高驱动注意网络(HANET)
文章首发:xmoon.info
PAPER: Cars Can’t Fly up in the Sky: Improving Urban-Scene Segmentation via Height-driven Attention Networks
CityScape数据集
- 介绍
Cityscapes是关于城市街道场景的语义理解图片数据集。它主要包含来自50个不同城市的街道场景,拥有5000张在城市环境中驾驶场景的高质量像素级注释图像(其中 2975 for train,500 for val,1525 for test, 共有19个类别);此外,它还有20000张粗糙标注的图像(gt coarse)。

- 数据集结构
cityscapes
└ leftImg8bit_trainvaltest
└ leftImg8bit
└ train
└ val
└ test
└ gtFine_trainvaltest
└ gtFine
└ train
└ val
└ test
HANet介绍

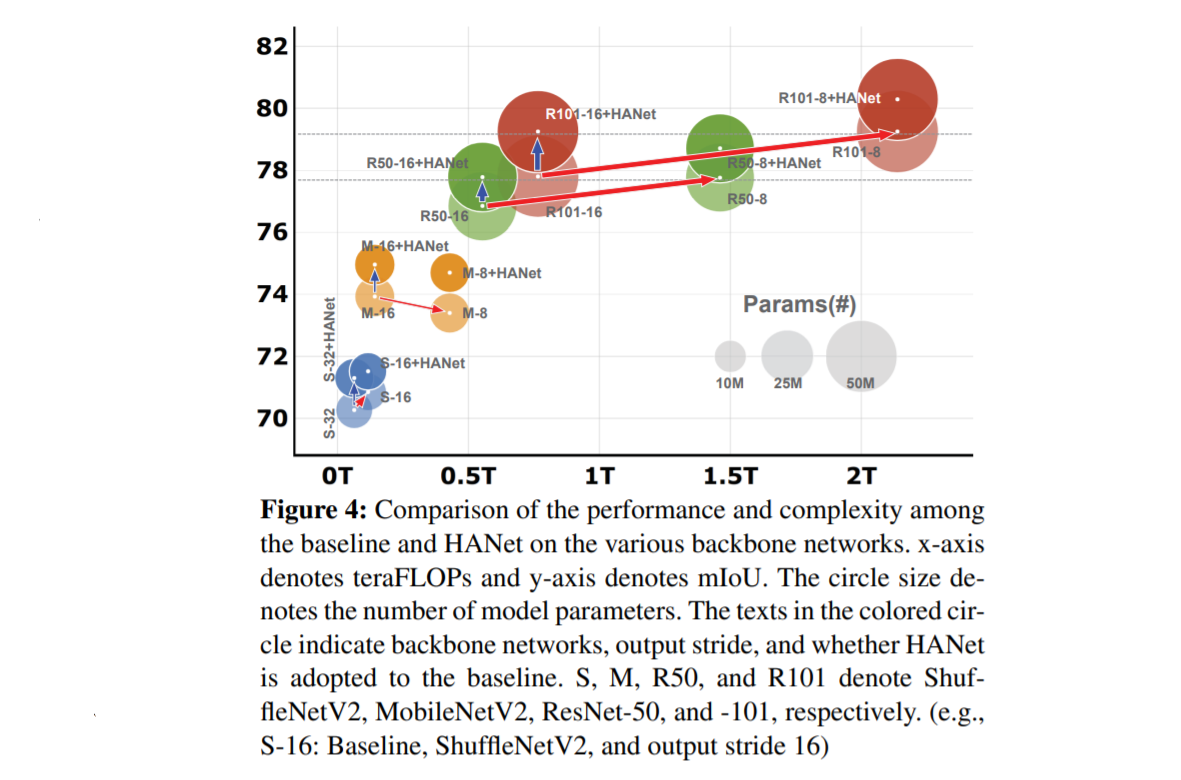
高驱动注意网络(height-driven attention networks)是根据城市数据集的内在特征而提出的通用网络附加模型,提高了城市环境的语义分割的accuracy,容易嵌入各个网络,且对于mIoU有着较为明显的提高
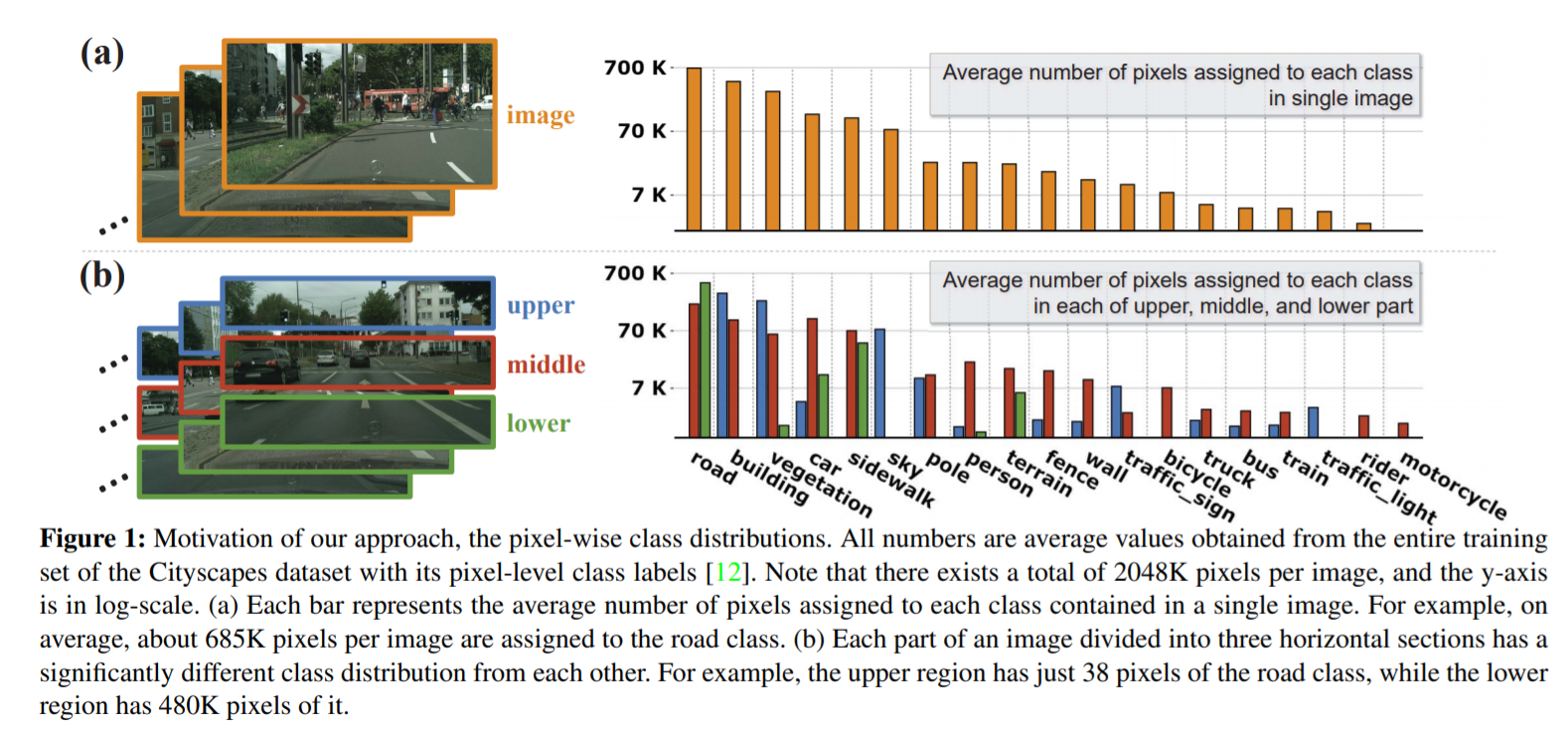
通过观察可以发现城市CityScape数据的数据在高度方向包含的信息密度要远少于水平方向的信息密度,并且有着较为明显的结构性,此方法将数据沿着高度方向分为上、中、下三部分。
Cityscapes dataset中一个像素超过19个类的概率分布X的熵计算为:
\[H(x) = H(p_{road}, p_{building},……,p_{motorcy})=-\sum _i p_i logp_i \]
网络结构
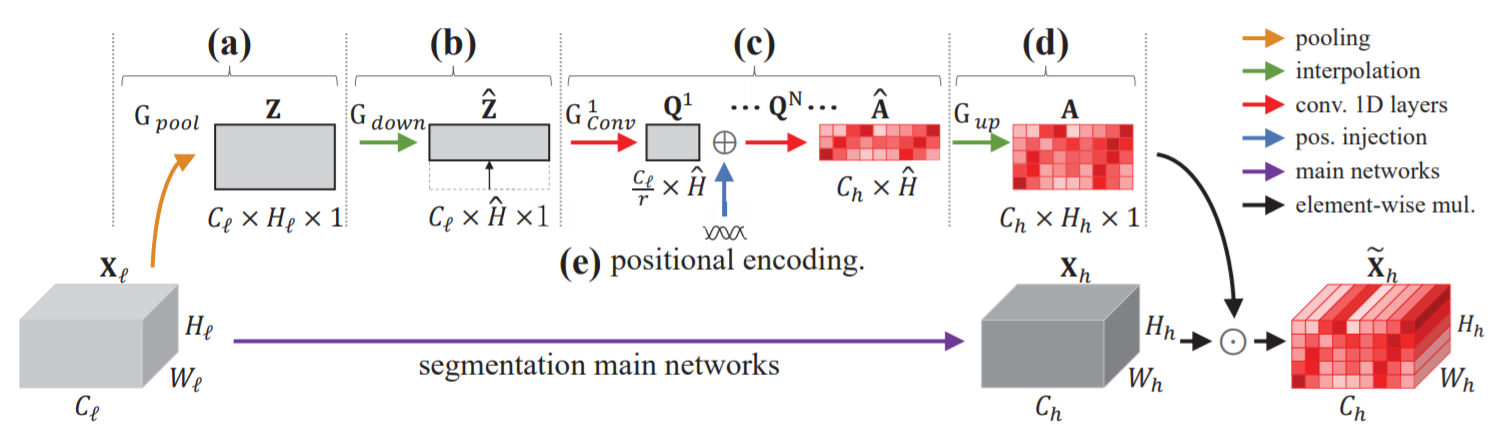
-
\(X_l,X_h\): 语义分割特征图中的底层和高层特征图
-
(a)宽度池化:
获得一个channel-wise attention map 为矩阵\(Z\), \(Z = G_{pool}(X_l)\), 池化方式为平均池化,\(Z\)中的第h行计算方式为$$Z_{:,h}=[\frac1W\sum_{i=1}WX_{1,h,i};…;\frac1W\sum_{i=1}WX_{C,h,i}]$$ -
(b)下采样(插入Coarse Attention):
将(a)中得到的\(Z(C_l \times H_l \times 1)\)进行下采样得到\(\hat{Z}(C_l \times \hat{H} \times 1)\)其中超参数\(\hat{H}\)设置为16 -
(c)计算:
由于每一行都与其相邻的行相关,在估计注意力图时,采用卷积层来考虑相邻行之间的关系。
注意图A表示在每一行中哪些通道是关键的。中间层的每一行可能存在多个信息特征;在最后一层中,每一行都可以与多个标签(如道路、汽车、人行道等)相关联。为了实现这些多重特征和标签,在计算注意力地图时使用了一个sigmoid函数,而不是softmax函数。对于N个卷积层,这些操作可以写成
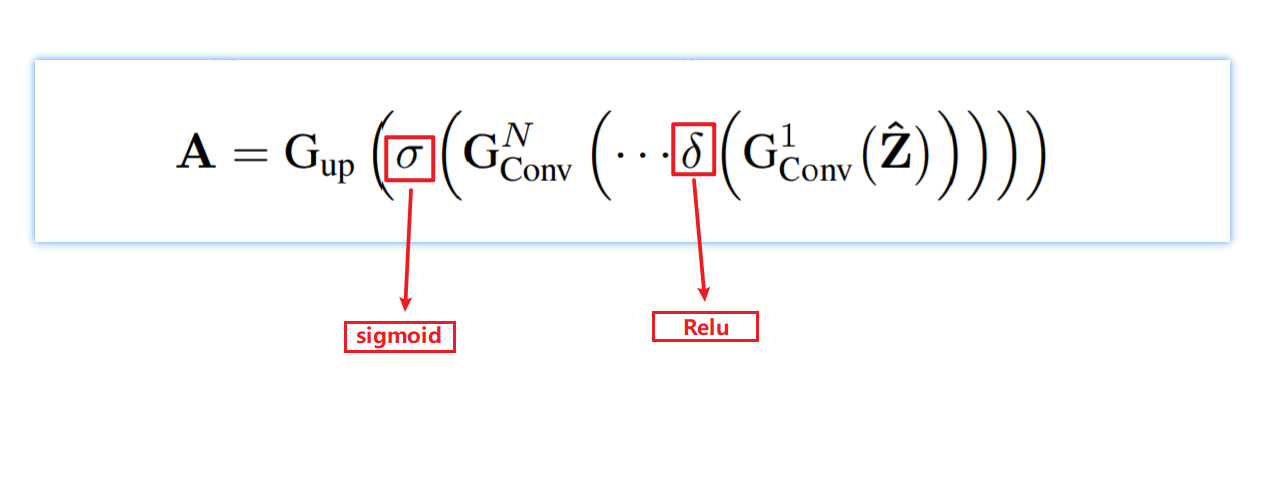
采用三层卷积操作:
1. 降低通道数:\(G_{conv}^1(\hat{Z})= Q^1 \in \R^{\frac{C_l}r \times \hat{H}}\)
2. \(G_{conv}^2(\delta(Q^1 ))=Q^2 \in \R^{2\cdot \frac{C_l}r \times \hat{H}}\)
3. 生成注意力图:\(G_{conv}^3(\delta(Q^2 ))=\hat{A} \in \R^{C_h \times \hat{H}}\)
其中\(r\)为压缩比,降低了参数量的同时还产生了一种正则化的效果 -
(d)上采样:
保持与\(X_h\)高度一致 -
(e)结合位置编码:
人在驾驶时有一些先验知识,比如知道路在下面,天空在上面,因此在中间层特征图\(Q^i\)的第\(i\)层的添加正弦位置编码
位置编码的维数与中间特征图\(Q^i\)的通道数\(C\)相同。位置编码定义为\[PE_{(p,2i)} = sin(p/100^{2i/C}) \]\[PE_{(p,2i+1)} = cos(p/100^{2i/C}) \]p为注意力从0到\(\hat{H}-1\)的整幅图像中的垂直位置指数,i为注意力的维数
垂直位置的数量设置为\(\hat{H}\),作为corse attention中的行数更新位置编码:\(\hat{Q} = Q\oplus PE\)
-
超参数的选取:
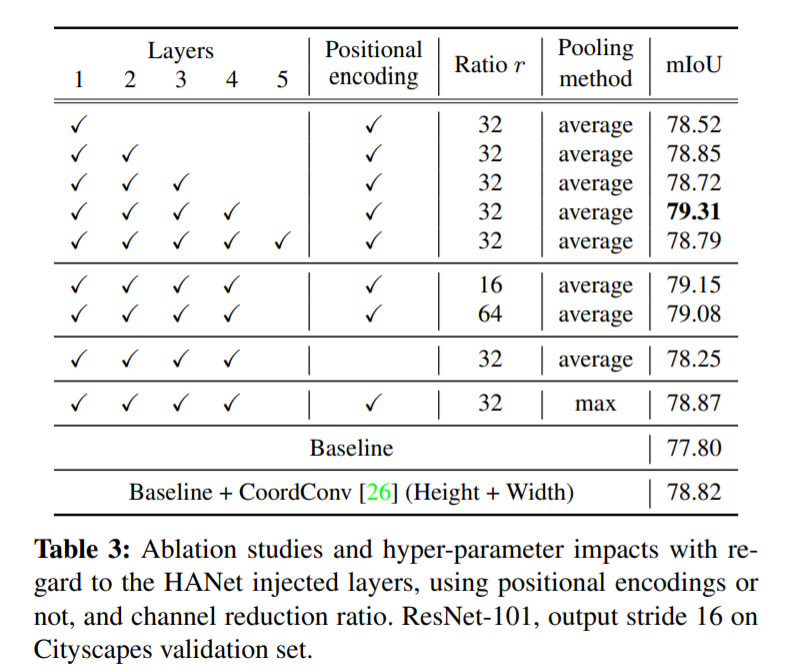
将HANet插入ResNet101
- 结构
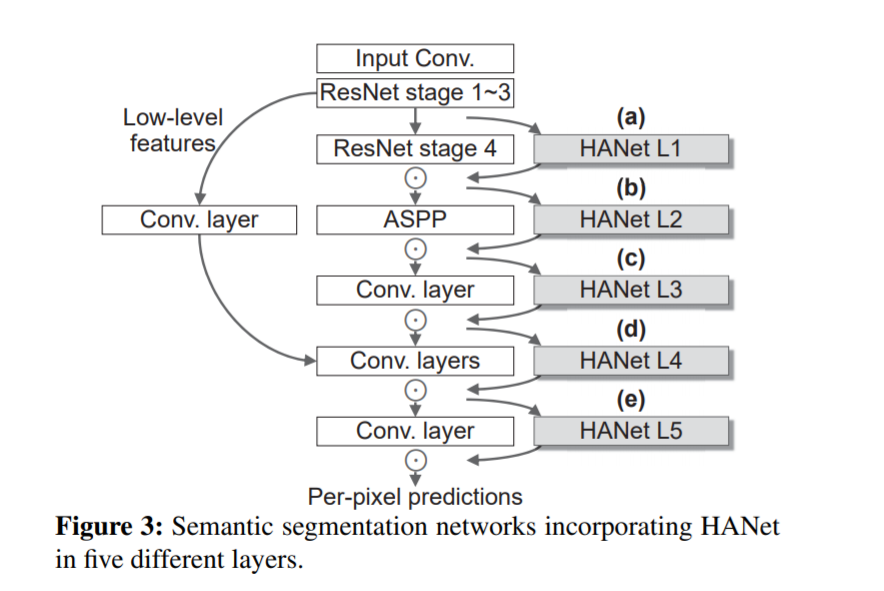
- 配置
- PyTorch v1.3
- 在第一层网络中,使用3个3 x 3的卷积代替一个7 x 7的卷积
- 在中间特征图和类均匀采样中还采用了一种辅助的交叉损失熵
- 采用SGD优化器,初始学习率为0.01,学习率调度遵循多项式学习率策略,动量为0.9
- 权重衰减分别为5e-4和1e-4用于主网络和HANet
- 为了避免过拟合,使用了语义图像分割模型中典型的数据增强方法,包括随机水平翻转、在[0.5,2]范围内随机缩放、高斯模糊、颜色抖动和随机裁剪。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号