python学习笔记
深拷贝和浅拷贝
import copy
# 深拷贝会创建一个新的对象,属性的独立出来的,之前所复制的属性做出了修改不会被影响
#浅拷贝会创建一个新的对象,对应的属性会跟之前的对象做属性的共享,当之前的属性受到影响做出修改后,新的对象的属性也会受到影响
# 定义一个嵌套对象
obj = {'name': 'Alice', 'age': 25, 'address': {'city': 'New York'}}
# 创建浅拷贝对象
obj_copy = copy.copy(obj)
# 创建深拷贝对象
obj_deep_copy = copy.deepcopy(obj)
obj_deep_copy1 = copy.copy(obj)
obj['address']['city'] = 'London'
print(obj) # {'name': 'Alice', 'age': 25, 'address': {'city': 'London'}}
print("深拷贝"+str(obj_deep_copy)) # {'name': 'Alice', 'age': 25, 'address': {'city': 'New York'}}
print("浅拷贝"+str(obj_deep_copy1))
Pytest
import sys
import pytest
def inc(x):
return x+1
def test_answer():
assert inc(4) == 5
def test_str():
assert "a" in "abc"
def test_print():
print(sys.platform)
assert True
params = ["appnium","pytest","selenium"]
@pytest.mark.parametrize("param",[
("3+5",8),("2+5",7),("7+5",12)
])
@pytest.mark.parametrize("expected",params)
def test_mark_more(param,expected):
print(f"param:{param},expected:{expected}")
# mark标签用来对测试用例做标记,可以通过标记来做对应的测试用例调用
# pytest -vs -m "mark标签名"
@pytest.mark.add
def test_function_add():
print("test number add function")
assert 1+5 == 6
@pytest.mark.sub
def test_function_sub():
print("test number sub function")
assert 1-5 == -4
@pytest.mark.mult
def test_function_mult():
print("test number mult function")
assert 1*5 == 5
@pytest.mark.divide
def test_function_divide():
print("test number divide function")
assert 1/5 == 0.2
@pytest.mark.divide
def test_function_divide2():
print("test number divide function")
assert 1/10 == 0.1
如果希望没有警告,在项目根目录下创建pytest.ini文件,并输入对应的内容
[pytest]
markers = add
sub
mult
divide
parametrize
# 跳过这条用例
@pytest.mark.skip
def test_print():
print("test)
# 跳过这条用例并返回原因
@pytest.mark.skip(reason="原因")
def test_print1():
print("test)
# 如果满足条件,就跳过这条用例
@pytest.mark.skipif(sys.platform="win",reason="do not run in windows")
def test_print3():
print("test)
# xfail预期运行失败能够符合预期
@pytest.mark.xfail(reason="原因")
def test_print4():
print("代码尚未开发完")
pytest test_demo.py -vs --lf
--lf参数:将所有失败的测试用例全部重新执行一次
pytest test_demo.py -vs --ff
--ff参数:先执行所有失败的测试用例,再去执行其他的测试用例
-x参数:用例一旦失败(fail/error),就立刻停止执行
--maxfail=num参数:用例达到num数量
-m参数:运行被标记的标签的用例
-k参数:执行包含某个关键字的测试用例
-v参数:打印详细日志
-s参数:打印输出日志(一般-vs一起使用)
-collect-only(测试平台,pytest 自动导入功能)
def test_raise1():
with pytest.raises(ZeroDivisionError) as exc_info:
raise ValueError("value must be 42")
# 获取异常并抛出进行断言
assert exc_info.type is ValueError
assert exc_info.value.args[0] == "value must be 42"
数据驱动-yaml
selenium高级交互
鼠标滚轮操作
import time
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
class TestScroll:
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(3)
def teardown_class(self):
self.driver.quit()
def test_scroll(self):
# 滚动到对应元素的位置
self.driver.get("https://ceshiren.com/tag/%E7%B2%BE%E5%8D%8E%E5%B8%96")
self.driver.maximize_window()
ele1 = self.driver.find_element(By.XPATH,"//*[text()='毕业设计-针对OB-制品项目业务测试方案']")
ActionChains(self.driver).scroll_to_element(ele1).perform()
time.sleep(15)
def test_scroll_to_xy(self):
# 滚动到对应坐标的位置
self.driver.get("https://ceshiren.com/tag/%E7%B2%BE%E5%8D%8E%E5%B8%96")
self.driver.maximize_window()
ActionChains(self.driver).scroll_by_amount(0,3000).perform()
time.sleep(10)
鼠标移动操作
import time
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
class TestMouse:
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(3)
def teardown_class(self):
self.driver.quit()
def test_double_click(self):
# 鼠标双击操作
self.driver.get("https://vip.ceshiren.com/#/ui_study/frame")
self.driver.maximize_window()
ele = self.driver.find_element(By.ID,"primary_btn")
ActionChains(self.driver).double_click(ele).perform()
time.sleep(5)
def test_drag_and_drop(self):
# 鼠标拖动操作
self.driver.get("https://vip.ceshiren.com/#/ui_study/action_chains")
self.driver.maximize_window()
ele1 = self.driver.find_element(By.ID,"item1")
ele2 = self.driver.find_element(By.ID,"item3")
ActionChains(self.driver).drag_and_drop(ele1, ele2).perform()
time.sleep(5)
def test_move_to_element(self):
# 鼠标悬浮操作
self.driver.get("https://vip.ceshiren.com/#/ui_study/action_chains2")
self.driver.maximize_window()
ele1 = self.driver.find_element(By.CLASS_NAME,"title")
ele2 = self.driver.find_element(By.XPATH,"//*[contains(text(),'管理班')]")
ActionChains(self.driver)\
.move_to_element(ele1)\
.click(ele2)\
.perform()
time.sleep(5)
键盘输入操作
import sys
import time
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
class Testweb:
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(3)
def teardown_class(self):
self.driver.quit()
def test_shife(self):
# 键盘输入带shift按键
self.driver.get("https://ceshiren.com")
self.driver.maximize_window()
self.driver.find_element(By.ID,"search-button").click()
ele = self.driver.find_element(By.ID,"search-term")
ActionChains(self.driver).key_down(Keys.SHIFT, ele).send_keys("selenium").perform()
time.sleep(5)
def test_enter_by_send_keys(self):
# 键盘输入指定内容
self.driver.get("https://www.sogou.com/")
self.driver.maximize_window()
self.driver.find_element(By.ID,"query").send_keys("selenium")
self.driver.find_element(By.ID,"stb").click()
time.sleep(5)
def test_exit_by_actions(self):
# 键盘输入指定内容并按回车进行搜索
self.driver.get("https://www.sogou.com/")
self.driver.maximize_window()
ActionChains(self.driver)\
.key_down(Keys.SHIFT)\
.send_keys("selenium")\
.key_down(Keys.ENTER)\
.perform()
time.sleep(5)
def test_copy_and_paste(self):
# 键盘进行copy和paste操作
self.driver.get("https://www.sogou.com/")
self.driver.maximize_window()
if sys.platform == "darwin":
command_control = Keys.COMMAND
else:
command_control = Keys.CONTROL
ele = self.driver.find_element(By.ID,"query")
ActionChains(self.driver)\
.key_down(Keys.SHIFT,ele)\
.send_keys("selenium")\
.key_down(Keys.ARROW_LEFT)\
.key_down(command_control)\
.send_keys("cvvvv").key_up(command_control).perform()
time.sleep(5)
多窗口和frame处理
切换页面和切换frame
import time
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
class TestBaidu:
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(3)
self.driver.maximize_window()
def tear_down(self):
self.driver.quit()
def test_baidu(self):
# 切换页面
self.driver.get("https://www.baidu.com/")
self.driver.find_element(By.LINK_TEXT, "登录").click()
# print(self.driver.current_window_handle)
self.driver.find_element(By.LINK_TEXT, "立即注册").click()
windows = self.driver.window_handles
self.driver.switch_to.window(windows[1])
self.driver.find_element(By.ID,"TANGRAM__PSP_4__userName").send_keys("username")
self.driver.find_element(By.ID,"TANGRAM__PSP_4__phone").send_keys("15915420233")
self.driver.find_element(By.ID,"TANGRAM__PSP_4__password").send_keys("password")
self.driver.switch_to.window(windows[0])
self.driver.find_element(By.ID, "TANGRAM__PSP_11__userName").send_keys("username")
self.driver.find_element(By.ID, "TANGRAM__PSP_11__password").send_keys("password")
time.sleep(5)
def test_switch_to_frame(self):
# 切换frame后切换回默认frame
self.driver.get("https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable")
self.driver.switch_to.frame("iframeResult")
print(self.driver.find_element(By.ID, "draggable").text)
self.driver.switch_to.parent_frame()
print(self.driver.find_element(By.ID, "submitBTN").text)
# time.sleep(5)
文件上传及弹窗处理
上传文件
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
class TestIamge:
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(3)
self.driver.maximize_window()
def teardown_class(self):
self.driver.quit()
def test_uploadfile(self):
# 文件上传
self.driver.get("https://image.baidu.com/")
self.driver.find_element(By.XPATH,"//*[@id='sttb']/img[1]").click()
self.driver.find_element(By.ID,"stfile").send_keys("D:\code_repository\pythonProject\img\img1.jpg")
time.sleep(5)
弹窗处理
import time
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
class TestAlert:
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(3)
self.driver.maximize_window()
def teardown_class(self):
self.driver.quit()
def test_alert(self):
# 弹窗处理
self.driver.get("https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable")
self.driver.switch_to.frame("iframeResult")
element = self.driver.find_element(By.ID, "draggable")
target_element = self.driver.find_element(By.ID, "droppable")
ActionChains(self.driver).drag_and_drop(element,target_element).perform()
alert = self.driver.switch_to.alert
print(alert.text)
alert.accept()
time.sleep(5)
获取日志
日志工具类
import logging
# 创建logger实例
logger = logging.getLogger('simple_example')
# 设置日志级别
logger.setLevel(logging.DEBUG)
# 流处理器
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG)
# 日志打印格式
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
# 添加格式配置
ch.setFormatter(formatter)
# 添加日志配置
logger.addHandler(ch)
打印日志和截图、获取源码
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from log_util import logger
class TestDataRecord:
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(3)
self.driver.maximize_window()
def teardown_class(self):
self.driver.quit()
def test_log_data_record(self):
# 打印日志
search_content = "selenium"
self.driver.get("https://www.sogou.com/")
self.driver.find_element(By.ID, "query").send_keys(search_content)
logger.debug(f"搜索信息为{search_content}")
self.driver.find_element(By.ID, "stb").click()
elements = self.driver.find_elements(By.CSS_SELECTOR, 'em')
for element in elements:
logger.info(f"实际结果为{element.text},预期结果为{search_content}")
time.sleep(5)
def test_screenshot_data_record(self):
# 保存截图
search_content = "selenium"
self.driver.get("https://www.sogou.com/")
self.driver.find_element(By.ID, "query").send_keys(search_content)
logger.debug(f"搜索信息为{search_content}")
self.driver.find_element(By.ID, "stb").click()
elements = self.driver.find_elements(By.CSS_SELECTOR, 'em')
print(elements)
for element in elements:
logger.info(f"实际结果为{element.text},预期结果为{search_content}")
index_num = str(elements.index(element))
self.driver.save_screenshot("search_content"+index_num+".jpg")
def test_page_source(self):
# 保存页面源码
search_content = "selenium"
self.driver.get("https://www.sogou.com/")
self.driver.find_element(By.ID, "query").send_keys(search_content)
logger.debug(self.driver.page_source)
with open("../log/log1.html", "x", encoding="u8") as file:
file.write(self.driver.page_source)
浏览器复用
步骤
1、获取浏览器的路径

2、配置环境变量到path

3、关闭所有chrome浏览器并关闭进程
cmd运行chrome --remote-debugging-port=9222
4、使用浏览器复用操作
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
# 定义配置的实例对象
option = Options()
# 修改实例属性为debug模式启动的ip+端口
option.debugger_address = "localhost:9222"
# 实例化driver的时候,添加option配置
driver = webdriver.Chrome(options=option)
driver.get("https://work.weixin.qq.com/wework_admin/loginpage_wx")
Cookie复用
import json
import time
import yaml
from selenium import webdriver
class TestChromeCookie:
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.maximize_window()
self.driver.implicitly_wait(3)
def test_get_cookie(self):
# 获取cookie并把内容写入到文件中
self.driver.get("https://work.weixin.qq.com/wework_admin/loginpage_wx")
time.sleep(20)
cookie = self.driver.get_cookies()
with open("../cookie/cookie.yaml", "w") as filter:
yaml.dump(cookie, filter)
print(cookie)
def test_add_cookie(self):
# 使用cookie进行登录
# cookies = self.test_get_cookie()
self.driver.get("https://work.weixin.qq.com/wework_admin/loginpage_wx")
cookies = yaml.safe_load(open("../cookie/cookie.yaml"))
for cookie in cookies:
self.driver.add_cookie(cookie)
self.driver.get("https://work.weixin.qq.com/wework_admin/loginpage_wx")
time.sleep(5)
异常截图并导入到报告中
import time
import allure
import pytest
from selenium import webdriver
from selenium.webdriver.common.by import By
class TestBaidu:
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.maximize_window()
def tearDown(self):
self.driver.quit()
def test_baidu(self):
self.driver.get("https://www.baidu.com")
try:
self.driver.find_element(By.ID, "su")
except Exception:
print("出现异常啦")
timestamp = int(time.time())
# 截图
image_path = f"../images/image_{timestamp}.png"
page_source_path = f"../page_source/page_source_{timestamp}.html"
self.driver.save_screenshot(image_path)
# 记录page_source
with open(page_source_path, mode="w", encoding='u8') as f:
f.write(self.driver.page_source)
allure.attach.file(image_path, name="picture", attachment_type=allure.attachment_type.PNG)
allure.attach.file(page_source_path, name="page_source", attachment_type=allure.attachment_type.HTML)
# 将异常抛出
raise Exception
通过命令行进行运行生成allure需要加载的内容
pytest python文件路径 --alluredir=./reports
然后通过allure命令进行allure测试报告进行读取
allure serve ./reports
代码优化
import time
import allure
import pytest
from selenium import webdriver
from selenium.webdriver.common.by import By
from util.decorators_util import ui_exception_record
"""
把装饰器的架子搭好
把相关的逻辑嵌套进来
问题1:
需要通过driver实例截图/打印page_source,装饰器需要先去获取driver对象
解决方案:
1、通过setup_class进行driver对象的声明
2、在使用driver之前声明driver
问题2:
隐藏的Bug:一旦被装饰方法有返回值,会丢失返回值
解决方法:
当被装饰方法被执行的时候,添加return
"""
class TestBaidu:
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.maximize_window()
def tear_down(self):
self.driver.quit()
@ui_exception_record
def find(self):
return self.driver.find_element(By.ID, "su1")
# 使用装饰器进行代码优化
def test_baidu(self):
self.driver.get("https://www.baidu.com")
self.find().click()
装饰器工具封装
# 通过装饰器进行优化代码
import allure
def ui_exception_record(func):
def inner(*args, **kwargs):
# 获取被装饰方法的self也就是实例方法
# 通过self就可以拿到声明的实例变量driver
# 前提条件:
# 1、被装饰的方法是一个实例方法
# 2、实例需要有实例变量self.driver
try:
# 当被装饰方法、函数发生异常就捕获并做数据记录
return func(*args, **kwargs)
except Exception:
driver = args[0].driver
print("出现异常啦")
timestamp = int(time.time())
# 截图
image_path = f"../images/image_{timestamp}.png"
page_source_path = f"../page_source/page_source_{timestamp}.html"
driver.save_screenshot(image_path)
# 记录page_source
with open(page_source_path, mode="w", encoding='u8') as f:
f.write(driver.path_source)
allure.attach.file(image_path, name="picture", attachment_type=allure.attachment_type.PNG)
allure.attach.file(page_source_path, name="page_source", attachment_type=allure.attachment_type.TEXT)
# # 将异常抛出
raise Exception
return inner
page object设计模式
POM建模原则
字段意义
不要暴露页面内部的元素给外部
不需要建模UI内的所有元素
方法意义
用公共方法代表UI所提供的功能
方法应该返回其他的PageObject或者返回用于断言的数据
同样的行为不同的结果可以建模为不同的方法
不要在方法内加断言
把元素信息和操作细节封装到PageObject类中
根据业务逻辑,在测试用例中链式调用
Django
创建项目方式
访问进入到想要放置项目的地址
终端运行命令
django-admin startproject 项目名
快速上手
确保App已注册 setting.py
在setting.py文件中注册App
from django.apps import AppConfig
class App01Config(AppConfig):
default_auto_field = 'django.db.models.BigAutoField'
name = 'DjangoTryProject'
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'DjangoProject.apps'
]
# 新版本Django不用写方法名 直接写应用名就能够注册
编写url和视图函数对应关系 ursl.py
如果访问 域名/index/,将会找到view中的index方法并执行index方法
from DjangoTryProject import view
urlpatterns = [
# path('admin/', admin.site.urls),
path('index/', view.index),
]

编写视图函数
from django.http import HttpResponse
def index(request):
return HttpResponse("欢迎使用Django")
启动Django项目
命令行方式
python manager.py runserver
pycharm直接运行
跟前端文件联动
创建一个templates文件夹,里面放需要使用的前端html文件
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>测试Django</title>
</head>
<body>
<h1>用户列表</h1>
</body>
</html>
from django.http import HttpResponse
from django.shortcuts import render
def index(request):
return HttpResponse("欢迎使用Django")
def user_list(request):
return render(request, "user_list.html")
静态文件
放到static文件夹并用文件夹区分好
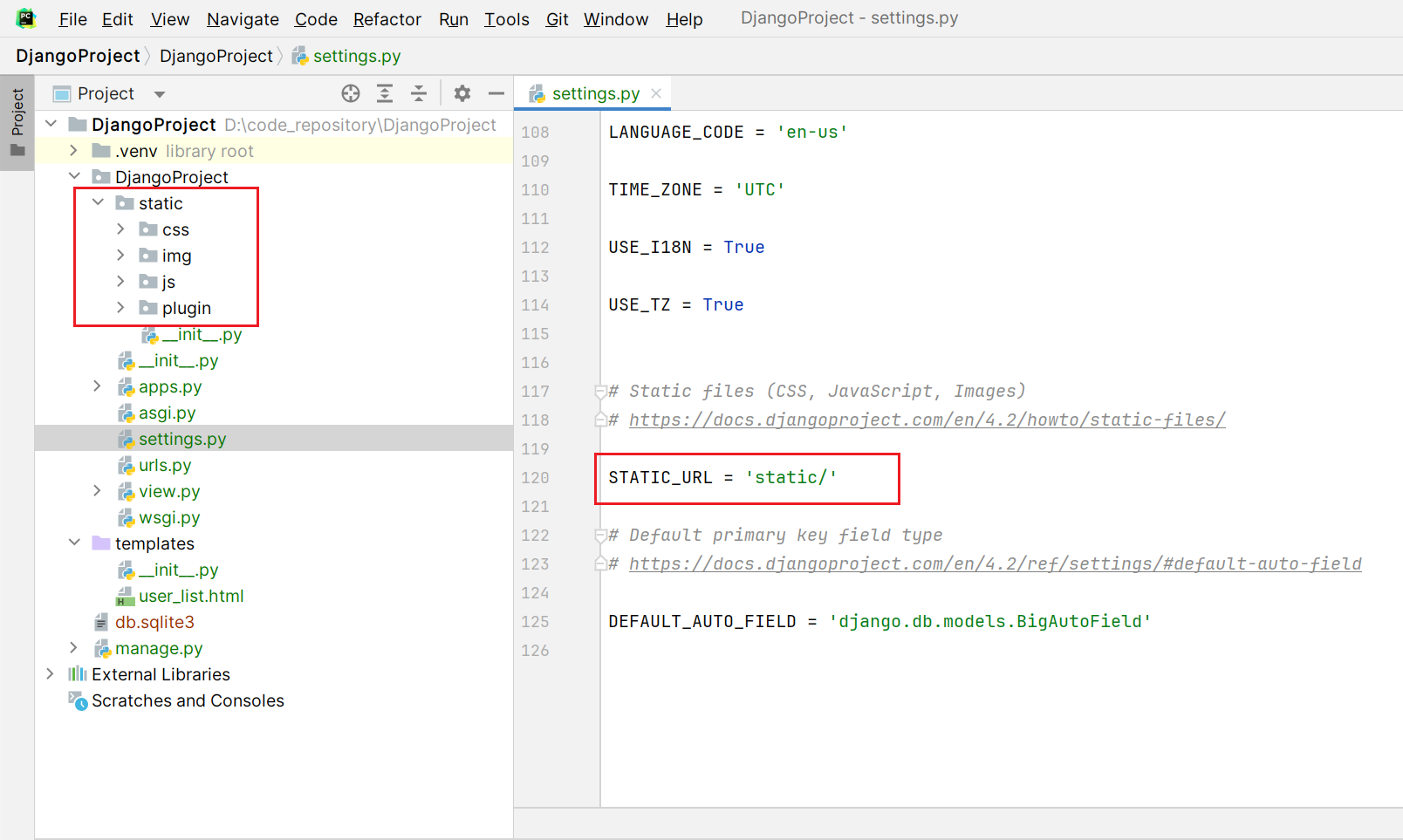
静态文件引入
{% load static %}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>测试Django</title>
</head>
<body>
<h1>用户列表</h1>
</body>
<script src="{% static 'js/jquery.js' %}"></script>
</html>
模版语法
通过在html文件中填写占位符,然后由数据对这些占位符进行替换和处理
def tpl(request):
name = "tpl测试"
roles = ["admin","user","CES"]
user_info = {"name":"郭嘉","salary":2000,"role":"CTO"}
data_list = [
{"name": "曹操", "salary": 2000, "role": "CTO"},
{"name": "郭嘉", "salary": 2000, "role": "CTO"},
{"name": "张飞", "salary": 2000, "role": "CTO"}
]
return render(request, "tpl.html", {"n1":name,"n2":roles,"n3":user_info,"n4":data_list})
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>tpl</title>
</head>
<body>
<h1>模版语法的学习</h1>
<div>{{ n1 }}</div>
<div>
{% for item in n2 %}
<span>{{ item }}</span>
{% endfor %}
</div>
<hr>
<ul>
{% for item in n3.values %}
<li>{{ item }}</li>
{% endfor %}
</ul>
<hr>
{{ n4 }}
{{ n4.0.name }}
{{ n4.0.salary }}
{{ n4.0.role }}
<hr>
{% for foo in n4 %}
<div>{{ foo.name }}</div>
<div>{{ foo.salary }}</div>
<div>{{ foo.role }}</div>
{% endfor %}
<hr>
{% if n1 == "tpl测试" %}
<div>tpl测试</div>
{% else %}
<div>tpl测试失败</div>
{% endif %}
</body>
</html>
模版语法实战
def news(request):
import requests
result = requests.get(
url="https://i.news.qq.com/gw/event/pc_hot_ranking_list?ids_hash=&offset=0&page_size=50&appver=15.5_qqnews_7.1.60&rank_id=hot"
)
data_list = result.json()["idlist"][0]["newslist"]
return render(request, "news.html", {"result": data_list})
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>腾讯新闻</title>
</head>
<body>
<ul>
{% for foo in result %}
<li>{{ foo.id }}</li>
<li>{{ foo.articletype }}</li>
<li>{{ foo.picShowType }}</li>
<li>{{ foo.title }}</li>
{% endfor %}
</ul>
{{ result }}
</body>
</html>
用户访问逻辑
用户访问地址,会到urls.py匹配到对应的方法,然后到view.py中找到这个方法,再又这个方法的模版页面替换里面的数据,然后再渲染给用户
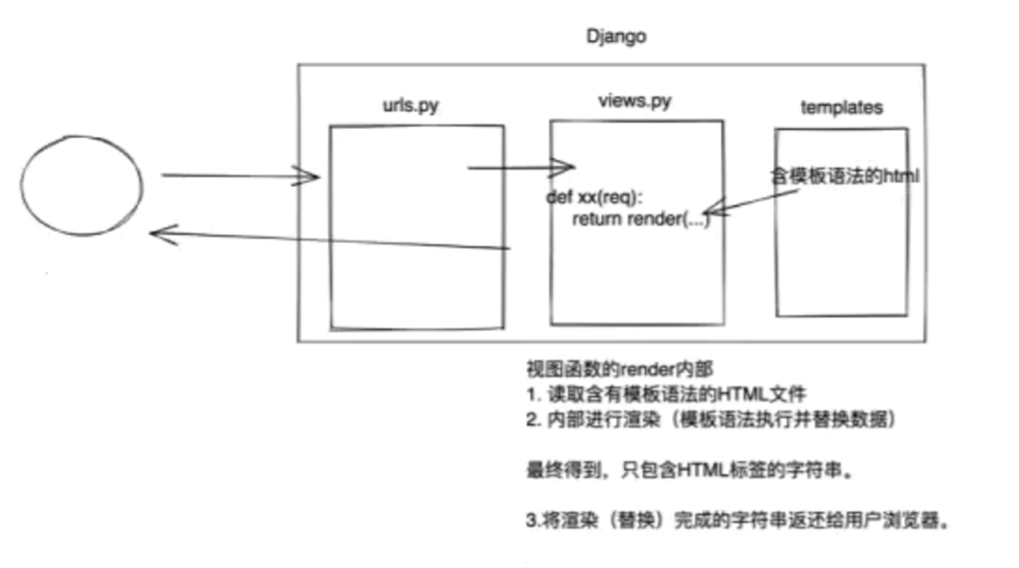
获取url的传参
- request.GET方法能够获取param
- request.POST方法能够获取到POST请求的请求体
- request.method方法能够获取请求方式
return的内容
- redirect重定向
- render方法页面模版
- HttpResponse响应
提交表单
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<form action="/login/" method="post" >
{% csrf_token %}
<input type="text" name="user" placeholder="用户名">
<input type="password" name="password" placeholder="密码">
<input type="submit" value="提交">{{ error_message }}
</form>
</body>
</html>
表单提交的时候,需要在form中补充{% csrf_token %}才不会报错
{{ error_message }}如果需要出现报错信息,就可以在方法中补充传值
def login(request):
if request.method == "GET":
return render(request, "login.html")
user = request.POST.get("user")
password = request.POST.get("password")
if user == "root" and password == "1234":
print(request.POST)
return render(request, "login.html", {"error_message":"登录成功"})
else:
return render(request, "login.html", {"error_message":"用户名或密码错误"})
数据库操作
Django开发操作数据库更简单,内部提供了ORM框架
安装第三方模块mysqlclient
pip install mysqlclient
ORM作用
- 不用亲自写SQL语句
- 创建修改删除数据库中的表(无法创建database)
- 操作表中的数据
Django连接数据库
DATABASES = {
"default": {
"ENGINE": "django.db.backends.mysql",#使用的引擎包
"NAME": "",#数据库database名称
"USER": "",#数据库账号
"PASSWORD": "",#数据库密码
"HOST": "",#本地ip
"PORT": "",#端口号
}
}
创建表
from django.db import models
"""
自动运行以下代码
create table DjangoProject_userinfo(
id bigint primary key autoincrement,
name varchar(32),
password varchar(64),
age int
)
"""
class User_info(models.Model):
name = models.CharField(max_length=32)
age = models.IntegerField()
password = models.CharField(max_length=64)
text = models.CharField(max_length=16)
textname = models.CharField(max_length=16,default=2)
# 如果希望字段可以为空,可以传参null=True,blank=True
#如果要在已有的表里面新增字段,需要添加默认值,或者新增字段的时候赋予默认值
#如果需要删除表, 直接删除class就可以
class department(models.Model):
name = models.CharField(max_length=16)
class role(models.Model):
name = models.CharField(max_length=16)
cmd运行(大前提:App必须已经注册)
python.exe .\manage.py makemigrations APP名称
python.exe .\manage.py migrate
# 如果出现了报错django.db.utils.NotSupportedError: MySQL 8 or later is required (found 5.5.27).
# 可以访问到C:\Users\方振钦\AppData\Local\Programs\Python\Python39\Lib\site-packages\django\db\backends\base下的bash.py文件中
# 找到self.check_database_version_supported()并注释掉
新建数据
department.object.create(name="销售部")
# 运行python manage.py migrate,会在mysql中生成数据
# 不能用python manage.py makemigrations来运行,会生成两份数据
def orm(request):
if request.method == 'GET':
return render(request, "orm.html")
username = request.POST.get("name")
age = request.POST.get("age")
password = request.POST.get("password")
text = request.POST.get("text")
#插入数据
User_info.objects.create(name= username, age = age, password =password, text = text)
#删除id=1的数据
User_info.objects.filter(id="1").delete()
#删除表中全部的数据
User_info.objects.all().delete()
#获取数据
userObject = User_info.objects
user_list = User_info.objects.all()
for user in user_list:
print(user.name, user.password, user.age, user.text)
# print(user_list)
userObject.filter(id=1).update(password = 123123)
first = userObject.filter(id=1).first()
print(first.name, first.age, first.text, first.password)
return HttpResponse("上传成功")
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>orm</title>
</head>
<body>
<form action="/orm/" method="post">
{% csrf_token %}
<input type="text" placeholder="name" name="name">
<input type="text" placeholder="age" name="age">
<input type="password" placeholder="password" name="password">
<input type="text" placeholder="text" name="text">
<input type="submit" value="提交">
</form>
</body>
</html>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号