


机器学习中的度量指标:ROC曲线,AUC值,K-S曲线
机器学习中的度量指标:ROC曲线,AUC值,K-S曲线
首先,回顾一下二分类问题的一些定义:
预测 1 0
实 1 TP FN
际 0 FP TN
上表中,四个项分别为:TP真阳性;FN假阴性;FP假阳性;TN真阴性
注意,真假表示预测的对错,后面的阳性和阴性表示预测结果,因此结合预测结果和预测结果的对错,可以知道对应的实际结果是什么。比如FN假阴性,预测为阴性,但是预测结果为假,所以真实答案应该是个阳性。预示对应第一行第二列。
下面介绍几个定义:
sensitivity:灵敏度,定义是TP/P = TP/(TP+FN),等价于召回率(recall)。表示真正例中有多少被召回了。
specificity:特异度,定义为TN/N = TN/(TN+FP),表示真阴性里面有多少被检出了。
1-sensitivity:FN/(TP+FN),说的是阳性中有多少被误判成了阴性,也就是漏检,或者说是Type II error
1-specificity:FP/(FP+TN),说的是阴性里有多少被当成了阳性,也就是虚警,就是Type I error
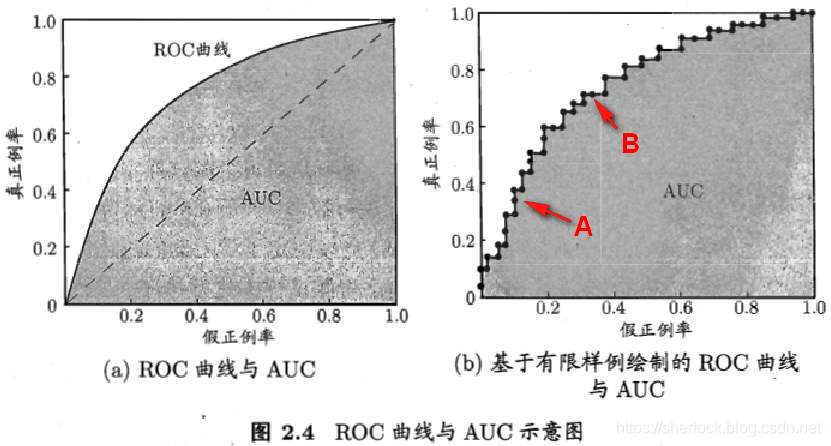
ROC曲线的定义和AUC值
ROC(Receiver Operating Characteristic)曲线横轴为虚警,纵轴是召回(灵敏度)。这一点可以这样理解:为了尽可能多的召回,最极端的方式就是把所有的都报告成阳性,但是这样一来,虚警就会变多。随着虚警的变多,召回的情况也越来越好,我们希望的是,尽量在虚警很低的时候,正样本都能尽可能全部被召回。因此,ROC下面围成的面积越大越好,这个面积就是AUC(Area Under Curve),翻译过来就是『曲线底下的面积』,非常简单直接粗暴。
K-S曲线
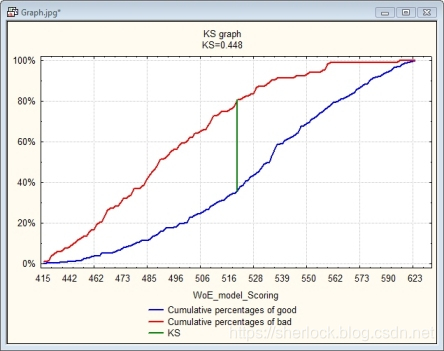
K-S曲线实际上就是把阈值作为横坐标,TPR和FPR,也就是召回率和虚警率,其实也就是ROC曲线的那两个变量,同时作为纵坐标,随着阈值的变化,召回和虚警都从0到1,这时候,两者距离最远的地方就是KS值。代表在某个阈值的时候,召回和虚警差距最大,也就意味着能用最少的虚警换来最多的召回,这个位置是我们需要的阈值。
其实可以想象一下,把虚警那条曲线拉直,然后让召回随着虚警也对应地变化,那么得到的其实就是ROC曲线。
2019-07-31 21:17:17
用科技让复杂的世界更简单。

