字符编码ASCII、Unicode 、UTF-8 及实例汉字与Unicode码的相互转化
ASCII 码
我们知道,计算机内部,所有信息最终都是一个二进制值。每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte)。也就是说,一个字节一共可以用来表示256种不同的状态,每一个状态对应一个符号,就是256个符号,从00000000到11111111。
上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。这被称为 ASCII 码,一直沿用至今。
ASCII 码一共规定了128个字符的编码,比如空格SPACE是32(二进制00100000),大写的字母A是65(二进制01000001)。这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的一位统一规定为0。
非 ASCII 编码
英语用128个符号编码就够了,但是用来表示其他语言,128个符号是不够的。比如,在法语中,字母上方有注音符号,它就无法用 ASCII 码表示。于是,一些欧洲国家就决定,利用字节中闲置的最高位编入新的符号。比如,法语中的é的编码为130(二进制10000010)。这样一来,这些欧洲国家使用的编码体系,可以表示最多256个符号。
但是,这里又出现了新的问题。不同的国家有不同的字母,因此,哪怕它们都使用256个符号的编码方式,代表的字母却不一样。比如,130在法语编码中代表了é,在希伯来语编码中却代表了字母Gimel (ג),在俄语编码中又会代表另一个符号。但是不管怎样,所有这些编码方式中,0--127表示的符号是一样的,不一样的只是128--255的这一段。
至于亚洲国家的文字,使用的符号就更多了,汉字就多达10万左右。一个字节只能表示256种符号,肯定是不够的,就必须使用多个字节表达一个符号。比如,简体中文常见的编码方式是 GB2312,使用两个字节表示一个汉字,所以理论上最多可以表示 256 x 256 = 65536 个符号。
Unicode
正如上一节所说,世界上存在着多种编码方式,同一个二进制数字可以被解释成不同的符号。因此,要想打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码。为什么电子邮件常常出现乱码?就是因为发信人和收信人使用的编码方式不一样。
可以想象,如果有一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会消失。这就是 Unicode,就像它的名字都表示的,这是一种所有符号的编码。
Unicode 当然是一个很大的集合,现在的规模可以容纳100多万个符号。每个符号的编码都不一样,比如,U+0639表示阿拉伯字母Ain,U+0041表示英语的大写字母A,U+4E25表示汉字严。具体的符号对应表,可以查询unicode.org,或者专门的汉字对应表。
UTF-8
互联网的普及,强烈要求出现一种统一的编码方式。UTF-8 就是在互联网上使用最广的一种 Unicode 的实现方式。其他实现方式还包括 UTF-16(字符用两个字节或四个字节表示)和 UTF-32(字符用四个字节表示),不过在互联网上基本不用。重复一遍,这里的关系是,UTF-8 是 Unicode 的实现方式之一。
UTF-8 最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8 的编码规则很简单,只有二条:
- 1)对于单字节的符号,字节的第一位设为
0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。 - 2)对于
n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
下表总结了编码规则,字母x表示可用编码的位。
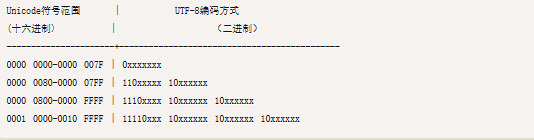
跟据上表,解读 UTF-8 编码非常简单。如果一个字节的第一位是0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。
下面,还是以汉字严为例,演示如何实现 UTF-8 编码。
严的 Unicode 是4E25(100111000100101),根据上表,可以发现4E25处在第三行的范围内(0000 0800 - 0000 FFFF),因此严的 UTF-8 编码需要三个字节,即格式是1110xxxx 10xxxxxx 10xxxxxx。然后,从严的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,严的 UTF-8 编码是11100100 10111000 10100101,转换成十六进制就是E4B8A5。
越是常用的字符,字节越短,最前面的128个字符,只使用1个字节表示,与ASCII码完全相同。
| 编号范围 | 字节 |
| 0x0000 - 0x007F | 1 |
| 0x0080 - 0x07FF | 2 |
| 0x0800 - 0xFFFF | 3 |
| 0x010000 - 0x10FFFF | 4 |
实例
有时候,我们在给后端传递变量的的值中有汉字,可能由于编码的原因,传递到后端后变为乱码了。所以有时候为了省事或者其它特殊要求的时候,会把传递的汉字转换成Unicode编码后再进行传递。
当然汉字转换成unicode编码,使用JS的charCodeAt()方法就可以。
'好'.charCodeAt(0).toString(16)
"597d"
这段代码的意思是,把字符'好'转化成Unicode编码,toString()就是把字符转化成16进制了
用法:charCodeAt() 方法可返回指定位置的字符的 Unicode 编码。这个返回值是 0 - 65535 之间的整数
语法:stringObject.charCodeAt(index)index参数必填,表示字符串中某个位置的数字,即字符在字符串中的下标。
注:字符串中第一个字符的下标是 0。如果 index 是负数,或大于等于字符串的长度,则 charCodeAt() 返回 NaN。
例如:
var str="Hello world!" document.write(str.charCodeAt(1)) //结果:101
'好哦'.charCodeAt(0).toString(16) "597d" '好哦'.charCodeAt(1).toString(16) "54e6"
要是想把unicode解码成字符呢?
要想对Unicode解码的话,必须要用转义字符'\u'
'\u54e6' "哦"
总结下:
js unicode是以十六进制代码外加开头\u表示的字符串。即\unnnn
Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。1990年开始研发,1994年正式公布。
下面先看一个简单的例子,汉字转化为unicode(16进制)方法:
function toUnicodeFun(data){ if(data == '' || typeof data == 'undefined') return '请输入汉字'; var str =''; for(var i=0;i<data.length;i++){ str+="\\u"+data.charCodeAt(i).toString(16); } return str; } var resultUnicode = toUnicodeFun('中国'); // \u4e2d\u56fd console.log(resultUnicode);
unicode(16进制)转化为汉字的方法:
function toChineseWords(data){ if(data == '' || typeof data == 'undefined') return '请输入十六进制unicode'; data = data.split("\\u"); var str =''; for(var i=0;i<data.length;i++){ str+=String.fromCharCode(parseInt(data[i],16).toString(10)); } return str; } var resultChineseWords = toChineseWords("\\u4e2d\\u56fd"); console.log(resultChineseWords);//中国
在网上找到另外一个实现方式:
var GB2312UnicodeConverter={ ToUnicode:function(str){ return escape(str).toLocaleLowerCase().replace(/%u/gi,'\\u'); }, ToGB2312:function(str){ console.log(str) return unescape(str.replace(/\\u/gi,'%u')); } }; var result = GB2312UnicodeConverter.ToUnicode('中国'); //\u4e2d\u56fd var result2 = GB2312UnicodeConverter.ToGB2312(result); // 中国
下面实现汉字转Unicode码(16进制):
function toUnicode(s){ return s.replace(/([\u4E00-\u9FA5]|[\uFE30-\uFFA0])/g,function(newStr){ return "\\u" + newStr.charCodeAt(0).toString(16); }); }
注:中文汉字的unicode范围:\u4e00-\u9fa5;全角字符的范围是:\ufe30-\uffa0
详细的编码可参考:
补充内容
1.国际标准化组织通过了一套ISO-8859-1的编码,规定了单字节256个符号的编码方式。目前,这是8位编码的国际标准。
2.Unicode编码中表示字节排列顺序的那个文件头,叫做BOM(byte-order mark),FFFE和FEFF就是不同的BOM。
UTF-8文件的BOM是“EF BB BF”,但是UTF-8的字节顺序是不变的,因此这个文件头实际上不起作用。有一些编程语言是ISO-8859-1编码,所以如果用UTF-8针对这些语言编程序,就必须去掉BOM,即保存成“UTF-8—无BOM”的格式才可以,PHP语言就是这样。
3.汉字编码中现在主要用到的有三类,包括GBK,GB2312和Big5:
- ①、GB2312又称国标码,由国家标准总局发布,1981年5月1日实施,通行于大陆。新加坡等地也使用此编码。它是一个简化字的编码规范,当然也包括其他的符号、字母、日文假名等,共7445个图形字符,其中汉字占6763个。我们平时说6768个汉字,实际上里边有5个编码为空白,所以总共有6763个汉字。 GB2312规定“对任意一个图形字符都采用两个字节表示,每个字节均采用七位编码表示”,习惯上称第一个字节为“高字节”,第二个字节为“低字节”。GB2312中汉字的编码范围为,第一字节0xB0-0xF7(对应十进制为176-247),第二个字节0xA0-0xFE(对应十进制为160-254)。 GB2312将代码表分为94个区,对应第一字节(0xa1-0xfe);每个区94个位(0xa1-0xfe),对应第二字节,两个字节的值分别为区号值和位号值加32(2OH),因此也称为区位码。01-09区为符号、数字区,16-87区为汉字区(0xb0-0xf7),10-15区、88-94区是有待进一步标准化的空白区。
- ②、Big5又称大五码,主要为香港与台湾使用,即是一个繁体字编码。每个汉字由两个字节构成,第一个字节的范围从0X81-0XFE(即129-255),共126种。第二个字节的范围不连续,分别为0X40-0X7E(即64-126),0XA1-0XFE(即161-254),共157种。
- ③、GBK是GB2312的扩展,是向上兼容的,因此GB2312中的汉字的编码与GBK中汉字的相同。另外,GBK中还包含繁体字的编码,它与Big5编码之间的关系我还没有弄明白,好像是不一致的。GBK中每个汉字仍然包含两个字节,第一个字节的范围是0x81-0xFE(即129-254),第二个字节的范围是0x40-0xFE(即64-254)。GBK中有码位23940个,包含汉字21003个。
专门介绍汉字与汉字计算机化的 汉典 http://www.zdic.net/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号