数据结构与算法知识树整理——数据结构篇——非线性结构
数据结构知识树整理
非线性结构
树
-
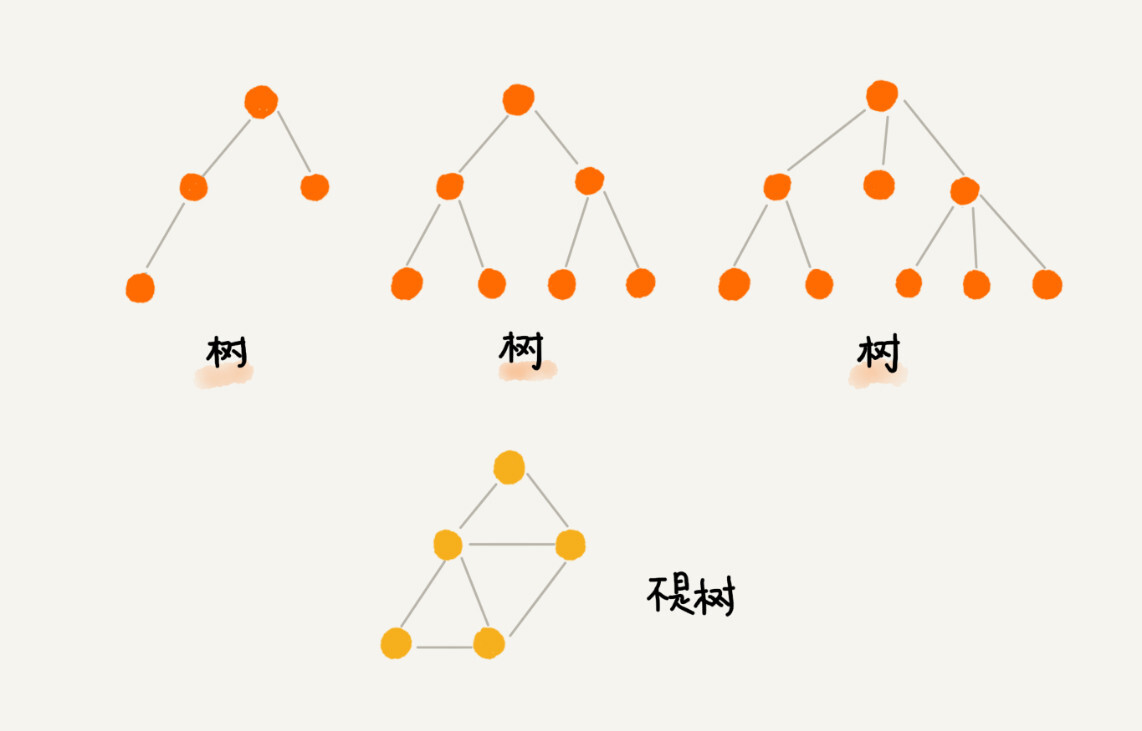
什么是“树”?
-
树”这种数据结构真的很像我们现实生活中的“树”,这里面每个元素我们叫做“节点”;用来连接相邻节点之间的关系,我们叫做“父子关系”
-
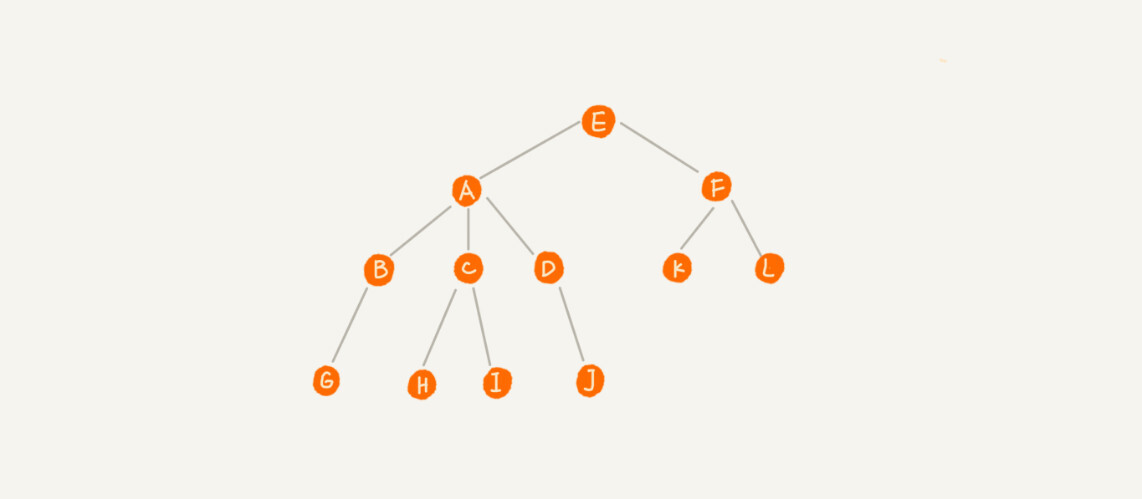
比如下面这幅图,A 节点就是 B 节点的父节点,B 节点是 A 节点的子节点。B、C、D 这三个节点的父节点是同一个节点,所以它们之间互称为兄弟节点。我们把没有父节点的节点叫做根节点,也就是图中的节点 E。我们把没有子节点的节点叫做叶子节点或者叶节点,比如图中的 G、H、I、J、K、L 都是叶子节点。
-
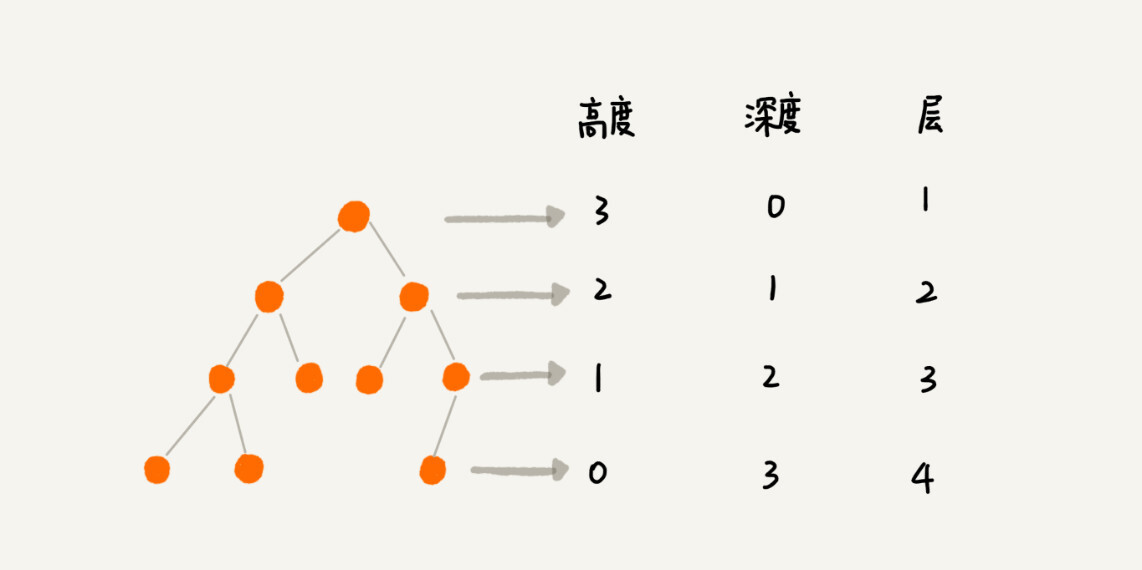
除此之外,关于“树”,还有三个比较相似的概念:高度(Height)、深度(Depth)、层(Level)。它们的定义是这样的:

-
-
二叉树(Binary Tree)
-
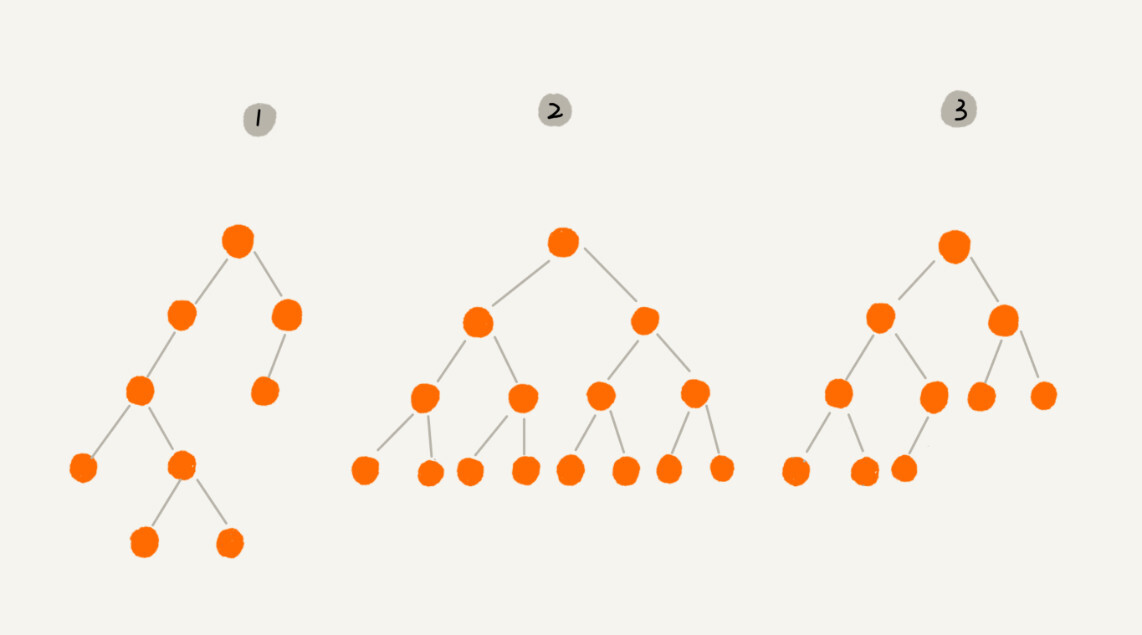
二叉树,顾名思义,每个节点最多有两个“叉”,也就是两个子节点,分别是左子节点和右子节点。
-
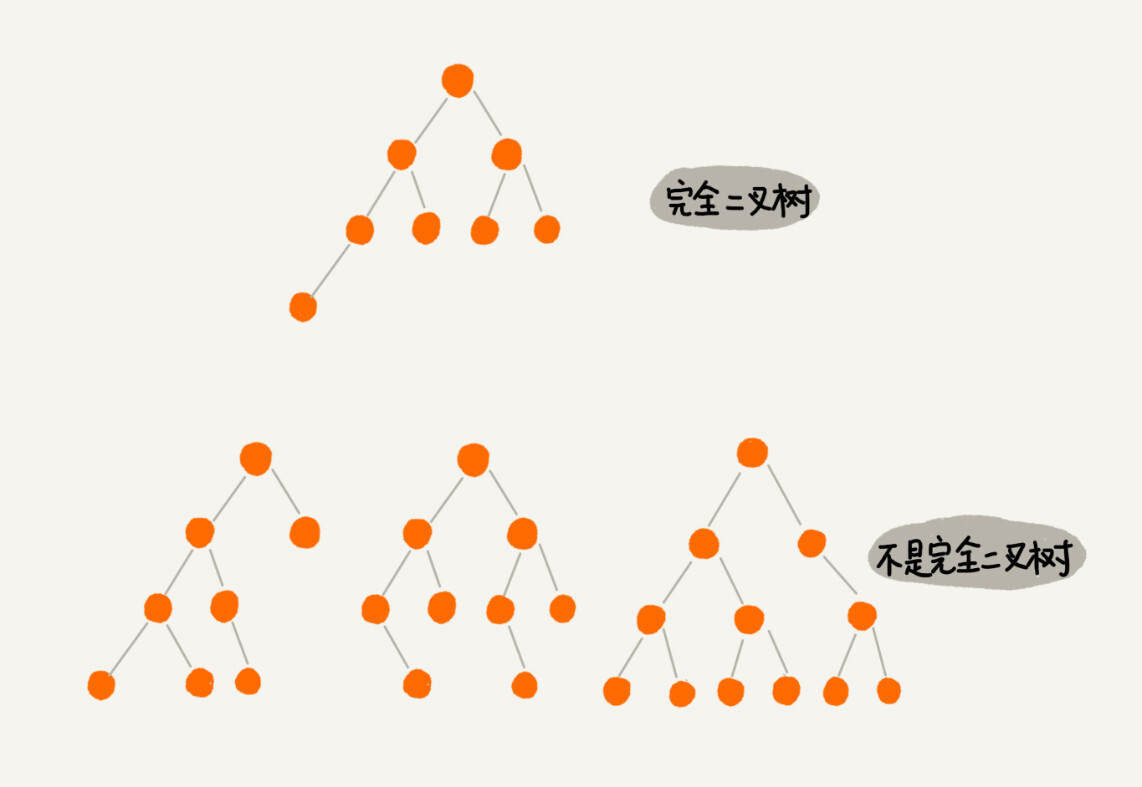
编号 2 的二叉树中,叶子节点全都在最底层,除了叶子节点之外,每个节点都有左右两个子节点,这种二叉树就叫做满二叉树。
-
编号 3 的二叉树中,叶子节点都在最底下两层,最后一层的叶子节点都靠左排列,并且除了最后一层,其他层的节点个数都要达到最大,这种二叉树叫做完全二叉树。
-
满二叉树很好理解,也很好识别,但是完全二叉树,有的人可能就分不清了。我画了几个完全二叉树和非完全二叉树的例子,你可以对比着看看
-
如何表示(或者存储)一棵二叉树?
-
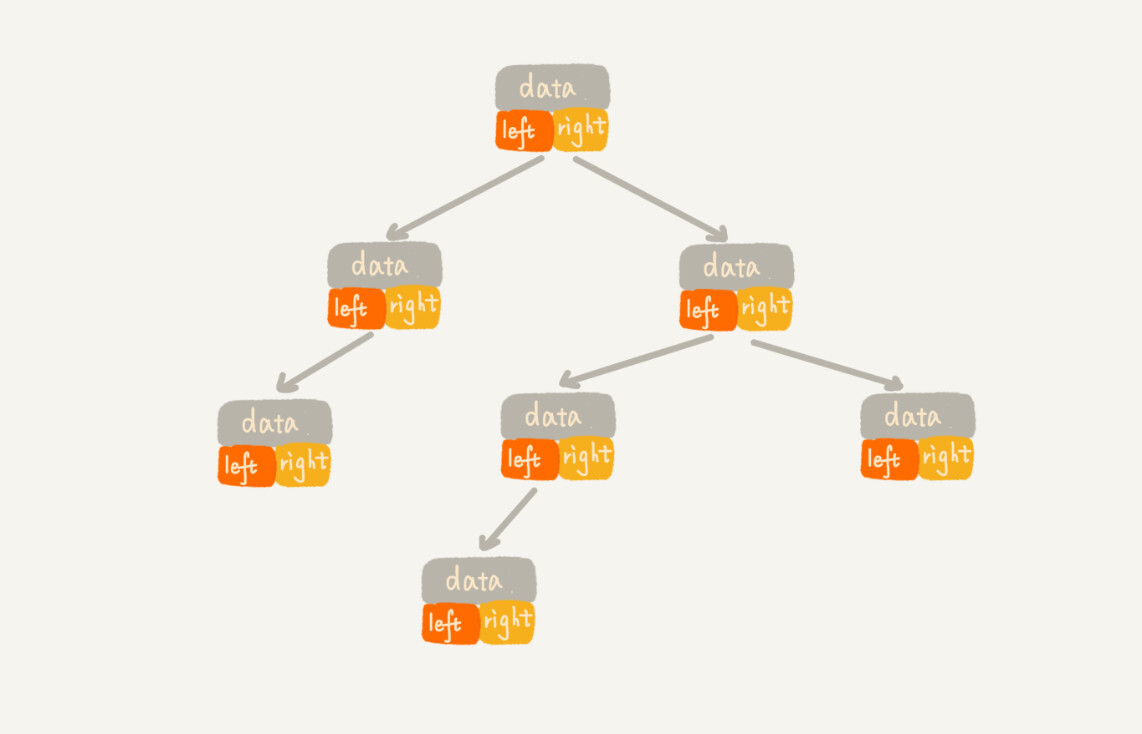
链式存储法
每个节点有三个字段,其中一个存储数据,另外两个是指向左右子节点的指针。我们只要拎住根节点,就可以通过左右子节点的指针,把整棵树都串起来。这种存储方式我们比较常用。大部分二叉树代码都是通过这种结构来实现的。
-
顺序存储法
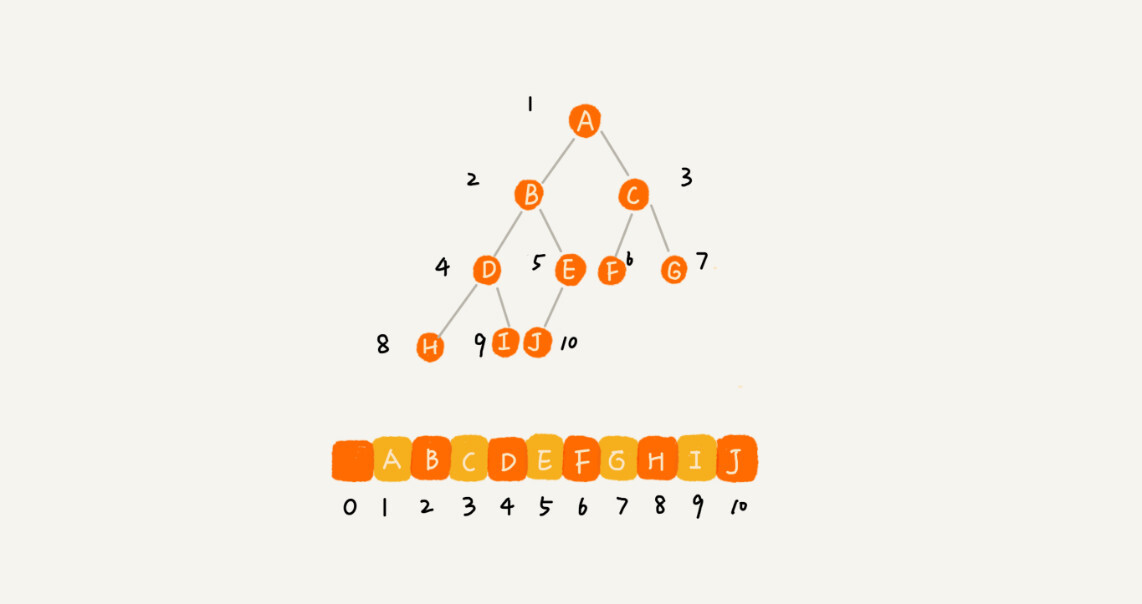
- 基于数组的顺序存储法。我们把根节点存储在下标 i = 1 的位置,那左子节点存储在下标 2 * i = 2 的位置,右子节点存储在 2 * i + 1 = 3 的位置。以此类推,B 节点的左子节点存储在 2 * i = 2 * 2 = 4 的位置,右子节点存储在 2 * i + 1 = 2 * 2 + 1 = 5 的位置。
-
如果节点 X 存储在数组中下标为 i 的位置,下标为 2 * i 的位置存储的就是左子节点,下标为 2 * i + 1 的位置存储的就是右子节点。反过来,下标为 i/2 的位置存储就是它的父节点。通过这种方式,我们只要知道根节点存储的位置(一般情况下,为了方便计算子节点,根节点会存储在下标为 1 的位置)
-
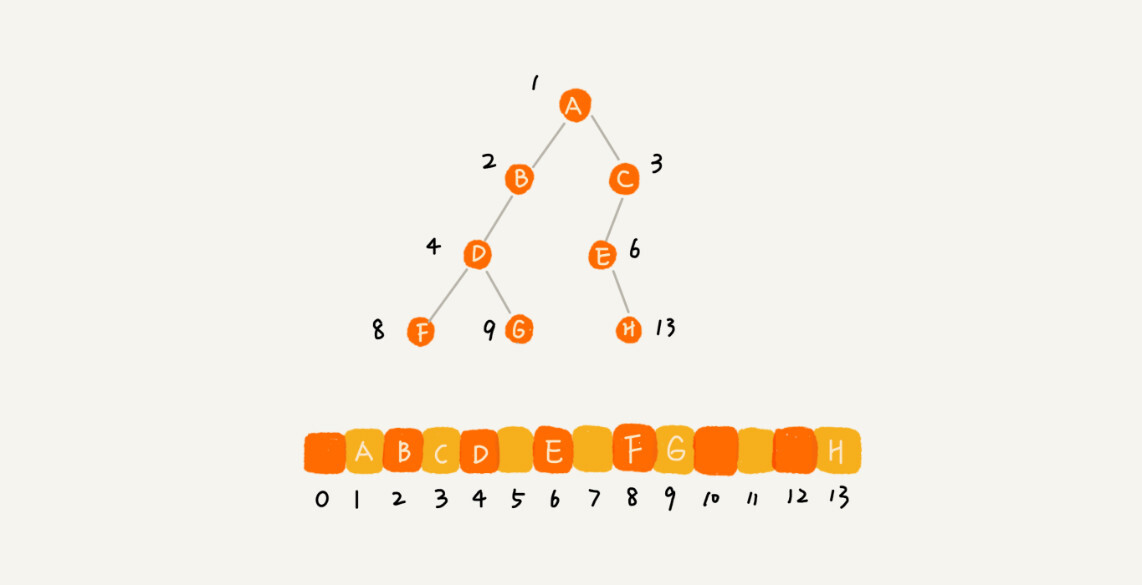
我刚刚举的例子是一棵完全二叉树,所以仅仅“浪费”了一个下标为 0 的存储位置。如果是非完全二叉树,其实会浪费比较多的数组存储空间。
-
如果某棵二叉树是一棵完全二叉树,那用数组存储无疑是最节省内存的一种方式。
-
当我们讲到堆和堆排序的时候,你会发现,堆其实就是一种完全二叉树,最常用的存储方式就是数组。
-
-
二叉树的遍历
-
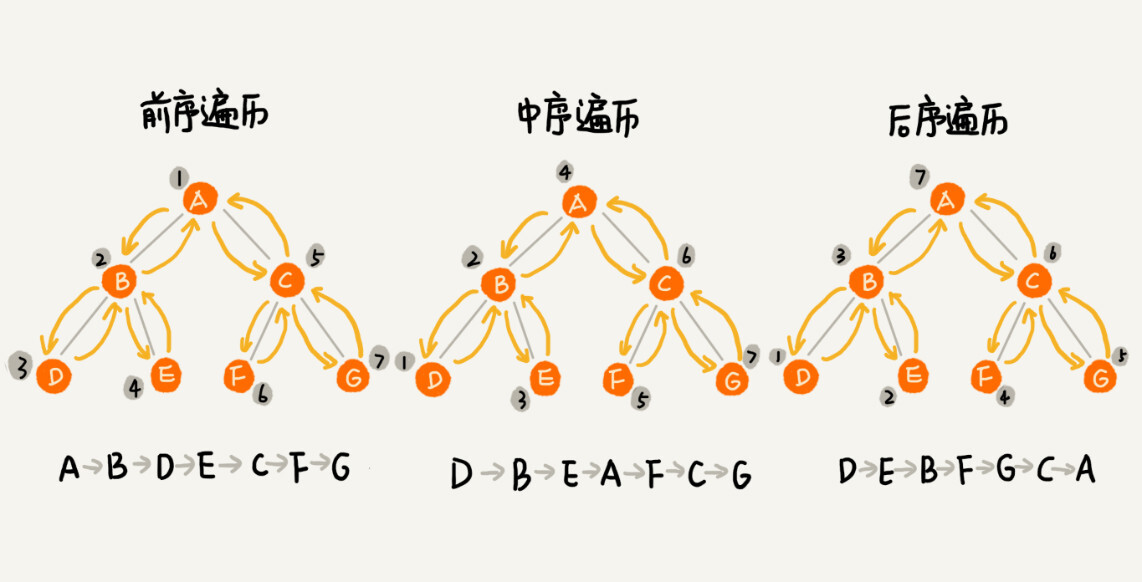
前序遍历
- 前序遍历是指,对于树中的任意节点来说,先打印这个节点,然后再打印它的左子树,最后打印它的右子树。
-
中序遍历
- 中序遍历是指,对于树中的任意节点来说,先打印它的左子树,然后再打印它本身,最后打印它的右子树。
-
后序遍历
- 后序遍历是指,对于树中的任意节点来说,先打印它的左子树,然后再打印它的右子树,最后打印这个节点本身。
-
按层遍历
- 就是从根节点开始逐层从左网右进行遍历
-
实际上,二叉树的前、中、后序遍历就是一个递归的过程。
//前序遍历伪代码表示 void preOrder(Node* root) { if (root == null) return; print root // 此处为伪代码,表示打印root节点 preOrder(root->left); preOrder(root->right); } //中序遍历伪代码表示 void inOrder(Node* root) { if (root == null) return; inOrder(root->left); print root // 此处为伪代码,表示打印root节点 inOrder(root->right); } //后序遍历伪代码表示 void postOrder(Node* root) { if (root == null) return; postOrder(root->left); postOrder(root->right); print root // 此处为伪代码,表示打印root节点 } -
二叉树遍历的时间复杂度是多少?
- 从我前面画的前、中、后序遍历的顺序图,可以看出来,每个节点最多会被访问两次,所以遍历操作的时间复杂度,跟节点的个数 n 成正比,也就是说二叉树遍历的时间复杂度是 O(n)。
-
-
二叉查找树(Binary Search Tree)
-
二叉查找树要求,在树中的任意一个节点,其左子树中的每个节点的值,都要小于这个节点的值,而右子树节点的值都大于这个节点的值
-
二叉查找树的查找操作
- 如果要查找的数据比根节点的值小,那就在左子树中递归查找;如果要查找的数据比根节点的值大,那就在右子树中递归查找。
-
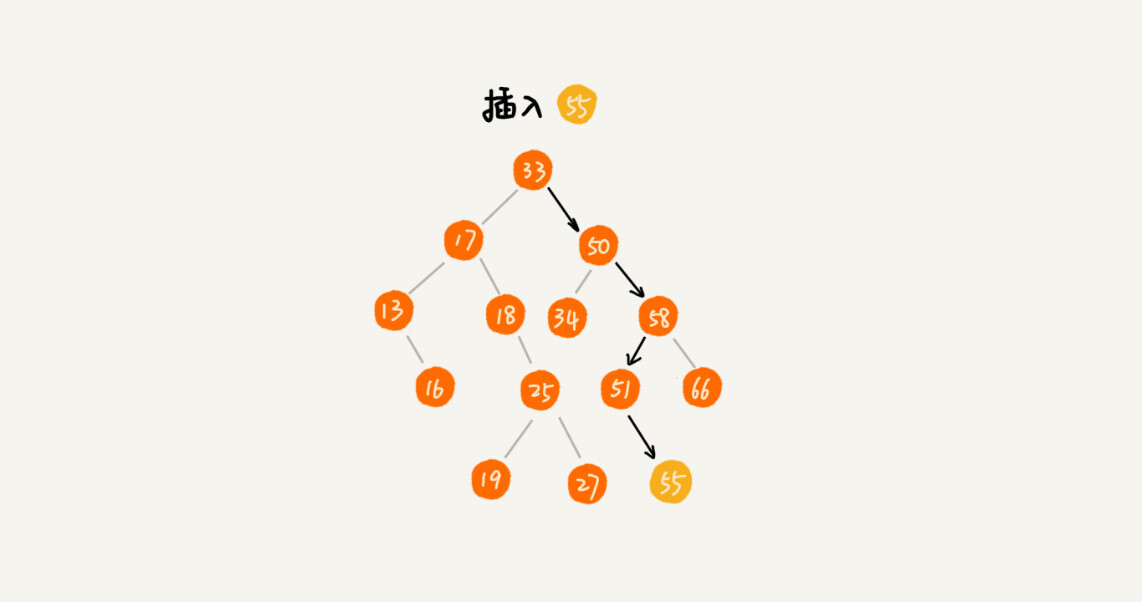
二叉查找树的插入操作
-
如果要插入的数据比节点的数据大,并且节点的右子树为空,就将新数据直接插到右子节点的位置;如果不为空,就再递归遍历右子树,查找插入位置。同理,如果要插入的数据比节点数值小,并且节点的左子树为空,就将新数据插入到左子节点的位置;如果不为空,就再递归遍历左子树,查找插入位置。
-
-
二叉查找树的删除操作
-
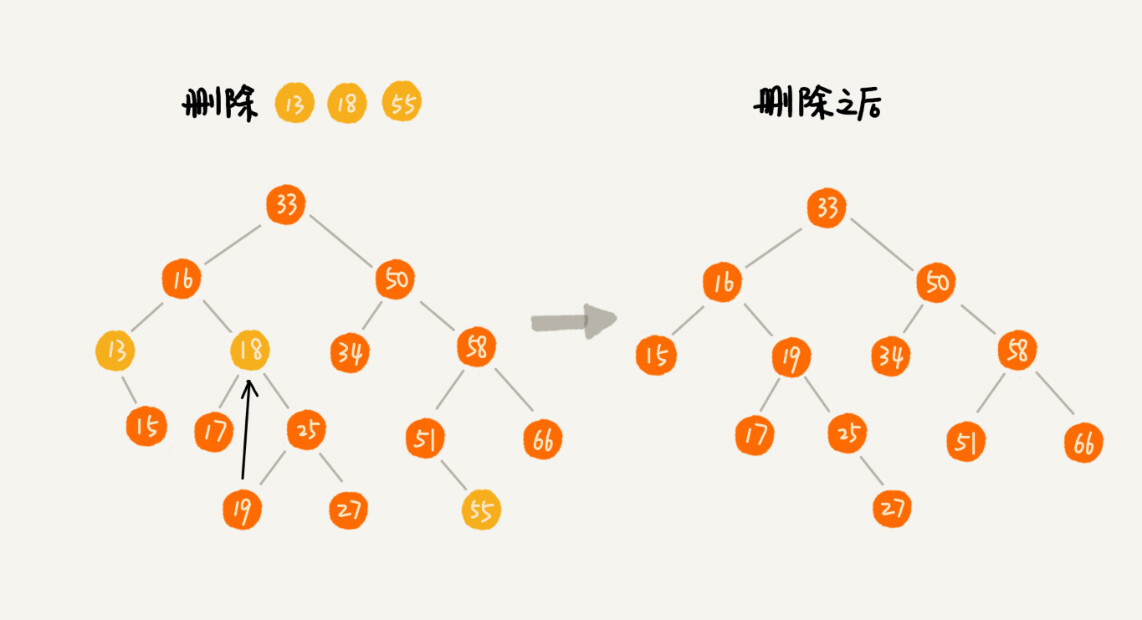
二叉查找树的查找、插入操作都比较简单易懂,但是它的删除操作就比较复杂了 。针对要删除节点的子节点个数的不同,我们需要分三种情况来处理。
-
如果要删除的节点没有子节点,我们只需要直接将父节点中,指向要删除节点的指针置为 null。比如图中的删除节点 55。
-
如果要删除的节点只有一个子节点(只有左子节点或者右子节点),我们只需要更新父节点中,指向要删除节点的指针,让它指向要删除节点的子节点就可以了。比如图中的删除节点 13。
-
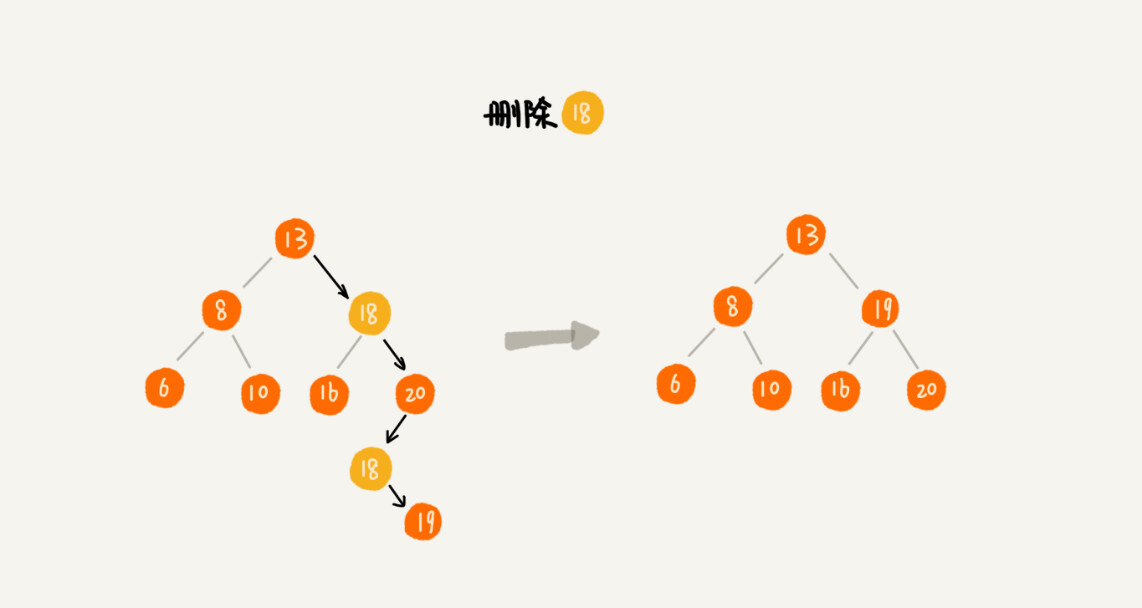
如果要删除的节点有两个子节点,这就比较复杂了。我们需要找到这个节点的右子树中的最小节点,把它替换到要删除的节点上。然后再删除掉这个最小节点,因为最小节点肯定没有左子节点(如果有左子结点,那就不是最小节点了),所以,我们可以应用上面两条规则来删除这个最小节点。比如图中的删除节点 18。
-
-
关于二叉查找树的删除操作,还有个非常简单、取巧的方法,就是单纯将要删除的节点标记为“已删除”,但是并不真正从树中将这个节点去掉。这样原本删除的节点还需要存储在内存中,比较浪费内存空间,但是删除操作就变得简单了很多。而且,这种处理方法也并没有增加插入、查找操作代码实现的难度。
-
-
二叉查找树的其他操作
- 快速地查找最大节点和最小节点、前驱节点和后继节点。
- 二叉查找树除了支持上面几个操作之外,还有一个重要的特性,就是中序遍历二叉查找树,可以输出有序的数据序列,时间复杂度是 O(n),非常高效,因此,二叉查找树也叫作二叉排序树。
//二叉排序树完整代码 public class BinarySearchTree { private Node _root; public void Insert(int data) { Node node = new Node(data); if (_root == null) { _root = node; return; } Insert(node,_root); } private void Insert(Node node,Node comparerNode) { if (comparerNode.Data == node.Data) return; if (node.Data < comparerNode.Data) { if (comparerNode.Left != null) Insert(node, comparerNode.Left); else { comparerNode.Left = node; node.Parent = comparerNode; } } else { if (comparerNode.Right != null) Insert(node, comparerNode.Right); else { comparerNode.Right = node; node.Parent = comparerNode; } } } public Node Find(int data) { return Find(data, _root); } private Node Find(int data,Node node) { if (node == null) return null; if (node.Data == data) return node; else if (data < node.Data ) return Find(data, node.Left); else return Find(data, node.Right); } public bool Delete(int data) { Node node = Find(data); if (node == null) return false; int count = 0; if (node.Left != null) count++; if (node.Right != null) count++; if (count == 0)//叶子节点 { if (node.Parent != null) { if (node.Parent.Left == node) node.Parent.Left = null; else node.Parent.Right = null; node.Reset(); } else _root = null; } else if(count == 1)//只有一边有子树 { Node child = node.Left != null ? node.Left : node.Right; if (node.Parent != null) { if (node.Parent.Left == node) node.Parent.Left = child; else node.Parent.Right = child; } else _root = child; node.Reset(); } else//左右子树健在,找右边最小的来背锅 { Node limit = FindLimit(node.Right); int tempData = limit.Data; Delete(limit.Data); node.Data = tempData; } return true; } //寻找当前树最小值 public Node FindLimit() { return FindLimit(_root); } private Node FindLimit(Node node) { if (node.Left != null) return FindLimit(node.Left); else return node; } public Node FindMax() { return FindMax(_root); } private Node FindMax(Node node) { if (node.Right != null) return FindMax(node.Right); else return node; } public override string ToString() { StringBuilder sb = new StringBuilder(); InorderTraversal(_root, sb); return sb.ToString(); } public void InorderTraversal(Node node , StringBuilder sb) { if (node == null) return; InorderTraversal(node.Left,sb); sb.Append(node.Data + " "); InorderTraversal(node.Right,sb); } public int GetHeight() { return GetHeight(_root); } public int GetHeight(Node node) { if (node == null) return -1; return Mathf.Max(GetHeight(node.Left), GetHeight(node.Right)) + 1; } } public class Node { private int _data; private Node _left; private Node _right; private Node _parent; public Node(int data) { _data = data; } public void Reset() { _data = 0; _left = null; _right = null; _parent = null; } public int Data { get => _data; set => _data = value; } public Node Left { get => _left; set => _left = value; } public Node Right { get => _right; set => _right = value; } public Node Parent { get => _parent; set => _parent = value; } } -
-
支持重复数据的二叉查找树
-
前面我们讲的二叉查找树的操作,针对的都是不存在键值相同的情况。那如果存储的两个对象键值相同,这种情况该怎么处理呢?我这里有两种解决方法。
-
第一种方法比较容易。二叉查找树中每一个节点不仅会存储一个数据,因此我们通过链表和支持动态扩容的数组等数据结构,把值相同的数据都存储在同一个节点上。
-
第二种方法比较不好理解,不过更加优雅。每个节点仍然只存储一个数据。在查找插入位置的过程中,如果碰到一个节点的值,与要插入数据的值相同,我们就将这个要插入的数据放到这个节点的右子树,也就是说,把这个新插入的数据当作大于这个节点的值来处理。
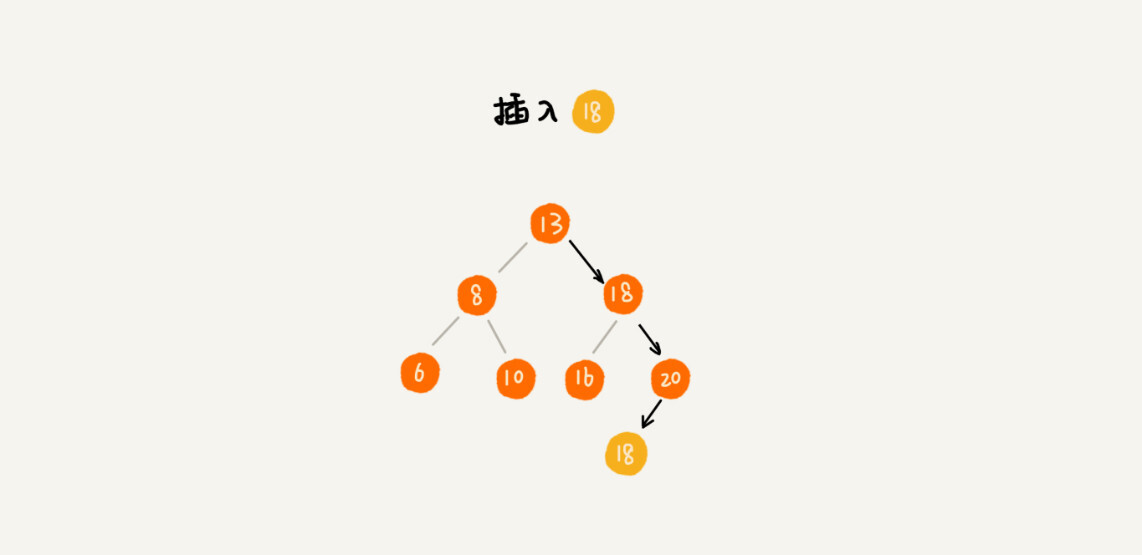
当要查找数据的时候,遇到值相同的节点,我们并不停止查找操作,而是继续在右子树中查找,直到遇到叶子节点,才停止。这样就可以把键值等于要查找值的所有节点都找出来。
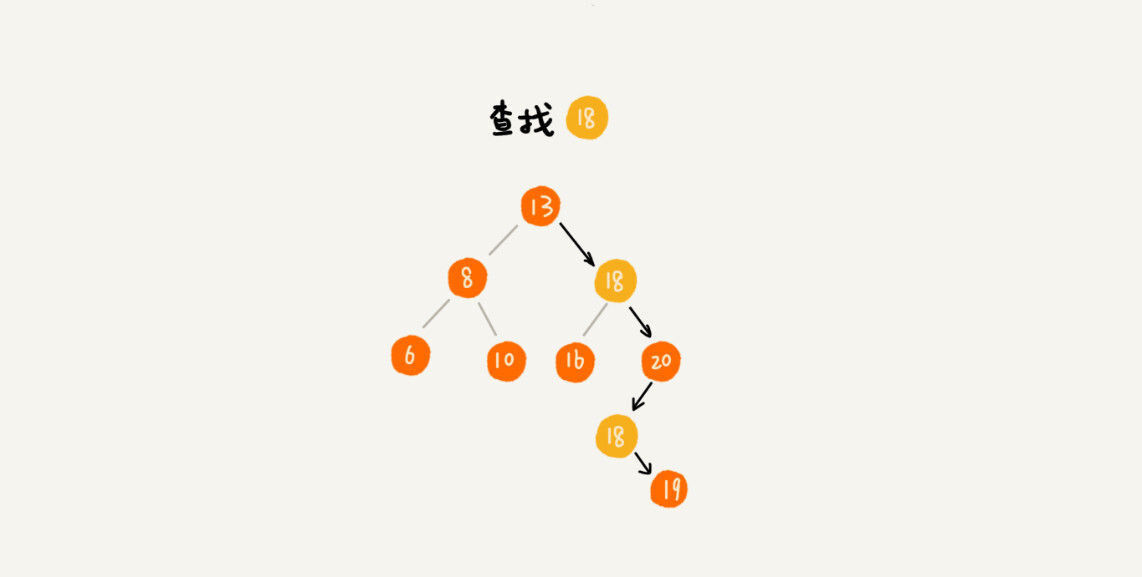
对于删除操作,我们也需要先查找到每个要删除的节点,然后再按前面讲的删除操作的方法,依次删除。
对于删除操作,我们也需要先查找到每个要删除的节点,然后再按前面讲的删除操作的方法,依次删除。
-
-
-
二叉查找树的时间复杂度分析
-
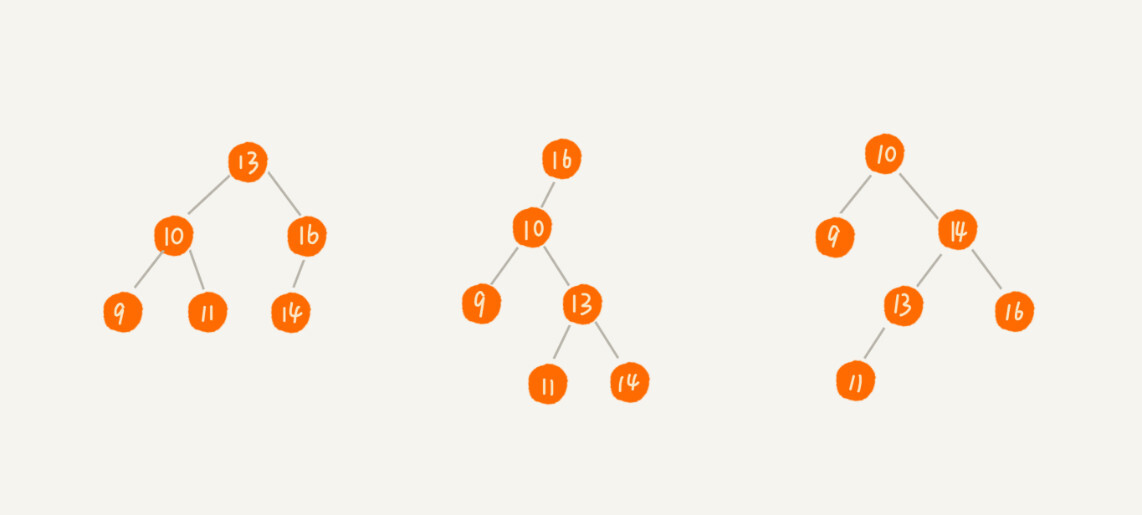
实际上,二叉查找树的形态各式各样。比如这个图中,对于同一组数据,我们构造了三种二叉查找树。它们的查找、插入、删除操作的执行效率都是不一样的。图中第一种二叉查找树,根节点的左右子树极度不平衡,已经退化成了链表,所以查找的时间复杂度就变成了 O(n)。
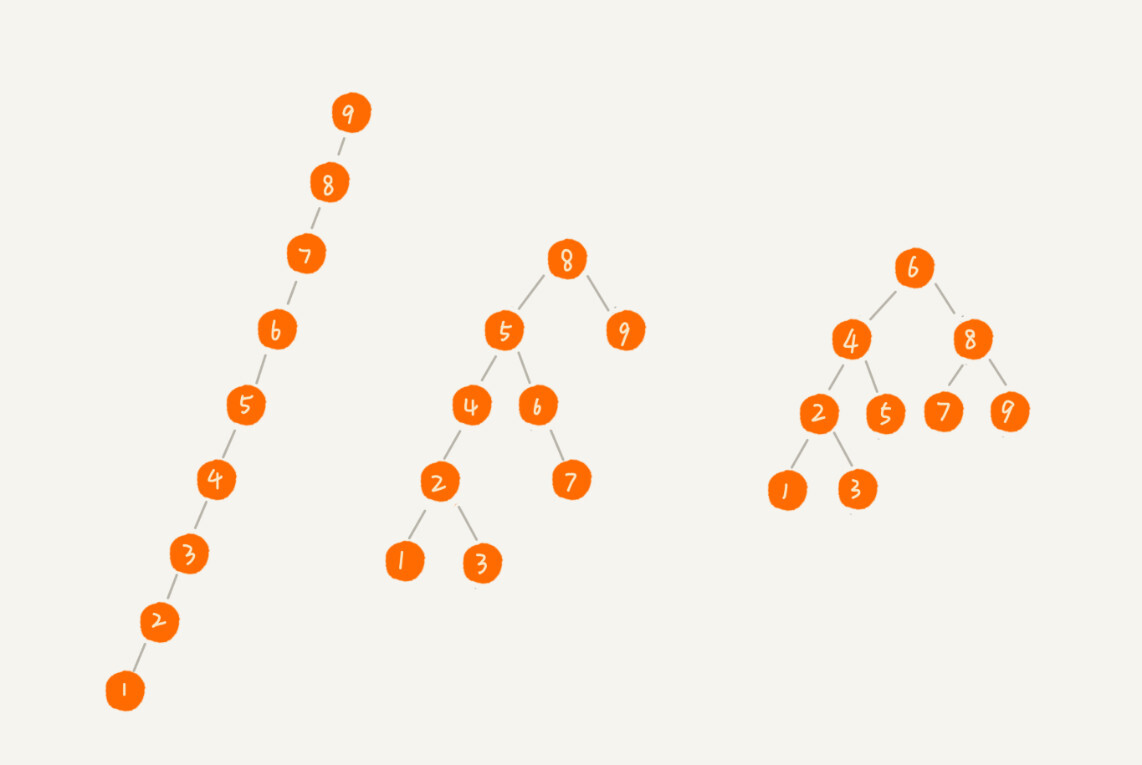
-
我刚刚其实分析了一种最糟糕的情况,我们现在来分析一个最理想的情况,二叉查找树是一棵完全二叉树(或满二叉树)这个时候,插入、删除、查找的时间复杂度是多少呢?
-
从我前面的例子、图,以及还有代码来看,不管操作是插入、删除还是查找,时间复杂度其实都跟树的高度成正比,也就是 O(height)。既然这样,现在问题就转变成另外一个了,也就是,如何求一棵包含 n 个节点的完全二叉树的高度?
-
借助等比数列的求和公式,我们可以计算出,L 的范围是[log2(n+1), log2n +1]。完全二叉树的层数小于等于 log2n +1,也就是说,完全二叉树的高度小于等于 log2n。
-
显然,极度不平衡的二叉查找树,它的查找性能肯定不能满足我们的需求。我们需要构建一种不管怎么删除、插入数据,在任何时候,都能保持任意节点左右子树都比较平衡的二叉查找树,这就是我们下一节课要详细讲的,一种特殊的二叉查找树,平衡二叉查找树。平衡二叉查找树的高度接近 logn,所以插入、删除、查找操作的时间复杂度也比较稳定,是 O(logn)。
-
-
相对散列表,好像并没有什么优势,那我们为什么还要用二叉查找树呢?
- 散列表中的数据是无序存储的,如果要输出有序的数据,需要先进行排序。而对于二叉查找树来说,我们只需要中序遍历,就可以在 O(n) 的时间复杂度内,输出有序的数据序列。
- 散列表扩容耗时很多,而且当遇到散列冲突时,性能不稳定,尽管二叉查找树的性能不稳定,但是在工程中,我们最常用的平衡二叉查找树的性能非常稳定,时间复杂度稳定在 O(logn)。
- 笼统地来说,尽管散列表的查找等操作的时间复杂度是常量级的,但因为哈希冲突的存在,这个常量不一定比 logn 小,所以实际的查找速度可能不一定比 O(logn) 快。加上哈希函数的耗时,也不一定就比平衡二叉查找树的效率高。
- 散列表的构造比二叉查找树要复杂,需要考虑的东西很多。比如散列函数的设计、冲突解决办法、扩容、缩容等。平衡二叉查找树只需要考虑平衡性这一个问题,而且这个问题的解决方案比较成熟、固定。
- 最后,为了避免过多的散列冲突,散列表装载因子不能太大,特别是基于开放寻址法解决冲突的散列表,不然会浪费一定的存储空间。
-
综合这几点,平衡二叉查找树在某些方面还是优于散列表的,所以,这两者的存在并不冲突。我们在实际的开发过程中,需要结合具体的需求来选择使用哪一个。
-
如何通过编程,求出一棵给定二叉树的确切高度呢?
//送分题,递归over public int GetHeight() { return GetHeight(_root); } public int GetHeight(Node node) { if (node == null)//叶子节点 return -1; return Mathf.Max(GetHeight(node.Left), GetHeight(node.Right)) + 1; }
-
-
红黑树
-
什么是“平衡二叉查找树”?
-
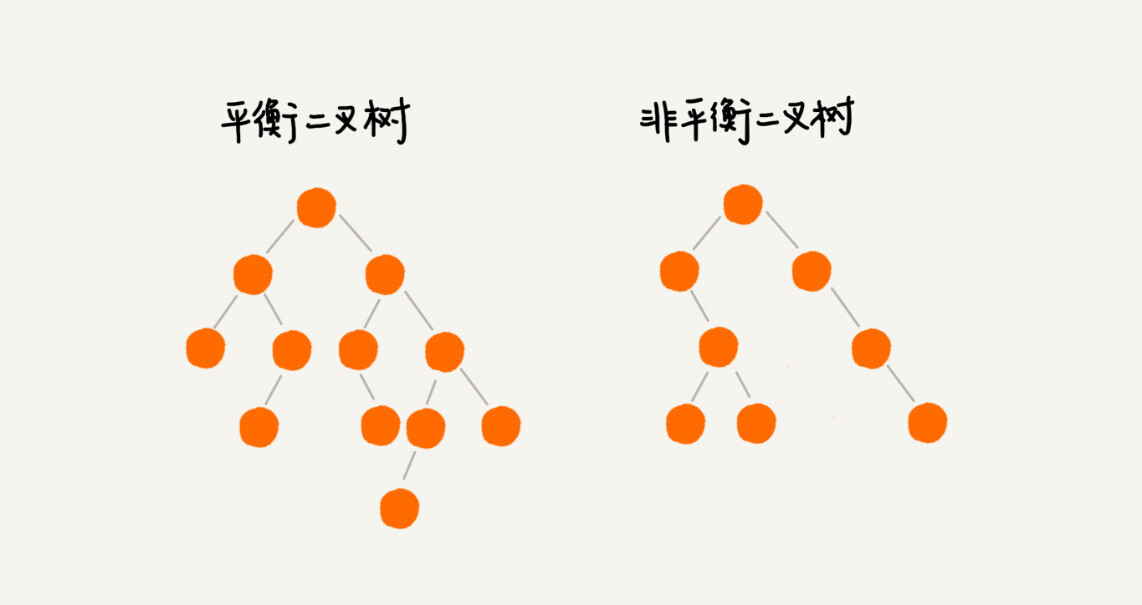
二叉树中任意一个节点的左右子树的高度相差不能大于 1。从这个定义来看,上一节我们讲的完全二叉树、满二叉树其实都是平衡二叉树,但是非完全二叉树也有可能是平衡二叉树。
-
平衡二叉查找树不仅满足上面平衡二叉树的定义,还满足二叉查找树的特点。最先被发明的平衡二叉查找树是AVL 树,它严格符合我刚讲到的平衡二叉查找树的定义,即任何节点的左右子树高度相差不超过 1,是一种高度平衡的二叉查找树。
-
但是很多平衡二叉查找树其实并没有严格符合上面的定义(树中任意一个节点的左右子树的高度相差不能大于 1),比如我们下面要讲的红黑树,它从根节点到各个叶子节点的最长路径,有可能会比最短路径大一倍
-
发明平衡二叉查找树这类数据结构的初衷是,解决普通二叉查找树在频繁的插入、删除等动态更新的情况下,出现时间复杂度退化的问题。
-
所以,平衡二叉查找树中“平衡”的意思,其实就是让整棵树左右看起来比较“对称”、比较“平衡”,不要出现左子树很高、右子树很矮的情况。这样就能让整棵树的高度相对来说低一些,相应的插入、删除、查找等操作的效率高一些。
-
-
如何定义一棵“红黑树”?
- 红黑树的英文是“Red-Black Tree”,简称 R-B Tree。它是一种不严格的平衡二叉查找树,我前面说了,它的定义是不严格符合平衡二叉查找树的定义的
- 顾名思义,红黑树中的节点,一类被标记为黑色,一类被标记为红色。除此之外,一棵红黑树还需要满足这样几个要求:
- 根节点是黑色的;
- 每个叶子节点都是黑色的空节点(NIL),也就是说,叶子节点不存储数据;
- 任何相邻的节点都不能同时为红色,也就是说,红色节点是被黑色节点隔开的;
- 每个节点,从该节点到达其可达叶子节点的所有路径,都包含相同数目的黑色节点;
-
为什么说红黑树是“近似平衡”的?
-
“平衡”的意思可以等价为性能不退化。“近似平衡”就等价为性能不会退化得太严重。
-
一棵极其平衡的二叉树(满二叉树或完全二叉树)的高度大约是 log2n,所以如果要证明红黑树是近似平衡的,我们只需要分析,红黑树的高度是否比较稳定地趋近 log2n 就好了。
-
首先,我们来看,如果我们将红色节点从红黑树中去掉,那单纯包含黑色节点的红黑树的高度是多少呢?
-
红色节点删除之后,有些节点就没有父节点了,它们会直接拿这些节点的祖父节点(父节点的父节点)作为父节点。所以,之前的二叉树就变成了四叉树。
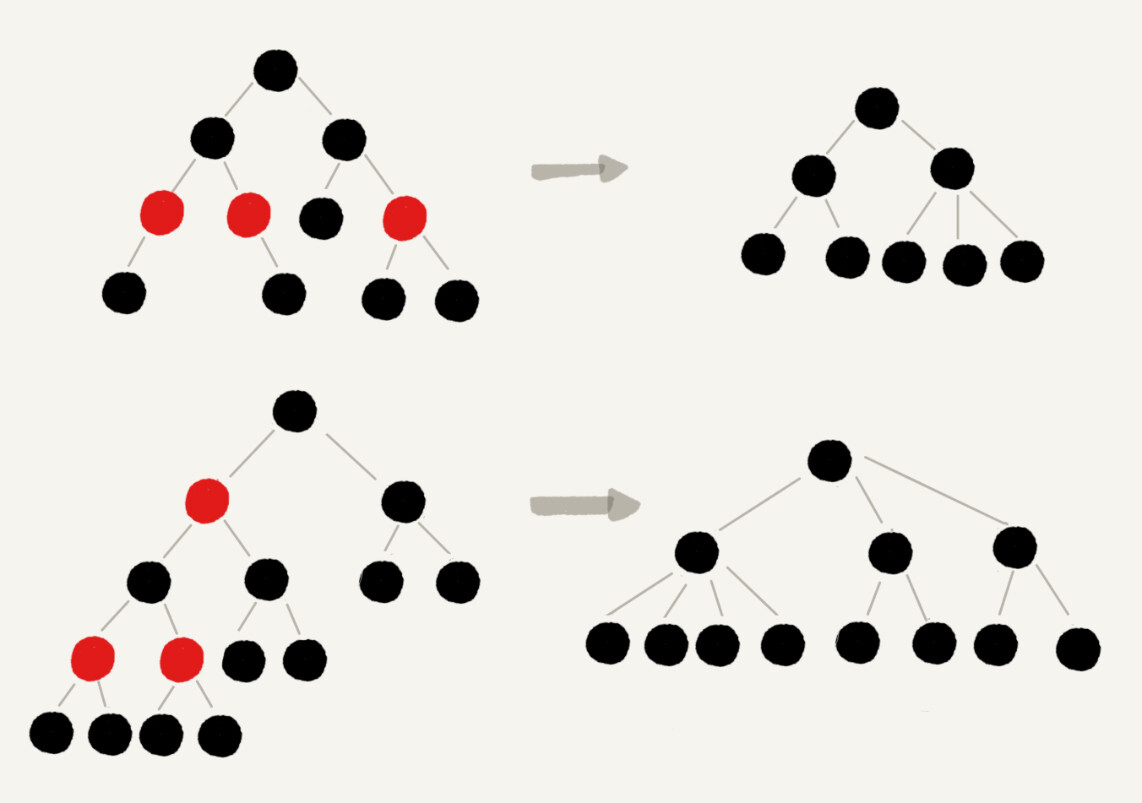
-
前面红黑树的定义里有这么一条:从任意节点到可达的叶子节点的每个路径包含相同数目的黑色节点。我们从四叉树中取出某些节点,放到叶节点位置,四叉树就变成了完全二叉树。所以,仅包含黑色节点的四叉树的高度,比包含相同节点个数的完全二叉树的高度还要小。
-
我们现在知道只包含黑色节点的“黑树”的高度,那我们现在把红色节点加回去,高度会变成多少呢?
-
从上面我画的红黑树的例子和定义看,在红黑树中,红色节点不能相邻,也就是说,有一个红色节点就要至少有一个黑色节点,将它跟其他红色节点隔开。红黑树中包含最多黑色节点的路径不会超过 log2n,所以加入红色节点之后,最长路径不会超过 2log2n,也就是说,红黑树的高度近似 2log2n。
-
所以,红黑树的高度只比高度平衡的 AVL 树的高度(log2n)仅仅大了一倍,在性能上,下降得并不多。这样推导出来的结果不够精确,实际上红黑树的性能更好。
-
-
-
AVL 树是一种高度平衡的二叉树,所以查找的效率非常高,但是,有利就有弊,AVL 树为了维持这种高度的平衡,就要付出更多的代价。每次插入、删除都要做调整,就比较复杂、耗时。所以,对于有频繁的插入、删除操作的数据集合,使用 AVL 树的代价就有点高了。
-
红黑树只是做到了近似平衡,并不是严格的平衡,所以在维护平衡的成本上,要比 AVL 树要低。所以,红黑树的插入、删除、查找各种操作性能都比较稳定。对于工程应用来说,要面对各种异常情况,为了支撑这种工业级的应用,我们更倾向于这种性能稳定的平衡二叉查找树。
-
我们学习数据结构和算法,要学习它的由来、特性、适用的场景以及它能解决的问题。对于红黑树,也不例外。你如果能搞懂这几个问题,其实就已经足够了。
-
动态数据结构支持动态的数据插入、删除、查找操作,除了红黑树,我们前面还学习过哪些呢?能对比一下各自的优势、劣势,以及应用场景吗?
- 散列表:插入删除查找都是O(1), 是最常用的,但其缺点是不能顺序遍历以及扩容缩容的性能损耗。适用于那些不需要顺序遍历,数据更新不那么频繁的。
- 跳表:插入删除查找都是O(logn), 并且能顺序遍历。缺点是空间复杂度O(n)。适用于不那么在意内存空间的,其顺序遍历和区间查找非常方便。
- 红黑树:插入删除查找都是O(logn), 中序遍历即是顺序遍历,稳定。缺点是难以实现,去查找不方便。其实跳表更佳,但红黑树已经用于很多地方了。
-
-
堆
-
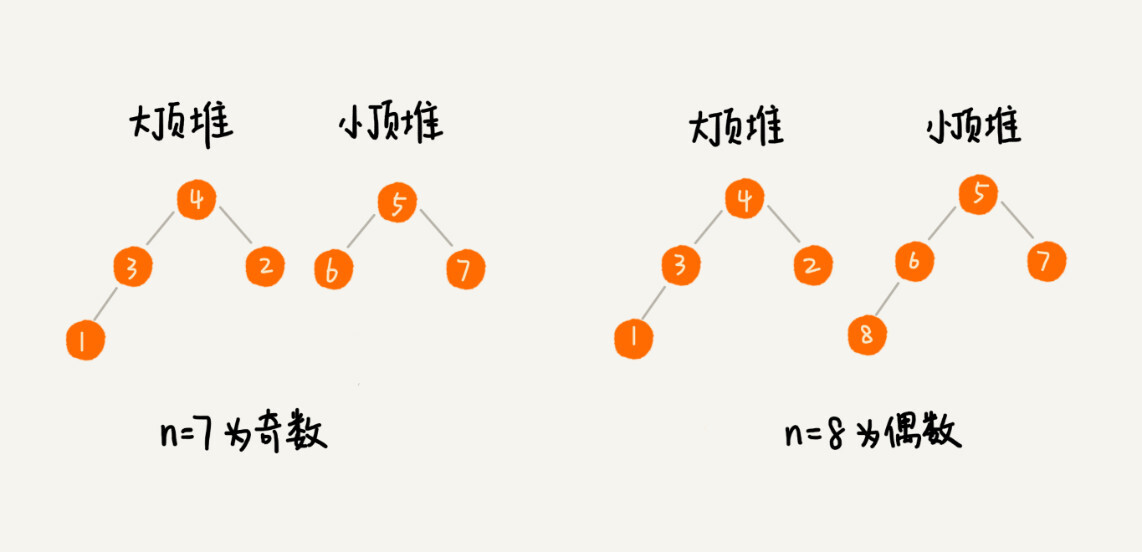
如何理解“堆”?
- 堆是一个完全二叉树
- 堆中每一个节点的值都必须大于等于(或小于等于)其子树中每个节点的值。
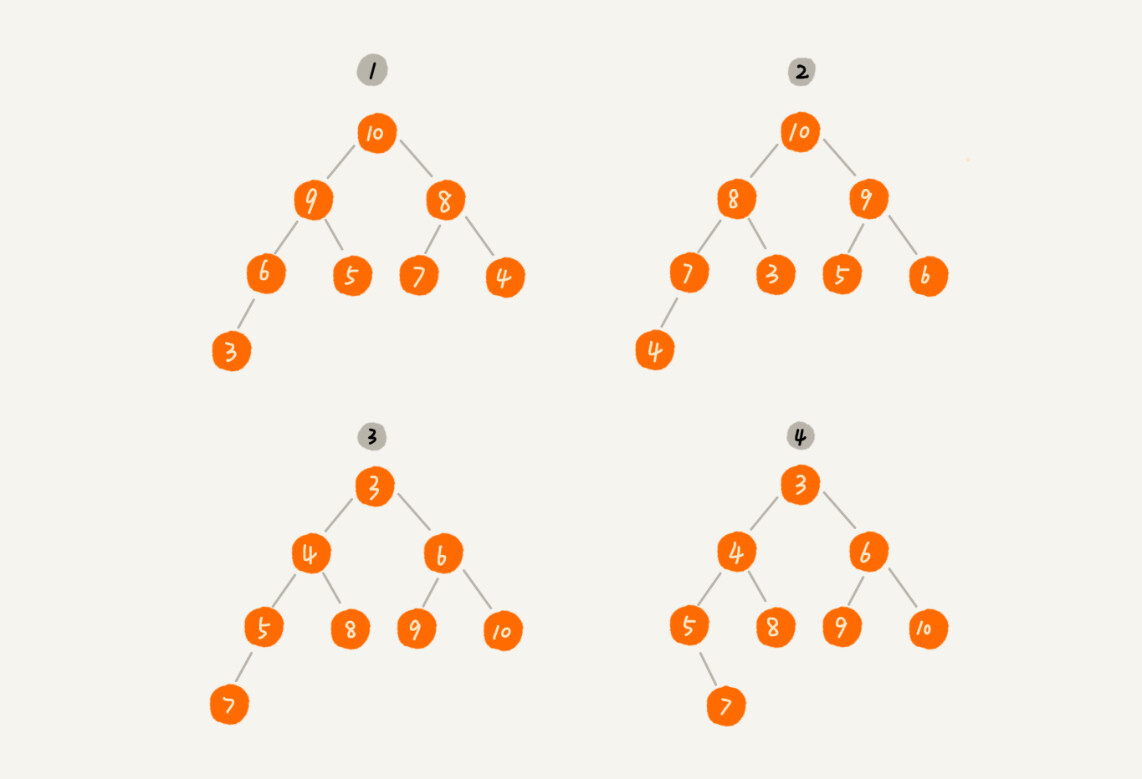
- 1,2,是大顶堆,3是小顶堆,4不是堆
-
如何实现一个堆?
-
完全二叉树比较适合用数组来存储。用数组来存储完全二叉树是非常节省存储空间的。因为我们不需要存储左右子节点的指针,单纯地通过数组的下标,就可以找到一个节点的左右子节点和父节点。
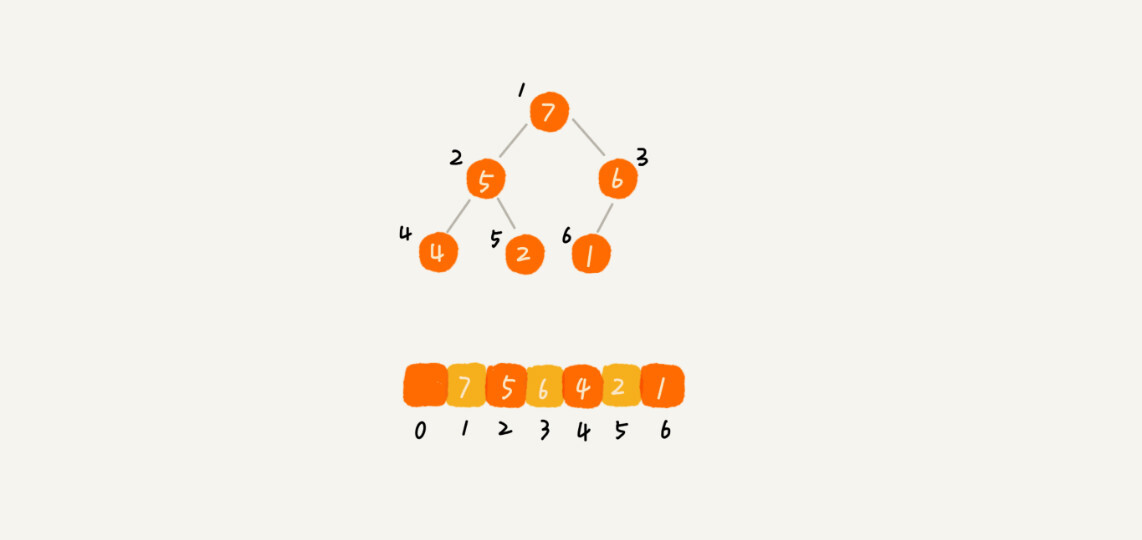
-
数组中下标为 i 的节点的左子节点,就是下标为 i∗2 的节点,右子节点就是下标为 i∗2+1 的节点,父节点就是下标为 2i 的节点。
-
-
往堆中插入一个元素
-
如果我们把新插入的元素放到堆的最后,你可以看我画的这个图,是不是不符合堆的特性了?于是,我们就需要进行调整,让其重新满足堆的特性,这个过程我们起了一个名字,就叫做堆化(heapify)。
-
堆化的方式有两种
-
从下往上
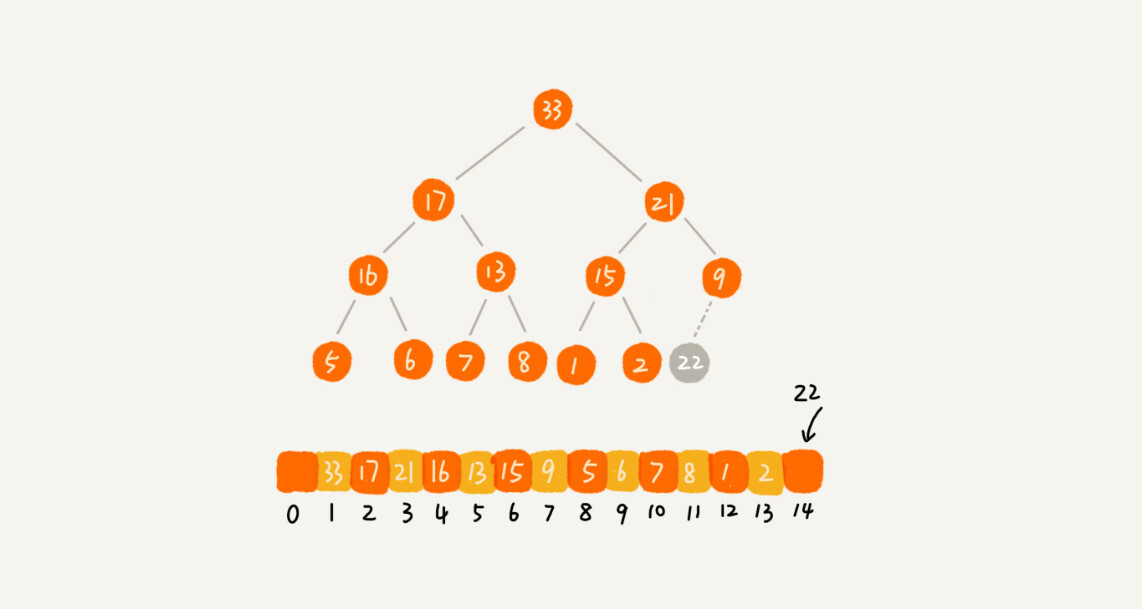
-
堆化非常简单,就是顺着节点所在的路径,向上或者向下,对比,然后交换。
-
我这里画了一张堆化的过程分解图。我们可以让新插入的节点与父节点对比大小。如果不满足子节点小于等于父节点的大小关系,我们就互换两个节点。一直重复这个过程,直到父子节点之间满足刚说的那种大小关系。
-
-
从上往下
-
-
-
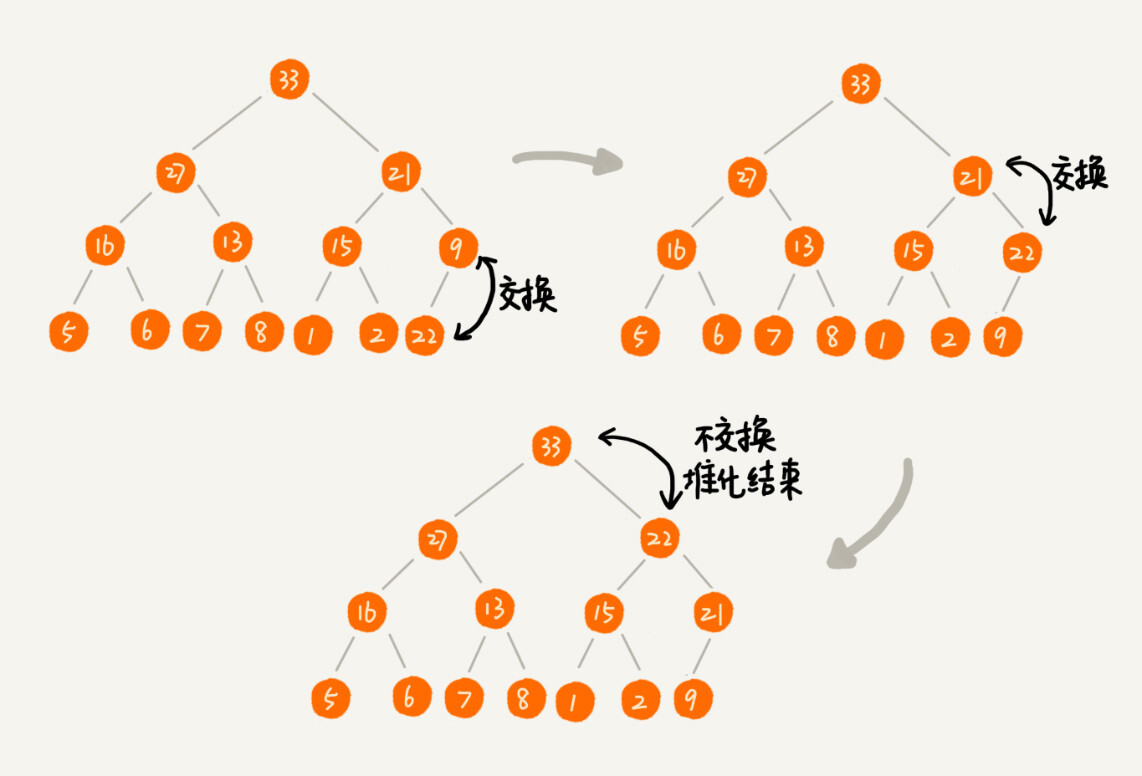
删除堆顶元素
-
我们把最后一个节点放到堆顶,然后利用同样的父子节点对比方法。对于不满足父子节点大小关系的,互换两个节点,并且重复进行这个过程,直到父子节点之间满足大小关系为止。这就是从上往下的堆化方法。
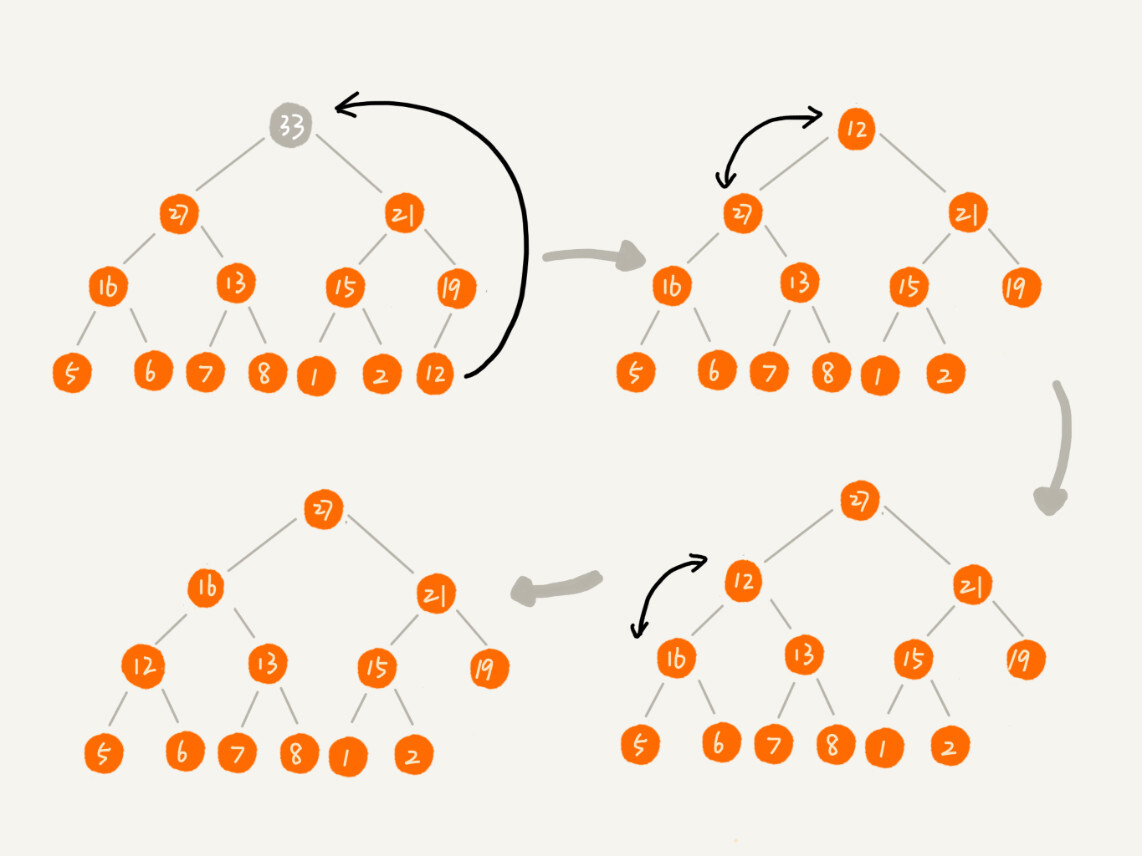
-
一个包含 n 个节点的完全二叉树,树的高度不会超过 log2n。堆化的过程是顺着节点所在路径比较交换的,所以堆化的时间复杂度跟树的高度成正比,也就是 O(logn)。插入数据和删除堆顶元素的主要逻辑就是堆化,所以,往堆中插入一个元素和删除堆顶元素的时间复杂度都是 O(logn)。
-
-
如何基于堆实现排序?
-
排序的过程大致分解成两个大的步骤,建堆和排序。
-
建堆
-
我们首先将数组原地建成一个堆。所谓“原地”就是,不借助另一个数组,就在原数组上操作。建堆的过程,有两种思路。
-
第一种是借助我们前面讲的,在堆中插入一个元素的思路。尽管数组中包含 n 个数据,但是我们可以假设,起初堆中只包含一个数据,就是下标为 1 的数据。然后,我们调用前面讲的插入操作,将下标从 2 到 n 的数据依次插入到堆中。这样我们就将包含 n 个数据的数组,组织成了堆。
-
第二种实现思路,跟第一种截然相反,也是我这里要详细讲的。第一种建堆思路的处理过程是从前往后处理数组数据,并且每个数据插入堆中时,都是从下往上堆化。而第二种实现思路,是从后往前处理数组,并且每个数据都是从上往下堆化。
-
因为叶子节点往下堆化只能自己跟自己比较,所以我们直接从最后一个非叶子节点开始,依次堆化就行了。
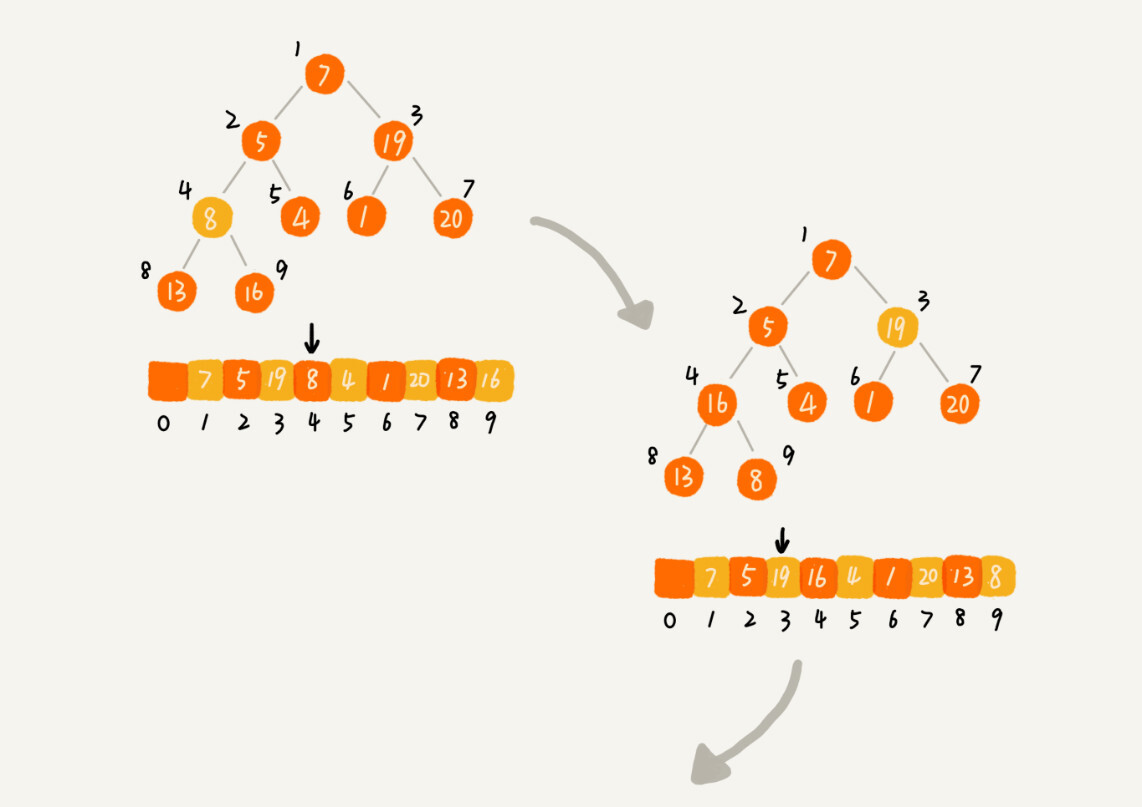
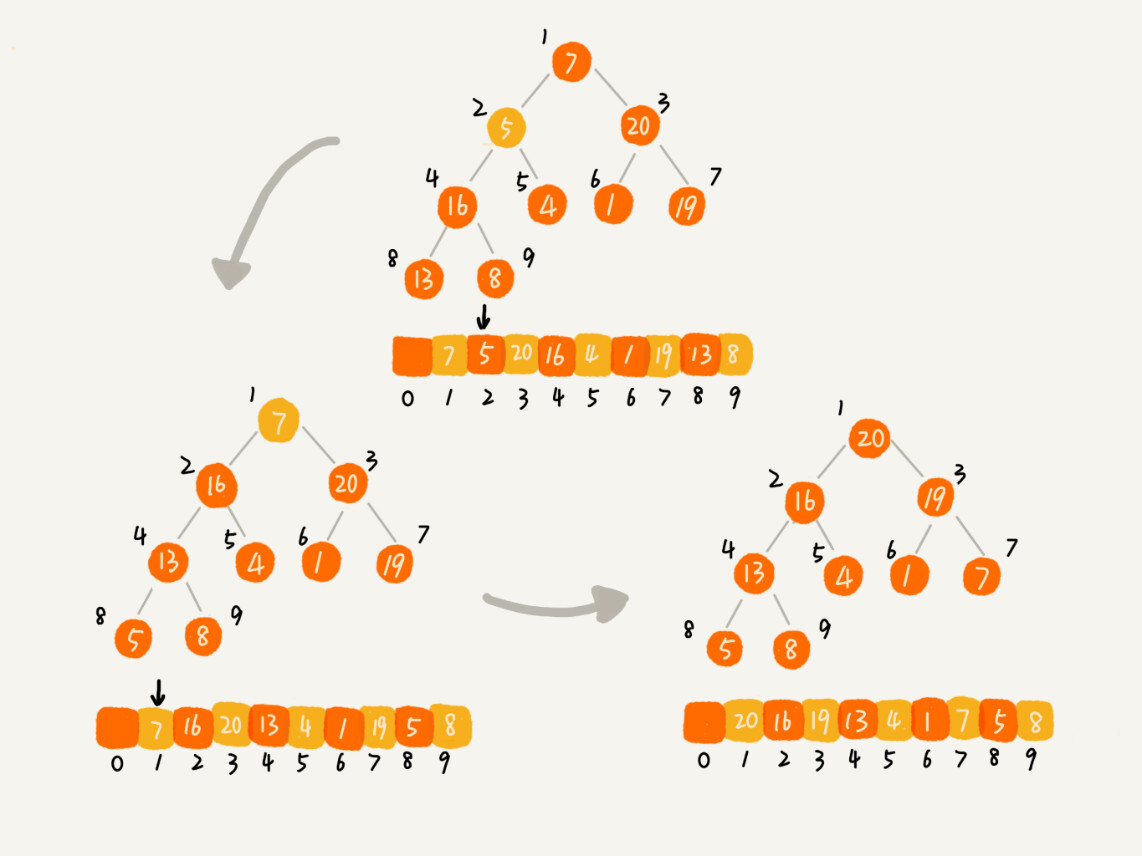
-
为什么从8开始呢,因为在这段代码中,我们对下标从 2/n 开始到 1 的数据进行堆化,下标是 2/n+1 到 n 的节点是叶子节点,我们不需要堆化。实际上,对于完全二叉树来说,下标从 2/n+1 到 n 的节点都是叶子节点。
-
建堆的时间复杂度是 O(n)。
-
-
-
-
排序
-
建堆结束之后,数组中的数据已经是按照大顶堆的特性来组织的。数组中的第一个元素就是堆顶,也就是最大的元素。我们把它跟最后一个元素交换,那最大元素就放到了下标为 n 的位置。
-
这个过程有点类似上面讲的“删除堆顶元素”的操作,当堆顶元素移除之后,我们把下标为 n 的元素放到堆顶,然后再通过堆化的方法,将剩下的 n−1 个元素重新构建成堆。堆化完成之后,我们再取堆顶的元素,放到下标是 n−1 的位置,一直重复这个过程,直到最后堆中只剩下标为 1 的一个元素,排序工作就完成了。
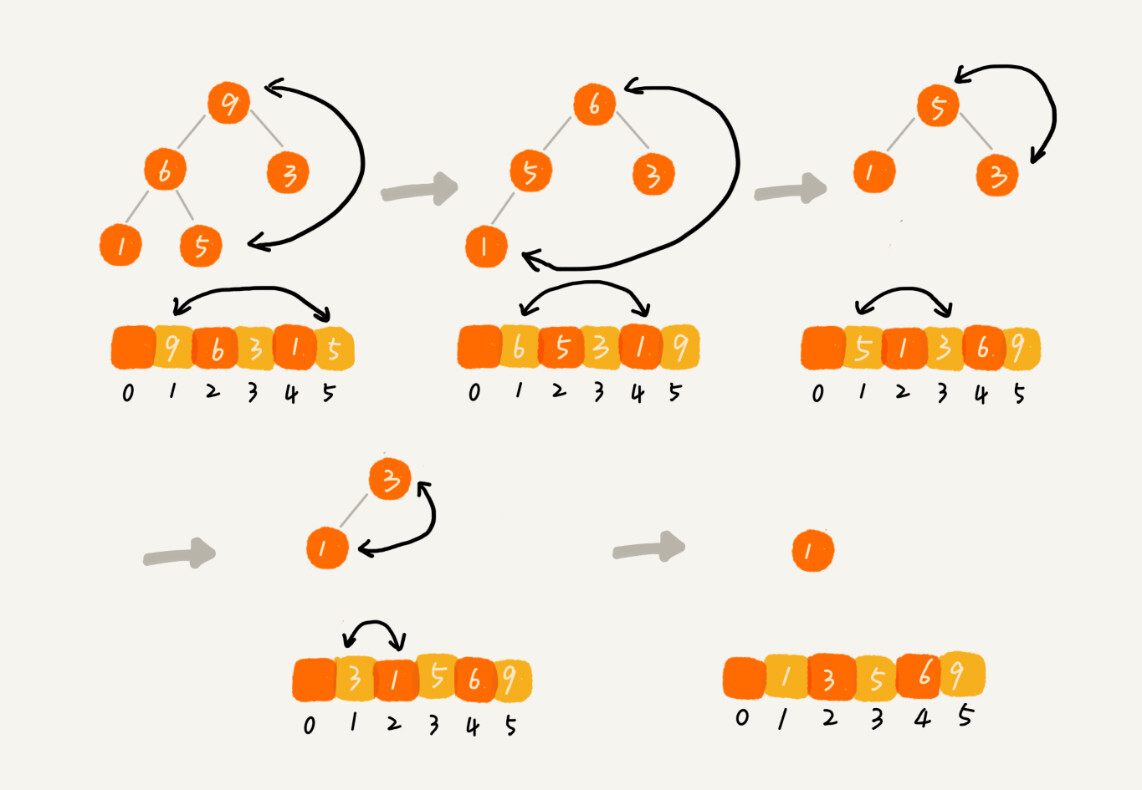
-
总的来说就是大顶堆的话拿掉头放最后其他的重新建堆,以此类推
-
整个堆排序的过程,都只需要极个别临时存储空间,所以堆排序是原地排序算法。堆排序包括建堆和排序两个操作,建堆过程的时间复杂度是 O(n),排序过程的时间复杂度是 O(nlogn),所以,堆排序整体的时间复杂度是 O(nlogn)。
-
-
在前面的讲解以及代码中,我都假设,堆中的数据是从数组下标为 1 的位置开始存储。那如果从 0 开始存储,实际上处理思路是没有任何变化的,唯一变化的,可能就是,代码实现的时候,计算子节点和父节点的下标的公式改变了。
-
如果节点的下标是 i,那左子节点的下标就是 2∗i+1,右子节点的下标就是 2∗i+2,父节点的下标就是 i−1/2。
-
-
为什么快速排序要比堆排序性能好?
-
堆排序数据访问的方式没有快速排序友好。
对于快速排序来说,数据是顺序访问的。而对于堆排序来说,数据是跳着访问的。 比如,堆排序中,最重要的一个操作就是数据的堆化。而不是像快速排序那样,局部顺序访问,所以,这样对 CPU 缓存是不友好的。
-
对于同样的数据,在排序过程中,堆排序算法的数据交换次数要多于快速排序。
-
-
大顶堆代码完整实现
public class MaxHeap { private int[] _data; private int _capacity;//容器大小 private int _count;//当前元素个数 public MaxHeap(int capacity) { _capacity = capacity; _count = 0; _data = new int[capacity]; } //根据指定数组构建一个堆 public MaxHeap(int[] data) { _data = data; _capacity = _data.Length; _count = _capacity; BuildHeap(_data, _count); } public void Insert(int value) { if (_count >= _capacity)//容器已满 return; _data[_count++] = value; BuildHeapUp(_count-1); } public void Remove() { if (_count == 0) return; _data[0] = _data[--_count]; BuildHeapDown(_data,_count,0); } // 自下往上堆化 private void BuildHeapUp(int i) { while ((i - 1) / 2 >= 0 && _data[(i - 1) / 2] < _data[i]) { Swap(_data, i, (i - 1) / 2); i = (i - 1) / 2; } } //自上往下堆化 private void BuildHeapDown(int[] arr,int count,int i) { int swapPos = i; while (i < count) { swapPos = i; if (i * 2 + 1 < count && arr[swapPos] < arr[i * 2 + 1]) swapPos = i * 2 + 1; if (i * 2 + 2 < count && arr[swapPos] < arr[i * 2 + 2])//细节是这里比的是swapos,因为要选左右子树里最大的来和自己换 swapPos = i * 2 + 2; if(swapPos == i) break; Swap(arr, i, swapPos); i = swapPos; } } public int Peek() { if (_count == 0) throw new Exception("heap is empty"); return _data[0]; } //堆排序 public void Sort(int[] arr) { //建堆 BuildHeap(arr, arr.Length); for (int i = arr.Length - 1; i > 0; i--) { Swap(arr, 0, i); BuildHeapDown(arr, i, 0); //重新维护堆 } } public void BuildHeap(int[] arr,int count) { for (int i = count/ 2 + 1; i >= 0; i--) { BuildHeapDown(arr,count,i); } } private void Swap(int[] arr, int i, int j) { int tmp = arr[i]; arr[i] = arr[j]; arr[j] = tmp; } } -
堆的应用
-
堆的应用一:优先级队列
- 如何实现一个优先级队列呢?方法有很多,但是用堆来实现是最直接、最高效的。这是因为,堆和优先级队列非常相似。一个堆就可以看作一个优先级队列。很多时候,它们只是概念上的区分而已。往优先级队列中插入一个元素,就相当于往堆中插入一个元素;从优先级队列中取出优先级最高的元素,就相当于取出堆顶元素。
- 例
- 合并有序小文件
- 假设我们有 100 个小文件,每个文件的大小是 100MB,每个文件中存储的都是有序的字符串。我们希望将这些 100 个小文件合并成一个有序的大文件。
- 整体思路有点像归并排序中的合并函数。我们从这 100 个文件中,各取第一个字符串,放入数组中,然后比较大小,把最小的那个字符串放入合并后的大文件中,并从数组中删除。假设,这个最小的字符串来自于 13.txt 这个小文件,我们就再从这个小文件取下一个字符串,放到数组中,重新比较大小,并且选择最小的放入合并后的大文件,将它从数组中删除。依次类推,直到所有的文件中的数据都放入到大文件为止。
- 高性能定时器
- 假设我们有一个定时器,定时器中维护了很多定时任务,每个任务都设定了一个要触发执行的时间点。定时器每过一个很小的单位时间(比如 1 秒),就扫描一遍任务,看是否有任务到达设定的执行时间。如果到达了,就拿出来执行。
- 但是,这样每过 1 秒就扫描一遍任务列表的做法比较低效,主要原因有两点:第一,任务的约定执行时间离当前时间可能还有很久,这样前面很多次扫描其实都是徒劳的;第二,每次都要扫描整个任务列表,如果任务列表很大的话,势必会比较耗时。
- 针对这些问题,我们就可以用优先级队列来解决。我们按照任务设定的执行时间,将这些任务存储在优先级队列中,队列首部(也就是小顶堆的堆顶)存储的是最先执行的任务。
- 它拿队首任务的执行时间点,与当前时间点相减,得到一个时间间隔 T。这个时间间隔 T 就是,从当前时间开始,需要等待多久,才会有第一个任务需要被执行。这样,定时器就可以设定在 T 秒之后,再来执行任务。从当前时间点到(T-1)秒这段时间里,定时器都不需要做任何事情。
- 当 T 秒时间过去之后,定时器取优先级队列中队首的任务执行。然后再计算新的队首任务的执行时间点与当前时间点的差值,把这个值作为定时器执行下一个任务需要等待的时间。
- 这样,定时器既不用间隔 1 秒就轮询一次,也不用遍历整个任务列表,性能也就提高了
- 合并有序小文件
-
堆的应用二:利用堆求 Top K
- 求 Top K 的问题一类是针对静态数据集合,也就是说数据集合事先确定,不会再变。
- 如何在一个包含 n 个数据的数组中,查找前 K 大数据呢?
- 我们可以维护一个大小为 K 的小顶堆,顺序遍历数组,从数组中取出数据与堆顶元素比较。如果比堆顶元素大,我们就把堆顶元素删除,并且将这个元素插入到堆中;如果比堆顶元素小,则不做处理,继续遍历数组。这样等数组中的数据都遍历完之后,堆中的数据就是前 K 大数据了。
- 遍历数组需要 O(n) 的时间复杂度,一次堆化操作需要 O(logK) 的时间复杂度,所以最坏情况下,n 个元素都入堆一次,时间复杂度就是 O(nlogK)。
- 如何在一个包含 n 个数据的数组中,查找前 K 大数据呢?
- 另一类是针对动态数据集合,也就是说数据集合事先并不确定,有数据动态地加入到集合中。
- 针对动态数据求得 Top K 就是实时 Top K。怎么理解呢?我举一个例子。一个数据集合中有两个操作,一个是添加数据,另一个询问当前的前 K 大数据。
- 如果每次询问前 K 大数据,我们都基于当前的数据重新计算的话,那时间复杂度就是 O(nlogK),n 表示当前的数据的大小。实际上,我们可以一直都维护一个 K 大小的小顶堆,当有数据被添加到集合中时,我们就拿它与堆顶的元素对比。如果比堆顶元素大,我们就把堆顶元素删除,并且将这个元素插入到堆中;如果比堆顶元素小,则不做处理。这样,无论任何时候需要查询当前的前 K 大数据,我们都可以立刻返回给他。
- 求 Top K 的问题一类是针对静态数据集合,也就是说数据集合事先确定,不会再变。
-
堆的应用三:利用堆求中位数
-
中位数,顾名思义,就是处在中间位置的那个数。如果数据的个数是奇数,把数据从小到大排列,那第 n/2+1 个数据就是中位数(注意:假设数据是从 0 开始编号的);如果数据的个数是偶数的话,那处于中间位置的数据有两个,第 n/2 个和第 n/2+1 个数据,这个时候,我们可以随意取一个作为中位数,比如取两个数中靠前的那个,就是第 n/2 个数据
-
对于一组静态数据,中位数是固定的,我们可以先排序,第 n/2 个数据就是中位数。每次询问中位数的时候,我们直接返回这个固定的值就好了。所以,尽管排序的代价比较大,但是边际成本会很小。
-
但是,如果我们面对的是动态数据集合,中位数在不停地变动,如果再用先排序的方法,每次询问中位数的时候,都要先进行排序,那效率就不高了
-
借助堆这种数据结构,我们不用排序,就可以非常高效地实现求中位数操作。我们来看看,它是如何做到的?
-
我们需要维护两个堆,一个大顶堆,一个小顶堆。大顶堆中存储前半部分数据,小顶堆中存储后半部分数据,且小顶堆中的数据都大于大顶堆中的数据。如果 n 是奇数,情况是类似的,大顶堆就存储 n/2+1 个数据,小顶堆中就存储 n/2 个数据
-
数据是动态变化的,当新添加一个数据的时候,我们如何调整两个堆,让大顶堆中的堆顶元素继续是中位数呢?
-
如果新加入的数据小于等于大顶堆的堆顶元素,我们就将这个新数据插入到大顶堆;否则,我们就将这个新数据插入到小顶堆。
-
这个时候就有可能出现,两个堆中的数据个数不符合前面约定的情况,这个时候,我们可以从一个堆中不停地将堆顶元素移动到另一个堆,通过这样的调整,来让两个堆中的数据满足上面的约定。
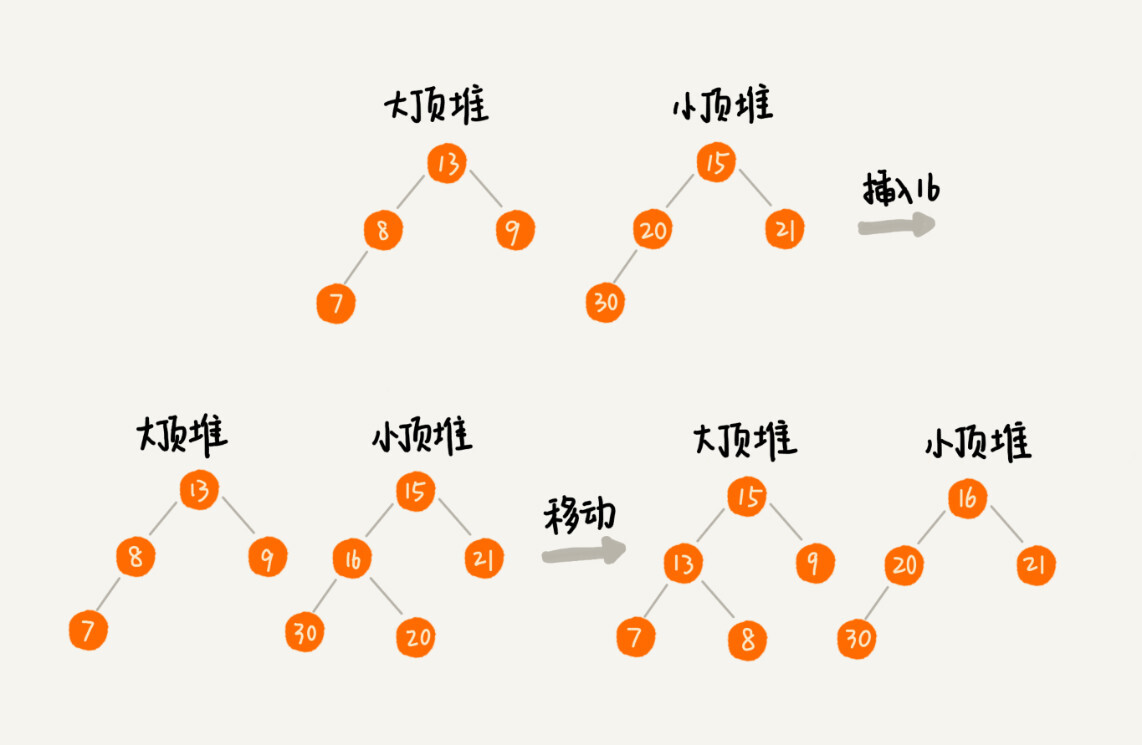
-
于是,我们就可以利用两个堆,一个大顶堆、一个小顶堆,实现在动态数据集合中求中位数的操作。插入数据因为需要涉及堆化,所以时间复杂度变成了 O(logn),但是求中位数我们只需要返回大顶堆的堆顶元素就可以了,所以时间复杂度就是 O(1)。
-
实际上,利用两个堆不仅可以快速求出中位数,还可以快速求其他百分位的数据,原理是类似的
-
-
-
假设现在我们有一个包含 10 亿个搜索关键词的日志文件,可以使用的内存为 1GB,如何快速获取到 Top 10 最热门的搜索关键词呢?
- 因为用户搜索的关键词,有很多可能都是重复的,所以我们首先要统计每个搜索关键词出现的频率。我们可以通过散列表、平衡二叉查找树或者其他一些支持快速查找、插入的数据结构,来记录关键词及其出现的次数。
- 假设我们选用散列表。我们就顺序扫描这 10 亿个搜索关键词。当扫描到某个关键词时,我们去散列表中查询。如果存在,我们就将对应的次数加一;如果不存在,我们就将它插入到散列表,并记录次数为 1。以此类推,等遍历完这 10 亿个搜索关键词之后,散列表中就存储了不重复的搜索关键词以及出现的次数。
- 然后,我们再根据前面讲的用堆求 Top K 的方法,建立一个大小为 10 的小顶堆,遍历散列表,依次取出每个搜索关键词及对应出现的次数,然后与堆顶的搜索关键词对比。如果出现次数比堆顶搜索关键词的次数多,那就删除堆顶的关键词,将这个出现次数更多的关键词加入到堆中。
- 以此类推,当遍历完整个散列表中的搜索关键词之后,堆中的搜索关键词就是出现次数最多的 Top 10 搜索关键词了。
- 但是其实这种解决方式是有漏洞的
- 10 亿的关键词还是很多的。我们假设 10 亿条搜索关键词中不重复的有 1 亿条,如果每个搜索关键词的平均长度是 50 个字节,那存储 1 亿个关键词起码需要 5GB 的内存空间,而散列表因为要避免频繁冲突,不会选择太大的装载因子,所以消耗的内存空间就更多了。而我们的机器只有 1GB 的可用内存空间,所以我们无法一次性将所有的搜索关键词加入到内存中。
- 相同数据经过哈希算法得到的哈希值是一样的。我们可以根据哈希算法的这个特点,将 10 亿条搜索关键词先通过哈希算法分片到 10 个文件中
- 具体可以这样做:我们创建 10 个空文件 00,01,02,……,09。我们遍历这 10 亿个关键词,并且通过某个哈希算法对其求哈希值,然后哈希值同 10 取模,得到的结果就是这个搜索关键词应该被分到的文件编号。
- 对这 10 亿个关键词分片之后,每个文件都只有 1 亿的关键词,去除掉重复的,可能就只有 1000 万个,每个关键词平均 50 个字节,所以总的大小就是 500MB。1GB 的内存完全可以放得下。
- 我们针对每个包含 1 亿条搜索关键词的文件,利用散列表和堆,分别求出 Top 10,然后把这个 10 个 Top 10 放在一块,然后取这 100 个关键词中,出现次数最多的 10 个关键词,这就是这 10 亿数据中的 Top 10 最频繁的搜索关键词了。
-
图
-
如何理解“图”
-
我们知道,树中的元素我们称为节点,图中的元素我们就叫做顶点(vertex)。从我画的图中可以看出来,图中的一个顶点可以与任意其他顶点建立连接关系。我们把这种建立的关系叫做边(edge)。
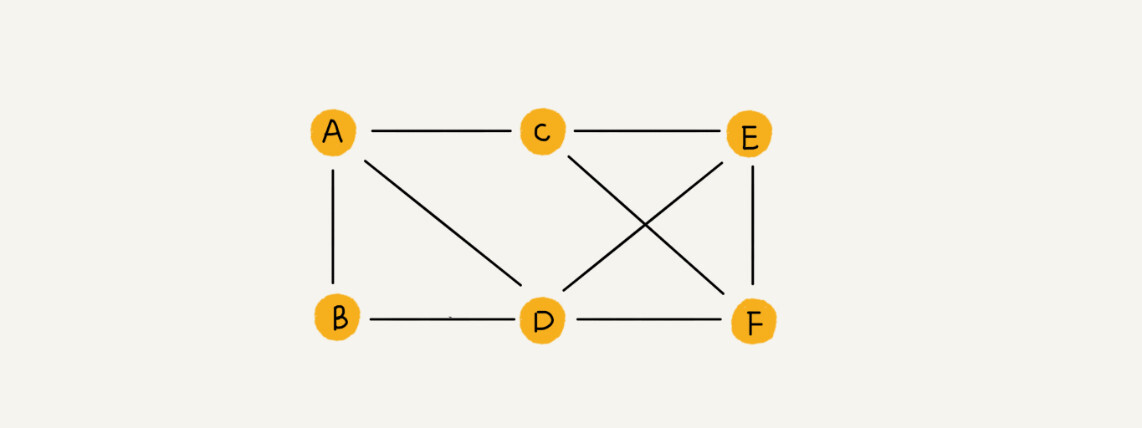
-
微信举例子吧。我们可以把每个用户看作一个顶点。如果两个用户之间互加好友,那就在两者之间建立一条边。所以,整个微信的好友关系就可以用一张图来表示。其中,每个用户有多少个好友,对应到图中,就叫做顶点的度(degree),就是跟顶点相连接的边的条数。
-
可以把刚刚讲的图结构稍微改造一下,引入边的“方向”的概念。如果用户 A 关注了用户 B,我们就在图中画一条从 A 到 B 的带箭头的边,来表示边的方向。如果用户 A 和用户 B 互相关注了,那我们就画一条从 A 指向 B 的边,再画一条从 B 指向 A 的边。我们把这种边有方向的图叫做“有向图”。以此类推,我们把边没有方向的图就叫做“无向图”。
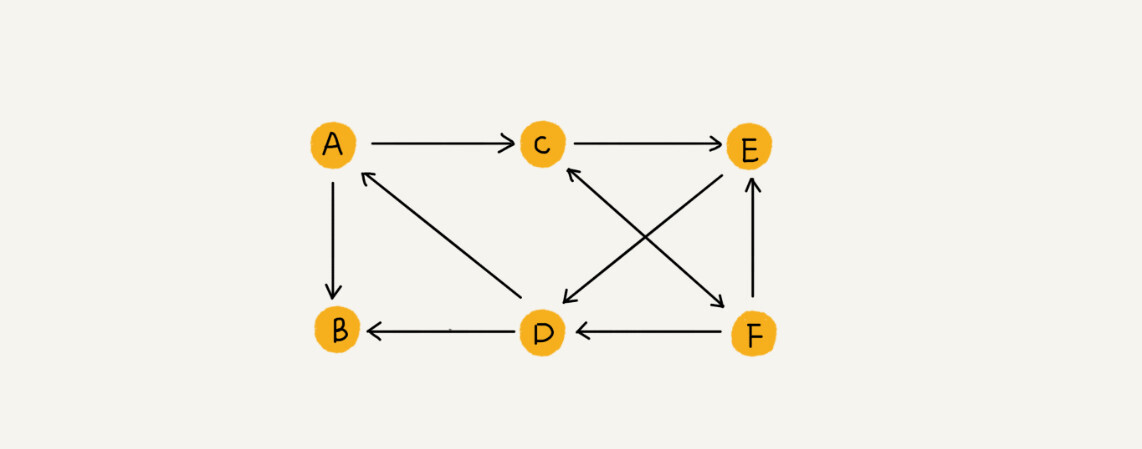
-
无向图中有“度”这个概念,表示一个顶点有多少条边。在有向图中,我们把度分为入度(In-degree)和出度(Out-degree)。
-
顶点的入度,表示有多少条边指向这个顶点;顶点的出度,表示有多少条边是以这个顶点为起点指向其他顶点。对应到微博的例子,入度就表示有多少粉丝,出度就表示关注了多少人。
-
带权图(weighted graph)。在带权图中,每条边都有一个权重(weight),我们可以通过这个权重来表示 QQ 好友间的亲密度。
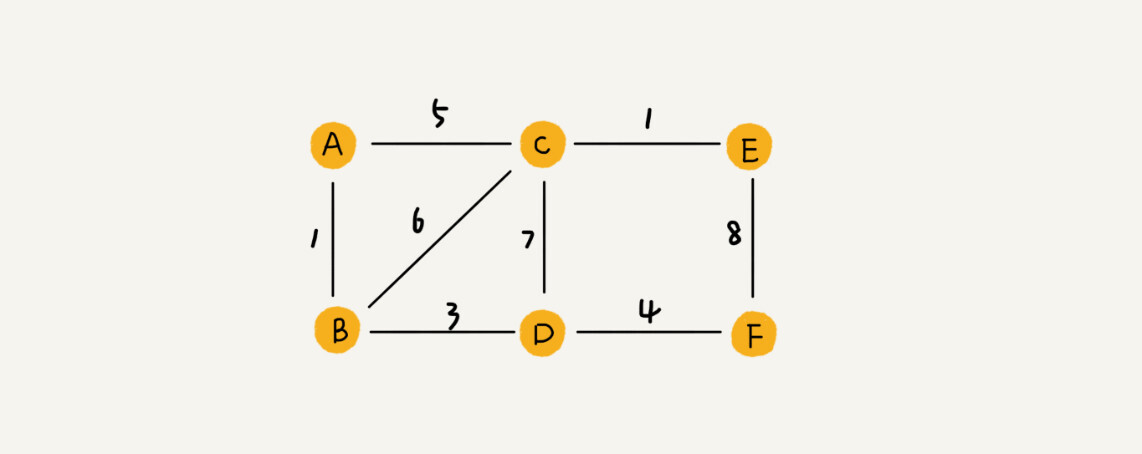
-
-
图的存储方式
-
邻接矩阵存储方法
-
图最直观的一种存储方法就是,邻接矩阵(Adjacency Matrix)。
-
邻接矩阵的底层依赖一个二维数组。对于无向图来说,如果顶点 i 与顶点 j 之间有边,我们就将 A[i][j]和 A[j][i]标记为 1;对于有向图来说,如果顶点 i 到顶点 j 之间,有一条箭头从顶点 i 指向顶点 j 的边,那我们就将 A[i][j]标记为 1。同理,如果有一条箭头从顶点 j 指向顶点 i 的边,我们就将 A[j][i]标记为 1。对于带权图,数组中就存储相应的权重。
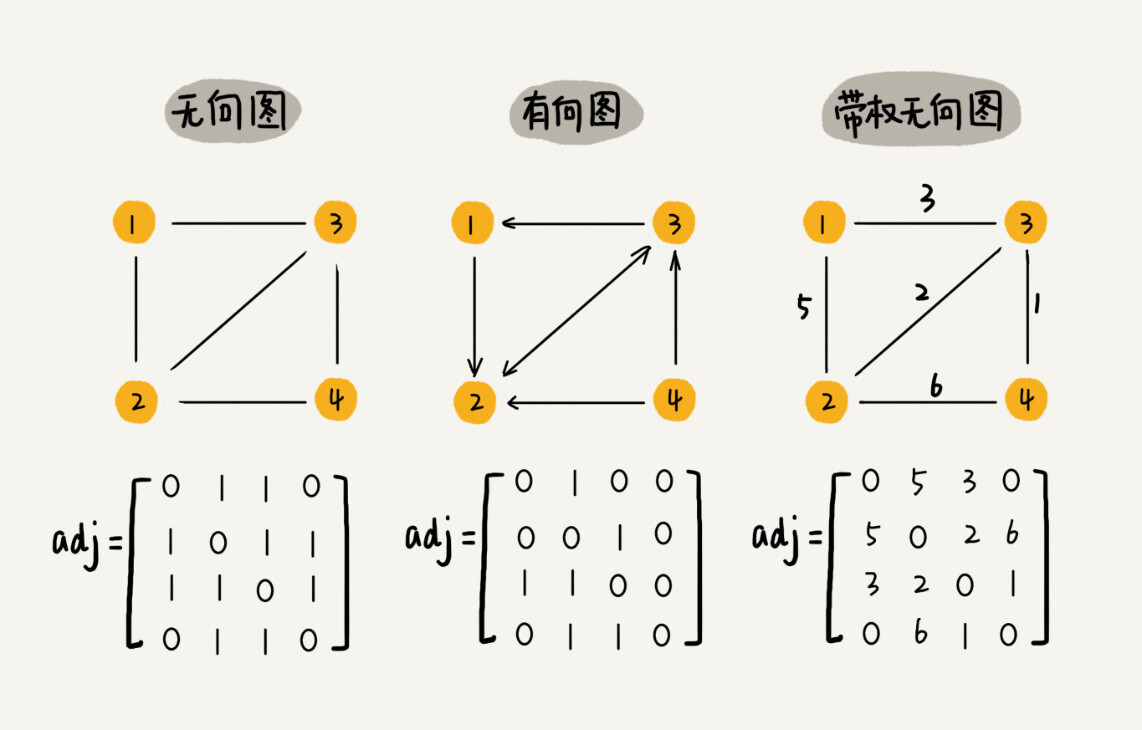
-
邻接矩阵的缺点
- 用邻接矩阵来表示一个图,虽然简单、直观,但是比较浪费存储空间。
- 如果我们存储的是稀疏图(Sparse Matrix),也就是说,顶点很多,但每个顶点的边并不多,那邻接矩阵的存储方法就更加浪费空间了。
-
邻接矩阵的存储方法的优点
- 邻接矩阵的存储方式简单、直接,因为基于数组,所以在获取两个顶点的关系时,就非常高效。
- 用邻接矩阵存储图的另外一个好处是方便计算。这是因为,用邻接矩阵的方式存储图,可以将很多图的运算转换成矩阵之间的运算。
-
-
邻接表存储方法
-
图中画的是一个有向图的邻接表存储方式,每个顶点对应的链表里面,存储的是指向的顶点。对于无向图来说,也是类似的,不过,每个顶点的链表中存储的,是跟这个顶点有边相连的顶点
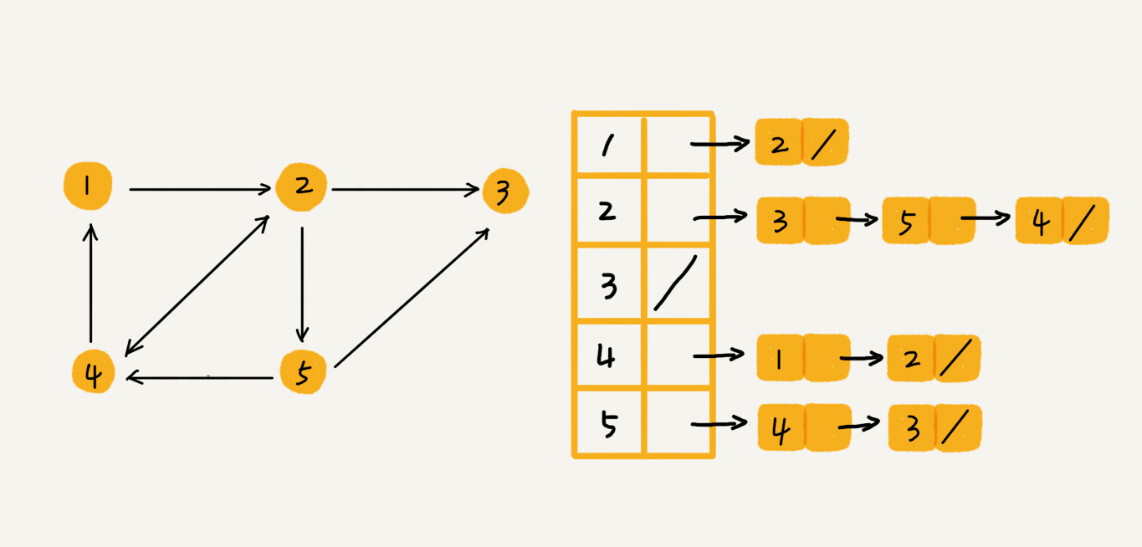
-
邻接矩阵存储起来比较浪费空间,但是使用起来比较节省时间。相反,邻接表存储起来比较节省空间,但是使用起来就比较耗时间。
-
我们可以将邻接表中的链表改成平衡二叉查找树。实际开发中,我们可以选择用红黑树。这样,我们就可以更加快速地查找两个顶点之间是否存在边了。当然,这里的二叉查找树可以换成其他动态数据结构,比如跳表、散列表等。除此之外,我们还可以将链表改成有序动态数组,可以通过二分查找的方法来快速定位两个顶点之间否是存在边。
-
-
-
假设针对微博用户关系,假设我们需要支持下面这样几个操作:
- 判断用户 A 是否关注了用户 B;
- 判断用户 A 是否是用户 B 的粉丝;
- 用户 A 关注用户 B
- 用户 A 取消关注用户 B;
- 根据用户名称的首字母排序,分页获取用户的粉丝列表;
- 根据用户名称的首字母排序,分页获取用户的关注列表
-
因为社交网络是一张稀疏图,使用邻接矩阵存储比较浪费存储空间。所以,这里我们采用邻接表来存储。
-
不过,用一个邻接表来存储这种有向图是不够的。我们去查找某个用户关注了哪些用户非常容易,但是如果要想知道某个用户都被哪些用户关注了,也就是用户的粉丝列表,是非常困难的。
-
基于此,我们需要一个逆邻接表。邻接表中存储了用户的关注关系,逆邻接表中存储的是用户的被关注关系。
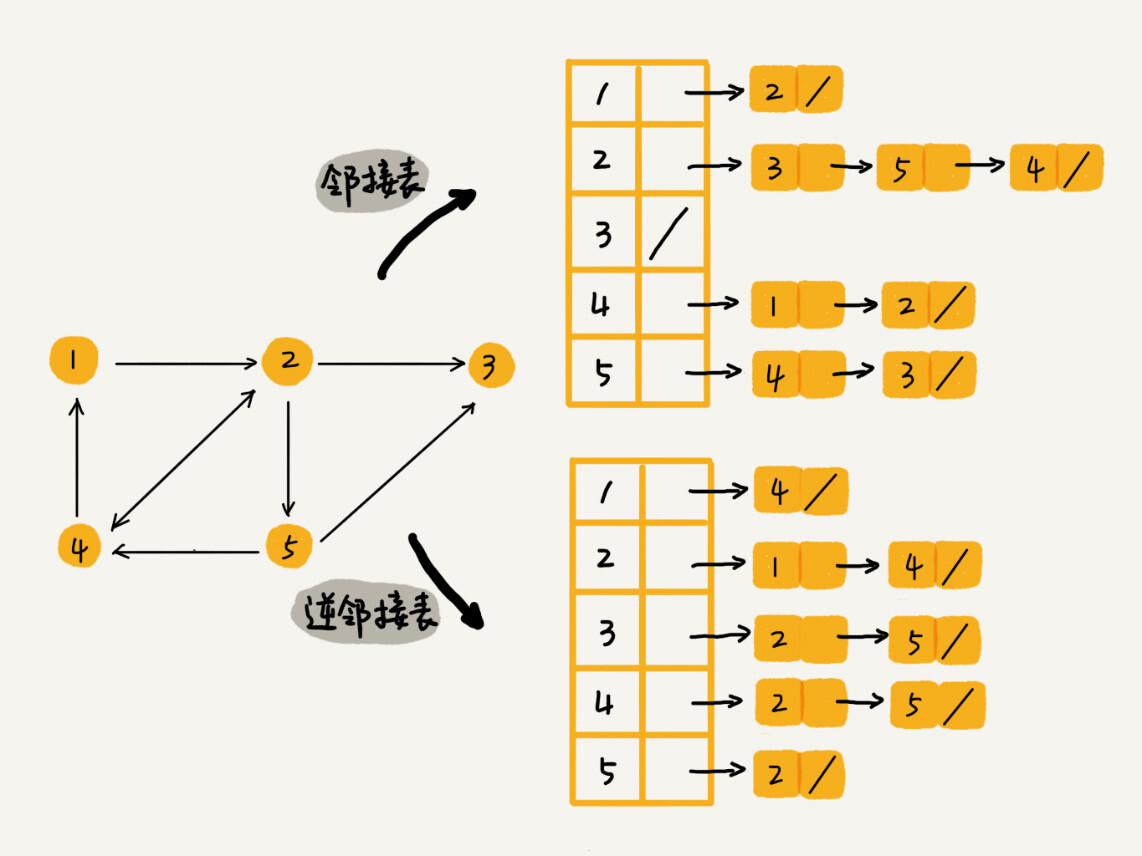
-
基础的邻接表不适合快速判断两个用户之间是否是关注与被关注的关系,所以我们选择改进版本,将邻接表中的链表改为支持快速查找的动态数据结构。选择哪种动态数据结构呢?红黑树、跳表、有序动态数组还是散列表呢?
- 因为我们需要按照用户名称的首字母排序,分页来获取用户的粉丝列表或者关注列表,用跳表这种结构再合适不过了。这是因为,跳表插入、删除、查找都非常高效,时间复杂度是 O(logn),空间复杂度上稍高,是 O(n)。最重要的一点,跳表中存储的数据本来就是有序的了,分页获取粉丝列表或关注列表,就非常高效。
-
如果对于小规模的数据,比如社交网络中只有几万、几十万个用户,我们可以将整个社交关系存储在内存中,上面的解决思路是没有问题的。但是如果像微博那样有上亿的用户,数据规模太大,我们就无法全部存储在内存中了。这个时候该怎么办呢?
- 我们可以通过哈希算法等数据分片方式,将邻接表存储在不同的机器上。你可以看下面这幅图,我们在机器 1 上存储顶点 1,2,3 的邻接表,在机器 2 上,存储顶点 4,5 的邻接表。逆邻接表的处理方式也一样。当要查询顶点与顶点关系的时候,我们就利用同样的哈希算法,先定位顶点所在的机器,然后再在相应的机器上查找。
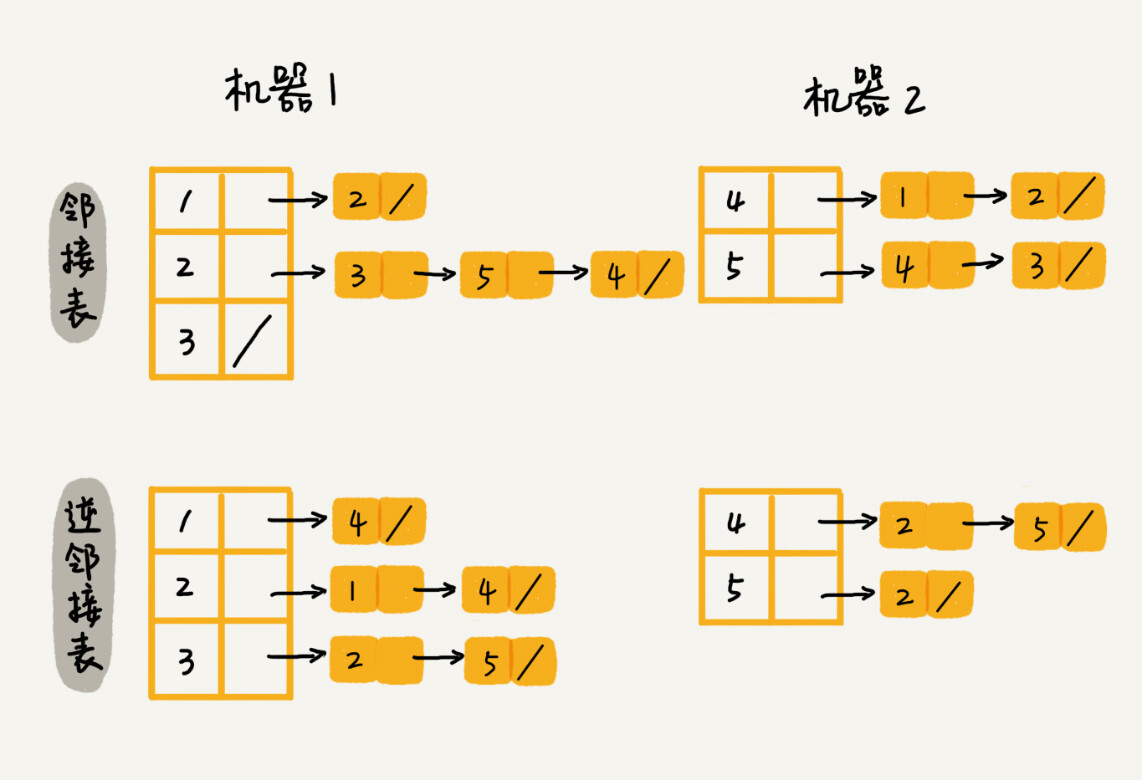
-
除此之外,我们还有另外一种解决思路,就是利用外部存储(比如硬盘),因为外部存储的存储空间要比内存会宽裕很多。数据库是我们经常用来持久化存储关系数据的
-
广度优先搜索(BFS)
-
广度优先搜索(Breadth-First-Search),我们平常都简称 BFS。直观地讲,它其实就是一种“地毯式”层层推进的搜索策略,即先查找离起始顶点最近的,然后是次近的,依次往外搜索。理解起来并不难,所以我画了一张示意图,你可以看下。
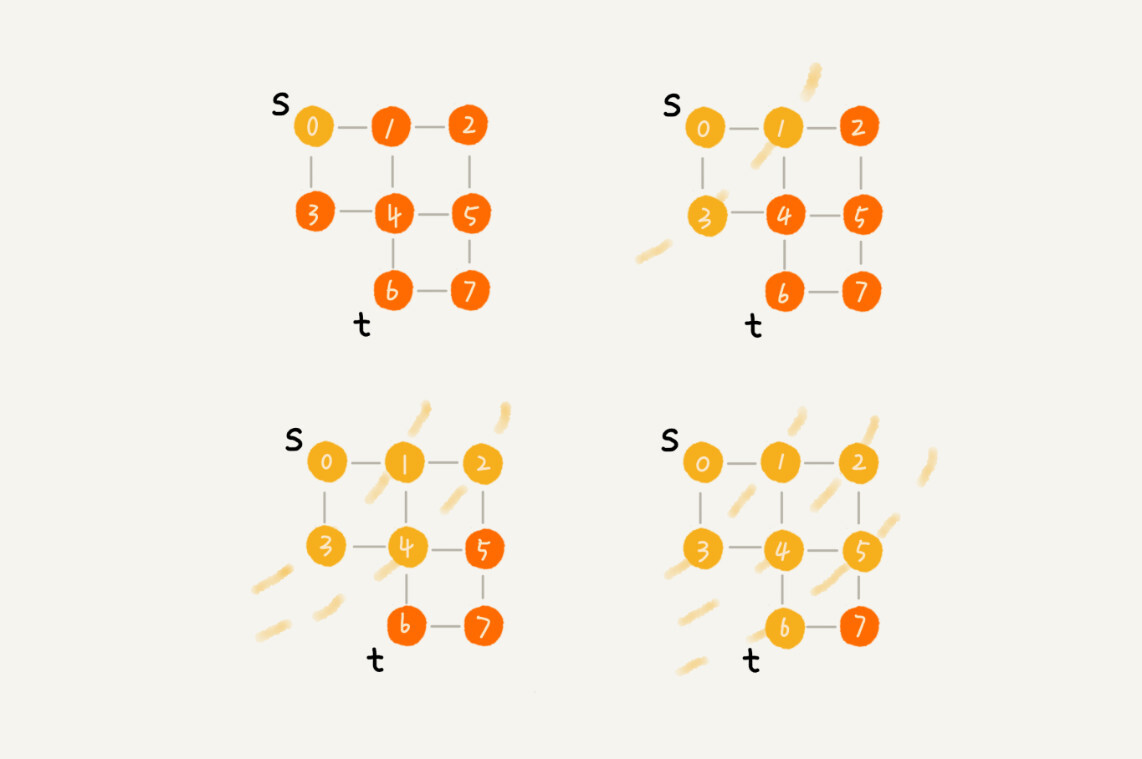
-
但代码实现还是稍微有点复杂度。所以,我们重点讲一下它的代码实现。
//s 表示起始顶点,t 表示终止顶点。我们搜索一条从 s 到 t 的路径。实际上,这样求得的路径就是从 s 到 t 的最短路径。 public void bfs(int s, int t) { if (s == t) return; boolean[] visited = new boolean[v];//记录已经被访问的顶点 visited[s]=true; Queue<Integer> queue = new LinkedList<>();//用来存储已经被访问、但相连的顶点还没有被访问的顶点。 queue.add(s); int[] prev = new int[v];//prev 用来记录搜索路径。当前顶点从哪个顶点过来的 for (int i = 0; i < v; ++i) { prev[i] = -1; } while (queue.size() != 0) { int w = queue.poll(); for (int i = 0; i < adj[w].size(); ++i) { int q = adj[w].get(i); if (!visited[q]) { prev[q] = w; if (q == t) { print(prev, s, t); return; } visited[q] = true; queue.add(q); } } } } private void print(int[] prev, int s, int t) { // 递归打印s->t的路径 if (prev[t] != -1 && t != s) { print(prev, s, prev[t]); } System.out.print(t + " "); } -
这段代码不是很好理解,里面有三个重要的辅助变量 visited、queue、prev。只要理解这三个变量,读懂这段代码估计就没什么问题了。
- visited 是用来记录已经被访问的顶点,用来避免顶点被重复访问。如果顶点 q 被访问,那相应的 visited[q]会被设置为 true。
- queue 是一个队列,用来存储已经被访问、但相连的顶点还没有被访问的顶点。因为广度优先搜索是逐层访问的,也就是说,我们只有把第 k 层的顶点都访问完成之后,才能访问第 k+1 层的顶点。当我们访问到第 k 层的顶点的时候,我们需要把第 k 层的顶点记录下来,稍后才能通过第 k 层的顶点来找第 k+1 层的顶点。所以,我们用这个队列来实现记录的功能。
- prev 用来记录搜索路径。当我们从顶点 s 开始,广度优先搜索到顶点 t 后,prev 数组中存储的就是搜索的路径。不过,这个路径是反向存储的。prev[w]存储的是,顶点 w 是从哪个前驱顶点遍历过来的。比如,我们通过顶点 2 的邻接表访问到顶点 3,那 prev[3]就等于 2。为了正向打印出路径,我们需要递归地来打印,你可以看下 print() 函数的实现方式。
-
把代码翻译成图示就能很好看懂了
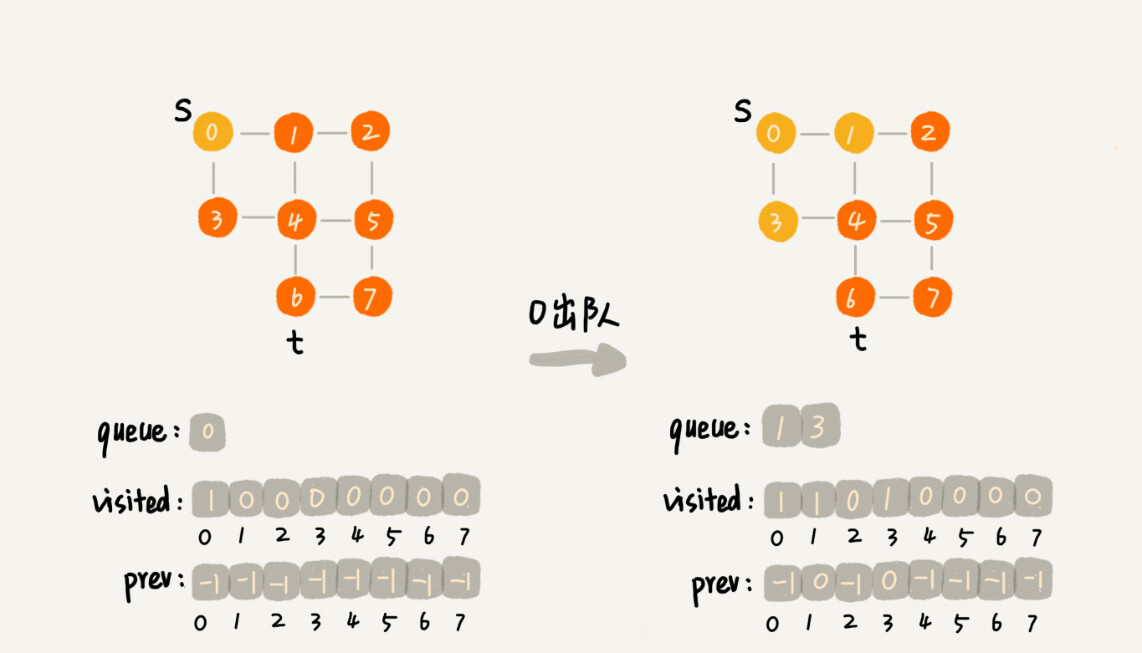
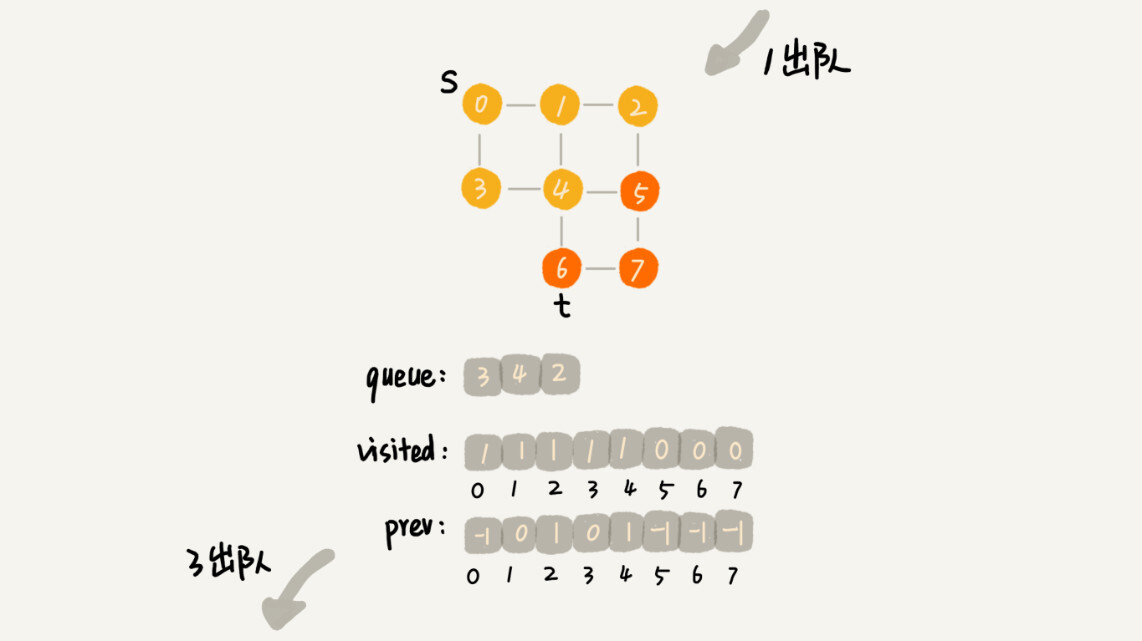
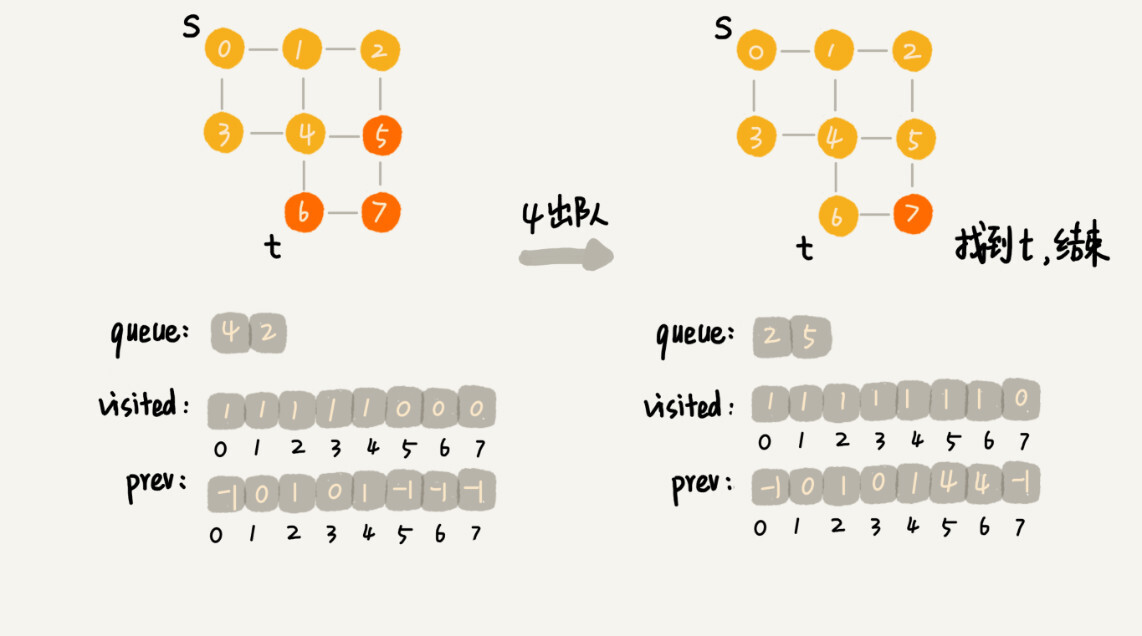
-
广度优先搜索的时间、空间复杂度是多少呢?
- 最坏情况下,终止顶点 t 离起始顶点 s 很远,需要遍历完整个图才能找到。这个时候,每个顶点都要进出一遍队列,每个边也都会被访问一次,所以,广度优先搜索的时间复杂度是 O(V+E),其中,V 表示顶点的个数,E 表示边的个数。当然,对于一个连通图来说,也就是说一个图中的所有顶点都是连通的,E 肯定要大于等于 V-1,所以,广度优先搜索的时间复杂度也可以简写为 O(E)。
- 广度优先搜索的空间消耗主要在几个辅助变量 visited 数组、queue 队列、prev 数组上。这三个存储空间的大小都不会超过顶点的个数,所以空间复杂度是 O(V)。
-
-
深度优先搜索(DFS)
-
深度优先搜索(Depth-First-Search),简称 DFS。最直观的例子就是“走迷宫”。
-
假设你站在迷宫的某个岔路口,然后想找到出口。你随意选择一个岔路口来走,走着走着发现走不通的时候,你就回退到上一个岔路口,重新选择一条路继续走,直到最终找到出口。这种走法就是一种深度优先搜索策略。
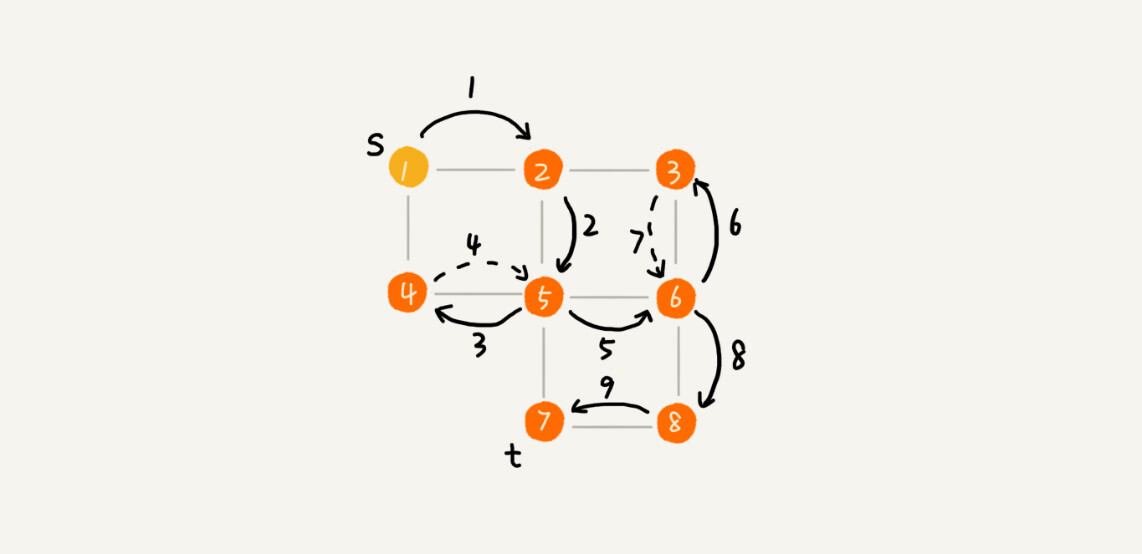
-
实际上,深度优先搜索用的是一种比较著名的算法思想,回溯思想。
-
我把上面的过程用递归来翻译出来,就是下面这个样子。我们发现,深度优先搜索代码实现也用到了 prev、visited 变量以及 print() 函数,它们跟广度优先搜索代码实现里的作用是一样的。不过,深度优先搜索代码实现里,有个比较特殊的变量 found,它的作用是,当我们已经找到终止顶点 t 之后,我们就不再递归地继续查找了。
boolean found = false; // 全局变量或者类成员变量 public void dfs(int s, int t) { found = false; boolean[] visited = new boolean[v]; int[] prev = new int[v]; for (int i = 0; i < v; ++i) { prev[i] = -1; } recurDfs(s, t, visited, prev); print(prev, s, t); } private void recurDfs(int w, int t, boolean[] visited, int[] prev) { if (found == true) return; visited[w] = true; if (w == t) { found = true; return; } for (int i = 0; i < adj[w].size(); ++i) { int q = adj[w].get(i); if (!visited[q]) { prev[q] = w; recurDfs(q, t, visited, prev); } } } -
深度优先搜索的时间、空间复杂度是多少呢?
- 从我前面画的图可以看出,每条边最多会被访问两次,一次是遍历,一次是回退。所以,图上的深度优先搜索算法的时间复杂度是 O(E),E 表示边的个数。
- 深度优先搜索算法的消耗内存主要是 visited、prev 数组和递归调用栈。visited、prev 数组的大小跟顶点的个数 V 成正比,递归调用栈的最大深度不会超过顶点的个数,所以总的空间复杂度就是 O(V)。
-

