x264 P 帧加权与解码时重排加权参考帧
参考:
https://www.cnblogs.com/wangnath/p/15057885.html
https://stephenzhou.blog.csdn.net/article/details/127342398
https://www.cnblogs.com/TaigaCon/p/3602548.html
T-REC-H.264-201704-S!!PDF-E (7.3.3.2 节, 7.3.3.1 节)
1. x264 对 P 帧加权的支持
在 x264 中,对 P 帧加权支持 X264_WEIGHTP_SIMPLE 和 X264_WEIGHTP_SMART 两种模式:
X264_WEIGHTP_SIMPLE:只对原始 P 帧加权X264_WEIGHTP_SMART:在原始加权 P 帧的基础上,再额外生成两个加权帧
X264_WEIGHTP_SIMPLE 模式比较好理解,而对于 X264_WEIGHTP_SMART 模式,额外生成的两个加权帧是什么呢?为什么要生成额外的?有什么作用?
以上问题的答案可以参考:https://www.cnblogs.com/wangnath/p/15057885.html
即 x264 如果支持 X264_WEIGHTP_SMART 模式,那么一般其会有 3 个加权帧并插入到 list0 参考帧列表中:
- 对原始 P 帧正常加权
- 加权参数 offset-1 后,即加权参数微调后生成的加权 P 帧
- 原始 P 帧,不进行任何加权
x264 这么做的目的可以简单理解为让运动搜索更准确(这里不深入探究算法原理)
x264 中生成加权的 P 帧并插入 list0 参考列表中的过程可以参看 encoder.c::reference_build_list() 函数:
static inline void reference_build_list( x264_t *h, int i_poc )
{
...
// 只支持 P 帧加权
if( h->fenc->i_type == X264_TYPE_P )
{
int idx = -1;
// 如果用户开启了加权
// 加权帧在参考列表中的顺序为 [weight-ref, weight-offset-ref, origin, ...]
if( h->param.analyse.i_weighted_pred >= X264_WEIGHTP_SIMPLE )
{
x264_weight_t w[3];
w[1].weightfn = w[2].weightfn = NULL;
if( h->param.rc.b_stat_read ) // 跳过
x264_ratecontrol_set_weights( h, h->fenc );
if( !h->fenc->weight[0][0].weightfn ) // 如果帧类型决策的时候没有生成加权信息,那么只会生成一个额外加权帧
{
h->fenc->weight[0][0].i_denom = 0;
SET_WEIGHT( w[0], 1, 1, 0, -1 );
idx = weighted_reference_duplicate( h, 0, w ); // list0 插入额外加权帧
}
else // 如果帧类型决策的时候生成了加权信息,那么会生成两个额外加权帧
{
if( h->fenc->weight[0][0].i_scale == 1<<h->fenc->weight[0][0].i_denom )
{
SET_WEIGHT( h->fenc->weight[0][0], 1, 1, 0, h->fenc->weight[0][0].i_offset );
}
weighted_reference_duplicate( h, 0, x264_weight_none ); // list0 插入额外加权帧
if( h->fenc->weight[0][0].i_offset > -128 )
{
w[0] = h->fenc->weight[0][0];
w[0].i_offset--;
h->mc.weight_cache( h, &w[0] );
idx = weighted_reference_duplicate( h, 0, w ); // list0 插入额外加权帧
}
}
}
h->mb.ref_blind_dupe = idx;
}
...
}
其中,x264_weight_none 表示插入一个原始 P 帧,w[0].i_offset-- 表示插入一个微调权重的 P 帧,而正常加权的 P 帧已经在 list0 中了。
再来看看插入函数 encoder.c::weighted_reference_duplicate():
static int weighted_reference_duplicate( x264_t *h, int i_ref, const x264_weight_t *w )
{
int i = h->i_ref[0];
// 插入到参考列表第二个位置
int j = 1;
x264_frame_t *newframe;
if( i <= 1 ) /* empty list, definitely can't duplicate frame */
return -1;
//Duplication is only used in X264_WEIGHTP_SMART
if( h->param.analyse.i_weighted_pred != X264_WEIGHTP_SMART )
return -1;
/* Duplication is a hack to compensate for crappy rounding in motion compensation.
* With high bit depth, it's not worth doing, so turn it off except in the case of
* unweighted dupes. */
if( BIT_DEPTH > 8 && w != x264_weight_none )
return -1;
newframe = x264_frame_pop_blank_unused( h );
if( !newframe )
return -1;
//FIXME: probably don't need to copy everything
*newframe = *h->fref[0][i_ref]; // 新的帧直接复制原始帧所有参数 (包括重要的 frame_num, poc 值)
newframe->i_reference_count = 1;
newframe->orig = h->fref[0][i_ref];
newframe->b_duplicate = 1; // 标识一下,编码完当前帧后,需要从参考列表移除
memcpy( h->fenc->weight[j], w, sizeof(h->fenc->weight[i]) ); // 加权参数
/* shift the frames to make space for the dupe. */
h->b_ref_reorder[0] = 1; // 插入了加权帧,需要生成重排序语法
if( h->i_ref[0] < X264_REF_MAX )
++h->i_ref[0]; // list0 参考列表长度+1
h->fref[0][X264_REF_MAX-1] = NULL;
x264_frame_unshift( &h->fref[0][j], newframe ); // 在 j = 1 的位置插入
return j;
}
现在已经有3个加权帧插入到 list0 中了,后面运动搜索的时候就能在加权帧上面进行运动搜索了.
另外需要了解的几点是:
- 真正对 luma 像素加权的计算在
encoder.c::weighted_pred_init()函数中 (如果启用了多线程编码,则在analyse.c::mb_analyse_init()中再对 luma 像素加权) - chroma 像素加权不是必须的,因为运动搜索计算 luma 的 cost 的时候,不一定会加上 chroma 的,所以如果后面需要时才会对 chroma 像素加权
- 插入额外加权帧会使能重排序标识
b_ref_reorder,这里很关键,后面会讲到 - 插入额外加权帧与原始帧
有相同的 frame_num 值,poc 值 - 插入额外加权帧会增加 list0 参考列表长度,最终
list0 长度会写入到码流 num_ref_idx_l0_active_minus1 字段中 - list0 参考列表中 3 个加权帧,都会在码流中生成加权语法
pred_weight_table
2. 解码器如何处理加权帧
如果参考列表中只有一个加权帧,那么比较好理解,解码器中会维护 DPB,如果遇到加权帧,则读取 pred_weight_table 语法表,对该帧进行加权即可。
但是 x264 中会额外生成 2 个加权帧,这会有一些疑问:
- 这 2 个加权帧仅仅用作 x264 内部运动搜索,实际上解码器 DPB 中默认不会存在这 2 个额外的帧
- 如果 x264 运动搜索参考到了这额外的 2 帧,那么码流中参考帧索引序号字段 ref_idx_l0 的值,就会等于额外帧在 x264 list0 中的索引。这时如果解码器 DPB 没有特殊处理,那么
ref_idx_l0 的值就会索引到错误的参考帧
解决如上问题的答案就在重排序算法上,首先我们知道:
- 解码器会维护一个 DPB 缓存,里面存储了解码器收到并解码后的帧,这些帧拥有独立的
frame_num 值(不考虑 B 帧) - 解码一个帧时,解码器也会先生成一个 list0 列表,list0 的长度为
num_ref_idx_l0_active_minus1 + 1。解码器先取 DPB 中的帧先按 frame_num 值从大到小进行默认排序 - 然后读取码流中重排序语法表
ref_pic_list_modification,对 list0 中的帧重新排序 (重排序具体步骤参考:https://stephenzhou.blog.csdn.net/article/details/127342398)
前面说过,x264 插入额外的加权帧时,会生成重排序语法,那么最终重排序是如何解决这个问题的呢?下面有一个示例:
-
x264 已经编码了 3 个可参考帧(一个 I,两个 P),
frame_num 分别为 0, 1, 2。且对frame_num == 1 的帧有额外加权(只生成一个额外加权帧)。那么在解码器 list0 中,默认排序为[2, 1, 0] -
当前解码帧的
frame_num == 3,参考列表长度 == 4,重排序后参考列表索引 1 有加权,语法如下 (H264 Visa 工具):
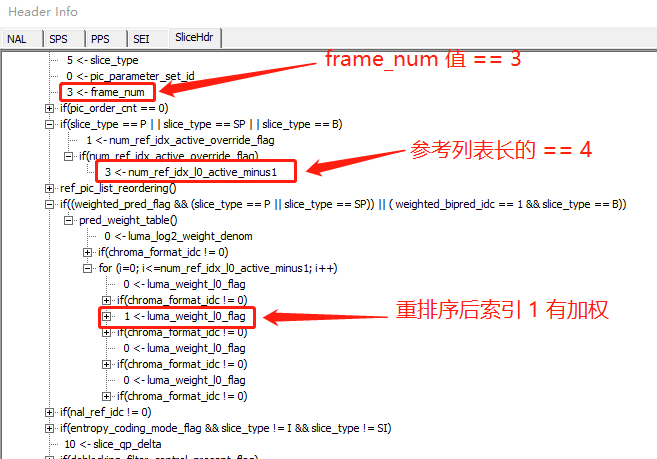
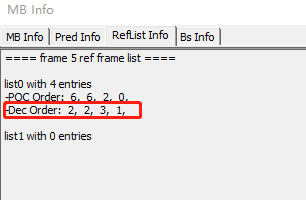
- 在 H264 Visa,显示的 list0 列表值如下 (
H264 Visa 有 BUG,实际上显示的 Dec Order 的所有值应该减 1 才对),可见,list0 中变成了[1, 1, 2, 0]:
- 那么 list0 列表如何从
[2, 1, 0]变换到[1, 1, 2, 0]的呢,首先我们看看当前解码帧的重排序语法表ref_pic_list_modification:
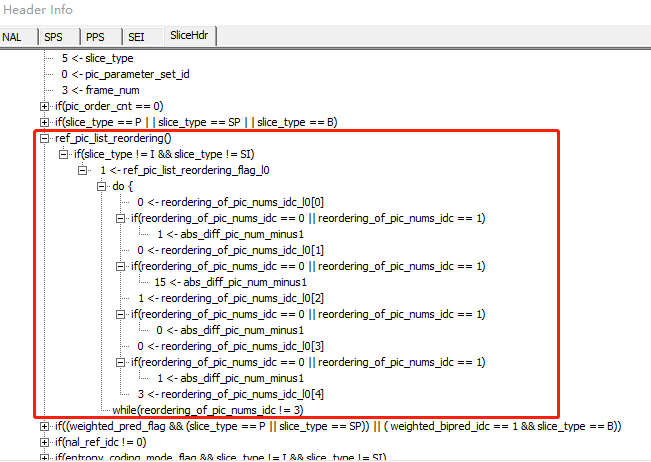
根据初始列表顺序和重排序语法,我们有如下步骤:
| 说明 | frame num (list0 中要移动的帧编号) | list0 (x 表示位置空缺, 括号表示本轮已经移动的帧) |
|---|---|---|
| 初始 | 3 | 2 1 0 x |
| 第一轮重排序 | 3-2=1 | (1) 2 0 x |
| 第二轮重排序 | 1-16+16=1 | 1 (1) 2 0 |
| 第三轮重排序 | 1+1=2 | 1 1 (2) 0 |
| 第四轮重排序 | 2-2=0 | 1 1 2 (0) |
可以看到,重点在第二轮重排中,帧 1 好像被复制了一次,事实也确实是这样,通过第二轮排序,额外加权帧 1 在 list0 中被复制了一份,复制帧在 list0 中的索引也与加权语法表 pred_weight_table 中要加权的索引值对应上了。
但是还有一个问题,这里复制帧仅仅是指针复制吗?(浅拷贝),这个问题可以到 ffmpeg h264 解码器源码中寻找答案,参看 h264_refs.c::ff_h264_build_ref_list() 函数:
// 构建参考列表函数
int ff_h264_build_ref_list(H264Context *h, H264SliceContext *sl)
{
// 初始排序
h264_initialise_ref_list(h, sl);
...
// 遍历参考列表
for (int list = 0; list < sl->list_count; list++) {
int pred = sl->curr_pic_num;
// 遍历重排序语法表
for (int index = 0; index < sl->nb_ref_modifications[list]; index++) {
...
// 真正执行参考帧移动
ref_from_h264pic(&sl->ref_list[list][index], ref);
...
}
}
...
}
里面有一句很关键的代码, 即ref_from_h264pic() 函数,我们看看这个函数里面干了什么:
static void ref_from_h264pic(H264Ref *dst, const H264Picture *src)
{
memcpy(dst->data, src->f->data, sizeof(dst->data));
memcpy(dst->linesize, src->f->linesize, sizeof(dst->linesize));
dst->reference = src->reference;
dst->poc = src->poc;
dst->pic_id = src->pic_id;
dst->parent = src;
}
可以看到,这个函数会将帧的内容复制一次(深拷贝),那么对额外的加权帧,应用像素加权计算,就不影响原始帧了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号