栈、函数调用与系统调用
参考:
- https://blog.csdn.net/lqt641/article/details/73002566
- https://blog.csdn.net/yangkuanqaz85988/article/details/52403726
- http://home.ustc.edu.cn/~hchunhui/linux_sched.html
- https://www.cnblogs.com/justcxtoworld/p/3155741.html
- https://www.tiehichi.site/2020/10/22/Linux进程栈空间大小/
实验环境:os: centos8.5 / kernel: 4.18.0 / gcc: 8.5.0 / arch: x86-64
1. 栈的概念
数据结构上,栈是一个特殊的数组,数组的头和尾分别为栈底和栈顶,数组中的元素只能在栈顶插入和删除
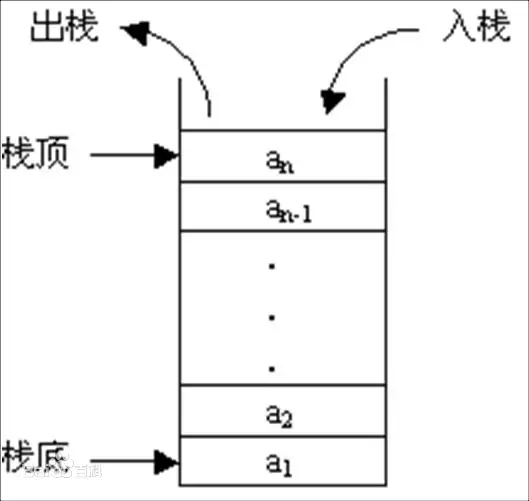
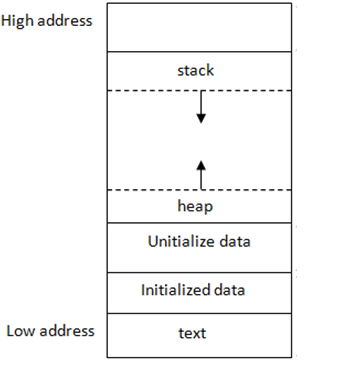
在操作系统中,栈是一段内存区域,这段内存区域同样遵循数据从栈顶插入和删除的特性,栈和其它内存段组成了一个程序的内存地址空间:
2. 栈帧
2.1 cpu 寄存器
函数调用在栈中进行,不同的函数间调用形成了栈帧的概念。栈帧是与 cpu 寄存器密切相关的,在 x86-64 体系结构下的 cpu 寄存器如下:
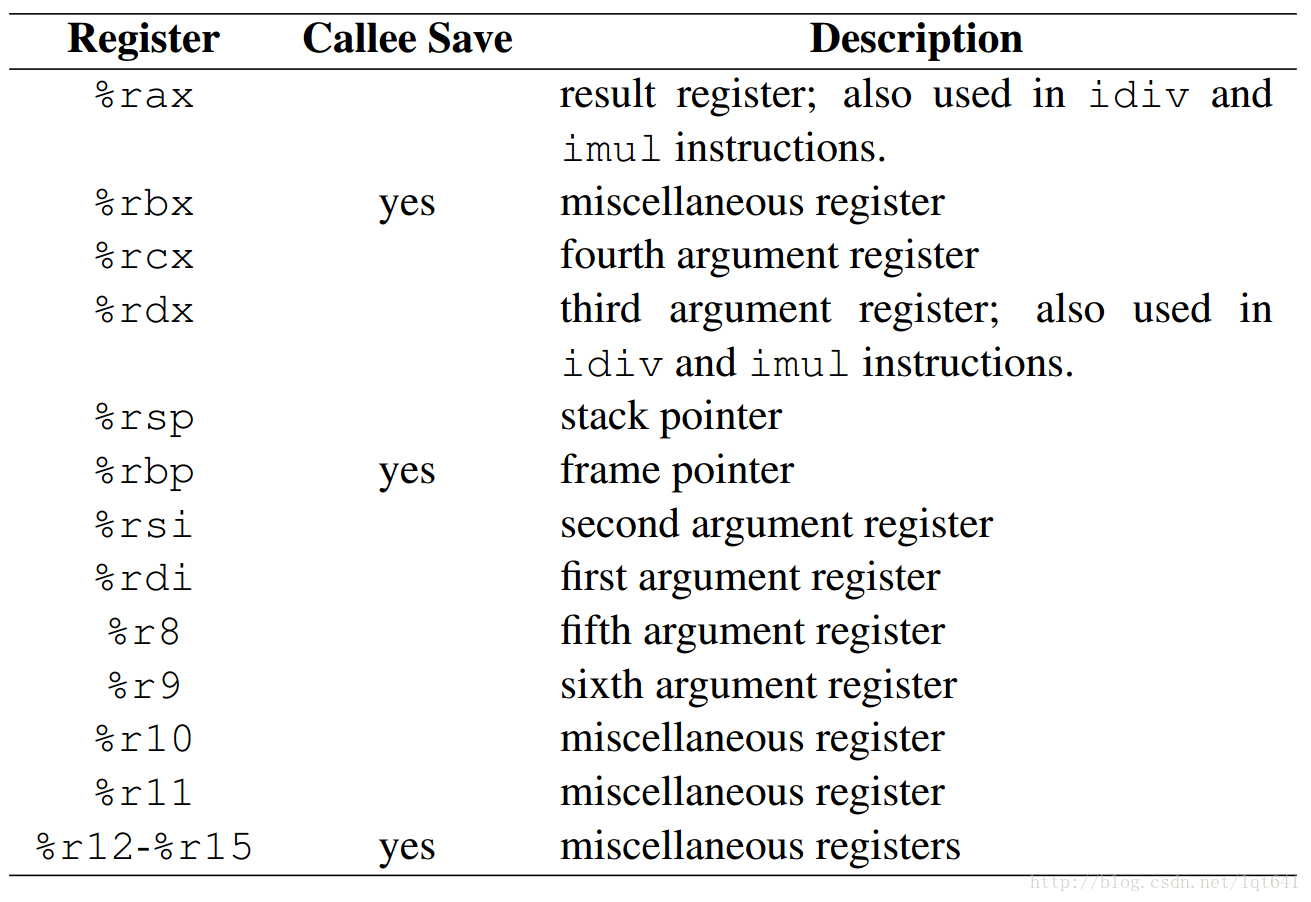
x86-64 体系结构共有 16 个通用寄存器,同样还有一些其它重要的寄存器(如 rip 寄存器、FLAGS 寄存器、SIMD 寄存器等,上图未列出),其中:
- rax 寄存器一般用作存储函数返回值
- rsp 是栈指针寄存器
- rbp 是栈基址寄存器(gcc 如果添加了编译选项
-fomit-frame-pointer,那么 rbp 变为可随意使用的寄存器,程序执行不再需要专门的基址寄存器) - rdi、rsi、rdx、rcx、r8、r9 寄存器用于存储函数调用时传递的的6个参数,如果多于6个,剩下的采用 x86-32 的传参方式,即从右往左写入内存中进行传递
callee save的寄存器,表示在被调用函数中,如果这些寄存器有几个会被使用,那么在使用前,必须先压栈保存,因为调用函数可能用到了,并在返回前退栈恢复caller save的寄存器,表示在调用函数中,如果有使用到其中某几个,在调用其它函数前,必须先压栈保存,因为被调用函数可能会用到,并在调用完毕后退栈恢复
2.2 栈帧
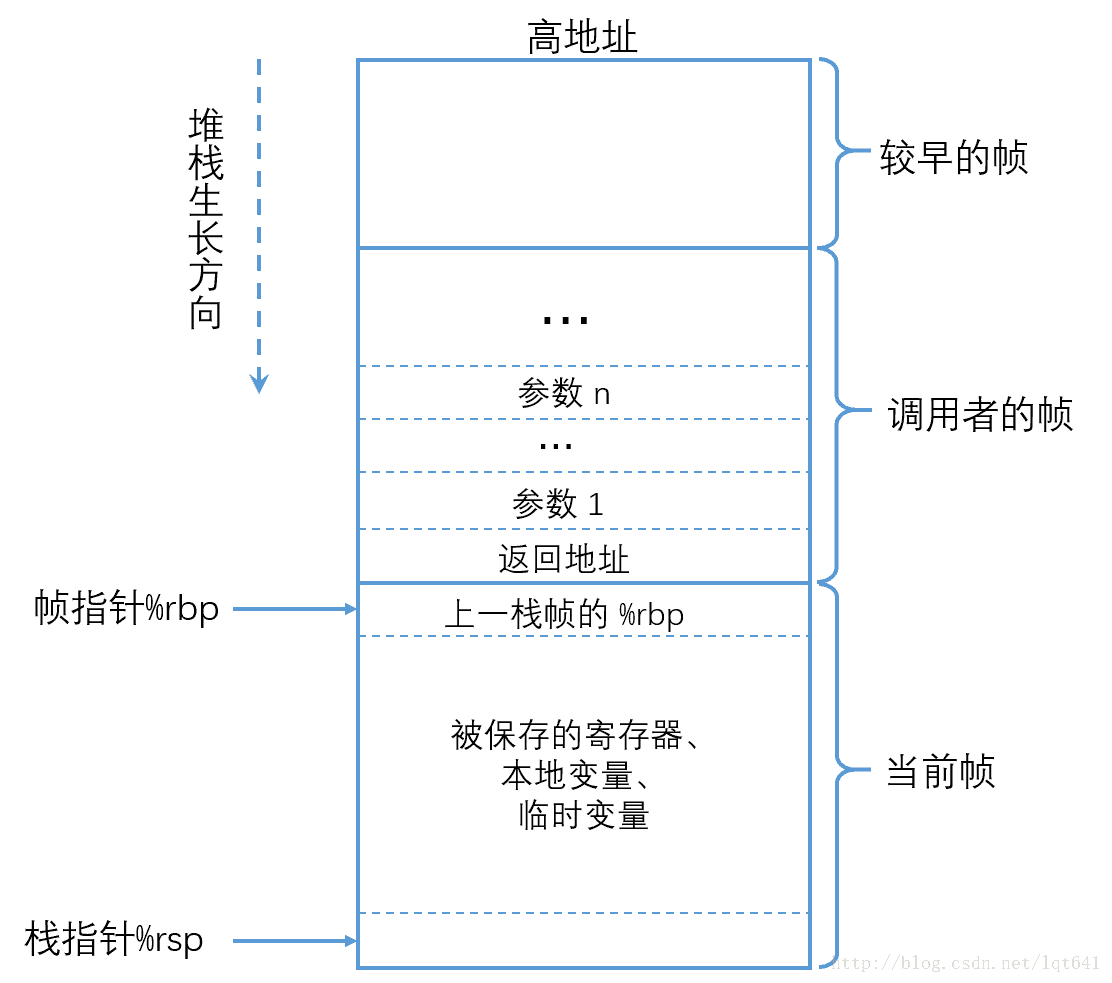
因为 cpu 寄存器数量有限,函数调用的时候,寄存器需要加载新的内容。当函数返回的时候,又需要恢复寄存器的内容,这样函数调用者(caller)的寄存器状态,需要在调用前保存到内存中,这就是栈帧
3. 函数调用
注意:以下内容大部分来自 https://blog.csdn.net/lqt641/article/details/73002566
这里只是总结记录一下,更详细请参考原博文
3.1 函数跳转
函数调用可以分解为如下步骤:
- 父函数将调用参数从后向前压栈
- 将返回地址压栈保存
- 跳转到子函数起始地址执行
- 子函数将父函数栈帧起始地址 rpb 压栈
- 将 rbp 的值设置为当前 rsp 的值,即将 rbp 指向子函数栈帧的起始地址
上述过程中,保存返回地址和跳转到子函数处执行由 call 一条指令完成,在 call 指令执行完成时,已经进入了子程序中,因而将上一栈帧 rbp 压栈的操作,需要由子程序来完成
示例汇编如下:
... # 参数压栈
call FUNC # 将返回地址压栈,并跳转到子函数 FUNC 处执行
... # 函数调用的返回位置
FUNC: # 子函数入口
pushq %rbp # 保存旧的帧指针,相当于创建新的栈帧
movq %rsp, %rbp # 让 %rbp 指向新栈帧的起始位置
subq $N, %rsp # 在新栈帧中预留一些空位(临时变量),供子程序使用,用 (%rsp+K) 或 (%rbp-K) 的形式引用空位
3.2 函数返回
函数返回时,返回值保存在 rax 寄存器中。之后需要将栈的结构恢复到函数调用之前的状态,并跳转到父函数的返回地址处继续执行
由于函数调用时已经保存了返回地址和父函数栈帧的起始地址,要恢复到子函数调用之前的父栈帧,我们只需要执行以下两条指令:
movq %rbp, %rsp # 使 %rsp 和 %rbp 指向同一位置,即子栈帧的起始处
popq %rbp # 将栈中保存的父栈帧的 %rbp 的值赋值给 %rbp,并且 %rsp 上移一个位置指向父栈帧的结尾处
x86-64 架构中提供了 leave 指令来实现上述两条命令的功能。执行 leave 后,前面图中函数调用的栈帧结构如下:
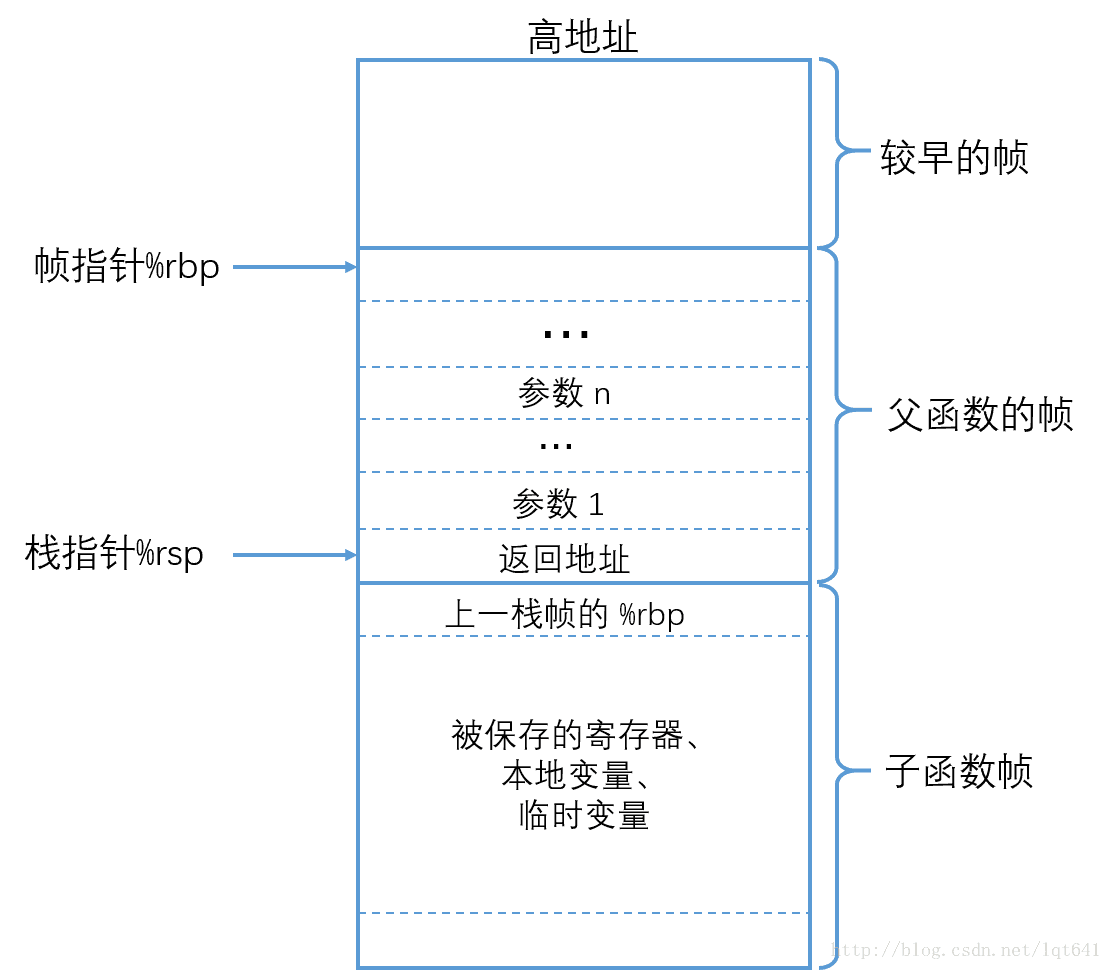
可以看到,调用 leave 后,rsp 指向保存返回地址的地址处
同时,x86-64 提供了 ret 指令,其作用为从 rsp 指向的位置(即栈顶)弹出数据,弹到 rip 指令指针寄存器中,同时 rsp 上移一个位置,这样就实现了 ret 指令后,接着父栈帧的返回地址继续正确的运行
可以看出,leave 指令用于恢复父函数的栈帧,ret 用于跳转到返回地址处,leave 和 ret 配合共同完成了子函数的返回
3.3 关于函数调用参数的传递
- x86-32 将参数写入内存进行传递,x86-64 优先采用6个传参寄存器进行传递,不够时写入内存进行传递
- 关于传递参数写入内存的先后顺序问题,为了适应不定参的传递,如 printf(const char* format, ...) 函数,参数个数不确定,从右往左压栈,format 参数最后压栈,printf 函数根据 fromat 的通配符确定参数个数,然后正确读取参数。如果从左往右压栈,format 第一个压栈,printf 函数将无法取得 format
3.4 示例
如下代码:
int func02(int a) {
int b = 1;
int c = a + b;
return c;
}
int func01() {
int a = func02(100);
int b = 1;
int c = a + b;
return c;
}
int main() {
int a = func01();
return 0;
}
gcc test.c -o mytest 后 objdump -d mytest 反汇编得到 AT&T 格式的汇编代码,func01() 函数的汇编注释如下:
...
0000000000400554 <func01>:
400554: 55 push %rbp // main() 函数 rbp 压栈保存起来,rsp 指向保存的 rbp 地址处
400555: 48 89 e5 mov %rsp,%rbp // 将 rsp 内的地址赋给 rbp,此时 func01() 函数的栈帧起始确定了
400558: 48 83 ec 10 sub $0x10,%rsp // 预留 16 字节的栈空间给 func01() 函数
40055c: bf 64 00 00 00 mov $0x64,%edi // 将 100 赋给 edi,用于参数传递给 func02()
400561: e8 d0 ff ff ff callq 400536 <func02> // 调用 func02()
400566: 89 45 fc mov %eax,-0x4(%rbp) // 将 func02() 保存在 eax 中的返回值保存在栈中
400569: c7 45 f8 01 00 00 00 movl $0x1,-0x8(%rbp) // 将数值 1 接着返回值保存到栈中
400570: 8b 55 fc mov -0x4(%rbp),%edx // 将返回值放到 edx 寄存器中
400573: 8b 45 f8 mov -0x8(%rbp),%eax // 将数值 1 放到 eax 寄存器中
400576: 01 d0 add %edx,%eax // 相加,结果放到 eax 寄存器中
400578: 89 45 f4 mov %eax,-0xc(%rbp) // 将相加的结果保存到栈中
40057b: 8b 45 f4 mov -0xc(%rbp),%eax // 将相加的结果保存到 eax 中作为 func01() 的返回值
40057e: c9 leaveq // 恢复 main() 函数的栈帧
40057f: c3 retq // 跳转到 main() 函数的返回地址继续执行
...
4. 进程内核栈
进程陷入内核态后,将从用户态进程栈切换到内核态内核栈,内核栈使用如下的联合体来分配:
---> /include/linux/sched.h
union thread_union {
...
struct thread_info thread_info;
unsigned long stack[THREAD_SIZE/sizeof(long)];
};
内核栈的大小为 THREAD_SIZE,一般来说是一页的大小,如 4k
内核栈通过 thread_union 联合体来分配的好处是,可以在栈的最低地址处(栈从高地址到低地址增长)映射 struct thread_info 结构体,而此结构体的 task 成员又指向所属的 struct task_struct 对象,这样就能在内核栈中快速方便的找到 task 结构体:
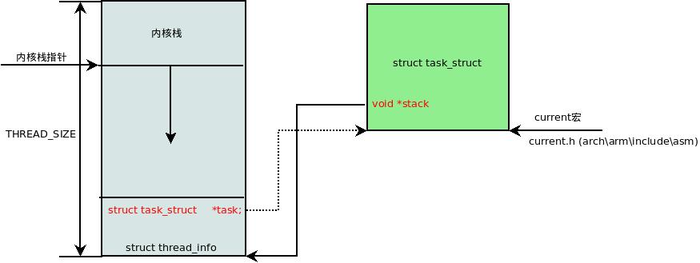
实际上我们常听说的 current() 宏就是通过此方法找到进程的:
register unsigned long current_stack_pointer asm ("sp");
static inline struct thread_info *current_thread_info(void)
{
return (struct thread_info *)
(current_stack_pointer & ~(THREAD_SIZE - 1));
}
#define get_current() (current_thread_info()->task)
#define current get_current()
将 rsp 寄存器的内容与上 ~(THREAD_SIZE - 1),就能得到 thread_info 对象的地址了(thread_union 联合体分配的时候,总是页对齐的)
5. 进程用户栈的大小
5.1 主线程栈
在 x86-64 linux 机器上,我们知道可以通过 ulimit -a 来查看进程最大栈大小,例如默认为 8M。但是一个程序我们使用 cat /proc/pid/maps 看到的 [stack] 段的大小很多为 128kb,远远小于 8M,这是怎么回事呢?
我们知道用户空间的栈段实际上就是一段连续的虚拟地址空间,在内核中通过 struct vm_area_stuct 结构对象来描述。在进程被初始化创建的时候,分配的大小就是 128kb,参见 https://www.tiehichi.site/2020/10/22/Linux进程栈空间大小/
当用户访问的栈地址空间超过 128kb 后,会产生一个缺页异常,内核对栈的缺页异常有特殊的处理,即扩展栈空间大小(深入linux内核架构 4.10章):
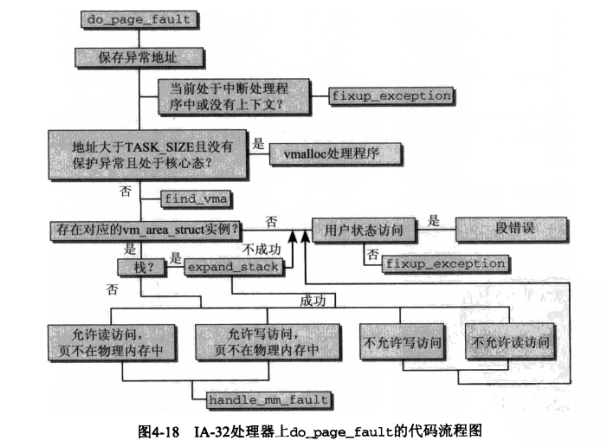
如上图,expand_stack() 函数会完成扩展栈空间的任务
5.2 子线程栈
子线程栈在子线程被创建的初始,就已经固定好大小了,无法像主线程栈一样,动态扩大
6. 系统调用
6.1 陷入内核态
进程从用户空间陷入内核态的时候,栈帧会保存到内核栈上,返回用户态的时候恢复寄存器
那么保存用户态的栈帧之后,怎么正确切换到内核栈的栈帧呢?密码在于存在一个特殊的段,叫做任务状态段(TSS),而 tss 的地址又由一个特殊的 cpu 寄存器 tr 保存,内核从 tr 寄存器找到 tss,再从 tss 恢复内核栈帧
6.2 进程切换
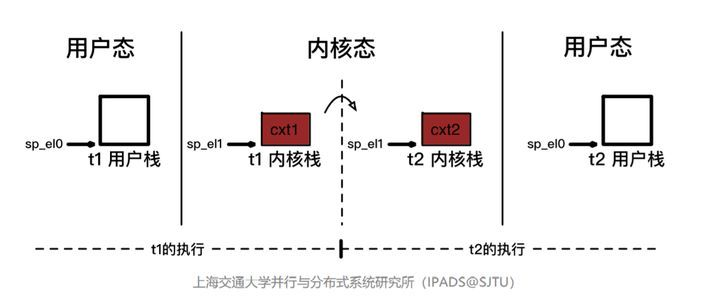
我们知道,进程切换只能发生在内核态,在内核态返回用户态之前,检测 need_resched 标志,如果需要切换进程,当前内核栈帧将会被保存起来,然后切换到其他进程的内核栈。在后面当前进程被重新调度回来之后,再执行正常的返回用户态的工作(保存内核栈帧,恢复用户态栈帧)
用户进程/线程切换需要两次权限等级切换和三次栈切换(https://cloud.tencent.com/developer/article/1903624):

 浙公网安备 33010602011771号
浙公网安备 33010602011771号