


12 2021 档案
摘要:如果我们希望后端过一段时间在执行一段代码,可以使用springboot提供的定时器 https://www.cnblogs.com/pejsidney/p/9046818.html
阅读全文
摘要:1、导入依赖 <!--websocket依赖--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-websocket</artifactId> <version>2.6
阅读全文
摘要:https://blog.csdn.net/yanxiaoyang12580/article/details/108300262
阅读全文
摘要:https://blog.csdn.net/csdnteach/article/details/112938992
阅读全文
摘要:问题发生的原因: SpringBoot 把静态的文件在启动的时候都会加载到classpath的目录下的,package时把static目录下的资源一起打包到了jar包或war包中,此时上传的图片并未传入启动了的项目中,所以访问不到。项目重启后又会打成新的jar包,包含上一次上传的的图片,此时才会在页
阅读全文
摘要:有个常见的场景:删除用户的时候需要先删除用户的外键关联数据,否则会触发规则报错。 解决办法不外乎有三个:1、多条sql分批执行;2、存储过程或函数调用;3、sql批量执行。 今天我要说的是MyBatis中如何一次执行多条语句(使用mysql数据库)。 1、修改数据库连接参数加上allowMultiQ
阅读全文
摘要:a.html <!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>a页面</title> <script type="text/javascript" src="link/jquery.min.js"></script> <scri
阅读全文
摘要:https://www.cnblogs.com/shianliang/p/10470740.html https://blog.csdn.net/qq_44241551/article/details/103768153 spring 缓存 @CachePut 和 @Cacheable 区别 htt
阅读全文
摘要:我们把checked这个属性绑定给vue,注意checked="checked"和checked是一个样的,只要写了checked,就表示默认选中。 我们页面加载后,根据从数据库中查出来的数据对radio进行默认选中,通过方法返回true/false的方式来使radio是否被选中。 用三元表达式,即
阅读全文
摘要:思路(代码看“chufangmama”这个项目): 我们登录成功后,可以将登录的用户存储到redis中。在redis中数据没有过期的情况下,我们再次进入登录页面时,会使用vue的created方法发送一个axios请求,去查询redis中是否有用户数据。如果有,可以使用sendRedirect进行跳
阅读全文
摘要:(1)这里是input标签 (2)js的方法,如果所有框都输入了内容,就改变提交按钮的样式 (3)如果所有框都输入了内容,即提交按钮改变了,我们才允许vue使用axios向后端发送请求 / / / / 源代码 <!DOCTYPE html> <html lang="en"> <head> <meta
阅读全文
摘要: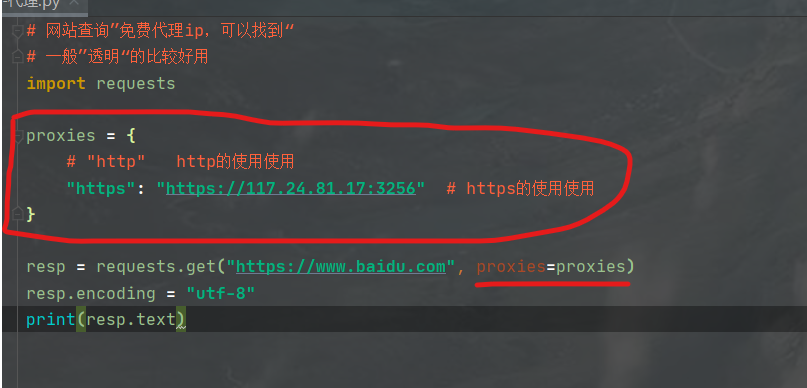
阅读全文
摘要:https://pearvideo.com/ 首先分析网页,查看网页源代码,发现并没有视频标签,所以判定这是通过二次请求加载的视频。打开开发者工具,点击网络 >XHR,刷新后查看网页发送的请求 / / / 这个是二次请求后从开发者工具的html代码那里看到的路径(注意一定播放视频后才能看到) / /
阅读全文
摘要:https://www.17k.com/ # 登录 -> 得到cookie # 带着cookie去请求到书架url -> 获取书架上的内容 # 必须把上面的两个操作连起来 # 我们可以使用session进行请求 -> session你可以认为是一连串的请求,在这个过程中的cookie不会丢失 imp
阅读全文
摘要:https://beijing.zbj.com/search/f/?type=n&kw=saas import requests from lxml import html etree = html.etree url = "https://beijing.zbj.com/search/f/?typ
阅读全文
摘要:from lxml import html etree = html.etree # 加载html文件 tree = etree.parse("b.html", etree.HTMLParser()) # ['百度', '谷歌', '搜狗'] # result = tree.xpath("/html
阅读全文
摘要:# xpath是在xml文档中搜索内容的一门语言 # html是xml的一个子集 # 安装lxml模块 pip install lxml # xpath解析 from lxml import html etree = html.etree xml = """ <book> <id>1</id> <n
阅读全文
摘要:https://m.ivsky.com/ # 1、拿到主页面的源代码,然后提取到子页面的链接地址,href # 2、通过href拿到子页面的内容,从子页面中找到图片的下载地址img -> src # 3、下载图片 import requests from bs4 import BeautifulSo
阅读全文
摘要:首先要安装bs4 pip install bs4 from bs4 import BeautifulSoup import requests import csv url = "http://www.maicainan.com/offer/show/id/3242.html" resp = requ
阅读全文
摘要:# 先进入到电影天堂首页,可以看到2021必看热片模块 # 随便点击一个连接,会再打开一个网站,网站下面有下载地址,我们要爬取这个下载地址 import requests import re url = "https://dytt89.com/" headers = { "user-agent":
阅读全文
摘要:我们把小说名、是否完结、男主名字、女主名字都给爬取下来 import requests import re url = "http://m.pinsuu.com/paihang/nanpindushi/" headers = { "User-Agent": "Mozilla/5.0 (Linux;
阅读全文
摘要:将提取的内容放到一个组中,通过这个组的名字获取我们想要的内容
阅读全文
摘要:import re # 前缀r表示这个是正则表达式,没有也可以,但是加上更规范,就像二进制、十六进制一样 # findAll:查找所有满足正则表达式的内容,但是用的不多,因为用的列表,列表效率并不高 list = re.findall(r"\d+", "我的手机号码是10086, 你的手机号码是10
阅读全文
摘要:每一个元字符默认只匹配一个字符,例如一个点匹配的是一个字符,两个点匹配的就是两个字符 / / / / / / / / / / (1)贪婪匹配 *先找到“玩儿”,然后通过.尽可能多的匹配,然后找到最远的那个“游戏” (2)惰性匹配 先找到“玩儿”,然后尽可能多的匹配,然后因为有?又是尽可能少的匹配,所
阅读全文
摘要:
阅读全文
摘要:我们每次发送的相应resp都要关掉,如果我们访问类好多请求路径,每次的resp都没有关闭,可能会出现错误 resp.close()
阅读全文
摘要:请求地址是豆瓣电影排行榜的喜剧类别 / / / / / 但是输出内容为空,我们应该想到是不是有反爬机制,接下来我们去尝试解决反爬 / / / / 1、首先添加| User-Agent 成功 / / / / / / 页面展示内容有限,我们每次滑倒网页底部,又会重新发送请求,加载新的内容,通过循环查询更
阅读全文
摘要:我们爬取百度翻译的单词内容,通过抓包,sug包是我们需要的内容 并且是post请求方式,所以不可使用拼接参数的方式 通过请求参数获知提交给服务器的表单参数key是kw / / / / post方式,将数据放在字典中,通过data方式进行传递 发现出现了中文乱码,是因为服务器返回给我们的是json格式
阅读全文
摘要:首先安装第三方库:pip install requests 但是,搜狗的服务器校验我们是不是爬虫程序发出的请求,并没有返回给我们有用的信息 / / / / 我们可以给我们的程序添加请求头headers,查看浏览器的User-Agent,添加到我们的程序中,模拟是浏览器发出的请求即可。 处理反爬: /
阅读全文
摘要: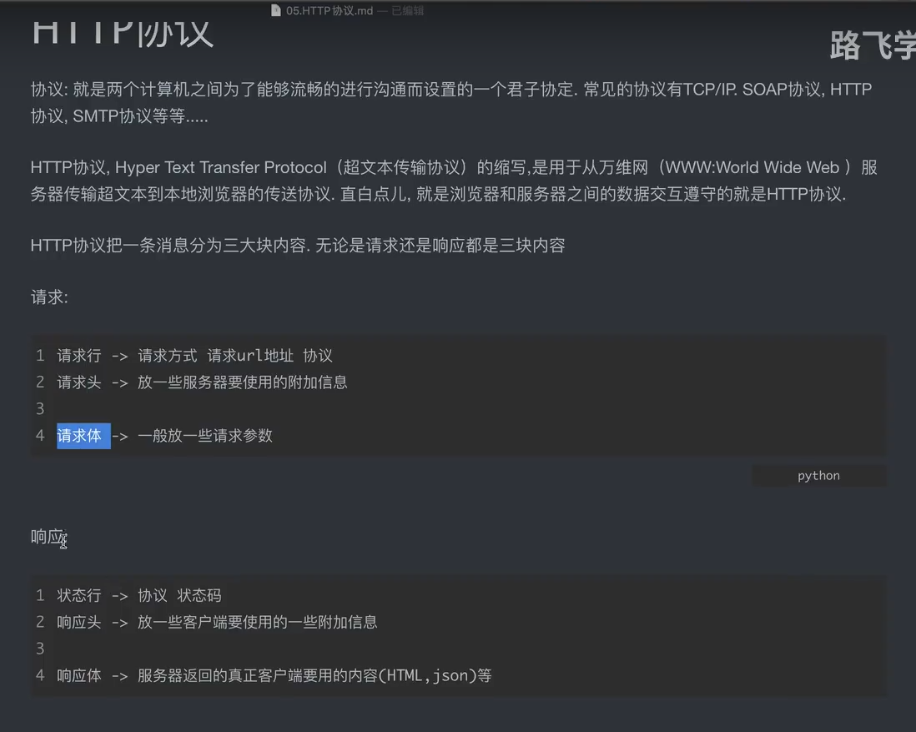 
阅读全文
摘要:#1、服务器渲染:在服务器那边直接把数据和html整合在一起,统一返回给浏览器 ** # 在页面源代码能看到数据** #2、客户端渲染 ** # 第一次请求只要要给html管家,第二次请求拿到数据,进行数据展示** ** # 在页面源代码中,看不到数据** # 熟练使用浏览器的抓包工具来查看网页的请
阅读全文
摘要:from urllib.request import urlopen url = "http://www.baidu.com" resp = urlopen(url) with open("mybaidu.html", mode="w", encoding="utf-8") as f: f.writ
阅读全文
摘要:1、创建数据库 CREATE TABLE `t_user` ( `id` int NOT NULL AUTO_INCREMENT, `username` varchar(255) DEFAULT NULL, `password` varchar(255) DEFAULT NULL, PRIMARY
阅读全文
摘要: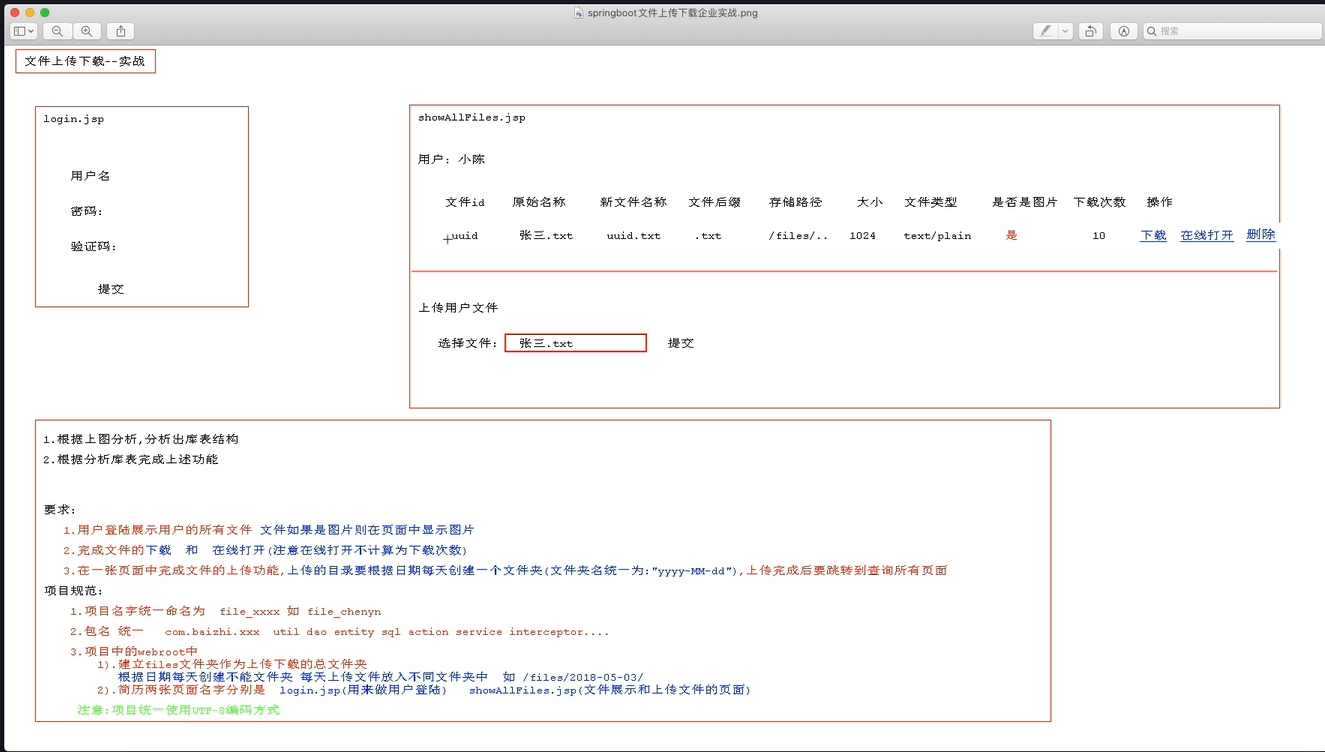
阅读全文
摘要:redis的session管理是利用spring提供的session管理解决方案,将一个应用session交给redis存储,整个应用中所有session的请求都会去redis中获取对应的session数据 / / / / 1、memcache和redis实现session共享的区别 (1)memc
阅读全文
摘要:Redis集群至少需要3个节点,因为投票容错机制要求超过半数节点认为某个节点挂了该节点才是挂了,所以2个节点无法构成集群。 要保证集群的高可用,需要每个节点都有从节点,也就是备份节点,所以Redis集群至少需要6台服务器。 / / / / / 1、创建6个文件夹7001-7006,分别存放redis
阅读全文
摘要: 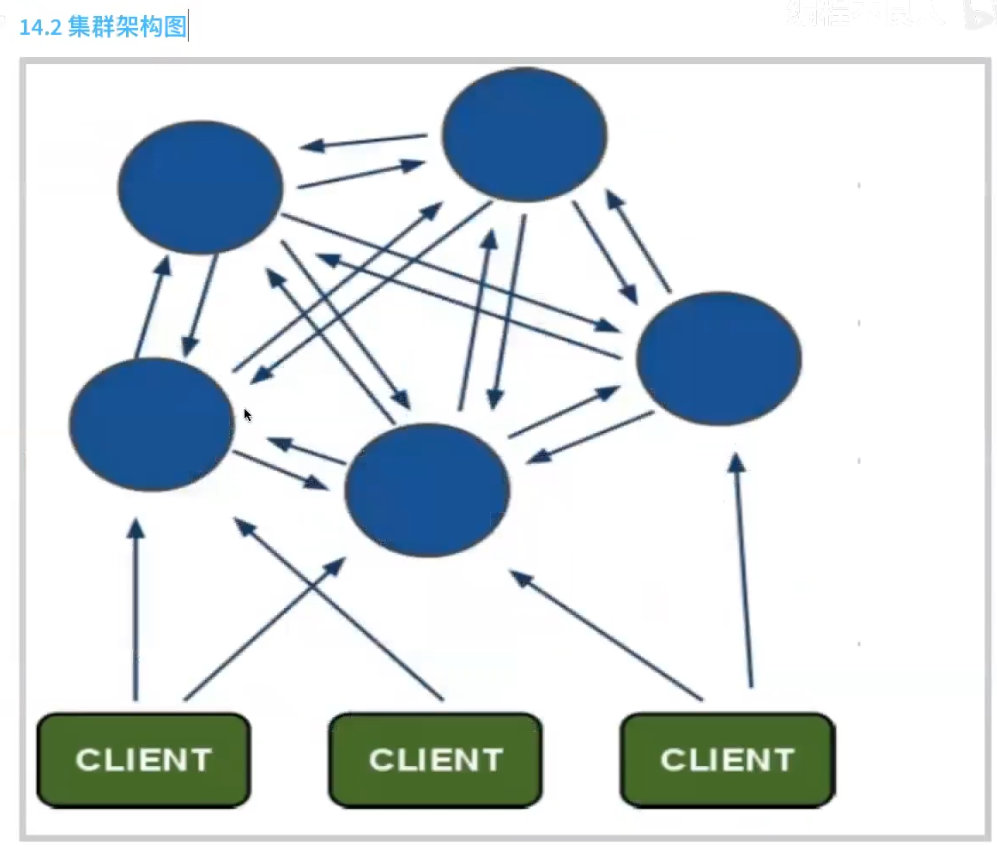 
阅读全文
摘要:通过getObject(Object key)方法,如果redis缓存中有值,直接取出,不用访问数据库了
阅读全文
摘要:一、编写自定义的RedisCache,实现ibatis的Cache接口 package com.study.cache; import org.apache.ibatis.cache.Cache; //自定义redis缓存 public class RedisCache implements Cac
阅读全文
