MySQL高级知识(十)——批量插入数据脚本
前言:使用脚本进行大数据量的批量插入,对特定情况下测试数据集的建立非常有用。
0.准备
#1.创建tb_dept_bigdata(部门表)。
create table tb_dept_bigdata(
id int unsigned primary key auto_increment,
deptno mediumint unsigned not null default 0,
dname varchar(20) not null default '',
loc varchar(13) not null default ''
)engine=innodb default charset=utf8;
#2.创建tb_emp_bigdata(员工表)。
create table tb_emp_bigdata(
id int unsigned primary key auto_increment,
empno mediumint unsigned not null default 0,/*编号*/
empname varchar(20) not null default '',/*名字*/
job varchar(9) not null default '',/*工作*/
mgr mediumint unsigned not null default 0,/*上级编号*/
hiredate date not null,/*入职时间*/
sal decimal(7,2) not null,/*薪水*/
comm decimal(7,2) not null,/*红利*/
deptno mediumint unsigned not null default 0 /*部门编号*/
)engine=innodb default charset=utf8;
#3.开启log_bin_trust_function_creators参数。
由于在创建函数时,可能会报:This function has none of DETERMINISTIC.....因此我们需开启函数创建的信任功能。
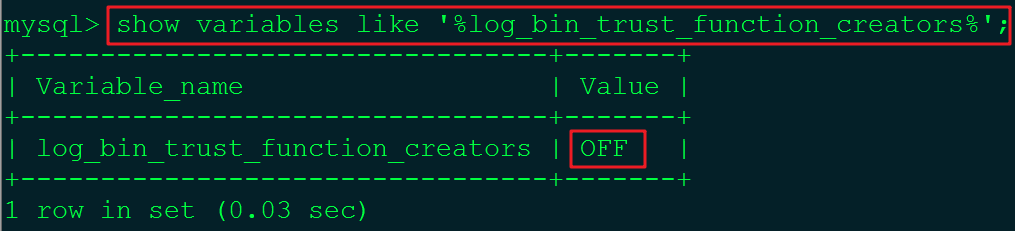
可通过set global log_bin_trust_function_creators=1的形式开启该功能,也可通过在my.cnf中永久配置的方式开启该功能,在[mysqld]下配置log_bin_trust_function_creators=1。
1.创建函数,保证每条数据都不同
#1.创建随机生成字符串的函数。
delimiter $$
drop function if exists rand_string;
create function rand_string(n int) returns varchar(255)
begin
declare chars_str varchar(52) default 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ';
declare return_str varchar(255) default '';
declare i int default 0;
while i<n do
set return_str=concat(return_str,substring(chars_str,floor(1+rand()*52),1));
set i=i+1;
end while;
return return_str;
end $$
#2.创建随机生成编号的函数。
delimiter $$
drop function if exists rand_num;
create function rand_num() returns int(5)
begin
declare i int default 0;
set i=floor(100+rand()*100);
return i;
end $$
2.创建存储过程用于批量插入数据
#1.创建往tb_dept_bigdata表中插入数据的存储过程。
delimiter $$
drop procedure if exists insert_dept;
create procedure insert_dept(in start int(10),in max_num int(10))
begin
declare i int default 0;
set autocommit=0;
repeat
set i=i+1;
insert into tb_dept_bigdata (deptno,dname,loc) values(rand_num(),rand_string(10),rand_string(8));
until i=max_num
end repeat;
commit;
end $$
#2.创建往tb_emp_bigdata表中插入数据的存储过程。
delimiter $$
drop procedure if exists insert_emp;
create procedure insert_emp(in start int(10),in max_num int(10))
begin
declare i int default 0;
set autocommit=0;
repeat
set i=i+1;
insert into tb_emp_bigdata (empno,empname,job,mgr,hiredate,sal,comm,deptno) values((start+i),rand_string(6),'developer',0001,curdate(),2000,400,rand_num());
until i=max_num
end repeat;
commit;
end $$
3.具体执行过程批量插入数据
#1.首先执行随机生成字符串的函数。
#2.然后执行随机生成编号的函数。
#3.查看函数是否创建成功。
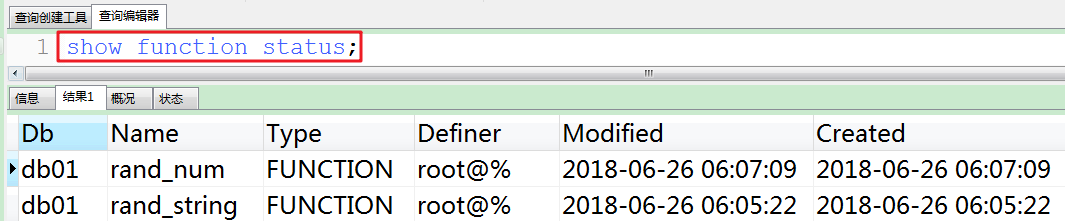
#4.执行插入数据的存储过程,并查看其创建情况。

#5.执行存储过程,插入数据。
a.首先执行insert_dept存储过程。
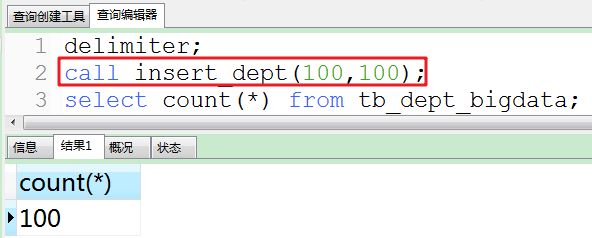
说明:deptno的范围[100,110),因为deptno的值使用了rand_num()函数。
b.然后执行insert_emp存储过程。
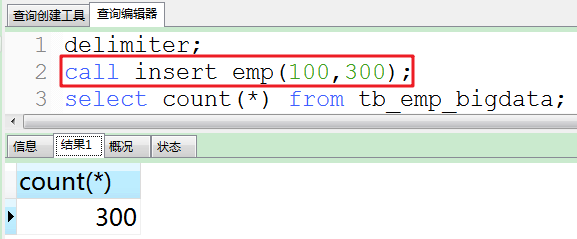
说明:tb_emp_bigdata表中deptno编号的范围[100,110),使用rand_num()函数。
注:对于部门表的deptno和员工表中deptno的数据都使用了rand_num()函数进行赋值,确保两边的值能对应。
4.删除函数与存储过程
#1.删除函数
drop function rand_num;
drop function rand_string;
#2.删除存储过程
drop procedure insert_dept;
drop procedure insert_emp;
总结
①注意mysql中函数和存储过程的写法。
②注意存储过程的调用,call procedurename。
③注意开启对函数的信任,log_bin_trust_function_creators参数。
by Shawn Chen,2018.6.26日,晚。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号