【Fundamentals of Windows Performance Analysis】翻译,第一章:你好,性能的世界
第一章 Hello, Performance World
性能问题(Performance issues)
什么是性能问题?本书将会有大量的样例来展示各种性能问题,对他们进行分类,并搭建一个框架,可以快速帮助你识别一个性能问题属于哪种类别。它也将教会你如何处理每一个这样的问题。 最重要的是,性能问题是端侧用户可以直接感知到的。
用户的关注/感知(User concern/perception)
并不是所有用户报告的问题都是真正的性能问题。 几类典型的有效的性能问题的例子包括:
- 系统运行缓慢
- 启动一个程序花了很长时间
- 浏览器加载一个页面太慢
- 操作超时
- 电池耗电快
- 网络慢
- 滚动/平移不流畅(Scrolling/panning is not smooth)
- 视频播放故障(Video playback is glitching)
还有一些抱怨实际上属于用户的误解, 比如: - 磁盘灯一直亮着
- 空闲内存少
- 太多的进程在运行
实际上这些可能这些并不是一个性能问题。 磁盘可能在不影响用户的前提下低优先级运行; 操作系统可能使用内存在做系统缓存; 拥有大量进程也并不一定意味着会消耗大量的资源。 这些活动都不一定与用户糟糕的体验有关, 但是有些用户可能把这些误解为是导致性能问题的原因。
如你所见,对一个问题的描述可能是非常模糊和笼统的。把用户的感知和实际的问题原因联系起来是一个非常复杂的工程。 我们将在本书中向你展示这其中的诀窍。
性能问题的类型(Types of performance issues)
简单来讲,大多数性能问题都是因为某个活动花费了比预期更长的时间。 一些问题直接影响产品外观(UI问题), 其他的可能导致不必要的长时间或者非竞争场景持续时间(非UI问题)。
那么,这些问题通常是如何被用户感知到的呢?它们可以从两个方面被用户感知到,一方面是特定用户交互期间的高延迟(high latencies),比如响应度问题(responsiveness issues), 一方面是特定场景的低吞吐量问题(low throughput)。度量延时和吞吐量是所有性能问题分析的基础。
上文讲到的最后两个例子代表了UI性能问题的一个特殊类别--平滑/流动性问题(fluidity issues)。当滑动的时候可能响应是非常及时的,但是如果产生了用户可以感知到的卡顿抖动,用户体验仍然是非常糟的。
**NOTE: 本书不会聚焦分析UI流动性问题,但我们将讨论一些造成该类问题的根本原因。比如高优先级线程和被中断的CPU使用。 又或者许多的UI流动性问题围绕着在显示间隔内显示一帧(VSync)。 在第8、9章对此的讨论和分析也会对分析该类问题有帮助。 **
性能问题描述(Performance issue description)
还有什么比从几个例子开始更好的方式来说明如何描述性能问题呢?请考虑以下说明:
-
Media Player中的视频流出现问题,因为数据包由于连接不可靠而被丢弃
-
由于并发下载,浏览器导航有时会变慢
-
计算机速度慢,因为foo.exe进程占用了所有CPU时间
所有这些陈述都描述了性能问题的表现以及其原因。请注意, 这些描述既意味着受影响的产品,也意味着该产品内部的用户场景。这些描述还试图说明为什么会发生这个问题。您可能已经看到了几类可能导致性能问题的原因:
- 利用不可靠的资源(即可能存在丢包的连接)执行任务
- 利用共享资源(即在多个应用程序之间共享受限带宽)执行任务
- 挤占资源导致其他程序饿死。
最后一个例子有点特殊,“产品”是机器和操作系统本身。这里也是资源共享导致性能问题的一个例子,因为行为不当的过程foo.exe没有为在系统上运行的其他应用程序留下更多的CPU时间,导致其他程序饿死。我们将在本章稍后看到一个实际的例子。
性能问题通常在本质上是短暂的(transient)。你会看到间歇性的慢速(intermittent slowdowns)和偶尔的故障(occasional glitches)。这一点因为执行环境的高度复杂性前面被我们回避了。您编写的代码和/或运行不得不与许多其他代码和程序进行竞争。代码和资源都经常表现得和平常不同。让我们来看看几个基本的例子:
- 第二次启动应用程序通常比第一次更快, 因为操作系统通常将数据缓存在内存中
- 因为内存缓存的影响,从另一个内存地址读数据甚至从同一个地址读数据时间相差可能会很大
- 从磁盘中读一个小文件可能会花很久,因为磁盘可能折叠/压缩了(spun down)
在本书的后面,我们会花很多时间讨论这些例子。我们还将仔细研究关键系统资源是如何运作的。现在重要的是你要理解,现代的计算机系统是许多运动部件的复杂组合。每个部分的性能都是不可预测的,这对任何试图在其上构建良好性能体验的人来说都是一个巨大的挑战。
显然,发生时间是描述性能问题的一个重要方面,就像发生的频率一样。考虑一些展示这个概念的额外例子:
- 在浏览器中跳转到网页X有时要花10s以上
- 看了《指环王》十分钟后,我感到了明显卡顿
我们不想详细讨论形式化的概念,但是要记住的关键是性能问题描述通常包括 什么慢了、有多慢、什么时候慢了。
量化性能问题(Quantifying performance issues)
我们已经多次提到计算机系统变得多么复杂和错综复杂。对于性能分析人员来说,这意味着需要从整体上看整个系统。您以前可能使用过一些性能工具,这些工具可能包含在代码开发环境中,它们向您展示了代码中最耗时的工具。虽然在开发的早期阶段很有用,但是这种有限的视图通常不足以发现系统中的问题所在以及引起问题的原因。
幸运的是,有一些很棒的工具可以来拯救我们。性能分析类似于侦探工作。你分析证据(即不法行为的表现),然后推断原因。在我们看分析之前,让我们先讨论一下如何收集我们将在侦查工作中使用的证据。在系统上运行的任何代码都可以记录调试数据。这个活动通常被称为日志记录。操作系统可以记录重要的操作系统调试信息。驱动程序和服务可以记录特定于其操作的调试信息。类似地,应用程序也可以记录它们自己的调试信息。这些组件中有许多已经做到了这一点,我们将在本书后面向您展示如何记录您自己的调试数据,以及如何从系统的其余部分收集它。
收集性能数据(Collecting performance data)
收集调试数据有两种方式:
•拉式(pull): 让任何需要它的人都可以使用
•推式(Push): 将诊断数据存储在文件中,以便后续分析
在pull模型的情况下,组件注册了性能计数器,系统上的任何人都可以在任何时间点查询它。如果希望通过此机制收集证据,可以使用一个工具,该工具定期轮询感兴趣的数据,并将其保存在文件中。底层组件负责始终保持所报告的调试数据的状态为最新,因为它不知道什么时候将轮询它。这可能会付出昂贵代价。
在push模型的情况下,您使用不同的工具要求感兴趣的组件开始将感兴趣的诊断数据记录到您选择的文件中。然后,底层组件在处理日常业务时简单地记录诊断数据,而不是试图随时准备响应诊断查询。
不管怎样,你最终都会把证据存储在一个文件中,现在你可以分析这个文件来找出问题出在哪里。在Windows中,这两个模型通过以下方式实现:
- Performance Counters for Windows (PCW)(性能计数器)
- Event Tracing for Windows(ETW)(时间追踪器)
那么,为什么要有两种衡量性能的方法呢?PCW是一个很好的性能监控平台。它允许您定期或按需取样(即获取性能度量的快照)。ETW是一个很好的平台,可以收集调试数据,准确地了解在基础活动方面发生了什么。ETW有时也用于高频采样(例如,测量CPU每毫秒做什么)。我们将在第二章和第三章中讨论性能评估的艺术和科学。
常见性能指标(Common Performance Metrics)
一旦我们将性能度量值收集到数据文件中,下一步就是分析它们以寻找线索。你会发现这些文件包含很多,我们指的是很多数据。如果不知道要找什么,你可能很快就会迷路。
您首先要关注的是与您的场景相关的系统中关键资源的使用情况。这些资源包括CPU、存储、内存等。在共享资源执行环境中(比如任何当代通用操作系统),这些资源的过度使用开始成为一个问题。这是因为其他代码正在争夺相同的共享资源,因此,每个竞争的一方现在得到的共享资源越来越少。
你要关注的第二件事是感兴趣的关键活动的持续时间,即特定于你感兴趣的场景的活动。如果您正在查看浏览器中的页面导航,您可能会看到页面导航中涉及的哪些操作对整个持续时间的贡献最大。另一个例子是,如果文件复制花费的时间太长,那么查看哪个磁盘I/ o(即输入/输出操作)花费的时间最长,可能有助于了解导致整体时间过长的原因。
通常,在分析性能数据时,您希望关注与感兴趣的场景和这些活动期间的资源使用相关的活动。对于活动来说,最有趣的是它们的持续时间。活动持续时间和资源使用代表了您的场景中最常见的一些性能指标。
当你翻阅这本书的时候,你会发现很多性能问题的例子。我们还包括了大量的实践练习,向您展示了如何分析实践中观察到的最常见的性能问题。
我们认为,与其花大量时间教你性能工程的基本原理,还不如让你尽快了解一下性能分析是什么。为了达到这个目的,我们在书中包含了大量的练习来让你做实际的分析。第一个是我们版本的“Hello World”示例,它是关于实际性能分析的
练习1.1: “Hello,Performance World”
概述
作为第一个练习,我们希望您了解典型性能分析的基本工作流。我们选择了最简单的性能问题——一个程序使用过多的CPU时间太长,这导致其他一切都运行得更慢。作为本练习的第一步,您将安装Windows性能工具包(WPT),其中包含我们将在本书中使用的工具来捕获和分析性能数据。安装工具后,您将运行套件附带的Windows Performance Recorder (WPR),并开始跟踪系统活动。之后,您将启动一个示例CpuHoger.exe实用程序,我们在本练习中包含了该实用程序,并观察到您的系统基本上没有响应。一旦CpuHoger.exe终止,您将停止跟踪收集,将收集的跟踪保存到文件中。最后,您将在Windows性能分析器(WPA)中打开此跟踪,并看到CpuHoger.exe导致的CPU使用率高。
练习材料
本书中引用的文件,如跟踪文件、分析配置文件、脚本和源代码,可在http://theperfbook.com/downloads/上在线找到(需要在外网访问下载,公司内网加了代理访问不了)。
安装windows性能工具包
对于本练习(以及本书中的所有其他练习),您需要安装Windows性能工具包(WPT)。WPT几乎附带了所有Windows套件和Visual Studio。如果您的系统上尚未安装它,我们将向您展示如何从Windows SDK获取它。该工具包附带了许多有用的工具,其中两个特别重要:
-
Windows Performance Recorder
-
Windows Performance Analyzer
我们将使用WPR捕获性能跟踪,然后依靠WPA分析这些跟踪日志。这些工具是免费提供的,获得它们的最简单方法是运行SDK web设置,然后只选择WPT安装选项,如图1.1所示。要查找最新的Windows SDK,您可以使用您最喜爱的搜索引擎(只需搜索“Windows
win10/11的下载地址:
https://docs.microsoft.com/zh-cn/windows-hardware/get-started/adk-install
测量过程(可选)
上面的下载网址已经预置了捕获好的etl文件,因此您不必花时间为本练习捕获跟踪。但我们建议您自己完成这些步骤,因为本练习的目的是让您对性能测量及其基本分析的收集有所了解。以下步骤提供了有关如何捕获本练习的性能跟踪的详细说明。
-
开始菜单搜索WPR, 或者everything搜索WPRUI.exe
-
点击开始记录,如图所示:
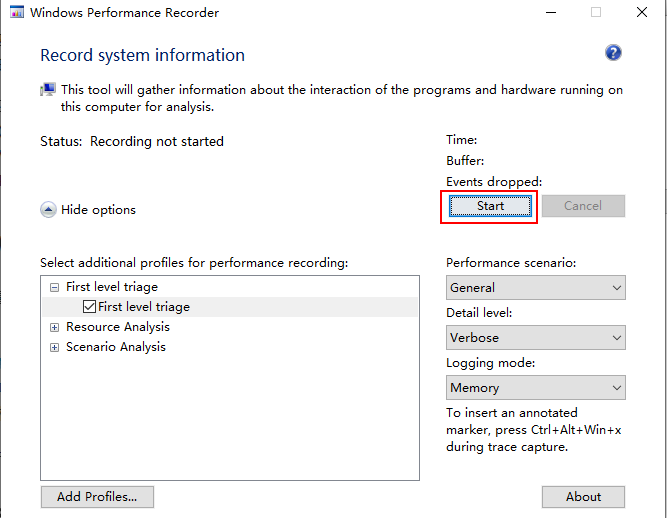
-
启动CpuHogger.exe,在这里下载
-
观察到系统变为未响应状态(大约15s),后面我们打开WPA后可以看到为什么。
-
保存收集的trace日志,可以在保存时输入细节描述
-
通过WPA打开。
恭喜,你已经成功捕获了你的第一个性能日志,下一节我们将展示如何解析这个日志。
分析方法
本节显示如何分析我们在本练习之前捕获的trace日志。它描述了导致您在系统上经历的卡顿过程的详细日志。
-
选一个etl文件来分析,自己记录的或者从网站上下载下来的。
-
打开这个etl文件
-
看一下整体的分析视图应该如下图所示:
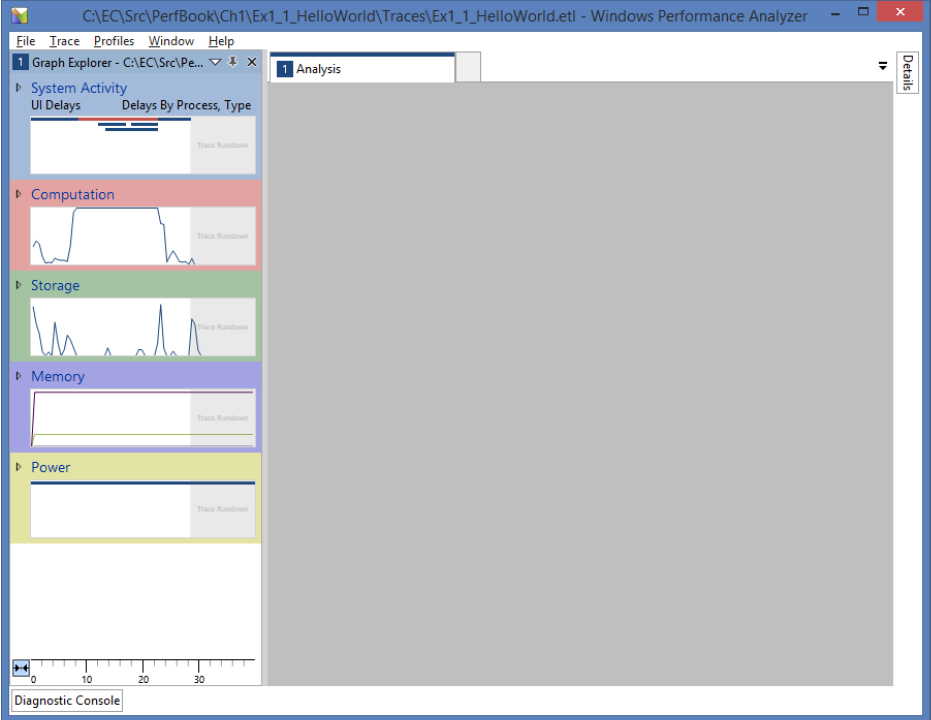
-
分析视图是一个窗口,默认情况下停靠在右侧,它可以承载一个或多个显示性能数据的图形和/或表。它通过共享时间轴同步各个窗口。我们将在第4章中更详细地介绍这些WPA功能。您也可以参考附录A了解WPA的详细概述。
-
请注意左侧的小图表。这些被称为KPI图表(Key Performance Indicators关键绩效指标),我们还将在第4章中更详细地介绍它们(附录A中更详细地介绍)。现在,观察到Computation KPI图表显示它的活跃度很高。这告诉我们,在我们的测量过程中,系统上的某些东西消耗了大量的CPU资源。
-
要更仔细地查看CPU消耗情况,请将CouputationKPI图表拖放到右侧的分析视图上。现在,您应该有一个类似于图1.7中所示的视图。
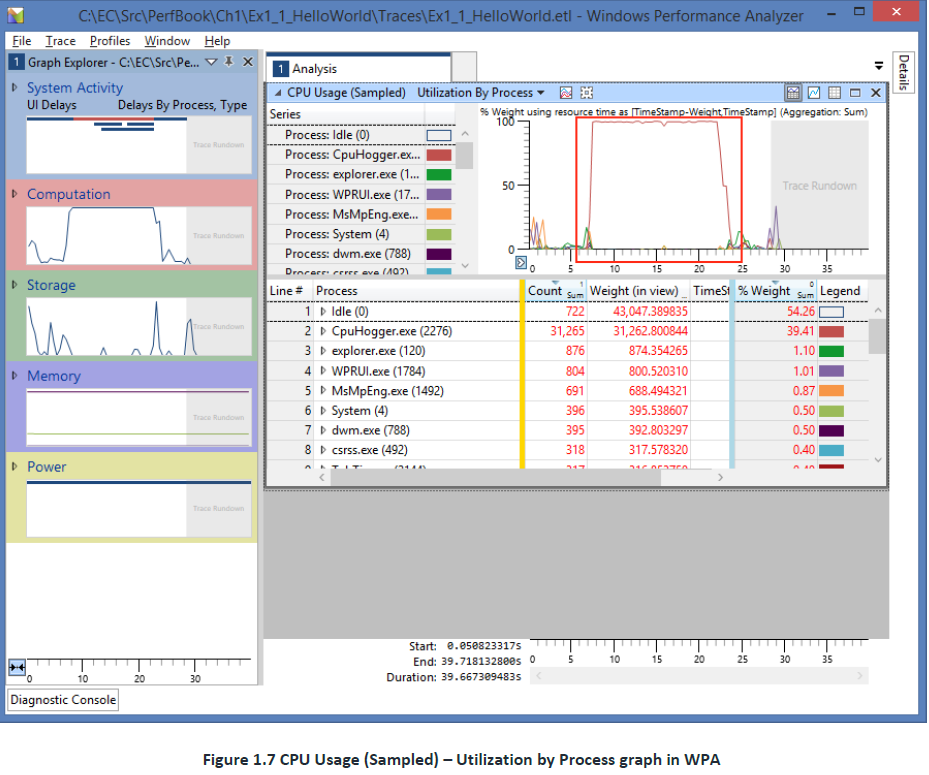
-
此视图可以观察在测量期间运行的每个进程的CPU使用情况。图形的左侧包含一个图例,列出了系统上运行的所有进程及其各自的图形颜色。
-
请注意,高CPU用户在此图表中很快就会脱颖而出。您可以将鼠标光标悬停在图形线上,通过工具提示快速查看该线对应的处理,如图1.8所示。在这种情况下,正如预期的那样,它是CpuHoger.exe。
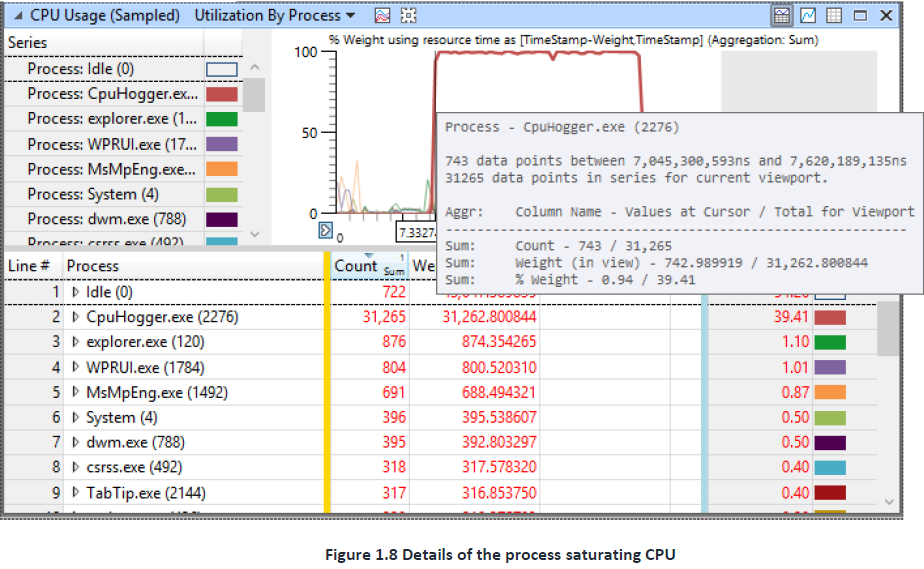
恭喜你!你已经找到了该性能问题的根因。
注意:高级读者可能希望查看CpuHoger的实现。您可能会惊讶地发现,它的代码(包含在本书中)只应该生成5秒的CPU工作,然而,正如我们在本练习中看到的,CPU饱和了大约15秒。我们要一直到第九章才能揭开这个谜团,所以请继续阅读。
练习总结
在此示例中,您已了解如何使用Windows性能记录器(WRP)收集trace日志,然后在Windows性能分析器(WPA)中打开它。然后,您使用WPA观察系统上运行的进程的CPU使用情况,并快速确定占用超多CPU时间的进程。
请注意,还有其他实用程序可以让您对此问题有类似的见解。例如,任务管理器和资源监视器(Windows附带)都会实时向您显示正在运行的进程和相应的CPU利用率的列表。虽然这是真的,但请记住,这是一个非常非常简单的例子。在后面的章节中,您将看到,通过WPT捕获的性能日志获得的详细日志与大多数其他性能工具相比具有许多优势。我们将在下一章中比较和对比这些替代工具中的一部分。
性能问题的因果分析(Causal nature of performance issues)
在上一个示例中,我们刚刚经历了整个性能工程周期——从抓取日志到分析再到定位根本原因——尽管这是个微不足道的周期。作为其中的一部分,我们进行了快速的一级分类,然后找到了问题的根本原因。当然,我们故意选择了一个非常非常简单的例子。现实世界的性能问题通常更难根本原因。毕竟,你拿着一整本专门讨论这个主题的书。
让我们来看看一个更现实的性能问题示例。当PC闲置一段时间后,您是不是经常碰到需要等待它唤醒场景?我们在观众中看到了一些人点头。您是否注意到当时磁盘LED疯狂闪烁?如果您的系统有旋转驱动器,您也很可能听到它工作非常努力。这实际上是典型性能问题的一个非常常见的例子。有些人已经学会了与他们的系统一起生活,等它慢慢醒来重新开始工作,但他们中没有一个人喜欢这种体验。
这个场景发生的背后是一个关键的系统功能,称为分页(paging)。它的主要价值是让应用程序使用比系统上物理存在的内存更多的内存。它通过将很少使用的数据交换到磁盘,从而使更多的物理内存可供使用来实现这一目标。当然,为了让事情继续工作,无论何时访问分页数据,它都需要从硬盘读取数据到物理内存。这可能会以推出其他一些少使用的数据为交换的代价,但更重要的是,这可能会在面向最终用户的活动中造成痛苦的延迟。
当系统空闲时,一些后台活动(例如,防病毒或搜索索引器)可能会因为访问大量数据而占用大量内存,因此一些数据可能会被分页。这将导致操作系统将用户数据交换到磁盘上,用户在返回使用计算机后又需要这些数据。因此导致了唤醒时间长。很明显,这里发生了一系列步骤,一件事通向另一件事——类似于多米诺骨牌效应。
- 首先,我们从一个后台任务开始,将大量数据从磁盘读取到内存
- 因此,系统认为我们遇到了容量压力,并决定将一些用户数据交换到磁盘
- 当用户回来并开始访问此数据时,他们不得不等待,因为系统开始遇到硬缺页故障(如果您将内存视为磁盘上数据的缓存,这类似于经历高概率缓存未命中)。
- 将数据带回内存的由此产生的磁盘I/O活动会使磁盘饱和很长一段时间。
- 这导致用户在屏幕上的应用程序经历间歇性的减速,因为它们在内存访问上被阻止,成本与磁盘访问一样高。当然,当开发人员编写这些应用程序时,他们假设这些内存访问需要纳秒,而不是毫秒。在严重的I/O争用下(就像从空闲恢复时的I/O风暴一样),这些毫秒甚至可以增长到秒级时延。
- 当然,用户会感到沮丧,等待他/她的应用程序恢复活力。
此示例显示了您在现实生活中很可能遇到的因果关系链。此链从潜在的根本原因(第1项),通过几个中间原因(第2-5项),一直到用户感知的顶级表现(第6项)。
因果链(Cascade chains)
事实上,事情更复杂。正如我们将在本书后面看到的,因果关系链可能形成因果关系树,在这种树中,多个原因一起可能导致性能问题。在某些情况下,解决其中一个原因可以解决这个问题,而在其他情况下,您必须解决所有这些原因。换句话说,即使在您修复了已确定的根本原因之后,问题仍可能存在。这通常被称为剥洋葱的挑战。更正式地说,这种现象被称为因果链。我们将在第5章看到这样的一个例子。
问题描述(Symptoms)
让我们考虑另一个现实,你来到医院治疗你生病的机器。你进入急诊室,入院,然后经历通常所说的分诊过程。作为分诊的一部分,入院护士会问你一些问题,帮助她和她的同事尝试确定(即猜测)你的系统出了什么问题。他们将特别关注几种常见症状。如果这是一家普通的医院,他们会询问发烧、疼痛、胃部不适等情况。对电脑来讲,这里也有一系列类似的供你判断的症状,这将帮助你在各种潜在原因之间的复杂网络中找到根因。
让我们来看看在性能分析实践中可能遇到的最常见症状:
- 饱和(Saturation) -- 属于你场景的关键资源已饱和使用
- 争用(Contention) -- 系统上的多个活动正在争夺共享资源,从而中断彼此的进度
- 饥饿(Starvation) -- 活动已经准备好下一步,但拿不到必要的资源继续往后执行
- 利用率不足(Underutilization) -- 活动没有有效地使用可用资源
- 巨大的操作成本(Significant operation cost) -- 活动正在执行的固有成本是巨大的
例如,考虑我们在练习1.1中诊断的问题,在练习1.1中,我们定位到导致系统速度慢的根因是CPU使用率高。在这种情况下,用户尝试做的一切都很慢,因为这些活动都需要占用CPU时间。我们现在知道,这种症状被称为CPU饿死。在我们的分析中,我们发现这种饥饿的原因是CPU饱和。其他一切都如此缓慢的原因是系统上的每个进程都在与CpuHoger.exe竞争CPU时间。我们现在知道,这种症状称为CPU争用
正如您所看到的,同一性能问题有时会有多个相关症状。事实上,由于饱和和由此产生的竞争而导致饥饿是很常见的
在上一个示例中,我们看到了自大狂CpuHoger.exe活动给系统上的其他活动造成了痛苦。然而,有时,罪魁祸首是你的代码。如果您的代码不能有效地利用可用的资源,那么它可能会表现不佳。在实践中,您可能会看到一个常见的例子是轮询的低效实现,这是一个典型的利用率不足的例子,即活动休眠几秒钟然后检查“是否有东西”。实现这一目标的另一种有效方法是使用推送模型,在该模型中,您的活动注册通知。
最后一个示例是启动一个需要很长时间的系统。在系统引导阶段,系统必须从磁盘读取大量数据。在我们调查的过程中,我们可能会发现,有时从磁盘读取的操作耗时非常长,这对于一些坏磁盘来说可能是典型的症结。或者,我们可能会发现系统必须读取大量数据(称为I/O占用空间),这自然需要大量的时间。引导需要很长的时间,因为在读取操作上花费的时间组合非常重要。我们现在知道,这种症状被称为巨大的操作成本。
请注意,就像医疗保健一样,并不是所有的症状都表明实际疾病。你可能会头痛,因为你工作过度。你的体温可能会很高,可能你只是喝了很多热茶或在桑拿房里呆了一个小时。同样,饱和、竞争、饥饿、利用率不足和巨大运营成本的症状也是容易误判的——也就是说,它们不一定表明问题。例如,如果后台任务正在饥饿,用户可能甚至不会注意到这一点。同样,在文件复制期间,您的磁盘可能会饱和——这是意料之中的,事实上,这通常是可取的。
总结(Summary)
在本章中,我们查看了一些典型性能问题的示例,讨论了如何量化它们,并通过一个再现、测量和分析性能问题的实际示例。
我们故意把这个例子做得非常非常简单。在本书的后面,您将会得到大量复杂的性能问题练习,但我们需要慢慢开始,首先了解关键概念。我们希望我们已经引起了您的注意,您已经准备好接受更多。继续读下去,我们会给你指路的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号