
Django之拾遗
一、设计模式
1.1 MVC
-
-
视图(V)是你看到的界面,是模型的表现层,此外还提供了收集用户输入的接口。
-
控制器(C)控制模型和视图之间的信息流动。通过程序逻辑从数据库信息,传送信息给视图。还通过视图从用户处收集信息,变更视图、通过模型修改数据。
1.2 MTV(Django)
-
-
T 表示“模板”,表现层。包含表现相关的决策:在网页或其他文档类型中如何显示某个东西。
-
V 表示“视图”,业务逻辑层。包含访问模型和选择合适模板的逻辑:模型和模板之间的桥梁。
二、在Python脚本中调用Django环境
import os if __name__ == '__main__': os.environ.setdefault("DJANGO_SETTINGS_MODULE", "untitled15.settings") import django django.setup() # 测试代码
三、Django终端打印SQL语句
# settings中配置 LOGGING = { 'version': 1, 'disable_existing_loggers': False, 'handlers': { 'console':{ 'level':'DEBUG', 'class':'logging.StreamHandler', }, }, 'loggers': { 'django.db.backends': { 'handlers': ['console'], 'propagate': True, 'level':'DEBUG', }, } }
四、Django请求生命周期
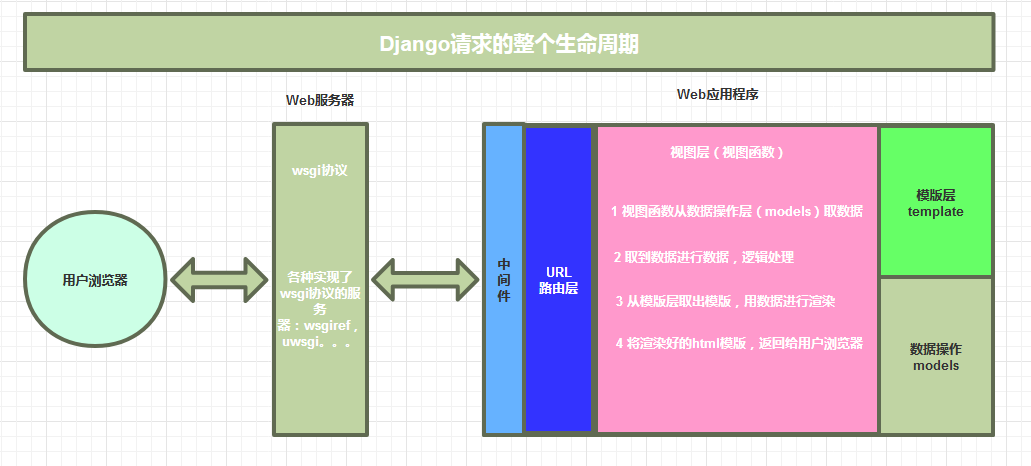
五、Django2.x版本与1.x版本的区别
django2.x的re_path和1.x的url一样
path基本规则
- 使用尖括号(
<>)从url中捕获值。 - 捕获值中可以包含一个转化器类型(converter type),比如使用
<int:name>捕获一个整数变量。若果没有转化器,将匹配任何字符串,当然也包括了/字符。 - 无需添加前导斜杠。
path转化器
Django默认支持以下5个转化器:
- str,匹配除了路径分隔符(
/)之外的非空字符串,这是默认的形式 - int,匹配正整数,包含0。
- slug,匹配字母、数字以及横杠、下划线组成的字符串。
- uuid,匹配格式化的uuid,如 075194d3-6885-417e-a8a8-6c931e272f00。
- path,匹配任何非空字符串,包含了路径分隔符(/)(不能用?)
注册自定义转化器
对于一些复杂或者复用的需要,可以定义自己的转化器。转化器是一个类或接口,它的要求有三点:
regex类属性,字符串类型
to_python(self, value)方法,value是由类属性regex所匹配到的字符串,返回具体的Python变量值,以供Django传递到对应的视图函数中。to_url(self, value)方法,和to_python相反,value是一个具体的Python变量值,返回其字符串,通常用于url反向引用。
栗子:
class FourDigitYearConverter: regex = '[0-9]{4}' def to_python(self, value): return int(value) def to_url(self, value): return '%04d' % value
使用register_converter 将其注册到URL配置中:
from django.urls import register_converter, path from . import converters, views register_converter(converters.FourDigitYearConverter, 'yyyy') urlpatterns = [ path('articles/2003/', views.special_case_2003), path('articles/<yyyy:year>/', views.year_archive), ... ]
六、简单文件上传
前端需要注意的点
1.method需要指定成post
2.enctype需要改为formdata格式
后端暂时需要注意的是
1.配置文件中注释掉csrfmiddleware中间件
2.通过request.FILES获取用户上传的post文件数据
print(request.FILES) print(type(request.FILES.get('file_name'))) file_name=request.FILES.get('file_name').name from django.core.files.uploadedfile import InMemoryUploadedFile with open(file_name,'wb')as f: for i in request.FILES.get('file_name').chunks(): f.write(i)
七、choice
在模型表中定义:choice = ((0,'女'),(1,'男'),(2,'未知'))
在字段上使用:gender = models.IntegerField(choices = choice)
在视图层取对应的文字:gender = author.get_gender_display()
八、only和defer
only('字段'):只会返回queryset中指定的字段对象和id。
defer('字段'):返回queryset中除了指定的字段对象以外的字段对象。
是数据库的优化操作。非要点其他字段也能查询,那就做了两次查询工作,反而会增加服务器压力。
九、事务
要么一起成功,要么一起失败。
ACID性质
-
原子性(Atomicity):事务作为一个整体被执行,包含在其中的对数据库的操作要么全部被执行,要么都不执行。
-
一致性(Consistency):事务应确保数据库的状态从一个一致状态转变为另一个一致状态。一致状态的含义是数据库中的数据应满足完整性约束。
-
隔离性(Isolation):多个事务并发执行时,一个事务的执行不应影响其他事务的执行。
-
持久性(Durability):已被提交的事务对数据库的修改应该永久保存在数据库中。
# 事务操作 from django.db import transaction with transaction.atomic(): # 事务操作代码块 print('事务操作') #结束事务 print('over')
十、多对多关系表的三种创建方式
方式一:自己创建第三张表
class Book(models.Model): title = models.CharField(max_length=32, verbose_name="书名") class Author(models.Model): name = models.CharField(max_length=32, verbose_name="作者姓名") # 自己创建第三张表,分别通过外键关联书和作者 class Author2Book(models.Model): author = models.ForeignKey(to="Author") book = models.ForeignKey(to="Book") class Meta: unique_together = ("author", "book")
方式二:通过ManyToManyField自动创建第三张表
class Book(models.Model): title = models.CharField(max_length=32, verbose_name="书名") # 通过ORM自带的ManyToManyField自动创建第三张表 class Author(models.Model): name = models.CharField(max_length=32, verbose_name="作者姓名") books = models.ManyToManyField(to="Book", related_name="authors")
方式三:设置ManyTomanyField并指定自行创建的第三张表
class Book(models.Model): title = models.CharField(max_length=32, verbose_name="书名") # 自己创建第三张表,并通过ManyToManyField指定关联 class Author(models.Model): name = models.CharField(max_length=32, verbose_name="作者姓名") books = models.ManyToManyField(to="Book", through="Author2Book", through_fields=("author", "book")) # through_fields接受一个2元组('field1','field2'): # 其中field1是定义ManyToManyField的模型外键的名(author),field2是关联目标模型(book)的外键名。 class Author2Book(models.Model): author = models.ForeignKey(to="Author") book = models.ForeignKey(to="Book") class Meta: unique_together = ("author", "book")
当我们需要在第三张关系表中存储额外的字段时,就要使用第三种方式。
但是当我们使用第三种方式创建多对多关联关系时,就无法使用set、add、remove、clear方法来管理多对多的关系了,需要通过第三张表的model来管理多对多关系。
十一、自定义char字段
class FixedCharField(models.Field): """ 自定义的char类型的字段类 """ def __init__(self, max_length, *args, **kwargs): self.max_length = max_length super(FixedCharField, self).__init__(max_length=max_length, *args, **kwargs) def db_type(self, connection): """ 限定生成数据库表的字段类型为char,长度为max_length指定的值 """ return 'char(%s)' % self.max_length class Class(models.Model): id = models.AutoField(primary_key=True) title = models.CharField(max_length=25) # 使用自定义的char类型的字段 cname = FixedCharField(max_length=25)
十二、元信息
ORM对应的类里面包含另一个Meta类,而Meta类封装了一些数据库的信息
class UserInfo(models.Model): nid = models.AutoField(primary_key=True) username = models.CharField(max_length=32) class Meta: # 数据库中生成的表名称 默认 app名称 + 下划线 + 类名 db_table = "table_name" # 联合索引 index_together = [ ("pub_date", "deadline"), ] # 联合唯一索引 unique_together = (("driver", "restaurant"),) ordering = ('name',) # admin中显示的表名称 verbose_name='哈哈' # verbose_name加s verbose_name_plural=verbose_name

