KCP 协议介绍与优化
参考:
- https://luyuhuang.tech/2020/12/09/kcp.html
- https://xiaolincoding.com/network/
- https://coolshell.cn/articles/11564.html
1. 概述
kcp 是一个基于 udp 的应用层协议,其只负责实现 ARQ 算法,需要调用者提供网络数据收发和时钟驱动能力。
其典型图示如下:
ikcp_send ikcp_recv
| |
| |
---------------------
| |
| KCP | ----- clock
| |
---------------------
| |
| |
output ikcp_input
深入 kcp,会发现其设计很多地方与 tcp 协议非常相似,下面首先会简单介绍一下 tcp 协议的一些关键概念,然后再介绍 kcp 内部的相关实现。
2. TCP 协议的几个关键概念简述
2.1 RTT 与 RTO
rtt(Round-Trip Time, 往返时间)反应的是一个网络的瞬时延迟情况(latency),是一个测量值。随着网络情况的变化,rtt 值也在不断变化:
t1 |\ |
| \ |
| \ |
| \|
| | ack
| /|
| / |
| / |
t2 |/ |
rtt = t2 - t1
rto(Retransmission TimeOut, 重传超时时间)是发送端数据重传需要的一个重要的时间指标,rto 是根据 rtt 计算得到一个预估值,合理的 rto 值才能高效的重传。
如果 rto 数值太小,可能会过早重传,浪费网络带宽:
发送端 ack 还没收到就重传:
-- |\ |
| | \ |
| | \ |
rto | \|
| | | ack
| | /|
-- | / |
重传 |\ / |
|/ \ |
| \ |
| \| 收到重复的数据包
如果数值太大,可能会带来更大的网络延迟,影响协议性能:
数据包丢失了了很久才重传:
-- |\ | --
| | \ | |
| | \ | |
| | miss | rtt
| | | |
rto | | |
| | | |
| | | --
| | |
-- | |
重传 |\ |
| \ |
| \ |
| \| 收到数据包, 但是延迟已经很大
所以 rto 应该稍大于 rtt,有合理盈余。
2.2 重传机制
重传机制为 tcp 协议提供了丢包恢复的方法,依靠重传机制,实现可靠传输。发送端首先需要感知到数据包丢失,这依赖于接收端发送过来的 ack 标识:
- 超时没有收到 ack,可以认为包丢失
- 连续三次收到对同一个数据包的 ack,也可以认为包丢失
- 通过 sack 报文判断丢失的报文
2.2.1 超时重传
每个数据包在发送的时候,都会关联一个定时器,超时后需要进行重传。
在 tcp 中,第一次重传定时器时间为计算的 rto 值,后续重传定时器以 rto <-- rto*2 的速率翻倍。
2.2.2 快速重传
超时重传会带来较大的延迟,通过另一种感知丢包的方式:连续三次收到对同一个数据包的 ack,可以触发快速重传。即无需等待超时结束,直接重传丢失的数据:
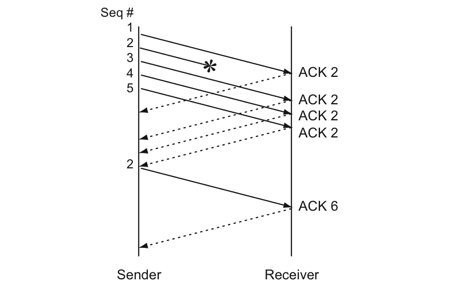
这里发送端 seq=2 丢失,发送 3、4、5 包的时候,接收端都是回复的 ack=2,既可以判断丢包,触发快速重传。
2.2.3 可选择性重传
快速重传带来的一个问题是,仅仅依靠 ack 方法,发送端不知道是丢失了一个报文还是后续发送的报文都丢失了,通过支持 sack 的方式,接收端在 tcp 头部字段中,添加 sack 标识,告诉发送端有哪些报文丢失了:
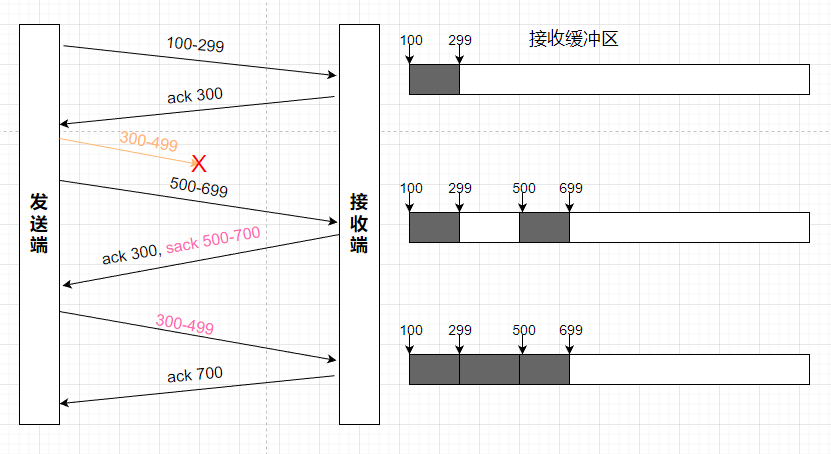
这里 300~499 包丢失,在发送端继续发送 500~699 包后,接收端回复 ack=300,同时携带 sack=500~700。发送端收到 ack 后,判断 300~499 包丢失,执行重传。
2.3 流量控制
接收端通过向发送端告知接收窗口的大小,限制发送端发送数据的能力,此即流量控制。
tcp 通过协议头内的窗口字段告知发送端自己当前能接收的字节数,窗口大小随着数据收发是不断变化的,因此也被成为滑动窗口:
初始窗口:
------------- -------------
| 100 byte | | 100 byte |
------------- -------------
发送 20 byte:
------------- -------------
| 100 byte | 20 byte inflight | 100 byte |
------------- -------------
接收到 20 byte:
------------- -------------
| 100 byte | | 80 byte |
------------- -------------
回复并收到 ack:
------------- -------------
| 80 byte | | 80 byte |
------------- -------------
2.4 拥塞控制
拥塞控制是发送端通过感知网络情况,主动限制自己的数据发送能力的方法。实际上发送端的发送窗口,除了接收端通告的接收窗口大小,还要考虑一个称为拥塞窗口的值(cwnd),最终的发送窗口大小 = min(发送端通告, 拥塞窗口)。
tcp 被设计为一个"君子协议",即只要发现有网络丢包,就主动退让,限制发送能力,然后又慢慢恢复发送能力,周而复始,这些变化通过计算得到的 cwnd(拥塞窗口大小)来体现。如下的一个经典图示:

- cwnd 拥塞窗口大小
- ssthresh 慢启动阈值
- slow start 慢启动阶段
- congestion avoidance 拥塞避免阶段
- fast recovery 快速恢复算法
由于拥塞控制比较复杂,这里不做过多解释,具体请参考网络资料。
3. KCP 协议设计简述
kcp 协议很多设计与 tcp 非常相似,下面介绍其实现。
3.1 kcp 报文格式
0 4 5 6 8 (BYTE)
+---------------+---+---+-------+
| conv |cmd|frg| wnd |
+---------------+---+---+-------+ 8
| ts | sn |
+---------------+---------------+ 16
| una | len |
+---------------+---------------+ 24
| |
| DATA (optional) |
| |
+-------------------------------+
其中:
- conv 连接标识
- cmd 报文类型,支持
IKCP_CMD_PUSH(数据报文)/IKCP_CMD_ACK(ack报文)/IKCP_CMD_WASK(窗口探测报文)/IKCP_CMD_WINS(窗口通知报文) - frg 数据分段标识
- wnd 接收端通告窗口大小
- ts 时间戳
- sn 报文序列号
- una 接收滑动窗口的起始序号标识,所有小于 sn 的报文都已有序到达
- len 数据部分长度
- data 负载,只有
IKCP_CMD_PUSH(数据报文)有这个部分
3.1 RTT 与 RTO
kcp 采用 rfc6298 的推荐的方式计算 rto:
srtt = (l-g)*srtt + g*rtt
rttvar = (1-h)*rttvar + h*|rtt-srtt|
rto = max(interval, srtt+4*rttvar)
其中:
- g 取 1/8; h 取 1/4; interval 为驱动时钟分辨率
- srtt 即对 rtt 的滑动平均
- rttvar 反应 rtt 值的变化情况,即当前 rtt 距离 srtt 变化越大,rttvar 值越大
- 最终 rto 取值最小限制为一个驱动时钟分辨率
初始化 srtt 与 rttval:
srtt = rtt
rttval = rtt/2
3.2 重传机制
tcp 通过 ack 和 sack 机制来实现丢包检测,在 kcp 中:
- kcp 报文 una 字段对应 tcp 中的 ack 字段
- tcp sack 功能通过 kcp 确认报文(
IKCP_CMD_ACK)类型来实现
需要注意的是,kcp 的 una 以包为单位,tcp 的 ack 以字节为单位。
3.2.1 超时重传
当发送端的报文没有被 una 或者 IKCP_CMD_ACK 确认收到时,定时器超时后触发超时重传:
- 如果没有开启 nodelay,则每次超时
rto <-- 2*rto,即每次翻 2 倍 - 如果开启 nodelay,则每次超时
rto <-- 1.5*rto,即每次翻 1.5 倍
3.2.2 快速重传与选择性重传
kcp 支持配置触发快速重传的次数 fastlimit。
实际上 kcp 基本上都是在进行选择性重传,即 kcp 接收端会对每个收到的报文构造一个确认报文(IKCP_CMD_ACK)并发送出去,被确认的报文会被标记已确认。剩下未被确认收到的报文,当 una 超过 fastlimit 次没有确认该报文,那么此报文就会被执行快速重传。
3.3 流量控制
kcp 数据包流经的内部缓冲区示意图:
send() recv()
| |
| |
--------- ---------
|snd_queue| |rcv_queue|
--------- ---------
| |
| |
--------- ---------
| snd_buf | ---------> | rcv_buf |
--------- ---------
其中:
snd_queue存在的目的是,当snd_buf满了的时候,snd_queue帮上层用户做数据缓存,调用者不再需要做数据缓存。snd_queue被设计为无限大。snd_buf作为数据发送缓存,所有在发送滑动窗口内的数据包都会从snd_queue移动到snd_buf中,且未确认的包也会一直保存在snd_buf中rcv_buf作为数据接收缓存,收到的在接收滑动窗口内的包会首先缓存与此,紧接着按序到达的包会被移动到rcv_queue中rcv_queue存储的一定是按序到达的数据包,并等待上层用户读取并移出
发送滑动窗口:
场景:发送端发送了 0、1、2、3 号包,0 号包已经被 ack,1、2、3 号包还没被 ack
---------------- snd_wnd --------------------
| |
------- ------- ------- ------- ------- -------
snd_buf: | 1 | 2 | 3 | | | |
------- ------- ------- ------- ------- -------
| |
snd_una snd_nxt
其中:
snd_una表示发送缓冲区中已发送但是第一个未被 ack 的包序号snd_nxt表示发送缓冲区中未发送但在可发送范围内的第一个包序号snd_wnd表示发送端发送窗口大小,当前时刻发送端可以发送snd_wnd个包
接收滑动窗口:
场景:发送端发送了 1、2、3、4、5、6 号包,1、2、3 号包已经移到了 rcv_queue,但是用户还没读取;4 号包丢失,5、6号包已成功接收并缓存在 rcv_buf 中。
----------------------- rcv_wnd -----------------------------
| |
------- ------- ------- ------- ------- ------- ------- -------
| 1 | 2 | 3 | miss | 5 | 6 | | |
------- ------- ------- ------- ------- ------- ------- -------
| | | | |
------ rcv_que ------ --|-- rcv_buf -------
|
rcv_nxt
其中:
rcv_wnd表示接收端接收窗口大小,可以看到由rcv_que和rcv_buf组成rcv_nxt表示接收端下一个期望的有序数据包
3.4 拥塞控制
kcp 使用与 tcp 基本相似的拥塞控制策略,这里略过。
4. 业务优化
4.1 优化场景
kcp 被设计为一种 ARQ 可靠传输协议,但是可靠意味着某些网络不好的场景会带来更多的延迟。在某些业务场景中,我们可以允许一定程度的丢包,用丢包换取平均低延迟。
考虑如下场景,发送端先后发送了 sn=100 和 sn=101 两个包,但是 sn=100 包丢失,此时 rcv_buf 缓存和 rcv_next 指针的状态如下:
------- ------- ----
rcv_buf: | miss | 101 | ...
------- ------- ----
|
rcv_next = 100
- 由于 sn=100 号包还未收到,sn=101 号包不能转移到
rcv_queue中,接收端会一直等待 sn=100 号包的到来 - sn=101 号包由于 ARQ 可靠传输的特性导致一直缓存用户不能进行读取,如果等待很长一段时间 sn=100 号包才收到,那么结果就是 sn=101 号包的延迟已经显著增加
- 基于此我们可以考虑放弃等待 sn=100 号包,让 sn=101 号包更快的被用户读取,即丢弃 sn=100 号包
4.2 实现方法
要实现主动丢包特性,可以做如下修改:
- 为 kcp 对象添加一个
rcv_buf_time的参数,限制每个在rcv_buf中报文的最大缓存时间 - 为报文对象添加一个
rcv_ts参数,标识接收端收到此报文段时的当前时间戳,即接收时间戳 - 每次 kcp 循环检查
rcv_buf时,都可以判断当前时间戳与接收时间戳的差值是否在最大缓存时间内 - 对于缓存超时的报文,可以向前移动
rcv_next指针以表示跳过某个丢失的报文段;否则继续等待包到达 rcv_buf_time最大缓存时间存在的意义是:sn=101 号包不会一直等待 sn=100 号包到达,等待超时后,允许丢弃前面的包,让用户层尽快读取到 sn=101 号包
4.3 报文分段支持
kcp 支持大数据分段发送,即用户层一次发送的数据大于 mss 时,kcp 内部会进行拆分、分段传输。kcp 报文的 frg 字段即用于此功能。在用户层接收端从 kcp 读取数据时,kcp 会等待数据的所有分段都到达了,然后一次性返回给用户层。
现在由于支持主动丢包,放入 rcv_queue 的报文段可能在业务上并不连续,kcp 不能将不完整的数据返回给用户层。基于此,我们需要扩展 kcp 协议结构:
0 4 5 6 8 (BYTE)
+---------------+---+---+-------+
| conv |cmd|frg| wnd |
+---------------+---+---+-------+ 8
| ts | sn |
+---------------+---------------+ 16
| una | len |
+---+-----------+---------------+ 24
|fs | tag | reserved |
+---+-----------+---------------+ 32
| |
| DATA (optional) |
| |
+-------------------------------+
新增如下两个字段:
fs(frgsize, 1Byte)即当前报文所在的分段总大小,最小为 1tag(3Byte)即当前报文所在的完整数据标识,每次用户发送数据为一个新 tag
依靠这两个参数,我们可以识别 rcv_queue 中的报文段是否在数据块上是连续的。
例如对于如下的缓存情景,我们可以直接按 tag=0 从队列中删除掉:
情景一(主要判断 fs):
------- ------- ------
rcv_queue: | 1 | miss | 3 |
------- ------- ------
| |
_______ tag=0 ______
情景二(主要判断 tag 和 fs):
------- ------- ------- -------
rcv_queue: | miss | 2 | 3 | 4 |
------- ------- ------- -------
| | |
_______ tag=0 _______ _tag=1_
5. 总结
个人认为,kcp 在丢包恢复性能上优于 tcp 得益于如下几点:
- 可配置的快速重传参数
- 更激进的 rto 翻倍策略
- 可配置关闭拥塞控制功能,只开启流控
这样带来的一个可能结果就是,如果当前信道已经被塞满或者丢包率很高,更激进的传输策略可能会导致更大量的丢包,影响其性能(具体待测试)。所以 kcp 应该更适合那些本身只占用小带宽的应用数据,例如游戏角色同步数据。
在业务上,我们也可以继续优化 kcp,通过允许部分丢包带来更低的平均延迟。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号