Lua知识树整理————lua源码分析
lua源码分析
-
-
数据类型的分类
#define LUA_TNONE (-1) //空类型 #define LUA_TNIL 0 //nil #define LUA_TBOOLEAN 1 //布尔 #define LUA_TLIGHTUSERDATA 2//指针 #define LUA_TNUMBER 3//数字 #define LUA_TSTRING 4//字符串 #define LUA_TTABLE 5//表 #define LUA_TFUNCTION 6//函数 #define LUA_TUSERDATA 7//指针 #define LUA_TTHREAD 8//虚拟机,携程 //可以看到除了LUA_TNONE,lua支持了9种基本类型。其实对于某些基本类型,lua还用了一个叫做variant tag的标记来定义其子类型,具体参见下图: /* Variant tags for functions */ #define LUA_TLCL (LUA_TFUNCTION | (0 << 4)) /* Lua closure (对于lua函数来说没有函数这个概念,所有的lua函数都是一个lua闭包)*/ #define LUA_TLCF (LUA_TFUNCTION | (1 << 4)) /* light C function (C函数) */ #define LUA_TCCL (LUA_TFUNCTION | (2 << 4)) /* C closure (c闭包)*/ /* Variant tags for strings */ #define LUA_TSHRSTR (LUA_TSTRING | (0 << 4)) /* short strings */ #define LUA_TLNGSTR (LUA_TSTRING | (1 << 4)) /* long strings */ /* Variant tags for numbers */ #define LUA_TNUMFLT (LUA_TNUMBER | (0 << 4)) /* float numbers */ #define LUA_TNUMINT (LUA_TNUMBER | (1 << 4)) /* integer numbers */ //string又细分为短string和长string,主要区别在于它们的hash值生成;而number也细分为了float和integer。 -
Type的组织方式
-
Value和TValue
首先,lua为了方便对所有的类型进行统一管理,把它们都抽象成了一个叫做Value的union结构,具体定义如下
/* ** Tagged Values. This is the basic representation of values in Lua, ** an actual value plus a tag with its type. */ /* ** Union of all Lua values */ typedef union Value { GCObject *gc; /* collectable objects */ void *p; /* light userdata */ int b; /* booleans */ lua_CFunction f; /* light C functions */ lua_Integer i; /* integer numbers */ lua_Number n; /* float numbers */ } Value; /* 从定义可以看出,主要把这些类型划分为了需要GC的类型和不需要GC的类型。由于Value是union的结构,所以每个Value实例里同时只会有一个字段是有效的。而为了知道具体哪个字段是有效的,也就是具体该Value是什么类型,从而有了TValue这个struct结构,主要在Value基础上wrap了一个_tt字段来标识Value的具体类型。TValue的定义如下:*/ #define TValuefields Value value_; int tt_ typedef struct lua_TValue { TValuefields; } TValue; -
GCUnion、GCObject、CommonHeader
lua把所有值按是否需要被GC,划分为了GCObject和一般类型。所有需要被GC的类型,被定义在了GCUnion里:
/* ** Union of all collectable objects (only for conversions) */ union GCUnion { GCObject gc; /* common header */ struct TString ts; struct Udata u; union Closure cl; struct Table h; struct Proto p; struct lua_State th; /* thread */ }; /*可以发现String、UserData、Closure、Table、Proto、luaState等类型都是需要被GC的,GCUnion结构和Value类似,也是同时只有一个字段是有效的。所以我们自然而然会想到,是不是类似TValue一样,在外面给包一层type呢,但是lua实现这边并没有这样做,而是让TString、UData这些"子类"都在各自定义的开头定义这个type字段。实际上,是定义了一个叫做CommonHeader的宏,这个宏里包含了type和一些其他字段,而每个GC类型都需要在在其struct头部定义该宏,从而可以造成一种所有GC类型都继承自一个带有CommonHeader宏的基类的假象。该宏定义如下:*/ #define CommonHeader GCObject *next; lu_byte tt; lu_byte marked struct GCObject { CommonHeader; }; /* 可以发现,它一共有三个字段: tt,即该GC对象的具体类型 next,指向GCObject的指针,用于GC算法内部实现链表 marked,用于GC算法内部实现 GCObject,其实它就是把CommonHeader这个数据区包成了一个struct,它的好处在于lua可以把所有的GC类型的对象都视作是一个GCObject,比如在lua_State结构里就定义了一个GC列表: GCObject* gclist。 */
-
-
-
-
长串和短串
在讲String的数据结构和重要函数前,先强调一点,出于对性能和内存等方面的考虑,lua对String实现的方方面面,都把短字符串和长字符串区分开来处理了。比如短串会走一个先查询再创建的路子,而长串不查询,直接创建。我个人的理解大概是出于以下两个方面考虑:
- 复用度。短串复用度会比长串要高,或者说短串在全局的引用计数一般会比长串高。比如obj["id"] = 12, obj["type"] = 0,类似"id"、"type"这种短串可能会在程序很多处地方使用到,如果开辟多份就有点浪费了。而长串则很少会有重复的,比如我一篇文章的文本,一般不会在两个地方重复打出来。
- 哈希效率。由于长串的字符串比较多,如果要把组成它的字符序列进行哈希,耗时会比短串长。
- 从定义可以看出,长度大于40的,在lua中处理为长串,反之则为短串。
-
String的基本数据结构
-
lua中string的实现为TString结构体:
typedef struct TString { CommonHeader; //gc用结构体 lu_byte extra; /* 对于短串,主要用于实现保留字符串;对于长串,作为一个标识,来表示该串有没有进行过hash,这点可以结合hash字段来理解。*/ lu_byte shrlen; /* 短串的长度,对于长串没有意义。 */ unsigned int hash;/* 该字符串的hash值,如果是短串,该hash值是在创建时就计算出来的,这是因为短串会加入到全局的stringtable这个hashmap结构中;而对于长串来说,这个hash字段是按需的,只有真正需要它的hash值时,手动调用luaS_hashlongstr函数,才会生成该值,lua内部现在只有在把长串作为table的key时,才会去计算它。当extra字段为0时,表示该长串的hash还没计算过,否则表示已经计算过了 */ union { /* 当是短串时,由于会被加入到全局stringtable的链表中,所以在该结构中保存了指向下一个TString的指针;当是长串时,表示该长串的长度。注意长串和短串没有共用一个字段来表示它们的长度,主要是长串的长度可以很长,而短串最长就为40,一个byte就够用了,这边也体现了lua实现是很抠细节的,反倒是把这两个不相关的字段打包到一个union里来节约内存了。 */ size_t lnglen; /* length for long strings */ struct TString *hnext; /* linked list for hash table */ } u; } TString; -
stringtable
typedef struct stringtable { TString **hash;//基于TString的hashmap,也叫做散列桶。基本结构是一个数组,每个数组里存的是相同hash值的TString的链表。 int nuse; /* 当前实际的元素数 */ int size; /* 桶个数 */ } stringtable;
-
-
string实现中的重要函数
-
luaS_newlstr函数
/*创建给定长度的string接口,由于lua内部对短串和长串的处理采用了两套方案,所以该函数会根据string的实际长度来决定调用短串处理函数(internshrstr)还是长串处理函数(luaS_createlngstrobj)。*/ TString *luaS_newlstr (lua_State *L, const char *str, size_t l) { if (l <= LUAI_MAXSHORTLEN) /* short string? */ return internshrstr(L, str, l); else { TString *ts; if (l >= (MAX_SIZE - sizeof(TString))/sizeof(char)) luaM_toobig(L); ts = luaS_createlngstrobj(L, l); memcpy(getstr(ts), str, l * sizeof(char)); return ts; } } -
internshrstr函数
static TString *internshrstr (lua_State *L, const char *str, size_t l) { TString *ts; global_State *g = G(L); /* hash查找。会先调用luaS_hash来得到字符串的hash值,然后去全局stringtable里查找,如果有就直接返回该TString对象。hash的具体实现可以参照luaS_hash函数,为了对长度较长的字符串不逐位hash,内部也是根据长度的2次幂计算出了一个步长step,来加速hash的过程。 */ unsigned int h = luaS_hash(str, l, g->seed); TString **list = &g->strt.hash[lmod(h, g->strt.size)]; lua_assert(str != NULL); /* otherwise 'memcmp'/'memcpy' are undefined */ for (ts = *list; ts != NULL; ts = ts->u.hnext) { if (l == ts->shrlen && (memcmp(str, getstr(ts), l * sizeof(char)) == 0)) { /* found! */ if (isdead(g, ts)) /* dead (but not collected yet)? */ changewhite(ts); /* resurrect it */ return ts; } } /* hashtable按需resize。如果第一步查找失败了,并且stringtable的元素数量已经大于桶数,那么以两倍的尺寸对stringtable进行resize。具体调用的是luaS_resize函数。 */ if (g->strt.nuse >= g->strt.size && g->strt.size <= MAX_INT/2) { luaS_resize(L, g->strt.size * 2); list = &g->strt.hash[lmod(h, g->strt.size)]; /* recompute with new size */ } /* 实际的TString创建工作。主要是调用createstrobj函数来实现。其中包括了内存的分配,CommonHeader的填充,TString特化字段的填充等。 */ ts = createstrobj(L, l, LUA_TSHRSTR, h); memcpy(getstr(ts), str, l * sizeof(char)); ts->shrlen = cast_byte(l); ts->u.hnext = *list; *list = ts; g->strt.nuse++; /* 更新stringtable信息。比如更新stringtable的链表,以及对stringtable的元素数量加1。 */ return ts; } -
luaS_reisze函数
/* 实际改变stringtable桶数量的函数。它目前只会被两个地方调用到: 1.短string创建时(internshrstr函数),如果发现桶数量小于了元素数量,说明散列比较拥挤了,会对桶进行两倍的扩容。 2.在gc时,如果发现桶数量大于了4倍的元素数量,说明散列太稀疏了,会对桶数量进行减半操作。 */ void luaS_resize (lua_State *L, int newsize) { int i; stringtable *tb = &G(L)->strt; /* newsize>oldsize。这个时候的顺序是,先进行扩容,然后进行rehash。扩容跟到里面去调用的就是realloc函数。 而rehash的代码也很简洁,就是简单的遍历每个桶,把每个桶里的元素再哈希到正确的桶里去 */ if (newsize > tb->size) { /* grow table if needed */ luaM_reallocvector(L, tb->hash, tb->size, newsize, TString *); for (i = tb->size; i < newsize; i++) tb->hash[i] = NULL; } for (i = 0; i < tb->size; i++) { /* rehash */ TString *p = tb->hash[i]; tb->hash[i] = NULL; while (p) { /* for each node in the list */ TString *hnext = p->u.hnext; /* save next */ unsigned int h = lmod(p->hash, newsize); /* new position */ p->u.hnext = tb->hash[h]; /* chain it */ tb->hash[h] = p; p = hnext; } } /* newsize < oldsize。顺序是倒过来的,需要先根据newsize进行rehash,然后在保证所有元素已经收缩到newsize个数的桶里以后,才能进行shrink操作,这里也是调用的realloc函数来实现。 */ if (newsize < tb->size) { /* shrink table if needed */ /* vanishing slice should be empty */ lua_assert(tb->hash[newsize] == NULL && tb->hash[tb->size - 1] == NULL); luaM_reallocvector(L, tb->hash, tb->size, newsize, TString *); } tb->size = newsize; } /* luaM_realloc_速览, frealloc(ud, NULL, x, s) 可以创建一个新的内存块,大小为s frealloc(ud, p, x, 0) 释放内存块b 底层调用(*g->frealloc),lua就是普通malloc,如果想设计的话可以尝试类似gunc的pool malloc或者bit map malloc做缓存池,我后面有空来试试,通过lua_setallocf接口可以设置这个frealloc函数 */ void *luaM_realloc_ (lua_State *L, void *block, size_t osize, size_t nsize) { void *newblock; global_State *g = G(L); size_t realosize = (block) ? osize : 0; lua_assert((realosize == 0) == (block == NULL)); #if defined(HARDMEMTESTS) if (nsize > realosize && g->gcrunning) luaC_fullgc(L, 1); /* force a GC whenever possible */ #endif newblock = (*g->frealloc)(g->ud, block, osize, nsize); if (newblock == NULL && nsize > 0) { lua_assert(nsize > realosize); /* cannot fail when shrinking a block */ if (g->version) { /* is state fully built? */ luaC_fullgc(L, 1); /* try to free some memory... */ newblock = (*g->frealloc)(g->ud, block, osize, nsize); /* try again */ } if (newblock == NULL) luaD_throw(L, LUA_ERRMEM); } lua_assert((nsize == 0) == (newblock == NULL)); g->GCdebt = (g->GCdebt + nsize) - realosize; return newblock; } -
createstrobj函数
static TString *createstrobj (lua_State *L, size_t l, int tag, unsigned int h) { TString *ts; GCObject *o; size_t totalsize; /* total size of TString object */ totalsize = sizelstring(l);//计算该string需要占用的内存大小size。lua实际把string的char数组紧贴UTString结构来存储,所以一个string实例实际占用内存大小其实是UTString结构占用,再加上(charlength+1)个char大小: o = luaC_newobj(L, tag, totalsize);//调用luaC_newobj来创建一个GC对象,该函数也是lua中相当重要的函数了。它负责了所有GCObject子类的创建,它会根据实际传入的内存大小来开辟空间,并帮忙填充掉CommonHeader的数据。最后,它还会把该obj挂接到global_State中的allgc列表中,以供GC模块使用。 ts = gco2ts(o); ts->hash = h; ts->extra = 0; getstr(ts)[l] = '\0'; //填充对象的TString特化字段。并且给char数组末尾添'\0'。 return ts; }
-
-
总结
在理完了string牵涉的主要数据结构和函数以后。从整个宏观的情况来理解lua的string:
- 首先,它是一个GCObject的子类,也就意味着它是被垃圾回收模块所管理的。
- 其次,它的长度决定了它的内部实现机制:短串意味着hashtable管理和内存去重;长串意味着内存副本。
- 最后,全局的hashtable大小,取决于string的创建和gc的sizecheck检查。
-
-
- 虚拟机基本概念
- 虚拟机指借助软件系统对物理机器指令执行进行的一种模拟。首先,对于物理机器的执行,主要是机器从内存中fetch指令,通过总线传输到CPU,然后进行译码、执行、结果存储等步骤。既然虚拟机是对其进行的一种模拟,那么也逃不过以下几个特点:
- 将源码编译成VM所能执行的字节码。
- 字节码格式(指令格式),例如三元式、四元式、波兰式等。
- 函数调用的相关栈结构,函数的出入口和传参方式。
- 指令指针,类似于物理机的指令寄存器(EIP)。
- 虚拟CPU。 instruction dispatche
- 取指:通过IP fetch下一条指令
- 译码:对指令进行翻译,得到指令类型,并且解析其操作数。
- 执行:跳到对应逻辑块进行执行。
- 虚拟机基本概念
-
-
栈式虚拟机和寄存器式虚拟机
-
栈式虚拟机
-
采用栈式虚拟机的语言有JVM、CPython以及.Net CLR等。
-
基于栈的虚拟机有一个操作数栈的概念,虚拟机在进行真正的运算时都是直接与操作数栈(operand stack)进行交互,不能直接操作内存中数据(其实这句话不严谨的,虚拟机的操作数栈也是布局在内存上的),也就是说不管进行何种操作都要通过操作数栈来进行,即使是数据传递这种简单的操作。这样做的直接好处就是虚拟机可以无视具体的物理架构,特别是寄存器。但缺点也显而易见,就是速度慢,因为无论什么操作都要通过操作数栈这一结构。:
-
-
寄存器式虚拟机
- 采用寄存器式的虚拟机有lua和Dalvik等。
- 这种实现没有操作数栈这一概念,但是会有许多的虚拟寄存器。这类虚拟寄存器有别于CPU的寄存器,因为CPU寄存器往往是定址的(比如DX本身就是能存东西),而寄存器式的虚拟机中的寄存器通常有两层含义:
- 寄存器别名(比如lua里的RA、RB、RC、RBx等),它们往往只是起到一个地址映射的功能,它会根据指令中跟操作数相关的字段计算出操作数实际的内存地址,从而取出操作数进行计算;
- 实际寄存器,有点类似操作数栈,也是一个全局的运行时栈,只不过这个栈是跟函数走的,一个函数对应一个栈帧,栈帧里每个slot就是一个寄存器,第1步中通过别名映射后的地址就是每个slot的地址。具体的栈帧可以参考后文讲CallInfo时的栈帧图。 好处是指令条数少,数据转移次数少。坏处是单挑指令长度较长。
- 具体来看,lua里的实际寄存器数组是用TValue结构的栈来模拟的,这个栈也是lua和C进行交互的虚拟栈。 lua里的字节码叫做opcode,
-
-
关键函数和结构分析
-
luaL_dofile
//包含了luaL_loadfile和lua_pcall两个步骤,分别对应了函数的解析和执行阶段。 #define luaL_dofile(L, fn) \ (luaL_loadfile(L, fn) || lua_pcall(L, 0, LUA_MULTRET, 0)) -
luaL_loadfile
#define luaL_loadfile(L,f) luaL_loadfilex(L,f,NULL) //再跟进去核心是会调用到lua_load LUA_API int lua_load (lua_State *L, lua_Reader reader, void *data, const char *chunkname, const char *mode) { ZIO z; int status; lua_lock(L); if (!chunkname) chunkname = "?"; luaZ_init(L, &z, reader, data); status = luaD_protectedparser(L, &z, chunkname, mode);//这句话是重点,对lua代码进行进行词法和语法分析,把source转化成opcode,并创建Proto结构保存该opcode和该函数的元信息 if (status == LUA_OK) { /* no errors? */ LClosure *f = clLvalue(L->top - 1); /* get newly created function */ if (f->nupvalues >= 1) { /* does it have an upvalue? */ /* get global table from registry */ Table *reg = hvalue(&G(L)->l_registry); const TValue *gt = luaH_getint(reg, LUA_RIDX_GLOBALS); /* set global table as 1st upvalue of 'f' (may be LUA_ENV) */ setobj(L, f->upvals[0]->v, gt); luaC_upvalbarrier(L, f->upvals[0]); } } lua_unlock(L); return status; } //---快进n步到closefunc函数里面就初始化了Proto结构和信息 static void close_func (LexState *ls) { lua_State *L = ls->L; FuncState *fs = ls->fs; Proto *f = fs->f; luaK_ret(fs, 0, 0); /* final return */ leaveblock(fs); luaM_reallocvector(L, f->code, f->sizecode, fs->pc, Instruction); f->sizecode = fs->pc; luaM_reallocvector(L, f->lineinfo, f->sizelineinfo, fs->pc, int); f->sizelineinfo = fs->pc; luaM_reallocvector(L, f->k, f->sizek, fs->nk, TValue); f->sizek = fs->nk; luaM_reallocvector(L, f->p, f->sizep, fs->np, Proto *); f->sizep = fs->np; luaM_reallocvector(L, f->locvars, f->sizelocvars, fs->nlocvars, LocVar); f->sizelocvars = fs->nlocvars; luaM_reallocvector(L, f->upvalues, f->sizeupvalues, fs->nups, Upvaldesc); f->sizeupvalues = fs->nups; lua_assert(fs->bl == NULL); ls->fs = fs->prev; luaC_checkGC(L); } // Proto结构如下: typedef struct Proto { CommonHeader; lu_byte numparams; /* number of fixed parameters */ lu_byte is_vararg; lu_byte maxstacksize; /* number of registers needed by this function */ int sizeupvalues; /* size of 'upvalues' */ int sizek; /* size of 'k' */ int sizecode; int sizelineinfo; int sizep; /* size of 'p' */ int sizelocvars; int linedefined; /* debug information */ int lastlinedefined; /* debug information */ TValue *k; /* constants used by the function */ Instruction *code; /* opcodes */ struct Proto **p; /* functions defined inside the function */ int *lineinfo; /* map from opcodes to source lines (debug information) */ LocVar *locvars; /* information about local variables (debug information) */ Upvaldesc *upvalues; /* upvalue information */ struct LClosure *cache; /* last-created closure with this prototype */ TString *source; /* used for debug information */ GCObject *gclist; } Proto; /* 该结构基本涵盖了parse阶段该函数的所有分析信息。主要包括以下几部分: 常量表。比如在函数里写了a = 1 + 2,那这里的1和2就会放在常量表里。 局部变量信息。包含了局部变量的名字和它在函数中的生存周期区间(用pc来衡量)。 Upvalue信息。包含了该upvalue的名字和它是否归属于本函数栈还是外层函数栈的标记。 opcode列表。包含了该函数实际调用的所有指令。其实就是一个int32类型的列表,因为lua虚拟机里每个指令对应一个int32. */ -
lua_pcall
这个函数最终会调到luaD_call,也就是lua虚拟机里函数执行的主要函数。
void luaD_call (lua_State *L, StkId func, int nResults) { if (++L->nCcalls >= LUAI_MAXCCALLS) stackerror(L); if (!luaD_precall(L, func, nResults)) /* is a Lua function? */ luaV_execute(L); /* call it */ L->nCcalls--; }-
luaD_precall:
- 如果是C函数或者C闭包,会直接创建单个函数调用的运行时结构CallInfo,来完成函数的进栈和出栈。
- 如果是lua闭包,在precall中只会做函数调用前的准备工作,实际执行会在后一步luaV_execute中进行。这里的准备工作主要包括:(1)处理lua的不定长参数、参数数量不够时的nil填充等。(2)分配CallInfo结构,并填充该函数运行时所需的base、top、opcode等信息,注意CallInfo结构里还有个很关键的func字段,它指向栈里对应的LClosure结构,这个结构为虚拟机后续执行提供upvalue表和常量表的查询,毕竟后续对常量和upvalue的read操作,都是需要把它们从这两个表中加载到寄存器里的。
-
luaV_execute
- 这一步就是我们前面提到的lua虚拟机的CPU了,因为所有指令的实际执行都是在这个函数里完成的。它做的主要工作,就是在一个大循环里,不断的fetch和dispatch指令。每次的fetch就是把pc加1,而dispatch就是一个大的swtich-case,每个不同类型的opcode对应不同的执行逻辑。
-
CallInfo
//CallInfo结构,包含了单个函数调用,lua虚拟机所需要的辅助数据结构,它的结构如下: typedef struct CallInfo { StkId func; /* function index in the stack */ StkId top; /* top for this function */ struct CallInfo *previous, *next; /* dynamic call link */ union { struct { /* only for Lua functions */ StkId base; /* base for this function */ const Instruction *savedpc; } l; struct { /* only for C functions */ lua_KFunction k; /* continuation in case of yields */ ptrdiff_t old_errfunc; lua_KContext ctx; /* context info. in case of yields */ } c; } u; ptrdiff_t extra; short nresults; /* expected number of results from this function */ unsigned short callstatus; } CallInfo; /* 我们来看下lua_State里与之相关的几个字段: stack。TValue*类型,记录了"内存"起始地址。 base。TValue*类型,记录当前函数的第一个参数位置。 top。TValue*类型,记录当前函数的栈顶。 base_ci。当前栈里所有的函数调用CallInfo数组。 ci。当前函数的CallInfo。 可以发现,通过这样的组织结构,luavm可以方便的获取到任意函数的位置以及其中的所有参数位置。而每个CallInfo里又记录了函数的执行pc,因此vm对函数的执行可以说是了如指掌了。 */
-
-
-
-
Table的设计特点
- 容器功能:与其他语言相似,lua也内置了容器功能,也就是table。而与其他语言不同的是,lua内置容器只有table。正因为如此,为了适配不同的应用需求,table的内部结构也比较考究,分为了数组和哈希表两个部分,根据不同需求来决定使用哪个部分。
- 面向对象功能:与其他语言不同的时,lua并没有把面向对象的功能以语法的形式包装给开发者。而是保留了这样一种能力,待开发者去实现自己的面向对象。而这一保留的能力,也是封装在table里的:table里可以组合一个metatable,这个metatable本身也是一个table,它的字段用来描述原table的行为。
-
Table的数据结构
typedef struct Table { CommonHeader;//垃圾回收通用结构 lu_byte flags; /*用于cache该表中实现了哪些元方法 */ lu_byte lsizenode; /* 哈希表大小取log2(哈希表大小只会为2的n次幂) */ unsigned int sizearray; /* 数组大小(数组大小只会为2的n次幂) */ TValue *array; /* 数组头指针 */ Node *node;//哈希表头指针 Node *lastfree; /* 哈希表可用尾指针,可用的节点只会小于该lastfree节点。 */ struct Table *metatable;//元表 GCObject *gclist;//GC的链表,用于垃圾回收 } Table;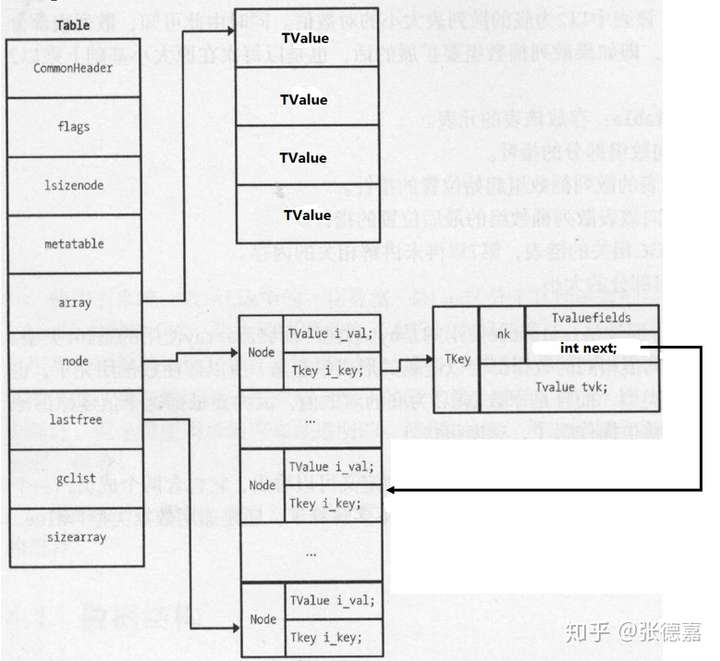
-
Table的重要操作
-
查询操作
/* 查询key是否存在,分为了int和非int类型。如果key是int类型并且小于sizearray,那么直接返回对应slot。 否则走hash表查询该key对应的slot。 */ const TValue *luaH_get (Table *t, const TValue *key) { switch (ttype(key)) { case LUA_TSHRSTR: return luaH_getshortstr(t, tsvalue(key)); case LUA_TNUMINT: return luaH_getint(t, ivalue(key));/* integer numbers */ case LUA_TNIL: return luaO_nilobject; case LUA_TNUMFLT: {/* float numbers */ lua_Integer k; if (luaV_tointeger(key, &k, 0)) /* index is int? */ return luaH_getint(t, k); /* use specialized version */ /* else... */ } /* FALLTHROUGH */ default: return getgeneric(t, key); } } -
新增元素
//由于lua对于下标超过数组的大小的数字,都会存储在散列表部分去,所以数组部分的插值不会触发rehash //散列表的组织,就是多个mainposition,每个单独的mainposition会对应一个数据链表,当插入一个key的时候,会调用luaHset\luaH_setnum\luaH_setstr,来获得该key对应的TValue指针,如果没有,则调用内部的newkey函数来分配一个新的key TValue *luaH_newkey (lua_State *L, Table *t, const TValue *key) { Node *mp; TValue aux; //...安全性校验,略 mp = mainposition(t, key);//根据key寻找再当前hash中的位置 if (!ttisnil(gval(mp)) || isdummy(t)) { /*如果该位置已经有数据了(ttisnil(gval(mp)))或者找不到该位置 (isdummy(t))*/ Node *othern; Node *f = getfreepos(t); /* 尝试获取一个空闲位置 */ if (f == NULL) { //如果freepos为NULL(没有可用空间了),调用rehash来扩容。rehash的具体细节将在后文详解。 rehash(L, t, key); /* grow table */ return luaH_set(L, t, key); /* insert key into grown table */ } lua_assert(!isdummy(t)); //找到newkey的mainposition,看是否可用,如果可用直接使用 othern = mainposition(t, gkey(mp)); if (othern != mp) { //如果占用节点的hash值与newkey不同,说明该节点是被“挤”到该位置来的,那么把该节点挪到freepos去,然后让newkey入住其mainposition。 while (othern + gnext(othern) != mp) /* find previous */ othern += gnext(othern); gnext(othern) = cast_int(f - othern); /* rechain to point to 'f' */ *f = *mp; /* copy colliding node into free pos. (mp->next also goes) */ if (gnext(mp) != 0) { gnext(f) += cast_int(mp - f); /* correct 'next' */ gnext(mp) = 0; /* now 'mp' is free */ } setnilvalue(gval(mp)); } else { //占用的节点和newkey的哈希值相同,那么直接插入到该mainposition的next。 if (gnext(mp) != 0) gnext(f) = cast_int((mp + gnext(mp)) - f); /* chain new position */ else lua_assert(gnext(f) == 0); gnext(mp) = cast_int(f - mp); mp = f; } } setnodekey(L, &mp->i_key, key); luaC_barrierback(L, t, key); lua_assert(ttisnil(gval(mp))); return gval(mp); } -
rehash操作:
static void rehash (lua_State *L, Table *t, const TValue *ek) { unsigned int asize; /* 最终数组的大小(一定为2的次幂)。 */ unsigned int na; /* 最终归入数组部分的key的个数。 */ unsigned int nums[MAXABITS + 1];//它的第i个位置存储的是key在2^(i-1)~2^i区间内的数量。 int i; int totaluse;//总共的key个数。 for (i = 0; i <= MAXABITS; i++) nums[i] = 0; /* reset counts */ na = numusearray(t, nums); //遍历当前的array部分,按其中key的分布来更新nums数组。同时返回na。 totaluse = na; /* 将totaluse加上na。 */ totaluse += numusehash(t, nums, &na); /* 遍历当前的hash表部分,如果其中的key为整数,na++并且更新nums数组,对于每个遍历的元素,totaluse++ */ na += countint(ek, nums);/* - countint:将newkey传进去,如果是整型的,那么na++。 - */ totaluse++; asize = computesizes(nums, &na);//计算optimal的array部分大小。这个函数根据整型key在2^(i-1)~2^i之间的填充率,来决定最终的array大小。一旦遇到某个子区间的填充率小于1/2,那么后续的整型key都存储到hash表中去,这一步是为了防止数组过于稀疏而浪费内存。函数将返回asize以及na luaH_resize(L, t, asize, totaluse - na);//根据上一步计算出的最终数组和哈希表大小,进行resize操作。当然,如果hash表的尺寸有变化,会对原来哈希表中的元素进行真正的rehash。 } -
迭代操作
//在使用测主要是ipairs和pairs两个函数。这两个函数都会在vm内部临时创建出两个变量state和index,用于对lua表进行迭代访问,每次访问的时候,会调用luaH_next函数 //该函数首先会根据findindex函数,找出迭代器对应lua表的哪个部分,是数组部分还是hash表部分。如果是数组部分,index会小于sizearray,否则会大于sizearray。注意该函数中的两个循环,只会进一个,取决于搜寻出来的key的index是否小于sizearray。 int luaH_next (lua_State *L, Table *t, StkId key) { unsigned int i = findindex(L, t, key); /* find original element */ for (; i < t->sizearray; i++) { /* try first array part */ if (!ttisnil(&t->array[i])) { /* a non-nil value? */ setivalue(key, i + 1); setobj2s(L, key+1, &t->array[i]); return 1; } } for (i -= t->sizearray; cast_int(i) < sizenode(t); i++) { /* hash part */ if (!ttisnil(gval(gnode(t, i)))) { /* a non-nil value? */ setobj2s(L, key, gkey(gnode(t, i))); setobj2s(L, key+1, gval(gnode(t, i))); return 1; } } return 0; /* no more elements */ }
-
-
-
-
-
函数闭包
首先,所有的lua函数,都是一个函数闭包。函数闭包是目前主流语言几乎都支持的一个机制,它指的是一个内部结构,该结构存储了函数本身以及一个在词法上包围该函数的环境,该环境包含了函数外围作用域的局部变量,通常这些局部变量又称作upvalue。
#define ClosureHeader \ CommonHeader; lu_byte nupvalues; GCObject *gclist typedef struct CClosure { ClosureHeader; lua_CFunction f; TValue upvalue[1]; /* list of upvalues */ } CClosure; typedef struct LClosure { ClosureHeader;//ClosureHeader:跟GC相关的结构,因为函数与是参与GC的。 struct Proto *p;//因为Closure=函数+upvalue嘛,所以p封装的就是纯粹的函数原型。该结构中封装了函数的很多基本特性,如局部变量、字节码序列、函数嵌套、常量表等。 UpVal *upvals[1]; /* upvals:函数的upvalue指针列表,记录了该函数引用的所有upvals。正是由于该字段的存在,导致函数对upvalue的访问要快于从全局表_G中向下查找。函数对upvalue的访问,一般就2个步骤:(1)从closure的upvals数组中按索引号取出upvalue。(2)将upvalue加到luastate的stack中 */ } LClosure; typedef union Closure { CClosure c; LClosure l; } Closure; -
其他参见虚拟机的proto部分
-
-
-
-
-
基本原理
-
和C#、Java类似,lua采用了Mark&Sweep的算法来进行垃圾回收,与之相对的还有个常用算法是Automatic Reference Counting(ARC)。Mark&Sweep的优点在于不用像ARC在每次赋值操作去操作引用计数(对于动态语言效率有较大影响),也不会有环形引用的问题,但是由于Mark&Sweep在触发时,需要从root节点全量遍历被引用到的节点,通常是比较耗时的操作。
在lua5.1之前,lua采用了双色的mark&sweep,它的大致流程如下:
- mark阶段
- 从根节点出发,先将root置黑
- 将root节点直接引用的节点置黑
- 递归将黑色节点引用到的节点置黑,直到不再有新增的黑色节点
- sweep阶段:
- 仍为白色的节点视为没有引用,从而将作为垃圾进行回收
该算法是一个不可中断的同步过程,非常容易造成CPU突刺。针对这个问题,lua从5.1以后便引入了增量GC的实现,将这样一整个同步的回收cycle,均摊到很多个可以增量执行的分步上,从而达到降低CPU突刺的目的。
- mark阶段
-
-
增量Collector与Program的关系
增量Collector与程序是交叉运行的,GC执行完一个step,就会把控制权交还给上层lua程序继续执行,上层执行一段时间又会触发下一个GC的step。基于这个运行时间线,Collector需要考虑的问题是:
1、如何将一整个Mark&Sweep的cycle切分成逻辑上的子步骤。
2、如何为每一个GC Step分配合理的工作量,使得一方面GC的频率可以满足应用程序对内存的需求,另一方面还要让每一个GC子步骤不至于造成应用程序的CPU突刺。3、如何解决在两个GC Step间,Mutator会改变GC状态的问题
-
GC状态机
-
针对问题(1),lua的做法是,使用了一个线性的状态机,将一整个Mark&Sweep的cycle拆分成若干子状态,每个子状态下去执行对应的action:
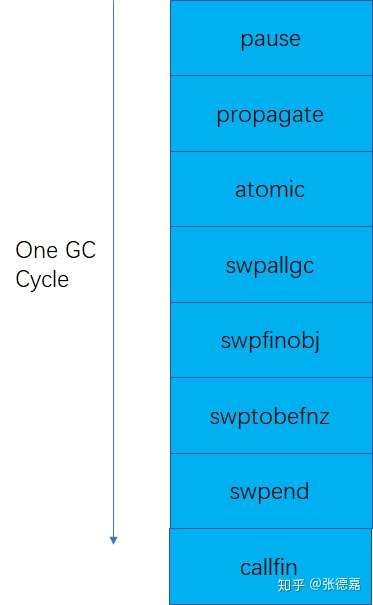
比如pause状态负责mark roots;propagate状态负责进行mark状态的传播,最终mark出所有reachable的节点;几个swp***状态负责清理unreachable节点的内存;callfin负责调用对象的finalizer。但是有的状态也是不可拆分的,具体情况具体分析。
-
GC Step工作量评估
-
如果只是以3.1模型中的以单个子状态为一个GC Step进行增量GC,实际上效果并不理想。这是因为:
- 就算每个状态的工作量是相等的,那每个状态的执行时间也只是整个cycle的1/8,而一般整个cycle的时间,拿手游项目为例,通常为几十ms几百ms不等,均摊到每个状态的耗时,也仍然有几ms几十ms,仍然会造成明显的CPU突刺。
- 更坏的情况是,各个子状态的耗时通常是非常不均等的,像propagate这种状态,要去全量递归的寻找reachable的节点,往往是一个耗时的大头,这样会导致在这个状态的耗时会非常突出。
基于以上两个考虑,可以得到的结论是,不能仅仅以GC的子状态为增量的最小单元。
lua为了解决这个问题,引入了一个“打工还债”的模型:把内存申请(如newstring,newtable等)量化成增加债务,当欠债达到一定规模时,程序运行会从Program态转变为Collector态,Collector会去打工还债,打工的内容就是上图中各个子状态下的action。为了进一步细化增量的最小单位,lua进一步对打工的工作量进行了评估,比如在propagate状态下,工作量就是traverse对象的内存量。有了这个债务与工作量的量化指标,那lua就可以把增量的单位进一步细化到工作量上
-
三色Mark&Sweep算法
-
对于问题(3)-如何解决在两个Step之间,Mutator会改变GC状态的问题。lua采用了下图的3色Mark&Sweep模型来解决:
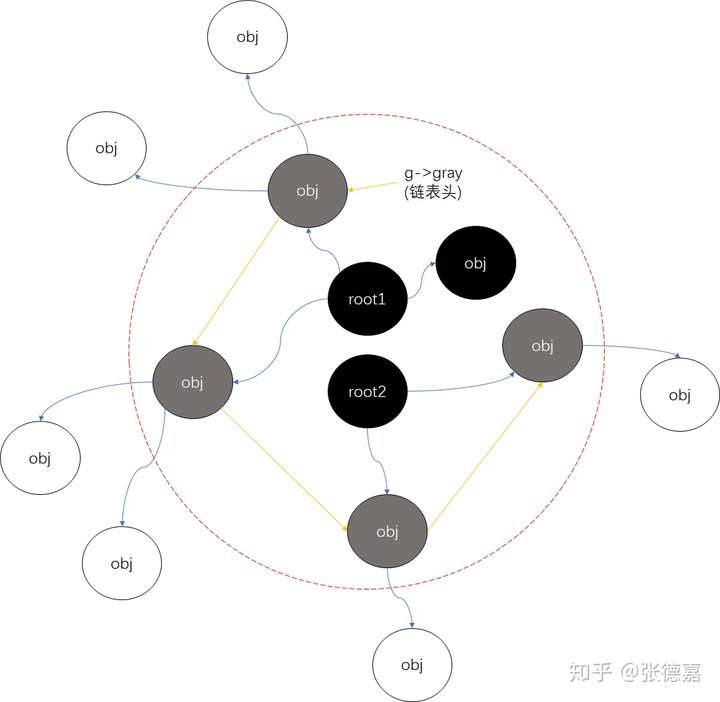
该算法的主要步骤还是mark和sweep两个大阶段。mark负责标记当前正在被程序使用的obj,sweep阶段负责释放没有被程序使用的obj。
相对于lua5.1之前的GC模型,该模型的主要特点是:
1.把GC的obj划分成3个颜色。- 黑色节点:已经完全扫描过的obj。
- 灰色节点:在扫描黑色节点时候初步扫描到,但是还未完全扫描的obj,这类obj会被放到一个待处理列表中进行逐个完全扫描。
- 白色节点:还未被任何黑色节点所引用的obj(因为一旦被黑色节点引用将被置为黑色或灰色)。这里白色又被进一步细分为cur white和old white,lua会记录当前的cur white颜色,每个obj新创建的时候都是cur white,lua会在mark阶段结束的时候翻转这个cur white的位,从而使得这之前创建的白色obj都是old的,在sweep阶段能够得到正确释放。
2.引用屏障。
在mark阶段,黑色节点只能指向黑色或灰色节点,不能指向白色节点;灰色节点可以指向灰色节点或白色节点。换句话说,灰色节点充当了黑、白节点间的屏障作用(图中的红色虚线)。这一屏障功能是合理的,想象一下,如果黑色节点跨越屏障引用到了白色节点,说明该白色节点实际上是被引用状态,不应该被GC释放。但是由于黑色节点已经遍历过,不会再重新遍历,会导致Collector在后面sweep阶段看到该obj为白色而将其错误的释放。
为了保证这一屏障功能,lua内部实现了barrier机制。
-
-
-
-
参考资料
-
[Lua程序设计(第4版)]("https://item.jd.com/12384305.html ")

