Linux 内存管理简述
参考:
- https://www.zhihu.com/question/24916947
- https://www.cnblogs.com/vamei/p/9329278.html
- https://zhuanlan.zhihu.com/p/346892153
- https://www.cnblogs.com/emperor_zark/archive/2013/03/15/linux_page_1.html
- linux内核设计与实现
1. 进程地址空间结构
1.1 地址空间划分
以下是一个 x86_32 体系结构的进程内存空间结构(https://blog.csdn.net/dahailantian1/article/details/78584845#comments_18955160):
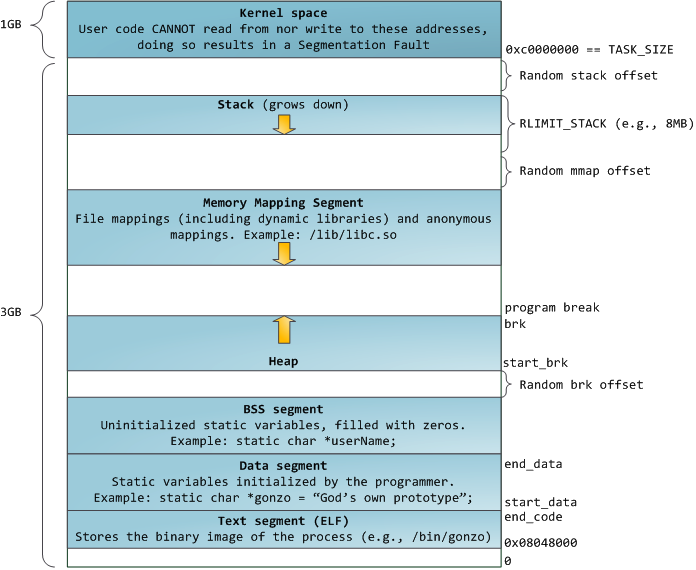
- 代码段、数据段、BSS 段,都是在我们执行 fork() + exec() 系统调用后,从可执行文件中载入内存,他们的结构和占用空间大小,在 ELF 文件中已经确定好
- 堆区可以看作接着 BSS 段向上生长,栈区可以看作从 TASK_SIZE(3G 地址) 开始向下生长
- 堆区和栈区之间是 mmap() 映射区,包括具名映射(打开的动态链接库、文件映射等)和匿名映射(管道、FIFO、共享内存的实现等)
- 最上面 1G 的空间是内核才能访问的空间,与用户空间进行了隔离
1.2 内核表示
我们知道一个进程在内核中使用 struct task_struct 结构体进行表示,使用 struct mm_struct 来管理地址空间(虚拟地址空间):
---> /include/linux/sched.h
struct task_struct {
// ...
struct mm_struct *mm;
// ...
}
---> /include/linux/mm_types.h
struct mm_struct {
// ...
unsigned long start_code, end_code, start_data, end_data;
unsigned long start_brk, brk, start_stack;
// ...
}
struct mm_struct 中的 unsigned long 类型成员变量(x86-64 系统),描述了地址空间的划分(https://blog.csdn.net/yangkuanqaz85988/article/details/52403726):

2. 分页内存管理
2.1 页帧
对于物理内存,使用 frame(页框) 的概念来管理,整个物理内存被划分为了一块块 frame,每个 frame 大小为 4KB 或者 8KB 等。
在虚拟内存中,linux 采用 struct page(页帧) 的数据结构来进行管理,page 和 frame 大小一样,后文可以统称为 page(页帧)。
无论是 frame 还是 page,都有一个编号:
- 对于 frame,有称为 PFN(page frame number) 或 PPN(physical page number) 的页编号
- 对于 page,有称为 VPN(virtial page number) 的页编号
在内核中,所有 struct page 结构都被放入了全局数组 mem_map 中,在根据虚拟页查找物理页时,首先要找到 PFN,然后就能找到物理页的地址(通过调用 page_to_phys() 函数),最后加上 4KB 的页内偏移,就是最终的物理地址。
struct page 一般按功能划分为以下3项:
- 虚拟地址到物理地址的映射
- 文件页缓存
- 私有数据(暂未研究)
物理内存使用 struct page 的结构来描述,那么这么多 struct page 本身会不会很占用内存呢(Linux内核设计与实现 12.1章):

2.2 分区
在 x86-32 体系结构中,对 1G 的内核空间,存在着分区的概念(在用户进程看来内核地址空间在 [3G, 4G] 地址空间,实际上物理地址上在 [0, 1G] 物理地址空间).
分区是指将 1G 地址空间,设计为多个分区,这称为 DMA zone、normal zone、high zone(Linux内核设计与实现 12.2章):

- DMA zone,即实现特定硬件 DMA 操作的内存区域,物理地址范围为[0, 16MB]
- normal zone,实现了物理地址到虚拟地址的线性映射(虚拟地址[3GB+16MB, 3GB+896MB]线性映射到物理地址[16MB, 896MB]),内核访问 normal zone 时,根据虚拟地址加上一个偏移量,就得到了物理地址
- high zone,线性映射无法映射的区域[896MB, ~]为高端内存。为了使内核能访问更多的内存,且减少线性映射造成的内存碎片化问题,[128MB, 1G] 的空间专门用来进行虚拟地址映射,内核访问 high zone 时,访问的是虚拟地址
2.3 内核内存分配函数
- struct page* alloc_pages(),直接获取一页或多个连续页,页对应的地址通过 void* page_address(struct page*) 来获得
- 如果不想一次获取一页,则可以使用 kmalloc(),其默认从 normal zone 分配线性映射内存,也可以从 DMA zone 和 high zone 分配内存
- 如果需要使用高端内存,则可以使用 vmalloc() 来申请内存
3. 页表
我们需要一个表来转换虚拟页到物理页,这个表称为 page table(页表),页表由一个个条目组成,这称为 PTE(page table entry)。
pte 中有包含很多信息,但是其中一定会包含上文说明的 PPN 或者 VPN 编号,通过此编号,就能换算出映射的地址。
3.1 一级页表
这里先假设只存在一级页表,即一级页表中的 pte 存储的是 PPN 编号。
如果一页大小是 4096 字节,以 x86-32 体系结构为例,那么地址的低 12bit 刚好可以表示 [0, 4095] 字节的范围,所以,虚拟地址的低 12bit 可以完全对应某个物理页帧内的地址偏移
这里以地址 0x0001a011 为例,通过页表翻译物理地址的图解如下(https://www.cnblogs.com/vamei/p/9329278.html):

0x0001a011 可以拆分为 0x0001a 和 0x001,通过 0x0001a 得到物理页帧的起始位置,最后通过 0x001 页内偏移加上物理页帧的基址,得到最终的物理地址
3.2 多级页表
一级页表存在如下问题(引用 https://zhuanlan.zhihu.com/p/36281246):
- 对于一个 32bits 的地址空间,如果一个分页大小为4Kb,那么虚拟内存地址需要 12bit(2^12约等于4000) 作为offset,其余 20 bits 作为 PPN
- 20bits 作为 PPN 则意味着一个 page table 要保存 2^20(大约一百万条)条 pte 记录
- 假如一条分页表单元大小为 4bytes, 那么整个分页表大小约为 4MB
- 如果共计有 100 个进程在运行,那么所有分页表占据的内存为 400MB
对于此,linux 采用了多级页表的方式,如典型的三级页表: PGD (页全局目录)、PMD (中间页目录)、PTE (页表)
这些页表被保存在内存中的某个区域,其中 PGD 页表的物理内存地址被放置在了 struct task_struct ---> struct mm_struct 中:
struct mm_struct {
// ...
pgd_t* pgd;
// ...
}
虚拟地址可以分为多段 VPN + offset(引用 https://zhuanlan.zhihu.com/p/484183354):
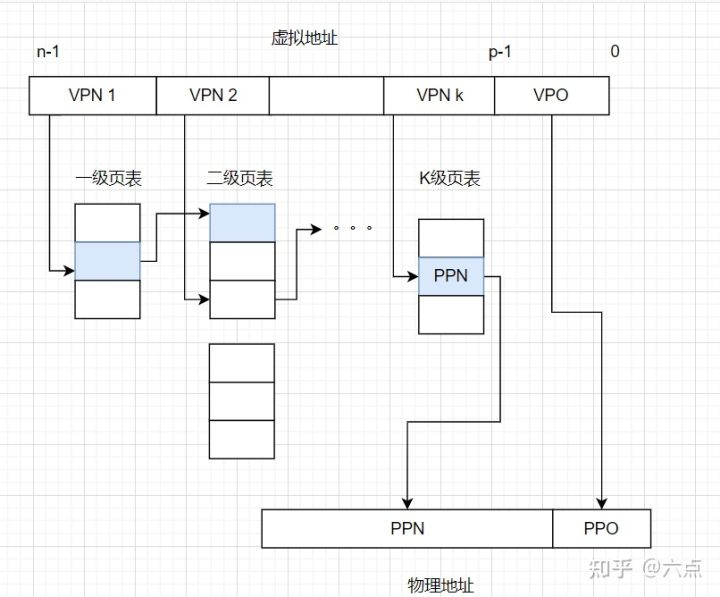
寻址时,首先通过进程 PGD 地址载入一级页表,然后通过每段 VPN 就能逐级找到所有的 page table 的物理地址。
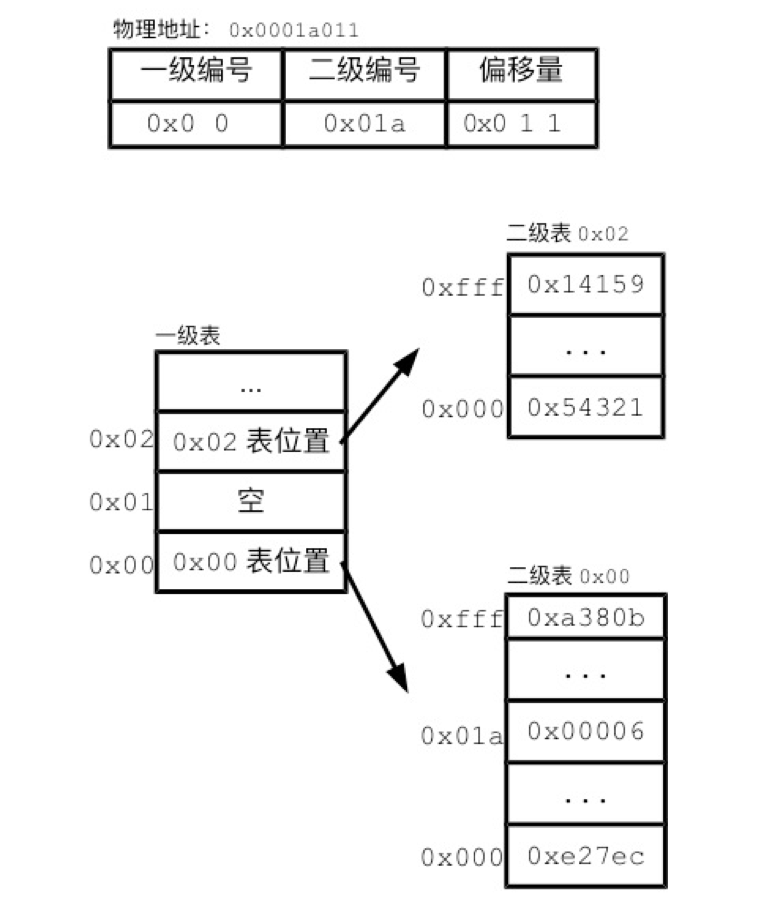
还是以地址 0x0001a011 为例,假设现在是两级页表,那么地址可以分为 0x00、0x01a、0x011 三部分。首先将 pgd 指向的全局页表载入内存,根据 0x00 页表索引,找到第二级页表的内存地址,然后将二级页表载入内存。根据 0x01a 页表索引,找到页帧的物理地址。最后根据 0x011 页内偏移,得到最终的物理地址:
可以注意到,多次从内存中加载页表速度较慢,因此 cpu 有专门的 MMU (内存管理单元) 来实现寻址,其中 TLB (翻译查找缓冲区) 会将页表缓存起来,类似 cpu cache,加快下次寻址。
另外每个进程都有自己独立的页表,我们常说进程切换比线程切换慢,一个重要原因就是 TLB 刷新导致 cache 失效,寻址变慢。
4. 内核空间
区分内核空间和用户空间的一个原因是为了安全性的考虑,用户空间不能申请到内核空间地址上的内存,如果能,内存越界的错误可能就不仅仅是进程崩溃了
另一个是 TLB 缓存性能上的考虑(见下文分析)
4.1 内核页表
根据前面的描述,使用高端内存需要地址空间映射,这样也就需要页表的存在,内核页表用于映射虚拟地址到物理地址
内核页表只有一个,其中 swapper_pg_dir 是内核顶级页目录指针,在内核初始化时创建,这个指针被存储到了 init 进程中,是 init 进程的页目录指针
在内核进程/线程、内核态中访问页表,通过 struct task_struct ---> active_mm 成员来进行访问(不是 swapper_pg_dir):
---> /include/linux/sched.h
struct task_struct {
// ...
struct mm_struct *mm;
struct mm_struct *active_mm;
// ...
}
这个 active_mm 来自哪里呢?
- 在任意用户进程调度到内核进程/线程的时候,调度器会将当前用户进程的 mm 成员赋值给内核进程的 active_mm 成员,mm 成员则为空
- 在陷入内核态的时候,active_mm 成员值也来自 mm 成员
即 active_mm 实际上来自 mm 成员指针,那么 mm 怎么与内核页目录 swapper_pg_dir 建立联系的呢?参看下文
4.2 共享内核空间
我们常常听说所有用户进程共享内核空间,那么这个共享是什么意思呢?为什么要共享呢?
4.2.1 什么是共享
共享是,所有用户进程的内核地址空间都是相同的,这个特性是这么实现的:
- 每个用户进程创建时,会复制 init 内核进程页目录指针,即 swapper_pg_dir 指向的页目录/页表到用户进程的页目录/页表中(struct task_struct--->mm 指针),这样创建进程后,即初步实现了共享内核地址空间
- 在内核中申请虚拟内存的时候,建立的页表映射会被添加到 init 进程页目录,即 swapper_pg_dir 指向的页目录/页表中,而没有建立到 active_mm 指向的页目录中
- 如果此时内核立即根据 active_mm 访问新申请内存的,会发生缺页异常,在异常处理函数中,会将 init 进程的页目录复制到当前 active_mm 指向的页目录中,然后才能正常访问内存
- 当内核进程被换出,或者退出内核态,然后再次进入内核态时,访问上面申请的内存,由于 active_mm 来自于任何用户进程的 mm,此 active_mm 指向的页目录大概率还没有映射过上面申请的内存,所以也会发生缺页异常,然后在缺页处理函数中复制 swapper_pg_dir 指向的页目录/页表
- 所以,内核页表更新后,通过这种 "用时复制" 的方式更新到所有的用户进程,即实现了所有进程更新内核地址空间
4.2.2 为什么要共享
- 每个用户进程都拥有一个页全局目录指针,在进程调度的时候,切换不同的用户态进程,mmu 需要根据页全局目录指针载入新进程对应的页目录
- 在发生用户进程到内核进程调度,或者用户进程陷入内核态的时候,内核访问页表使用的是上一个用户进程的 mm 成员指向的页目录,即 mmu 不重新载入页目录/页表
- 4.2.1 讨论的内核页表共享更新特性,使得内核能够根据任意用户进程的 mm 成员,正常访问内核申请的内存空间
- 然后从内核进程调度到相同的用户进程,或者从内核态退出,mmu 中的 TLB 一直没有载入新的页目录/页表,这样缓存继续有效
4.3 内核对内存的管理
linux 内核对内存的管理分为大体上分为上下两层(实际上内核对内存的管理是非常复杂的,有需要还得深入研究):
- 页管理层,管理物理页帧,需要通过伙伴系统(buddy system)进行页的申请和释放
- 对象管理层,由于伙伴系统申请内存是以页为单位的,所以针对非页大小的内存,特别是小于页大小的内存,采用 slab 分配器在页管理器的基础上进行任意内存大小的管理。同时 slab 也管理着内核常用结构体对象的申请和释放,因此称为对象管理
在内核中调用 kmalloc()、vmalloc() 等申请任意大小的内存,底层依赖于 slab 分配器
4.4 进程地址空间(内存)映射
内存映射即使用 mmap() 接口映射一块物理内存到虚拟内存,虚拟内存地址是连续的,且操作权限相同,但是物理内存地址不必是连续的
映射区域使用 struct vm_area_struct 结构体对象来描述(linux内核设计与实现 15.3章):

文章开头第一节展示了进程地址空间的划分,实际上一个可执行程序第一次从磁盘载入内存,它的代码段、数据段、BSS段、动态链接库、栈都会通过 struct vm_area_struct 结构体对象来进行映射(https://www.cnblogs.com/huxiao-tee/p/4660352.html):

内存映射分为具名的和匿名的,具名映射如动态库载入、文件映射、代码段载入等,匿名映射如堆内存空间的申请
查看程序内存映射可以 cat /proc/pid/maps 或则 pmap pid,实际上他们都是读取进程 struct vm_area_struct 结构体对象中的信息,以如下一小段代码为例:
#include <stdlib.h>
int main() {
char* b = (char*)malloc(4096*10);
while (1) {}
return 0;
}
其 pmap 结果如下:

其中,前三项为映射的代码段、数据段、BSS段,[] 方括号表示匿名映射内存区域,anon 为匿名单词的缩写,接着的 [anon] 即是代码中 malloc() 申请大块内存创建的匿名映射(注意到实际申请的内存大小比需要的大很多)
[stack] 是进程用户态使用的栈空间,也是匿名映射,但是能够看到这段内存是专门用作栈的(注意到当前实际大小比 ulimit -all 看到的栈大小要小很多,具体可以参考 https://www.tiehichi.site/2020/10/22/Linux进程栈空间大小/)
值得一提的是,linux 共享内存、pipe、fifo 等实现,既是将多个 struct vm_area_struct 结构体对象指向同一块物理内存来实现的
5. 用户空间
5.1 内存分配
在系统层,linux 内核提供了 sys_brk() 、do_mmap() 、munmap() 等系统调用接口,用于申请和释放堆内存
在标准库中,提供了如 malloc()、mmap() 等申请内存的接口
以 malloc() 为例(未深入研究,仅仅来自粗浅了解):
- brk,当 malloc() 申请的内存较小时(如小于 128kb),将堆内存的结束地址 brk 增加一定的数值,free() 时,将 brk 恢复到申请内存前的位置。brk 有内存碎片化的问题
- mmap,当 malloc() 申请的内存较大时,采用匿名映射的方式,在堆栈间申请一块内存
实际上 malloc() 内部也有自己的内存缓存块控制,减少系统调用,更高效的申请、释放内存,减少内存碎片,但未深入研究

6. 缺页中断
产生缺页中断的原因有很多,操作系统处理缺页中断也很复杂。大概来说,用户通过进程访问的地址分为两类:
- 匿名的地址空间,如调用 malloc() 申请的堆内存
- 具名的地址空间,如 mmap() 映射的某个磁盘上的文件
对应的,当用户访问这些地址空间的时候,可能会发生缺页中断:
- 多级页表中,某级页表不存在虚拟地址对应的表项,进而不能寻址到最终的物理页面
- 读写的文件内容时,文件并未从磁盘加载到物理内存中
linux 内核处理缺页中断的入口是 do_page_fault() 函数(深入linux内核架构 4.10章):


 浙公网安备 33010602011771号
浙公网安备 33010602011771号