Adaboost算法
集成学习的一般结构是,先产生一组个体学习器,再用某种结合策略将它们结合起来,从而获得一个准确性更高,稳定性更强,泛化性能更佳的集成模型。常用的结合策略有绝对多数投票法,相对多数投票法,加权投票法,简单平均法,加权平均法等。
集成学习方法中具有代表性的两类算法是Bagging和Boosting。Bagging算法的各个弱学习器之间没有依赖关系,Boosting算法的各个弱学习器之间有依赖关系。Boosting是串行式集成学习方法的代表,其代表算法是Adaboost。Adaboost算法在训练过程中,注重减少每个弱学习器的误差,在训练下一个弱学习器时,根据上一次的训练结果,调整样本的分布,更加关注那些被分错的样本,使它们在下一次训练中得到更多的关注,有更大的可能被分类正确。Boosting算法通过在训练集上不断调整样本分布,基于不同的样本分布,重复训练多个弱分类器,最后通过结合策略将所有的弱分类器组合起来,构成强分类器。
Adaboost使用指数函数损失,通过最小化指数损失函数,得到在每次迭代中更新的权重参数计算公式。
错误率:

alpha的计算公式如下:
![]()
计算出alpha的值后,可以对权重向量D进行更新,以使得那些正确分类的样本的权重降低而错分样本的权重升高
样本权重向量D的计算方式如下:
如果样本被正确分类,那么该样本的权重更改为:
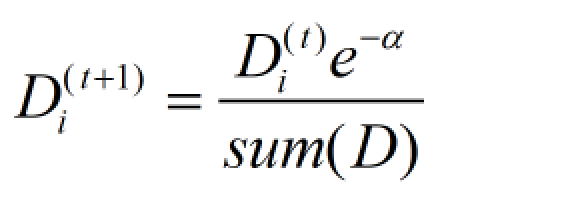
如果样本被错分,那么该样本的权重更改为:
![]()
在计算出D之后,Adaboost又开始进入下一轮迭代,Adaboost算法会不断地重复训练和调整权重的过程,直到训练错误率为0或者弱分类器的数目达到指定值。
Adaboost算法优点:
泛化错误率低,易编码,可以应用在大部分分类器上,无参数调整。
缺点:对离群点敏感。
适用数据类型:数值型和标称型数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号