
面试总结——Java篇
前言:前期对Java基础的相关知识点进行了总结,具体参看:Java基础和面试知识点。近期由于笔者正在换工作(ing),因此下面将笔者在面试过程中或笔者朋友面试过程中反馈的题目进行总结,相信弄清楚下面题目,对面试还是有一定帮助的。
说明:
1)在面试过程中切记不要过分紧张,当然紧张是在所难免的。注意表述清晰,语速不要过快。表述清晰,不要紧张。表述清晰,不要紧张。表述清晰,不要紧张。重要的事说三遍,很重要。
2)以下所有知识点均来自笔者或者笔者朋友在实际面试过程中所遇到的题目,对面试还是有一定的参考价值。
3)老套路第一步自我介绍,可根据网上的一些相关建议,做好准备。
4)在面试过程中,面试官很可能让你选择简历中某个项目的重点来谈一下,对于这点要特别注意,因为从这点可以聊出你对项目了解得是否清楚,并且判断出你的表述、逻辑是否清晰有条理,说话也是一种艺术,特别是面对面的交谈,所以该点需要特别注意。(表述清晰,不要紧张)
5)换工作也有一段时间了,这次特别回来看当时写的这篇随笔,发现还有很多值得细究的地方,于是准备细究。
Java篇
说明:
a)包含一小部分java基础题,主要是特别容易出错的知识点。
b)绝大部分为相对较难或高级一点的题目。
1)java基础
1 String str1 = "hello"; 2 String str2 = "he" + new String("llo"); 3 System.out.println(str1 == str2);
返回false,因为str1地址在字符常量池中,str2地址在堆上,str2并不会在编译期间被优化。
2)switch在调用的时,如果case后不加break或者return,则程序会从条件符合处一直执行到条件结尾。
3)在java中,i+1<i可能出现吗?可能,如i=Integer.MAX_VALUE,i+1则为负数,此时满足条件。
4)HashMap和ConcurrentHashMap必问,在jdk1.8中,当元素的个数大于等于8时,HashMap的底层存储为转向红黑树。面试点:红黑树基础了解、能否画出数据结构图、相比其他数据结构的优势。
关于HashMap和ConcurrentHashMap的相关知识,参考:Java基础知识点(一)
关于红黑树的相关知识点,参考:
https://github.com/julycoding/The-Art-Of-Programming-By-July/blob/master/ebook/zh/03.01.md
https://www.cnblogs.com/CarpenterLee/p/5503882.html
红黑树是一个相对来说较复杂的数据结构,只有一点一点的积累,才能最终掌握它。
5)ThreadLocal进行set操作时的key值,涉及到ThreadLocal的源码解析。
有关ThreadLocal的原理,可参考:
http://www.jasongj.com/java/threadlocal/
https://www.cnblogs.com/shoren/p/java.html
结论:
ThreadLocal在set时,其key为当前ThreadLocal对象,因为set的时候会对每个线程都创建一个ThreadLocalMap,在map中进行值的set和get。该map为当前线程的属性,从而实现一个线程一个副本,达到变量间的隔离效果。
具体分析过程请参看:ThreadLocal源码调试——“this”作为key
6)Lock与synchronized的区别,以及其底层实现。
区别:
①Lock是Java的接口,synchronized是Java的关键字。
②Lock必须手动释放锁,否则有可能导致死锁,synchronized在代码执行完成或者发生异常时,自动释放锁。
③Lock可判断锁的获取状态,synchronized不可判断。
④Lock可中断(中断演示),公平或非公平锁(默认),synchronize不可中断,非公平锁,都可重入。
⑤Lock可提高多个线程读的效率。
⑥Lock与Condition搭配,可绑定多个条件(多个Condition),而synchronized只可以实现一个隐含的条件,通过wait()和notify()或者notifyall()。
⑦目前jdk对两者都进行了优化,性能上已经相差无几了。
底层实现:
synchronized代码块的同步与方法的同步实现有差异。
要点:
①同步代码块会在代码前后形成monitorenter和monitorexit执行。
②同步方法是通过ACC_SYNCHRONIZED指示符来实现。
参考:
https://www.cnblogs.com/paddix/p/5367116.html
Lock的底层实现。
要点:
①基于AQS实现。
②提供公平与非公平锁。
参考:
http://www.cnblogs.com/leesf456/p/5350186.html
https://www.cnblogs.com/xrq730/p/4979021.html
7)为什么要优先使用非公平锁。
关于为什么要优先使用非公平锁的原因,可以从公平锁的角度来谈。
①对于公平锁,保证了线程获取锁的顺序,先到的线程优先获取锁,即FIFO顺序(“排队”)。
②对于非公平锁,不提供获取锁顺序的保证,获取锁具有抢占机制,可以进行“插队”。
即公平锁“排队”,非公平锁可“插队”。
总结:
在公平锁策略下,当一个线程持有锁或在等待队列中的线程正在等待锁时,新的线程请求会被加入队列中进行排队;而在非公平策略下,只有当锁被某个线程持有时,新的线程请求才会被加入队列中进行排队,从而有一定几率减少了线程挂起的开销,因此非公平锁的效率较高。因为线程从挂起到运行中间还是会消耗一些资源,非公平锁对于新来的线程请求,在一定几率上减少了线程挂起的开销,这就是非公平锁效率高于公平锁的原因。
8)volatile的底层实现相关。
volatile的相关知识,请参考笔者的另一篇随笔:https://www.cnblogs.com/developer_chan/p/9129342.html
9)如何更进一步提高ConcurrentHashMap的并发性。
笔者认为可以从以下两方面来更进一步提高ConcurrentHashMap的并发性:
①减少对同一锁的请求频率
②减少持有锁的时间。
10)TreeMap和HashMap的实现原理,及其性能的比较。
HashMap的实现原理属于基础,TreeMap是基于红黑树来实现的,具体参考:http://www.cnblogs.com/skywang12345/p/3310928.html
HashMap是基于散列表的实现,TreeMap是基于红黑树的实现,硬要在性能上作比较的话,散列表的性能肯定要好些。对于这两者的比较更多是功能上的比较,TreeMap是有序的,而HashMap是无序的。
11)Collection、List、Set、Map之间的层级关系。
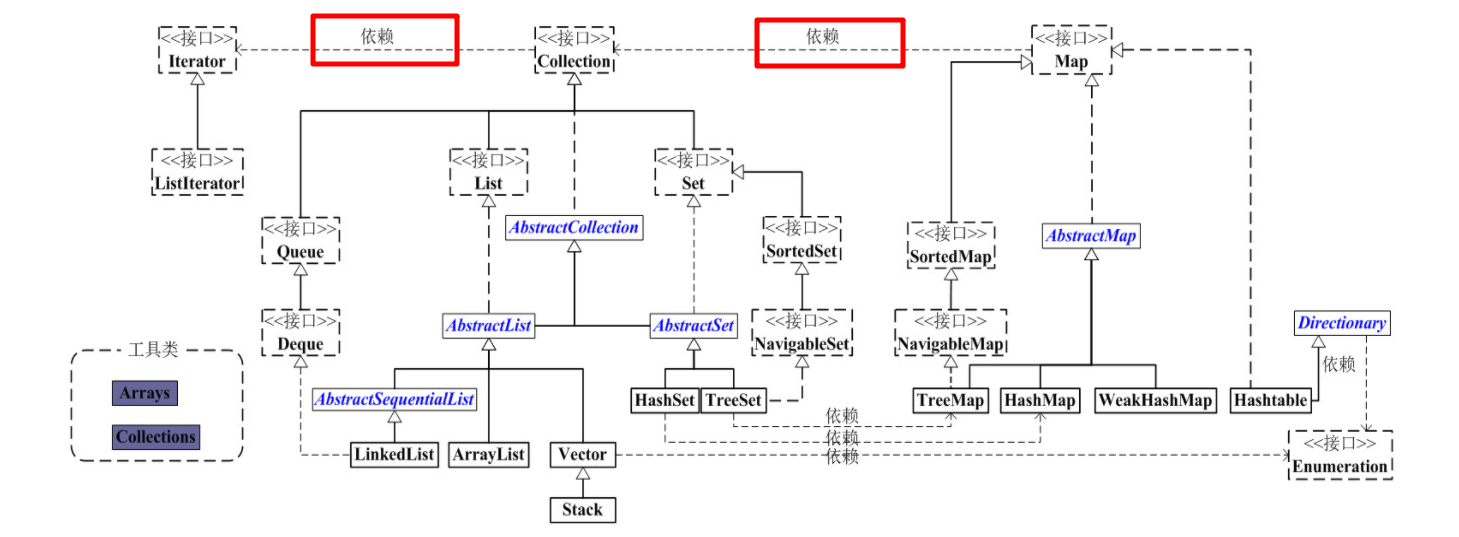 Collection
Collection
---List
---Set
List与Set都继承Collection。
Map与Collection有依赖关系,其values()方法,返回Collection。
参考:
http://www.cnblogs.com/skywang12345/p/3308498.html
12)SortedMap的具体实现。
SortedMap是一个接口,具体实现可参考TreeMap。
13)线程池ThreadPoolExecutor,基本实现原理、队列中放的是线程还是任务、内部线程是如何运作的、如果是无界队列有什么问题、拒绝策略。
ThreadPoolExecutor传送门:ThreadPoolExecutor解析
14)AQS(AbstractQueuedSynchronizer)实现原理。
AQS的源码分析,笔者最近进行了总结,传送门:AQS框架源码分析-AbstractQueuedSynchronizer
15)CAS(compare and swap)如何实现,底层用到了哪个Class,以及其优劣势,在ABA问题中,从一致性角度来看,对数据看到底有影响没。
CAS传送门:Java中的CAS原理
CAS有3个操作数,内存值V,预期值A,要修改的新值B。当且仅当预期值A和内存值V相同时,将内存值V修改为B,否则什么都不做。
CAS的底层实现:CAS是通过JNI调用CPU的CAS指令(本地方法,非阻塞式算法)来完成的,这些本地方法在Unsafe类中。
CAS的优点:
使用汇编指令来保证操作的原子性,速度快。
CAS的缺点:
①ABA问题。(当one线程从内存中取出A后,这时two线程也从内存中取出A,并做了一系列操作:先将A修改为B,然后再改为A,这时one线程发现内存值仍是A,则进行操作。)
②由于CAS本质上是乐观锁,在高并发的场景下,CAS操作的失败概率增加,增加了CPU的开销。
在ABA问题上,从一致性角度来看,对数据还是有影响的。比如有一个栈,栈顶为A,A元素后紧跟着B、C,在执行CAS的过程中,B、C出栈了,此时栈顶仍然为A,数据其实是改变了,所以ABA问题,从一致性角度来看,对数据还是有影响的。
16)CountDownLatch、CyclicBarrier、Semaphore新生的并发控制类,CountDownLatch 底层是如何保证多线程同时 wait。
①CountDownLatch
利用它可以实现类似计数器的功能,可实现任务的等待。如有一个任务A,它要等待其他4个任务执行完毕之后才能执行,就可以利用CountDownLatch来实现;计数器无法被重置。
CountDownLatch是通过“共享锁”实现的。在创建CountDownLatch中时,会传递一个int类型参数count,该参数是“锁计数器”的初始状态,表示该“共享锁”最多能被count给线程同时获取。当某线程调用该CountDownLatch对象的await()方法时,该线程会等待“共享锁”可用时,才能获取“共享锁”进而继续运行。而“共享锁”可用的条件,就是“锁计数器”的值为0!而“锁计数器”的初始值为count,每当一个线程调用该CountDownLatch对象的countDown()方法时,才将“锁计数器”-1;通过这种方式,必须有count个线程调用countDown()之后,“锁计数器”才为0,而前面提到的等待线程才能继续运行
②CyclicBarrier
字面意思回环栅栏,通过它可以实现让一组线程等待至某个状态之后再全部同时执行。叫做回环是因为当所有等待线程都被释放以后,CyclicBarrier可以被重用;计数器可以被重置。
③Semaphore
Semaphore信号量,Semaphore可以控同时访问的线程个数,通过 acquire() 获取一个许可,如果未取到就等待,而 release() 释放一个许可。
参考:
http://www.cnblogs.com/skywang12345/p/java_threads_category.html
17)ForkJoinPool工作窃取算法是如何实现的。
ForkJoinPool框架的核心思想:把一个大的任务分割成若干小任务,最终汇总每个小任务的结果得到大任务的结果。
工作窃取算法:某个线程从其他队列里窃取任务来执行。队列采用双端队列,比如A线程和B线程同时执行任务,A线程已经执行完了,则A线程就从B线程的任务队列尾中取任务进行操作,而B线程是从队列头取数据进行操作。
参考:
http://ifeve.com/talk-concurrency-forkjoin/
18)Java8 中的 Stream的惰性求值是如何实现。
惰性求值是一种求值策略,也就是把求值延迟到真正需要的时候。
Stream有两种类型的方法:
①中间操作
②终结操作
这两种操作外加数据源就构成了处理管道。在每次使用Stream的时候,都会连接多个中间操作,并在最后附上一个结束操作;在调用中间操作时,会立即返回一个Stream对象,只有在调用终结操作时,才会真正去执行中间操作。
参考:
https://www.cnblogs.com/heimianshusheng/p/5674372.html
19)BIO、NIO底层是如何实现的,操作系统 IO 是如何实现及调用的,如何实现非阻塞、异步 IO。
进程执行操作系统的I/O请求包括数据从缓冲区排出(写操作)和数据填充缓冲区(读操作),这就是I/O的整体概念。
进程中的IO调用步骤大致可以分为以下四步:
①进程向操作系统请求数据。
②操作系统把外部数据加载到内核的缓冲区中。
③操作系统把内核的缓冲区拷贝到进程的缓冲区。
④进程获得数据完成自己的功能。
BIO(Blocking I/O):同步阻塞I/O模式,数据的读取写入必须阻塞在一个线程内等待其完成。解释:经典的烧开水例子。假设一个烧开水的场景,有一排水壶在烧开水,BIO的工作模式就是, 让一个线程停留在一个水壶上,直到这个水壶烧开,才去处理下一个水壶。但是实际上线程在等待水壶烧开的时间段什么都没有做。通过加锁实现,独占锁。
NIO(New I/O):同时支持阻塞与非阻塞模式,以同步非阻塞I/O模式来说,还是以烧开水的例子:NIO的做法是叫一个线程不断的轮询每个水壶的状态,看看是否有水壶的状态发生了改变,从而进行下一步的操作。共享锁。
AIO ( Asynchronous I/O):异步非阻塞I/O模型。异步非阻塞与同步非阻塞的区别:异步非阻塞无需一个线程去轮询所有IO操作的状态改变,在相应的状态改变后,系统会通知对应的线程来处理。对应到烧开水中就是,为每个水壶上面装了一个开关,水烧开之后,水壶会自动通知我水烧开了。使用线程返回值来进行处理。
参考:
http://www.importnew.com/14111.html
https://juejin.im/entry/598da7d16fb9a03c42431ed3
20)线程池中使用ThreadLocal 可能会出现问题。
由于线程池中可以对线程重复使用,而ThreadLocal在使用时,是根据每个线程创建ThreadLocalMap的,key为当前的ThreadLocal对象,而不是当前线程对象,因此在线程池中使用ThreadLocal会出现的问题:当再次使用A线程时,在未使用ThreadLocal的set操作情况下,进行get操作能获取值(并不是我们所想要的),原因:有可能在上一次使用A线程时,已经已经进行了set操作,解决方法:在使用ThreadLocal进行操作之前或之后,进行remove操作。
参考:
https://blog.csdn.net/Dongguabai/article/details/79752545
by Shawn Chen,于2018.6月,开始找工作途中......end,start......于2019.1.30日,细究开始......

 浙公网安备 33010602011771号
浙公网安备 33010602011771号