
Application of Opposition-Based Reinforcement Learning in Image Segmentation
论文笔记:Application of Opposition-Based Reinforcement Learning in Image Segmentation
这是一个番外篇的论文笔记。了解一下强化学习(RL)在图像方面可以有那些应用的切入点。
Application of Opposition-Based Reinforcement Learning in Image Segmentation
Farhang Sahba1’3, Hamid R. Tizhooshl’3, Magdy M. M. A. Salama2
这篇文章是用RL的方法做图像分割。The main purpose of this work is to demonstrate the ability that a reinforcement learning agent can be trained using a very limited number of samples and also can gain extra knowledge during the segmentation process. This is a major advantage in contrast to other approaches (like supervised methods) which either need a large training set or significant amount of expert or apriori knowledge. RL方法的优点在于可以用较少的样本来进行训练,并且能得到额外的知识,而监督学习通常需要较大的训练集。而所谓的oppsition-based 方法是为了解决 difficult to derive the state-action information especially when we need to store past experiences 而采取的一种加速算法。下面主要就是先介绍reinforcement learning的相关知识,以及opposition-based相关,以及本文的方法。
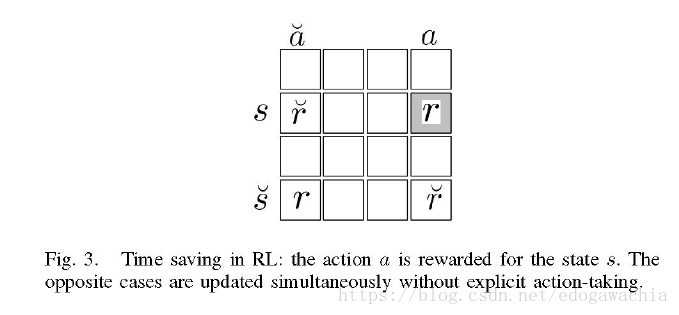
opposition based theory 用来优化 Q-learning,基本思路就是对于state和action,在做一次动作以后,找到s 的对跖点,和a的对跖点,这样就形成四个组合,也就是说,在只采取一步的行动,就能个更新四个点,于是原则上得到了四倍的效率。用Q-learning的话就是对Q-matrix的操作。
算法流程如下所示:

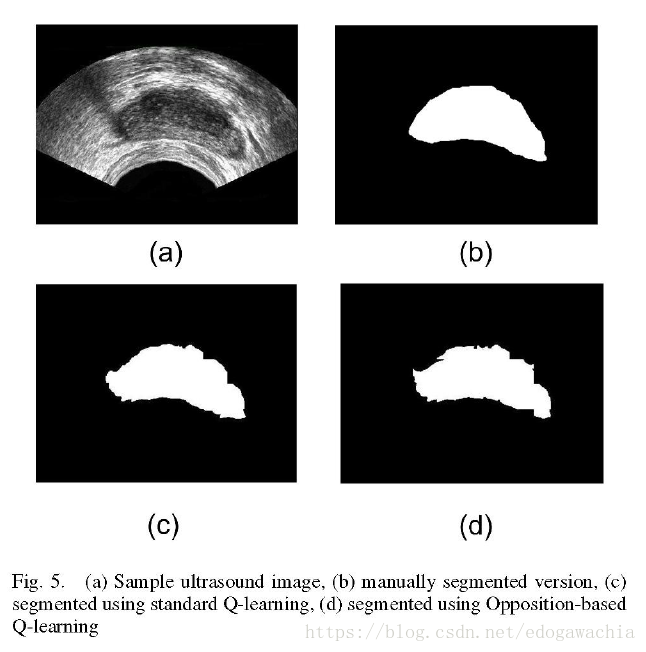
这个算法在切分之后有artifacts, 所以要用形态学开运算进行一下后处理。The reinforcement learning agent determines the local thresholding value and the size of structuring element for each individual sub-image. 也就是说,这个RL策略是用来选择local threshold以及形态学结构元的尺寸。
框图如下:
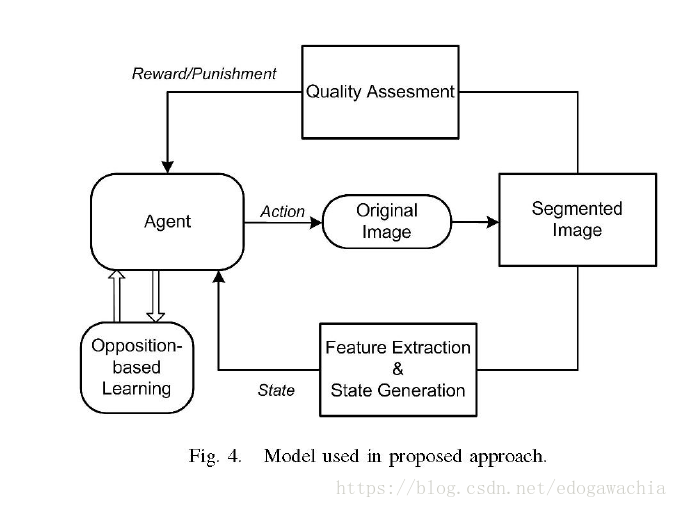
下面就是定义states, actions 和reward/punishment。states就是图像的状态,也就是可以反映出图像质量的一些参数:

而actions就是阈值和结构元大小,都被在某个范围内离散化了,因此就是固定的选取某个参数组合,然后看看效果好坏,给出一个reward,依次下去,从而找到最优解。
2018年06月19日17:07:59
太阳每天都是新的,而且会永远常新。 —— 哲学家,赫拉克利特

 浙公网安备 33010602011771号
浙公网安备 33010602011771号