momentum,Adagrad都取得了SOTA的效果。SGD是minimize所有训练样本上的loss的平均值,或者同样的,loss的和,但是在训练时候常常不会直接把所有的样本投喂进去训练,而是把大小为N的样本分成多个大小为m的mini-batch,然后顺次将mini-batch投入训练,这里,用minibatch上的对参数的导数来代替全体样本的导数,也就是梯度,然后按照这个梯度进行下降。这样的好处是,一方面比一个个训练要快,另一方面,在一个batch上的grad可以看做是整体的一个estimate。
但是sgd调节超参数很麻烦,而且由于每层的输入都是要收到前面的层影响,因此前面的参数的每一点微小的改变都会随着网络层数的加深被逐渐放大,最终影响分布。
考虑一个两层的网络:

可以发现,如果把第一层的输出记为x,那么第二层的梯度只和x直接相关,因此可以看成一个独立的子网络,这个网络输入就是x。我们一般希望对于一个网络的训练来说,训练和测试具有相同的分布,那么这一点对于这个子网络也同样适用。
如果对于sigmoid函数做激活的话,如果落在饱和区域,那么就会有梯度消失的现象。而且网络越深越明显。如果我们能让非线性的输入更稳定,那么就会更好训练网络,并且更快的收敛。
normalization via mini-batch statistics
The first is that instead of whitening the features in layer inputs and outputs jointly, we willnormalize each scalar feature independently, by making it have the mean of zero and the variance of 1.
Batch Normalizing Transform

其中,均值和方差是通过minibatch里的数据统计计算得出的,而gamma和beta,也就是scale和shift是可以学习的。然后,作者说明了BN层是可导的。

trainning & inference
上面是训练的情况,那么inference的时候没有batch,因此BN Transform前两步骤求mu和sigma就不能做,此时的解决方法就是:用训练集上的每个mini-batch的平均值和方差求期望,并计算出无偏估计量(对均值就是样本均值,对方差要乘以m/(m-1)的系数)。
具体做法如下:

对于convolutional network的BN层
对于卷积层,记每个batch大小为m,feature map为多个p×q,那么希望对m个batch中的数据对应的fm中的每个位置相同的点做归一化,For convolutional layers, we additionally want the normalization to obey the convolutional property – so that different elements of the same feature map, at different locations, are normalized in the same way.
BN层的作用
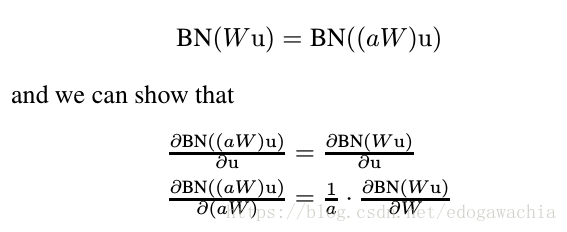
上面可以看出,Moreover, larger weights lead to smaller gradients, and Batch Normalization will stabilize the parameter growth.
BN层可以用更大的学习率 lr,也可以看做是对模型的一个规范化(所以有了BN层可以取消或者减轻dropout的使用)。
BN层的加速
- 增大学习率
- 去掉dropout
- 减少 l2 权重正则化
- 加速学习率衰减
- 去掉LRN层(局部相应归一化)
- 更彻底打乱训练样本
- 减少光度的畸变(因为batch normalization训练速度更快,所以看到训练样本更少,因此希望让它更关注真实样本)
2018年04月22日16:58:55
将人间变成地狱的原因,恰恰是人们试图将其变成天堂。 —— 诗人,荷尔德林 【塔楼之诗】
