


随笔分类 - 爬虫
摘要: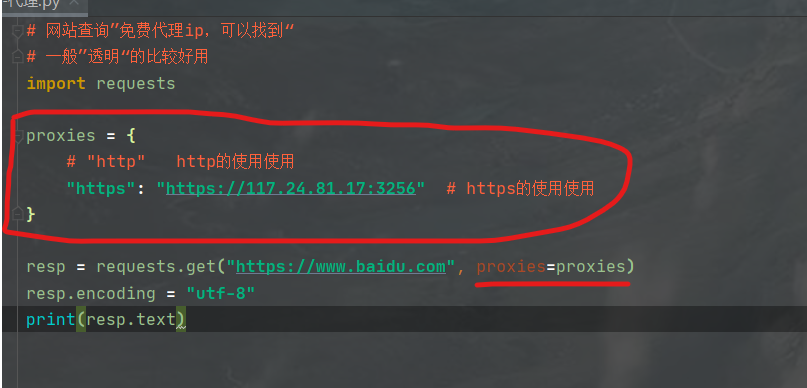
阅读全文
摘要:https://pearvideo.com/ 首先分析网页,查看网页源代码,发现并没有视频标签,所以判定这是通过二次请求加载的视频。打开开发者工具,点击网络 >XHR,刷新后查看网页发送的请求 / / / 这个是二次请求后从开发者工具的html代码那里看到的路径(注意一定播放视频后才能看到) / /
阅读全文
摘要:https://www.17k.com/ # 登录 -> 得到cookie # 带着cookie去请求到书架url -> 获取书架上的内容 # 必须把上面的两个操作连起来 # 我们可以使用session进行请求 -> session你可以认为是一连串的请求,在这个过程中的cookie不会丢失 imp
阅读全文
摘要:https://beijing.zbj.com/search/f/?type=n&kw=saas import requests from lxml import html etree = html.etree url = "https://beijing.zbj.com/search/f/?typ
阅读全文
摘要:from lxml import html etree = html.etree # 加载html文件 tree = etree.parse("b.html", etree.HTMLParser()) # ['百度', '谷歌', '搜狗'] # result = tree.xpath("/html
阅读全文
摘要:# xpath是在xml文档中搜索内容的一门语言 # html是xml的一个子集 # 安装lxml模块 pip install lxml # xpath解析 from lxml import html etree = html.etree xml = """ <book> <id>1</id> <n
阅读全文
摘要:https://m.ivsky.com/ # 1、拿到主页面的源代码,然后提取到子页面的链接地址,href # 2、通过href拿到子页面的内容,从子页面中找到图片的下载地址img -> src # 3、下载图片 import requests from bs4 import BeautifulSo
阅读全文
摘要:首先要安装bs4 pip install bs4 from bs4 import BeautifulSoup import requests import csv url = "http://www.maicainan.com/offer/show/id/3242.html" resp = requ
阅读全文
摘要:# 先进入到电影天堂首页,可以看到2021必看热片模块 # 随便点击一个连接,会再打开一个网站,网站下面有下载地址,我们要爬取这个下载地址 import requests import re url = "https://dytt89.com/" headers = { "user-agent":
阅读全文
摘要:我们把小说名、是否完结、男主名字、女主名字都给爬取下来 import requests import re url = "http://m.pinsuu.com/paihang/nanpindushi/" headers = { "User-Agent": "Mozilla/5.0 (Linux;
阅读全文
摘要:将提取的内容放到一个组中,通过这个组的名字获取我们想要的内容
阅读全文
摘要:import re # 前缀r表示这个是正则表达式,没有也可以,但是加上更规范,就像二进制、十六进制一样 # findAll:查找所有满足正则表达式的内容,但是用的不多,因为用的列表,列表效率并不高 list = re.findall(r"\d+", "我的手机号码是10086, 你的手机号码是10
阅读全文
摘要:每一个元字符默认只匹配一个字符,例如一个点匹配的是一个字符,两个点匹配的就是两个字符 / / / / / / / / / / (1)贪婪匹配 *先找到“玩儿”,然后通过.尽可能多的匹配,然后找到最远的那个“游戏” (2)惰性匹配 先找到“玩儿”,然后尽可能多的匹配,然后因为有?又是尽可能少的匹配,所
阅读全文
摘要:
阅读全文
摘要:我们每次发送的相应resp都要关掉,如果我们访问类好多请求路径,每次的resp都没有关闭,可能会出现错误 resp.close()
阅读全文
摘要:请求地址是豆瓣电影排行榜的喜剧类别 / / / / / 但是输出内容为空,我们应该想到是不是有反爬机制,接下来我们去尝试解决反爬 / / / / 1、首先添加| User-Agent 成功 / / / / / / 页面展示内容有限,我们每次滑倒网页底部,又会重新发送请求,加载新的内容,通过循环查询更
阅读全文
摘要:我们爬取百度翻译的单词内容,通过抓包,sug包是我们需要的内容 并且是post请求方式,所以不可使用拼接参数的方式 通过请求参数获知提交给服务器的表单参数key是kw / / / / post方式,将数据放在字典中,通过data方式进行传递 发现出现了中文乱码,是因为服务器返回给我们的是json格式
阅读全文
摘要:首先安装第三方库:pip install requests 但是,搜狗的服务器校验我们是不是爬虫程序发出的请求,并没有返回给我们有用的信息 / / / / 我们可以给我们的程序添加请求头headers,查看浏览器的User-Agent,添加到我们的程序中,模拟是浏览器发出的请求即可。 处理反爬: /
阅读全文
摘要: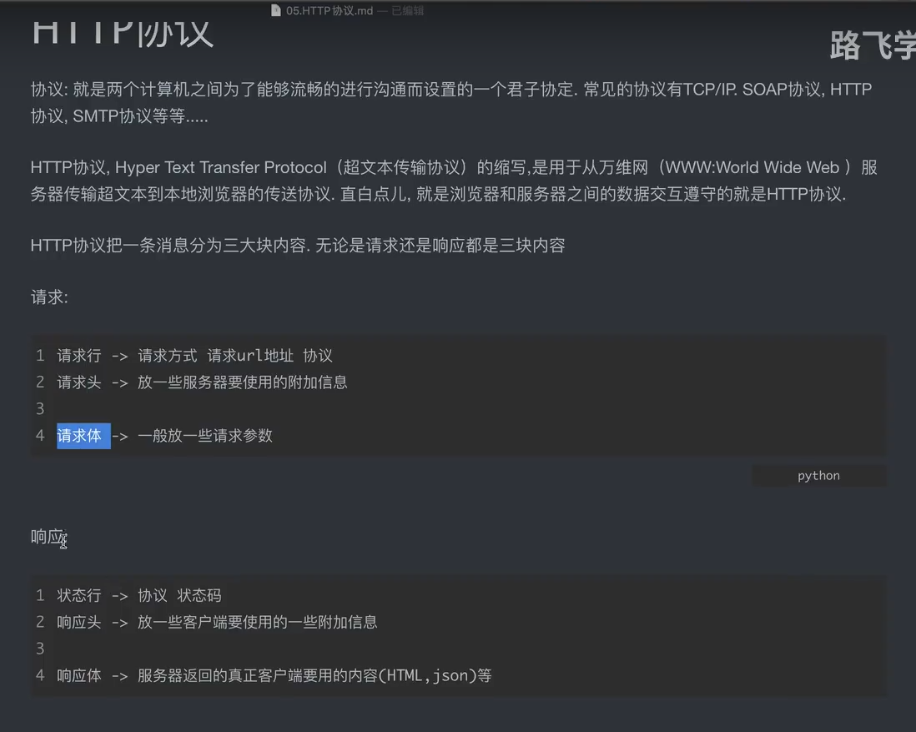 
阅读全文
摘要:#1、服务器渲染:在服务器那边直接把数据和html整合在一起,统一返回给浏览器 ** # 在页面源代码能看到数据** #2、客户端渲染 ** # 第一次请求只要要给html管家,第二次请求拿到数据,进行数据展示** ** # 在页面源代码中,看不到数据** # 熟练使用浏览器的抓包工具来查看网页的请
阅读全文
