数据结构与算法知识树整理——算法篇——字符串匹配
算法知识树整理
字符串匹配
-
BF 算法
-
BF 算法中的 BF 是 Brute Force 的缩写,中文叫作暴力匹配算法,也叫朴素匹配算法。从名字可以看出,这种算法的字符串匹配方式很“暴力”,当然也就会比较简单、好懂,但相应的性能也不高。
-
在开始讲解这个算法之前,我先定义两个概念,方便我后面讲解。它们分别是主串和模式串。比方说,我们在字符串 A 中查找字符串 B,那字符串 A 就是主串,字符串 B 就是模式串,我们把主串的长度记作 n,模式串的长度记作 m。因为我们是在主串中查找模式串,所以 n>m。
-
作为最简单、最暴力的字符串匹配算法,BF 算法的思想可以用一句话来概括,那就是,我们在主串中,检查起始位置分别是 0、1、2....n-m 且长度为 m 的 n-m+1 个子串,看有没有跟模式串匹配的。我举一个例子给你看看,你应该可以理解得更清楚。
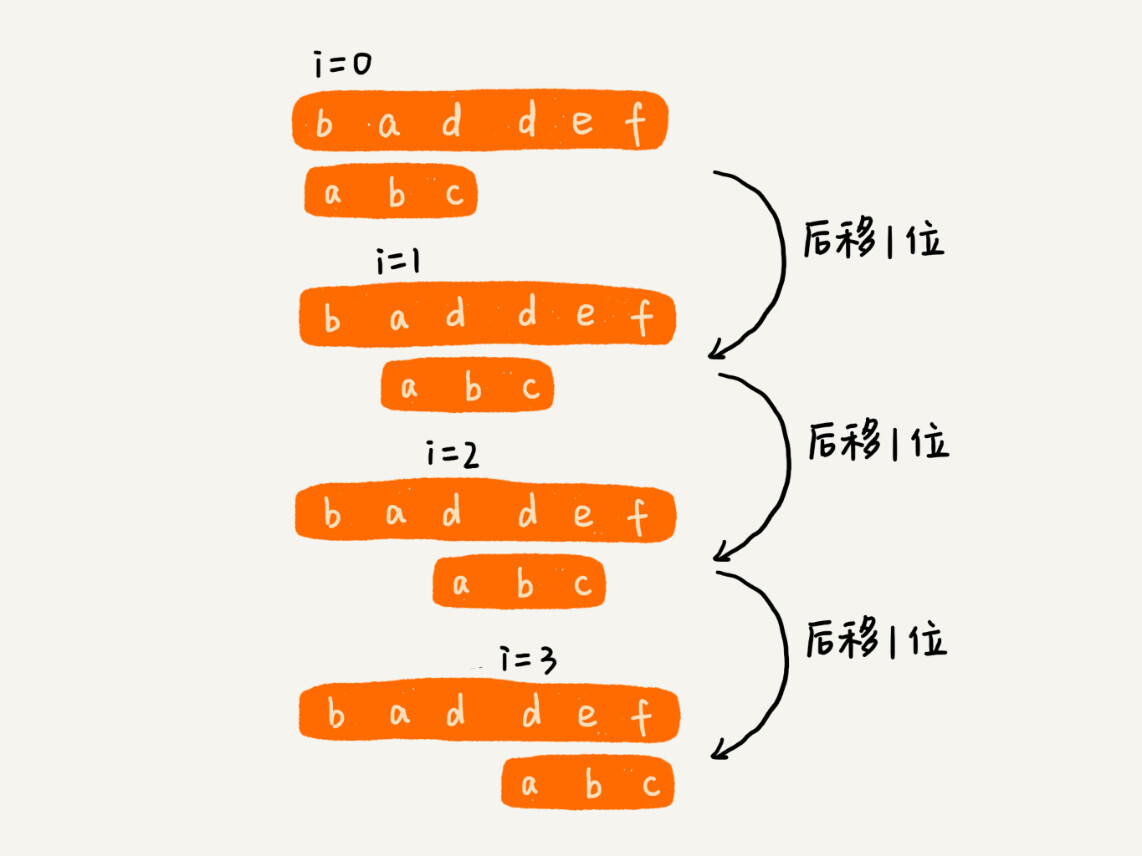
-
从上面的算法思想和例子,我们可以看出,在极端情况下,比如主串是“aaaaa....aaaaaa”(省略号表示有很多重复的字符 a),模式串是“aaaaab”。我们每次都比对 m 个字符,要比对 n-m+1 次,所以,这种算法的最坏情况时间复杂度是 O(n*m)。
-
尽管理论上,BF 算法的时间复杂度很高,是 O(n*m),但在实际的开发中,它却是一个比较常用的字符串匹配算法。为什么这么说呢?原因有两点。
- 实际的软件开发中,大部分情况下,模式串和主串的长度都不会太长。而且每次模式串与主串中的子串匹配的时候,当中途遇到不能匹配的字符的时候,就可以就停止了,不需要把 m 个字符都比对一下。所以,尽管理论上的最坏情况时间复杂度是 O(n*m),但是,统计意义上,大部分情况下,算法执行效率要比这个高很多。
- 朴素字符串匹配算法思想简单,代码实现也非常简单。简单意味着不容易出错,如果有 bug 也容易暴露和修复。在工程中,在满足性能要求的前提下,简单是首选。这也是我们常说的KISS(Keep it Simple and Stupid)设计原则。
-
RK 算法
-
概念
-
RK 算法的全称叫 Rabin-Karp 算法。我个人觉得,它其实就是刚刚讲的 BF 算法的升级版。
-
对于 BF 算法,如果模式串长度为 m,主串长度为 n,那在主串中,就会有 n-m+1 个长度为 m 的子串,我们只需要暴力地对比这 n-m+1 个子串与模式串,就可以找出主串与模式串匹配的子串。
-
但是,每次检查主串与子串是否匹配,需要依次比对每个字符,所以 BF 算法的时间复杂度就比较高,是 O(n*m)。我们对朴素的字符串匹配算法稍加改造,引入哈希算法,时间复杂度立刻就会降低。
-
RK 算法的思路是这样的:我们通过哈希算法对主串中的 n-m+1 个子串分别求哈希值,然后逐个与模式串的哈希值比较大小。如果某个子串的哈希值与模式串相等,那就说明对应的子串和模式串匹配了(这里先不考虑哈希冲突的问题,后面我们会讲到)。因为哈希值是一个数字,数字之间比较是否相等是非常快速的,所以模式串和子串比较的效率就提高了。

-
不过,通过哈希算法计算子串的哈希值的时候,我们需要遍历子串中的每个字符。尽管模式串与子串比较的效率提高了,但是,算法整体的效率并没有提高。有没有方法可以提高哈希算法计算子串哈希值的效率呢?
-
这就需要哈希算法设计的非常有技巧了。我们假设要匹配的字符串的字符集中只包含 K 个字符,我们可以用一个 K 进制数来表示一个子串,这个 K 进制数转化成十进制数,作为子串的哈希值。表述起来有点抽象,我举了一个例子,看完你应该就能懂了。
-
比如要处理的字符串只包含 a~z 这 26 个小写字母,那我们就用二十六进制来表示一个字符串。我们把 a~z 这 26 个字符映射到 0~25 这 26 个数字,a 就表示 0,b 就表示 1,以此类推,z 表示 25。
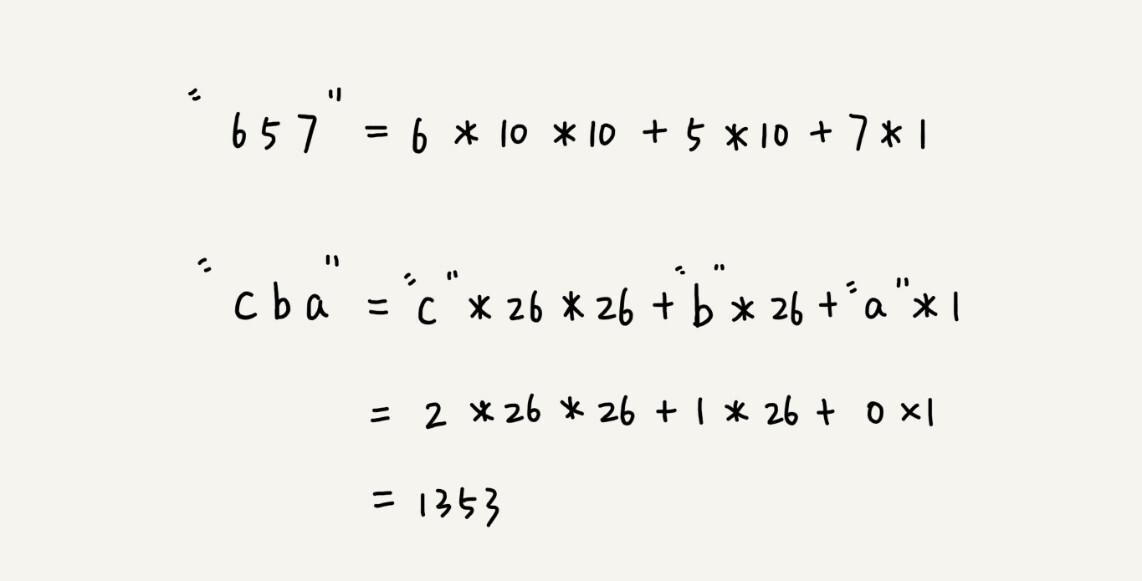
-
这个哈希算法你应该看懂了吧?现在,为了方便解释,在下面的讲解中,我假设字符串中只包含 a~z 这 26 个小写字符,我们用二十六进制来表示一个字符串,对应的哈希值就是二十六进制数转化成十进制的结果。
-
这种哈希算法有一个特点,在主串中,相邻两个子串的哈希值的计算公式有一定关系。比如下面这个例子,第一个数都是262,第二个数是261,最后是26^0再去乘一个常量
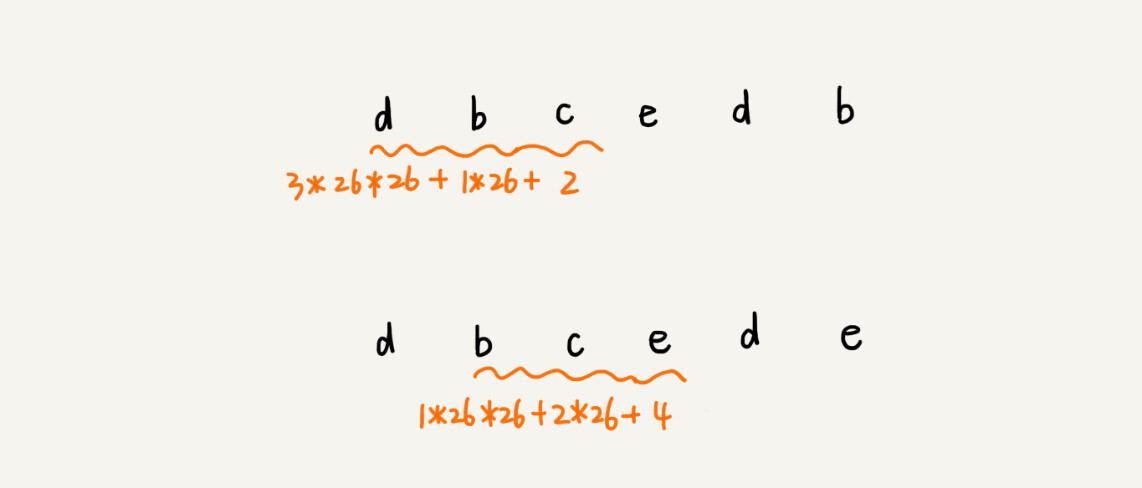
-
从这里例子中,我们很容易就能得出这样的规律:相邻两个子串 s[i-1]和 s[i](i 表示子串在主串中的起始位置,子串的长度都为 m),对应的哈希值计算公式有交集,也就是说,我们可以使用 s[i-1]的哈希值很快的计算出 s[i]的哈希值。如果用公式表示的话,就是下面这个样子:

-
不过,这里有一个小细节需要注意,那就是 26^(m-1) 这部分的计算,我们可以通过查表的方法来提高效率。我们事先计算好 260、261、262……26(m-1),并且存储在一个长度为 m 的数组中,公式中的“次方”就对应数组的下标。当我们需要计算 26 的 x 次方的时候,就可以从数组的下标为 x 的位置取值,直接使用,省去了计算的时间。
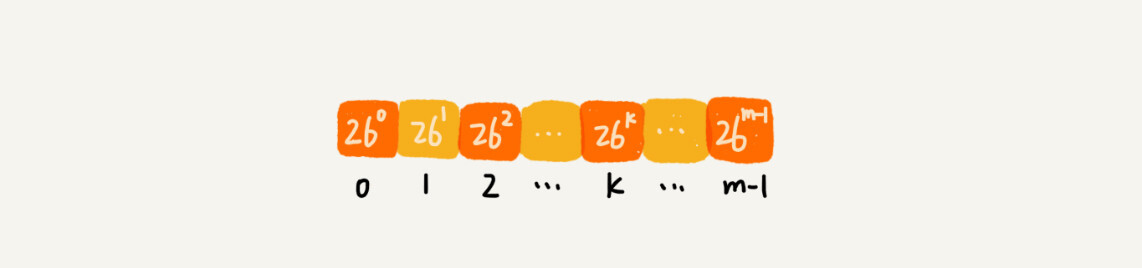
-
RK 算法的效率要比 BF 算法高,现在,我们就来分析一下,RK 算法的时间复杂度到底是多少呢?
- 整个 RK 算法包含两部分,计算子串哈希值和模式串哈希值与子串哈希值之间的比较。第一部分,我们前面也分析了,可以通过设计特殊的哈希算法,只需要扫描一遍主串就能计算出所有子串的哈希值了,所以这部分的时间复杂度是 O(n)。
- 模式串哈希值与每个子串哈希值之间的比较的时间复杂度是 O(1),总共需要比较 n-m+1 个子串的哈希值,所以,这部分的时间复杂度也是 O(n)。所以,RK 算法整体的时间复杂度就是 O(n)。
-
这里还有一个问题就是,模式串很长,相应的主串中的子串也会很长,通过上面的哈希算法计算得到的哈希值就可能很大,如果超过了计算机中整型数据可以表示的范围,那该如何解决呢?
- 刚刚我们设计的哈希算法是没有散列冲突的,也就是说,一个字符串与一个二十六进制数一一对应,不同的字符串的哈希值肯定不一样。因为我们是基于进制来表示一个字符串的,你可以类比成十进制、十六进制来思考一下。实际上,我们为了能将哈希值落在整型数据范围内,可以牺牲一下,允许哈希冲突。这个时候哈希算法该如何设计呢?
- 实际上,解决方法很简单。当我们发现一个子串的哈希值跟模式串的哈希值相等的时候,我们只需要再对比一下子串和模式串本身就好了。当然,如果子串的哈希值与模式串的哈希值不相等,那对应的子串和模式串肯定也是不匹配的,就不需要比对子串和模式串本身了
- 所以,哈希算法的冲突概率要相对控制得低一些,如果存在大量冲突,就会导致 RK 算法的时间复杂度退化,效率下降。极端情况下,如果存在大量的冲突,每次都要再对比子串和模式串本身,那时间复杂度就会退化成 O(n*m)。但也不要太悲观,一般情况下,冲突不会很多,RK 算法的效率还是比 BF 算法高的。
-
-
-
-
BM 算法的核心思想
-
BM 算法原理
-
BM 算法包含两部分,分别是坏字符规则(bad character rule)和好后缀规则(good suffix shift)。我们下面依次来看,这两个规则分别都是怎么工作的。
-
坏字符规则
-
前面两节讲的算法,在匹配的过程中,我们都是按模式串的下标从小到大的顺序,依次与主串中的字符进行匹配的。这种匹配顺序比较符合我们的思维习惯,而 BM 算法的匹配顺序比较特别,它是按照模式串下标从大到小的顺序,倒着匹配的。我画了一张图,你可以看下。
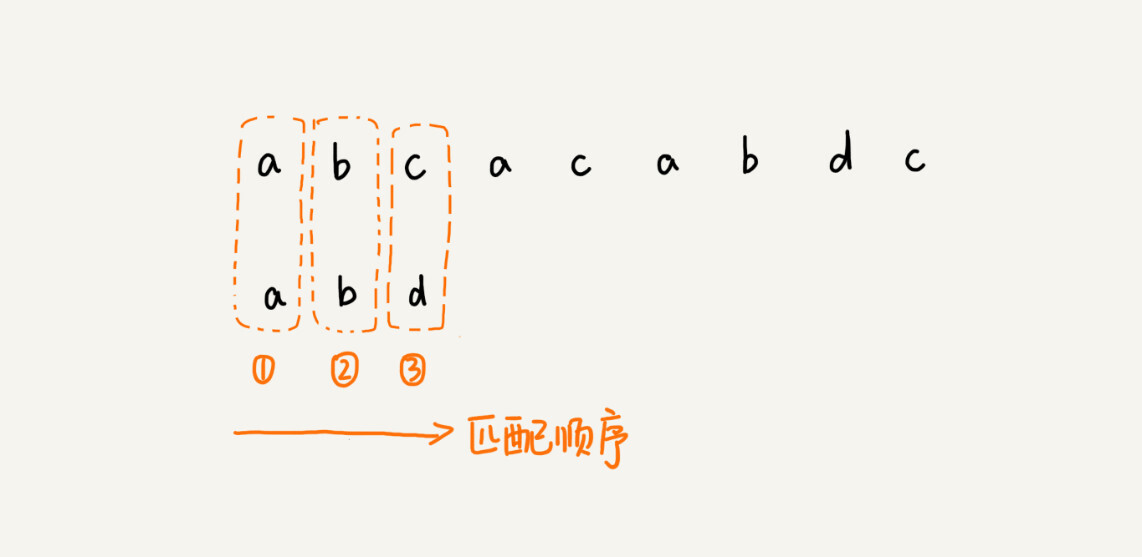
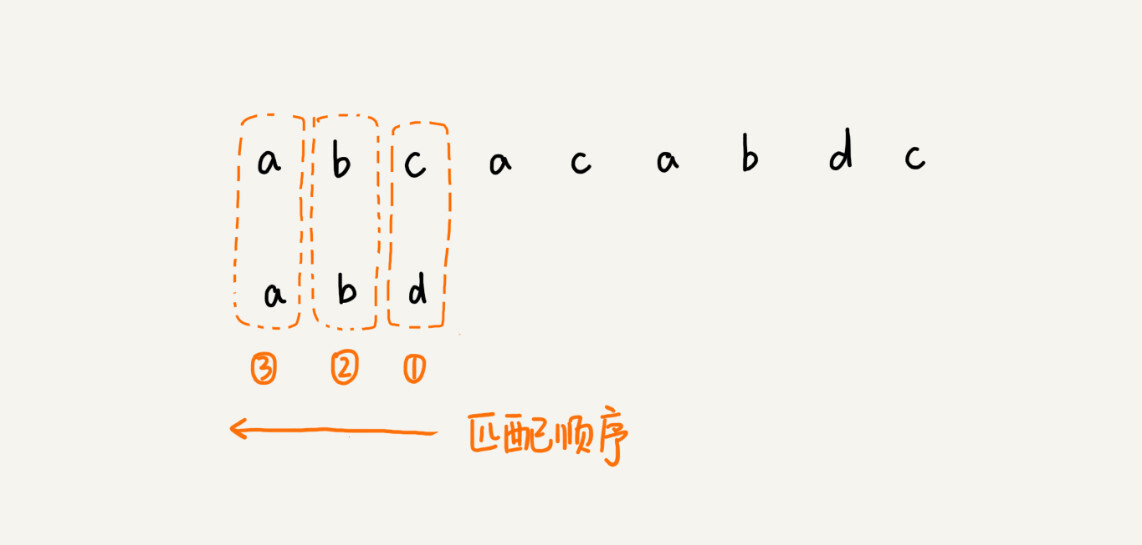
我们从模式串的末尾往前倒着匹配,当我们发现某个字符没法匹配的时候。我们把这个没有匹配的字符叫作坏字符(主串中的字符)。
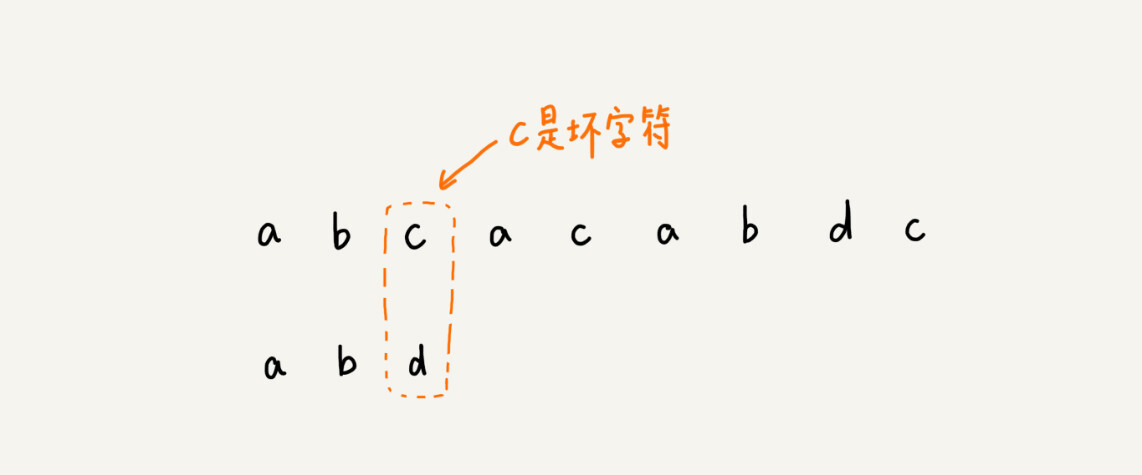 我们拿坏字符 c 在模式串中查找,发现模式串中并不存在这个字符,也就是说,字符 c 与模式串中的任何字符都不可能匹配。这个时候,我们可以将模式串直接往后滑动三位,将模式串滑动到 c 后面的位置,再从模式串的末尾字符开始比较。
我们拿坏字符 c 在模式串中查找,发现模式串中并不存在这个字符,也就是说,字符 c 与模式串中的任何字符都不可能匹配。这个时候,我们可以将模式串直接往后滑动三位,将模式串滑动到 c 后面的位置,再从模式串的末尾字符开始比较。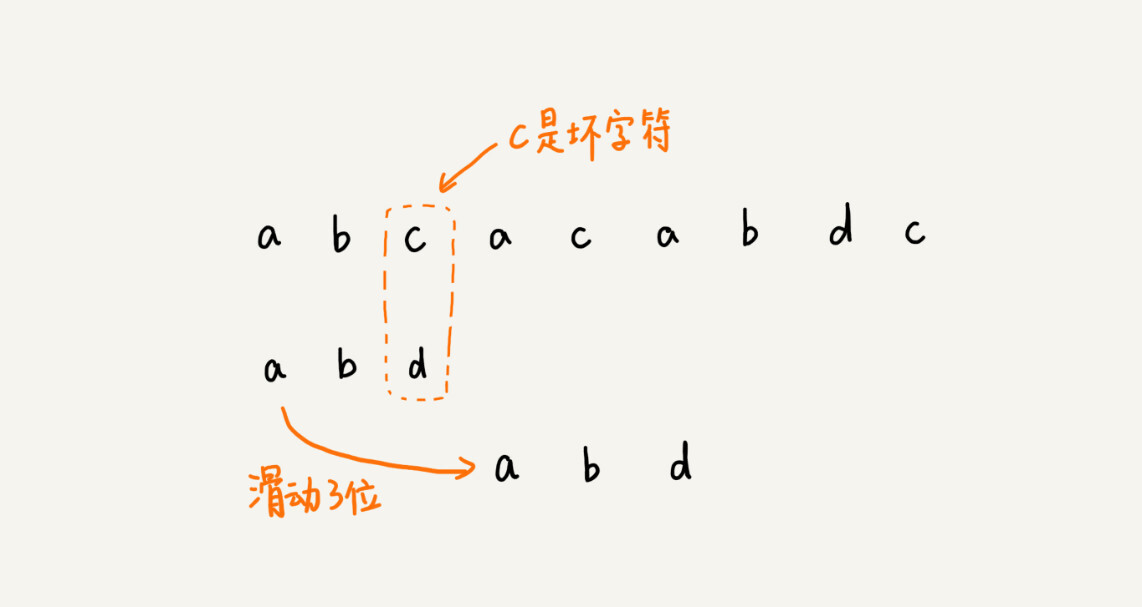
这个时候,我们发现,模式串中最后一个字符 d,还是无法跟主串中的 a 匹配,这个时候,还能将模式串往后滑动三位吗?答案是不行的。因为这个时候,坏字符 a 在模式串中是存在的,模式串中下标是 0 的位置也是字符 a。这种情况下,我们可以将模式串往后滑动两位,让两个 a 上下对齐,然后再从模式串的末尾字符开始,重新匹配。
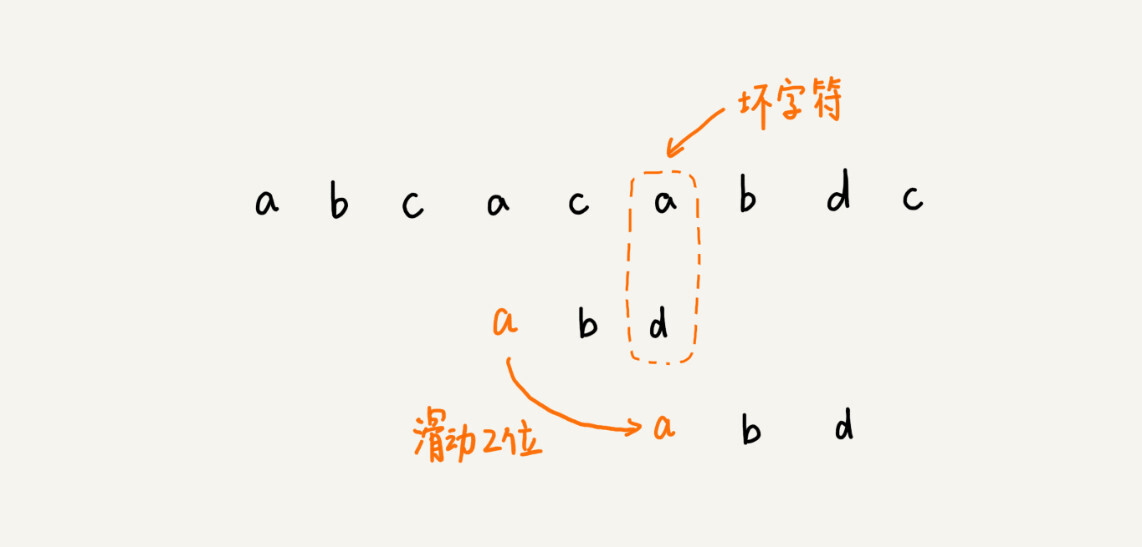
当发生不匹配的时候,我们把坏字符对应的模式串中的字符下标记作 si。如果坏字符在模式串中存在,我们把这个坏字符在模式串中的下标记作 xi。如果不存在,我们把 xi 记作 -1。那模式串往后移动的位数就等于 si-xi。(注意,我这里说的下标,都是字符在模式串的下标)。
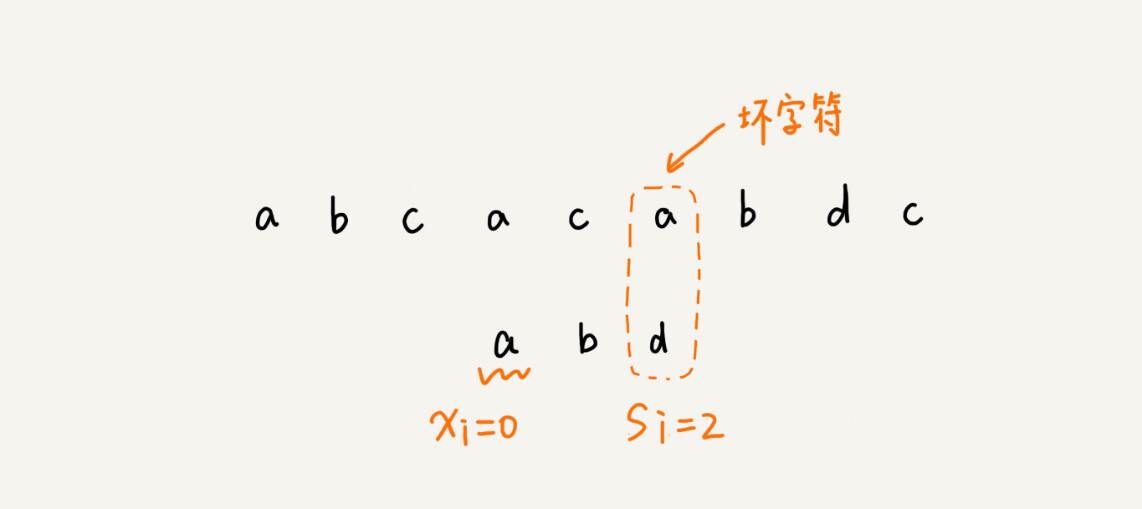
这里我要特别说明一点,如果坏字符在模式串里多处出现,那我们在计算 xi 的时候,选择最靠后的那个,因为这样不会让模式串滑动过多,导致本来可能匹配的情况被滑动略过。
利用坏字符规则,BM 算法在最好情况下的时间复杂度非常低,是 O(n/m)。比如,主串是 aaabaaabaaabaaab,模式串是 aaaa。每次比对,模式串都可以直接后移四位,所以,匹配具有类似特点的模式串和主串的时候,BM 算法非常高效。
不过,单纯使用坏字符规则还是不够的。因为根据 si-xi 计算出来的移动位数,有可能是负数,比如主串是 aaaaaaaaaaaaaaaa,模式串是 baaa。不但不会向后滑动模式串,还有可能倒退。所以,BM 算法还需要用到“好后缀规则”。
-
-
好后缀规则
-
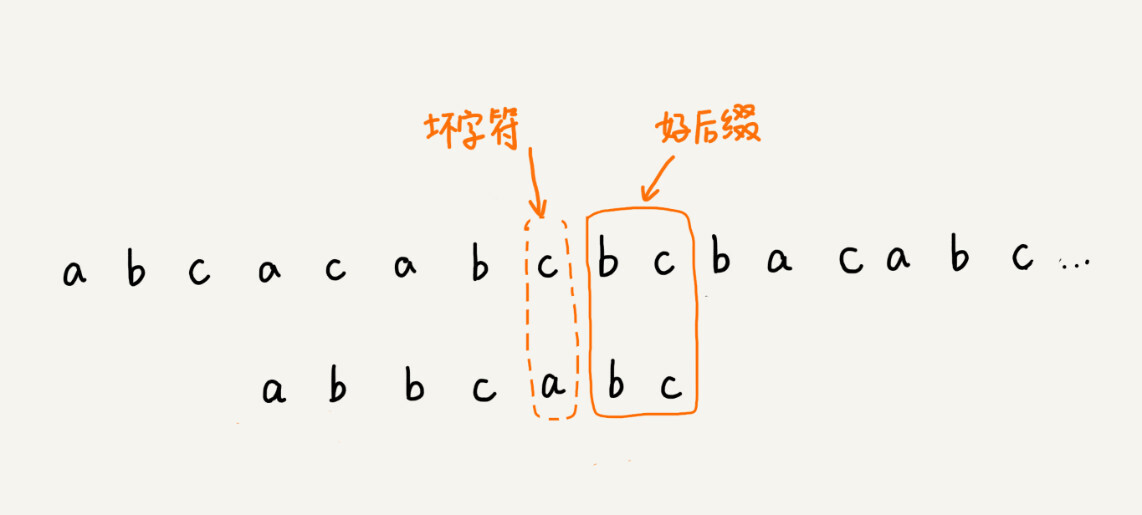
好后缀规则实际上跟坏字符规则的思路很类似。你看我下面这幅图。当模式串滑动到图中的位置的时候,模式串和主串有 2 个字符是匹配的,倒数第 3 个字符发生了不匹配的情况。
-
这个时候该如何滑动模式串呢?当然,我们还可以利用坏字符规则来计算模式串的滑动位数,不过,我们也可以使用好后缀处理规则。两种规则到底如何选择,我稍后会讲。抛开这个问题,现在我们来看,好后缀规则是怎么工作的?
-
我们把已经匹配的 bc 叫作好后缀,记作{u}。我们拿它在模式串中查找,如果找到了另一个跟{u}相匹配的子串{u},那我们就将模式串滑动到子串{u}与主串中{u}对齐的位置。
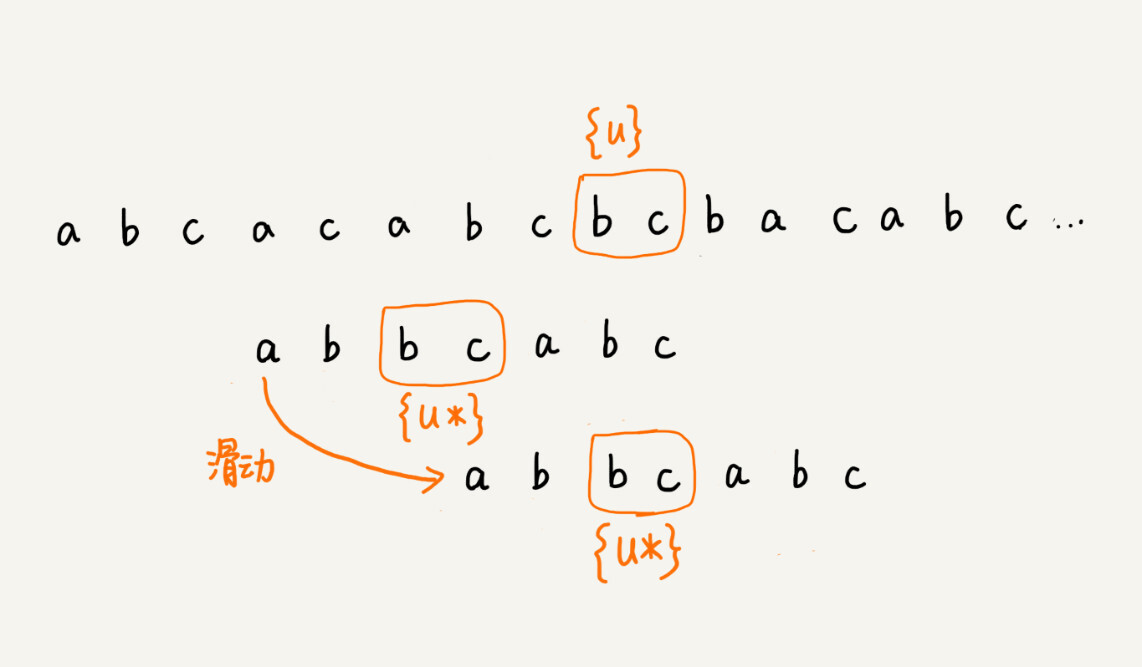
如果在模式串中找不到另一个等于{u}的子串,我们就直接将模式串,滑动到主串中{u}的后面,因为之前的任何一次往后滑动,都没有匹配主串中{u}的情况。
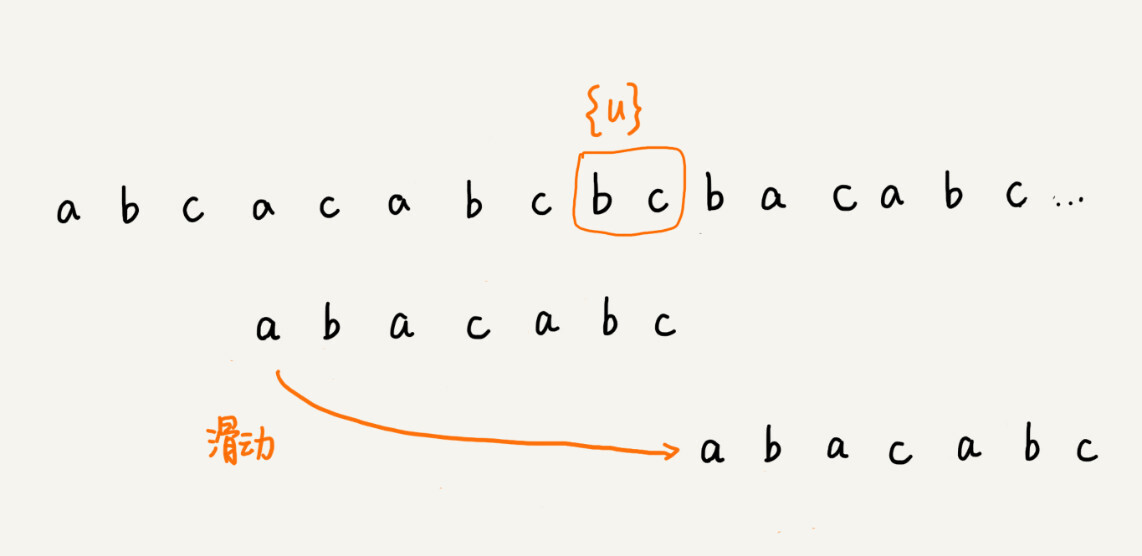
不过,当模式串中不存在等于{u}的子串时,我们直接将模式串滑动到主串{u}的后面。这样做是否有点太过头呢?我们来看下面这个例子。这里面 bc 是好后缀,尽管在模式串中没有另外一个相匹配的子串{u*},但是如果我们将模式串移动到好后缀的后面,如图所示,那就会错过模式串和主串可以匹配的情况。
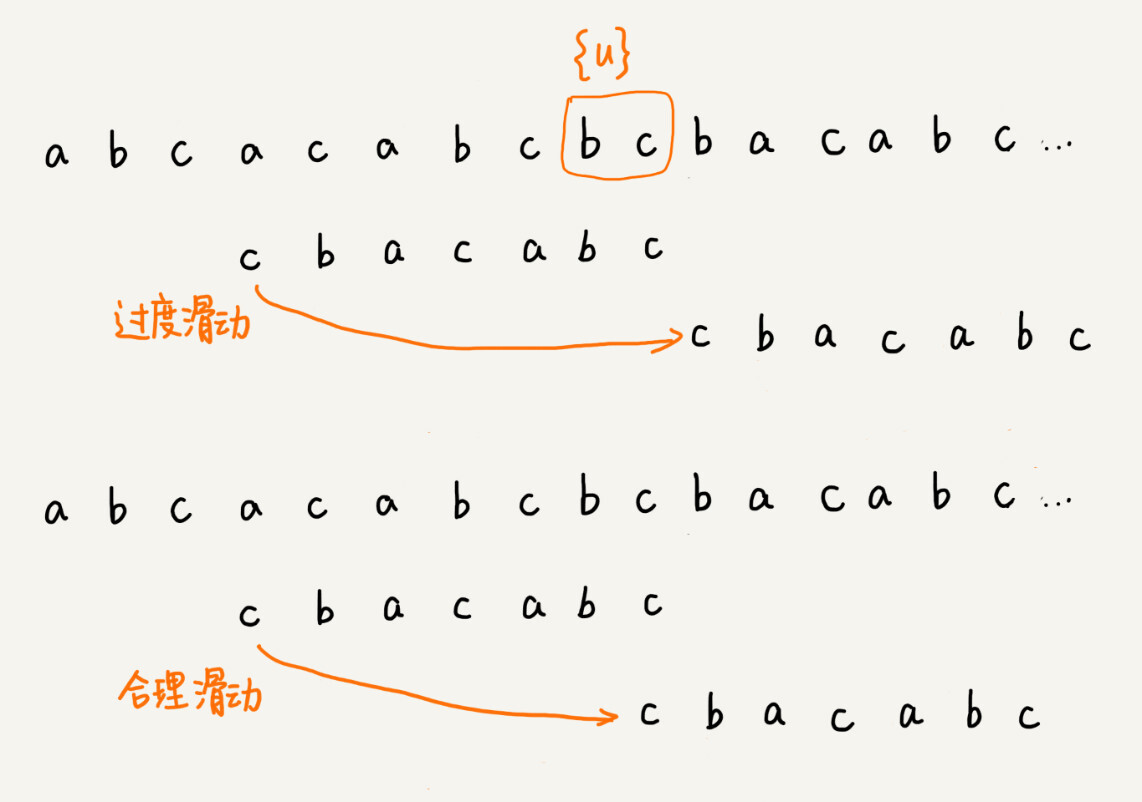
如果好后缀在模式串中不存在可匹配的子串,那在我们一步一步往后滑动模式串的过程中,只要主串中的{u}与模式串有重合,那肯定就无法完全匹配。但是当模式串滑动到前缀与主串中{u}的后缀有部分重合的时候,并且重合的部分相等的时候,就有可能会存在完全匹配的情况。
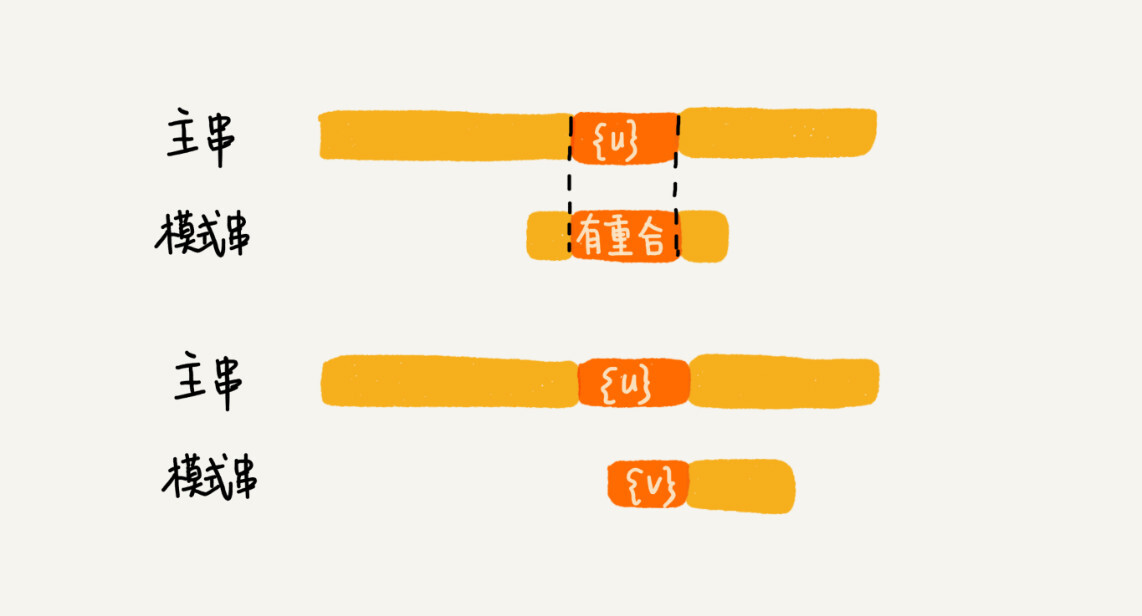
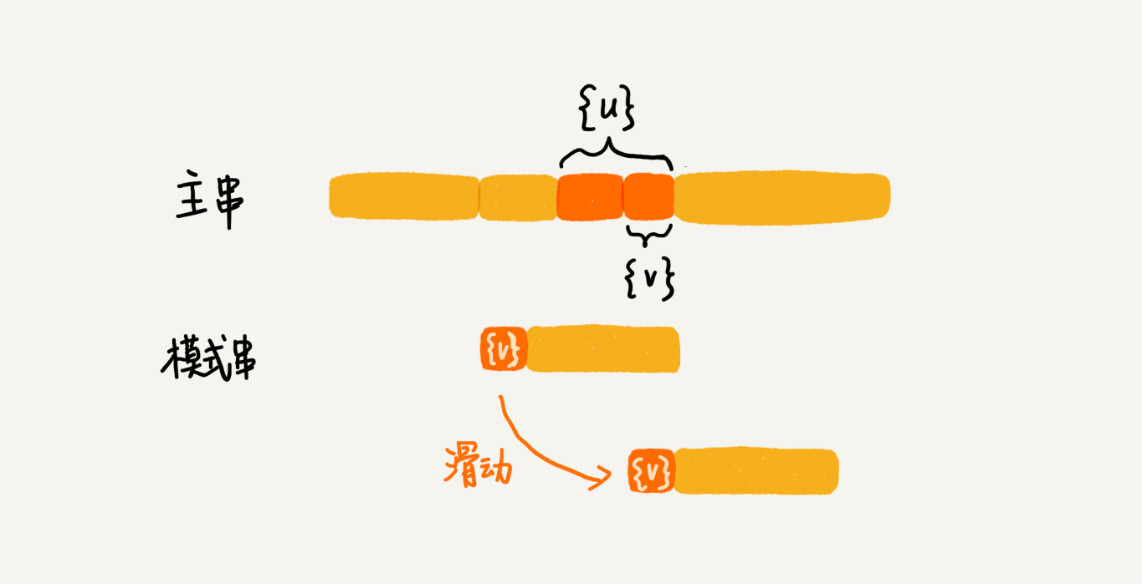
所以,针对这种情况,我们不仅要看好后缀在模式串中,是否有另一个匹配的子串,我们还要考察好后缀的后缀子串,是否存在跟模式串的前缀子串匹配的。
所谓某个字符串 s 的后缀子串,就是最后一个字符跟 s 对齐的子串,比如 abc 的后缀子串就包括 c, bc。所谓前缀子串,就是起始字符跟 s 对齐的子串,比如 abc 的前缀子串有 a,ab。我们从好后缀的后缀子串中,找一个最长的并且能跟模式串的前缀子串匹配的,假设是{v},然后将模式串滑动到如图所示的位置。
-
-
坏字符和好后缀的基本原理都讲完了,我现在回答一下前面那个问题。当模式串和主串中的某个字符不匹配的时候,如何选择用好后缀规则还是坏字符规则,来计算模式串往后滑动的位数?
-
我们可以分别计算好后缀和坏字符往后滑动的位数,然后取两个数中最大的,作为模式串往后滑动的位数。这种处理方法还可以避免我们前面提到的,根据坏字符规则,计算得到的往后滑动的位数,有可能是负数的情况。
-
-
BM 算法代码实现
-
先实现坏字符
-
“坏字符规则”本身不难理解。当遇到坏字符时,要计算往后移动的位数 si-xi,其中 xi 的计算是重点,我们如何求得 xi 呢?或者说,如何查找坏字符在模式串中出现的位置呢?
-
如果我们拿坏字符,在模式串中顺序遍历查找,这样就会比较低效,势必影响这个算法的性能。有没有更加高效的方式呢?我们之前学的散列表,这里可以派上用场了。我们可以将模式串中的每个字符及其下标都存到散列表中。这样就可以快速找到坏字符在模式串的位置下标了。
-
关于这个散列表,我们只实现一种最简单的情况,假设字符串的字符集不是很大,每个字符长度是 1 字节,我们用大小为 256 的数组,来记录每个字符在模式串中出现的位置。数组的下标对应字符的 ASCII 码值,数组中存储这个字符在模式串中出现的位置。
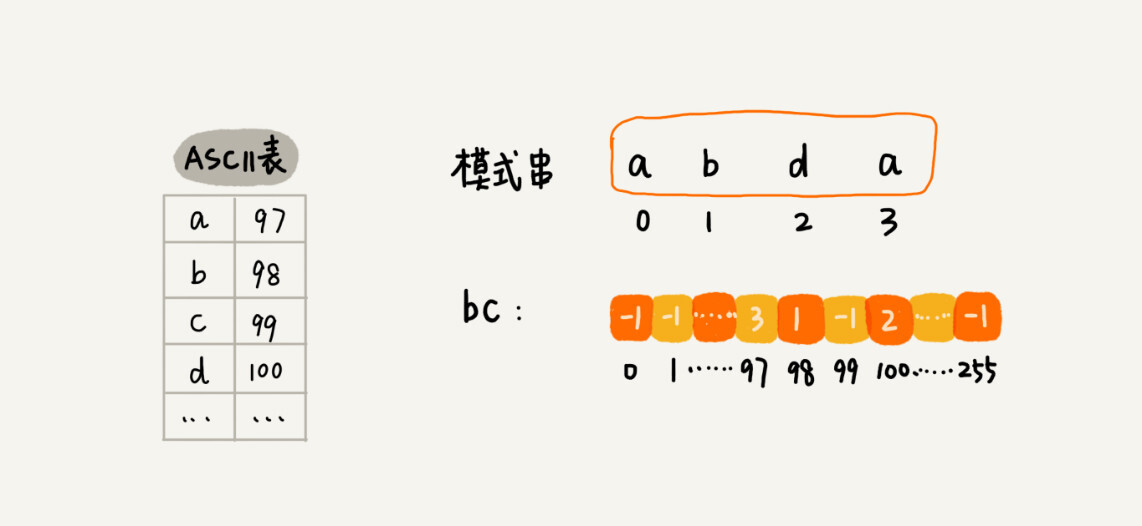
-
如果将上面的过程翻译成代码,就是下面这个样子。其中,变量 b 是模式串,m 是模式串的长度,bc 表示刚刚讲的散列表。
private const int SIZE = 256;// 全局变量或成员变量 private void GenerateBC(char[] str, int[] hashTab) { for (int i = 0; i < SIZE; i++) { hashTab[i] = -1;// 初始化散列表 } int ascii; for (int i = 0; i < str.Length; i++) { ascii = str[i]; hashTab[ascii] = i; } } -
掌握了坏字符规则之后,我们先把 BM 算法代码的大框架写好,先不考虑好后缀规则,仅用坏字符规则,并且不考虑 si-xi 计算得到的移动位数可能会出现负数的情况。
public int BMSerch(char[] str, char[] child) { int[] hashTab = new int[SIZE]; GenerateBC(child, hashTab); int childLen = child.Length; int strLen = str.Length; int idx = -1; int badAscii = -1;//坏字符 for (int i = 0; i < strLen - childLen; ) { int j = childLen - 1; for ( ; j >= 0 ; j--) { if(child[j]!=str[i+j]) break; } if (j < 0) //找到 return i; i = i + (j - hashTab[str[i + j]]); } return idx; }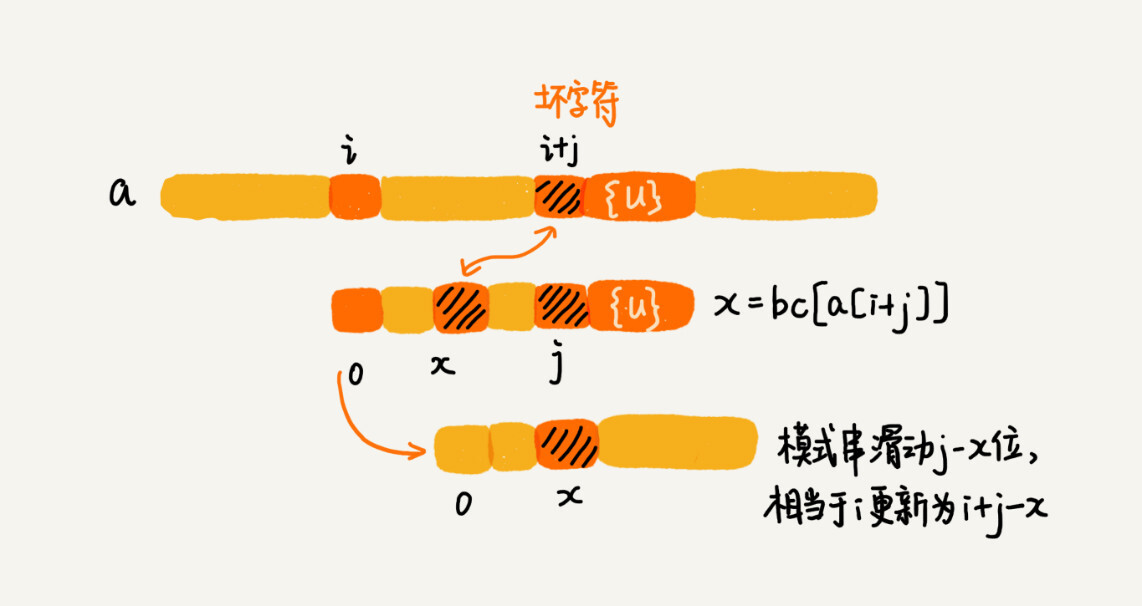
-
至此,我们已经实现了包含坏字符规则的框架代码,只剩下往框架代码中填充好后缀规则了。现在,我们就来看看,如何实现好后缀规则。它的实现要比坏字符规则复杂一些。
-
好后缀的处理规则中最核心的内容:
- 在模式串中,查找跟好后缀匹配的另一个子串;
- 在好后缀的后缀子串中,查找最长的、能跟模式串前缀子串匹配的后缀子串;
-
在不考虑效率的情况下,这两个操作都可以用很“暴力”的匹配查找方式解决。但是,如果想要 BM 算法的效率很高,这部分就不能太低效。如何来做呢?
-
因为好后缀也是模式串本身的后缀子串,所以,我们可以在模式串和主串正式匹配之前,通过预处理模式串,预先计算好模式串的每个后缀子串,对应的另一个可匹配子串的位置。
-
我们先来看,如何表示模式串中不同的后缀子串呢?因为后缀子串的最后一个字符的位置是固定的,下标为 m-1,我们只需要记录长度就可以了。通过长度,我们可以确定一个唯一的后缀子串。
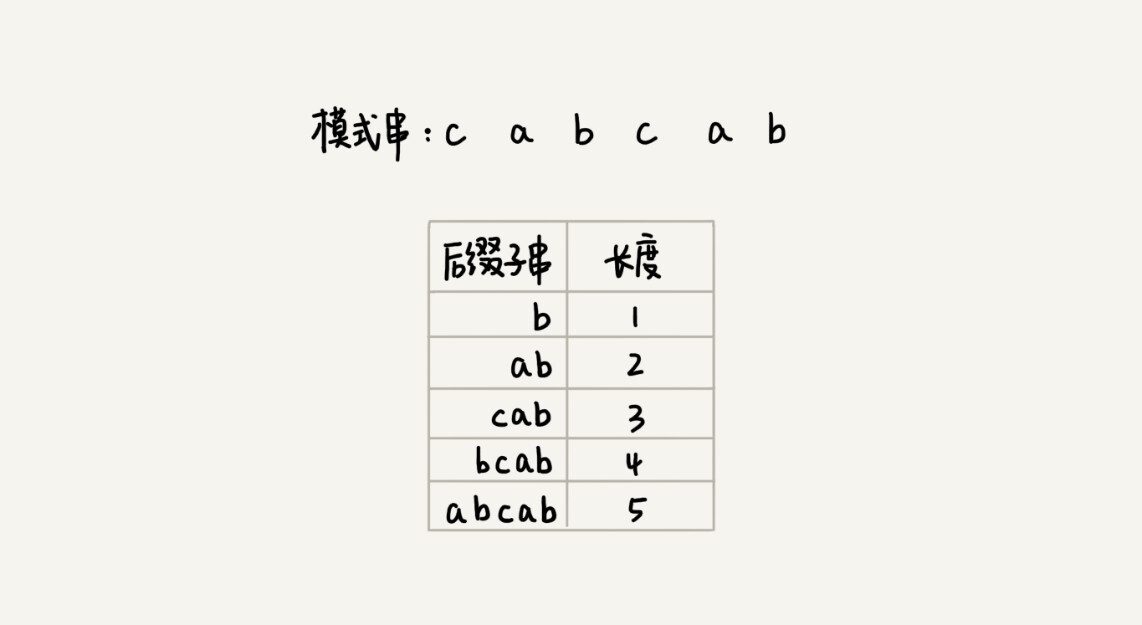
-
现在,我们要引入最关键的变量 suffix 数组。suffix 数组的下标 k,表示后缀子串的长度,下标对应的数组值存储的是,在模式串中跟好后缀{u}相匹配的子串{u*}的起始下标值。这句话不好理解,我举一个例子。

-
但是,如果模式串中有多个(大于 1 个)子串跟后缀子串{u}匹配,那 suffix 数组中该存储哪一个子串的起始位置呢?为了避免模式串往后滑动得过头了,我们肯定要存储模式串中最靠后的那个子串的起始位置,也就是下标最大的那个子串的起始位置。不过,这样处理就足够了吗?
-
我们不仅要在模式串中,查找跟好后缀匹配的另一个子串,还要在好后缀的后缀子串中,查找最长的能跟模式串前缀子串匹配的后缀子串。
-
如果我们只记录刚刚定义的 suffix,实际上,只能处理规则的前半部分,也就是,在模式串中,查找跟好后缀匹配的另一个子串。所以,除了 suffix 数组之外,我们还需要另外一个 boolean 类型的 prefix 数组,来记录模式串的后缀子串是否能匹配模式串的前缀子串

-
我们拿下标从 0 到 i 的子串(i 可以是 0 到 m-2)与整个模式串,求公共后缀子串。如果公共后缀子串的长度是 k,那我们就记录 suffix[k]=j(j 表示公共后缀子串的起始下标)。如果 j 等于 0,也就是说,公共后缀子串也是模式串的前缀子串,我们就记录 prefix[k]=true。
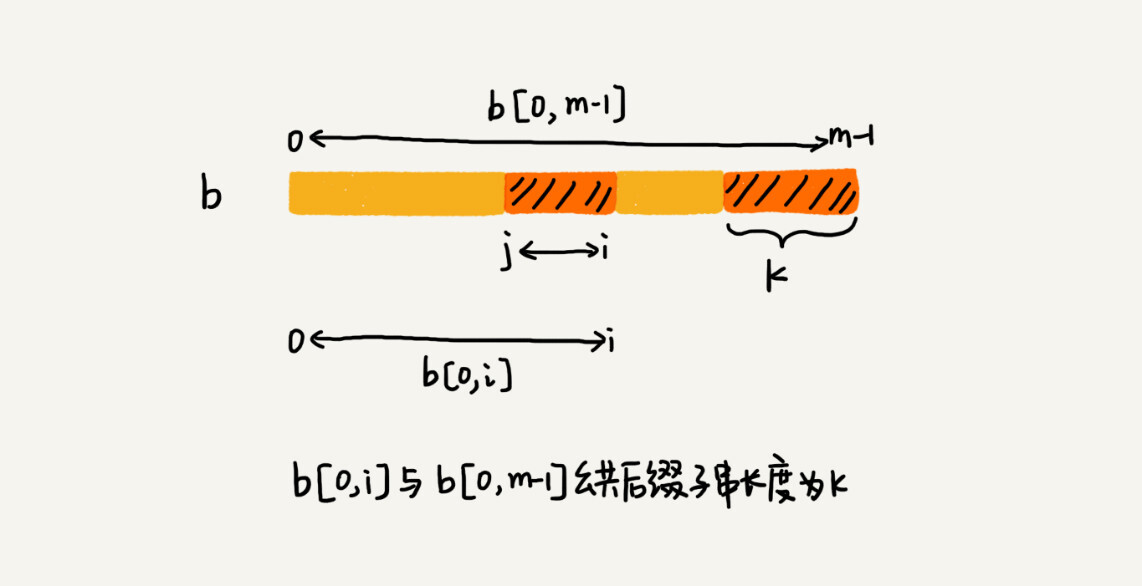
-
我们把 suffix 数组和 prefix 数组的计算过程,用代码实现出来,就是下面这个样子:
// b表示模式串,len表示长度,suffix,prefix数组事先申请好了 private void GenerateGS(char[] b, int len, int[] suffix, bool[] prefix) { for (int i = 0; i < len; i++)//初始化,注意这里长度1用0的位置去存储 { prefix[i] = false; suffix[i] = -1; } for (int i = 0; i < len; i++)//从第一种情况开始往后搜 { for (int j = 0; j < len - i - 1 ; j++)//从前开始搜,找到第一个和后缀第一个匹配的 { if (b[j] == b[len - i - 1]) { suffix[i] = j; if (j == 0) prefix[i] = true; break; } } } } -
有了这两个数组之后,我们现在来看,在模式串跟主串匹配的过程中,遇到不能匹配的字符时,如何根据好后缀规则,计算模式串往后滑动的位数?
-
假设好后缀的长度是 k。我们先拿好后缀,在 suffix 数组中查找其匹配的子串。如果 suffix[k]不等于 -1(-1 表示不存在匹配的子串),那我们就将模式串往后移动 j-suffix[k]+1 位(j 表示坏字符对应的模式串中的字符下标)。如果 suffix[k]等于 -1,表示模式串中不存在另一个跟好后缀匹配的子串片段。我们可以用下面这条规则来处理。
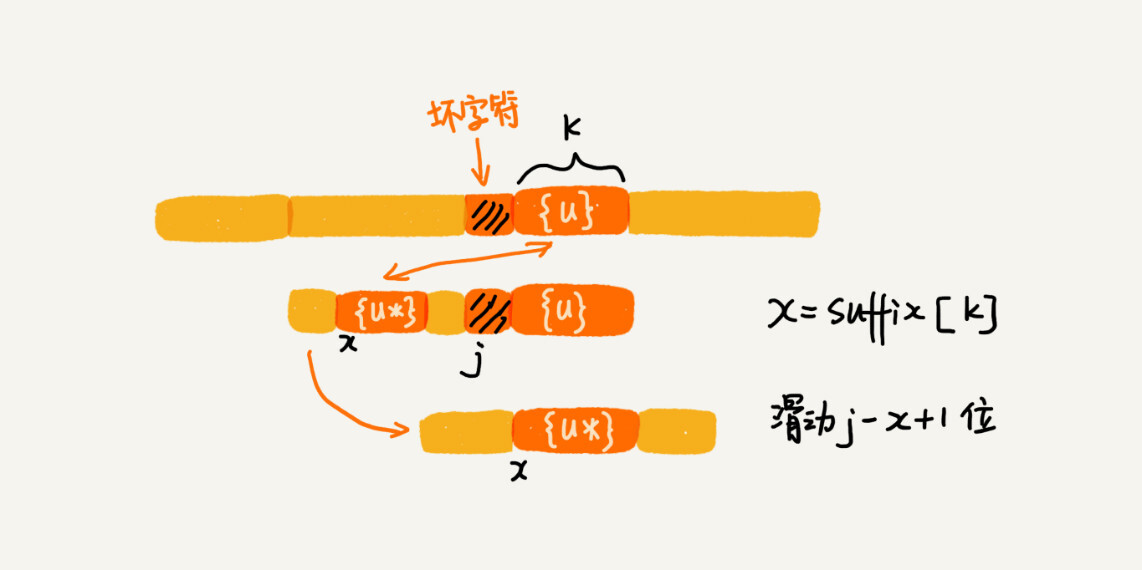
-
好后缀的后缀子串 b[r, m-1](其中,r 取值从 j+2 到 m-1)的长度 k=m-r,如果 prefix[k]等于 true,表示长度为 k 的后缀子串,有可匹配的前缀子串,这样我们可以把模式串后移 r 位。
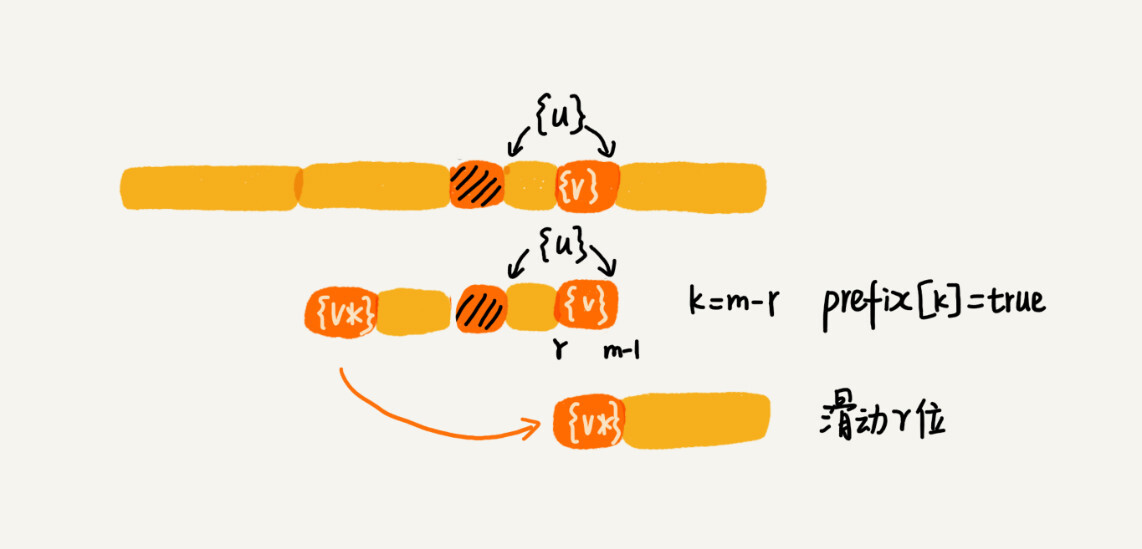
-
如果两条规则都没有找到可以匹配好后缀及其后缀子串的子串,我们就将整个模式串后移 m 位。
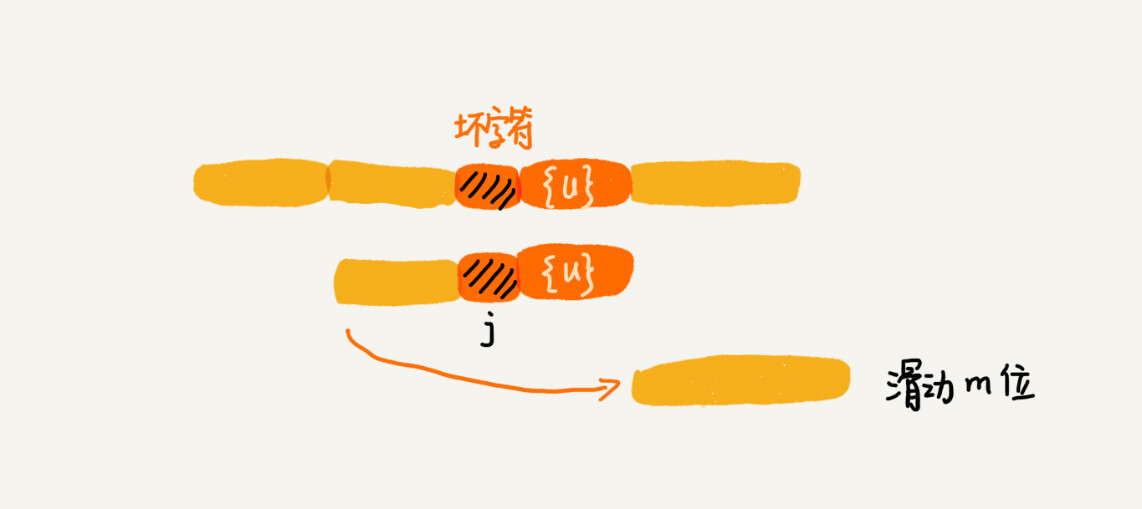
-
至此,好后缀规则的代码实现我们也讲完了。我们把好后缀规则加到前面的代码框架里,就可以得到 BM 算法的完整版代码实现。
private const int SIZE = 256; private void GenerateBC(char[] str, int[] hashTab) { for (int i = 0; i < SIZE; i++) { hashTab[i] = -1; } int ascii; for (int i = 0; i < str.Length; i++) { ascii = str[i]; hashTab[ascii] = i; } } // b表示模式串,len表示长度,suffix,prefix数组事先申请好了 private void GenerateGS(char[] b, int len, int[] suffix, bool[] prefix) { for (int i = 0; i < len; i++) { prefix[i] = false; suffix[i] = -1; } for (int i = 0; i < len; i++) { for (int j = 0; j < len - i - 1 ; j++) { if (b[j] == b[len - i - 1]) { suffix[i] = j; if (j == 0) prefix[i] = true; break; } } } } public int BMSerch(char[] str, char[] child) { int strLen = str.Length; int childLen = child.Length; int[] hashTab = new int[SIZE]; GenerateBC(child, hashTab); int[] suffix = new int[childLen]; bool[] prefix = new bool[childLen]; GenerateGS(child, childLen, suffix, prefix); int badAscii = -1;//坏字符 for (int i = 0; i <= strLen - childLen; ) { int j = childLen - 1; for ( ; j >= 0 ; j--) { if(child[j]!=str[i+j]) break; } if (j < 0) //找到 return i; int x = j - hashTab[str[i + j]]; int y = 0; if (j < childLen - 1)//有好后缀 { y = MoveByGS(j, childLen, suffix, prefix); } i += Mathf.Max(x, y); } return -1; } // j表示坏字符对应的模式串中的坏字符下标; m表示模式串长度 private int MoveByGS(int j, int m, int[] suffix, bool[] prefix) { int k = m - 1 - j;//好后缀的长度 if (suffix[k] != -1) return j - suffix[k] + 1; for ( int r = j + 2 ; r < m-1; r++) { if (prefix[m - r]) return r; } return m; }
-
-
-
-
KMP算法
-
KMP 算法基本原理
-
基于上面BM算法的好后缀和坏字符这里我们可以类比一下,在模式串和主串匹配的过程中,把不能匹配的那个字符仍然叫作坏字符,把已经匹配的那段字符串叫作好前缀。
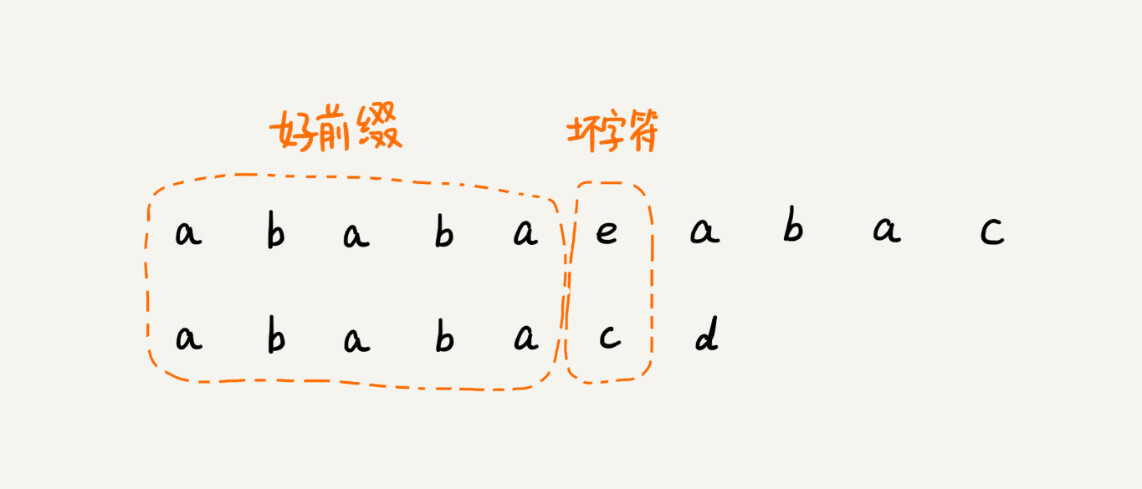
-
当遇到坏字符的时候,我们就要把模式串往后滑动,在滑动的过程中,只要模式串和好前缀有上下重合,前面几个字符的比较,就相当于拿好前缀的后缀子串,跟模式串的前缀子串在比较。这个比较的过程能否更高效了呢?可以不用一个字符一个字符地比较了吗?
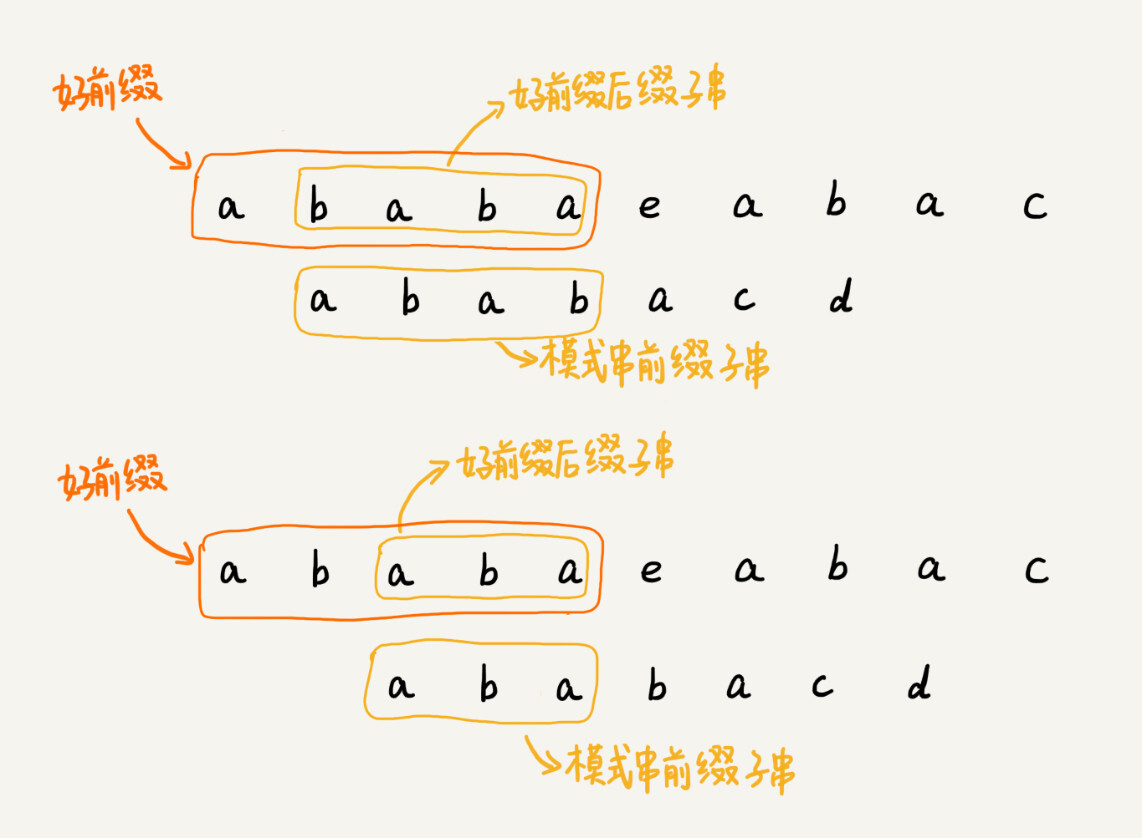
-
KMP 算法就是在试图寻找一种规律:在模式串和主串匹配的过程中,当遇到坏字符后,对于已经比对过的好前缀,能否找到一种规律,将模式串一次性滑动很多位?
-
我们只需要拿好前缀本身,在它的后缀子串中,查找最长的那个可以跟好前缀的前缀子串匹配的。假设最长的可匹配的那部分前缀子串是{v},长度是 k。我们把模式串一次性往后滑动 j-k 位,相当于,每次遇到坏字符的时候,我们就把 j 更新为 k,i 不变,然后继续比较。

-
为了表述起来方便,我把好前缀的所有后缀子串中,最长的可匹配前缀子串的那个后缀子串,叫作最长可匹配后缀子串;对应的前缀子串,叫作最长可匹配前缀子串。

-
如何来求好前缀的最长可匹配前缀和后缀子串呢?我发现,这个问题其实不涉及主串,只需要通过模式串本身就能求解。所以,我就在想,能不能事先预处理计算好,在模式串和主串匹配的过程中,直接拿过来就用呢?
-
类似 BM 算法中的 bc、suffix、prefix 数组,KMP 算法也可以提前构建一个数组,用来存储模式串中每个前缀(这些前缀都有可能是好前缀)的最长可匹配前缀子串的结尾字符下标。我们把这个数组定义为 next 数组,很多书中还给这个数组起了一个名字,叫失效函数(failure function)。
-
数组的下标是每个前缀结尾字符下标,数组的值是这个前缀的最长可以匹配前缀子串的结尾字符下标。如下
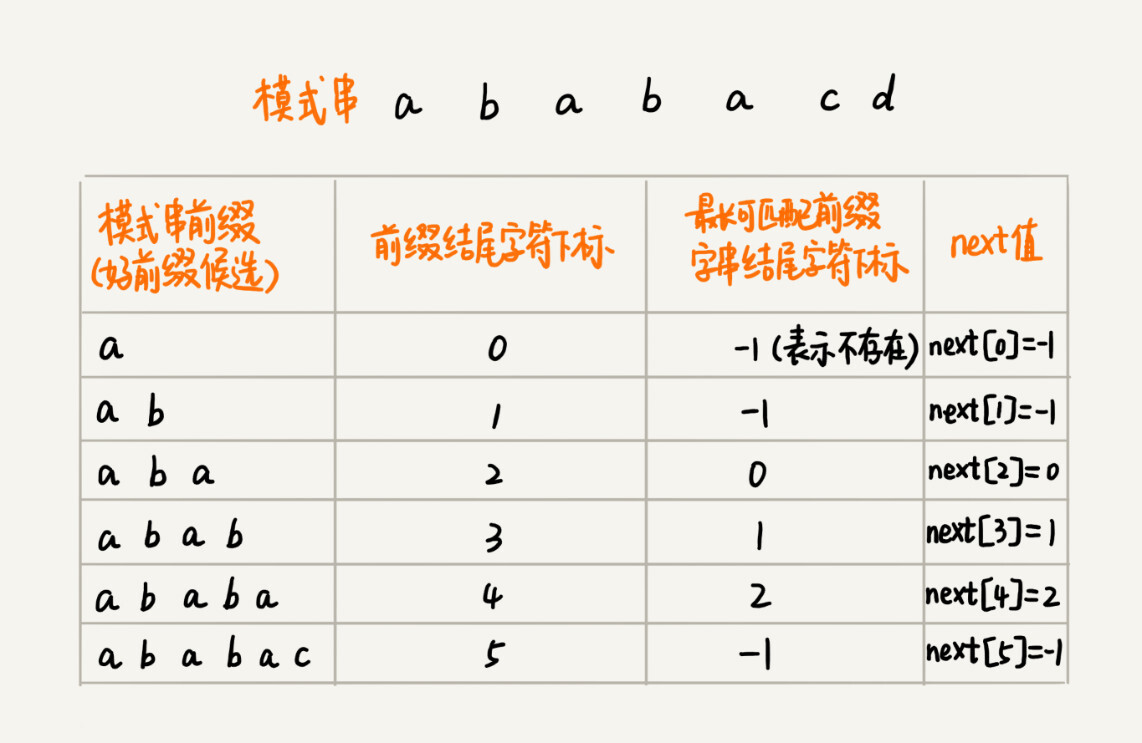
-
有了 next 数组,我们很容易就可以实现 KMP 算法了。我先假设 next 数组已经计算好了,先给出 KMP 算法的框架代码。
public int kmp(char[] main, char[] child) { int mainLen = main.Length; int childLen = child.Length; int[] next = GetNexts(child, childLen); int j = 0; for (int i = 0; i < mainLen; i++) { while (j > 0 && main[i] != child[j])//当两个不匹配的时候j的指针借助next数组回退 j = next[j - 1] + 1; if (main[i] == child[j]) j++; if (j == childLen) return i - childLen + 1; } return -1; }
-
-
失效函数计算方法
-
KMP 算法的基本原理讲完了,我们现在来看最复杂的部分,也就是 next 数组是如何计算出来的?
-
当然,我们可以用非常笨的方法,比如要计算下面这个模式串 b 的 next[4],我们就把 b[0, 4]的所有后缀子串,从长到短找出来,依次看看,是否能跟模式串的前缀子串匹配。很显然,这个方法也可以计算得到 next 数组,但是效率非常低。有没有更加高效的方法呢?

-
我们按照下标从小到大,依次计算 next 数组的值。当我们要计算 next[i]的时候,前面的 next[0],next[1],……,next[i-1]应该已经计算出来了。利用已经计算出来的 next 值,我们是否可以快速推导出 next[i]的值呢?
-
如果 next[i-1]=k-1(i表示后缀长度,k表示前缀位置),也就是说,子串 b[0, k-1]是 b[0, i-1]的最长可匹配前缀子串。如果子串 b[0, k-1]的下一个字符 b[k],与 b[0, i-1]的下一个字符 b[i]匹配,那子串 b[0, k]就是 b[0, i]的最长可匹配前缀子串。所以,next[i]等于 k。但是,如果 b[0, k-1]的下一字符 b[k]跟 b[0, i-1]的下一个字符 b[i]不相等呢?这个时候就不能简单地通过 next[i-1]得到 next[i]了。这个时候该怎么办呢?
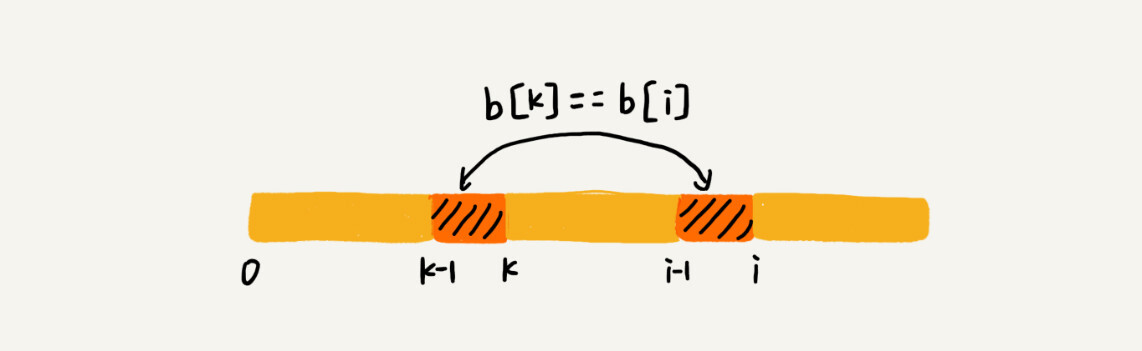
-
我们假设 b[0, i]的最长可匹配后缀子串是 b[r, i]。如果我们把最后一个字符去掉,那 b[r, i-1]肯定是 b[0, i-1]的可匹配后缀子串,但不一定是最长可匹配后缀子串。所以,既然 b[0, i-1]最长可匹配后缀子串对应的模式串的前缀子串的下一个字符并不等于 b[i],那么我们就可以考察 b[0, i-1]的次长可匹配后缀子串 b[x, i-1]对应的可匹配前缀子串 b[0, i-1-x]的下一个字符 b[i-x]是否等于 b[i]。如果等于,那 b[x, i]就是 b[0, i]的最长可匹配后缀子串。
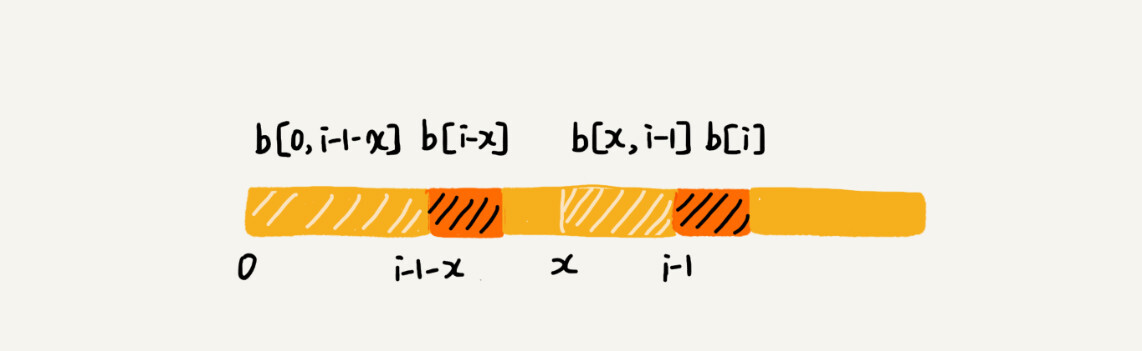
-
可是,如何求得 b[0, i-1]的次长可匹配后缀子串呢?次长可匹配后缀子串肯定被包含在最长可匹配后缀子串中,而最长可匹配后缀子串又对应最长可匹配前缀子串 b[0, y]。于是,查找 b[0, i-1]的次长可匹配后缀子串,这个问题就变成,查找 b[0, y]的最长匹配后缀子串的问题了。
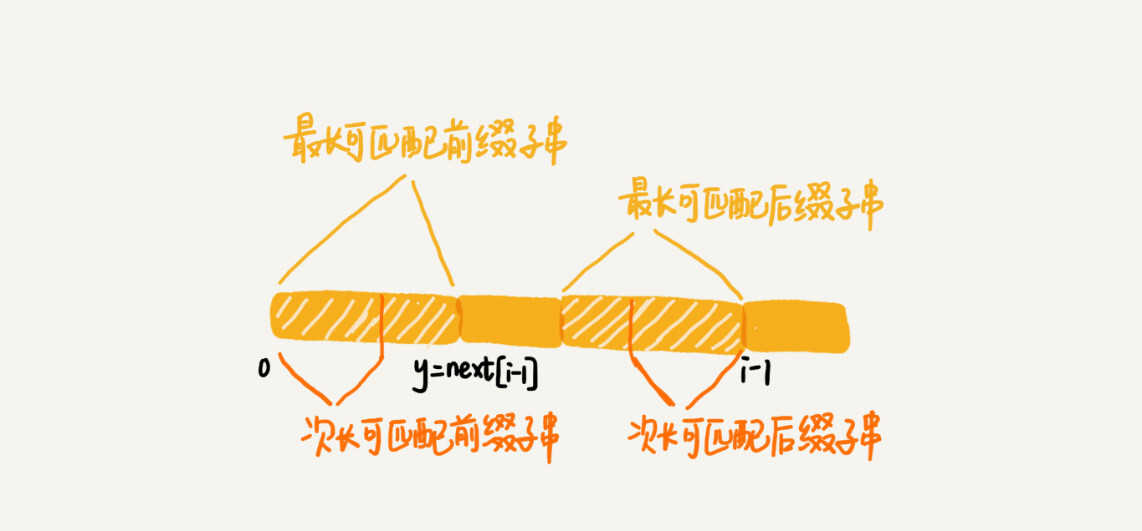
-
按照这个思路,我们可以考察完所有的 b[0, i-1]的可匹配后缀子串 b[y, i-1],直到找到一个可匹配的后缀子串,它对应的前缀子串的下一个字符等于 b[i],那这个 b[y, i]就是 b[0, i]的最长可匹配后缀子串。
private int[] GetNext(char[] child , int len) { int[] next = new int[len]; next[0] = -1; int j = -1; for (int i = 1; i < len; i++) { while (j != -1 && child[j + 1] != child[i]) { j = next[j]; } if (child[j + 1] == child[i]) j++; next[i] = j; } return next; }
-
-
-
Trie树
-
什么是“Trie 树”?
-
Trie 树,也叫“字典树”。顾名思义,它是一个树形结构。它是一种专门处理字符串匹配的数据结构,用来解决在一组字符串集合中快速查找某个字符串的问题。
-
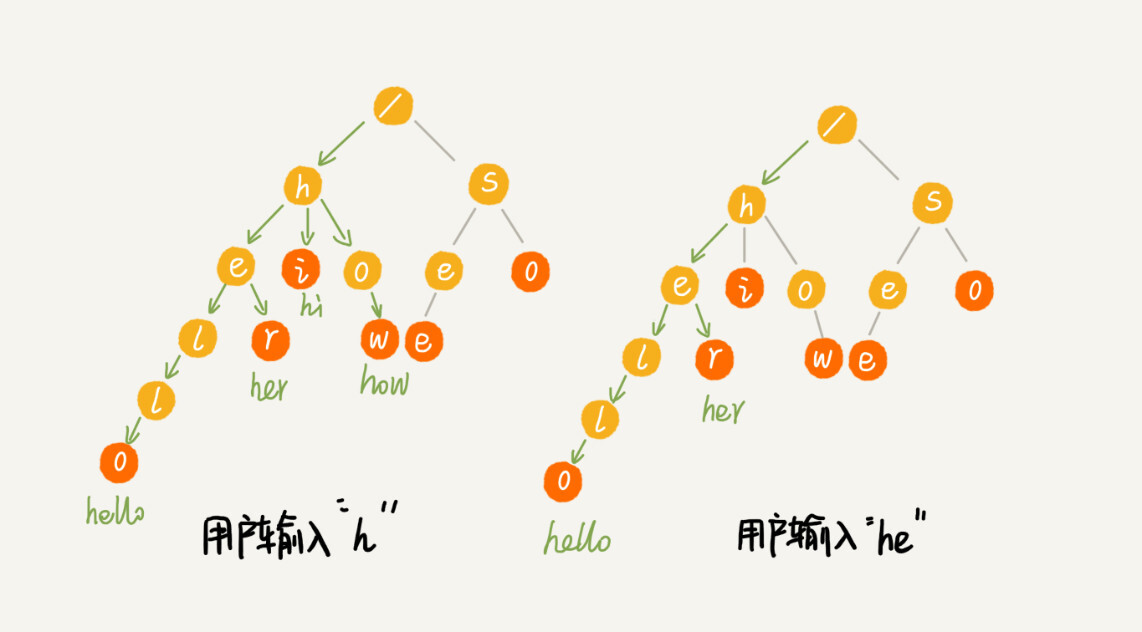
我们有 6 个字符串,它们分别是:how,hi,her,hello,so,see。我们希望在里面多次查找某个字符串是否存在。如果每次查找,都是拿要查找的字符串跟这 6 个字符串依次进行字符串匹配,那效率就比较低,有没有更高效的方法呢?
-
这个时候,我们就可以先对这 6 个字符串做一下预处理,组织成 Trie 树的结构,之后每次查找,都是在 Trie 树中进行匹配查找。Trie 树的本质,就是利用字符串之间的公共前缀,将重复的前缀合并在一起。最后构造出来的就是下面这个图中的样子。
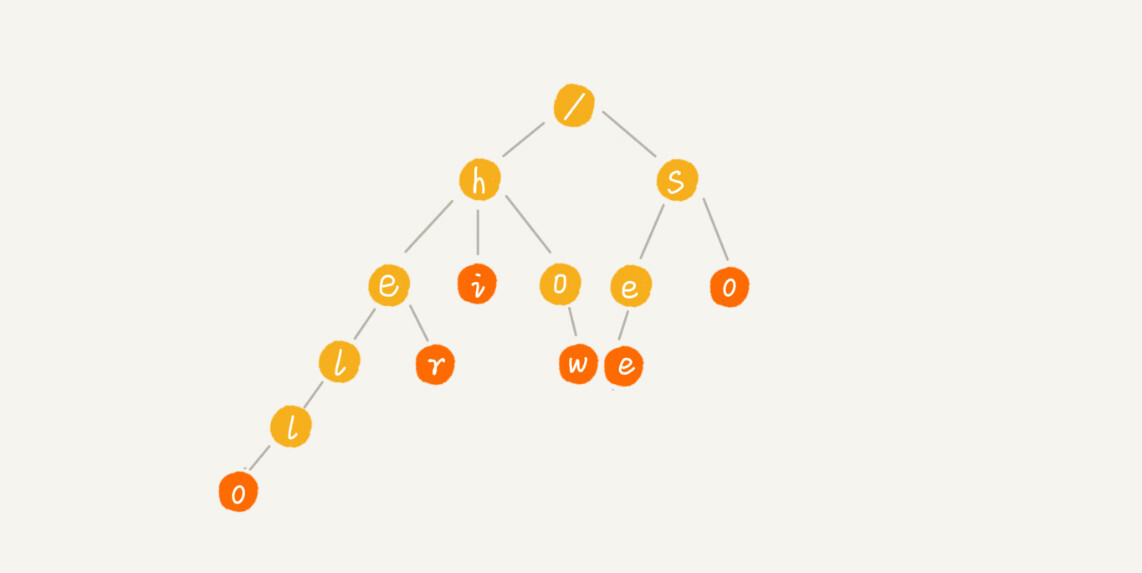
-
其中,根节点不包含任何信息。每个节点表示一个字符串中的字符,从根节点到红色节点的一条路径表示一个字符串(注意:红色节点并不都是叶子节点)。
-
Trie 树是怎么构造出来的?
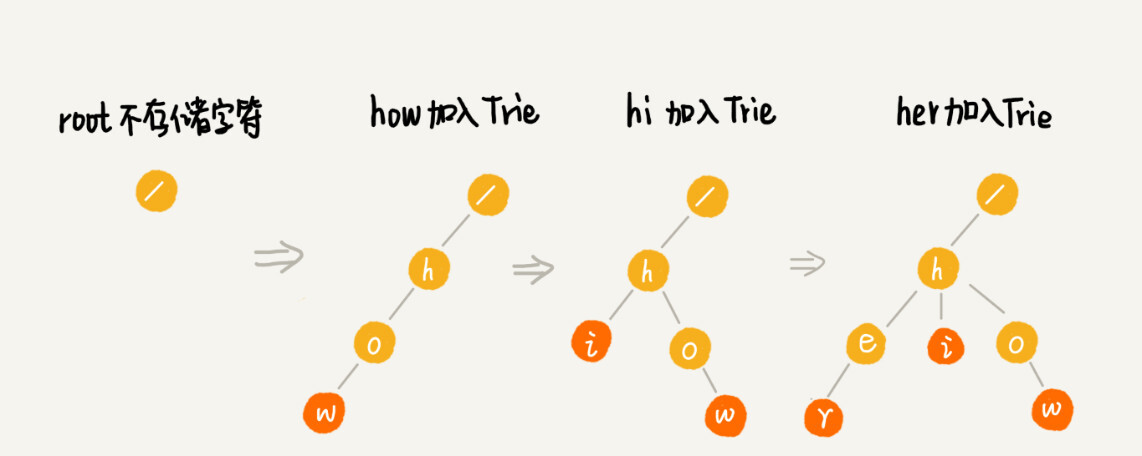
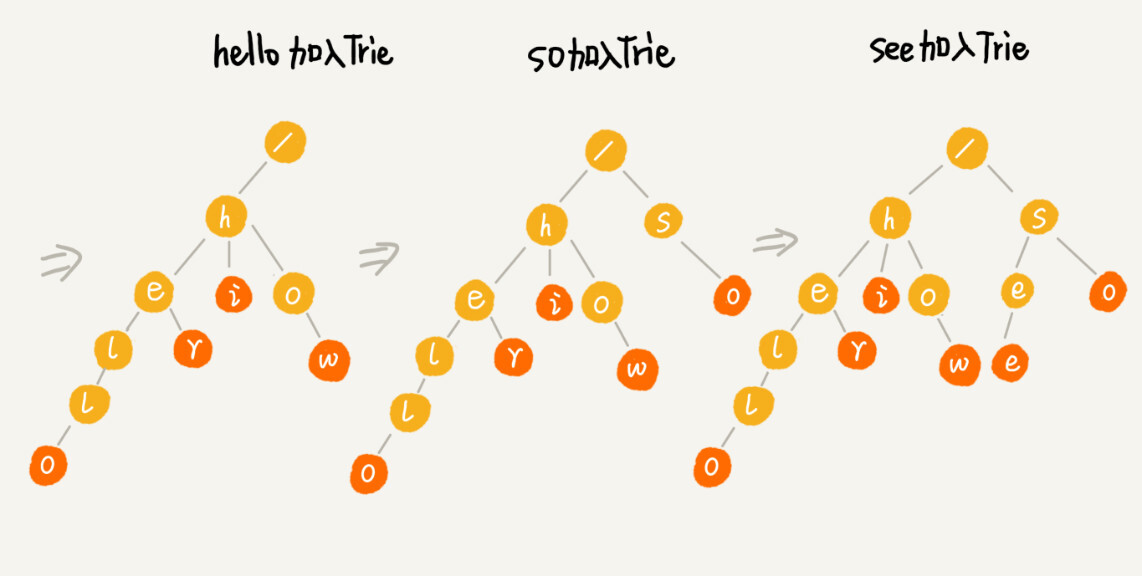
-
当我们在 Trie 树中查找一个字符串的时候,比如查找字符串“her”,那我们将要查找的字符串分割成单个的字符 h,e,r,然后从 Trie 树的根节点开始匹配。如图所示,绿色的路径就是在 Trie 树中匹配的路径
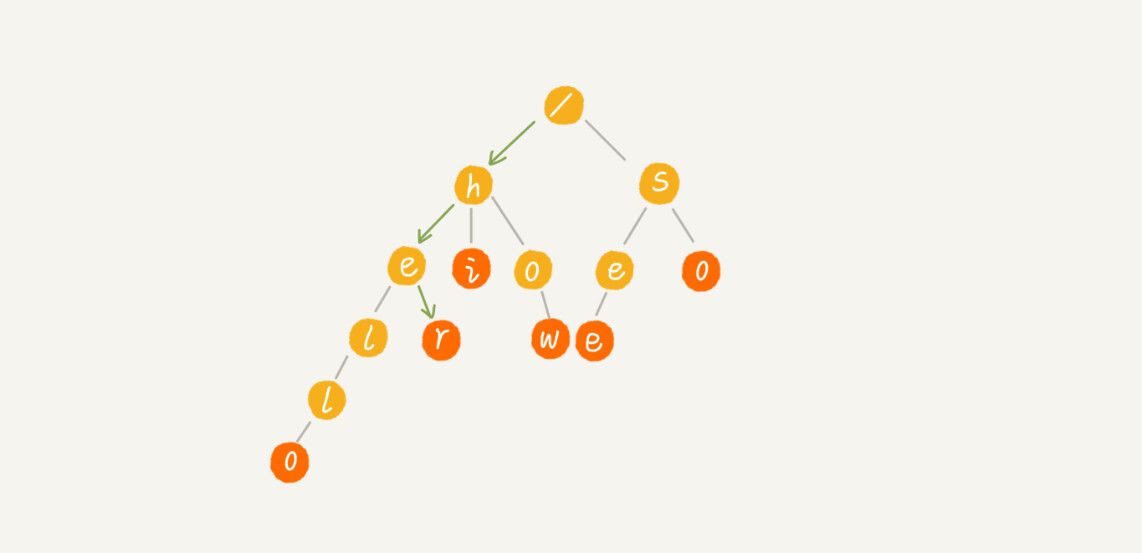
-
如果我们要查找的是字符串“he”呢?我们还用上面同样的方法,从根节点开始,沿着某条路径来匹配,如图所示,绿色的路径,是字符串“he”匹配的路径。但是,路径的最后一个节点“e”并不是红色的。也就是说,“he”是某个字符串的前缀子串,但并不能完全匹配任何字符串。
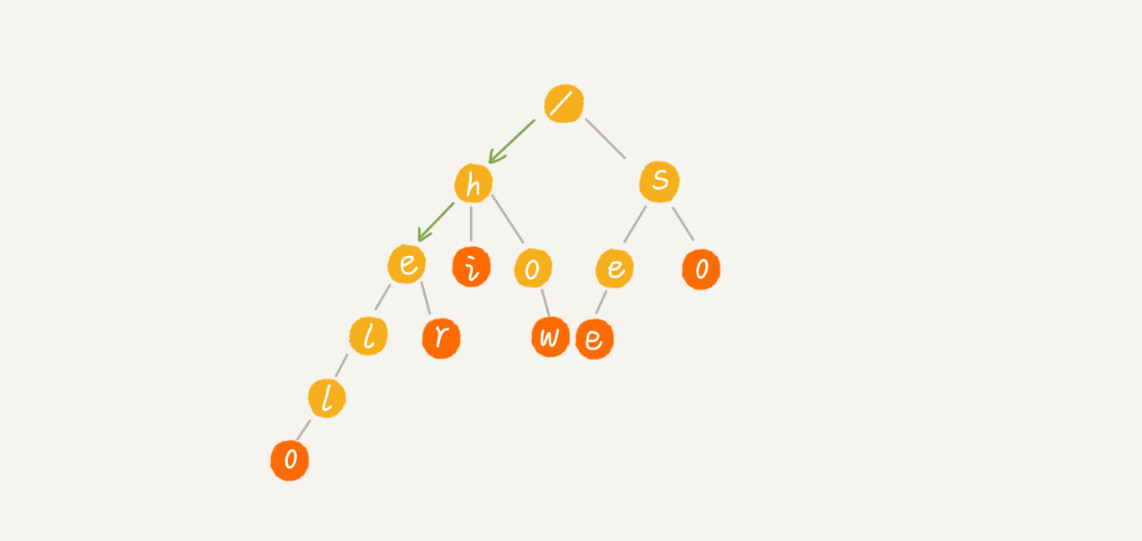
-
-
Trie 树的实现
-
Trie 树主要有两个操作
- 将字符串集合构造成 Trie 树。这个过程分解开来的话,就是一个将字符串插入到 Trie 树的过程。
- 是在 Trie 树中查询一个字符串。
-
如何存储一个 Trie 树
-
Trie 树是一个多叉树。我们知道,二叉树中,一个节点的左右子节点是通过两个指针来存储的,如下所示 Java 代码。那对于多叉树来说,我们怎么存储一个节点的所有子节点的指针呢?
-
借助散列表的思想,我们通过一个下标与字符一一映射的数组,来存储子节点的指针。这句话稍微有点抽象,不怎么好懂,我画了一张图你可以看看。
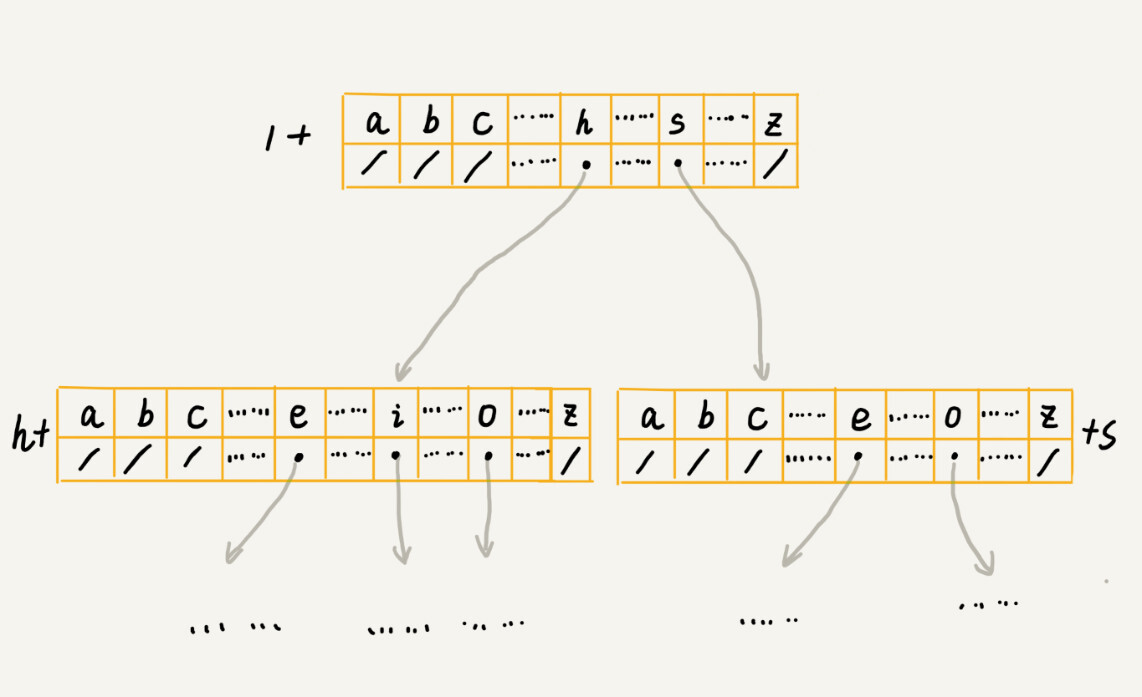
-
假设我们的字符串中只有从 a 到 z 这 26 个小写字母,我们在数组中下标为 0 的位置,存储指向子节点 a 的指针,下标为 1 的位置存储指向子节点 b 的指针,以此类推,下标为 25 的位置,存储的是指向的子节点 z 的指针。如果某个字符的子节点不存在,我们就在对应的下标的位置存储 null。
class TrieNode { char data; TrieNode children[26]; } -
当我们在 Trie 树中查找字符串的时候,我们就可以通过字符的 ASCII 码减去“a”的 ASCII 码,迅速找到匹配的子节点的指针。比如,d 的 ASCII 码减去 a 的 ASCII 码就是 3,那子节点 d 的指针就存储在数组中下标为 3 的位置中。
-
代码实现
public class Trie { private TrieNode root = new TrieNode('/'); // 存储无意义字符 // 往Trie树中插入一个字符串 public void insert(char[] text) { TrieNode p = root; for (int i = 0; i < text.length; ++i) { int index = text[i] - 'a'; if (p.children[index] == null) { TrieNode newNode = new TrieNode(text[i]); p.children[index] = newNode; } p = p.children[index]; } p.isEndingChar = true; } // 在Trie树中查找一个字符串 public boolean find(char[] pattern) { TrieNode p = root; for (int i = 0; i < pattern.length; ++i) { int index = pattern[i] - 'a'; if (p.children[index] == null) { return false; // 不存在pattern } p = p.children[index]; } if (p.isEndingChar == false) return false; // 不能完全匹配,只是前缀 else return true; // 找到pattern } public class TrieNode { public char data; public TrieNode[] children = new TrieNode[26]; public boolean isEndingChar = false; public TrieNode(char data) { this.data = data; } } }
-
-
-
在 Trie 树中,查找某个字符串的时间复杂度是多少?
- 如果要在一组字符串中,频繁地查询某些字符串,用 Trie 树会非常高效。构建 Trie 树的过程,需要扫描所有的字符串,时间复杂度是 O(n)(n 表示所有字符串的长度和)。但是一旦构建成功之后,后续的查询操作会非常高效。
- 构建好 Trie 树后,在其中查找字符串的时间复杂度是 O(k),k 表示要查找的字符串的长度。
-
Trie 树真的很耗内存吗?
-
实际上,Trie 树的变体有很多,都可以在一定程度上解决内存消耗的问题。比如,缩点优化,就是对只有一个子节点的节点,而且此节点不是一个串的结束节点,可以将此节点与子节点合并。这样可以节省空间,但却增加了编码难度。
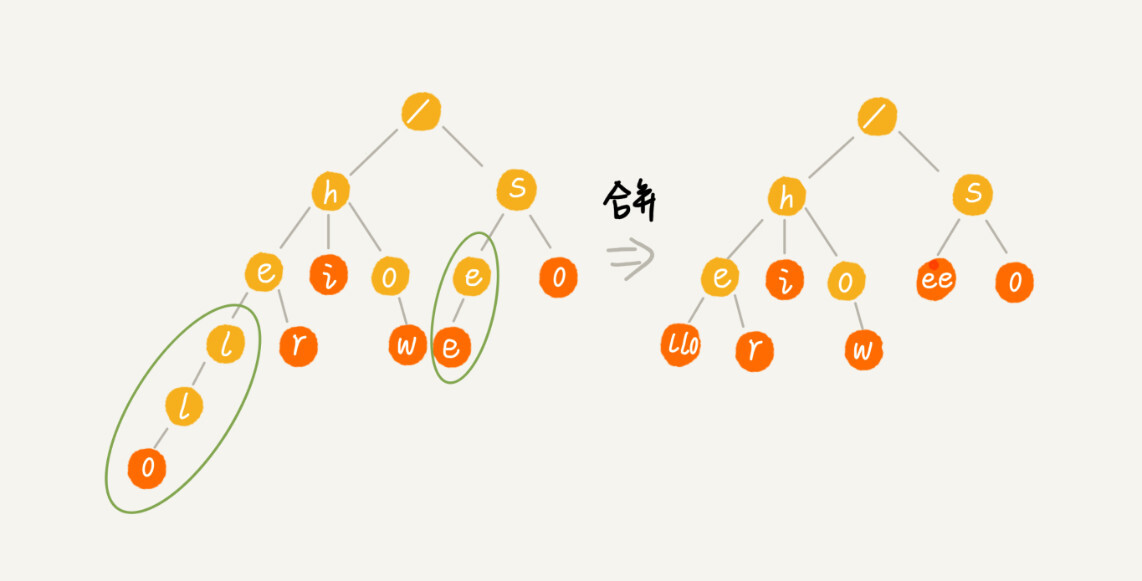
-
-
Trie 树与散列表、红黑树的比较
- 字符串中包含的字符集不能太大。我们前面讲到,如果字符集太大,那存储空间可能就会浪费很多。即便可以优化,但也要付出牺牲查询、插入效率的代价。
- 要求字符串的前缀重合比较多,不然空间消耗会变大很多。
- 如果要用 Trie 树解决问题,那我们就要自己从零开始实现一个 Trie 树,还要保证没有 bug,这个在工程上是将简单问题复杂化,除非必须,一般不建议这样做。
- 我们知道,通过指针串起来的数据块是不连续的,而 Trie 树中用到了指针,所以,对缓存并不友好,性能上会打个折扣。
- 综合这几点,针对在一组字符串中查找字符串的问题,我们在工程中,更倾向于用散列表或者红黑树。因为这两种数据结构,我们都不需要自己去实现,直接利用编程语言中提供的现成类库就行了。
- 实际上,Trie 树只是不适合精确匹配查找,这种问题更适合用散列表或者红黑树来解决。Trie 树比较适合的是查找前缀匹配的字符串,也就是类似下列问题的场景。
-
如何利用 Trie 树,实现搜索关键词的提示功能?
-
我们假设关键词库由用户的热门搜索关键词组成。我们将这个词库构建成一个 Trie 树。当用户输入其中某个单词的时候,把这个词作为一个前缀子串在 Trie 树中匹配。为了讲解方便,我们假设词库里只有 hello、her、hi、how、so、see 这 6 个关键词。当用户输入了字母 h 的时候,我们就把以 h 为前缀的 hello、her、hi、how 展示在搜索提示框内。当用户继续键入字母 e 的时候,我们就把以 he 为前缀的 hello、her 展示在搜索提示框内。这就是搜索关键词提示的最基本的算法原理。
-
Trie 树的这个应用可以扩展到更加广泛的一个应用上,就是自动输入补全,比如输入法自动补全功能、IDE 代码编辑器自动补全功能、浏览器网址输入的自动补全功能等等。
-
-
-
AC自动机
-
AC 自动机算法,全称是 Aho-Corasick 算法。其实,Trie 树跟 AC 自动机之间的关系,就像单串匹配中朴素的串匹配算法,跟 KMP 算法之间的关系一样,只不过前者针对的是多模式串而已。所以,AC 自动机实际上就是在 Trie 树之上,加了类似 KMP 的 next 数组,只不过此处的 next 数组是构建在树上罢了。如果代码表示,就是下面这个样子
public class AcNode { public char data; public AcNode[] children = new AcNode[26]; // 字符集只包含a~z这26个字符 public boolean isEndingChar = false; // 结尾字符为true public int length = -1; // 当isEndingChar=true时,记录模式串长度 public AcNode fail; // 失败指针 public AcNode(char data) { this.data = data; } }所以,AC 自动机的构建,包含两个操作:
- 将多个模式串构建成 Trie 树
- 在 Trie 树上构建失败指针(相当于 KMP 中的失效函数 next 数组)。
-
建好 Trie 树之后,如何在它之上构建失败指针?
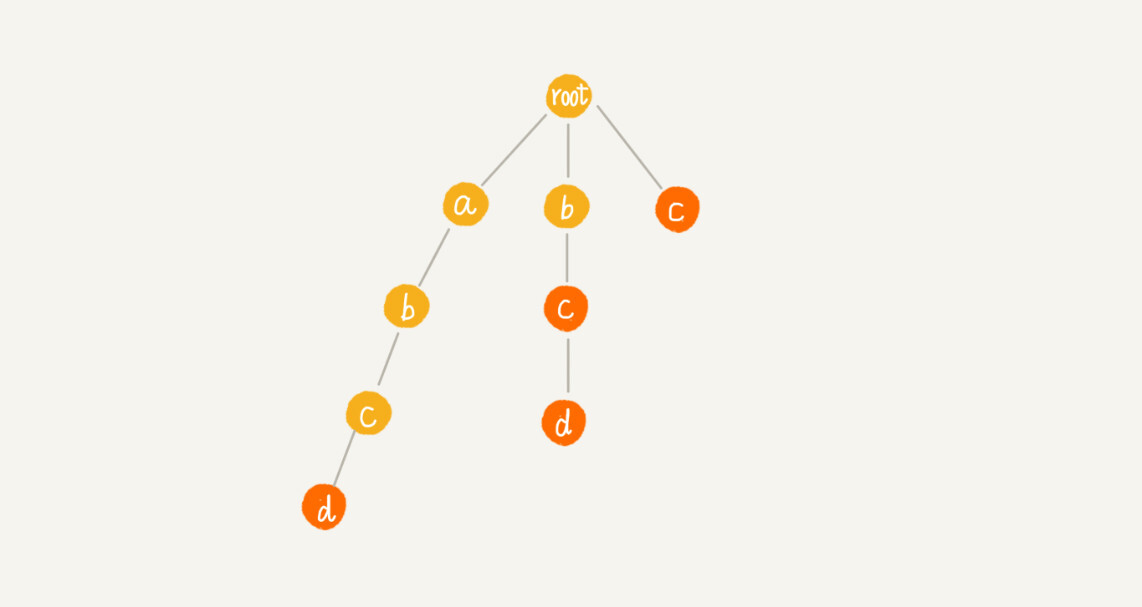
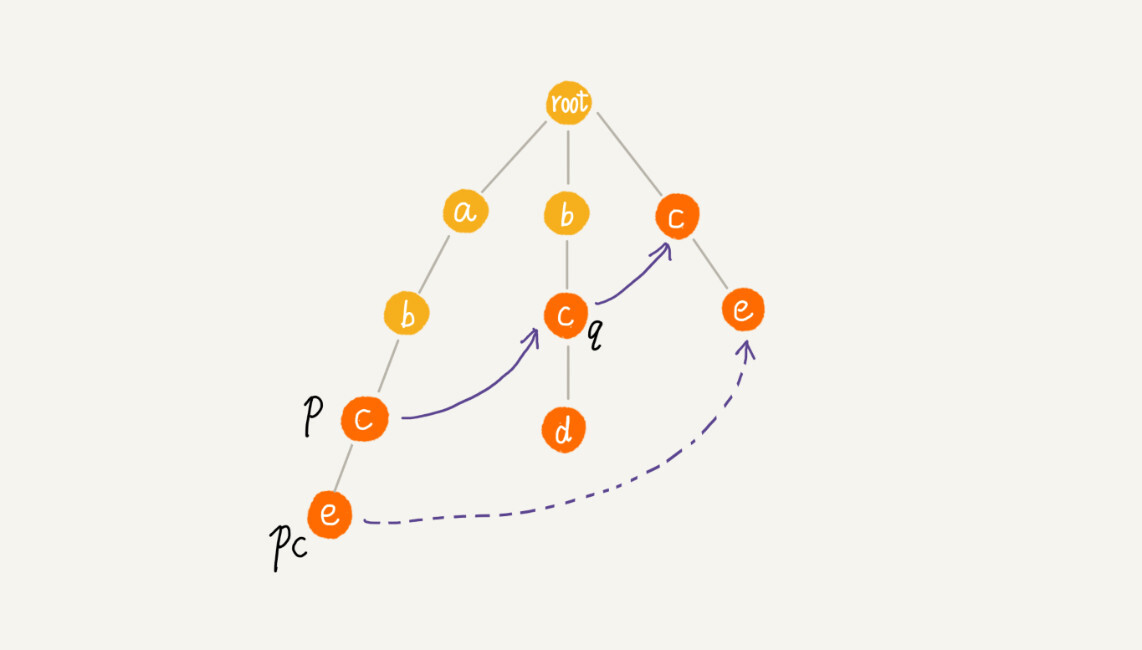
这里有 4 个模式串,分别是 c,bc,bcd,abcd;主串是 abcd。Trie 树中的每一个节点都有一个失败指针,它的作用和构建过程,跟 KMP 算法中的 next 数组极其相似
假设我们沿 Trie 树走到 p 节点,也就是下图中的紫色节点,那 p 的失败指针就是从 root 走到紫色节点形成的字符串 abc,跟所有模式串前缀匹配的最长可匹配后缀子串,就是箭头指的 bc 模式串。
这里的最长可匹配后缀子串,我稍微解释一下。字符串 abc 的后缀子串有两个 bc,c,我们拿它们与其他模式串匹配,如果某个后缀子串可以匹配某个模式串的前缀,那我们就把这个后缀子串叫作可匹配后缀子串。
我们从可匹配后缀子串中,找出最长的一个,就是刚刚讲到的最长可匹配后缀子串。我们将 p 节点的失败指针指向那个最长匹配后缀子串对应的模式串的前缀的最后一个节点,就是下图中箭头指向的节点。
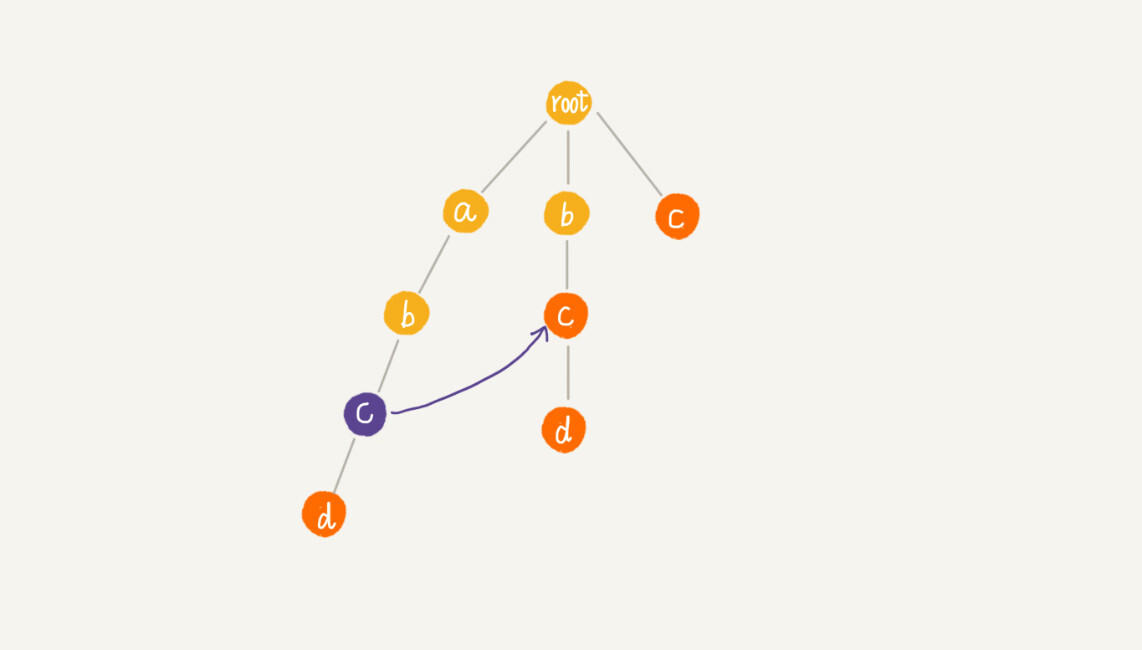
计算每个节点的失败指针这个过程看起来有些复杂。其实,如果我们把树中相同深度的节点放到同一层,那么某个节点的失败指针只有可能出现在它所在层的上一层。
我们可以像 KMP 算法那样,当我们要求某个节点的失败指针的时候,我们通过已经求得的、深度更小的那些节点的失败指针来推导。也就是说,我们可以逐层依次来求解每个节点的失败指针。所以,失败指针的构建过程,是一个按层遍历树的过程。
首先 root 的失败指针为 NULL,也就是指向自己。当我们已经求得某个节点 p 的失败指针之后,如何寻找它的子节点的失败指针呢?
我们假设节点 p 的失败指针指向节点 q,我们看节点 p 的子节点 pc 对应的字符,是否也可以在节点 q 的子节点中找到。如果找到了节点 q 的一个子节点 qc,对应的字符跟节点 pc 对应的字符相同,则将节点 pc 的失败指针指向节点 qc。
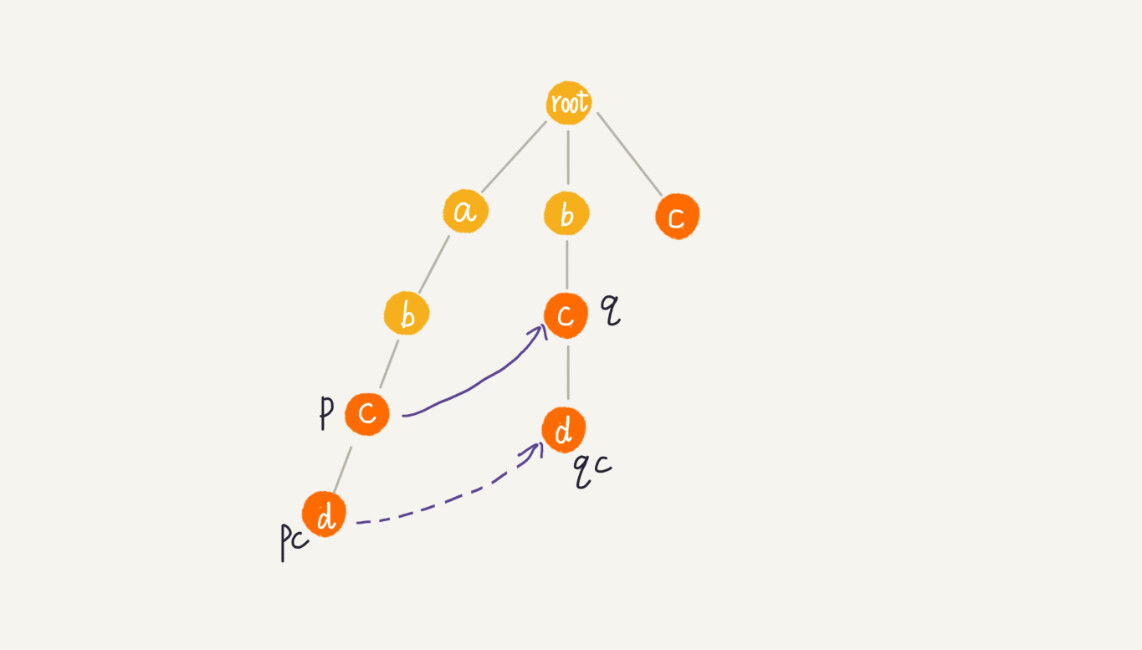
如果节点 q 中没有子节点的字符等于节点 pc 包含的字符,则令 q=q->fail(fail 表示失败指针,这里有没有很像 KMP 算法里求 next 的过程?),继续上面的查找,直到 q 是 root 为止,如果还没有找到相同字符的子节点,就让节点 pc 的失败指针指向 root。
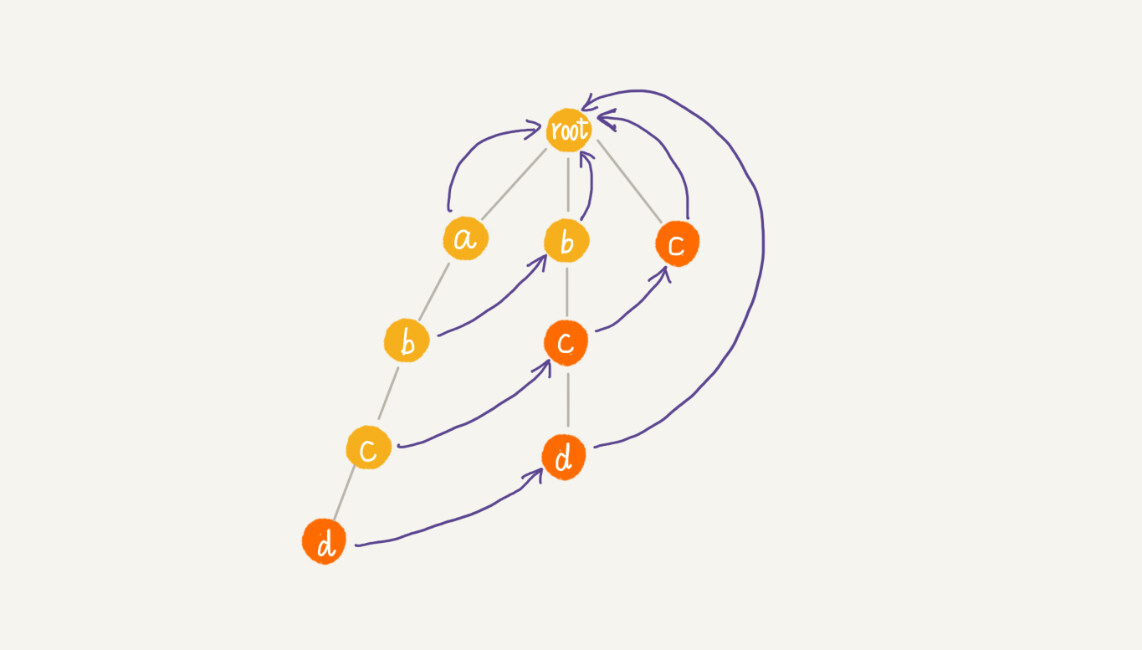
//构建失败指针,结合图理解 public void buildFailurePointer() { Queue<AcNode> queue = new LinkedList<>(); root.fail = null; queue.add(root); while (!queue.isEmpty()) { AcNode p = queue.remove(); for (int i = 0; i < 26; ++i) { AcNode pc = p.children[i]; if (pc == null) continue; if (p == root) { pc.fail = root; } else { AcNode q = p.fail; while (q != null) { AcNode qc = q.children[pc.data - 'a']; if (qc != null) { pc.fail = qc; break; } q = q.fail; } if (q == null) { pc.fail = root; } } queue.add(pc); } } }通过按层来计算每个节点的子节点的失效指针,刚刚举的那个例子,最后构建完成之后的 AC 自动机就是下面这个样子:
-
如何在 AC 自动机上匹配主串?
-
我们还是拿之前的例子来讲解。在匹配过程中,主串从 i=0 开始,AC 自动机从指针 p=root 开始,假设模式串是 b,主串是 a。
- 如果 p 指向的节点有一个等于 b[i]的子节点 x,我们就更新 p 指向 x,这个时候我们需要通过失败指针,检测一系列失败指针为结尾的路径是否是模式串。这一句不好理解,你可以结合代码看。处理完之后,我们将 i 加一,继续这两个过程;
- 如果 p 指向的节点没有等于 b[i]的子节点,那失败指针就派上用场了,我们让 p=p->fail,然后继续这 2 个过程。
-
代码
public void match(char[] text) { // text是主串 int n = text.length; AcNode p = root; for (int i = 0; i < n; ++i) { int idx = text[i] - 'a'; while (p.children[idx] == null && p != root) { p = p.fail; // 失败指针发挥作用的地方 } p = p.children[idx]; if (p == null) p = root; // 如果没有匹配的,从root开始重新匹配 AcNode tmp = p; while (tmp != root) { // 打印出可以匹配的模式串 if (tmp.isEndingChar == true) { int pos = i-tmp.length+1; System.out.println("匹配起始下标" + pos + "; 长度" + tmp.length); } tmp = tmp.fail; } } } -
用 AC 自动机做匹配的时间复杂度是多少?
- 跟刚刚构建失败指针的分析类似,for 循环依次遍历主串中的每个字符,for 循环内部最耗时的部分也是 while 循环,而这一部分的时间复杂度也是 O(len),所以总的匹配的时间复杂度就是 O(n*len)。
- 因为敏感词并不会很长,而且这个时间复杂度只是一个非常宽泛的上限,实际情况下,可能近似于 O(n),所以 AC 自动机做敏感词过滤,性能非常高。
- 从时间复杂度上看,AC 自动机匹配的效率跟 Trie 树一样啊。实际上,因为失效指针可能大部分情况下都指向 root 节点,所以绝大部分情况下,在 AC 自动机上做匹配的效率要远高于刚刚计算出的比较宽泛的时间复杂度。只有在极端情况下,如图所示,AC 自动机的性能才会退化的跟 Trie 树一样。
-
-
-
各个字符串匹配算法的特点和比较适合的应用场景
- 单模式串匹配:
- BF: 简单场景,主串和模式串都不太长, O(m*n)
- RK:字符集范围不要太大且模式串不要太长, 否则hash值可能冲突,O(n)
- naive-BM:模式串最好不要太长(因为预处理较重),比如IDE编辑器里的查找场景; 预处理O(m*m), 匹配O(n), 实现较复杂,需要较多额外空间.
- KMP:适合所有场景,整体实现起来也比BM简单,O(n+m),仅需一个next数组的O(n)额外空间;
- 多模式串匹配:
- naive-Trie: 适合多模式串公共前缀较多的匹配(O(n*k)) 或者 根据公共前缀进行查找(O(k))的场景,比如搜索框的自动补全提示.
- AC自动机: 适合大量文本中多模式串的精确匹配查找, 可以到O(n).
- 单模式串匹配:

