计算机网络知识树整理
计算机网络知识树整理
-
OSI模型(开放式系统互联通信参考模型)
-
OSI将计算机网络体系结构(architecture)划分为以下七层:
物理层: 将数据转换为可通过物理介质传送的电子信号 相当于邮局中的搬运工人。
数据链路层: 决定访问网络介质的方式。
在此层将数据分帧,并处理流控制。本层指定拓扑结构并提供硬件寻址,相当于邮局中的装拆箱工人。
网络层: 使用权数据路由经过大型网络 相当于邮局中的排序工人。
传输层: 提供终端到终端的可靠连接 相当于公司中跑邮局的送信职员。
会话层: 允许用户使用简单易记的名称建立连接 相当于公司中收寄信、写信封与拆信封的秘书。
表示层: 协商数据交换格式 相当公司中简报老板、替老板写信的助理。
应用层: 用户的应用程序和网络之间的接口。
-
-
计算机网络的模型
-
应用层
应用软件控制(协议,https、ftp、ssh)
-
传输层
-
TCP
-
面向连接的、可靠的传输协议
-
TCP 提供可靠交付,通过 TCP 连接传输的数据,无差错、不丢失、不重复、并且按序到达
-
TCP 是面向字节流的。发送的时候发的是一个流,没头没尾
-
TCP 是可以有拥塞控制的。它意识到包丢弃了或者网络的环境不好了,就会根据情况调整自己的行为,看看是不是发快了,要不要发慢点
-
TCP 其实是一个有状态服务,通俗地讲就是有脑子的,里面精确地记着发送了没有,接收到没有,发送到哪个了,应该接收哪个了,错一点儿都不行
-
三次握手
-
C—— syn(建立连接)——> S (C:您好,我是 C。)
-
C<——syn(建立连接) + ack(收到了)—— S(S:您好 C,我是 S。)
-
C——ack(收到了)——>S (A:您好 B。)
-
我们也常称为“请求 -> 应答 -> 应答之应答”的三个回合。当三次握手之后才算建立连接
-
首先,为什么要三次,而不是两次?按说两个人打招呼,一来一回就可以了啊?为了可靠,为什么不是四次?
- 由于丢包的情况存在,如果没有丢包的情况下,两次握手其实是最理想的情况,但是因为有了丢包,A 和 B 原来建立了连接,做了简单通信后,结束了连接。但是当A 建立连接的时候,请求包重复发了几次,有的请求包绕了一大圈又回来了,B 会认为这也是一个正常的的请求的话,再次建立了连接,可以想象,这个连接不会进行下去,也没有个终结的时候,因而两次握手肯定不行。
- 所以为了避免这种情况,B 发送的应答可能会发送多次,但是只要一次到达 A,A 就认为连接已经建立了,因为对于 A 来讲,他的消息有去有回。A 会给 B 发送应答之应答,而 B 也在等这个消息,才能确认连接的建立,只有等到了这个消息,对于 B 来讲,才算它的消息有去有回。
- 当然 A 发给 B 的应答之应答也会丢,也会绕路,甚至 B 挂了。按理来说,还应该有个应答之应答之应答,这样下去就没底了。所以四次握手是可以的,四十次都可以,关键四百次也不能保证就真的可靠了。只要双方的消息都有去有回,就基本可以了。
-
三次握手除了双方建立连接外,主要还是为了沟通一件事情,就是 TCP 包的序号的问题。
-
A 要告诉 B,我这面发起的包的序号起始是从哪个号开始的,B 同样也要告诉 A,B 发起的包的序号起始是从哪个号开始的。为什么序号不能都从 1 开始呢?因为这样往往会出现冲突。例如,A 连上 B 之后,发送了 1、2、3 三个包,但是发送 3 的时候,中间丢了,或者绕路了,于是重新发送,后来 A 掉线了,重新连上 B 后,序号又从 1 开始,然后发送 2,但是压根没想发送 3,但是上次绕路的那个 3 又回来了,发给了 B,B 自然认为,这就是下一个包,于是发生了错误。
-
因而,每个连接都要有不同的序号。这个序号的起始序号是随着时间变化的,可以看成一个 32 位的计数器,每 4 微秒加一,如果计算一下,如果到重复,需要 4 个多小时,那个绕路的包早就死翘翘了,因为我们都知道 IP 包头里面有个 TTL,也即生存时间。
-
-
当建立了连接长时间没有发送数据,突然要发送的时候他是有效的吗?不一定,所以有了心跳
-
三次握手的时序变化图
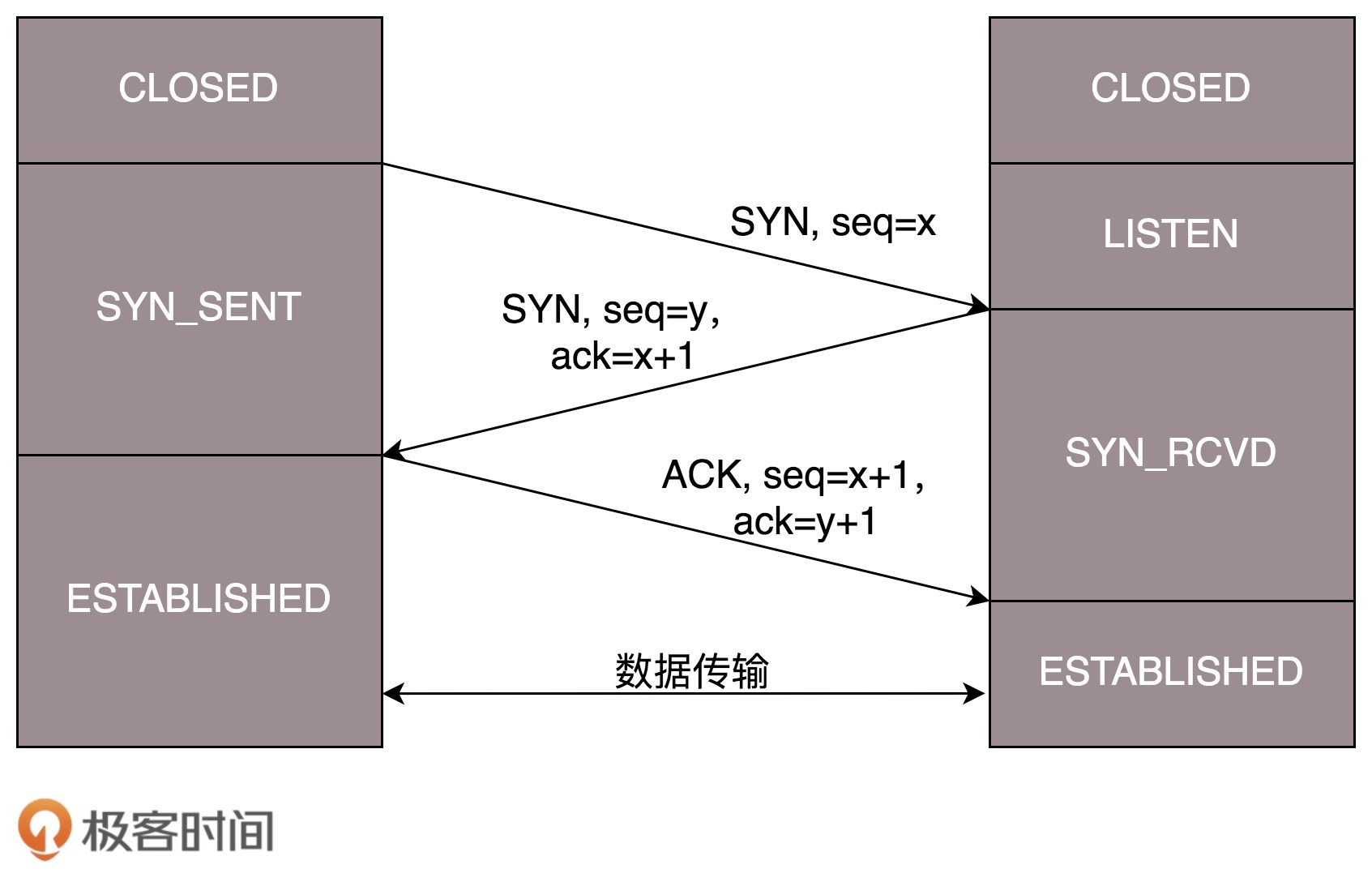
-
-
开始发送数据
-
四次分手
-
C——fin(断开连接)——>S(C:S 啊,我不想玩了。)
-
C<——fin(断开连接)+ ack(收到了)——S(S:哦,你不想玩了啊,我知道了。)
这个时候,还只是 C单方面的不想玩了,也即 C 不会再发送数据,但是 S 能不能在 ACK 的时候,直接关闭呢?当然不可以了,很有可能 C 是发完了最后的数据就准备不玩了,但是 S 还没做完自己的事情,还是可以发送数据的,所以称为半关闭的状态。这个时候 C 可以选择不再接收数据了,也可以选择最后再接收一段数据,等待 S 也主动关闭。
-
C<——fin(断开连接)——S (S:C 啊,好吧,我也不玩了,拜拜。)
-
C——ack(收到了)——>S(C:好的,拜拜。)
-
这样整个连接就关闭了。但是这个过程有没有异常情况呢?当然有,上面也是基于是和平分手(网络状况良好)的场面。
-
A 开始说“不玩了”,B 说“知道了”,这个回合,是没什么问题的,因为在此之前,双方还处于合作的状态,如果 A 说“不玩了”,没有收到回复,则 A 会重新发送“不玩了”。但是这个回合结束之后,就有可能出现异常情况了,因为已经有一方率先撕破脸。
-
一种情况是,A 说完“不玩了”之后,直接跑路,是会有问题的,因为 B 还没有发起结束,而如果 A 跑路,B 就算发起结束,也得不到回答,B 就不知道该怎么办了。
-
另一种情况是,A 说完“不玩了”,B 直接跑路,也是有问题的,因为 A 不知道 B 是还有事情要处理,还是过一会儿会发送结束。那怎么解决这些问题呢?TCP 协议专门设计了几个状态来处理这些问题。我们来看断开连接的时候的状态时序图。
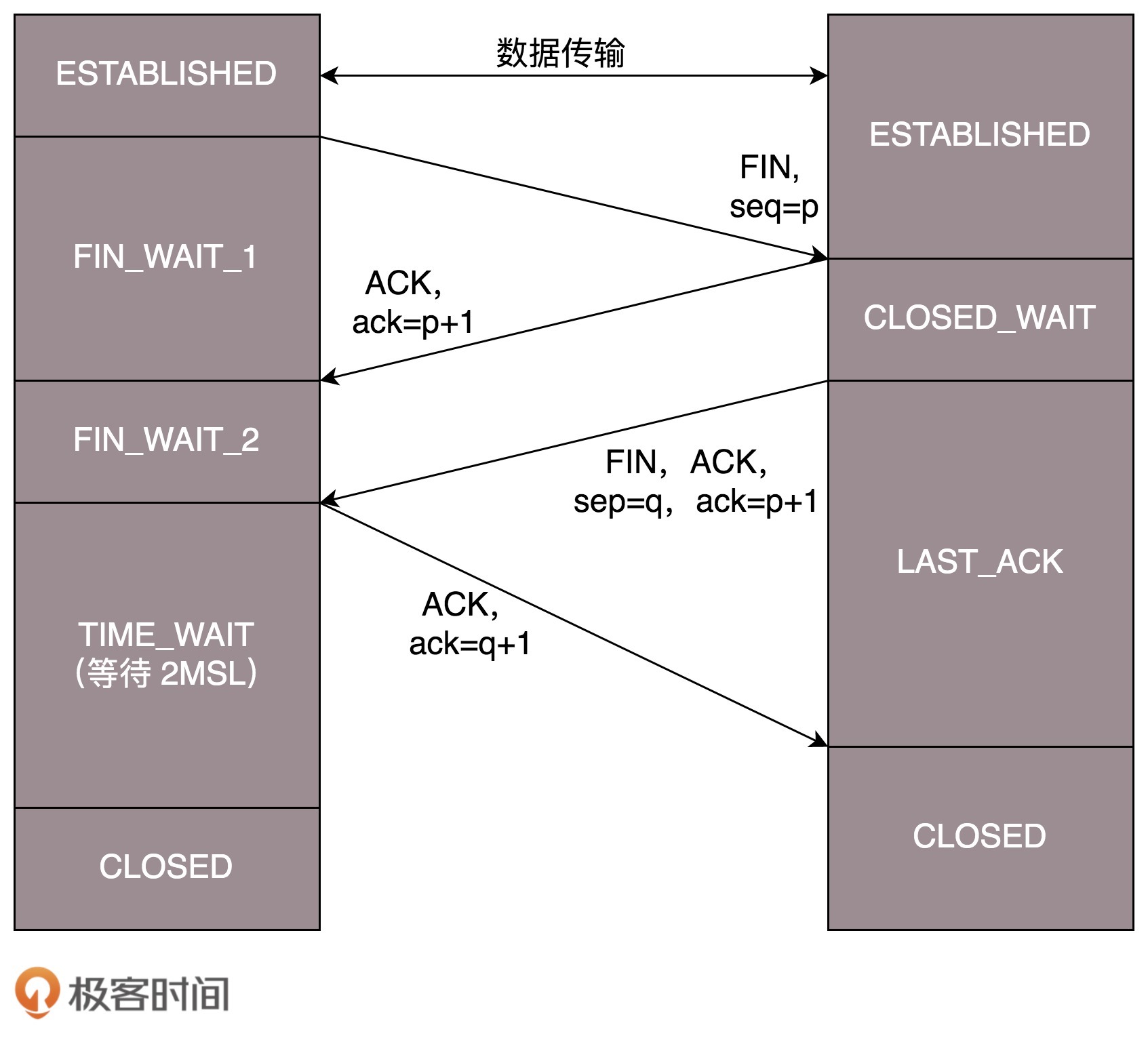
-
断开的时候,我们可以看到,当 A 说“不玩了”,就进入 FIN_WAIT_1 的状态,B 收到“A 不玩”的消息后,发送知道了,就进入 CLOSE_WAIT 的状态。
-
A 收到“B 说知道了”,就进入 FIN_WAIT_2 的状态,如果这个时候 B 直接跑路,则 A 将永远在这个状态。TCP 协议里面并没有对这个状态的处理,但是 Linux 有,可以调整 tcp_fin_timeout 这个参数,设置一个超时时间。
-
如果 B 没有跑路,发送了“B 也不玩了”的请求到达 A 时,A 发送“知道 B 也不玩了”的 ACK 后,从 FIN_WAIT_2 状态结束,按说 A 可以跑路了,但是最后的这个 ACK 万一 B 收不到呢?则 B 会重新发一个“B 不玩了”,这个时候 A 已经跑路了的话,B 就再也收不到 ACK 了,因而 TCP 协议要求 A 最后等待一段时间 TIME_WAIT,这个时间要足够长,长到如果 B 没收到 ACK 的话,“B 说不玩了”会重发的,A 会重新发一个 ACK 并且足够时间到达 B。
-
A 直接跑路还有一个问题是,A 的端口就直接空出来了,但是 B 不知道,B 原来发过的很多包很可能还在路上,如果 A 的端口被一个新的应用占用了,这个新的应用会收到上个连接中 B 发过来的包,虽然序列号是重新生成的,但是这里要上一个双保险,防止产生混乱,因而也需要等足够长的时间,等到原来 B 发送的所有的包都死翘翘,再空出端口来。等待的时间设为 2MSL,MSL 是 Maximum Segment Lifetime,报文最大生存时间,它是任何报文在网络上存在的最长时间,超过这个时间报文将被丢弃。
-
-
TCP 状态机
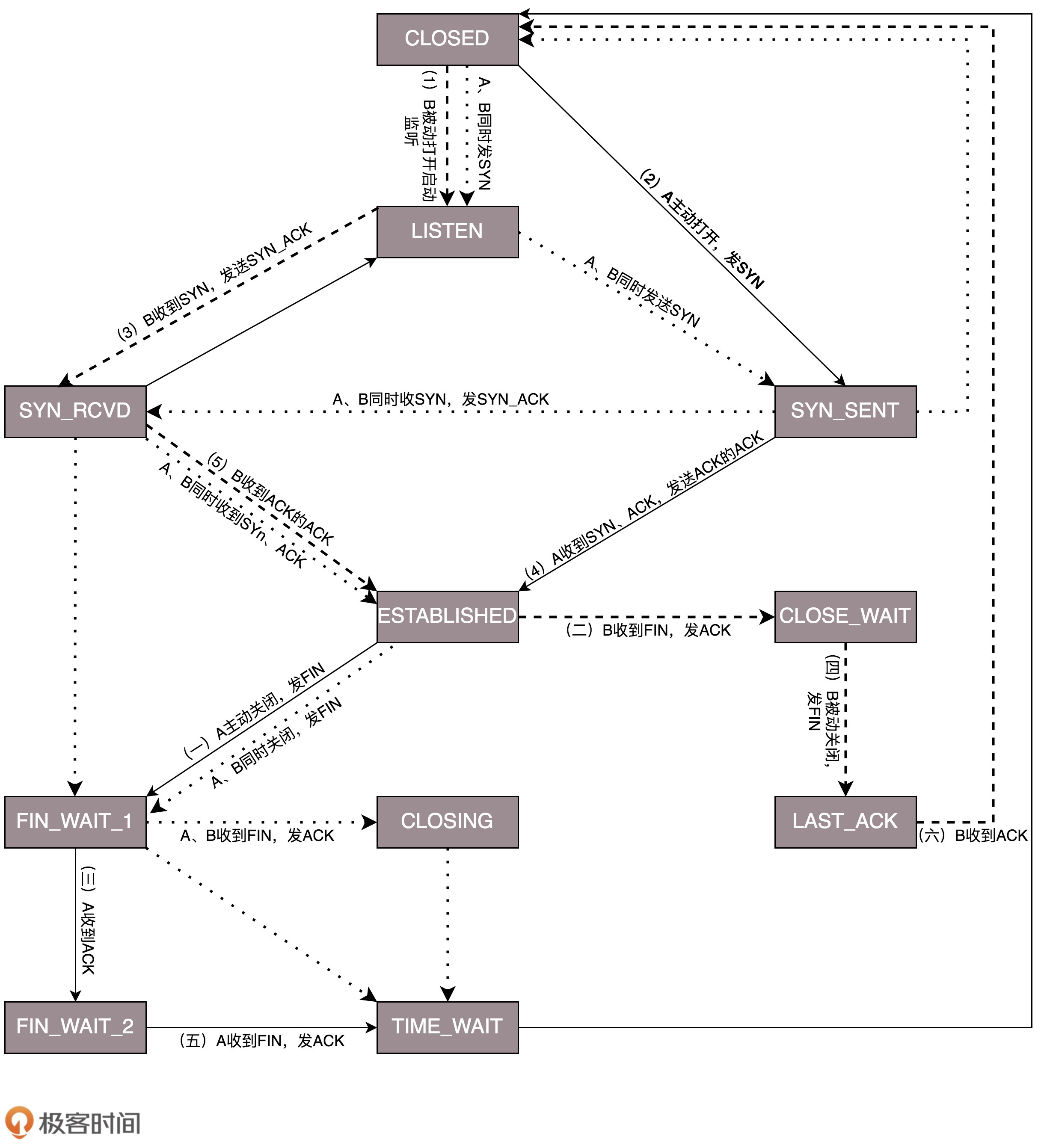
将连接建立和连接断开的两个时序状态图综合起来,就是这个著名的 TCP 的状态机。学习的时候比较建议将这个状态机和时序状态机对照着看,在这个图中,加黑加粗的部分,是上面说到的主要流程,其中阿拉伯数字的序号,是连接过程中的顺序,而大写中文数字的序号,是连接断开过程中的顺序。加粗的实线是客户端 A 的状态变迁,加粗的虚线是服务端 B 的状态变迁。
-
-
TCP 包头格式
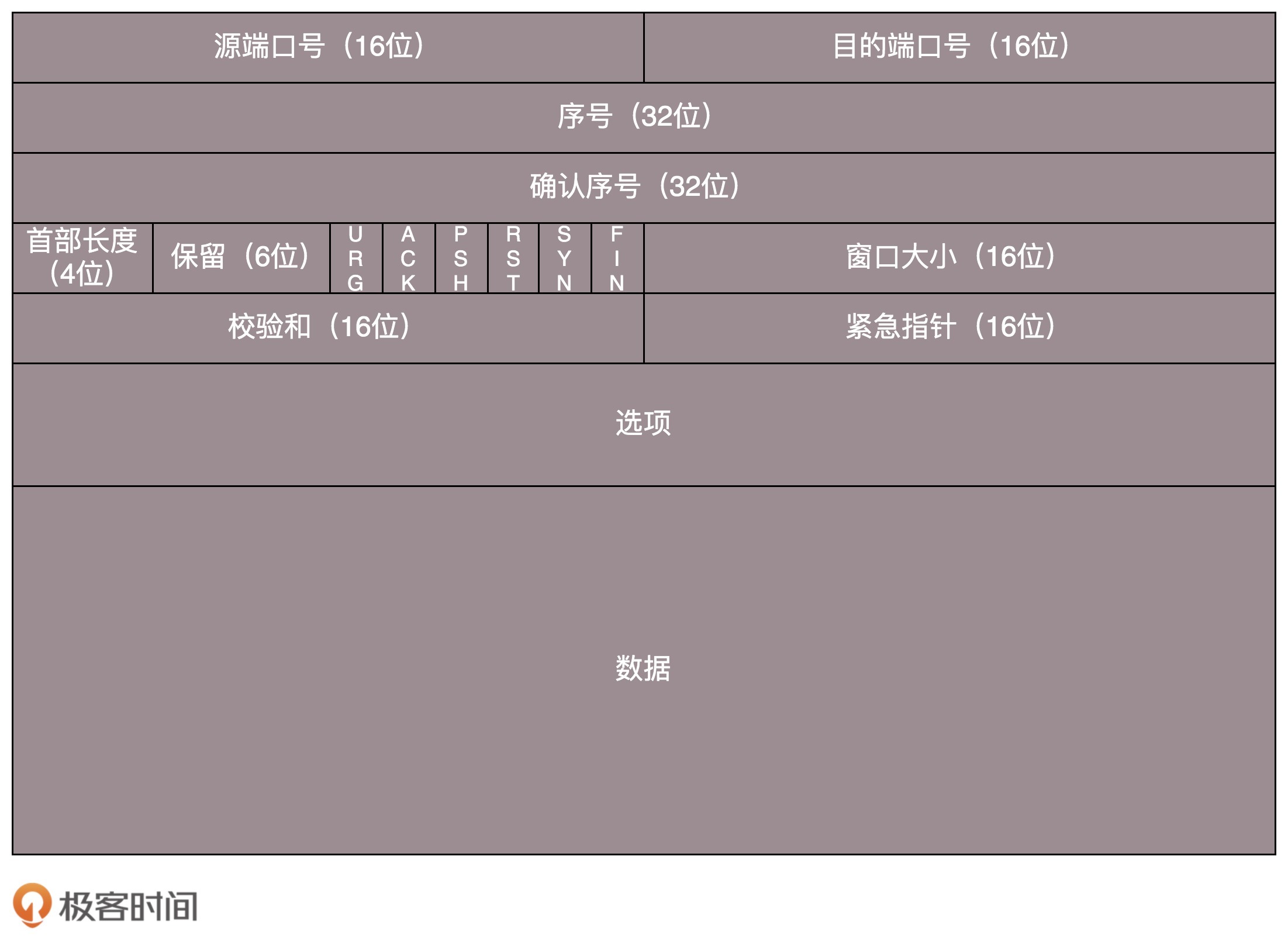
源端口号和目标端口号是不可少的,这一点和 UDP 是一样的。如果没有这两个端口号。数据就不知道应该发给哪个应用。
接下来是包的序号。为什么要给包编号呢?当然是为了解决乱序的问题。不编好号怎么确认哪个应该先来,哪个应该后到呢。
还应该有的就是确认序号。发出去的包应该有确认,要不然我怎么知道对方有没有收到呢
-
TCP 包头很复杂,但是主要关注五个问题,顺序问题,丢包问题,连接维护,流量控制,拥塞控制;
-
顺序问题与丢包问题
-
为了保证顺序性,每一个包都有一个 ID。在建立连接的时候,会商定起始的 ID 是什么,然后按照 ID 一个个发送。为了保证不丢包,对于发送的包都要进行应答,但是这个应答也不是一个一个来的,而是会应答某个之前的 ID,表示都收到了,这种模式称为累计确认或者累计应答(cumulative acknowledgment)。
-
为了保证顺序性,每一个包都有一个 ID。在建立连接的时候,会商定起始的 ID 是什么,然后按照 ID 一个个发送。为了保证不丢包,对于发送的包都要进行应答,但是这个应答也不是一个一个来的,而是会应答某个之前的 ID,表示都收到了,这种模式称为累计确认或者累计应答(cumulative acknowledgment)。
-
为了记录所有发送的包和接收的包,TCP 也需要发送端和接收端分别都有缓存来保存这些记录。
-
发送端的缓存里是按照包的 ID 一个个排列,根据处理的情况分成四个部分。
-
第一部分:发送了并且已经确认的
-
第二部分:发送了并且尚未确认的
-
第三部分:没有发送,但是已经等待发送的
-
第四部分:没有发送,并且暂时还不会发送的
-
这里面为什么要区分第三部分和第四部分呢?这就是为了流量控制,把握分寸。到底一个接收端能够同时处理多少事情呢?在 TCP 里,接收端会给发送端报一个窗口的大小,叫 Advertised window。告诉发送端自己能做多少,这个窗口的大小应该等于上面的第二部分加上第三部分。超过这个窗口的,接收端做不过来,就不能发送了。
-
于是,发送端需要保持下面的数据结构。

- LastByteAcked:第一部分和第二部分的分界线
- LastByteSent:第二部分和第三部分的分界线
- LastByteAcked + AdvertisedWindow:第三部分和第四部分的分界线
-
对于接收端来讲,它的缓存里记录的内容要简单一些。
-
第一部分:接受并且确认过的。
-
第二部分:还没接收,但是马上就能接收的。也即是自己能够接受的最大工作量。
-
第三部分:还没接收,也没法接收的。也即超过工作量的部分,实在做不完。
-
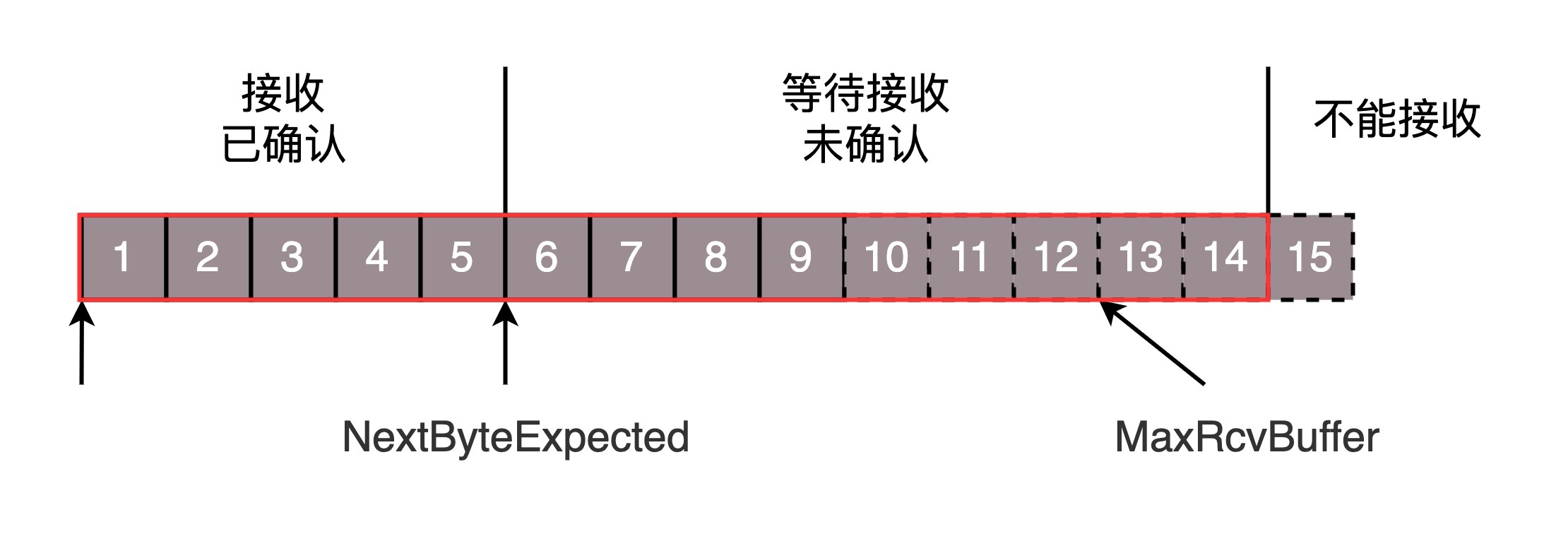
对应的数据结构就像这样
-
MaxRcvBuffer:最大缓存的量;
-
LastByteRead 之后是已经接收了,但是还没被应用层读取的;
-
NextByteExpected 是第一部分和第二部分的分界线。
-
第二部分的窗口有多大呢?
- NextByteExpected 和 LastByteRead 的差其实是还没被应用层读取的部分占用掉的 MaxRcvBuffer 的量,我们定义为 A。
- AdvertisedWindow 其实是 MaxRcvBuffer 减去 A。
- 也就是:AdvertisedWindow=MaxRcvBuffer-((NextByteExpected-1)-LastByteRead)。
-
那第二部分和第三部分的分界线在哪里呢?NextByteExpected 加 AdvertisedWindow 就是第二部分和第三部分的分界线,其实也就是 LastByteRead 加上 MaxRcvBuffer。
-
-
其中第二部分里面,由于受到的包可能不是顺序的,会出现空档,只有和第一部分连续的,可以马上进行回复,中间空着的部分需要等待,哪怕后面的已经来了。
-
-
-
-
确认与重发的机制。
- 超时重试,超时时间评估通过自适应重传算法,超时间隔加倍。每当遇到一次超时重传的时候,都会将下一次超时时间间隔设为先前值的两倍。两次超时,就说明网络环境差,不宜频繁反复发送
-
-
-
还有一种方式称为 Selective Acknowledgment (SACK)。这种方式需要在 TCP 头里加一个 SACK 的东西,可以将缓存的地图发送给发送方。例如可以发送 ACK6、SACK8、SACK9,有了地图,发送方一下子就能看出来是 7 丢了。
-
-
流量控制问题
-
在对于包的确认中,同时会携带一个窗口的大小。发送方会定时发送窗口探测数据包,看是否有机会调整窗口的大小。当接收方比较慢的时候,要防止低能窗口综合征,别空出一个字节来就赶快告诉发送方,然后马上又填满了,可以当窗口太小的时候,不更新窗口,直到达到一定大小,或者缓冲区一半为空,才更新窗口。
-
拥塞控制
-
拥塞控制的问题,也是通过窗口的大小来控制的,前面的滑动窗口 rwnd 是怕发送方把接收方缓存塞满,而拥塞窗口 cwnd,是怕把网络塞满。这里有一个公式 LastByteSent - LastByteAcked <= min {cwnd, rwnd} ,是拥塞窗口和滑动窗口共同控制发送的速度。
-
TCP 的拥塞控制主要来避免两种现象,包丢失和超时重传
-
慢启动。一条 TCP 连接开始,cwnd 设置为一个报文段,一次只能发送一个;当收到这一个确认的时候,cwnd 加一,于是一次能够发送两个;当这两个的确认到来的时候,每个确认 cwnd 加一,两个确认 cwnd 加二,于是一次能够发送四个;当这四个的确认到来的时候,每个确认 cwnd 加一,四个确认 cwnd 加四,于是一次能够发送八个。可以看出这是指数性的增长。
-
涨到什么时候是个头呢?有一个值 ssthresh 为 65535 个字节,当超过这个值的时候,就要小心一点了,不能倒这么快了,可能快满了,再慢下来。
- 每收到一个确认后,cwnd 增加 1/cwnd,我们接着上面的过程来,一次发送八个,当八个确认到来的时候,每个确认增加 1/8,八个确认一共 cwnd 增加 1,于是一次能够发送九个,变成了线性增长。
-
拥塞的一种表现形式是丢包,需要超时重传,这个时候,将 sshresh 设为 cwnd/2,将 cwnd 设为 1,重新开始慢启动。这真是一旦超时重传,马上回到解放前。但是这种方式太激进了,将一个高速的传输速度一下子停了下来,会造成网络卡顿。
-
前面我们讲过快速重传算法。当接收端发现丢了一个中间包的时候,发送三次前一个包的 ACK,于是发送端就会快速地重传,不必等待超时再重传。TCP 认为这种情况不严重,因为大部分没丢,只丢了一小部分,cwnd 减半为 cwnd/2,然后 sshthresh = cwnd,当三个包返回的时候,cwnd = sshthresh + 3,也就是没有一夜回到解放前,而是还在比较高的值,呈线性增长。
-
TCP 的拥塞控制主要来避免的两个现象都是有问题的。
-
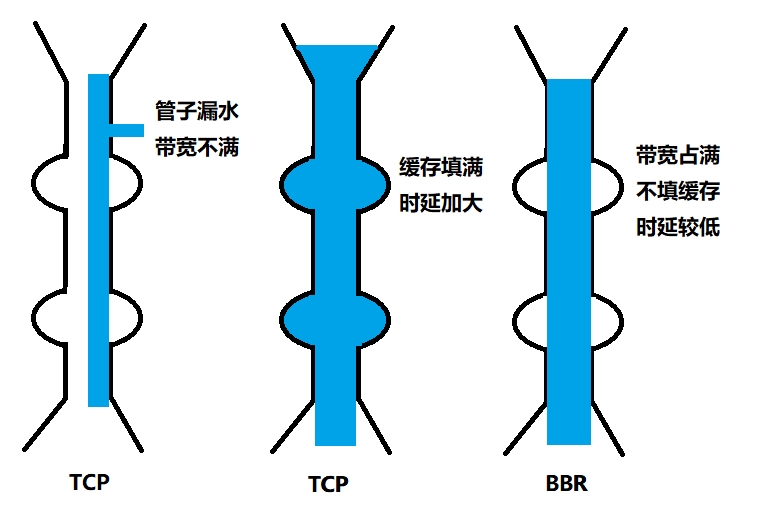
第一个问题是丢包并不代表着通道满了,也可能是管子本来就漏水。例如公网上带宽不满也会丢包,这个时候就认为拥塞了,退缩了,其实是不对的。
-
第二个问题是 TCP 的拥塞控制要等到将中间设备都填充满了,才发生丢包,从而降低速度,这时候已经晚了。其实 TCP 只要填满管道就可以了,不应该接着填,直到连缓存也填满。
-
为了优化这两个问题,后来有了 TCP BBR 拥塞算法。它企图找到一个平衡点,就是通过不断地加快发送速度,将管道填满,但是不要填满中间设备的缓存,因为这样时延会增加,在这个平衡点可以很好的达到高带宽和低时延的平衡。
-
-
总结
- 顺序问题、丢包问题、流量控制都是通过滑动窗口来解决的,这其实就相当于你领导和你的工作备忘录,布置过的工作要有编号,干完了有反馈,活不能派太多,也不能太少;
- 拥塞控制是通过拥塞窗口来解决的,相当于往管道里面倒水,快了容易溢出,慢了浪费带宽,要摸着石头过河,找到最优值
- 顺序问题、丢包问题、流量控制都是通过滑动窗口来解决的,这其实就相当于你领导和你的工作备忘录,布置过的工作要有编号,干完了有反馈,活不能派太多,也不能太少;
-
-
-
UDP
-
UDP 是面向无连接的无状态服务。(通俗地说是没脑子的,发出去就发出去了,谁TM管你收不收得到)
-
UDP 继承了 IP 的特性,基于数据报的,一个一个地发,一个一个地收。
-
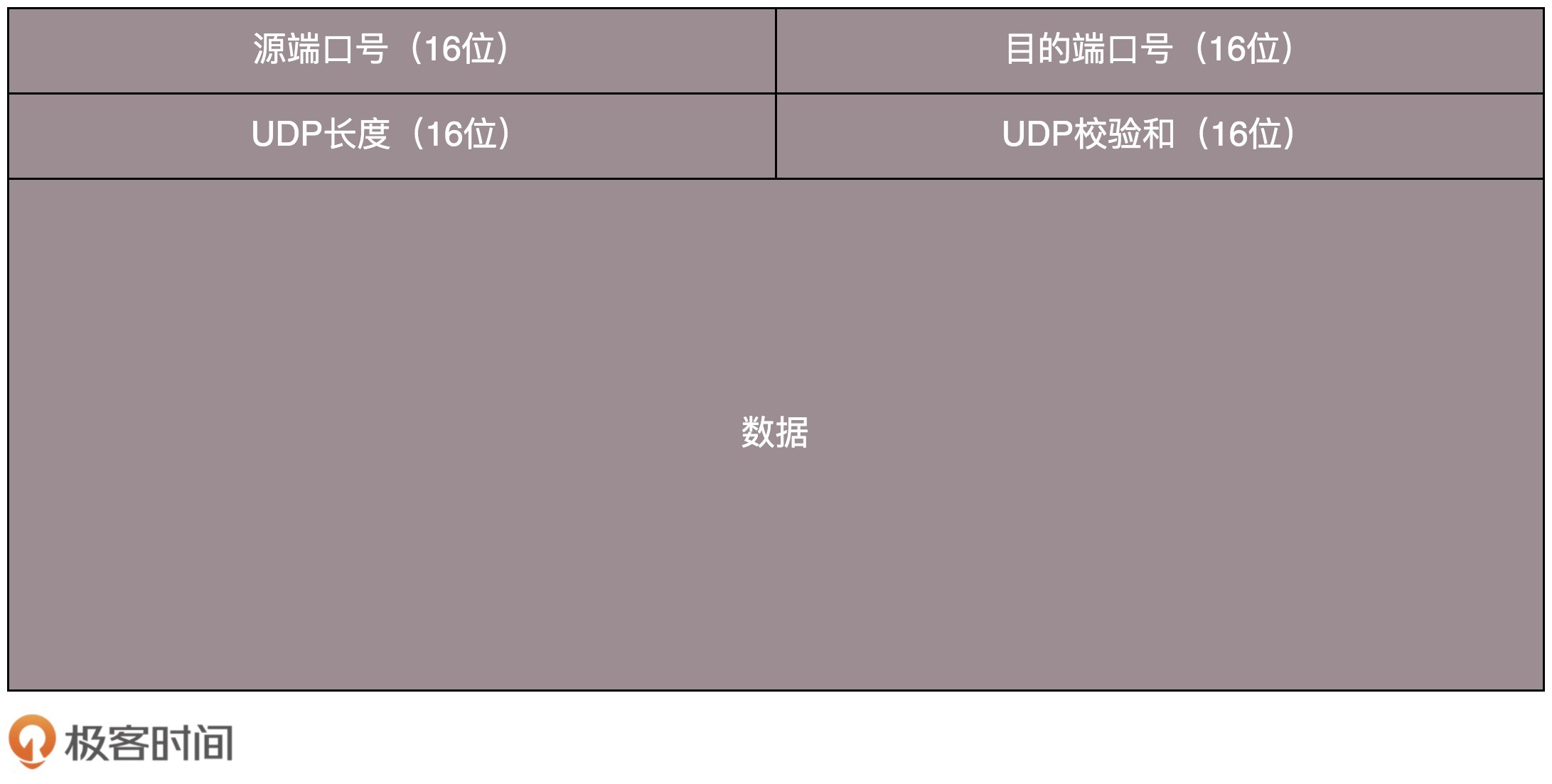
UDP 包头是什么样的?
-
UDP 的三大特点
- 沟通简单:不需要大量的数据结构、处理逻辑、包头字段
- 轻信他人:它不会建立连接,虽然有端口号,但是监听在这个地方,谁都可以传给他数据,他也可以传给任何人数据,甚至可以同时传给多个人数据。
- 不会根据网络的情况进行发包的拥塞控制,无论网络丢包丢成啥样了,它该怎么发还怎么发。
-
UDP 的三大使用场景
- 需要资源少,在网络情况比较好的内网,或者对于丢包不敏感的应用。
- 不需要一对一沟通,建立连接,而是可以广播的应用。
- 需要处理速度快,时延低,可以容忍少数丢包,但是要求即便网络拥塞,也毫不退缩,一往无前的时候
-
基于 UDP 实现的五个例子
-
网页或者 APP 的访问
原来访问网页和手机 APP 都是基于 HTTP 协议的。HTTP 协议是基于 TCP 的,建立连接都需要多次交互,对于时延比较大的目前主流的移动互联网来讲,建立一次连接需要的时间会比较长,然而既然是移动中,TCP 可能还会断了重连,也是很耗时的。而且目前的 HTTP 协议,往往采取多个数据通道共享一个连接的情况,这样本来为了加快传输速度,但是 TCP 的严格顺序策略使得哪怕共享通道,前一个不来,后一个和前一个即便没关系,也要等着,时延也会加大。
而 QUIC(全称 Quick UDP Internet Connections,快速 UDP 互联网连接)是 Google 提出的一种基于 UDP 改进的通信协议,其目的是降低网络通信的延迟,提供更好的用户互动体验。QUIC 在应用层上,会自己实现快速连接建立、减少重传时延,自适应拥塞控制。
-
流媒体的协议
TCP 的严格顺序传输要保证前一个收到了,下一个才能确认,如果前一个收不到,下一个就算包已经收到了,在缓存里面,也需要等着。对于直播来讲,这显然是不合适的,因为老的视频帧丢了其实也就丢了,就算再传过来用户也不在意了,他们要看新的了,如果老是没来就等着,卡顿了,新的也看不了,那就会丢失客户,所以直播,实时性比较比较重要,宁可丢包,也不要卡顿的。TCP 协议会主动降低发送速度,这对本来当时就卡的看视频来讲是要命的,应该应用层马上重传,而不是主动让步。因而,很多直播应用,都基于 UDP 实现了自己的视频传输协议。
-
实时游戏
实时游戏中客户端和服务端要建立长连接,来保证实时传输。但是游戏玩家很多,服务器却不多。由于维护 TCP 连接需要在内核维护一些数据结构,因而一台机器能够支撑的 TCP 连接数目是有限的,然后 UDP 由于是没有连接的,在异步 IO 机制引入之前,常常是应对海量客户端连接的策略。
游戏对实时要求较为严格的情况下,采用自定义的可靠 UDP 协议,自定义重传策略,能够把丢包产生的延迟降到最低,尽量减少网络问题对游戏性造成的影响。
-
IoT 物联网
一方面,物联网领域终端资源少,很可能只是个内存非常小的嵌入式系统,而维护 TCP 协议代价太大;另一方面,物联网对实时性要求也很高,而 TCP 还是因为上面的那些原因导致时延大。
-
移动通信领域
在 4G 网络里,移动流量上网的数据面对的协议 GTP-U 是基于 UDP 的。因为移动网络协议比较复杂,而 GTP 协议本身就包含复杂的手机上线下线的通信协议。如果基于 TCP,TCP 的机制就显得非常多余
-
-
如何建立一个可靠的UDP?
-
自定义连接机制
- 一条 TCP 连接是由四元组标识的,分别是源 IP、源端口、目的 IP、目的端口。一旦一个元素发生变化时,就需要断开重连,重新连接。在移动互联情况下,当手机信号不稳定或者在 WIFI 和 移动网络切换时,都会导致重连,从而进行再次的三次握手,导致一定的时延。
- 这在 TCP 是没有办法的,但是基于 UDP,就可以在 QUIC 自己的逻辑里面维护连接的机制,不再以四元组标识,而是以一个 64 位的随机数作为 ID 来标识,而且 UDP 是无连接的,所以当 IP 或者端口变化的时候,只要 ID 不变,就不需要重新建立连接。
-
自定义重传机制
- 前面我们讲过,TCP 为了保证可靠性,通过使用序号和应答机制,来解决顺序问题和丢包问题。
- 任何一个序号的包发过去,都要在一定的时间内得到应答,否则一旦超时,就会重发这个序号的包。那怎么样才算超时呢?还记得我们提过的自适应重传算法吗?这个超时是通过采样往返时间 RTT 不断调整的。
- 其实,在 TCP 里面超时的采样存在不准确的问题。例如,发送一个包,序号为 100,发现没有返回,于是再发送一个 100,过一阵返回一个 ACK101。这个时候客户端知道这个包肯定收到了,但是往返时间是多少呢?是 ACK 到达的时间减去后一个 100 发送的时间,还是减去前一个 100 发送的时间呢?事实是,第一种算法把时间算短了,第二种算法把时间算长了。
- QUIC 也有个序列号,是递增的。任何一个序列号的包只发送一次,下次就要加一了。例如,发送一个包,序号是 100,发现没有返回;再次发送的时候,序号就是 101 了;如果返回的 ACK 100,就是对第一个包的响应。如果返回 ACK 101 就是对第二个包的响应,RTT 计算相对准确。但是这里有一个问题,就是怎么知道包 100 和包 101 发送的是同样的内容呢?QUIC 定义了一个 offset 概念。QUIC 既然是面向连接的,也就像 TCP 一样,是一个数据流,发送的数据在这个数据流里面有个偏移量 offset,可以通过 offset 查看数据发送到了哪里,这样只要这个 offset 的包没有来,就要重发;如果来了,按照 offset 拼接,还是能够拼成一个流。
-
无阻塞的多路复用
- 有了自定义的连接和重传机制,我们就可以解决上面 HTTP 2.0 的多路复用问题。同 HTTP 2.0 一样,同一条 QUIC 连接上可以创建多个 stream,来发送多个 HTTP 请求。但是,QUIC 是基于 UDP 的,一个连接上的多个 stream 之间没有依赖。这样,假如 stream2 丢了一个 UDP 包,后面跟着 stream3 的一个 UDP 包,虽然 stream2 的那个包需要重传,但是 stream3 的包无需等待,就可以发给用户。
-
自定义流量控制
-
TCP 的流量控制是通过滑动窗口协议。QUIC 的流量控制也是通过 window_update,来告诉对端它可以接受的字节数。但是 QUIC 的窗口是适应自己的多路复用机制的,不但在一个连接上控制窗口,还在一个连接中的每个 stream 控制窗口。
-
还记得吗?在 TCP 协议中,接收端的窗口的起始点是下一个要接收并且 ACK 的包,即便后来的包都到了,放在缓存里面,窗口也不能右移,因为 TCP 的 ACK 机制是基于序列号的累计应答,一旦 ACK 了一个序列号,就说明前面的都到了,所以只要前面的没到,后面的到了也不能 ACK,就会导致后面的到了,也有可能超时重传,浪费带宽。
-
QUIC 的 ACK 是基于 offset 的,每个 offset 的包来了,进了缓存,就可以应答,应答后就不会重发,中间的空档会等待到来或者重发即可,而窗口的起始位置为当前收到的最大 offset,从这个 offset 到当前的 stream 所能容纳的最大缓存,是真正的窗口大小。显然,这样更加准确。
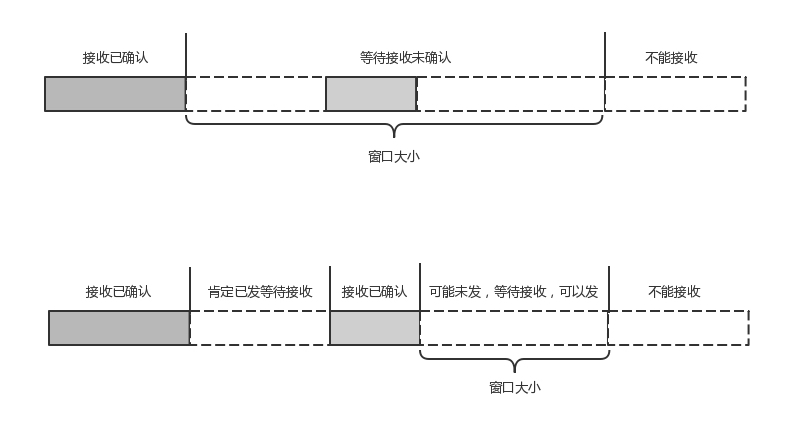
另外,还有整个连接的窗口,需要对于所有的 stream 的窗口做一个统计。
-
-
-
-
-
网络层(寻找下一条)
- IP to IP
- 数据包头:当前的网络地址为源IP、目标IP地址,送达消息的mac地址
- 一个局域网内不一定有目标的IP,所以当当前局域网内找不到目标ip时,就会有一个远端转发端口
- 这时候源ip是不知道远端端口的mac地址的,所以会局域网广播发一个自己ip到远端ip的包(带上了自己的mac)
- 当远端收到时会吧他的mac带上发回源目标ip的mac地址,当源ip收到时会在数据包写上路由的mac地址然后发出去
- 路由器收到后根据目标ip和当前路由表来计算是继续转发还是在当前连接的局域网内寻址,会将包头的mac地址换成新的mac地址
- 所以网络层的过程实际上就是寻找下一跳的过程,这个过程中源ip地址和目标地址都不变,mac地址会动态改变
- IP to IP
-
数据链路层
- MAC层,对于mac的处理,mac是每个机子一出场的时候默认绑定的
-
物理层
- 比对MAC和IP地址,看看是否是自身
-

