爬取豆瓣电影
一、任务描述
爬取https://movie.douban.com/tag/#/豆瓣电影,选择电影,中国大陆,2018年,按评分最高,爬取前200部,保存电影名称,图片链接,和电影评分。
由于网页是动态加载,每页显示20条,每一页的网址是变化的,需要去网页上查看网址。
打开网页,进入开发者模式。
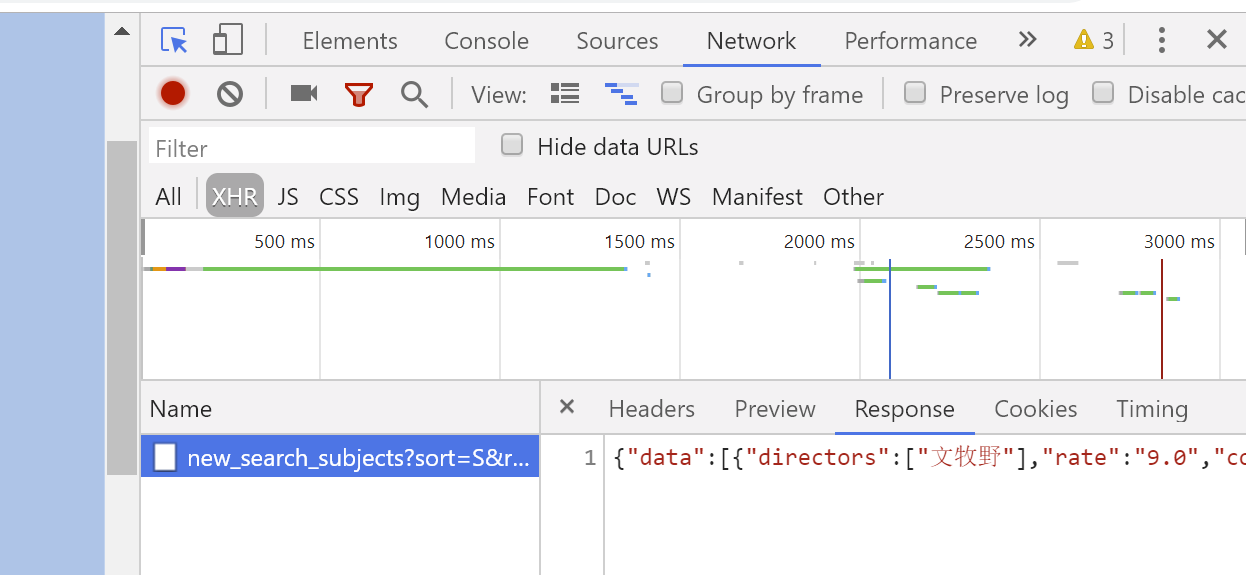
右键new_search_subjects,打开一个新的网页,网页以结构化数据的形式显示了当前页面加载的20部电影的详细信息,例如,电影名称,导演,图片,评分等,此时页面的网址就是要爬取时请求的网址。第一页网址中start的值是0,点击加载更多,加载下一页,出现一个新的new_search_subjects,打开,可以发现,网址的start值变成20,其他不变。第三页的start值变成40,其他不变。所以,加载电影时,一次加载20部,网址中只有start的值是变化的,从0开始,每次增加20,其他地方不变。爬取200部电影就是前10页。

从数据中可以发现,电影名称是title字段,图片链接是cover字段,评分是rate字段。
二、代码
#-*-coding:utf-8-*- import re import json import requests ll = [] for c in range(10): #一页显示20条 url=r'https://movie.douban.com/j/new_search_subjects?sort=S&range=0,10&tags=电影&start={}&countries=中国大陆&year_range=2018,2018'.format(c*20) headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'} page=requests.get(url=url,headers=headers).json() page_list = [] for r in range(20): #每次加载20条 list=page['data'] dict=list[r] item = {} item['name'] = dict['title'] #电影名称 item['img_src'] = dict['cover'] #图片链接 item['score']=dict['rate'] #电影评分 page_list.append(item) ll.extend(page_list) with open("F:/ans.json", 'w', encoding='utf-8') as f: json.dump(ll, f,ensure_ascii=False)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号